冒泡排序(实验报告)

一、实验目的和要求
理解和掌握冒泡排序技术,使用C语言根据相应算法编写一个程序,实现冒泡排序。要求仔细阅读下面的内容,编写C程序,上机通过,并观察其结果,写出实验报告书。
二、实验内容和原理
内容:用冒泡排序对顺序存储的长度为10的无序线性表排序。
原理:
首先,从表头开始往后扫描线性表,依次比较相邻两个元素,若前面的元素大于后面的元素,将它们交换。
然后,从后往前扫描后面的线性表,依次比较相邻两个元素,若后面的元素大于前面的元素,将它们交换。
对剩下的线性表重复上述过程,直到剩余表为空。此时的线性表为有序。
三、主要仪器设备
计算机一台
四、实验主程序
#include
void bub(int a[],int n);
int main(void)
{
int
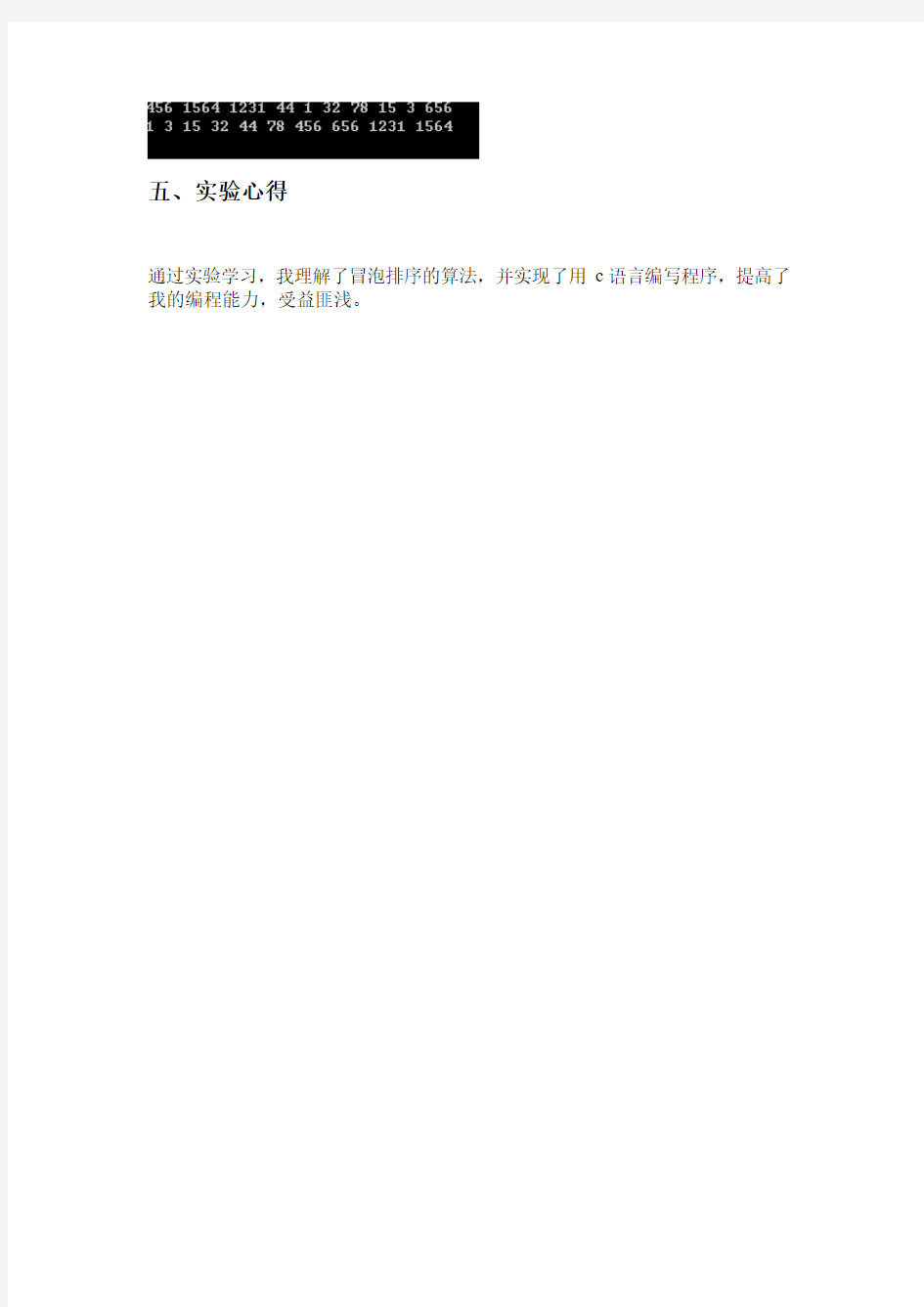
a[10]={456,1564,1231,44,1,32,78,15,3,6 56},i;
for(i=0;i<10;++i)
printf("%d ",a[i]);
printf("\n");
bub(a,10);
for(i=0;i<10;++i)
printf("%d ",a[i]);
printf("\n");
getchar();
return 0;
}
void bub(int a[],int n)
{
int i,j,k,m,temp;
k=0;
m=n-1;
while(k { j=m; m=0; for(i=k;i if(a[i]>a[i+1]) { temp=a[i]; a[i]=a[i+1]; a[i+1]=temp; m=i; } j=k; k=0; for(i=m;i>j;--i) if(a[i] { temp=a[i]; a[i]=a[i-1]; a[i-1]=temp; k=i; } } } 实验结果 五、实验心得 通过实验学习,我理解了冒泡排序的算法,并实现了用c语言编写程序,提高了我的编程能力,受益匪浅。 拓扑排序 [基本要求] 用邻接表建立一个有向图的存储结构。利用拓扑排序算法输出该图的拓扑排序序列。 [编程思路] 首先图的创建,采用邻接表建立,逆向插入到单链表中,特别注意有向是不需要对称插入结点,且要把输入的字符在顶点数组中定位(LocateVex(Graph G,char *name),以便后来的遍历操作,几乎和图的创建一样,图的顶点定义时加入int indegree,关键在于indegree 的计算,而最好的就是在创建的时候就算出入度,(没有采用书上的indegree【】数组的方法,那样会增加一个indegree算法,而是在创建的时候假如一句计数的代码(G.vertices[j].indegree)++;)最后调用拓扑排序的算法,得出拓扑序列。 [程序代码] 头文件: #define MAX_VERTEX_NUM 30 #define STACKSIZE 30 #define STACKINCREMENT 10 #define OK 1 #define ERROR 0 #define INFEASIBLE -1 #define OVERFLOW -2 #define TRUE 1 #define FALSE 0 typedef int Status; typedef int InfoType; typedef int Status; typedef int SElemType; /* 定义弧的结构*/ typedef struct ArcNode{ int adjvex; /*该边所指向的顶点的位置*/ struct ArcNode *nextarc; /*指向下一条边的指针*/ InfoType info; /*该弧相关信息的指针*/ 微机原理实验报告 班级:XXXXX 姓名:XXXX 学号:20XXXX XXXXX大学 信息科学与技术学院 信息工程系 实验一汇编语言程序设计-(具体题目) 一、实验目的(根据实际情况修改): 1、熟悉MASM编译环境,了解程序的汇编方法; 2、熟悉常用汇编指令,学习汇编程序设计方法; 3、学习汇编语言的调试过程,通过调试过程认识CPU执行程序的方式; 4、了解冒泡法原理,学习多重循环的编程方法。 二、实验内容: 编写程序,用冒泡法实现将数据段内9,8,7,6,5,4,3,2,1按照由小到大的顺序重新排列。 