交通量时间序列ARIMA预测技术研究_裴武

作者简介:1)裴 武,男,1982年11月出生,在读硕士研究
生,410076,湖南省长沙理工大学云塘校区至诚轩3栋A315
收稿日期:2008-07-29
○问题探讨
交通量时间序列ARIMA 预测技术研究
裴 武,陈 凤,程立勤
(长沙理工大学交通运输工程学院,湖南长沙,410076)
摘 要:实时准确的交通流量预测是智能运输系统实现的前提和关键。随着预测时间间隔的
进一步缩短,交通流量的不确定性越来越强。作为时域分析方法之一的ARIMA 模型,以其理论基础扎实、操作步骤规范、分析结果易于解释的优点,成为时间序列分析的主流方法。文章结合SPSS 软件对该预测技术进行研究,并利用某高速公路交通量调查序列进行实证分析。
关键词:交通量;ARIMA ;SPSS ;预测
中图分类号:U491.1+
4 文献标识码:A 文章编号:1004-6429(2009)01-0075-03
出于交通实时控制系统的需要,人们在六、七十年代开始
把在其他领域应用成熟的预测模型用于短时交通流量预测领域,据文献报道至今已提出了近30种预测方法。较早期的预测方法主要有自回归滑动平均模型(ARMA )、自回归模型(AR )、滑动平均模型(MA )和历史平均模型(HA )等等。这些线性预测模型考虑因素都较为简单,参数一般都用最小二乘法(LS )在线估计,具有(相对而言)计算简便,易于实时更新数据,便于大规模应用的优点;但是由于这些模型未能反映交通流过程的不确定性与非线性,无法克服随机干扰因素对交通流量的影响,所以随着预测时间间隔的缩短,这些模型的预测精度就会变得很差。于是又提出了一种改良的具有变型参数λ的回归分析模型(又称Box -Cox 法),但并未从根本上解决问题。为了适应短时交通流量变化的非线性特点,人们又提出了一批更复杂的、精度更高的预测方法。包括多元回归模型、ARIMA 模型、自适应权重联合模型、Kalman 滤波模型、基准函数-指数平滑模型、UTCS -2(3)模型以及由这些模型构成的各种组合预测模型及非参数回归、KARIMA 算法、谱分析法、状态空间重构模型、小波网络、基于多维分形的方法、基于小波分解与重构的方法和多种与神经网络相关的复合预测模型等。
作为时域分析方法之一的AR MA 模型,主要是从序列自相关的角度揭示时间序列的发展规律。相对于谱分析方法,它具有理论基础扎实、操作步骤规范、分析结果易于解释的优点。目前它已广泛应用于自然科学和社会科学的各个领域,成为时间序列分析的主流方法。1 ARM A 模型预测方法
ARMA 模型的一般形式是:
AR MA (p ,q ):φ(B )x t =θ(B )a t (1)
其中,φ(B )、θ(B )是算子表达式:
φ(B )=I -φ1B -φ2B 2-…-φP B
P
(2)θ(B )=I -θ1B -θ2B 2-…-θq B
q (3)
B 是线性推移算子,B k y t =y t -k ;x t 为平稳随机序列;a t 为
有色噪声干扰项;p ,q 分别为自回归系数和滑动平均系数;
AR (p ):模型形式与式(1)相同,但θ(B )中的θ1,θ2…,θq 均为零;M A (q ):模型形式与式(1)相同,但φ(B )中的φ1,φ2…,φq 均为零。
将这种模型应用到交通流量预测问题上,实际上是把v i (t )序列看成平稳随机序列,应用时根据对预测因子选择的不同,将变量具体化即可。例如(1)式中的x t 可以是v i (t )
。
图1 AR IMA 建模步骤
2 交通量调查序列ARIMA 建模与求解2.1 AR MA 模型与ARIMA 模型
对于AR (p )模型,如果U t 不是白噪声,而是表现为MA (q )的形式,则是ARMA (p ,q )模型,即 (B )Z t =θ(B )U t 。运用AR MA 模型的前提条件是,用作预测的时间序列已经是由一个零均数的平稳随机过程产生的。反映在图形上就是所有的样本点都围绕某一水平直线上下随机波动。所以对于某些不稳定的序列必须经过差分变换。经过差分变换后的序列再应用ARMA 模型,习惯上称为ARIMA (Autoregressive inte -grated moving average models )模型———求和自回归—移动平均模
·
75·
型。记作 (B )W t =θ(B )U t ,如果是d 阶差分,其中W t 是Z t 的d 阶差分,记作ARIMA (p ,d ,q ),这时模型需要对p ,d ,q 定阶,而且需要对θ, 做出估计。AR (p )和MA (q )模型实际上是ARIMA 的特殊情况。2.2 ARIMA 标准建模步骤
1)序列的平稳性检验(stationarity ):使原序列满足AR MA 模型平稳可逆的要求。
2)模型识别(identification ):主要是通过读ACF 、PACF 和CCF 把握模型的大致方向,为目标序列定阶,提供几个粗模型以便进一步分析完善。其中:ACF 、PAC F 分别为样本自相关系数和样本偏自相关系数,CCF 为多序列之间的互相关系数。
3)参数估计和模型诊断(estimation and diagnostic ):参数估计是对识别阶段提供的粗模型参数估计并假设检验,做模型的诊断。
4)预测(forecasting ):这是模型实际应用价值的体现。
