TP4056(TDS)-1

数据手册 DATASHEET
TP4056
(1A 线性锂离子电池充电器)
í?μ?°?μ?ì?£¨????£?óD?T1???TD semiconductor (Hongkong) Co., Ltd.
TP4056
TD semiconductor
https://www.360docs.net/doc/dc2767344.html,
应用
·移动电话、PDA ·MP3、MP4播放器 ·数码相机 ·电子词典 ·GPS
·便携式设备、各种充电器
描述 TP4056是一款完整的单节锂离子电池采用恒定电流/恒定电压线性充电器。其底部带有散热片的SOP8/MSOP8封装与较少的外部元件数目使得TP4056成为便携式应用的理想选择。TP4056可以适合USB 电源和适配器电源工作。 由于采用了内部PMOSFET 架构,加上防倒充电路,所以不需要外部隔离二极管。热反馈可对充电电流进行自动调节,以便在大功率操作或高环境温度条件下对芯片温度加以限制。充电电压固定于4.2V ,而充电电流可通过一个电阻器进行外部设置。当充电电流在达到最终浮充电压之后降至设定值1/10时,TP4056将自动终止充电循环。 当输入电压(交流适配器或USB 电源)被拿掉时,TP4056自动进入一个低电流状态,将电池漏电流降至2uA 以下。TP4056在有电源时也可置于停机模式,以而将供电电流降至55uA 。TP4056的其他特点包括电池温度检测、欠压闭锁、自动再充电和两个用于指示充电、结束的LED 状态引脚。 特点 ·高达1000mA 的可编程充电电流 ·无需MOSFET 、检测电阻器或隔离二极管 ·用于单节锂离子电池、采用SOP 封装的完整线性充电器 ·恒定电流/恒定电压操作,并具有可在无过热
危险的情况下实现充电速率最大化的热调节
功能
·
精度达到±1%的4.2V 预设充电电压 ·用于电池电量检测的充电电流监控器输出
·
自动再充电 ·充电状态双输出、无电池和故障状态显示
·
C/10充电终止 ·
待机模式下的供电电流为55uA ·
2.9V 涓流充电器件版本 ·软启动限制了浪涌电流 ·电池温度监测功能 ·采用8引脚SOP-PP/MSP-PP 封装。
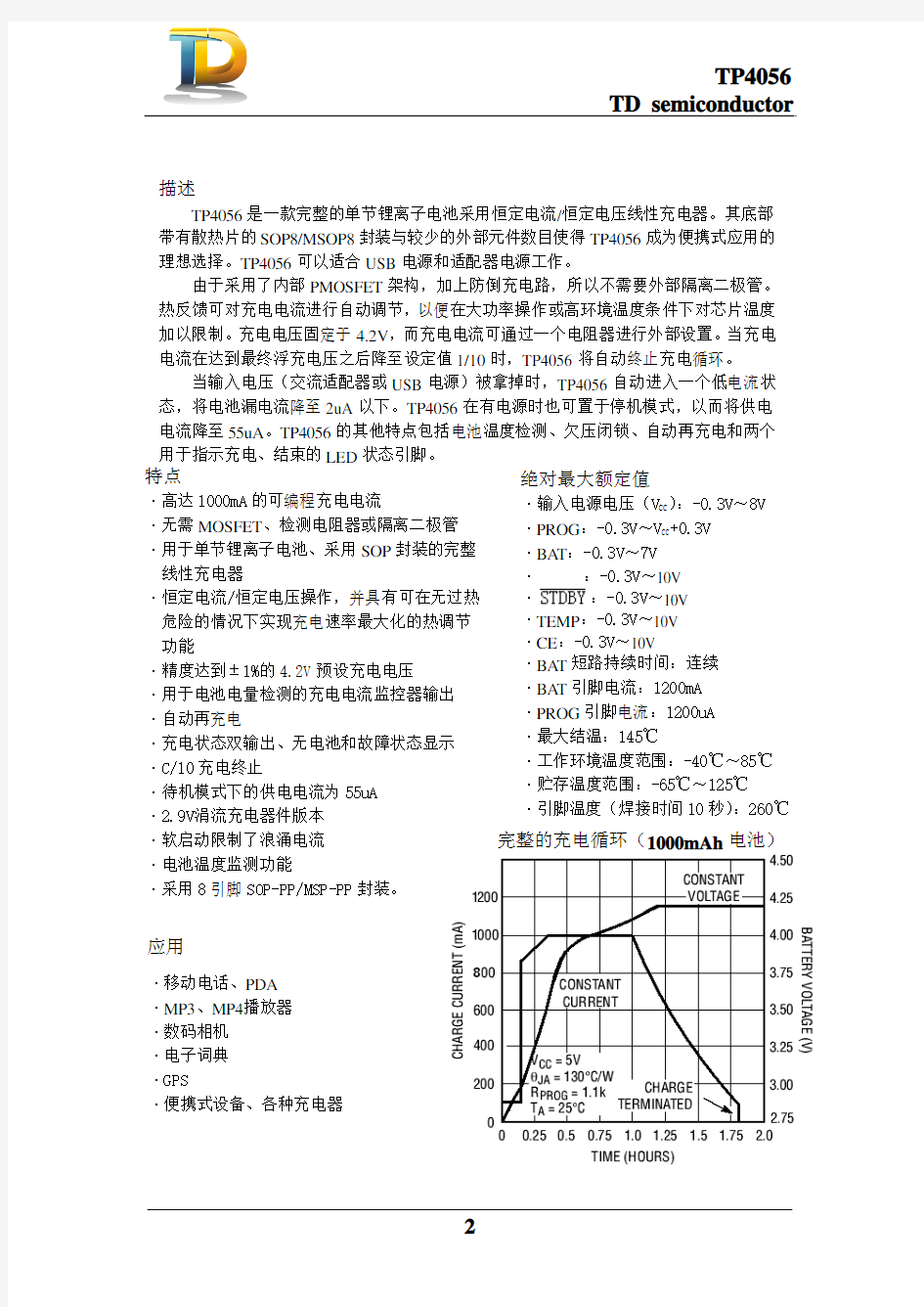
完整的充电循环(1000mAh 电池)
绝对最大额定值 ·输入电源电压(V CC ):-0.3V ~8V ·PROG :-0.3V ~V CC +0.3V ·BA T :-0.3V ~7V ·:-0.3V ~10V ·:-0.3V ~10V ·TEMP :-0.3V ~10V ·CE :-0.3V ~10V ·BA T 短路持续时间:连续 ·BA T 引脚电流:1200mA ·PROG 引脚电流:1200uA ·最大结温:145℃ ·工作环境温度范围:-40℃~85℃ ·贮存温度范围:-65℃~125℃ ·引脚温度(焊接时间10秒):260℃ TP4056
TD semiconductor
典型应用
封装/订购信息
订单型号
TP4056-42-SOP8-PP
器件标记
TP4056
实物图片8引脚SOP封装(底部带有散热片)
订单型号
TP4056-42-MSOP8-PP
器件标记
TP4056
实物图片
8引脚MSOP封装(底部带有散热片)
电特性
凡表注●表示该指标适合整个工作温度范围,否则仅指T A=25NO V CC=5V,除非特别注明。
典型性能特征
恒定电流模式下PROG引脚PROG引脚电压与温度的充电电流与PROG引脚电电压与电源电压的关系曲线关系曲线压的关系曲线
稳定输出(浮充)电压与充稳定输出(浮充)电压与温稳定输出(浮充)电压与电电电流的关系曲线度的关系曲线压的关系曲线
涓流充电门限与温度的关系充电电流与电池电压的关系充电电流与电源电压的关系曲线曲线曲线
充电电流与环境温度的关再充电电压门限与温度的关功率FET“导通”电阻与温系曲线系曲线度的关系曲线
引脚功能
TEMP (引脚1):电池温度检测输入端。将TEMP 管脚接到电池的NTC 传感器的输出端。如果TEMP 管脚的电压小于输入电压的45%或者大于输入电压的80%,意味着电池温度过低或过高,则充电被暂停。
如果TEMP 直接接GND ,电池温度检测功能取消,其他充电功能正常。 PROG (引脚2):恒流充电电流设置和充电电流监测端。从PROG 管脚连接一个外部电阻到地端可以对充电电流进行编程。在预充电阶段,此管脚的电压被调制在0.1V ;在恒流充电阶段,此管脚的电压被固定在1V 。在充电状态的所有模式,测量该管脚的电压都可以根据下面的公式来估算充电电流:
1200PROG
BAT PROG
V I R =
× GND (引脚3):电源地。
Vcc (引脚4):输入电压正输入端。此管脚的电压为内部电路的工作电源。当Vcc 与BA T 管脚的电压差小于30mV 时,TP4056
将进入低功耗的停机模式,此时BA T 管脚 的电流小于2uA 。 BAT (引脚5):电池连接端。将电池的正端连接到此管脚。在芯片被禁止工作或者睡眠模式,BA T 管脚的漏电流小于2uA 。BAT 管脚向电池提供充电电流和4.2V 的限制电压。
(引脚6):电池充电完成指示端。
当电池充电完成时
被内部开关拉到低电平,表示充电完成。除此之外,管脚将处于高阻态。
(引脚7)漏极开路输出的充电状态指示端。当充电器向电池充电时,管脚被内部开关拉到低电平,表示充电正在进
行;否则
管脚处于高阻态。 CE (引脚8)芯片始能输入端。高输入电平将使TP4056处于正常工作状态;低输入电平使TP4056处于被禁止充电状态。CE 管脚可以被TTL 电平或者CMOS 电平驱动。
方框图
工作原理
TP4056是专门为一节锂离子或锂聚合物电池而设计的线性充电器电路,利用芯片内部的功率晶体管对电池进行恒流和恒压充电。充电电流可以用外部电阻编程设定,最大持续充电电流可达1A ,不需要另加阻流二极管和电流检测电阻。TP4056包含两个漏极开路输出的状态指示
输出端,充电状态指示端
和电池故障状态指示输出端
。芯片内部的功率管理电路在芯片的结温超过145℃时自动降低充电电流,这个功能可以使用户最大限度的利用芯片的功率处理能力,不用担心芯片过热而损坏芯片或者外部元器件。这样,用户在设计充电电流时,可以不用考虑最坏情况,而只是根据典型情况进行设计就可以了,因为在最坏情况下,TP4056会自动减小充电电流。