三、程序流程图和程序代码 1、流程图 2、代码与注释(代码不能和指导书完全一样,写出注释,写出寄存器尤其是DS的值) data segment buf1 db 8,7,6,5,4,3,2,1 data ends code segment assume cs:code,ds:data start: mov ax,data //传送数据段data mov ds,ax mov dx,7 //dx放外循环7次 L3: mov cx,dx //cx放内循环7次 lea si,buf1 //将db里的数据传送到si L2: mov al,[si] cmp al,[si+1] //比较[si]与[si+1] jb L1 //[si]<[si+1],跳转到L1 xchg al,[si+1] //[si]>[si+1],两两交换 mov [si],al L1: inc si //si减1 loop L2 //循环L2 dec dx //外循环减1,没减到0则跳转到L3 jnz L3 //入内循环,计数初值 mov ah,4ch int 21h code ends end start 四、调试过程及遇到的问题 1、程序执行截图 《数据结构》实验报告排序实验题目: 输入十个数,从插入排序,快速排序,选择排序三类算法中各选一种编程实现。 实验所使用的数据结构内容及编程思路: 1. 插入排序:直接插入排序的基本操作是,将一个记录到已排好序的有序表中,从而得到一个新的,记录增一得有序表。 一般情况下,第i 趟直接插入排序的操作为:在含有i-1 个记录的有序子序列r[1..i-1 ]中插入一个记录r[i ]后,变成含有i 个记录的有序子序列r[1..i ];并且,和顺序查找类似,为了在查找插入位置的过程中避免数组下标出界,在r [0]处设置哨兵。在自i-1 起往前搜索的过程中,可以同时后移记录。整个排序过程为进行n-1 趟插入,即:先将序列中的第一个记录看成是一个有序的子序列,然后从第2 个记录起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。 2. 快速排序:基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 假设待排序的序列为{L.r[s] ,L.r[s+1],…L.r[t]}, 首先任意选取一个记录 (通常可选第一个记录L.r[s])作为枢轴(或支点)(PiVOt ),然后按下述原则重新排列其余记录:将所有关键字较它小的记录都安置在它的位置之前,将所有关键字较大的记录都安置在它的位置之后。由此可以该“枢轴”记录最后所罗的位置i 作为界线,将序列{L.r[s] ,… ,L.r[t]} 分割成两个子序列{L.r[i+1],L.[i+2], …,L.r[t]}。这个过程称为一趟快速排序,或一次划分。 一趟快速排序的具体做法是:附设两个指针lOw 和high ,他们的初值分别为lOw 和high ,设枢轴记录的关键字为PiVOtkey ,则首先从high 所指位置起向前搜索找到第一个关键字小于PiVOtkey 的记录和枢轴记录互相交换,然后从lOw 所指位置起向后搜索,找到第一个关键字大于PiVOtkey 的记录和枢轴记录互相 交换,重复这两不直至low=high 为止。 具体实现上述算法是,每交换一对记录需进行3 次记录移动(赋值)的操作。而实际上, 算法设计与分析基础 实验报告 应用数学学院 二零一六年六月 实验一插入排序算法 一、实验性质设计 二、实验学时14学时 三、实验目的 1、掌握插入排序的方法和原理。 2、掌握java语言实现该算法的一般流程。 四、实验内容 1、数组的输入。 2、输入、输出的异常处理。 3、插入排序的算法流程。 4、运行结果的输出。 五、实验报告 Ⅰ、算法原理 从左到右扫描有序的子数组,直到遇到一个大于(或小于)等于A[n-1]的元素,然后就把A[n-1]插在该元素的前面(或后面)。 插入排序基于递归思想。 Ⅱ、书中源代码 算法InsertionSort(A[0..n-1]) //用插入排序对给定数组A[0..n-1]排序 //输入:n个可排序元素构成的一个数组A[0..n-1] //输出:非降序排列的数组A[0..n-1] for i ←1 to n-1 do v ← A[i] j ← i-1 while j ≥0and A[j] > v do A[j+1] ← A[j] j ← j-1 A[j+1] ← v Ⅲ、Java算法代码: import java.util.