数据挖掘-多维数据集

1.多维数据集
实验目的:
在 BI Development Studio 的 Analysis Services 项目中定义数据源、数据源视图、维度、属性、属性关系、层次结构和多维数据集。通过将 Analysis Services 项目部署到 Analysis Services 实例来查看多维数据集和维度数据,以及如何在随后处理已部署的对象以使用基础数据源中的数据来填充对象。在Analysis Services 项目中修改度量值、维度、层次结构、属性和度量值组,
以及如何将增量更改部署到开发服务器上的已部署多维数据集。
实验内容:
通过Analysis Services –多维数据的教程,理解维、成员、粒度等基
本概念及其之间的关系,知道Microsoft SQL Server 中的联机分析处理(OLAP) 和数据挖掘项目是根据一个或多个数据源中相关表、视图和查询的逻辑数据模型来设计的。使用数据源视图可以定义填充大型数据仓库的数据子集。此外,通过数据源视图还可以定义基于异类数据源或数据源子集的同源架构。运用Analysis Server工具进行维度、度量值以及多维数据集的创建。使用维度浏览器进行多维数据的查询、编辑操作。对多维数据集进行切片、切块、旋转、操作。实验步骤:
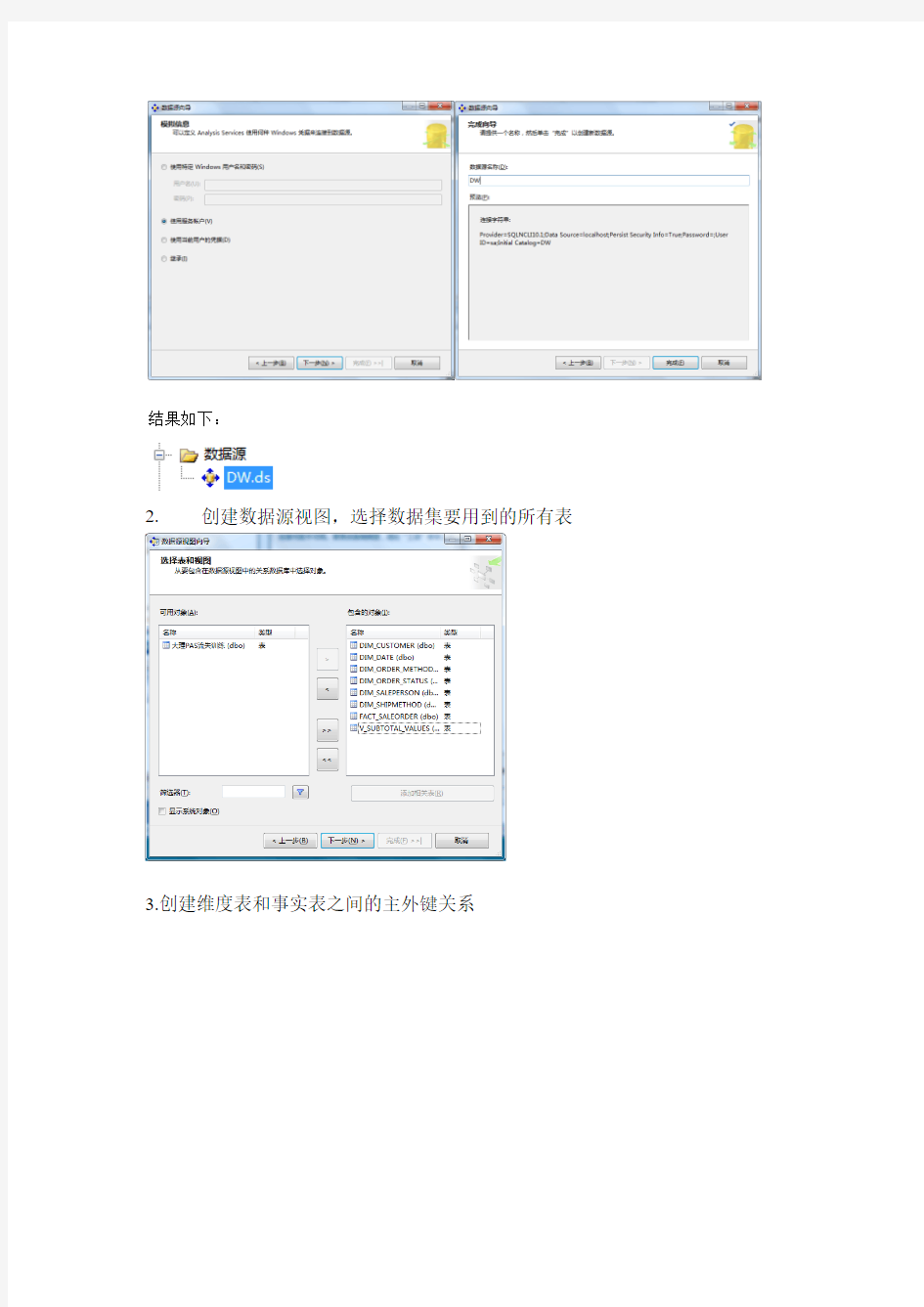
1.首先应在Business Intelligence Development Studio 中创建一个Analysis Services 项目。将项目名称更改为:DW,并创建数据源。
结果如下:
2.