当输入电压大于电源低电压检测阈值和芯片使能输入端接高电平时,TP4056开始对电池充电,管脚输出低电平,表示充电正在进
行。如果电池电压低于3V ,充电器用小电流对
电池进行预充电。当电池电压超过3V 时,充电器采用恒流模式对电池充电,充电电流由PROG 管脚和GND 之间的电阻R PROG 确定。当电池电压接近4.2V 电压时,充电电流逐渐减小,TP4056进入恒压充电模式。当充电电流减小到充电结
束阈值时,充电周期结束,
端输出高阻态,
端输出低电位。
充电结束阈值是恒流充电电流的10%。当电池电压降到再充电阈值以下时,自动开始新的充电周期。芯片内部的高精度的电压基准源,误差放大器和电阻分压网络确保电池端调制电压的精度在1%以内,满足了锂离子电池和锂聚合物电池的要求。当输入电压掉电或者输入电压低于电池电压时,充电器进入低功耗的睡眠模式,电池端消耗的电流小于3uA ,从而增加了待机时间。如果将使能输入端CE 接低电平,充电器停止充电.
充电电流的设定
充电电流是采用一个连接在PROG 引脚与地之
间的电阻器来设定的。设定电阻器和充电电流采用下列公式来计算:
根据需要的充电电流来确定电阻3阻值,
1200
PROG BAT
R I =
(误差±10%) 客户应用中,可根据需求选取合适大小的R PROG
R PROG 与充电电流的关系确定可参考下表:
R PROG (k)
I BA T (mA)
30 50 20 70 10 130 5 250 4 300 3 400 2 580 1.66 690 1.5 780 1.33 900 1.2
1000
充电终止
当充电电流在达到最终浮充电压之后降至设定值的1/10时,充电循环被终止。该条件是通过采用一个内部滤波比较器对PROG 引脚进行监控来检测的。当PROG 引脚电压降至100mV 以下的时间超过TERM t (一般为1.8ms)时,充电被终止。充电电流被锁断,TP4056进入待机模式,此时输入电源电流降至55μA 。(注:C/10终止在3流充电和热限制模式中失效)。 充电时,BA T 引脚上的瞬变负载会使PROG 引脚电压在DC B&&R 降至设定值的1/10之间短暂地降至100mV 以>。终止n 较器上的1.8ms 滤波
时间(TERM t )确保这种性质的瞬变负载不会导致充电循环过早终止。一旦平均充电电流PQ 设定值
的1/10以下,TP4056即终止充电循环并停止通过BAT 引脚提供任何电流。在这种状态下,BA T 引脚上的所有负载都必须由电池来供电。
在待机模式中,TP4056对BA T 引脚电压进行连续监控。如果该引脚电压降到4.05V 的再
充电电门限(RECHRG V )以下,则另一个充电循环开始并再次向电池供应电流。
图1示出了一个典型充电循环的状态图。
充电状态指示器
TP4056有两个漏极6路状态指示输出端,和。当充电器处于充电状态时,被拉到低电平,在其它状态~处于高阻态。当电池的温度处于正常温度范围之外,
和 管脚都输出高阻态。
当TEMP 端典型接法使用时, 当电池没有接到充电器时,表示/0状态: 红灯和绿灯都不亮
2TEMP 端接GND 时,电池温度检测不起作用,当电池没有接到充电器时,输出脉冲信号表示没有安装电池。当电池连接端BAT 管脚的外接电容为10uF 时闪烁频率约1-4秒
当不用状态指示功能时,将不用的状态指示输出端接到地。
充电状态 红灯
绿灯
正在充电状态 亮 灭 电池充满状态
灭 亮 欠压,电池温度过高,过低 等故障状态,或无电池接入(TEMP 使用)
灭
灭
BAT 端接10u 电容,无电池 (TEMP=GND)
绿灯亮,红灯闪烁
T=1-4 S 热限制
如果芯片温度升至约140℃的预设值以上,
则一个内部热反馈环
路将减小设定的充电电流,直到150℃以上减小电流至0。该功能可防止TP4056过\~并允许用户提高给定电路板功率处理能力的上限而没有损坏TP4056的风险。在保证充电器将在最坏情况条件下自动减小电流的前提下,可+,典型(而不是最坏情况)环境温度来设定充电电流。
电池温度监测
为了防止温度过高或者过低对电池造成的损害,TP4056内部集成有电池温度监测电路。电池温度监测是通过测量TEMP 管脚的电压实现的,TEMP 管脚的电压是由电池内的NTC 热敏电阻和一个电阻分压网络实现的,如图1所示。
TP4056
TD semiconductor
TP4056将TEMP 管脚的电压同芯片内部的两个阈值V LOW 和V HIGH 相比较,以确>电池的温度是否超出正常范围。在TP4056内部,V LOW 被固定在45%×Vcc ,V HIGH 被固定在80%×Vcc 。如果TEMP 管脚的电压V TEMP
如果将TEMP 管脚接到地线,电池温度监测功能将被禁止。
确定R1和R2的值
R1和R2的值要根据电池的温度监测范围和热敏电阻的电阻值来确定,现BCD 明如下: 假设设定的电池温度范围为T L ~T H ,(其中T L F T H );电池中使用的是负温度系数的热<电阻(NTC ),R TL 为其在温度T L 时的阻值,R TH 为其在温度T H 时的阻值,则R TL >R TH ,HI ,在温度T L 时,第一管脚TEMP 端的电压为:
212TL
TEMPL
TL
R R V VIN R R R =×+ 在温度T H 时,第一管脚TEMP 端的电压为:
212TH
TEMPH
TH
R R V VIN R R R =×+ 然后,由V TEMPL L V HIGH =k 2×Vcc (k 2=0.8)
V TEMPH =V LOW =k 1×Vcc (k 1=0.45) 则可解得:
2
112
21112212()1()()
2()()
TL TH TL TH TL TH TL TH R R K K R R R K K R R K K R R K K K R K K K ?=??=
??? 同理,如果电池内部是正温度系数(PTC )的热敏电阻,则>,NO 可以计算得到:
2112
21112212()1()()
2()()
TL TH TH TL TL TH TH TL R R K K R R R K K R R K K R R K K K R K K K ?=
??=
???