*; public class Charu { public static void main(String[] args) { int n = 5; int a[] = new int[n]; int s = a.length; int i = 0, j = 0, v = 0; System.out.println("请输入若干个数字:"); Scanner sc = new Scanner(System.in); try { while (i < s) { a[i] = sc.nextInt(); i++; } for (i = 1; i 算法与数据结构 实验报告 系(院):计算机科学学院 专业班级:软工11102 姓名:潘香杰 学号: 201104449 班级序号: 18 指导教师:詹泽梅老师 实验时间:2013.6.17 - 2013.6.29 实验地点:4号楼5楼机房 目录 1、课程设计目的...................................... 2、设计任务.......................................... 3、设计方案.......................................... 4、实现过程.......................................... 5、测试.............................................. 6、使用说明.......................................... 7、难点与收获........................................ 8、实现代码.......................................... 9、可改进的地方..................................... 算法与数据结构课程设计是在学完数据结构课程之后的实践教学环节。本实践教学是培养学生数据抽象能力,进行复杂程序设计的训练过程。要求学生能对所涉及问题选择合适的数据结构、存储结构及算法,并编写出结构清楚且正确易读的程序,提高程序设计基本技能和技巧。 一.设计目的 1.提高数据抽象能力。根据实际问题,能利用数据结构理论课中所学到的知识选择合适的逻辑结构以及存储结构,并设计出有效解决问题的算法。 2.提高程序设计和调试能力。学生通过上机实习,验证自己设计的算法的正确性。学会有效利用基本调试方法,迅速找出程序代码中的错误并且修改。 3.初步了解开发过程中问题分析、整体设计、程序编码、测试等基本方法和技能。二.设计任务 设计一个基于DOS菜单的应用程序。要利用多级菜单实现各种功能。内容如下: ①创建无向图的邻接表 ②无向图的深度优先遍历 ③无向创建无向图的邻接矩阵 ④无向图的基本操作及应用 ⑤图的广度优先遍历 1.有向图的基本操作及应用 ①创建有向图的邻接矩阵 ②创建有向图的邻接表 ③拓扑排序 2.无向网的基本操作及应用 ①创建无向网的邻接矩阵 ②创建无向网的邻接表 ③求最小生成树 3.有向网的基本操作及应用 ①创建有向网的邻接矩阵 ②创建有向网的邻接表 ③关键路径 ④单源最短路径 三.设计方案 第一步:根据设计任务,设计DOS菜单,菜单运行成果如图所示: 一、实验目的 (1)学习汇编语言循环结构语句的特点,重点掌握冒泡排序的方法。 (2)理解并掌握各种指令的功能,编写完整的汇编源程序。 (3)进一步熟悉DEBUG的调试命令,运用DEBUG进行调试汇编语言程序。 二、实验内容及要求 (1)实验内容:从键盘输入五个有符号数,用冒泡排序法将其按从小到大的顺序排序。(2)实验要求: ①编制程序,对这组数进行排序并输出原数据及排序后的数据; ②利用DEBUG调试工具,用D0命令,查看排序前后内存数据的变化; ③去掉最大值和最小值,求出其余值的平均值,输出最大值、最小值和平均值; ④用压栈PUSH和出栈POP指令,将平均值按位逐个输出; ⑤将平均值转化为二进制串,并将这组二进制串输出; ⑥所有数据输出前要用字符串的输出指令进行输出提示,所有数据结果能清晰显示。 三、程序流程图Array (1)主程序:MAIN (2)冒泡排序子程序: SORT 四、程序清单 NAME BUBBLE_SORT DATA SEGMENT ARRAY DW 5 DUP(?) ;输入数据的存储单元 COUNT DW 5 TWO DW 2 FLAG1 DW 0 ;判断符号标志 FLAG2 DB 0 ;判断首位是否为零的标志 FAULT DW -1 ;判断出错标志 CR DB 0DH,0AH,'$' STR1 DB 'Please input five numbers seperated with space and finished with Enter:','$' STR2 DB 'The original numbers:','$' STR3 DB 'The sorted numbers:','$' STR4 DB 'The Min:','$' STR5 DB 'The Max:','$' STR6 DB 'The Average:','$' STR7 DB 'The binary system of the average :','$' STR8 DB 'Input error!Please input again!''