创建数据源视图,选择数据集要用到的所有表
3.创建维度表和事实表之间的主外键关系
3.建立分析维度:以发货方式、下单方式、订单状态、订单价值、销售人员、日期、客户等表来建立维度。
以订单价值维度为例:
在创建维度时,选择使用现有表并且选择订单价值表
在选择维度属性时,添加所有属性,并修改维度名称:订单价值
在订单价值的维度属性中,选择DSC为层次结构
在维度中创建一个属性关系,处理后查看效果如下:
其他维度的查询结果如下:
4.建立多维数据集,确定度量值(修改相应度量值的显示名称),选择已经建好的维度
完成多维数据集向导如下:
钻取地区:国家→省→市-订单数量
切块:订单价值-订单数量-客户受教育程度
切片:订单价值-订单数量
实验心得:
通过此次实验,明白了联机分析处理(OLAP)是数据仓库的重要数据分析工具,它是处理共享多维信息的快速分析,建立OLAP 的基础是多维数据模型,它将数据分为度量和维度,度量表示定量的数据,被组织为事实表,而维度是表示定性的数据,相对于事实,它的描述性更强,被组织为维度表。并且多维数据分析操作包括:切片、切块、旋转(可以得到不同视角的数据)、钻取(可以得到更多的细节性数据)等。
实验1_建立多维数据集
实验1 建立多维数据集 实验目的 通过使用SQL Server建立多维数据集,使学生理解和掌握建立多维数据集的一般过程和方法。 实验内容 1、建立FoodMart多维数据集 实验条件 1.操作系统:Windows XP SP2 2.SQL Server 2000 实验要求: 1、按照实验步骤中练习建立FOODMART多维数据集。 实验步骤 第一步, 建立系统数据源连接 1.单击“开始”按钮,指向“设置”,单击“控制面板”,然后双击“管理工具”,再双击“数据源(ODBC)”。 1.在“系统DSN”选项卡上单击“添加”按钮。 2.选择“Microsoft Access 驱动程序(*.mdb)”,然后单击“完成”按钮。 3.在“数据源名”框中,输入“教程”,然后在“数据库”下,单击“选择”。 4.在“选择数据库”对话框中,浏览到“C:\Program Files\Microsoft Analysis Services\Samples”,然后单击“FoodMart 2000.mdb”。单击“确定”按钮。 5.在“ODBC Microsoft Access 安装”对话框中单击“确定”按钮。 6.在“ODBC 数据源管理器”对话框中单击“确定”按钮。 第二步, 启动Analysis Manager
单击“开始”按钮,依次指向“程序”、“Microsoft SQL Server”和“Analysis Services”,然后单击“Analysis Manager”。 第三步,建立数据库和数据源 1.在Analysis Manager 树视图中展开“Analysis Servers”。 2.单击服务器名称,即可建立与Analysis Servers 的连接。 3.右击服务器名称,然后单击“新建数据库”命令。 4.在“数据库”对话框中的“数据库名称”框中,输入“教程”,然后单击“确定”按钮。 5.在Analysis Manager 树窗格中展开服务器,然后展开刚才创建的“教程”数据库。 6.在Analysis Manager 树窗格中,右击“教程”数据库下的“数据源”文件夹,然后单击“新数据源” 命令。 7.在“数据链接属性”对话框中,单击“提供者”选项卡,然后单击“Microsoft OLE DB Provider for ODBC Drivers”。
图销售分析”的多维数据集模型的设计共8页word资料
数据仓库与数据挖掘 实验报告 姓名:岩羊先生 班级:数技2011 学号:XXXXXX 实验日期:2013年11月14日 目录 实验.............................................. 错误!未定义书签。 【实验目的】............................... 错误!未定义书签。 1、熟悉SQLservermanager studio和VisualStudio2008软件功能 和操作特点; ................................ 错误!未定义书签。 2、了解SQLservermanager studio和VisualStudio2008软件的各 选项面板和操作方法; ........................ 错误!未定义书签。 3、熟练掌握SQLserver manager studio和VisualStudio2008工 作流程。................................... 错误!未定义书签。 【实验内容】............................... 错误!未定义书签。 1.打开SQLserver manager studio软件,逐一操作各选项,熟悉
软件功能; (4) 2.根据给出的数据库模型“出版社销售图书Pubs”优化结构,新建立数据库并导出; (4) 3.打开VisualStudio2008,导入已有数据库、或新建数据文件,设计一个“图书销售分析”的多维数据集模型。并使用各种输出节点,熟悉数据输入输出。 (4) 【实验环境】............................... 错误!未定义书签。【实验步骤】............................... 错误!未定义书签。 1.打开 SQL Server manager studio; (5) 2.附加备份的数据库文件pubs_DW_Data.MDF和pubs_DW_Log.LDF 并且做出优化; (5) 3.修改数据库属性; (5) 4.建立数据仓库所需的数据库bb(导出); (5) 5. 创建新的分析服务项目; (5) 6. 新建数据源(本地服务器输入“.”) (5) 7.建立多维数据集 (6) 8.处理多维数据集,得出模型: (6) 9.模型实例: (6) 【实验中的困难及解决办法】................. 错误!未定义书签。问题1:SQLserver中数据库的到导出. (6)
kdd99数据集详解-数据挖掘