假如某个观察值序列通过序列预处理,可以判定为平稳非白噪声序列,我们就可以利用模型对该序列建模。建模的基本步骤如图1所示。
3 交通量数据ARIMA 实例分析
本文结合SPSS 软件对江西省某高速公路一天24h 观测的每分钟交通量进行ARIMA 分析。
由交通量时序图、ACF 图及PACF 图的特征得:
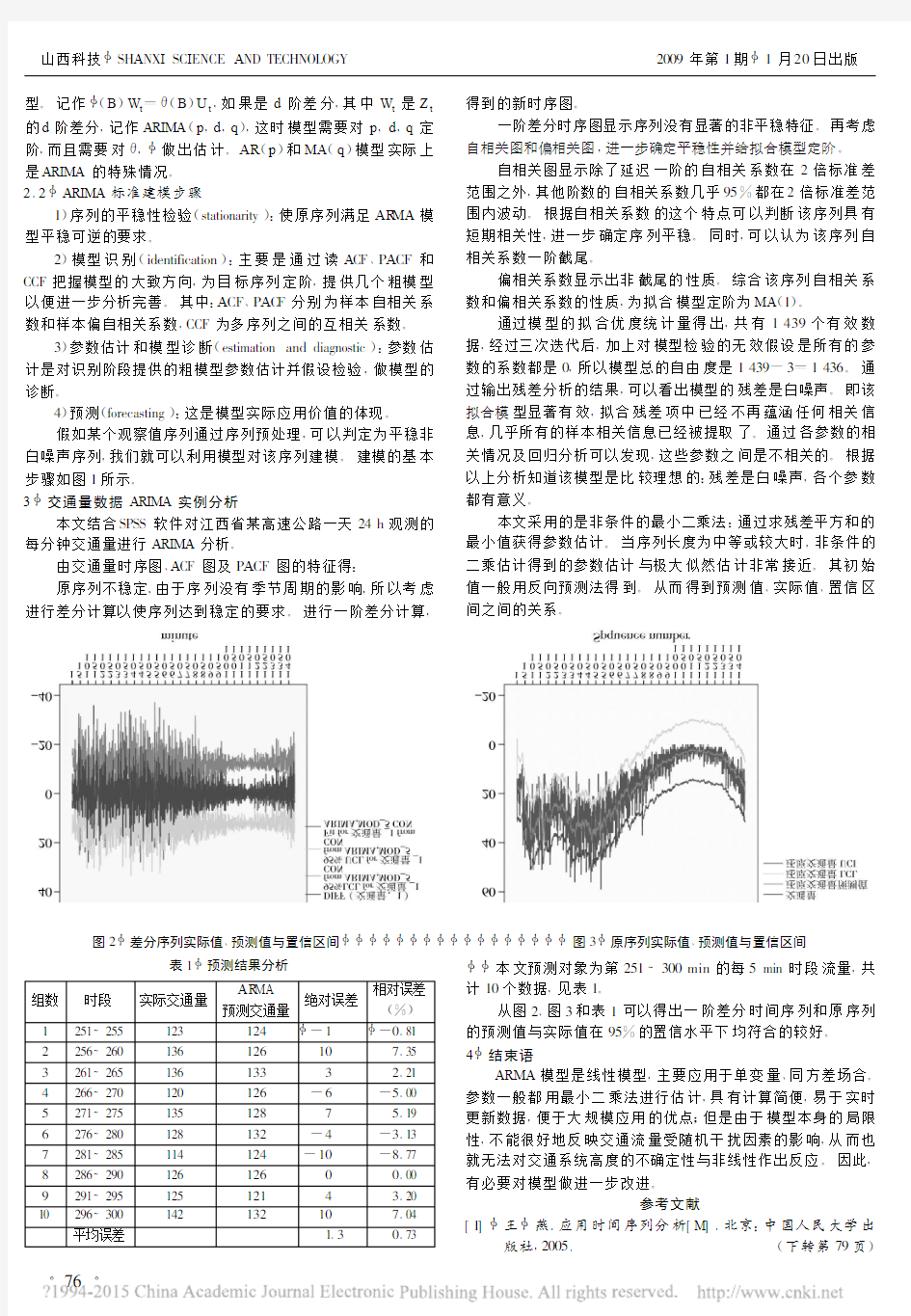
原序列不稳定,由于序列没有季节周期的影响,所以考虑进行差分计算以使序列达到稳定的要求。进行一阶差分计算,
得到的新时序图。
一阶差分时序图显示序列没有显著的非平稳特征。再考虑自相关图和偏相关图,进一步确定平稳性并给拟合模型定阶。
自相关图显示除了延迟一阶的自相关系数在2倍标准差范围之外,其他阶数的自相关系数几乎95%都在2倍标准差范围内波动。根据自相关系数的这个特点可以判断该序列具有短期相关性,进一步确定序列平稳。同时,可以认为该序列自相关系数一阶截尾。
偏相关系数显示出非截尾的性质。综合该序列自相关系数和偏相关系数的性质,为拟合模型定阶为MA (1)。
通过模型的拟合优度统计量得出,共有1439个有效数据,经过三次迭代后,加上对模型检验的无效假设是所有的参数的系数都是0,所以模型总的自由度是1439-3=1436。通过输出残差分析的结果,可以看出模型的残差是白噪声。即该拟合模型显著有效,拟合残差项中已经不再蕴涵任何相关信息,几乎所有的样本相关信息已经被提取了。通过各参数的相关情况及回归分析可以发现,这些参数之间是不相关的。根据以上分析知道该模型是比较理想的:残差是白噪声,各个参数都有意义。
本文采用的是非条件的最小二乘法:通过求残差平方和的最小值获得参数估计。当序列长度为中等或较大时,非条件的二乘估计得到的参数估计与极大似然估计非常接近。其初始值一般用反向预测法得到。从而得到预测值、实际值、置信区间之间的关系
。
图2 差分序列实际值、预测值与置信区间 图3 原序列实际值、预测值与置信区间
表1 预测结果分析
组数时段实际交通量
AR MA 预测交通量
绝对误差相对误差(%)1251~255123124 -1 -0.81
2256~260136126107.353261~26513613332.214266~270120126-6-5.005271~27513512875.196276~280128132-4-3.137281~285114124-10-8.778286~29012612600.009291~29512512143.20
10
296~300142
132
107.04平均误差
1.3
0.73
本文预测对象为第251~300min 的每5min 时段流量,共
计10个数据,见表1。
从图2、图3和表1可以得出一阶差分时间序列和原序列的预测值与实际值在95%的置信水平下均符合的较好。4 结束语
ARMA 模型是线性模型,主要应用于单变量、同方差场合。参数一般都用最小二乘法进行估计,具有计算简便,易于实时更新数据,便于大规模应用的优点;但是由于模型本身的局限性,不能很好地反映交通流量受随机干扰因素的影响,从而也就无法对交通系统高度的不确定性与非线性作出反应。因此,有必要对模型做进一步改进。
参考文献
[1] 王 燕.应用时间序列分析[M ].北京:中国人民大学出
版社,2005.(下转第79页)
·
76·
要有两种,根据客流需求划分和利用现有的大型公交设施确定控制点。
2)分区布线。所谓“分区布线”指的是在一般公交线路规划布设原则上,只在单个服务区内布设。根据对我国城市化发展进程和趋势的分析,发现我国城市化发展极有可能形成两种模式,即大城市和特大城市多中心的城市结构模式和中等城市群分散组团式城市结构模式。我们可以把整个城市分成多个服务区后,把每个服务区首先看作几个独立的“城市”,快速干线公交是联系这些“城市”的“快速火车”,一般公交线路的布设问题就成了在多个规模适中的“城市”内进行公交规划的问题。
3)最终线网形成。所谓“酌实补充、线网形成”指的是形成最终线网之前要考虑分级、分区的优化行为是不可能同时将所有的因素完全考虑进去的,此刻形成的公交线网难免还会存在公交空白区。对此,应该根据实际情况进行补充调整,具体的工作程序将已进行服务分区的城市还原为最初的交通分区状态对整个城市的公交矩阵进行调整,消除已设公交线路的影响对修正后仍满足公交设线要求的交通小区之间进行公交线路布设,此时得到的公交线路往往是跨服务区的继续修正公交乘客矩阵,直至不再产生设线要求为止。
2.5 线网设计中所需注意的问题
1)线路走向要与主要客流方向一致,使线路直捷。
2)线路规划要使乘客在市区活动时,尽量少换乘,多数人能直接到达目的地。
3)使整条线路的客流量较均衡,对经常出现客流量变化较大的线路要予以调整。
4)线路的运载能力应与客流量相适应,必要时可选择不同的交通方式或工具。
5)线路行车要尽量少受道路干扰,确保行车准点,树立公交信誉。
3 结论
快速公交系统作为一种新兴的交通方式,是发展大、中容量快速客运的一种新选择,也是实施公交优先的有效途径之一,科学规划BRT,除了规划BRT的线网之外,还需进一步系统综合地研究和探讨BRT其他方面。
参考文献
[1] 王 炜,等.城市公共交通系统规划方法与管理技术
[M].北京:科学出版社,2002.