$' DATA ENDS CODE SEGMENT MAIN PROC FAR ASSUME CS:CODE,DS:DATA,ES:DATA START: PUSH DS AND AX,0 PUSH AX MOV AX,DATA MOV DS,AX LEA DX,STR1 MOV AH,09H ;9号DOS功能调用,提示输入数据 INT 21H CALL CRLF ;回车换行 REIN: CALL INPUT ;调用INPUT子程序,输入原始数据CMP AX,FAULT ;判断是否出错, JE REIN ;出错则重新输入 LEA DX,STR2 MOV AH,09H ;9号DOS功能调用,提示输出原始数据 INT 21H CALL OUTPUT ;调用OUTPUT子程序,输出原始数据 CALL SORT ;调用SORT子程序,进行冒泡排序 LEA DX,STR3 MOV AH,09H ;9号DOS功能调用,提示输出排序后的数据 INT 21H CALL OUTPUT ;调用OUTPUT子程序,输出排序后的数据 电子科技大学实验报告 课程名称:数据结构与算法 学生姓名: 学号: 点名序号: 指导教师: 实验地点:基础实验大楼 实验时间: 5月20日 2014-2015-2学期 信息与软件工程学院 实验报告(二) 学生姓名学号:指导教师: 实验地点:基础实验大楼实验时间:5月20日 一、实验室名称:软件实验室 二、实验项目名称:数据结构与算法—排序与查找 三、实验学时:4 四、实验原理: 快速排序的基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一不部分的所有数据都要小,然后再按次方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。 假设要排序的数组是A[1]……A[N],首先任意选取一个数据(通常选用第一个数据)作为关键数据,然后将所有比它的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一躺快速排序。一躺快速排序的算法是: 1)设置两个变量I、J,排序开始的时候I:=1,J:=N 2)以第一个数组元素作为关键数据,赋值给X,即X:=A[1]; 3)从J开始向前搜索,即(J:=J-1),找到第一个小于X的值,两者交换; 4)从I开始向后搜索,即(I:=I+1),找到第一个大于X的值,两者交换; 5)重复第3、4步,直到I=J。 二分法查找(折半查找)的基本思想: (1)确定该区间的中点位置:mid=(low+high)/2 min代表区间中间的结点的位置,low代表区间最左结点位置,high代表区间最右结点位置(2)将待查a值与结点mid的关键字(下面用R[mid].key)比较,若相等,则查找成功,否则确定新的查找区间: A)如果R[mid].key>a,则由表的有序性可知,R[mid].key右侧的值都大于a,所以等于a的关键字如果存在,必然在R[mid].key左边的表中,这时high=mid-1; B)如果R[mid].key 数据结构与算法设计 实验报告 (2016 — 2017 学年第1 学期) 实验名称: 年级: 专业: 班级: 学号: 姓名: 指导教师: 成都信息工程大学通信工程学院 一、实验目的 验证各种简单的排序算法。在调试中体会排序过程。 二、实验要求 (1)从键盘读入一组无序数据,按输入顺序先创建一个线性表。 (2)用带菜单的主函数任意选择一种排序算法将该表进行递增排序,并显示出每一趟排序过程。 三、实验步骤 1、创建工程(附带截图说明) 2、根据算法编写程序(参见第六部分源代码) 3、编译 4、调试 四、实验结果图 图1-直接输入排序 图2-冒泡排序 图3-直接选择排序 五、心得体会 与哈希表的操作实验相比,本次实验遇到的问题较大。由于此次实验中设计了三种排序方法导致我在设计算法时混淆了一些概念,设计思路特别混乱。虽然在理清思路后成功解决了直接输入和直接选择两种算法,但冒泡 排序的算法仍未设计成功。虽然在老师和同学的帮助下完成了冒泡排序的算法,但还需要多练习这方面的习题,平时也应多思考这方面的问题。而且,在直接输入和直接选择的算法设计上也有较为复杂的地方,对照书本做了精简纠正。 