KDD是数据挖掘与知识发现(Data Mining and Knowledge Discovery)的简称,KDD CUP 是由ACM(Association for Computing Machiner)的SIGKDD (Special Interest Group on Knowledge Discovery and Data Mining)组织的年度竞赛。竞赛主页在这里。 下面是历届KDDCUP的题目: KDD-Cup 2008, Breast cancer KDD-Cup 2007, Consumer recommendations KDD-Cup 2006, Pulmonary embolisms detection from image data KDD-Cup 2005, Internet user search query categorization KDD-Cup 2004, Particle physics; plus Protein homology prediction KDD-Cup 2003, Network mining and usage log analysis KDD-Cup 2002, BioMed document; plus Gene role classification KDD-Cup 2001, Molecular bioactivity; plus Protein locale prediction. KDD-Cup 2000, Online retailer website clickstream analysis KDD-Cup 1999, Computer network intrusion detection KDD-Cup 1998, Direct marketing for profit optimization KDD-Cup 1997, Direct marketing for lift curve optimization ”KDD CUP 99 dataset ”就是KDD竞赛在1999年举行时采用的数据集。从这里下载KDD99数据集。 1998年美国国防部高级规划署(DARPA)在MIT林肯实验室进行了一项入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的一个网络环境,收集了9周时间的TCPdump(*) 网络连接和系统审计数据,仿真各种用户类型、各种不同的网络流量和攻击手段,使它就像一个真实的网络环境。这些TCPdump采集的原始数据被分为两个部分:7周时间的训练数据(**) 大概包含5,000,000多个网络连接记录,剩下的2周时间的测试数据大概包含2,000,000个网络连接记录。 一个网络连接定义为在某个时间内从开始到结束的TCP数据包序列,并且在这段时间内,数据在预定义的协议下(如TCP、UDP)从源IP地址到目的IP地址的传递。每个网络连接被标记为正常(normal)或异常(attack),异常类型被细分为4大类共39种攻击类型,其中22种攻击类型出现在训练集中,另有17种未知攻击类型出现在测试集中。
数据仓库的多维数据模型定义 作用 实例
数据仓库的多维数据模型定义作用实例 2010年08月19日06:53 来源:网站数据分析作者:佚名编辑:李伟评论:0条 本文Tag:信息化频道商业智能数据仓库参考文献BI行业信息化【IT168 信息化】 可能很多人理解的数据仓库就是基于多维数据模型构建,用于OLAP的数据平台,通过上一篇文章——数据仓库的基本架构,我们已经看到数据仓库的应用可能远不止这些。但不得不承认多维数据模型是数据仓库的一大特点,也是数据仓库应用和实现的一个重要的方面,通过在数据的组织和存储上的优化,使其更适用于分析型的数据查询和获取。 多维数据模型的定义和作用 多维数据模型是为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型,其基本的应用是为了实现OLAP (Online Analytical Processing)。 当然,通过多维数据模型的数据展示、查询和获取就是其作用的展现,但其真的作用的实现在于,通过数据仓库可以根据不同的数据需求建立起各类多维模型,并组成数据集市开放给不同的用户群体使用,也就是根据需求定制的各类数据商品摆放在数据集市中供不同的数据消费者进行采购。 多维数据模型实例 在看实例前,这里需要先了解两个概念:事实表和维表。事实表是用来记录具体事件的,包含了每个事件的具体要素,以及具体发生的事情;维表则是对事实表中事件的要素的描述信息。比如一个事件会包含时间、地点、人物、事件,事实表记录了整个事件的信息,但对时间、地点和人物等要素只记录了一些关键标记,比如事件的主角叫“Michael”,那么Michael到底“长什么样”,就需要到相应的维表里面去查询“Michael”的具体描述信息了。基于事实表和维表就可以构建出多种多维模型,包括星形模型、雪花模型和星座模型。这里不再展开了,解释概念真的很麻烦,而且基于我的理解的描述不一定所有人都能明白,还是直接上实例吧:
数据挖掘_Yeast Dataset(酵母数据集)
Yeast Dataset(酵母数据集) 数据摘要: Interaction detection methods have led to the discovery of thousands of interactions between proteins, and discerning relevance within large-scale data sets is important to present-day biology. The dataset consists of protein-protein interaction network described and analyzed in (1) and available as an example in the software package - PIN (2). 中文关键词: 酵母,交互检测,蛋白质,数据集, 英文关键词: Yeast,Interaction detection,proteins,dataset, 数据格式: TEXT 数据用途: Information Processing Classification