[2] 陆锡明,王 祥,朱 洪,等.综合交通规划[M].上海:同
济大学出版社,2003.
[3] 王 炜,徐吉谦,杨 涛,等.城市交通规划理论及其应用
[M].南京:东南大学出版社,1998.
[4] 彭庆艳.大城市轨道交通线网规划方案研究[D].上海:
同济大学,2002.
[5] 陈爱萍.快速公交的基本问题研究[D].西安:长安大学,
2004.
Research into the Network Planning of Bus Rapid Transit
Zhu Xiaoguo,Ma Jiangshan
ABSTRACT:The paper briefly introduces the concept,content and design principles of the BRT network,analyzes the influencing factors of the structure and scale,proposes the principle of s ystems engineering,in which the qualitative and quantitative methods are combined to plan the urban BRT network and explains the procedures and things needin g attention in the design.
KEYW ORDS:BRT;net work planning;illustration;model method
(上接第76页)
[2] 贺国光,马寿锋,李 宇.基于数学模型的短时交通流预
测方法探讨[J].系统工程理论与实践,2000(12).[3] 张文彤.SPSS11统计分析教程[M].北京:北京希望电子
出版社,2002.
Research of ARIMA Forecasting Technology for Traffic Volume Time Series
Pei Wu,Chen Feng,Cheng Liqin
ABSTRACT:Real-time and exact prediction of short-term traffic flow volu me is the precondition and key point to ITS system.And the uncertainty of traffic volume may become increasingly stronger along with the shortening of forecasting intervals.Being a model of time domain anal-ysis method,ARIMA has the advantages of solid theoretical basis,standard operation steps,analysis results easily explained,and has become the mainstream method of the anal ysis of time series.The article studies the forecasting technology with the help of the sofeware of SPSS,and an exam-ple analysis of a highway traffic volume survey series is given in the end.
KEYW ORDS:traffic volume;ARIMA;SPSS;forecasting
·
79
·朱小郭,等:快速公交的线网规划研究2009年第1期 1月20日出版
关于解决城市交通堵塞问题的数学模型的探究
城市交通拥阻的分析与治理 摘要 随着经济的高速发展和城市化进程的加快,机动车拥有量急剧增加。城市道路交通拥堵问题成为困扰世界各大城市的主要社会问题之一,严重影响着城市的可持续发展和人们的日常工作与生活。快速、准确地发现路网中发生的交通拥堵,并估计出拥挤在未来一段时间内的扩散范围和持续时间,对于制定合理有效的交通拥挤疏导策略具有重要意义。 本文通过调查洛阳市中州中路与定鼎路交叉口车流量与红绿灯的设置等情况,发现此路口南北方向的车辆主要是由关林与洛阳站方向的往返车辆,东西方向的车辆主要是由中央百货大楼与老城方向的往返车辆,且南北方向的车流量大于东西方向的车流量。 模型一,通过我们的调查发现,造成此路口交通拥堵的原因之一是黄灯时间较短,黄灯时间只有3秒,这样会造成有些车辆因来不及停车而越过十字路口的停车线, 又由于红灯亮了而过不了路口, 故而造成交通混乱。针对此问题,我们在力学与动力学原理的基础上,提出一种调整黄灯时间的模型,利用微分方程列出黄灯时间的求解公式,并计算出黄灯闪亮的最佳时间为7秒。 模型二,道路的增长速度跟不上车辆增长速度,这就导致了车辆静止平均密度逐年增大,结果花费了大量人力物力财力修路架桥,但换来的不是交通顺畅,而是越来越严重的交通拥挤。针对此现象,我们以交通工具为研究对象,运用线性规划方法并结合LINGO软件,得出人们出行选用自行车和大型机动车有利于缓解当前交通拥堵现象。 模型三,为了使交通部门有充分的时间来预防交通拥堵,应该在交通流高峰到来之前做出预测, 进而采取及时的措施并通过交通控制系统削减交通流高峰、避免拥堵的发生,我们采用径向基函数预测功能的神经网络[5],对十字路口的车流量进行实时预测,应用MATLAB软件编程[4]预测出交通高峰期可能通过每个路口的车流量,从而可以给交通部门提供数据,让他们有更充分的时间预防交通拥堵的发生。 关键词:微分方程;线性规划;神经网络; LINGO; MATLAB
基于ARIMA模型下的时间序列分析与预测
龙源期刊网 https://www.360docs.net/doc/fa5232316.html, 基于ARIMA模型下的时间序列分析与预测 作者:万艳苹 来源:《金融经济·学术版》2008年第09期 摘要:大多数的时间序列存在着惯性,或者说具有迟缓性。通过对这种惯性的分析,可以由时间序列的当前值对其未来值进行估计。本文以1949年到2004年江苏省社会消费品零售总额数据为研究对象,将这些数据平稳化并做分析,发现ARIMA(1,1,2)模型能比较好的对江苏省社会消费品零售总额进行市时间序列分析和预测,。 关键词:ARIMA;江苏省消费品零售总额;时间序列分析 一、引言 江苏省是一个经济大省,经济一直保持平稳较快增长,城乡居民收入都位于全国前茅,消费品需求旺盛,人们生活水平比较高。其中社会消费品零售总额是反映人民生活水平提高的一个很好的指标。所以对社会消费品零售总额做分析就比较重要。但是影响社会消费品零售总额的因素有很多,包括收入、住房、医疗、教育以及人们的预期等很多因素,而且这些因素之间又保持着错综复杂的联系。因此运用数理经济模型来分析和预测较为困难。所以本文采用ARIMA模型对江苏省的社会消费品零售总额进行分析,得出其规律性,并预测其未来值。 二、ARIMA模型的说明和构建 ARIMA模型又称为博克斯-詹金斯模型。ARIMA模型是由三个过程组成:自回归过程(AR(p));单整(I(d));移动平均过程(MA(q))。AR(p)即自回归过程,是指一个过程的当前值是过去值的线性函数。如:如果当前观测值仅与上期(滞后一期)的观测值有显著的线性函数关系,则我们就说这是一阶自回归过程,记作AR(1)。推广之,如果当前值与滞后p期的观测值都有线性关系则称p阶自回归过程,记作AR(p)。MA(q),即移动平均过程,是指模型值可以表示为过去残差项(即过去的模型拟合值与过去观测值的差)的线性函数。如:MA(1)过程,说明时间序列受到滞后一期残差项的影响。推广之,MA(q)是指时间序列受到滞后q期残差项的