从上面的推导中可以Q 出,待设定的温度范围与电源电压Vcc 是无关的,仅与R1、R2、R TH 、R TL 有关;其中,R TH 、R TL 可通过查阅相关的电池手册或通过实V 测试得到。
在实W 应用中,若只关注某一端的温度特性,比如过热保护,则R2可以不用,而只用R1即可。R1的推导也变得简单,在此不再赘述。
欠压闭锁
一个内部欠压闭锁电路对输入电压进行监控,并在Vcc 升至欠压闭锁门限以上之前使充电器保持在停机模式。UVLO 电路将使充电器保持在停机模式。如果UVLO 比较器发生跳变,则在Vcc 升至比电池电压高100mV 之前充电器将不会退出停机模式。
手动停机
在充电循环中的任何时刻都能通过置CE 端为低电位或去掉R PROG (从而使PROG 引脚浮置)来把TP4056置于停机模式。这使得电池漏电流降至2μA 以下,e 电源电流降至55μA 以下。重新将CE 端置为高电位或连接设定电阻器可启动一个新的充电循环。
如果TP4056处于欠压闭锁模式,则CHRG 和
引脚g 高阻抗状态:要么Vcc 高出BAT
引脚电压的幅度不足100mV ,要么施加在Vcc 引脚上的电压不足。
自动再启动
一旦充电循环被终止,TP4056立即采用一个具有1.8ms 滤波时间(RECHARGE t )的比较器来对BAT 引脚上的电压进行连续监控。当电池电压降至4.05V (大致对应于电池容量的80%至90%)以下时,充电循环重新开始。这确保
了电池被l 持在(或接近)一个满充电状态,并免除了进行周期性充电循环启动的需要。在再充电循环过程中,CHRG 引脚输出进入一个强下拉状态。
图1:一个典型充电循环的状态图
稳定性的考虑
在恒定电流模式中,位于反馈环路中的是
PROG 引脚,而不是电池。恒定电流模式的稳定性受PROG 引脚阻抗的影响。当PROG 引脚上没有附加电容会减小设定电阻器的最大容许阻值。PROG 引脚上的极点频率应保持在C PROG ,则可采用下式来计算R PROG 的最大电阻值:
PROG
PROG C R ??≤
51021
π
对用户来说,他们更感兴趣的可能是充电电流,而不是瞬态电流。例如,如果一个运行在低电流模式的开关电源与电池并联,则从BAT 引脚流出的平均电流通常比瞬态电流脉冲更加重要。在这种场合,可在PROG 引脚上采用一个简单的RC 滤波器来测量平均的电池电流(如图2所示)。在PROG 引脚和滤波电容器之间增设了一个10k 电阻器以确保稳定性。
图2:隔离PROG 引脚上的容性负载
和滤波电路
功率损耗
TP4056因热反馈的缘故而减小充电电流的条件可通过IC 中的功率损耗来估算。这种功率损耗几乎全部都是由内部MOSFET 产生的――这可由下式近似求出:
BAT BAT CC D I V V P ??=)(
式中的P D 为耗散的功率,V CC 为输入电源电压,V BA T 为电池电压,I BAT 为充电电流。当热反馈开始对IC 提供保护时,环境温度近似为:
145A D JA T C P θ=°?
145()A CC BAT BAT JA T C V V I θ=°????
实例:通过编程使一个从5V 电源获得工作电源的TP4056向一个具有3.75V 电压的放电锂离子
电池提供800mA 满幅度电流。假设JA θ为150℃/W (请参见电路板布局的考虑),当TP4056开始减小充电电流时,环境温度近似为:
145(5 3.75)(800)150/A T C V V mA C W =°????°1450.5150/14575A T C W C W C C =°??°=°?°65A T C =°
TP4056可在65℃以上的环境温度条件下使用,但充电电流将被降至800mA 以下。对于一个给定的环境温度,充电电流可有下式近似求出:
145()A
BAT CC BAT JA
C T I V V θ°?=
??
正如工作原理部分所讨论的那样,当热反馈使充电电流减小时,PROG 引脚上的电压也将成比例地减小。
切记不需要在TP4056应用设计中考虑最坏的热条件,这一点很重要,因为该IC 将在结温达到145℃左右时自动降低功耗。
热考虑
由于SOP8/MSOP8封装的外形尺寸很小,因此,需要采用一个热设计精良的PC 板布局以
最大幅度地增加可使用的充电电流,这一点非常重要。用于耗散IC 所产生的热量的散热通路从芯片至引线框架,并通过底部的散热片到达PC 板铜面。PC 板铜面为散热器。散热片相连的铜箔面积应尽可能地宽阔,并向外延伸至较大的铜面积,以便将热量散播到周围环境中。至内部或背部铜电路层的通孔在改善充电器的总体热性能方面也是颇有用处的。当进行PC 板布局设计时,电路板上与充电器无关的其他热源也是必须予以考虑的,因为它们将对总体温升和最大充电电流有所影响。
增加热调节电流
降低内部MOSFET 两端的压降能够显著减少IC 中的功耗。在热调节期间,这具有增加输送至电池的电流的作用。对策之一是通过一个外部元件(例如一个电阻器或二极管)将一部分功率耗散掉。
实例:通过编程使一个从5V 交流适配器获得工作电源的TP4056向一个具有3.75V 电压的放电锂离子电池设置为800mA 的满幅充电电流。假设JA θ为125℃/W ,则在25℃的环境温度条件下,充电电流近似为:
14525768(5 3.75)125/BAT C C
I mA V V C W
°?°=
=??°
通过降低一个与5V 交流适配器串联的电阻器两端的电压(如图3所示),可减少片上功耗,从而增大热调整的充电电流:
14525()BAT S BAT CC BAT JA
C C
I V I R V θ°?°=
???
图3:一种尽量增大热调节模式充节电流
的电路
利用二次方程可求出2
BAT I 。
BAT CC
I =
取R CC =0.25Ω、V S =5V 、V BA T =3.75V 、T A =25℃且/W 亷125JA =θ,我们可以计算出热调整的充电电流:I BA T =948mA,结果说明该结构可以在更高的环境温度下输出800MA 满幅充电.
虽然这种应用可以在热调整模式中向电池输送更多的能量并缩短充电时间,但在电压模式中,如果V CC 变得足够低而使TP4056处于低压降状态,则它实际上有可能延长充电时间。图4示出了该电路是如何随着R CC 的变大而导致电压下降的。
当为了保持较小的元件尺寸并避免发生压降而使R CC 值最小化时,该技术能起到最佳的作用。请牢记选择一个具有足够功率处理能力的电阻器。
V CC 旁路电容器
输入旁路可以使用多种类型的电容器。然而,在采用多层陶瓷电容器时必须谨慎。由于有些类型的陶瓷电容器具有自谐振和高Q 值的特点,因此,在某些启动条件下(比如将充电器输入与一个工作中的电源相连)有可能产生高的电压瞬态信号。增加一个与X5R 陶瓷电容器串联的1.5Ω电阻器将最大限度地减小启动电压瞬态信号。
充电电流软启动
TP4056包括一个用于在充电循环开始时最大限度地减小涌入电流的软启动电路。当一个充电循环被启动时,充电电流将在20μs左右的时间里从0上升至满幅全标度值。在启动过程中,这能够起到最大限度地减小电源上的瞬变电流负载的作用。
图5:低损耗输入反向极性保护
USB和交流适配器电源
TP4056允许从一个交流适配器或一个USB 端口进行充电。图6示出了如何将交流适配器与USB电源输入加以组合的一个实例。一个P 沟道MOSFET(MP1)被用于防止交流适配器接入时信号反向传入USB端口,而一个肖特基二极管(D1)则被用于防止USB功率在经过1K 下拉电阻器时产生损耗。
一般来说,交流适配器能够提供比电流限值为500mA的USB端口大得多的电流。因此,当交流适配器接入时,可采用一个N沟道MOSFET(MN1)和一个附加的10K设定电阻器来把充电电流增加至600mA。
图6:交流适配器与USB电源的组合
封装描述
8引脚SOP-PP 封装(单位mm )
TP4056
TD semiconductor
8引脚MSOP-PP 封装(单位mm )
TP4056
TD semiconductor
典型应用
适合需要电池温度检测功能,电池温度异常指示
和充电状态指示的应用
适合需要充电状态指示,不需要 适合既不需要充电状态指示,也不需要 电池温度监测功能的应用 电池温度监测功能的应用
适合同时应用USB 接口和墙上适配器充电 充电状态用红色LED 指示,充电结束状态
用绿色LED 指示,增加热耗散功率电阻
TP4056
TD semiconductor
TP4056使用注意事项及 DEMO 板说明书
一、TP4056使用注意事项:
1、TP4056采用SOP8/MSOP8-PP 封装,使用中需将底部散热片与PCB 板焊接良好,底
部散热区域需要加通孔,并有大面积铜箔散热为优。多层PCB 加充分过孔对散热有良好的效果,散热效果不佳可能引起充电电流受温度保护而减小。在SOP8/MSOP8 背面散热部分加适当的过孔,也方便了手工焊接,(可以从背面过孔处灌焊锡,将散热面可靠焊接)。
2、TP4056应用在大电流充电(700mA 以上),为了缩短充电时间,需增加热耗散电阻
