ansys14实例分析

六角扳手应力有限元方法分析
实体模型如图5.1所示为一六方孔螺钉头用扳手,在手柄端部加斜向上的面力100N。然后加向下的面力20N。本例题的目的是算出在这两种外载作用下扳手的应力分布。详细参数如下:
截面宽:10mm,正六边形边长为5.8mm;
形状:正六边形
杆长:7.5cm
手柄长:20cm
弯曲半径:1cm
弹性模量:2.07×1011Pa
向下的面力:20N
斜向上的面力:100N
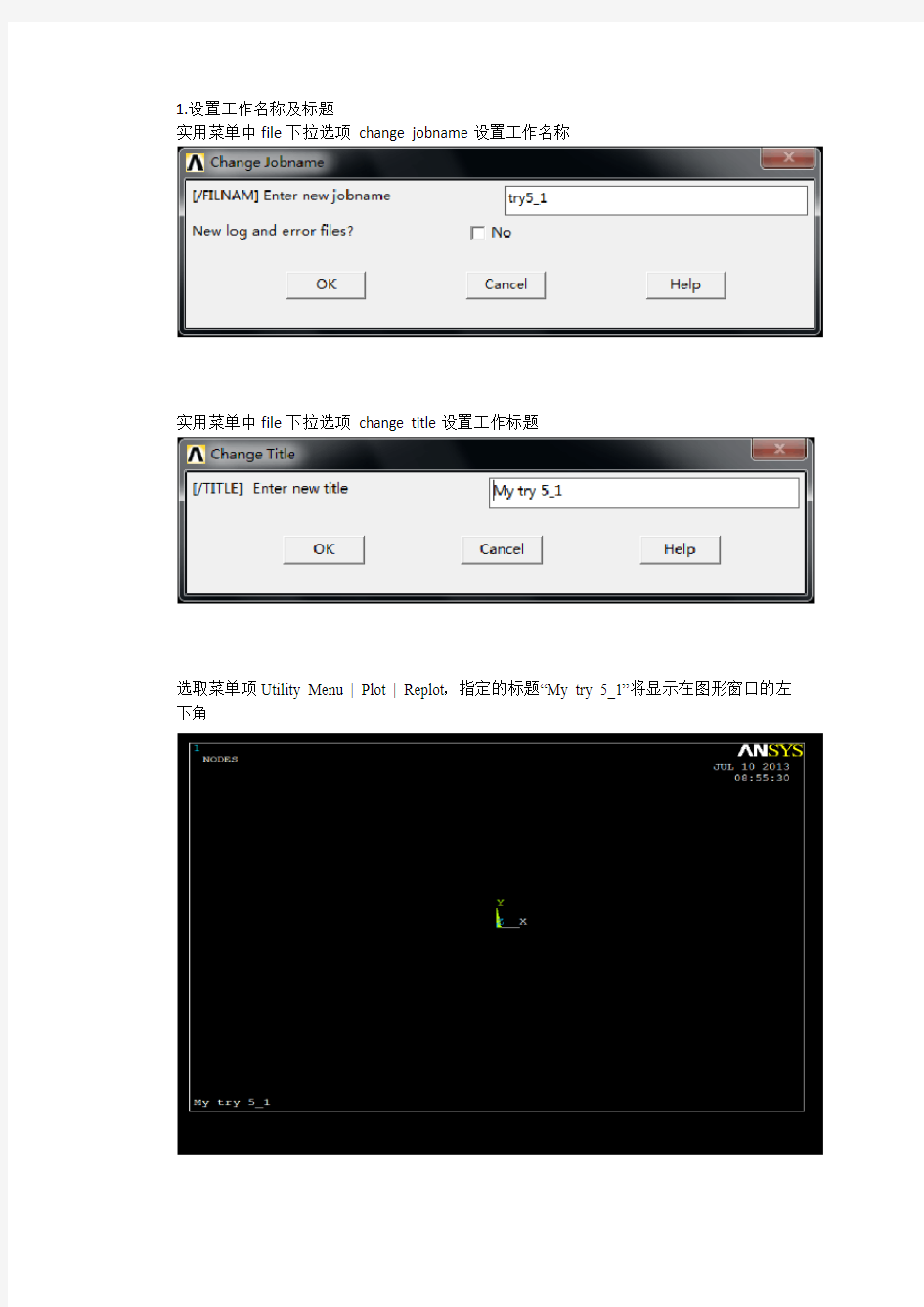
1.设置工作名称及标题
实用菜单中file下拉选项change jobname设置工作名称
实用菜单中file下拉选项change title设置工作标题
选取菜单项Utility Menu | Plot | Replot,指定的标题“My try 5_1”将显示在图形窗口的左下角
选取菜单项Main Menu | Preference,将弹出Preference of GUI Filtering(菜单过滤参数选择)对话框,选中Structural(结构)复选框,设置为与结构分析相对应的菜单选项。
2.设置单位制及定义后面要用到的参数
在命令输入框中输入“/units,si”按回车键确定,将单位制设为国际单位制。
单击菜单项Utility Menu | Parameters | Angular Units,弹出Angular Units for Parametric Functions设定在ANSYS内部函数中角度参数的单位为“Degrees DEG”
单击Utility Menu | Parameters | Scalar Parameters,弹出Scalar Parameters(参变量)对话
按上表提供参数进行定义
输入结束后close。
3.定义单元类型
选取菜单项Main Menu | Preprocessor | Element Type | Add/Edit/Delete,将弹出Element Types(单元类型)对话框,单击add按钮,分别添加“Mesh Facet 200”和Brick 8Node 185,其中Mesh Facet 200,此种单元类型划分网格生成的单元和节点在求解时是无效的,即不会对这些单元和节点求解。
选type2 点击options按钮,选择quad 4-node然后ok
4.定义材料属性
选取菜单项Main Menu | Preprocessor | Material Props | Material Models,将弹出Define Material Model Behavior(定义材料模型)对话框,
在ex栏输入之前定义的模量参数exx,在prxy栏输入0.3(泊松比),ok
5.建立扳手模型
建立模型思路:采用沿路径拖拉的方式建立实体模型和有限元网格,首先建立扳手的截面,然后做出扳手的一条路径线,将截面沿此路径线拖拉生成扳手实体模型和网格。(1)建立扳手界面正六边形,单击菜单项Main Menu | Preprocessor | Modeling | Create | Areas | Polygon | By Side Length,弹出Polygon by Side Length(根据边长创建正多边形)对话框。边数6,边长为之前定义的参数i_side。
生成界面
(2)创建截面拖拉路径上的关键点
单击Main Menu | Preprocessor | Modeling | Create | Keypoints | In Active CS,弹出Create Keypoint in Active Coordinate System(在激活坐标系下创建关键点)对话框。输入下表坐标
结果如图
单击菜单项Utility Menu | Plot | Multi-Plots,显示所有图元
单击Utility Menu | PlotCtrls | Pan Room Rotate,弹出Pan-Zoom-Rotate(平移-缩放-旋转)对话框,在此对话框中可以指定图形窗口的视角,也可以动态改变视角(将Dynamic Mode复选框选中,然后鼠标右键拖动图形是旋转,中键拖动图形是缩放和旋转,左键拖动图形是平移),以便于观察或者选取图形窗口的图形。依次点击iso,fit,close显示界面如图
(3)创建引导路径
单击菜单项Utility Menu | PlotCtrls | Numbering,弹出Plot Numbering Controls(编号显示控制)对话框。选择Keypoint numbers和Line numbers
显示如图
单击菜单项Main Menu | Preprocessor | Modeling | Create | Lines | Straight Line,弹出在关键点选择对话框,要求选择欲创建线的端点。此对话框要求通过指定线的两个端点创建线,可以通过输入两个端点的编号来创建线,也可以用鼠标在图形窗口中点取。