交通拥堵解决方案
交通拥堵解决方案设计 2013年5月21日
目录 一、拥堵判断 (3) 1. 视频内容分析 (3) 2. 车速大小分析 (3) 3. GPS 信息分析 (3) 4. 交通事故报警 (4) 二、应用过程 (4) 1. 预案联动 (4) 2. 信息传递 (4) 三、交通疏导 (5) 1. 交通诱导牌 (5) 2. 红绿信号灯 (5) 3. 现场交警协助 (6) 4. 视频分析 (6) 5. 拥堵预测 (6) 四、事后处理 (7) 1. 拥堵解除 (7) 2. 应急宣传 (7) 3. 梳理流程 (7)
一、拥堵判断 1.视频内容分析 视频监控是实时查看交通状况的最好方式,直观呈现道路拥堵情况,基于视频图像智能应用,可以部署200万像素红外高清摄像机,在高清摄像机视频图像中,按照道路范围进行规制划定,根据视频区域内车辆密度,采用视频算法进行智能分析,在3个红绿灯后,仍无密度无明显变化,则产生拥堵告警,向应用平台发送拥堵告警消息。 2.车速大小分析 车速检测由环形速度检测器检测,在路段下铺设检测器,捕捉通过该路段车速大小,依据车速大于该路段的平均车速,则该路段空旷,车速接近平均车速,则属于正常,车速小于平均车速,则可以显示为拥堵,而拥堵产生后,及时向应用平台发送拥堵告警信息。 3.GPS 信息分析 GPS信息获取从出租车,公交车上获取,获取GPS车辆所在地点,当时速度信息,当该路段GPS信号大量聚集,越来越密集,且 GPS显示车辆长时间移动缓慢,正常速度下3个红绿灯未能明显变化,则判断为拥堵。
4.交通事故报警 发生车辆事故,由事故和事故发生现场勘查,引起街道拥堵,求助者电话判断拥堵。 二、应用过程 1.预案联动 2.1.1.指挥中心值班客户端接收视频报警信息,同时间多 个路段发生拥堵报警,依照报警时间,对报警摄像头按照报警 时间先后分组,形成路段拥堵报警列表。 2.1.2.报警列表中,每行信息按照报警摄像头名称,时间, 该路段平均车速,GPS车辆GPS信息,所属管辖片区,片区负 责人信息和联系方式形成。 2.1.3.获取报警摄像头所在路段就近摄像头,分析视频内 容。 2.1.4.调阅实时视频内容,查看路面车辆通行情况,检测 该路段车速信息,gps数量信息,3个红绿灯无明显变化则初 步确认为拥堵路段。 2.1.5.拥堵路段信息上报值班领导,由领导确认,然后向 外界发布该路段为拥堵的信息。 2.信息传递 2.2.1.指挥中心值班客户端地图上调看警力部署图,对已
时间序列预测模型
时间序列预测模型时间序列是指把某一变量在不同时间上的数值按时间先后顺序排列起来所形成的序列,它的时间单位可以是分、时、日、周、旬、月、季、年等。时间序列模型就是利用时间序列建立的数学模型,它主要被用来对未来进行短期预测,属于趋势预测法。一、简单一次移动平均预测法例1.某企业1月~11月的销售收入时间序列如下表所示.取n 4,试用简单一次移动平均法预测第12月的销售收入,并计算预测的标准误差. 二、加权一次移动平均预测法简单一次移动平均预测法,是把参与平均的数据在预测中所起的作用同等对待,但参与平均的各期数据所起的作用往往是不同的。为此,需要采用加权移动平均法进行预测,加权一次移动平均预测法是其中比较简单的一种。三、指数平滑预测法 1、一次指数平滑预测法一元线性回归模型 * 项数n的数值,要根据时间序列的特点而定,不宜过大或过小.n过大会降低移动平均数的敏感性,影响预测的准确性;n过小,移动平均数易受随机变动的影响,难以反映实际趋势.一般取n的大小能包含季节变动和周期变动的时期为好,这样可消除它们的影响.对于没有季节变动和周期变动的时间序列,项数n的取值可取较大的数;如果历史数据的类型呈上升或下降型的发展趋势,则项数n的数值应取较小的数,这样能取得较好的预测效果. 1102.7 1015.1 963.9 892.7 816.4 772.0 705.1 649.8 606.9 574.6 533.8 销售收入 11 10 9 8 7 6 5 4 3 2 1 月份 t 158542.7 993.6 12 12950.4 19016.4 17662.4 24617.6 27989.3
时间序列分析方法及应用7
青海民族大学 毕业论文 论文题目:时间序列分析方法及应用—以青海省GDP 增长为例研究 学生姓名:学号: 指导教师:职称: 院系:数学与统计学院 专业班级:统计学 二○一五年月日
时间序列分析方法及应用——以青海省GDP增长为例研究 摘要: 人们的一切活动,其根本目的无不在于认识和改造世界,让自己的生活过得更理想。时间序列是指同一空间、不同时间点上某一现象的相同统计指标的不同数值,按时间先后顺序形成的一组动态序列。时间序列分析则是指通过时间序列的历史数据,揭示现象随时间变化的规律,并基于这种规律,对未来此现象做较为有效的延伸及预测。时间序列分析不仅可以从数量上揭示某一现象的发展变化规律或从动态的角度刻画某一现象与其他现象之间的内在数量关系及其变化规律性,达到认识客观世界的目的。而且运用时间序列模型还可以预测和控制现象的未来行为,由于时间序列数据之间的相关关系(即历史数据对未来的发展有一定的影响),修正或重新设计系统以达到利用和改造客观的目的。从统计学的内容来看,统计所研究和处理的是一批有“实际背景”的数据,尽管数据的背景和类型各不相同,但从数据的形成来看,无非是横截面数据和纵截面数据两类。本论文主要研究纵截面数据,它反映的是现象以及现象之间的关系发展变化规律性。在取得一组观测数据之后,首先要判断它的平稳性,通过平稳性检验,可以把时间序列分为平稳序列和非平稳序列两大类。主要采用的统计方法是时间序列分析,主要运用的数学软件为Eviews软件。大学四年在青海省上学,基于此,对青海省的GDP十分关注。本论文关于对1978年到2014年以来的中国的青海省GDP(总共37个数据)进行时间序列分析,并且对未来的三年中国的青海省GDP进行较为有效的预测。希望对青海省的发展有所贡献。 关键词: 青海省GDP 时间序列白噪声预测
实验三:ARIMA模型建模与预测实验报告
课程论文 (2016 / 2017学年第 1 学期) 课程名称应用时间序列分析 指导单位经济学院 指导教师易莹莹 学生姓名班级学号 学院(系) 经济学院专业经济统计学
实验三ARIMA 模型建模与预测实验指导 一、实验目的: 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念: 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验任务: 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验要求: 实验过程描述(包括变量定义、分析过程、分析结果及其解释、实验过程遇到的问题及体会)。 实验题:对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。
时间序列分析基于R——习题答案
第一章习题答案 略 第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 2.2 (1)非平稳,时序图如下 (2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
2.3 (1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2)平稳序列 (3)白噪声序列 2.4 ,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。显著性水平=0.05 不能视为纯随机序列。 2.5 (1)时序图与样本自相关图如下