本次实验让我发现自己在算法设计上存在一些思虑不周的地方,思考问题过于片面,逻辑思维能力太过单薄,还需要继续练习。 六、源代码 要求:粘贴个人代码,以便检查。 #include 《离散数学》 课程设计 学院计算机学院 学生姓名 学号 指导教师 评阅意见 提交日期 2011 年 11 月 25 日 引言 《离散数学》是现代数学的一个重要分支,也是计算机科学与技术,电子信息技术,生物技术等的核心基础课程。它是研究离散量(如整数、有理数、有限字母表等)的数学结构、性质及关系的学问。它一方面充分地描述了计算机科学离散性的特点,为学生进一步学习算法与数据结构、程序设计语言、操作系统、编译原理、电路设计、软件工程与方法学、数据库与信息检索系统、人工智能、网络、计算机图形学等专业课打好数学基础;另一方面,通过学习离散数学课程,学生在获得离散问题建模、离散数学理论、计算机求解方法和技术知识的同时,还可以培养和提高抽象思维能力和严密的逻辑推理能力,为今后爱念族皮及用计算机处理大量的日常事务和科研项目、从事计算机科学和应用打下坚实基础。特别是对于那些从事计算机科学与理论研究的高层次计算机人员来说,离散数学更是必不可少的基础理论工具。 实验一、编程判断一个二元关系的性质(是否具有自反性、反自反性、对称性、反对称性和传递性) 一、前言引语:二元关系是离散数学中重要的内容。因为事物之间总是可以根据需要确定相应的关系。从数学的角度来看,这类联系就是某个集合中元素之 间存在的关系。 二、数学原理:自反、对称、传递关系 设A和B都是已知的集合,R是A到B的一个确定的二元关系,那么集合R 就是A×B的一个合于{()∈A×}的子集合 设R是集合A上的二元关系: 自反关系:对任意的x∈A,都满足<>∈R,则称R是自反的,或称R具有自反性,即R在A上是自反的?(?x)((x∈A)→(<>∈R))=1 对称关系:对任意的∈A,如果<>∈R,那么<>∈R,则称关系R是对称的,或称R具有对称性,即R在A上是对称的? (?x)(?y)((x∈A)∧(y∈A)∧(<>∈R)→(<>∈R))=1 传递关系:对任意的∈A,如果<>∈R且<>∈R,那么<>∈R,则称关系R是传递的,或称R具有传递性,即R在A上是传递的? (?x)(?y)(?z)[(x∈A)∧(y∈A)∧(z ∈A)∧((<>∈R)∧(<>∈R)→(<>∈R))]=1 三、实验原理:通过二元关系与关系矩阵的联系,可以引入N维数组,以数组的运算来实现二元关系的判断。 图示: 实验七查找、排序的应用 一、实验目的 1、本实验可以使学生更进一步巩固各种查找和排序的基本知识。 2、学会比较各种排序与查找算法的优劣。 3、学会针对所给问题选用最适合的算法。 4、掌握利用常用的排序与选择算法的思想来解决一般问题的方法和技巧。 二、实验内容 [问题描述] 对学生的基本信息进行管理。 [基本要求] 设计一个学生信息管理系统,学生对象至少要包含:学号、姓名、性别、成绩1、成绩2、总成绩等信息。要求实现以下功能:1.总成绩要求自动计算; 2.查询:分别给定学生学号、姓名、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现); 3.排序:分别按学生的学号、成绩1、成绩2、总成绩进行排序(要求至少用两种排序算法实现)。 [测试数据] 由学生依据软件工程的测试技术自己确定。 三、实验前的准备工作 1、掌握哈希表的定义,哈希函数的构造方法。 2、掌握一些常用的查找方法。 1、掌握几种常用的排序方法。 2、掌握直接排序方法。 四、实验报告要求 1、实验报告要按照实验报告格式规范书写。 2、实验上要写出多批测试数据的运行结果。 3、结合运行结果,对程序进行分析。 五、算法设计 a、折半查找 设表长为n,low、high和mid分别指向待查元素所在区间的下界、上界和中点,key为给定值。初始时,令low=1,high=n,mid=(low+high)/2,让key与mid指向的记录比较, 若key==r[mid].key,查找成功 若key 【一】需求分析 课程题目是排序算法的实现,课程设计一共要设计八种排序算法。这八种算法共包括:堆排序,归并排序,希尔排序,冒泡排序,快速排序,基数排序,折半插入排序,直接插入排序。 为了运行时的方便,将八种排序方法进行编号,其中1为堆排序,2为归并排序,3为希尔排序,4为冒泡排序,5为快速排序,6为基数排序,7为折半插入排序8为直接插入排序。 【二】概要设计 1.堆排序 ⑴算法思想:堆排序只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。