数据详细介绍: Yeast Description https://www.360docs.net/doc/a015565271.html, network with 2361 vertices and 7182 edges (536 loops). https://www.360docs.net/doc/a015565271.html, network with 2361 vertices and 7182 edges (536 loops). yeast.clu partition of vertices. yeast.paj Pajek project file with complete dataset. Download complete dataset (ZIP, 134K) Background Interaction detection methods have led to the discovery of thousands of interactions between proteins, and discerning relevance within large-scale data sets is important to present-day biology. The dataset consists of protein-protein interaction network described and analyzed in (1) and available as an example in the software package - PIN (2). PIN class encoding: 1 - T, 2 - M, 3 - U, 4 - C, 5 - F, 6 - P, 7 - G, 8 - D, 9 - O, 10 - E, 11 - R, 12 - B, 13 - A. https://www.360docs.net/doc/a015565271.html, X interacts with Y relation, short names. https://www.360docs.net/doc/a015565271.html, X interacts with Y relation, long labels. yeast.clu PIN class partition of vertices, see encoding. yeast.paj Pajek project file with complete dataset. References Shiwei Sun, Lunjiang Ling, Nan Zhang, Guojie Li and Runsheng Chen: Topological structure analysis of the protein-protein interaction network in budding yeast. Nucleic Acids Research, 2003, Vol. 31, No. 9 2443-2450 (PDF).
数据仓库与数据挖掘实验二(多维数据组织与分析)
一、实验内容和目的 目的: 1.理解维(表)、成员、层次(粒度)等基本概念及其之间的关系; 2.理解多维数据集创建的基本原理与流程; 3.理解并掌握OLAP分析的基本过程与方法; 内容: 1.运用Analysis Server工具进行维度、度量值以及多维数据集的创建(模拟案例)。 2.使用维度浏览器进行多维数据的查询、编辑操作。 3.对多维数据集进行切片、切块、旋转、钻取操作。 二、所用仪器、材料(设备名称、型号、规格等) 操作系统平台:Windows 7 数据库平台:SQL Server 2008 SP2 三、实验原理 在数据仓库系统中,联机分析处理(OLAP)是重要的数据分析工具。OLAP的基本思想是企业的决策者应能灵活地、从多方面和多角度以多维的形式来观察企业的状态和了解企业的变化。 OLAP是在OLTP的基础上发展起来的,OLTP是以数据库为基础的,面对的是操作人员和低层管理人员,对基本数据的查询和增、删、改等进行处理。而OLAP是以数据仓库为基础的数据分析处理。它具有在线性(online)和多维分析(multi-dimension analysis)的特点。OLAP超越了一般查询和报表的功能,是建立在一般事务操作之上的另外一种逻辑步骤,因此,它的决策支持能力更强。 建立OLAP的基础是多维数据模型,多维数据模型的存储可以有多种不同的形式。MOLAP和ROLAP是OLAP的两种主要形式,其中MOLAP(multi-dimension OLAP)是基
于多维数据库的OLAP,简称为多维OLAP;ROLAP(relation OLAP)是基于关系数据库的OLAP,简称关系OLAP。 OLAP的目的是为决策管理人员通过一种灵活的多维数据分析手段,提供辅助决策信息。基本的多维数据分析操作包括切片、切块、旋转、钻取等。随着OLAP的深入发展,OLAP也逐渐具有了计算和智能的能力,这些能力称为广义OLAP操作。 四、实验方法、步骤 要求:利用实验室和指导教师提供的实验软件,认真完成规定的实验内容,真实地记录实验中遇到的各种问题和解决的方法与过程,并根据实验案例绘出多维数据组织模型及其OLAP操作过程。实验完成后,应根据实验情况写出实验报告。 五、实验过程原始记录(数据、图表、计算等) 本实验以实验一建立的数据仓库为基础,使用Microsoft的SQL Server Business Intelligence Development Studio工具,建立OLAP相关模型,并实现OLAP的一些简单基本功能。 首先打开SQL Server Business Intelligence Development Studio工具,新建一个Analysis Service项目,命名为:DW
SQL Server 2005 多维数据集创建过程