(2) 非平稳 (3)非纯随机 2.6 (1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机 第三章习题答案 3.1 ()0t E x =,2 1 () 1.9610.7 t Var x ==-,220.70.49ρ==,220φ= 3.2 1715φ=,2115 φ= 3.3 ()0t E x =,10.15 () 1.98(10.15)(10.80.15)(10.80.15) t Var x += =--+++ 10.8 0.7010.15 ρ= =+,210.80.150.41ρρ=-=,3210.80.150.22ρρρ=-= 1110.70φρ==,2220.15φφ==-,330φ= 3.4 10c -<<, 1121,1,2 k k k c c k ρρρρ--?=? -??=+≥? 3.5 证明: 该序列的特征方程为:32 --c 0c λλλ+=,解该特征方程得三个特征根: 11λ=,2c λ=3c λ=-
实验十时间序列模型
实验十时间序列模型 实验目的 掌握时间序列的基本理论,时间序列模型种类的识别、估计、诊断和预测方法,以及相应的EViews软件操作方法。 实验原理 时间序列分析方法由Box-Jenkins (1976) 年提出。它适用于各种领域的时间序列分析。 时间序列模型不同于经济计量模型的两个特点是: (1)这种建模方法不以经济理论为依据,而是依据变量自身的变化规律,利用外推机制描述时间序列的变化。 (2)明确考虑时间序列的非平稳性。如果时间序列非平稳,建立模型之前应先通过差分把它变换成平稳的时间序列,再考虑建模问题。 时间序列模型的应用: (1)研究时间序列本身的变化规律(建立何种结构模型,有无确定性趋势,有无单位根,有无季节性成分,估计参数)。 (2)在回归模型中的应用(预测回归模型中解释变量的值)。 (3)时间序列模型是非经典计量经济学的基础之一(不懂时间序列模型学不好非经典计量经济学)。 实验内容 建立中国人口时间序列模型。 表给出了中国人口数据y t(1952-2004,单位万人),试建立y t的时间序列模型,并预测2005年中国人口总数。 表
建模步骤 10.4.1 识别模型 利用表数据建立y t序列图,如图。 图中国人口序列(1952-2004) 从人口序列图可以看出我国人口总水平除在1960和1961两年出现回落外,其余年份基本上保持线性增长趋势。 察看序列的相关图,在序列窗口选择View/Correlogram,便会弹出如下窗口,见图,选择滞后阶数(本例输入滞后期10),点击ok,得到如图所示的序列y t的相关图和偏相关图。 图 图y t的相关图,偏相关图 由y t的相关图,偏相关图判断y t为非平稳性序列。进一步考察其差分序列Dy t,序列图见图,其相关图,偏相关图见图。 图 图Dy t的相关图,偏相关图 人口差分序列Dy t是平稳序列。应该用Dy t建立模型。因为Dy t均值非零,结合图拟建立带有漂移项的AR(1)模型。 10.4.2 估计模型 采用AR(1)模型对Dy t进行估计,从EViews主菜单中点击Quick键,选择Estimate Equation功能。随即会弹出Equation specification对话框。输入漂移项非零的AR(1)模型估计命令(C表示漂移项)如下: D(Y) C AR(1) 结果如图所示,整理如下: Dy t = + (Dy t-1–+ v t
ARIMA时间序列建模过程——原理及python实现
ARIMA时间序列建模过程——原理及python实现 ARIMA模型的全称叫做自回归查分移动平均模型,全称是(ARIMA, Autoregressive Integrated Moving Average Model),是统计模型(statistic model)中最常见的一种用来进行时间序列预测的模型,AR、MA、ARMA模型都可以看作它的特殊形式。 1. ARIMA的优缺点 优点:模型十分简单,只需要内生变量而不需要借助其他外生变量。 缺点:要求时序数据是稳定的(stationary),或者是通过差分化(differencing)后是稳定的;本质上只能捕捉线性关系,而不能捕捉非线性关系。 2. ARIMA的参数与数学形式 ARIMA模型有三个参数:p,d,q。 p--代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做 AR/Auto-Regressive项; d--代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项; q--代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项。 差分:假设y表示t时刻的Y的差分。 if d=0, yt=Yt, if d=1, yt=Yt?Yt?1, if d=2, yt=(Yt?Yt?1)?(Yt?1?Yt ?2)=Yt?2Yt?1+Yt?2 ARIMA的预测模型可以表示为: Y的预测值= 白噪音+1个或多个时刻的加权+一个或多个时刻的预测误差。 假设p,q,d已知,
ARIMA用数学形式表示为: yt?=μ+?1?yt?1+...+?p?yt?p+θ1?et?1+...+θq?et?q 其中,?表示AR的系数,θ表示MA的系数 3.Python建模 ##构建初始序列 import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm from statsmodels.graphics.tsaplots import acf,pacf,plot_acf,plot_pacf from statsmodels.tsa.arima_model import ARMA from statsmodels.tsa.arima_model import ARIMA #序列化 time_series_ = pd.Series([151.0, 188.46, 199.38, 219.75, 241.55, 262.58, 328.22, 396.26, 442.04, 517.77, 626.52, 717.08, 824.38, 913.38, 1088.39, 1325.83, 1700.92, 2109.38, 2499.77, 2856.47, 3114.02, 3229.29, 3545.39, 3880.53, 4212.82, 4757.45, 5633.24, 6590.19, 7617.47, 9333.4, 11328.92, 12961.1, 15967.61]) time_series_.index = pd.Index(sm.tsa.datetools.dates_from_range('1978','2010')) time_series_.plot(figsize=(12,8)) plt.show() 3.1 异常值及缺失值处理 异常值一般采用移动中位数方法: frompandasimportrolling_median threshold =3#指的是判定一个点为异常的阈值 df['pandas'] = rolling_median(df['u'], window=3, center=True).fillna(method='bfill').fillna(method='ffill') #df['u']是原始数据,df['pandas'] 是求移动中位数后的结果,window指的 是移动平均的窗口宽度 difference = np.abs(df['u'] - df['pandas']) outlier_idx = difference > threshold 缺失值一般是用均值代替(若连续缺失,且序列不平稳,求查分时可能出现nan) 或直接删除。