(如下图R11、R12),阻值范围0.2~0.5Ω。客户根据使用情况选取合适电阻大小。 3、TP4056应用中BA T 端的10u 电容位置以靠近芯片BA T 端为优,不宜过远。
4、TP4056测试中,BA T 端应直接连接电池,不可串联电流表,电流表可接在Vcc 端。
5、为保证各种情况下可靠使用,防止尖峰和毛刺电压引起的芯片损坏,建议在BA T 端
和电源输入端各接一个0.1u 的陶瓷电容,而且在布线时十分靠近TP4056芯片。
二、TP4056 DEMO 板电路图
三、功能演示说明:(工作环境:电源电压5V ,环境温度25℃。) 1、设置充电电流。(用户可以调节电位器选择需要的充电电流) 闭合KPR1k, RPROG=1k 1300mA 闭合KPR1.2k, RPROG=1.2k 1000mA 闭合KPR2k, RPROG=2k 600mA 闭合KPR10k, RPROG=10k 130mA
闭合KPR103, RPROG=0.82k -10.5k 120mA -1300mA 2、设置指示灯,红绿双灯指示:
充电状态
指示灯状态 正在充电状态 红灯亮,绿灯灭 电池充满状态
红灯灭,绿灯亮 欠压,电池温度过高,过低,无电池等故障状态(TEMP 端正常连接) 红灯灭,绿灯灭 BAT 端接10u 电容,无电池(TEMP 端接地)
绿灯亮,红灯闪烁
TP4056
TD semiconductor
3、模拟充电状态
闭合KPR10k, KBA T-C, KBAT-R ,KT-GND
BAT 端连接一电容C2和一电阻R6代替锂电池,模拟正在充电状态:红灯亮,绿灯灭。 说明:此状态模拟仅限电源电压小于等于5V ,大于5V 时请用锂电池实际测试。 闭合KPR10k, KBA T-C ,KT-GND
BAT 端连接一电容C2代替锂电池,模拟充电完成状态:绿灯亮,红灯闪烁。
说明:由于使用10uF 的电容C2代替锂电池模拟充满状态,电容充满后缓慢放电,当电
容电压变低至再充电门限电压4.05V 时,自动再次充电,则可看见红灯周期性闪烁。
4、模拟充电末端BA T 端电压
闭合KPR10k, KBA T-C, KBAT-R ,KT-GND
测量BA T 端电压。即为充电结束时电压4.2V ±1.5%。
5、如客户需要监测电池温度,断开KT-GND ,连接TP4056的TEMP 端(1脚,已预留连接孔)至锂电池温度监测端,客户根据实际情况自定R9,R10大小并安装。如不需要此项功能,闭合KT-GND 即可。
6、CE 始能端。闭合开关KCE-GND ,CE 端下拉至低电平,芯片停止充电;打开KCE-GND ,芯片正常充电。
7、有的客户在应用中BA T 端无锂电池时不希望红色指示灯闪烁,闭合KBA TUP ,将BA T 端用100k 电阻连接至Vdd ,绿灯亮,可用于指示待机状态,不影响正常充电使用。 8、锂电池充电
将锂电池正极连接至芯片BA T 端,负极接地。需要温度监测功能请连接TEMP 端(1脚),否则闭合KT-GND 。设置需要的充电电流和指示灯,断开KBA TR ,KCE-GND ,即可开始充电。
TP4056
TD semiconductor
哈希表应用
附件4: 北京理工大学珠海学院 课程设计任务书 2010 ~2011学年第二学期 学生姓名:专业班级: 指导教师:工作部门: 一、课程设计题目 哈希表应用 二、课程设计内容(含技术指标) 【问题描述】 利用哈希表进行存储。 【任务要求】 任务要求:针对一组数据进行初始化哈希表,可以进行显示哈希表,查找元素,插入元素,删除元素,退出程序操作。 设计思想:哈希函数用除留余数法构造,用线性探测再散列处理冲突。 设计目的:实现哈希表的综合操作 简体中文控制台界面:用户可以进行创建哈希表,显示哈希表,查找元素,插入元素,删除元素。 显示元素:显示已经创建的哈希表。 查找元素:查找哈希表中的元素,分为查找成功和查找不成功。 插入元素:在哈希表中,插入一个元素,分为插入成功和失败。 删除元素:在已有的数据中,删除一个元素。 退出系统:退出程序。 【测试数据】 自行设定,注意边界等特殊情况。
三、进度安排 1.初步设计:写出初步设计思路,进行修改完善,并进行初步设计。 2.详细设计:根据确定的设计思想,进一步完善初步设计内容,按要求编写出数据结构类型定义、各算法程序、主函数。编译分析调试错误。 3.测试分析:设计几组数据进行测试分析,查找存在的设计缺陷,完善程序。 4.报告撰写:根据上面设计过程和结果,按照要求写出设计报告。 5.答辩考核验收:教师按组(人)检查验收,并提出相关问题,以便检验设计完成情况。 四、基本要求 1.在设计时,要严格按照题意要求独立进行设计,不能随意更改。若确因条件所限,必须要改变课题要求时,应在征得指导教师同意的前提下进行。 2.在设计完成后,应当场运行和答辩,由指导教师验收,只有在验收合格后才能算设计部分的结束。 3.设计结束后要写出课程设计报告,以作为整个课程设计评分的书面依据和存档材料。设计报告以规定格式的电子文档书写、打印并装订,报告格式严格按照模板要求撰写,排版及图、表要清楚、工整。 从总体来说,所设计的程序应该全部符合要求,问题模型、求解算法以及存储结构清晰;具有友好、清晰的界面;设计要包括所需要的辅助程序,如必要的数据输入、输出、显示和错误检测功能;操作使用要简便;程序的整体结构及局部结构要合理;设计报告要符合规范。 课程负责人签名: 年月日
哈希表基本操作
一,哈希表(Hashtable)简述 在.NET Framework中,Hashtable是System.Collections命名空间提供的一个容器,用于处理和表现类似key/value的键值对,其中key通常可用来快速查找,同时key是区分大小写;value用于存储对应于key的值。Hashtable中key/value键值对均为object 类型,所以Hashtable可以支持任何类型的key/value键值对. 二,哈希表的简单操作 在哈希表中添加一个key/value键值对:HashtableObject.Add(key,value); 在哈希表中去除某个key/value键值对:HashtableObject.Remove(key); 从哈希表中移除所有元素:HashtableObject.Clear(); 判断哈希表是否包含特定键key:HashtableObject.Contains(key); 下面控制台程序将包含以上所有操作: using System; using System.Collections; //使用Hashtable时,必须引入这个命名空间 class hashtable { public static void Main() { Hashtable ht=new Hashtable(); //创建一个Hashtable实例 ht.Add("E","e");//添加key/value键值对 ht.Add("A","a"); ht.Add("C","c"); ht.Add("B","b"); string s=(string)ht["A"]; if(ht.Contains("E")) //判断哈希表是否包含特定键,其返回值为true或false Console.WriteLine("the E key:exist"); ht.Remove("C");//移除一个key/value键值对 Console.WriteLine(ht["A"]);//此处输出a ht.Clear();//移除所有元素 Console.WriteLine(ht["A"]); //此处将不会有任何输出 } } 三,遍历哈希表 遍历哈希表需要用到DictionaryEntry Object,代码如下: for(DictionaryEntry de in ht) //ht为一个Hashtable实例 { Console.WriteLine(de.Key);//de.Key对应于key/value键值对key Console.WriteLine(de.Value);//de.Key对应于key/value键值对value
散列表(哈希表)
1. 引言 哈希表(Hash Table)的应用近两年才在NOI(全国青少年信息学奥林匹克竞赛)中出现,作为一种高效的数据结构,它正在竞赛中发挥着越来越重要的作用。 哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。 哈希表又叫做散列表,分为“开散列” 和“闭散列”。考虑到竞赛时多数人通常避免使用动态存储结构,本文中的“哈希表”仅指“闭散列”,关于其他方面读者可参阅其他书籍。 2. 基础操作 2.1 基本原理 我们使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数,也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方。 但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。后面我们将看到一种解决“冲突”的简便做法。 总的来说,“直接定址”与“解决冲突”是哈希表的两大特点。 2.2 函数构造 构造函数的常用方法(下面为了叙述简洁,设h(k) 表示关键字为k 的元素所对应的函数值): a) 除余法: 选择一个适当的正整数p ,令h(k ) = k mod p ,这里,p 如果选取的是比较大