依次点取编号为7和8的关键点,创建一条线L7,其端点为关键点7和8;再先后点取关键点8和9,创建一条端点为关键点8和9的线L8。点取时可能需要通过Pan-Zoom-Rotate对话框改变视角以方便点取。
单击Main Menu | Preprocessor | Modeling | Create | Lines | Line Fillet,弹出线选择对话框,要求选择欲创建圆角的两条线。在Fillet radius(圆角半径)文本框中输入圆角半径BENDRAD
单击ANSYS工具条上的save-db按钮,保存数据库。
6.对截面进行网格划分
点击单击Main Menu | Preprocessor | Meshing | MeshTool,弹出Mesh Tool(网格工具),
单击Lines域set按钮,弹出线选择对话框,依次点取截面得六条边,然后单击
选择对话框的按钮,弹出Element Sizes on Picked Lines(在选定线上设置单元分划数)对话框,以设定正六边形每条边的单元分划数。
在网格工具中选择分网对象为Area,网格形状为Quad(四边形),分网形式为Mapped (映射),在附加选项中选择“Pick corners”
单击mesh按钮,弹出面选择对话框,选择定义的截面后单击按钮,弹出点选择对话框,要求选择正六边形的顶点即在图形窗口中用鼠标点取正六边形的三个顶点关键点1、3、5,ok,ANSYS程序将对截面划分网格,生成单元和节点
单击菜单项Utility Menu | Plot | Elements,图形窗口中将只显示刚刚生成的单元。
单击Utility Menu | PlotCtrls | Pan Room Rotate,弹出Pan-Zoom-Rotate对话框,依次单击
front,fit,close按钮,得到的视图
7.将截面沿路径生成体
在刚才的mesh tool 工具条中,单击网格工具上Size Controls | Global域set按钮,弹出Global Element Sizes(全局单元尺寸)设置对话框,也可以直接单击菜单项Main Menu | Preprocessor | Meshing | Size Cntrls | Global | Size调出此对话框。长度填写l_elem
单击Utility Menu | Plot | Lines,图形窗口中将只显示线。
把前面创建的扳手截面沿路径线拖拉生成扳手实体。单击菜单项Main Menu | Preprocessor | Modeling | Modeling | Operate | Extrude | Areas | Along Lines,选择要求欲拖拉的截面(pick all)。
又弹出线选择对话框,要求选择拖拉路径。依次点取线 L7、L9、L8(或直接输入文中“7,9,8”,然后回车)
生成如图
单击Utility Menu | Plot | Element,可以显示扳手的实体单元,如图所示
单击菜单项Main Menu | Preprocessor | Meshing | Clear | Areas,弹出面选择对话框,要求选择欲清除网格的面,点击pick all 清楚所有面。
点击save db保存数据。
8.定义边界条件
实例的位移边界条件为将扳手杆部的底面边界上节点的全部位移固定。具体步骤如下(1)单机菜单项Utility Menu | Select | Entities,弹出Select Entities(实体选择)对话框
在最上面的下拉列表选择Areas(面),表示将要选择图元类型是面,在下面的下拉列表中选择By Num/Pick,单击apply,弹出面选择对话框,要求选取欲加入选择集中的面,即前面创建的面ok
返回到实体选择对话框中,在第一个下拉列表中选择Lines(线)
在第二个下拉列中选择Exterior(外部),选择已选择面的边界线,即底面边界线,apply,然后在第一个下拉列表中选择Nodes(节点),在下面的下拉列表中选择Attach to(关联于),表示要选择与某一种图元的可用选择集相关联的节点。在中部的选择域中单击“Lines,All”前的单选钮,表示选择已构造的线选择集中的线上的的所有节点,即底面边界线上的所有节点。
单击Utility Menu | Plot | Nodes,则显示当前所有可操作的节点。(即通过实体选择对话框构造的节点选择集中的节点,关于实体选择命令的详细说明参见ANSYS命令参考手册)
单击Main Menu | Solution | Define Loads | Apply | Structural | Displacement | On Nodes,弹出节点选择对话框,要求选择欲对其施加位移约束的节点。
单击pick all按钮,选择所有当前可操作(即选择集中)的节点。弹出Apply U,ROT on Nodes (在节点上施加位移约束)对话框。