将序列所存储的元素A[N]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的元素均不大于(或不小于)其左右孩子(若存在)结点的元素。算法的平均时间复杂度为O(N log N)。 ⑵程序实现及核心代码的注释: for(j=2*i+1; j<=m; j=j*2+1) { if(j temp=su[i]; su[i]=su[0]; su[0]=temp; head(0,i-1); } cout<<"排序之后的数组为:"< 一、实验目的 (1)学习汇编语言循环结构语句的特点,重点掌握冒泡排序的方法。 (2)理解并掌握各种指令的功能,编写完整的汇编源程序。 (3)进一步熟悉DEBUG的调试命令,运用DEBUG进行调试汇编语言程序。 二、实验内容及要求 (1)实验内容:从键盘输入五个有符号数,用冒泡排序法将其按从小到大的顺序排序。 (2)实验要求: ①编制程序,对这组数进行排序并输出原数据及排序后的数据; ②利用DEBUG调试工具,用D0命令,查瞧排序前后内存数据的变化; ③去掉最大值与最小值,求出其余值的平均值,输出最大值、最小值与平均值; ④用压栈PUSH与出栈POP指令,将平均值按位逐个输出; ⑤将平均值转化为二进制串,并将这组二进制串输出; ⑥所有数据输出前要用字符串的输出指令进行输出提示,所有数据结果能清晰显示。 三、程序流程图Array (1)主程序:MAIN (2) 就是 NAME BUBBLE_SORT DATA SEGMENT ARRAY DW 5 DUP(?) ;输入数据的存储单元 COUNT DW 5 TWO DW 2 FLAG1 DW 0 ;判断符号标志 FLAG2 DB 0 ;判断首位就是否为零的标志FAULT DW -1 ;判断出错标志 CR DB 0DH,0AH,'$' STR1 DB 'Please input five numbers seperated with space and finished with Enter:','$' STR2 DB 'The original numbers:','$' STR3 DB 'The sorted numbers:','$' STR4 DB 'The Min:','$' STR5 DB 'The Max:','$' STR6 DB 'The Average:','$' STR7 DB 'The binary system of the average :','$' STR8 DB 'Input error!Please input again!''$' DATA ENDS CODE SEGMENT MAIN PROC FAR ASSUME CS:CODE,DS:DATA,ES:DATA START: PUSH DS AND AX,0 PUSH AX MOV AX,DATA MOV DS,AX LEA DX,STR1 MOV AH,09H ;9号DOS功能调用,提示输入数据 INT 21H CALL CRLF ;回车换行 REIN: CALL INPUT ;调用INPUT子程序,输入原始数据CMP AX,FAULT ;判断就是否出错, JE REIN ;出错则重新输入 《数据结构》实验报告一 学院:班级: 学号:姓名: 日期:程序名 一、上机实验的问题和要求: 顺序表的查找、插入与删除。设计算法,实现线性结构上的顺序表的产生以及元素的查找、插入与删除。具体实现要求: 1.从键盘输入10个整数,产生顺序表,并输入结点值。 2.从键盘输入1个整数,在顺序表中查找该结点的位置。若找到,输出结点的位置;若找 不到,则显示“找不到”。 3.从键盘输入2个整数,一个表示欲插入的位置i,另一个表示欲插入的数值x,将x插 入在对应位置上,输出顺序表所有结点值,观察输出结果。 4.从键盘输入1个整数,表示欲删除结点的位置,输出顺序表所有结点值,观察输出结果。 二、源程序及注释: #include 算法分析与设计实验报告 学院:信息科学与工程学院 专业班级: 指导老师: 学号: 姓名: 目录 实验一:递归与分治 (3) 1.实验目的 (3) 2.实验预习内容 (3) 3.实验内容和步骤 (3) 4.实验总结及思考 (5) 实验二:回溯算法 (6) 1.实验目的: (6) 2.实验预习内容: (6) 3. 实验内容和步骤 (6) 4. 实验总结及思考 (9) 实验三:贪心算法和随机算法 (10) 1. 实验目的 (10) 2.实验预习内容 (10) 3.实验内容和步骤 (10) 4. 实验总结及思考 (13) 实验一:递归与分治 1.