的素数,效果比较好。而且此法非常容易实现,因此是最常用的方法。 b) 数字选择法: 如果关键字的位数比较多,超过长整型范围而无法直接运算,可以选择其中数字分布比较均匀的若干位,所组成的新的值作为关键字或者直接作为函数值。 2.3 冲突处理 线性重新散列技术易于实现且可以较好的达到目的。令数组元素个数为S ,则当h(k)已经存储了元素的时候,依次探查(h(k)+i) mod S , i=1,2,3…… ,直到找到空的存储单元为止(或者从头到尾扫描一圈仍未发现空单元,这就是哈希表已经满了,发生了错误。当然这是可以通过扩大数组范围避免的)。 2.4 支持运算 哈希表支持的运算主要有:初始化(makenull)、哈希函数值的运算(h(x))、插入元素(i nsert)、查找元素(member)。设插入的元素的关键字为x ,A 为存储的数组。初始化比较容易,例如: const empty=maxlongint; // 用非常大的整数代表这个位置没有存储元素 p=9997; // 表的大小 procedure makenull; var i:integer; begin for i:=0 to p-1 do A[i]:=empty; End; 哈希函数值的运算根据函数的不同而变化,例如除余法的一个例子:
哈希表设计-大大数据结构课程设计
实习6、哈希表设计 一、需求分析 1. 问题描述 针对某个集体(比如你所在的班级)中的“人名”设计一个哈希表,使得平均查找长度均不超过R,完成相应的建表和查表顺序。 2. 基本要求 假设人名为中国人姓名的汉语拼音形式。待填入哈希表的人名共有30个,取平均查找长度的上限为2。哈希函数用除留余数法构造,用伪随机探测再散列法处理冲突。 3. 测试数据 取读者周围较熟悉的30个人的姓名。 4. 实现提示 如果随机数自行构造,则应首先调整好随机函数,使其分布均匀。人名的长度均不超过19个字符(最长的人名如:庄双双(Zhuang Shuangshuang))。字符的取码方法可直接利用C语言中的toascii函数,并可先对过长的人名先作折叠处理。 二、概要设计 ADT Hash { 数据对象D:D是具有相同特征的数据元素的集合。各数据元素均含有类型相同,可唯一标识数据元素的关键字。 数据关系R:数据元素同属一个集合。 InitNameT able() 操作结果:初始化姓名表。 CreateHashT able() 操作结果:建立哈希表。 DisplayNameTable() 操作结果:显示姓名表。 DisplayHashT able() 操作结果:显示哈希表。 FindName() 操作结果:查找姓名。 }ADT Hash 三、详细设计(源代码) (使用C语言) #include
哈希表设计数据结构课程设计
哈希表设计数据结构课程设计
实习6、哈希表设计 一、需求分析 1. 问题描述 针对某个集体(比如你所在的班级)中的“人名”设计一个哈希表,使得平均查找长度均不超过R,完成相应的建表和查表顺序。 2. 基本要求 假设人名为中国人姓名的汉语拼音形式。待填入哈希表的人名共有30个,取平均查找长度的上限为2。哈希函数用除留余数法构造,用伪随机探测再散列法处理冲突。 3. 测试数据 取读者周围较熟悉的30个人的姓名。 4. 实现提示 如果随机数自行构造,则应首先调整好随机函数,使其分布均匀。人名的长度均不超过19个字符(最长的人名如:庄双双(Zhuang Shuangshuang))。字符的取码方法可直接利用C语言中的toascii函数,并可先对过长的人名先作折叠处理。 二、概要设计 ADT Hash { 数据对象D:D是具有相同特征的数据元素的集合。各数据元素均含有类型相同,可唯一标识数据元素的关键
字。 数据关系R:数据元素同属一个集合。 InitNameTable() 操作结果:初始化姓名表。 CreateHashTable() 操作结果:建立哈希表。 DisplayNameTable() 操作结果:显示姓名表。 DisplayHashTable() 操作结果:显示哈希表。 FindName() 操作结果:查找姓名。 }ADT Hash 三、详细设计(源代码) (使用C语言) #include
哈希表及其应用-课程设计
课程设计题目哈希表及其应用 教学院计算机学院 专业 班级 姓名 指导教师 年月日
课程设计任务书 2010 ~2010 学年第 1 学期 一、课程设计题目哈希表及其应用 二、课程设计内容 建立一个小型信息管理系统(可以是图书、人事、学生、物资、商品等任何信息管理系统)。要求: 1.使用哈希查找表存储信息; 2.实现查找、插入、删除、统计、输出等功能; 三、进度安排 1.初步完成总体设计,搭好框架; 2.完成最低要求:尝试使用多种哈希函数和冲突解决方法,并通过实际运行测试给出自己的评价 四、基本要求 1.界面友好,函数功能要划分好 2.程序要加必要的注释 3.要提供程序测试方案 教研室主任签名: 年月日
1 概述 (4) 2 设计目的 (4) 3 设计功能说明 (4) 4 详细设计说明 (5) 5 流程图 (5) 6 程序代码 (6) 7 程序运行结果 (15) 8 总结 (19) 参考文献 (19) 成绩评定表 (20)
数据结构是一门理论性强、思维抽象、难度较大的课程,是基础课和专业课之间的桥梁,只有进行实际操作,将理论应用于实际中,才能确实掌握书中的知识点。通过课程设计,不仅可以加深学生对数据结构基本概念的了解,巩固学习成果,还能够提高实际动手能力。为学生后继课程的学习打下良好的基础。 2 设计目的 《数据结构》课程设计是在教学实践基础上进行的一次大型实验,也是对该课程所学理论知识的深化和提高。因此,要求学生能综合应用所学知识,设计与制造出具有较复杂功能的应用系统,并且在实验的基本技能方面上进行一次全面的训练。通过程序的编译掌握对程序的调试方法及思想,并且让学生学会使用一些编程技巧。促使学生养成良好的编程习惯。 1.使学生能够较全面地巩固和应用课堂中所学的的基本理论和程序设计方法,能够较熟练地完成程序的设计和调试。 2.培养学生综合运用所学知识独立完成程序课题的能力。 3.培养学生勇于探索、严谨推理、实事求是、有错必改,用实践来检验理论,全方位考虑问题等科学技术人员应具有的素质。 4.提高学生对工作认真负责、一丝不苟,对同学团结友爱,协作攻关的基本素质。 5.培养学生从资料文献、科学实验中获得知识的能力,提高学生从别人经验中找到解决问题的新途径的悟性,初步培养工程意识和创新能力。 6.对学生掌握知识的深度、运用理论去处理问题的能力、实验能力、课程设计能力、书面及口头表达能力进行考核。 3 设计功能分析 本设计的功能如下: 1、利用哈希函数来实现一个小型信息管理系统,其中信息包含用户名,地址,电话等。 2、能添加用户信息,并能保存该信息。 3、查询管理系统中的信息:可通过姓名查找,也可通过电话查找等两种方式。
哈希表
哈希表(hashtable) 注:哈希表为1.24及以上版本才有的功能,以下版本是无法使用的说~ (在1.24之前,游戏缓存(ganecache)+return bug起到了相同的作用,124之后它们即被哈希表取代, 并且return bug在1,24之后,被修复了) 本演示侧重于hashtable,仅仅会顺带提到hashtable与gamecache两种方式的等价代码转换~ ☆哈希表的特点与优势~ 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 当然这个概念可能过于深奥,我们不必了解那么深入,只需要了解它的功能以及如何使用~(当然有能力的童鞋,推荐去百度寻找详解) 先简单介绍下好了~hashtable就相当于一个存储数据的仓库,其具有容量大以及存储速度稳定的特点~ 使用hashtable与GetHandleId函数,能够非常轻易地实现一个技能的多人无冲突使用~ ☆先来认识下这货~ 首先,我们先来声明一个哈希表对象~ 由于哈希表通常起到全局范围内的数据存储以及传递~ 所以我们绝大多数情况(和所有基本没区别)都是将其作为一个全局变量来声明(几乎没有局部变量的 哈希表,只有在某些特殊需求下,才会罕见地出现;如果你明确知道自己创建局部hashtable的目的,并 且知道如何妥善掌控,那么是毫无问题的) jass globals hashtable ht=InitHashtable() //函数InitHashtable,无参数,返回一个新建的哈希表对象 //在向一个哈希表中存入数据之前,必须先通过此函数创建哈希表,否则无效(好比你无法往一个根本 不存在的容器中倒水一样的说~) endglobals 很简单,这样就创建了一个哈希表,你可以在地图中的任何地方(没错,任何地方)访问它~ Tips: (显式声明globals块(也就是上面)的方式,其实是Vjass才有的功能~如果你的编辑器UI没有这个,请 在T的变量管理器中,创建一个哈希表对象,但别忘了加上udg_前缀以及调用InitHashtable函数进行初 始化~) 然后我们可以试着,在其中存并且读取一些数据~ jass function Trig_Init_Actions takes nothing returns nothing local integer i=5 local integer ret//两个整数变量