多元线性回归模型的案例分析
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
白盒测试实例
白盒测试实例之一——需求说明 三角形的问题在很多软件测试的书籍中都出现过,问题虽小,五脏俱全,是个很不错的软件测试的教学例子。本文借助这个例子结合教学经验,从更高的视角来探讨需求分析、软件设计、软件开发与软件测试之间的关系与作用。 题目:根据下面给出的三角形的需求完成程序并完成测试: 一、输入条件: 1、条件1:a+b>c 2、条件2:a+c>b 3、条件3:b+c>a 4、条件4:0 11. if(a==b && b==c && a==c) //这里可以省掉一个判断 12. { 13. printf("1是等边三角形"); 14. } 15. else 16. { 17. if(a==b || b==c || a==c) 18. { 19. printf("2是等腰三角形"); 20. } 21. else 22. { 23. if(a*a+b*b==c*c || a*a+c*c==b*b || b*b+c*c==a*a) 24. { 25. printf("3是直角三角形"); 26. } 27. else 28. { 29. printf("4是一般三角形"); 30. } 31. } 32. } 33. } 34. else 35. { 36. printf("5不能组成三角形"); 37. } 38. } 39. else 40. { 41. printf("6某些边不满足限制"); 42. } 43. } 点评:这样的思路做出来的程序只能通过手工方式来测试所有业务逻辑,而且这个程序只能是DOS界面版本了,要是想使用web或图形化界面来做输入,就得全部写过代码。 回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: ( 2010年中国各地区城市居民人均年消费支出和可支配收入 } 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1: 表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX 案例分析报告(2014——2015学年第一学期) 课程名称:预测与决策 专业班级:电子商务1202 学号: 2204120202 学生姓名:陈维维 2014 年 11月 案例分析(一元线性回归模型) 我国城镇居民家庭人均消费支出预测 一、研究目的与要求 居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我研究的对象是各地区居民消费的差异。居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。 所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。 因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模 实验报告书 实验一白盒测试 学生姓名:李庆忠 专业:计算机科学与技术学号:1341901317 白盒测试实验报告 一实验内容 1、系统地学习和理解白盒测试的基本概念、原理,掌握白盒测试的基本技术和方法; 2、举例进行白盒测试,使用语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、组合 覆盖、路径覆盖进行测试。 3、通过试验和应用,要逐步提高和运用白盒测试技术解决实际测试问题的能力; 4、熟悉C++编程环境下编写、调试单元代码的基本操作技术和方法; 5、完成实验并认真书写实验报告(要求给出完整的测试信息,如测试程序、测试用例, 测试报告等) 二实验原理 白盒测试原理:已知产品的内部工作过程,可以通过测试证明每种内部操作是否符合设计规格要求,所有内部成分是否已经过检查。它是把测试对象看作装在一个透明的白盒子里,也就是完全了解程序的结构和处理过程。这种方法按照程序内部的逻辑测试程序,检验程序中的每条通路是否都能按预定要求正确工作。其又称为结构测试。 流程图如下图所示 实验代码 #include"stdio.h" int main() { int x,y,z; scanf("%d%d",&x,&y); if((x>0)&&(y>0)) { z=x+y+10; } else { z=x+y-10; } if(z<0) { z=0; printf("%d\n",z); } else { printf("%d\n",z); } return 0; } 语句覆盖是指选择足够的测试,使得程序中每个语句至少执行一次。如选择测试x=1,y=1和x=1,y=-1可覆盖所有语句。 