2019英语六级翻译预测及解析:交通拥堵
2019英语六级翻译预测及解析:交通拥堵 请将下面这段话翻译成英文: 交通拥堵是世界各国普遍面临的问题。近年来,我国城市化水平空前加快,大中城市交通拥堵问题尤其突出,交通阻塞已由局部向大范围蔓延。这不但影响了城市生活的效率和质量,而且带来了环境污染、能源紧张等一系列经济社会问题,严重制约了城市的发展。要想解决这个问题,良好的公共交通是必不可少的。实行低票价政策,是实现公交优先的基本保证。从长远来看,则要大力发展轨道交通(rail transportation),降低路面拥堵。 参考翻译 Traffic jam has been a problem shared by all countries around the world.In recent years,the urbanization of China reaches an unprecedented level,which leads to especially prominent traffic jam in large and medium-sized cities.The problem of traffic jam has extended from part to a wide range.Traffic jam not only affects the efficiency and quality of uiban life,but also causes a series of economic and social problems like environmental pollution and energy deficiency,which greatly restricts the development of cities.To solve the problem,well-organized public transportation is indispensable.Low ticket price is the basic guarantee of priority of public transportation.In the long term,we must vigorously develop rail transportation to lessen traffic jam. 参考翻译
时间序列分析基于R——习题答案
第一章习题答案 第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 Au+ocorreliil. i ons Correlation -1 M 7 6 5 4 3 2 1 0 I ; 3 4 5 6 7 9 9 1 1.00000■Hi ■ K. B H,J B ik L L1■* J.1 jA1-.IM L L* rn^rp ■ i>i?iTwin H'iTiii M[lrp i,*nfr 'TirjlvTilT'1 iBrp O.7QOO0■ill. Ii ill ■ _.ill?L■ ill iL si ill .la11 ■ fall■ 1 ■ rpTirp Tp和阳申■丽轉■晒?|?卉(ft 0.41212■强:料榊<牌■ 0.14343'■讯榊* -.07078■ -.25758, WWHOHHf ■ -.375761 marks two 总t and&rd errors 2.2 (1) 非平稳,时序图如下 (2) - ( 3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
Ctorrelat ion LOOOOO n.A'7F1 0.72171 0.51252 Q,34982 0.24600 0.20309 0.?1021 0.26429 0.36433 0.49472 0.58456 0.60198 0.51841 Q ?菲晡 日 0.20671 0.0013& -,03243 -.02710 Q.01124 0,08275 0.17011 Autocorrel at ions raarka two standard errors 2.3 (1) 自相关系数为: 0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2 )平稳序列 (3) 白噪声序列 2.4 LB=4.83 , LB 统计量对应的分位点为 0.9634 , P 值为0.0363。显著性水平 :-=0.05,序列 不能视为纯随机序列。 2.5 (1) 时序图与样本自相关图如下 AuEocorreI ati ons 弗卅制iti 电卅栅冷卅樹 側樹 榊 惟 1 ■ liihCidi iliihQriHi il>LljU_nll Hnlidiili Hialli iT ,, T^,, T^s ?T* iTijTirr ,^T 1 IT * -i> ■> - ■ ■ *畑** ? ■ ■ 耶曲邯 ? ■ ■ ■ >|{和怦I {册卅KHi 笊出恸 mrpmrp 山!rpEHi erp . 卑*寧* a 1 *
时间序列分析上机操作题教学提纲
情况如6月澳大利亚季度常住人口变动(单位:千人)199320.1971年9月—年 问题:(1)判断该序列的平稳性与纯随机性。 (2)选择适当模型拟合该序列的发展。 (3)绘制该序列拟合及未来5年预测序列图。 针对问题一:将以下程序输入SAS编辑窗口,然后运行后可得图1. data example3_1; input x@@; time=_n_; ; cards55.4 50.2 49.5 67.9 55.8 63.2 53.1 61.7 45.3 48.1 49.9 55.2 42.1 30.4 59.9 49.5 33.8 30.6 36.6 44.1
45.5 32.9 28.4 35.8 37.3 29 34.2 39.5 49.8 48.8 43.9 49 47.6 37.3 47.6 39.2 48.9 60.8 65.4 65.4 51.2 67 49.6 55.1 47.3 67.6 62.5 57.3 47.9 45.5 49.1 48 44.5 48.8 60.9 51.4 55.8 59.4 60.9 51.6 60.3 71 64 62.1 58.6 64.6 75.4 83.4 79.4 59.9 80.2 55.9 59.1 21.5 69.5 65.2 58.5 62.5 33.1 62.2 60 170 35.3 -47.4 34.4 43.4 58.4 42.7 ; =example3_1; data proc gplot; 1plot x*time==star; v=join =red symbol1cI;run 该序列的时序图1 图这两个异常数据外,该时序图显示澳大-47.4和由图1可读出:除图中170附近随机波动,没有明显的趋势或周期,基60利亚季度常住人口变动一般在在本可视为平稳序列。5. 再接着输入以下程序运行后可输出五方面的信息。具体见表1-表arima data proc= example3_1;
交通流预测方法