SQL Server 2005 多维数据集创建过程 一.创建新的Analysis Services项目 1.单击“开始”,指向“所有程序”,再指向Microsoft SQL Server 2005,再单击SQL Server Business Intelligence Development Studio,打开Microsoft Visual Studio 2005开发环境。 2.在Visual Studio的“文件”菜单上,指向“新建”,再单击“项目”。 3.在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“Analysis Services项目”。 4.将项目名称更改为Analysis Services Tutorial1,这也将更改解决方案名称,然后单击“确定”。 至此,在同样名为Analysis Services Tutorial1的新解决方案中基于Analysis Services项目模板成功创建了Analysis Services Tutorial1项目。 二.定义新的数据源 1.在Microsoft Visual Studio 2005开发环境中,打开解决方案资源管理器,右键单击“数据源”,然后单击“新建数据源”,将打开数据源向导。
2.在“欢迎使用数据源向导”页上,单击“下一步”。 3.在“选择如何定义连接”页上,单击“新建”。 4.在“提供程序”的下拉列表框中,选中“本机OLE DB\Microsoft OLE DB Provider for SQL Server”,然后单击“确定”。 5.在“服务器名称”文本框中,键入localhost。 6.确保已选中“使用Windows身份验证”。在“选择或输入数据库名称”列表中,选择AdventureWorksDW,然后单击“确定”。 7.在“新建数据源向导”页上,然后单击“下一步”。 8.选择“使用服务帐户”,然后单击“下一步”。 9.在“完成向导”页上,单击“完成”以创建名为Adventure Works DW的新数据源。 10.打开解决方案资源管理器,可以看到“数据源”文件夹中的新数据源。 三.定义一个新的数据源视图 1.在解决方案资源管理器中,右键单击“数据源视图”,再单击“新建数据源视图”。 2.在“欢迎使用数据源视图向导”页中,单击“下一步”。
数据挖掘_Epinions datasets(Epinions数据集)
Epinions datasets(Epinions数据集) 数据摘要: it contains the ratings given by users to items and the trust statements issued by users. 中文关键词: Epinions,数据集,信息,信任度,等级, 英文关键词: Epinions,datasets,information,trust metrics,ratings, 数据格式: TEXT 数据用途: Social Network Analysis Information Processing Classification 数据详细介绍: Epinions datasets
The dataset was collected by Paolo Massa in a 5-week crawl (November/December 2003) from the https://www.360docs.net/doc/a015565271.html, Web site. The dataset contains 49,290 users who rated a total of 139,738 different items at least once, writing 664,824 reviews. 487,181 issued trust statements. Users and Items are represented by anonimized numeric identifiers. The dataset consists of 2 files. Contents 1 Files 1.1 Ratings data 1.2 Trust data 1.3 Data collection procedure 2 Papers analyzing Epinions dataset Ratings data ratings_data.txt.bz2 (2.5 Megabytes): it contains the ratings given by users to items. Every line has the following format: user_id item_id rating_value For example, 23 387 5 represents the fact "user 23 has rated item 387 as 5" Ranges: user_id is in [1,49290] item_id is in [1,139738] rating_value is in [1,5] Trust data
数据挖掘报告
哈尔滨工业大学 数据挖掘理论与算法实验报告(2016年度秋季学期) 课程编码S1300019C 授课教师邹兆年 学生姓名汪瑞 学号 16S003011 学院计算机学院
一、实验内容 决策树算法是一种有监督学习的分类算法;kmeans是一种无监督的聚类算法。 本次实验实现了以上两种算法。在决策树算法中采用了不同的样本划分方式、不同的分支属性的选择标准。在kmeans算法中,比较了不同初始质心产生的差异。 本实验主要使用python语言实现,使用了sklearn包作为实验工具。 二、实验设计 1.决策树算法 1.1读取数据集 本次实验主要使用的数据集是汽车价值数据。有6个属性,命名和属性值分别如下: buying: vhigh, high, med, low. maint: vhigh, high, med, low. doors: 2, 3, 4, 5more. persons: 2, 4, more. lug_boot: small, med, big. safety: low, med, high. 分类属性是汽车价值,共4类,如下: class values:unacc, acc, good, vgood 该数据集不存在空缺值。