判定覆盖是指选择足够的测试,使得程序中每一个判定至少获得一次“真”值和“假”值,从而使得程序的每个分支都通过一次(不是所有的逻辑路径)。选择测试x=1,y=1和x=1,y=-1可覆盖所有判定。 条件覆盖是指选择语句多数的测试,使得程序判定中的每个条件能获得各种不同的结果。选择测试x=1,y=1和x=-1,y=-1可覆盖所有条件。 判定/条件覆盖是指选择足够多的测试,使得程序判定中每个条件取得条件可能的值,并使每个判定取到各种可能的结果(每个分支都通过一次)。即满足条件覆盖,又满足判定覆盖。选择测试x=1,y=1和x=-1,y=-1可覆盖所有判定/条件。 条件组合覆盖是指选择足够的测试,使得每个判定中的条件的各种可能组合都至少出现一次(以判定为单位找条件组合)。 注:a,条件组合只针对同一个判断语句存在多个条件的情况,让这些条件的取值进行笛卡尔乘积组合。 b,不同的判断语句内的条件取值之间无需组合。 c,对于但条件的判断语句,只需要满足自己的所有取值即可。 选择测试用例x=1,y=1;x=1,y=-1,x=-1,y=1和x=-1,y=-1可覆盖所有条件组合。 路径覆盖是分析软件过程流的通用工具,有助分离逻辑路径,进行逻辑覆盖的测试,所用的流程图就是讨论软件结构复杂度时所用的流程图。 一、核心程序代码 /** 判断三角形的类*/ public class TriangleTestMethod { /** 判断三角形的种类。参数a, b, c 分别为三角形的三边, * 返回的参数值为0 ,表示非三角形; * 为 1 ,表示普通三角形; * 为 2 ,表示等腰三角形; * 为 3 ,表示等边三角形。 */ public static int comfirm( int a, int b, int c) { if ((a + b > c) && (b + c > a) && (a + c > b)) { if ((a == b) && (b ==c)) // 判断为等边三角形 return 3; if ((a == b) || (b == c) || (a == c)) // return 2; else // 判断为普通三角形return 1; } else { // 为非三角形 return 0; } } } // 判断为三角形判断为等腰三角形 、程序流程图 三、测试用例 F6, F7, T8 Case28 a=4, b=3, c=3 2 T1, T2, T3, F4, T5, F6, T7, F8 2 Case29 a=3, b=4, c=5 1 T1, T2, T3, F4, F5, F6, F7, F8 1 Case30 a=3, b=4, c=3 2 T1, T2, T3, F4, F5, F6, F7, T8 2 备注 其他条件组合,无法到达结束 四、程序控制流图 -> a B a == b E F b == c Return 3 Ffet urn 2 Ret ur n 1 K 输入 期望输出 覆盖对象 测试结果 Case31 a=1,b=6,c=7 0 A->D 0 Case32 a=7, b=6, c=1 0 A->B->D 0 Case33 a=1,b=7,c=6 0 A->B->C->D D Return 0 G b == c Ret ur n 2 H 斗 J a == C 一般线性回归分析案例 1、案例 为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康的影响,随机抽取了30个观测数据,基于多员线性回归分析的理论方法,对儿童体内几种必需元素与血红蛋白浓度的关系进行分析研究。这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu)。 表一血红蛋白与钙、铁、铜必需元素含量 (血红蛋白单位为g;钙、铁、铜元素单位为ug) case y(g)ca fe cu 17.0076.90295.300.840 27.2573.99313.00 1.154 37.7566.50350.400.700 48.0055.99284.00 1.400 58.2565.49313.00 1.034 68.2550.40293.00 1.044 78.5053.76293.10 1.322 88.7560.99260.00 1.197 98.7550.00331.210.900 109.2552.34388.60 1.023 119.5052.30326.400.823 129.7549.15343.000.926 1310.0063.43384.480.869 1410.2570.16410.00 1.190 1510.5055.33446.00 1.192 1610.7572.46440.01 1.210 1711.0069.76420.06 1.361 1811.2560.34383.310.915 1911.5061.45449.01 1.380 2011.7555.10406.02 1.300 2112.0061.42395.68 1.142 2212.2587.35454.26 1.771 2312.5055.08450.06 1.012 2412.7545.02410.630.899 2513.0073.52470.12 1.652 2613.2563.43446.58 1.230 白盒测试 白盒测试,又称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试。