哈希算法介绍
哈希算法简介
目录 1哈希算法概念 (2) 2哈希函数 (3) 3冲突的解决方法 (3) 4哈希算法应用 (4)
关键词: 算法、哈希、c语言 摘要: 哈希算法在软件开发和Linux内核中多次被使用,由此可以见哈希算法的实用性和重要性。本文介绍了哈希算法的原理和应用,并给出了简略的代码实现,以便读者理解。
1哈希算法概念 哈希(hash 散列,音译为哈希) 算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。 哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希算法都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。 哈希表是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的项作为记录在表中的存储位置,这种表称为哈希表,所得存储位置称为哈希地址。作为线性数据结构与表格和队列等相比,哈希表无疑是查找速度比较快的一种。 查找一般是对项的摸个部分(及数据成员)进行,这部分称为键(key )。例如,项可以由字符串作为键,附带一些数据成员。 理想的哈希表数据结构只不过是一个包含一些项的具有固定大小的数组。 通常的习惯是让项从0到 TableSize-1之间变化。 将每个键映射到0到TableSize-1 这个范围中的某个数 ,并且将其放到适当的单元中,这个映射就称为散列函数(hash funciton )。 如右图,john 被散列到3,phil 被散列到4,dave 被散列到6,mary 被散列到7. 这是哈希的基本思想。剩下的问题则是要选择一个函数,决定当两个键散列到同一个值的时候(称为冲突),应该做什么。
哈希表的操作
哈希表操作 一目的 1.巩固和加深对哈希表的创建、查找、插入等方法理论知识的理解。 2.掌握建立哈希表的办法,本实验是采用的是除留余数法创建。 3.掌握哈希表解决冲突的办法,本实验用的是线性探测再散列的方法。 4.巩固对程序模块化设计的要求。 二需求分析 1.对于哈希表的基本操作首先是要创建一个哈希表,哈希表的创建思想是由哈希函 数得到,本实验就采用了除留余数法创建哈希表。 2.创建好哈希表就需要在哈希表中插入元素,本实验是需要插入单词,所以需要调 用string函数库,通过每个单词的地址数来进行下一步的查找计划。当插入单词地址已经存在时,就产生了冲突,因此需要采用线性探测再散列的方式来解决冲突。 3.当哈希表插入单词完成之后便可以显示哈希表的存储情况,因此需要输出整个哈 希表。 4.要想计算平均查找长度首先要对哈希表中的元素进行查找,当所有单词查找结 束,查找长度也得出。 5.要实现上诉需求,程序需要采用模块化进行设计。 三概要设计 1.基本操作: void Initwordlist(int n) 初始化哈希表 操作结果:以字符形式插入单词,将字符串的各个字符所对应的ASCII码相加,所得的整数做为哈希表的关键字。
void Createhashlist(int n) 创建哈希表,并插入单词 操作结果: (1)用除留余数法构建哈希函数; (2)用线性探测再散列处理冲突。 void find() 查找哈希表中的单词 操作结果:在哈希表中进行查找,输出查找的结果和关键字,并计算和输出查找成功的平均查找长度。 void printhash() 显示哈希表 操作结果:显示哈希表的存储情况:位置%d\t\t关键字%-6d\t\t单词%s\n。 float average() 操作结果:计算出平均查找长度。 void menu() 菜单函数设计 操作结果:显示格式: 1向哈希表中插入单词(<15); 2查找哈希表中的单词; 3显示哈希表的存储情况; 4计算哈希表的平均查找长度; 5退出程序。 int main() 主程序设计 操作结果:通过调用各个函数操作得到结果。
数据结构课程设计-哈希表建立职工管理系统
一.问题描述 职工的姓名通过哈希表建表,基于哈希表的查找,建立一个简单的职工管理 系统。可以利用自己的班集体中的“人名”设计一个哈希表,使得平均查找长度 不超过R,完成相应的建表和查表程序。对将班上同学看做职工进行管理,包括 插入、删除、查找、排序等功能。 二.基本要求 假设人名为中国姓名的汉语拼音形式。待填入哈希表的人名共有30个,取 平均查找长度的上限为2。哈希函数用除留余数法构照,用链表法处理冲突。 职工对象包括姓名、性别、出生年月、工作年月、学历、职务、住址、电话 等信息。 (1)新增一名职工:将新增职工对象按姓名以字典方式职工管理文件中。 (2)删除一名职工:从职工管理文件中删除一名职工对象。 (3)查询:从职工管理文件中查询符合某些条件的职工。 (4)修改:检索某个职工对象,对其某些属性进行修改。 (5)排序:按某种需要对职工对象文件进行排序。 三.数据结构的设计 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进 行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做哈希表。 1.哈希表的构造方法多种多样,实际工作中需视不同的情况采用不同的哈希 函数,经常在构建一个哈希表选择构造方法时需要考虑的因素有:计算哈希函 数所需时间、关键字的长度、哈希表的大小、关键字的分布情况、记录的查找频 率等。本次题目要求采用除留余数法构造哈希函数,一般方法如下:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。 即 H(key) = key MOD p,p<=m 不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p 的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。由于职工主 要以姓名为标志,于是将职工姓名的汉语拼音所对应的ASCII码进行相加,所得 到的和作为关键字;取p等于表长30,则关键字除以30以后所得到的余数便是 哈希地址。 2.哈希表是种数据结构,它可以提供快速的插入操作和查找操作。哈希表也 有一些缺点它是基于数组的,数组创建后难于扩展某些哈希表被基本填满时,性 能下降得非常严重。这个问题是哈希表不可避免的,即冲突现象:对不同的关键 字可能得到同一哈希地址。对于如何解决冲突现象,也有喝多方法,本次题目要 求用连地址法处理冲突。一般方法如下: 将所有关键字为同义词的记录存储在同一线性链表中。假设某哈希函数产生 哈希地址的区间在【0,m-1】上,则设立一个指针型变量 Chain ChainHash[m]; 其每个分量的初始状态都是空指针。凡哈希地址为i的记录都插入到头指针为ChainHash[i]的链表中。在链表中的插入位置可以再表头或表尾,也可以再中间,以保持同义词在同一线性链表中按关键字有序。 3.哈希表的查找过程和建表过程基本一致。给定K值,根据建表时设定的哈
哈希查找_数据结构实验报告
南昌航空大学实验报告 课程名称:数据结构实验名称:实验九查找 班级:学生姓名:学号: 指导教师评定:签名: 题目:编程实现哈希表的造表和查找算法。 要求:用除留余数法构造哈希函数,用二次探测再散列解决冲突。 一、需求分析 1.用户可以根据自己的需求输入一个顺序表(哈希表) 2.通过用除留余数法构造哈希函数,并用开放地址的二次探测再散列解决冲突。 3.在经过排序后显示该哈希表。 4.程序执行的命令包括: (1)创建哈希表(2)输出哈希表(3)二次探测再散列解决冲突 二、概要设计 ⒈为实现上述算法,需要顺序表的抽象数据类型: ADT Hash { 数据对象D:D是具有相同特征的数据元素的集合。各数据元素均含有类型相同,可唯一标识数据元素的关键字。 数据关系R:数据元素同属一个集合。 基本操作P: Creathash(&h) 操作结果:构造一个具有n个数据元素的哈希查找表h。 destroyhash(&h) 初始条件:哈希查找表h存在。 操作结果:销毁哈希查找表h。 displayhash(h) 初始条件:哈希查找表h存在。 操作结果:显示哈希查找表h。 hash(h,&k) 初始条件:哈希查找表h存在。 操作结果:通过除留余数法得到地址用k返回。 hash2 (i,&k) 初始条件:哈希查找表h存在存在,i是除留余数法得到的地址。 操作结果:返回二次探测再散列解决冲突得到的地址k。 search (h,key) 初始条件:哈希查找表h存在。 操作结果:查找表h中的key,若查找成功,返回其地址,否则返回