由于sklearn.tree只能使用数值数据,因此需要对数据进行预处理,将所有标签类属性值转换为整形。 1.2数据集划分 数据集预处理完毕后,对该数据进行数据集划分。数据集划分方法有hold-out法、k-fold交叉验证法以及有放回抽样法(boottrap)。 Hold—out法在pthon中的实现是使用如下语句: 其中,cv是sklearn中cross_validation包,train_test_split 方法的参数分别是数据集、数据集大小、测试集所占比、随机生成方法的可
BI_数据仓库基础
1 BI Business Intelligence,即商业智能,商务智能综合企业所有沉淀下来的信息,用科学的分析方法,为企业领导提供科学决策信息的过程。 BOSS业务运营支撑系 BPM企业绩效管理 BPR业务流程重整 CRM客户关系管理 CUBE立方体 DM(Datamart)数据集市数据仓库的子集,它含有较少的主题域且历史时间更短数据量更少,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。 DM(DataMine)数据挖掘 DSS决策支持系统 EDM企业数据模型 3 ERP Enterprise Resourse Planning企业资源规划。它是一个以管理会计为核心的信息系统,识别和规划企业资源,从而获取客户订单,完成加工和交付,最后得到客户付款。换言之,ERP将企业内部所有资源整合在一起,对八个采购、生产、成本、库存、分销、运输、财务、人力资源进行规划,从而达到最佳资源组合,取得最佳效益。 4 ETL 数据抽取(Extract)、转换(Transform)、清洗(Cleansing)、装载(Load)的过程。构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终 按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。 KDD数据库中知识发现 5 KPI 企业关键业绩指标(KPI:KeyProcessIndication)是通过对组织内部流程的输入端、输出端的关键参数进行设臵、取样、计算、分析,衡量流程绩效的一种目标式量化管理指标,是把企业的战略目标分解为可操作的工作目标的工具,是企业绩效管理的基础。 LDM逻辑数据模型 6 MDD 多维数据库(Multi Dimesional Database,MDD)可以简单地理解为:将数据存放在一个n维数组中,而不是像关系数据库那样以记录的形式存放。因此它存在大量稀疏矩阵,人们可以通过多维视图来观察数据。多维数据库增加了一个时间维,与关系数据库相比,它的优势在于可以提高数据处理速度,加快反应时间,提高查询效率。 Metadata(元数据),它是“关于数据的数据,其内容主要包括数据仓库的数据字典、数据的定义、数据的抽取规则、数据的转换规则、数据加载频率等信息。 MOLAP自行建立了多维数据库,来存放联机分析系统数据 7 ODS(四个特点) (Oprational Data Store)操作型数据存储,是建立在数据准备区和数据仓库之间的一个部件。用来满足企业集成的、综合的操作型处理需要,操作数据存储是个可选的部件。对于一些准实时的业务数据库当中的数据的暂时存储,支持一些同时关连到历史数据与实时数据分
多维数据模型与OLAP实现
多维数据模型与OLAP实现 近年来,随着网络技术和数理分析在银行业中的广泛应用,西方商业银行开始广泛采用人口地理统计理论,运用数据挖掘及商业智能 对用户请求的快速响应和交互式操作。 OLAP技术在国内兴起和发展的过程中,人们对某些基本概念还有不同的理解。比如,OLAP与多维数据模型的关系,多维数据模型与多维数据库(MDD,MultiDimensionalDatabase)的关系,MOLAP(Multidime
nsionalOLAP,多维联机分析处理)、ROLAP(RelationalOLAP,关系联机分析处理)和HOLAP(HybridOLAP,混合联机分析处理)间的差异,多维数据库与多维联机分析处理是不是完全一致等问题,还有待于进一步澄清。 一、多维数据模型及相关概念 同的维属性。 2.维:是人们观察数据的特定角度,是考虑问题时的一类属性。 属性的集合构成一个维(如时间维、机构维等)。 3.维分层:同一维度还可以存在细节程度不同的各个描述方面(如时间维可包括年、季度、月份、旬和日期等)。
4.维属性:维的一个取值,是数据项在某维中位置的描述(例如“某年某月某日”是在时间维上位置的描述)。 5.度量:立方体中的单元格,用以存放数据。 OLAP的基本多维分析操作有钻取(Rollup,Drilldown)、切片(Slice)、切块(Dice)及旋转(P 钻取包含向下钻取和向上钻取 在多维数据结构中 OLAP多维数据模型的实现有多种途径,其中主要有采用数组的多维数据库、关系型数据库以及两者相结合的方式,人们通常称之为MOLAP、ROLAP和HOLAP。但MOLAP的提法容易引起误解,毕竟根据OLAP的多维概念,ROLAP也是一种多 维数据的组织方式。
多维数据集
数据集通过其度量值和维度定义。多维数据集中的度量值和维度派生自多维数据集所基于的数据源视图中的表和视图。多维数据集由基于一个或多个事实数据表的度量值和基于一个或多个维度表的维度组成。维度基于属性,而属性映射到数据源视图中的维度表或视图中的一列或多列,然后通过这些属性定义层次结构。 多维数据集示例 请考虑下面的“进口”多维数据集,其中包含“包”和“上一次”两个度量值以及“路线”、“源”和“时间”三个相关维度。 多维数据集周围更小的字母数字值是维度的成员。示例成员为“陆地”(“路线”维度的成员)、“非洲”(“源”维度的成员)以及“第一季度”(“时间”维度的成员)。 度量值 多维数据集中的值表示两个度量值:“包”和“上一次”。“包”度量值表示进口包的数量,使用 Sum 函数聚合其事实数据。“上一次”度量值表示收到的日期,使用 Max 函数聚合其事实数据。 维度 “路线”维度表示进口货物到达目的地的方式。该维度的成员包括“陆地”、“非陆地”、“航空”、“海路”、“公路”或“铁路”。“源”维度表示进口货物的原产地,如“非洲”或“亚洲”。“时间”维度表示一年的四个季度以及上半年和下半年。 聚合 多维数据集的业务用户可以确定多维数据集每个维度的每个成员的度量值,不用考虑维度中成员的级别,因为 Analysis Services 将按需在更高级别中聚合值。例如,上图中的度量值按下面的方式在“时间”维度中的标准日历层次结构内聚合。