白盒测试是一种测试用例设计方法,盒子指的是被测试的软件,白盒指的是盒子是可视的,你清楚盒子部的东西以及里面是如何运作的。"白盒"法全面了解程序部逻辑结构、对所有逻辑路径进行测试。"白盒"法是穷举路径测试。在使用这一方案时,测试者必须检查程序的部结构,从检查程序的逻辑着手,得出测试数据。贯穿程序的独立路径数是天文数字。 采用什么方法对软件进行测试呢?常用的软件测试方法有两大类:静态测试方法和动态测试方法。其中软件的静态测试不要求在计算机上实际执行所测程序,主要以一些人工的模拟技术对软件进行分析和测试;而软件的动态测试是通过输入一组预先按照一定的测试准则构造的实例数据来动态运行程序,而达到发现程序错误的过程。在动态分析技术中,最重要的技术是路径和分支测试。下面要介绍的六种覆盖测试方法属于动态分析方法。 中文名:白盒测试 外文名:white-box testing 别称:结构测试、透明盒测试 白盒测试测试方法 白盒测试的测试方法有代码检查法、静态结构分析法、静态质量度量法、逻辑覆盖法、基本路径测试法、域测试、符号测试、路径覆盖和程序变异。 白盒测试法的覆盖标准有逻辑覆盖、循环覆盖和基本路径测试。其中逻辑覆盖包括语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖。六种覆盖标准发现错误的能力呈由弱到强的变化: 1.语句覆盖每条语句至少执行一次。 2.判定覆盖每个判定的每个分支至少执行一次。 3.条件覆盖每个判定的每个条件应取到各种可能的值。 4.判定/条件覆盖同时满足判定覆盖条件覆盖。 5.条件组合覆盖每个判定中各条件的每一种组合至少出现一次。 6.路径覆盖使程序中每一条可能的路径至少执行一次。 白盒测试要求 SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示: 点击“分析”——回归——线性——进入如下图所示的界面: 将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除) 广西科技大学计算机学院《软件测试技术》实验报告书 实验一白盒测试 学生姓名:xxxx 学号:xxxx 班级:xxxx 指导老师:xxxxx 专业:计算机学院软件工程 提交日期:2014年10月20日 白盒测试实验报告 一实验内容 1、系统地学习和理解白盒测试的基本概念、原理,掌握白盒测试的基本技术和方法; 2、举例进行白盒测试,使用语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、组合 覆盖、路径覆盖进行测试。 3、通过试验和应用,要逐步提高和运用白盒测试技术解决实际测试问题的能力; 4、熟悉C++编程环境下编写、调试单元代码的基本操作技术和方法; 5、完成实验并认真书写实验报告(要求给出完整的测试信息,如测试程序、测试用例, 测试报告等) 二实验原理 白盒测试原理:已知产品的内部工作过程,可以通过测试证明每种内部操作是否符合设计规格要求,所有内部成分是否已经过检查。它是把测试对象看作装在一个透明的白盒子里,也就是完全了解程序的结构和处理过程。这种方法按照程序内部的逻辑测试程序,检验程序中的每条通路是否都能按预定要求正确工作。其又称为结构测试。 对于该实验的例子给出其流程图如下图所示,我们来了解白盒测试的基本技术和方法。 语句覆盖是指选择足够的测试用例,使得程序中每个语句至少执行一次。如上例选择测试用例x=1,y=1和x=1,y=-1可覆盖所有语句。 判定覆盖是指选择足够的测试用例,使得程序中每一个判定至少获得一次“真”值和“假”值,从而使得程序的每个分支都通过一次(不是所有的逻辑路径)。选择测试用例x=1,y=1和x=1,y=-1可覆盖所有判定。 条件覆盖是指选择语句多数的测试用例,使得程序判定中的每个条件能获得各种不同的结果。选择测试用例x=1,y=1和x=-1,y=-1可覆盖所有条件。 判定/条件覆盖是指选择足够多的测试用例,使得程序判定中每个条件取得条件可能的值,并使每个判定取到各种可能的结果(每个分支都通过一次)。即满足条件覆盖,又满足判定覆盖。选择测试用例x=1,y=1和x=-1,y=-1可覆盖所有判定/条件。 条件组合覆盖是指选择足够的测试用例,使得每个判定中的条件的各种可能组合都至少出现一次(以判定为单位找条件组合)。 