实验目的 理解递归算法的思想和递归程序的执行过程,并能熟练编写快速排序算法程序。 掌握分治算法的思想,对给定的问题能设计出分治算法予以解决。 2.实验预习内容 递归:递归算法是把问题转化为规模缩小了的同类问题的子问题。然后递归调用函数(或过程)来表示问题的解。 一个过程(或函数)直接或间接调用自己本身,这种过程(或函数)叫递归过程(或函数). 分治:分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。 3.实验内容和步骤 快速排序的基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。 源代码: #include 实验六图的应用及其实现 一、实验目的 1.进一步功固图常用的存储结构。 2.熟练掌握在图的邻接表实现图的基本操作。 3.理解掌握AOV网、AOE网在邻接表上的实现以及解决简单的应用问题。 二、实验内容 [题目一]:从键盘上输入AOV网的顶点和有向边的信息,建立其邻接表存储结构,然后对该图拓扑排序,并输出拓扑序列. 试设计程序实现上述AOV网的类型定义和基本操作,完成上述功能。 测试数据:教材图7.28 [题目二]:从键盘上输入AOE网的顶点和有向边的信息,建立其邻接表存储结构,输出其关键路径和关键路径长度。试设计程序实现上述AOE网类型定义和基本操作,完成上述功能。 测试数据:教材图7.29 三、实验步骤 ㈠、数据结构与核心算法的设计描述 基本数据结构: #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0 #define INFEASIBLE -1 typedef int Status; /* Status 是函数的类型,其值是函数结果状态代码,如OK 等*/ #define INFINITY INT_MAX //定义无穷大∞ #define MAX_VERTEX_NUM 20 typedef int V ertexType; typedef int InfoType; typedef struct ArcNode // 表结点定义 { InfoType info; int adjvex; //邻接点域,存放与V i邻接的点在表头数组中的位置ArcNode *nextarc; //链域,指示依附于vi的下一条边或弧的结点, }ArcNode; typedef struct VNode //表头结点 { int data; //存放顶点信息 struct ArcNode *firstarc; //指示第一个邻接点 }VNode,AdjList[MAX_VERTEX_NUM]; typedef struct { //图的结构定义 实验报告 实验名称冒泡排序和快速排序 班级 学号 姓名 成绩 #include 实验四:查找与排序 【实验目的】 1.掌握顺序查找算法的实现。 2.掌握折半查找算法的实现。 【实验内容】 1.编写顺序查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 2.编写折半查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 【实验步骤】 1.打开VC++。 2.建立工程:点File->New,选Project标签,在列表中选Win32 Console Application,再在右边的框里为工程起好名字,选好路径,点OK->finish。 至此工程建立完毕。 3.创建源文件或头文件:点File->New,选File标签,在列表里选C++ Source File。给文件起好名字,选好路径,点OK。至此一个源文件就被添加到了你刚创建的工程之中。 4.写好代码 5.编译->链接->调试 #include "stdio.h" #include "malloc.h" #define OVERFLOW -1 #define OK 1 #define MAXNUM 100 typedef int Elemtype; typedef int Status; typedef struct { Elemtype *elem; int length; }SSTable; Status InitList(SSTable &ST ) { int i,n; ST.elem = (Elemtype*) malloc (MAXNUM*sizeof (Elemtype)); if (!ST.elem) return(OVERFLOW); printf("输入元素个数和各元素的值:"); scanf("%d\n",&n); for(i=1;i<=n;i++) { scanf("%d",&ST.elem[i]); } ST.length = n; return OK; } int Seq_Search(SSTable ST,Elemtype key) { int i; ST.elem[0]=key; for(i=ST.length;ST.elem[i]!