除了在一个维度内聚合之外,度量值还可以聚合来自不同维度的成员的各种组合。这样使业务用户得以同时按多个维度中的成员对度量值进行评估。例如,如果业务用户要分析各个季度通过航空运输从东半球和西半球进口的货物,则业务用户可以对多维数据集发出相应的查询以检索以下数据集。 定义完多维数据集之后,可以定义聚合以确定处理过程中预先计算的聚合范围与查询时计算的聚合范围。有关详细信息,请参阅聚合和聚合设计 (SSAS)。 映射度量值、属性和层次结构 多维数据集的度量值、属性和层次结构派生自多维数据集事实数据表和维度表中的下列各列。
数据挖掘_概念与技术(第三版)部分习题答案汇总
1.4 数据仓库和数据库有何不同?有哪些相似之处? 答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。它用表组织数据,采用ER数据模型。 相似:它们都为数据挖掘提供了源数据,都是数据的组合。 1.3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。 答:特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息, 还有所修的课程的最大数量。 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。 关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。例如,一个数据挖掘系统可能发现的关联规则为:major(X, “computing science”) ? owns(X, “personal computer”) [support=12%, confidence=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。 分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。它们的相似性是他们都是预测的工具: 分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。 聚类分析的数据对象不考虑已知的类标号。对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组。形成的每一簇可以被看作一个对象类。聚类也便于分类法组织形式,将观测组织成类分 层结构,把类似的事件组织在一起。 数据演变分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分析、序列或周期模式匹配、和基于相似性的数据分析 2.3 假设给定的数据集的值已经分组为区间。区间和对应的频率如下。――――――――――――――――――――――――――――――――――――― 年龄频率――――――――――――――――――――――――――――――――――――― 1~5 200 5~15 450 15~20 300 20~50 1500 50~80 700 80~110 44 ―――――――――――――――――――――――――――――――――――――计算数据的近似中位数值。 解答:先判定中位数区间:N=200+450+300+1500+700+44=3194;N/2=1597 ∵ 200+450+300=950<1597<2450=950+1500; ∴ 20~50 对应中位数区间。
数据仓库多维数据模型的设计
1、数据仓库基本概念 1.1、主题(Subject) 主题就是指我们所要分析的具体方面。例如:某年某月某地区某机型某款App的安装情况。主题有两个元素:一是各个分析角度(维度),如时间位置;二是要分析的具体量度,该量度一般通过数值体现,如App安装量。 1.2、维(Dimension) 维是用于从不同角度描述事物特征的,一般维都会有多层(Level:级别),每个Level 都会包含一些共有的或特有的属性(Attribute),可以用下图来展示下维的结构和组成:以时间维为例,时间维一般会包含年、季、月、日这几个Level,每个Level一般都会有ID、NAME、DESCRIPTION这几个公共属性,这几个公共属性不仅适用于时间维,也同样表现在其它各种不同类型的维。 1.3、分层(Hierarchy) OLAP需要基于有层级的自上而下的钻取,或者自下而上地聚合。所以我们一般会在维的基础上再次进行分层,维、分层、层级的关系如下图:
每一级之间可能是附属关系(如市属于省、省属于国家),也可能是顺序关系(如天周年),如下图所示: 1.4、量度 量度就是我们要分析的具体的技术指标,诸如年销售额之类。它们一般为数值型数据。我们或者将该数据汇总,或者将该数据取次数、独立次数或取最大最小值等,这样的数据称为量度。 1.5、粒度 数据的细分层度,例如按天分按小时分。 1.6、事实表和维表 事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发
生的事情。事实表中存储数字型ID以及度量信息。 维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。 事实表和维表通过ID相关联,如图所示: 1.7、星形/雪花形/事实星座 这三者就是数据仓库多维数据模型建模的模式 上图所示就是一个标准的星形模型。 雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。 事实星座模式就是星形模式的集合,包含星形模式,也就包含多个事实表。
网络电影数据集(IMDB dataset)_数据挖掘_科研数据集