注:a,条件组合只针对同一个判断语句存在多个条件的情况,让这些条件的取值进行笛卡尔乘积组合。 b,不同的判断语句内的条件取值之间无需组合。 c,对于但条件的判断语句,只需要满足自己的所有取值即可。 选择测试用例x=1,y=1;x=1,y=-1,x=-1,y=1和x=-1,y=-1可覆盖所有条件组合。 路径覆盖是分析软件过程流的通用工具,有助分离逻辑路径,进行逻辑覆盖的测试,所用的流程图就是讨论软件结构复杂度时所用的流程图。 三实验方法 多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024 SPSS19.0实战之多元线性回归分析 (2011-12-09 12:19:11) 转载▼ 分类:软件介绍 标签: 文化 线性回归数据(全国各地区能源消耗量与产量)来源,可点击协会博客数据挖掘栏:国泰安数据服务中心的经济研究数据库。 1.1 数据预处理 数据预处理包括的内容非常广泛,包括数据清理和描述性数据汇总,数据集成和变换,数据归约,数据离散化等。本次实习主要涉及的数据预处理只包括数据清理和描述性数据汇总。一般意义的数据预处理包括缺失值填写和噪声数据的处理。于此我们只对数据做缺失值填充,但是依然将其统称数据清理。 1.1.1 数据导入与定义 单击“打开数据文档”,将xls格式的全国各地区能源消耗量与产量的数据导入SPSS中,如图1-1所示。 图1-1 导入数据 导入过程中,各个字段的值都被转化为字符串型(String),我们需要手动将相应的字段转回数值型。单击菜单栏的“ ”-->“ ”将所选的变量改为数值型。如图1-2所示: 图1-2 定义变量数据类型 1.1.2 数据清理 数据清理包括缺失值的填写和还需要使用SPSS分析工具来检查各个变量的数据完整性。单击“ ”-->“ ”,将检查所输入的数据的缺失值个数以及百分比等。如图1-3所示: 图1-3缺失值分析 表1-1 能源消耗量与产量数据缺失值分析 SPSS提供了填充缺失值的工具,点击菜单栏“ ”-->“ ”,即可以使用软件提供的几种填充缺失值工具,包括序列均值,临近点中值,临近点中位数等。结合本次实习数据的具体情况,我们不使用SPSS软件提供的替换缺失值工具,主要是手动将缺失值用零值来代替。 1.1.3 描述性数据汇总 描述性数据汇总技术用来获得数据的典型性质,我们关心数据的中心趋势和离中趋势,根据这些统计值,可以初步得到数据的噪声和离群点。中心趋势的量度值包括:均值(mean),中位数(median),众数(mode)等。离中趋势量度包括四分位数(quartiles),方差(variance)等。 SPSS提供了详尽的数据描述工具,单击菜单栏的“ ”-->“ ”-->“ ”,将弹出如图2-4所示的对话框,我们将所有变量都选取到,然后在选项中勾选上所希望描述的数据特征,包括均值,标准差,方差,最大最小值等。由于本次数据的单位不尽相同,我们需要将数据标准化,同时勾选上“将标准化得分另存为变量”。 实验2 白盒测试 一、实验目的与要求 1、掌握白盒测试的语句覆盖和判定覆盖测试方法的原理及应用 2、掌握条件覆盖、条件组合覆盖的方法,提高应用能力 3、掌握路径法测试 二、实验设备 1、电脑PC 三、实验原理 白盒测试原理:已知产品的内部工作过程,可以通过测试证明每种内部操作是否符合设计规格要求,所有内部成分是否已经过检查。它是把测试对象看作装在一个透明的白盒子里,也就是完全了解程序的结构和处理过程。这种方法按照程序内部的逻辑测试程序,检验程序中的每条通路是否都能按预定要求正确工作,其又称为结构测试。 1、语句覆盖 语句覆盖指代码中的所有语句都至少执行一遍,用于检查测试用例是否有遗漏,如果检查到没有执行到的语句时要补充测试用例。无须细分每条判定表达式,该测试虽然覆盖了可执行语句,但是不能检查判断逻辑是否有问题。 2、判定覆盖 又称判断覆盖、分支覆盖,指设计足够的测试用例,使得程序中每个判断的取真分支和取假分支至少经历一次,即判断真假取值均曾被满足。 判定覆盖比语句覆盖强,但是对程序逻辑的覆盖度仍然不高,比如由多个逻辑条件组合而成的判定,仅判定整体结果而忽略了每个条件的取值情况。 3、条件覆盖、条件判定覆盖 条件覆盖指程序中每个判断中的每个条件的所有可能的取值至少要执行一次,但是条件覆盖不能保证判定覆盖,条件覆盖只能保证每个条件至少有一次为真,而不考虑所有的判定结果。 条件判定覆盖是条件覆盖和判定覆盖的组合,指设计足够的测试用例,使得判定中每个条件的所有可能的取值至少出现一次,并且每个判定取到的各种可能的结果也至少出现一次。条件判定覆盖弥补了条件和判定覆盖的不足,但是未考虑条件的组合情况。 4、条件组合覆盖 又称多条件覆盖,设计足够的测试用例,使得判定条件中每一个条件的可能组合至少出现一次。线性地增加了测试用例的数量。 5、基本路径法 在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行的路径集合,从而设计测试用例的方法。