=key;--i); return i; } int BinarySearch(SSTable ST,Elemtype key) { int low,high,mid; low=1; high=ST.length; WORD格式 一、实验目的 (1)学习汇编语言循环结构语句的特点,重点掌握冒泡排序的方法。 (2)理解并掌握各种指令的功能,编写完整的汇编源程序。 (3)进一步熟悉DEBUG的调试命令,运用DEBUG进行调试汇编语言程序。 二、实验内容及要求 (1)实验内容:从键盘输入五个有符号数,用冒泡排序法将其按从小到大的顺序排序。(2)实验要求: ①编制程序,对这组数进行排序并输出原数据及排序后的数据; ②利用DEBUG调试工具,用D0命令,查看排序前后内存数据的变化; ③去掉最大值和最小值,求出其余值的平均值,输出最大值、最小值和平均值; ④用压栈PUSH和出栈POP指令,将平均值按位逐个输出; ⑤将平均值转化为二进制串,并将这组二进制串输出; ⑥所有数据输出前要用字符串的输出指令进行输出提示,所有数据结果能清晰显示。 三、程序流程图 开 始(1)主程序:MAIN 初始化 键盘输入数据 调用INPUT子程序 显示输入错误 否 输入是否正确 是 显示原始数据 调用OUTPUT子程序 WORD格式 显示冒泡排序后的数据 调用SORT子程序 调用OUTPUT子程序 显示最小值Min 显示One子程序 显示最大值Max 调用One子程序 显示其余数平均值Average 调用One子程序 显示平均值二进制串Binary 调用One子程序 结束 (2)冒泡排序子程序:SORT COUNT1----外循环次数 进入COUNT2----内循环次数 i----数组下标 初始化 COUNT1=N-1 COUNT2=COUNT1 SI=0 否 Ai≥i A+1 是 Ai与A i+1两数交换 SI=SI+2 COUNT2=COUNT2-1 否 COUNT2=0? 是 COUNT1=COUNT1-1 否 COUNT2=0? 是 返回 实验四——查找 一、实验目的 1.掌握顺序表的查找方法,尤其是折半查找方法; 2.掌握二叉排序树的查找算法。 二、实验内容 1.建立一个顺序表,用顺序查找的方法对其实施查找; 2.建立一个有序表,用折半查找的方法对其实施查找; 3.建立一个二叉排序树,根据给定值对其实施查找; 4.对同一组数据,试用三种方法查找某一相同数据,并尝试进行性能分析。 三、实验预习内容 实验一包括的函数有:typedef struct ,创建函数void create(seqlist & L),输出函数void print(seqlist L),顺序查找int find(seqlist L,int number),折半查找int halffind(seqlist L,int number) 主函数main(). 实验二包括的函数有:结构体typedef struct,插入函数void insert(bnode * & T,bnode * S),void insert1(bnode * & T),创建函数void create(bnode * & T),查找函数bnode * search(bnode * T,int number),主函数main(). 四、上机实验 实验一: 1.实验源程序。 #include<> #define N 80 typedef struct { int number; umber; for(i=1;[i].number!=0;) { cin>>[i].name>>[i].sex>>[i].age; ++; cout<大数据结构拓扑排序实验报告材料
微机原理-实验一-汇编语言-冒泡排序
《数据结构》实验报告——排序.docx
插入排序算法实验报告
实验报告
微机原理实验报告-冒泡排序
实验报告-排序与查找
排序操作实验报告
离散数学实验报告四个实验
(完整word版)查找、排序的应用 实验报告
各种排序实验报告
微机原理实验报告冒泡排序
顺序表的查找、插入与删除实验报告
算法实验报告
图的应用的实验报告
北航计算机软件技术基础实验报告计软实验报告3——冒泡排序和快速排序
查找与排序实验报告
微机原理实验报告-冒泡排序
《数据结构》实验报告查找