-1 insert (&h,key) 初始条件:哈希查找表h存在。 操作结果:若表h中没有key,则在h中插入key。 search1(h, key,&p) 初始条件:哈希查找表h存在。 操作结果:在表h中查找key,若没有,则返回p的插入的地址,否 则返回-1。 }ADT Hash 2. 本程序有三个模块: ⑴主程序模块 main(){ 初始化; { 接受命令; 显示结果; } } ⑵创建hash表的模块:主要建立一个哈希表; ⑶解决冲突模块:利用开放地址的二次探测再散列解决冲突; (4)输出哈希表模块:显示已创建哈希表。 三、详细设计 ⒈元素类型,结点类型 typedef struct { int key; }keytype; typedef struct { keytype elem[100]; int length; /*当前的长度*/ int size; /*哈希表的总长*/ }hashtable; /*全局变量*/ int a=0,b=0; /*哈希函数*/ 2.对抽象数据类型中的部分基本操作的伪码算法如下: /*哈希函数*/ int hash(hashtable *h,int k) { return k%h->size; }
常见的Hash算法
常见的Hash算法 1.简介 哈希函数按照定义可以实现一个伪随机数生成器(PRNG),从这个角度可以得到一个公认的结论:哈希函数之间性能的比较可以通过比较其在伪随机生成方面的比较来衡量。 一些常用的分析技术,例如泊松分布可用于分析不同的哈希函数对不同的数据的碰撞率(collision rate)。一般来说,对任意一类的数据存在一个理论上完美的哈希函数。这个完美的哈希函数定义是没有发生任何碰撞,这意味着没有出现重复的散列值。在现实中它很难找到一个完美的哈希散列函数,而且这种完美函数的趋近变种在实际应用中的作用是相当有限的。在实践中人们普遍认识到,一个完美哈希函数的哈希函数,就是在一个特定的数据集上产生的的碰撞最少哈希的函数。 现在的问题是有各种类型的数据,有一些是高度随机的,有一些有包含高纬度的图形结构,这些都使得找到一个通用的哈希函数变得十分困难,即使是某一特定类型的数据,找到一个比较好的哈希函数也不是意见容易的事。我们所能做的就是通过试错方法来找到满足我们要求的哈希函数。可以从下面两个角度来选择哈希函数: 1.数据分布 一个衡量的措施是考虑一个哈希函数是否能将一组数据的哈希值进行很好的分布。要进行这种分析,需要知道碰撞的哈希值的个数,如果用链表来处理碰撞,则可以分析链表的平均长度,也可以分析散列值的分组数目。 2.哈希函数的效率 另个一个衡量的标准是哈希函数得到哈希值的效率。通常,包含哈希函数的算法的算法复杂度都假设为O(1),这就是为什么在哈希表中搜索数据的时间复杂度会被认为是"平均为O(1)的复杂度",而在另外一些常用的数据结构,比如图(通常被实现为红黑树),则被认为是O(logn)的复杂度。 一个好的哈希函数必修在理论上非常的快、稳定并且是可确定的。通常哈希函数不可能达到O(1)的复杂度,但是哈希函数在字符串哈希的线性的搜索中确实是非常快的,并且通常哈希函数的对象是较小的主键标识符,这样整个过程应该是非常快的,并且在某种程度上是稳定的。 在这篇文章中介绍的哈希函数被称为简单的哈希函数。它们通常用于散列(哈希字符串)数据。它们被用来产生一种在诸如哈希表的关联容器使用的key。这些哈希函数不是密码安全的,很容易通过颠倒和组合不同数据的方式产生完全相同的哈希值。 2.哈希方法学 哈希函数通常是由他们产生哈希值的方法来定义的,有两种主要的方法: 1.基于加法和乘法的散列 这种方式是通过遍历数据中的元素然后每次对某个初始值进行加操作,其中加的值和这个数据的一个元素相关。通常这对某个元素值的计算要乘以一个素数。
哈希表c语言程序代码
/* 实验项目名称:电话号码查询系统的实现 实验目的与要求: 1.基础知识:掌握数据结构中的查找、排序等算法相关知识; 掌握C或VC++语言中程序设计的方法。 2.参考教材相关算法,完成以下程序功能: (1)自选存储结构实现电话号码表的初始化; (2)编写一个电话号码查询系统,要求有电话号码记录的录入(插入)存储、查询、记录删除、排序、打印等模块; 实验性质: 综合性(4学时) 说明: 存储结构可采用哈希表的方式,完成用电话号码或姓名为关键字构建哈希表,并进行查询、添加、删除、打印记录等功能模 块(此方式为推荐方式),其次子函数的调用顺序由最终用户决定(可用多分支结构),程序中应有用户的操作选择界面. */ # include "stdio.h" # include "stdlib.h" # define SUCCESS 1 # define NULL_KEY -2 //-2为无标志记录 # define UNSUCCESS 0
# define DUPLICATE -1 int Hashsize[]={11,19,29,37}; //哈希表容量递增表,一个合适的素数序列int m=0; //哈希表表长,全局变量 typedef int KeyType; //设关键字为整形 typedef struct { char name; //姓名 KeyType num; //号码 }Node; typedef struct { Node *elem; //数据元素存储地址,动态分配数组 int count; //当前数据元素个数 int sizeindex; //Hashsize[H.sizeindex]为当前容量 }HashTable; void ChuangJian(HashTable &H) { //构建一个空哈希表 int i; H.count=0; //当前元素个数 H.sizeindex=0; //初试存储容量为hashsize[0]
常用的哈希函数
常用的哈希函数 通用的哈希函数库有下面这些混合了加法和一位操作的字符串哈希算法。下面的这些算法在用法和功能方面各有不同,但是都可以作为学习哈希算法的实现的例子。(其他版本代码实现见下载) 1.RS 从Robert Sedgwicks的Algorithms in C一书中得到了。我(原文作者)已经添加了一些简单的优化的算法,以加快其散列过程。 [java]view plaincopy 1.public long RSHash(String str) 2. { 3.int b = 378551; 4.int a = 63689; 5.long hash = 0; 6.for(int i = 0; i < str.length(); i++) 7. { 8. hash = hash * a + str.charAt(i); 9. a = a * b; 10. } 11.return hash; 12. } 2.JS Justin Sobel写的一个位操作的哈希函数。 [c-sharp]view plaincopy 1.public long JSHash(String str) 2. { 3.long hash = 1315423911; 4.for(int i = 0; i < str.length(); i++) 5. { 6. hash ^= ((hash << 5) + str.charAt(i) + (hash >> 2)); 7. } 8.return hash; 9. } 3.PJW 该散列算法是基于贝尔实验室的彼得J温伯格的的研究。在Compilers一书中(原则,技术和工具),建议采用这个算法的散列函数的哈希方法。
数据结构报告——散列表、哈希表
数 据 结 构 实 验 报 告 班级:姓名:学号:时间:
一、题目 散列表的设计 二、要求 1、问题描述 针对某个集体中人名设计一个散列表,使得平均查找长度不超过R,并完成相应的建表和查表程序。 2、基本要求 假设人名为中国人姓名的汉语拼音形式,待填入散列表的人名共有30个,取平均查找长度上限为2。散列函数用除留余数法构造,用伪随机探测再散列法处理冲突 3、测试数据 取读者周围较熟悉的30人的姓名。 4、实现提示 如果随机函数自行构造,则应首先调整好随机函数,使其发布均匀。人名的长度不超过20个字符。可先对过长的人名作折叠处理。 三、设计思想 1、散列函数的构造方法: 散列列函数的构造方法有四种:平方取中法、除余法、相乘取整法、随机数法。 这里用了除余法,该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m 该方法的关键是选取m。选取的m应使得散列函数值尽可能与关键字的各位相关。m最好为素数。 【例】若选m是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。 【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。 2、冲突的处理:
(1)冲突 两个不同的关键字,由于散列函数值相同,因而被映射到同一表位置上。该现象称为冲突(Collision)或碰撞。发生冲突的两个关键字称为该散列函数的同义词(Synonym)。 (2)安全避免冲突的条件 最理想的解决冲突的方法是安全避免冲突。要做到这一点必须满足两个条件: ①其一是|U|≤m ②其二是选择合适的散列函数。 这只适用于|U|较小,且关键字均事先已知的情况,此时经过精心设计散列函数h有可能完全避免冲突。 (3)冲突不可能完全避免 通常情况下,h是一个压缩映像。虽然|K|≤m,但|U|> m,故无论怎样设计h,也不可能完全避免冲突。因此,只能在设计h时尽可能使冲突最少。同时还需要确定解决冲突的方法,使发生冲突的同义词能够存储到表中。 (4)影响冲突的因素 冲突的频繁程度除了与h相关外,还与表的填满程度相关。 设m和n分别表示表长和表中填人的结点数,则将α=n/m定义为散列表的装填因子(Load Factor)。α越大,表越满,冲突的机会也越大。通常取α≤1。 (5)冲突处理 对不同的关键字可能得到同一个哈希地址即key1≠key2,而f(key1)=f(key2)。因此,在建造哈希表时不仅要设定一个好的哈希函数,而且要设定一种处理冲突的方法。用伪随机探测法。求下一个开放地址的公式为:Hi = (H(k)+di) MOD m Di=伪随机数序列; 3、相应的数据结构: 1)、对哈希表的操作 InitNameList() 操作结果:姓名(结构体数组)初始化 CreateHashList() 操作结果:建立哈希表 FindList() 操作结果:在哈希表中查找 Display() 操作结果:显示哈希表
哈希表制作通讯录数据结构程序设计
哈希表制作通讯录-数据结构程序设计
————————————————————————————————作者:————————————————————————————————日期:
软件学院 课程设计报告书 课程名称数据结构 设计题目哈希表制作通讯录 专业班级 学号 姓名 指导教师 2014年 1月
目录 1 设计时间 (1) 2 设计目的 (1) 3设计任务 (1) 4 设计内容 (1) 4.1需求分析 (1) 4.11程序所能达到的功能 (1) 4.12输入的形式和输入的范围 (1) 4.2总体设计 (1) 4.21说明本程序中用到的所有抽象数据类型的定义 (1) 4.22说明主程序的流程 (2) 4.23说明各程序模块之间的层次(调用)关系 (3) 4.3详细设计 (3) 4.31实现概要设计中定义的所有数据类型,对每个操作只需 要写出伪码算法 (3) 4.32对主程序和其它主要函数写出伪码算法 (4) 4.4测试 (5) 4.5 附录 (6) 5 总结与展望 (16) 参考文献 (18) 成绩评定 (18)
1 设计时间 2014年1月13日到2014年1月15号 2 设计目的 要求学生掌握数据结构的应用、算法的编写、类C语言的算法转换成C程序并上机调试的基本方法。这对于学生基本程序设计素养的培养和软件工作者工作作风的训练,将起到显著的促进作用。 3设计任务 针对你所在班集体中的“人名”,设计一个哈希表,使得平均查找长度不超过R,完成相应的建表和查找过程。 4 设计内容 (1)每个人的信息至少包括姓名,电话,地址。至少包括对通讯录的创建,添加和按姓名查找等功能。 (2)假设人名为汉语拼音全拼形式,待插入哈希表的长度为你所在班级的人数。哈希函数用除留余数法构造,采用链地址法或二次探测再散列法解决冲突。 (3)完成菜单设计。操作有必要的提示。 4.1需求分析 4.11程序所能达到的功能 以人命的汉语拼音全拼形式查找你所在班级的人的信息(姓名,电话,地址) 4.12输入的形式和输入的范围 把人名都到转换成汉语拼音全拼的形式,人命最大长度不超过20个字符 4.2总体设计 4.21说明本程序中用到的所有抽象数据类型的定义 该程序采用的是结构体类型来处理学生的所有基本信息,如下所述。
哈希表及其应用
哈希表及其应用 一、定义 二、基本原理 哈希表的基本原理是:使用一个下标范围比较大的数组A来存储元素,设计一个函数h,对于要存储的线性表的每个元素node,取一个关键字key,算出一个函数值h(key),把h(key)作为数组下标,用A[h(key)]这个数组单元来存储node。也可以简单的理解为,按照关键字为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方(这一过程称为“直接定址”)。 但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。例如,假设一个结点的关键码值为key,把它存入哈希表的过程是:根据确定的函数h计算出h(key)的值,如果以该值为地址的存储空间还没有被占用,那么就把结点存入该单元;如果此值所指单元里已存了别的结点(即发生了冲突),那么就再用另一个函数I进行映象算出I(h(key)),再看用这个值作为地址的单元是否已被占用了,若已被占用,则再用I映象,……,直到找到一个空位置将结点存入为止。当然这只是解决“冲突”的一种简单方法,如何避免、减少和处理“冲突”是使用哈希表的一个难题。
在哈希表中查找的过程与建立哈希表的过程相似,首先计算 h(key)的值,以该值为地址到基本区域中去查找。如果该地址对应的空间未被占用,则说明查找失败,否则用该结点的关键码值与要找的key比较,如果相等则检索成功,否则要继续用函数I 计算I(h(key))的值,……。如此反复到某步或者求出的某地址空间未被占用(查找失败)或者比较相等(查找成功)为止。 三、基本概念和简单实现 1、两个集合:U是所有可能出现的关键字集合;K是实际存储的关键字集合。 2、函数h将U映射到表T[0..m-1]的下标上,可以表示成h:U→{0,1,2,...,m-1},通常称h为“哈希函数(Hash Function)”,其作用是压缩待处理的下标范围,使待处理的|U|个值减少到m 个值,从而降低空间开销(注:|U|表示U中关键字的个数,下同)。 3、将结点按其关键字的散列地址存储到哈希表(散列表)中的过程称为“散列(Hashing)”。方法称为“散列法”。 4、h(Ki)(Ki∈U)是关键字为Ki的结点的“存储地址”,亦称散列值、散列地址、哈希地址。 5、用散列法存储的线性表称为“哈希表(Hash Table)”,又称散列表。图中T即为哈希表。在散列表里可以对结点进行快速检索(查找)。
基于哈希表的词频统计
本例可执行文件下载: 下载 本案例知识要点 ●链表的使用 ●文件操作 ●哈希表的使用 ●快速排序法 ●类的设计和使用 一、案例需求 1.案例描述 词频统计就是统计一个句子或一篇文章中各种词出现的频率,它是中文信息处理的一项基本技术,在很多领域都有重要的应用。比如在中文搜索引擎(如:google,baidu)中,除去特别常用的词,一篇文章中出现频率较高的词通常能反映这篇文章的主题,因此可以使用词频来对中文文章进行文本聚类。本案例实现按词表对文章中的词语进行分析,并按字典序给出词表中各词语在文章中出现的频数。 2.案例效果图 (1)案例需要一个待统计文本文件,效果图如图20-3、20-4所示。 图20-1待统计文本文件内容 (2)本案例需一个词表文件,效果图如图20-2所示。 图20-2词表文件内容 (3)本案例最终统计出每个词在文本中出现的次数。运行结果如图20-3所示。
图20-3运行结果 (3)本案例最终统计出的结果保存在out.txt中。效果图如图20-4所示。 图20-4运行结果文件内容 3.功能说明 (1)本案例需要一个文本和一个词表,统计出每个词在文本中出现的次数。统计的原则包括以下两种: ●交集型:如“内存在涨价”,需要统计“内存”和“存在”(假设这两个词都在词 表中)。 ●组合型:如“中美关系在发展”,需要统计“中美”、“关系”和“中美关系”(假 设这三个词都在词表中)。 (2)文本和词表的格式是: 输入文本是一个长句,句中只包含汉字,不包含数字、标点、空格、回车以及其它任何特殊符号。文本规模小于等于50,000汉字。 输入词表的规模小于等于100,000个词,所有词不重复,词在2~7个汉字之间,每个词占一行。 (3)实现基于词表的词频统计,从磁盘中读取词表和文本,将词频统计结果输出到磁盘中,输出结果要求按字典序排序,并计算出程序运行时间。 二、案例分析 首先分析选取哪种数据结构,以达到高速搜索的目的。具备搜索功能的数据结构很多,如线性表、平衡树、哈希表等,当数据量庞大时,使用哈希表最合适。哈希表的概念在案例“哈希表的演示”已经做了介绍。 根据需要构造一个哈希表类,在类中实现如下操作: ●建立哈希表将词表在内存中存储起来,这个存储的过程就是类的构造函数。案例中的词表是数量较大的词组,词与词之间用空格隔开。因此可用文件流函数getline来实现。每次调用getline函数便得到一个存有词的字符串,然后将字符串按照某种散列函数插入到哈希表中,一直到词表全部存储为止。 ●统计词频:从词表中读取文本文件,存储在一个字符串里,因为每个汉字存储在两个字节里,所以词在4~14个字节之间,用char word[15]即可表示一个词。考虑到词频统计的交集性和组合性原则,可对在文本字符串中的每个汉字与其后的汉字分别组成2~7个汉字的词,在词表中进行搜索,每被搜到一次,次数加1。循环直到文本末尾。