在基本路径测试中,设计出的测试用例要保证在测试中程序的每条可执行语句至少执行一次,在基本路径法中,需要使用程序的控制流图进行可视化表达。 1 利用Excel2000进行一元线性回归分析 第一步,录入数据 以连续10年最大积雪深度和灌溉面积关系数据为例予以说明。录入结果见下图(图1)。 图1 第二步,作散点图 如图2所示,选中数据(包括自变量和因变量),点击“图表向导”图标;或者在 “插入”菜单中打开“图表(H)”。图表向导的图标为。选中数据后,数据变为蓝色(图2)。 图2 点击“图表向导”以后,弹出如下对话框(图3): 图3 在左边一栏中选中“XY散点图”,点击“完成”按钮,立即出现散点图的原始形式(图4 第三步,回归 观察散点图,判断点列分布是否具有线性趋势。只有当数据具有线性分布特征时,才能采用线性回归分析方法。从图中可以看出,本例数据具有线性分布趋势,可以进行线性回归。回归的步骤如下: ⑴首先,打开“工具”下拉菜单,可见数据分析选项(见图5): 图5 用鼠标双击“数据分析”选项,弹出“数据分析”对话框(图6): 图6 ⑵然后,选择“回归”,确定,弹出如下选项表: 图7 进行如下选择:X、Y值的输入区域(B1:B11,C1:C11),标志,置信度(95%),新工作表组,残差,线性拟合图。 或者:X、Y值的输入区域(B2:B11,C2:C11),置信度(95%),新工作表组,残差,线性拟合图。 注意:选中数据“标志”和不选“标志”,X、Y值的输入区域是不一样的:前者包括数据标志: 最大积雪深度x(米)灌溉面积y(千亩) 后者不包括。这一点务请注意。 图8-1 包括数据“标志” 图8-2 不包括数据“标志” ⑶再后,确定,取得回归结果(图9)。 图9 线性回归结果 ⑷最后,读取回归结果如下: 第二章一元线性模型案例分析 居民消费模式和消费规模分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入 软件质量保证与测试 实验指导 计算机工程学院 测试环境配置 1.settingJunit (1)startEclipse Selectwindows-preferences-java-buildpath–classpathvariables (2)clicknew,thefigureofnewvariableentryisshown. (3)name JUNIT_LIB selectfile-选择JUnit插件所对应的JAR文件所在地,在Eclipse的安装目录的plugins目录中 2.JUNIT的组成框架 其中,junit.framework和junit.runner是两个核心包。 junit.framework负责整个测试对象的框架 junit.runner负责测试驱动 Junit的框架又可分为: A、被测试的对象。 B、对测试目标进行测试的方法与过程集合,可称为测试用例(TestCase)。 C、测试用例的集合,可容纳多个测试用例(TestCase),将其称作测试包(TestSuite)。 D、测试结果的描述与记录。(TestResult)。 E、每一个测试方法所发生的与预期不一致状况的描述,称其测试失败元素(TestFailure) F、JUnitFramework中的出错异常(AssertionFailedError)。 JUnit框架是一个典型的Composite模式:TestSuite可以容纳任何派生自Test 的对象;当调用TestSuite对象的run()方法是,会遍历自己容纳的对象,逐个调用它们的run()方法。 3.JUnit中常用的接口和类 Test接口——运行测试和收集测试结果 Test接口使用了Composite设计模式,是单独测试用例(TestCase),聚合测试模式(TestSuite)及测试扩展(TestDecorator)的共同接口。 它的publicintcountTestCases()方法,它来统计这次测试有多少个TestCase,另外一个方法就是publicvoid run(TestResult),TestResult是实例接受测试结果,run方法执行本次测试。 TestCase抽象类——定义测试中固定方法 TestCase是Test接口的抽象实现,(不能被实例化,只能被继承)其构造函数TestCase(stringname)根据输入的测试名称name创建一个测试实例。由于每一个TestCase在创建时都要有一个名称,若某测试失败了,便可识别出是哪个测试失败。 TestCase类中包含的setUp()、tearDown()方法。setUp()方法集中初始化测试所需的所有变量和实例,并且在依次调用测试类中的每个测试方法之前再次执行setUp()方法。tearDown()方法则是在每个测试方法之后,释放测试程序方法中引用的变量和实例。 