交通流预测方法 随着社会经济和交通运输业的不断发展,交通拥挤等交通问题越来越凸现出来,成了全球共同关注的问题。那么对于交通流的预测不仅是城市交通控制与诱导的基础,还是解决道路拥堵问题的关键。如果能精确的预测交通网中各个支路上的汽车流量,那么我们可以运用规划方法对交通流进行合理的优化,从而使得道路的利用率达到最大,也可以解决部分拥堵问题。在新建道路的前期也需要对兴建道路的车流量进行一个长期的交通预测,从而对道路的经济效益进行评估,对论证道路修建的可行性研究提供依据。由此可见,对交通流的预测是必要的,在本课题中我对四公里立交车流作一个最优函数估计,旨在对四公里立交的车流进行精确预测。 交通流理论是研究交通随时间和空间变化规律的模型和方法体系。多年来交通流理论有了较快的发展,众多学者在这一研究方向做出了许多优秀的成果,将交通流理论运用于交通运输工程的许多研究领域,如交通规划、交通控制、道路与交通设施设计等。 预测方法从大体上可分为定性预测与定量预测。定性预测中主要有相关类比法、德尔菲法等;定性预测则分为因果分析、趋势分析智能模型。因果分析主要方法有线性回归、非线性回归等模型;趋势分析主要有时间序列模型、趋势回归模型等;智能模型主要包括神经网络模型和非参数回归模型。 短期交通流的预测方法较早期的有:自回归模型(AR)、滑动平均模型(MA)、自回归滑动平均模型(ARMA)、历史平均模型(HA)和Box-Cox法等,随着该领域的发展,预测方法不断趋于精确,在大批学者的共同努力下出现了许多更加复杂、精度更高的预测模型。大体来说可分为两类:一类是以数理统计和微积分等传统的数学方法为基础的预测模型,主要包括:时间序列模型、卡尔曼滤波模型、参数回归模型等;第二类是以现代科学技术和方法(如模拟技术、神经网络、模拟技术)为主要研究手段而形成的短期预测模型,该种方法不追求严格意义上的数学推导和明确的物理意义,更加重视与现实交通流量的拟合接近程度,该种方法主要包括非参数回归模型、KARIMA算法、基于小波理论的方法、谱分析和多种与神经网络相关的复合预测模型等。现阶段广泛应用的主要有以下四种模型。 历史平均模型Stepehanedes于1981年将此方法应用于城市交通控制系统中。其特点有算法简单,参数可用最小二乘法进行估计,操作简单,速度快,但其由于它是一种静态的预测方法,不能反映动态交通流基本的不确定性和非线性性,无法克服随即干扰因素的影响。 时间序列-ARIMA模型由Ahmed和Cook于1979年首次在交通领域提出。在大量连续数据的基础上,此模型没有较好的预测精度,但需要复杂的参数估计,且其对历史数据的依赖性较高,成本较高。该方法技术比较成熟,特别适用于稳定的交通流。该模型只是单纯从时间序列分析的角度进行预测,没有考虑上下游路段之间的流量关系。 神经网络模型人工神经网络诞生于20世纪40年代,Schin 于1992年用之于长期的交通预测,1993年1994年Dougherty 和Clark 分别将其应用于短期交通预测。该方法在一定程度上摆脱了建立精确数学模型的困扰,为研究工作开辟了新的思路。应用较广泛的有BP神经网络-误差反传神经网络模型、单元神经网络模型、基于谱分析的神经网络模型、高阶神经网络模型和模糊神经网络模型等方法 非参数回归模型,由Davis和Smith于1991年应用到交通预测领域,该预测方法是一种适合不确定性、非线性的动态系统的非参数建模方法。无需先验知识,只需足够的历史数据。 鉴于道路交通系统的非线性、复杂性和不确定性等特征,许多无模型的预测方法被应用到短期的交通流预测当中,且取得了良好的效果,研究发现,考虑上下游道路流量的关系的预测方法更能反映实际情况,比起单纯的时间序列预测方法更加贴合实际,有更大的发展空间。
交通预测模型【对各种交通流预测模型的简要分析】
交通预测模型【对各种交通流预测模型的简要分析】 摘要:随着社会的发展,交通事故、交通堵塞、环境污染和能源消耗等问题日趋严重。多年来,世界各国的城市交通专家提出各种不同的方法,试图缓解交通拥堵问题。交通流预测在智能交通系统中一直是一个热门的研究领域,几十年来,专家和学者们用各种方法建立了许多相对精确的预测模型。本文在提出交通流短期预测模型应具备的特性的基础上,讨论了几类主要模型的结果和精确度。 关键词:交通流预测;模型;展望 20世纪80年代,我国公路建设项目交通量预测研究尚处于探索成长阶段,交通量预测主要采用个别推算法,又可分为直接法和间接法。直接法是直接以路段交通量作为研究对象;间接法则是以运输量作为研究对象,最后转换为路段交通量。 进入90年代后,我国的公路建设项目,特别是高速公路建设项目的交通量分析预测多采用“四阶段”预测,该法以机动车出行起讫点调查为基础,包括交通量的生成、交通分布、交通方式选择和交通量分配四个阶段。
几十年来,世界各国的专家和学者利用各学科领域的方法开发出了各种预测模型用于短时交通流预测,总结起来,大概可以分为六类模型:基于统计方法的模型、动态交通分配模型、交通仿真模型、非参数回归模型、神经网络模型、基于混沌理论的模型、综合模型等。这些模型各有优缺点,下面分别进行分析与评价。 一、基于统计方法的模型 这类模型是用数理统计的方法处理交通历史数据。一般来说统计模型使用历史数据进行预测,它假设未来预测的数据与过去的数据有相同的特性。研究较早的历史平均模型方法简单,但精度较差,虽然可以在一定程度内解决不同时间、不同时段里的交通流变化问题,但静态的预测有其先天性的不足,因为它不能解决非常规和突发的交通状况。线性回归模型方法比较成熟,用于交通流预测,所需的检测设备比较简单,数量较少,而且价格低廉,但缺点也很明显,主要是适用性差、实时性不强,单纯依据预先确定的回归方程,由测得的影响交通流的因素进行预测,只适用于特定路段的特定流量范围,且不能及时修正误差。当实际情况与参数标定时的交通状态相差较远时,
基于时间序列模型的中国GDP增长预测分析
第33卷 第178期2012年7月 财经理论与实践(双月刊) THE THEORY AND PRACTICE OF FINANCE AND ECONOMICS Vol.33 No.178 Jul. 2012 ·信息与统计· 基于时间序列模型的中国GDP增长预测分析 何新易 (南通大学商学院,江苏南通 226019)* 摘 要:作为度量一个国家或地区所有常住单位在一定时期之内所生产和所提供的最终产品或服务的重要总量指标,如果能够对GDP做出正确的预测,必然可以有效引导宏观经济健康发展,为高层管理部门提供决策依据。选用适合短期预测的ARIMA模型对中国1952~2010年的GDP进行计量建模分析,预测结果认为未来五年中国的经济增长仍将处于一个水平较高的上升通道。 关键词:时间序列模型;GDP;预测 中图分类号:F234 文献标识码: A 文章编号:1003-7217(2012)04-0096-04 一、引 言 作为度量一个国家或地区所有常住单位在一定时期之内所生产和所提供的最终产品或服务的重要总量指标,国内生产总值(Gross Domestic Product,GDP)对于判断经济态势运行、衡量经济综合实力、正确制定经济政策等诸多方面,以及在经济研究实际工作中,均起着不可替代的重要作用。 熊志斌(2011)深入分析了时间序列模型与神经网络(NN)模型的优势和劣势,按照两种模型的预测特性,在比较的基础之上,分别构建了ARIMA模型和NN模型,并根据一定算法对两种模型进行了集成。将GDP时间序列的数据结构,根据在非线性空间和线性空间的预测优势,进一步分解为线性非线性残差和自相关主体两部分,即首先用ARIMA分析技术构建线性主体模型,然后用NN模型估计非线性残差,再对序列的整个预测结果进行最终集成。仿真实证结果表明:与单一模型相比,集成模型的预测准确率显著提高,进行GDP预测当然使用集成模型更为有效[1]。桂文林和韩兆洲(2011)认为由于迄今为止,包括季度GDP在内的经季节调整之后的经济数据,中国政府尚未进行公布,不但无法进行国际之间的横向比较,也不利于监测中国宏观经济态势。