网络电影数据集(IMDB dataset) 数据介绍: This is a link dataset built with permission from the Internet Movie Data (IMDB). Each row is a film or television program. Each attribute represents an actors, directors, etc. In a given row, there is a 1 (one) for every person associated with that row (i.e. film or television program), and a 0 (zero) for every person not associated with that row. The data file is itself stored in a sparse format, so don't expect a giant CSV matrix. The output is 1 (one) if Mel Blanc, voice of Bugs Bunny and other cartoon characters, was involved in the film or television program. Mel Blanc was chosen as the output because he appeared in more films or television programs than any other person in the database, at the time of compilation. Note, Mel Blanc is not among input attributes. 关键词: 链接数据集,IMDB,电影,电视节目,演员,导演, link dataset,IMDB,film,television program,actor,director, 数据格式: TEXT
多维数据组织与分析
多维数据组织与分析 Prepared on 22 November 2020
昆明理工大学信息工程与自动化学院学生实验报告 ( 2016 — 2017 学年第二学期) 一、上机目的 目的: 1.理解维(表)、成员、层次(粒度)等基本概念及其之间的关系; 2.理解多维数据集创建的基本原理与流程; 3.理解并掌握OLAP分析的基本过程与方法; 4. 学会使用基本的MDX语句 二、上机内容 1.基于上次实验建立的地铁数据仓库,构建地铁公司收入的多维数据 集。 2.使用维度浏览器进行多维数据的查询、编辑操作。 3.对多维数据集进行切片、切块、旋转、钻取操作。 4.使用MDX语句对多维数据集进行切片。 注意:可参照Analysis Services的教程,构建多维数据集。要求时间和站点维度采用层次结构。 利用实验室和指导教师提供的实验软件,认真完成规定的实验内
容,真实地记录实验中遇到的各种问题和解决的方法与过程,并根据实验案例绘出多维数据组织模型及其OLAP操作过程。实验完成后,应根据实验情况写出实验报告。 三、实验原理及基本技术路线图(方框原理图或程序流程图) 请描述联机分析处理的相关基本概念(MOLAP、ROLAP、切片、切块、旋转、钻取等)。 1.M OLAP:表示基于多维数据组织的OLAP实现。使用多维数组存储数 据。 特点:将细节数据和聚合后的数据均保存在cube中,所以以空间换效率,查询时效率高,但生成cube时需要大量的时间和空间。 2.R OLAP:表示基于关系数据库的OLAP实现。将多维数据库的多维结构 划分为事实表,和维表。 特点:将细节数据保留在关系型数据库的事实表中,聚合后的数据也保存在关系型的数据库中。这种方式查询效率最低,不推荐使用。 3.切片:在给定数据立方体的一个维上进行选择操作就是切片,切片的 结果是得到一个二维平面数据。 4.切块:在给定数据立方体的两个或多个维上进行选择操作就是切块, 切块的结果得到一个子立方体。 5.旋转:维度变换的方向,即在表格中重新安排维的放置(例如行列互 换)。 6.钻取:改变维的层次,变换分析的粒度。它包括向下钻取和向上钻 取。 四、实验方法、步骤(或:程序代码或操作过程) 1.多维数据集
汽车数据集(cars dataset)_数据挖掘_科研数据集
汽车数据集(cars dataset) 数据介绍: This was the 1983 ASA Data Exposition dataset. The dataset was collected by Ernesto Ramos and David Donoho and dealt with automobiles. Data on mpg, cylinders, displacement, etc. (8 variables) for 406 different cars. The dataset includes the names of the cars. 关键词: 汽车,缸,排气量,名字,展览会, automobile,cylinder,displacement,name,exposition, 数据格式: TEXT 数据详细介绍: Cars dataset The Committee on Statistical Graphics of the American Statistical Association (ASA) invites you to participate in its Second (1983) Exposition of Statistical Graphics Technology. The purposes of the Exposition are (l) to provide a forum in which users and providers of statistical graphics technology can exchange information and ideas and (2) to expose those members of the ASA community who are less familiar with statistical graphics to its capabilities and potential benefits to them. The Exposition wil1 be held in conjunction with the Annual Meetings in Toronto, August 15-18, 1983 and is tentatively scheduled for the afternoon of Wednesday, August 17.