本文运用1996年第1季度至2009年第4季度的中国实际GDP数据,构建了状态空间模型,使用卡尔曼滤波迭代算法对季节调整模型状态向量的 各分量,进行了最优平滑、预测和估计,并使用极大似然方法估计了超参数。经过对GDP的主要季节和趋势特征的分析,计算出了环比增长率指标来监测和分析经济走势,并与国际通用的TRAMO-SEATS季节调整模型进行了对比,以便鉴别趋势拐点,制定相关的经济政策[2]。高帆(2010)运用1952~2008年的上海GDP增长率数据,实证研究其内在变动机制,将GDP增长率分解为纯生产率效应、纯劳动投入效应、纯生产结构效应、纯劳动结构效应,并分析了这四种效应之间的交互影响。结果表明:在上海GDP增长率提高的四种效应之中,纯生产率效应起到了关键作用。上海GDP增长率自1978年改革开放之后,在整体上对纯生产率效应的依赖度趋于增强。在1978~1989年期间,纯劳动结构效应是GDP增长的主要因素,由于市场化改革的进一步加大,劳动力跨部门流转在很大程度上得以实现。在1990~2008年期间,纯生产率效应是GDP增长的主要因素,正是由于在此历史阶段,由于资本深化进一步加速,从而有效提高了部门劳动生产率。基于实证的研究结论,可以针对性地制定出今后上海市经济实现持续增长的若干宏观政策[3]。腾格尔和何跃(2010)利用中国季度GDP数据分别构建了ARIMA和ARCH模型,同时利用GMDH自组织方法尝试建模,经过Bon-ferroni-Dunn检验,表明与单一模型相比,组合模型的拟合能力更强。研究表明,基于GMDH组合的GDP模 *收稿日期: 2012-02-12 作者简介: 何新易(1966—),男,湖北武汉人,南通大学商学院副教授,经济学博士,研究方向:宏观国民经济问题、中国企业集团融资和投资。
基于时间序列序列分析优秀论文
梧州学院 论文题目基于时间序列分析梧州市财政 收入研究 系别数理系 专业信息与计算科学 班级 09信息与计算科学 学号 200901106034 学生姓名胡莲珍 指导老师覃桂江 完成时间
摘要 梧州市财政收入主要来源于基金收入,地方税收收入和非税收收入等几方面。近年来梧州市在自治区党委、自治区政府和市委的正确领导下,全市广大干部群众深入贯彻落实科学发展观,抢抓机遇,开拓进取,克难攻坚,使得全市经济连续几年快速发展,全市人民的生活水平也大幅度提高,但伴随着发展的同时也存在一些问题,本文主要通过研究分析梧州财政收入近几年的状况,根据采用时间序列分析中的一次简单滑动平均法研究分析梧州市财政收入和支出的情况,得到的结果是梧州市财政收入呈现下降状态,而财政支出却逐年上涨,这种状况将导致梧州市人民生活水平下降,影响梧州市各方面的发展。给予一些有益于梧州市财政发展的建议。本文首先介绍主要运用的时间序列分析的概念及其一次简单滑动平均法的方法,再用图表说明了梧州市财政近几年的财政收入和支出状况,然后建立模型,分析由时间序列分析方法得出的对2012年财政收入状况的预测结果,最后,鉴于提高梧州市财政收入的思想,给予了一些合理性建议,比如:积极实施工业强县战略,壮大工业主导财源;大力发展第三产业,强化地方财源建设;完善公共财政支出机制,着力构建和谐社会。 关键词:梧州市;财政收入;时间序列分析;建立模型;建议
Based onThe Time Series Analysis of Wuzhou city Finance Income Studies Abstract Wuzhou city, fiscal revenue mainly comes from fund income, local tax revenue and the tax revenue etc. Wuzhou city in recent years in the autonomous region party committee, the government of the autonomous region and the municipal party committee under the correct leadership, the cadres and masses thoroughly apply the scientific outlook on development, catch every opportunity, pioneering and enterprising, g hard, make the crucial economic rapid development for several years, the people's living standard has also increased significantly, but with the development at the same time, there are also some problems, this paper mainly through the research and analysis the condition of wuzhou fiscal revenue in recent years, according to the time series analysis of a simple moving average method research and analysis of financial income and expenditure wuzhou city, the result obtained is wuzhou city, fiscal revenue decline present condition, and fiscal spending is rising year by year, the situation will lead to wuzhou city, the people's living standards decline, influence all aspects of wuzhou city development. Give some Suggestions on the development of the financial benefit wuzhou city. This paper first introduces the main use of the time series analysis of the concept and a simple moving average method method, reoccupy chart illustrates the wuzhou city, in recent years the financial revenue and expenditure situation, then set a model, analysis the time series analysis method to draw 2012 fiscal income condition prediction results, finally, in view of wuzhou city, improve the financial income thoughts, give some advice, for instance: rationality vigorously implement the strategy of industrial county, strengthen the industry leading financial sources, A vigorous development of the third industry, and to strengthen the construction of local revenue;