开发人员编写测试用例时,只需继承TestCase,来完成run方法即可,然后JUnit获得测试用例,执行它的run方法,把测试结果记录在TestResult之中。 Assert静态类——一系列断言方法的集合 Assert包含了一组静态的测试方法,用于期望值和实际值比对是否正确,即测试失败,Assert类就会抛出一个AssertionFailedError异常,JUnit测试框架将这种错误归入Failes并加以记录,同时标志为未通过测试。如果该类方法中指定一个String类型的传参则该参数将被做为AssertionFailedError异常的标识信息,告诉测试人员改异常的详细信息。 JUnit提供了6大类31组断言方法,包括基础断言、数字断言、字符断言、布尔断言、对象断言。 其中assertEquals(Objectexpcted,Objectactual)内部逻辑判断使用equals()方法,这表明断言两个实例的内部哈希值是否相等时,最好使用该方法对相应类实例的值进行比较。而assertSame(Objectexpected,Objectactual)内部逻辑判断使用了Java运算符“==”,这表明该断言判断两个实例是否来自于同一个引用(Reference),最好使用该方法对不同类的实例的值进行比对。 软件测试案例分析 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】 对软件测试理解 软件测试作为软件质量保证的一种重要方法,近些年来, 软件测试越来越受到产业界、教育界和学术界的重视。软件测试,描述一种用来促进鉴定软件的正确性、完整性、安全性和质量的过程。换句话说,软件测试是一种实际输出与预期输出间的审核或者比较过程。软件测试的经典定义是:在规定的条件下对程序进行操作,以发现程序错误,衡量软件质量,并对其是否能满足设计要求进行评估的过程。 1软件测试的方法 黑盒测试 在黑盒测试(或称功能测试)中,不考虑程序的内部结构和表现,其目的是确定程序的输入与输出是否与其规格一致,力图发现以下几类错误: 是否有不正确或遗漏了的功能在接口上,输入能否正确地接受能否正确地输出结果 是否有数据结构错误或外部信息(例如数据文件)访问错误性能上是否能满足要求是否有初始化或终止性错误 黑盒测试的主要缺点是依赖于规格的正确性(实际情况并非如此)和需要采用所有可能的输入作为测试用例才能保证模块的正确性。 白盒测试 在该方法对软件的过程性细节做细致检查,对程序所有逻辑进行测试。通过在不同点检查程序的状态,确定实际的状态是否与预期的状态一致。测试用例从程序的逻辑中产生。确定程序逻辑覆盖有几条原则,其中之一是语句覆盖,要求程序中的每条语句至少执行一次。这条原则是必要的,但不充分,因为部分错误并不能检测出来。 从上至下测试 从上至下测试从程序的顶点模块开始,然后逐步对较低级的模块进行测试。为了模仿被测试模块的低级模块,需要哑模块或桩子模块。从上至下测试的主要好处就是排除了系统测试和集成,它可以让人们看见系统的早期版本并证明系统的正确性。它的效果之一可以提高程序员的士气。从上至下测试的主要缺点是需要桩子模块,并 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:毫无疑问,多元线性回归方程应该为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样)1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示: 点击“分析”——回归——线性——进入如下图所示的界面: 将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于,当概率值大于等于时将会被剔除) “选择变量(E)" 框内,我并没有输入数据,如果你需要对某个“自变量”进行条件筛选,可以将那个自变量,移入“选择变量框”内,有一个前提就是:该变量从未在另一个目标列表中出现!,再点击“规则”设定相应的“筛选条件”即可,如下图所示: 点击“统计量”弹出如下所示的框,如下所示: 在“回归系数”下面勾选“估计,在右侧勾选”模型拟合度“ 和”共线性诊断“ 两个选项,再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值)点击继续。 提示: 共线性检验,如果有两个或两个以上的自变量之间存在线性相关关系,就会产生多重共线性现象。这时候,用最小二乘法估计的模型参数就会不稳定,回归系数的估计值很容易引起误导或者导致错误的结论。所以,需要勾选“共线性诊断”来做判断 通过容许度可以计算共线性的存在与否?容许度TOL=1-RI平方或方差膨胀因子(VIF): VIF=1/1-RI平方,其中RI平方是用其他自变量预测第I个变量的复相关系数,显然,VIF为TOL的倒数,TOL的值越小,VIF的值越大,自变量XI与其他自变量之间存在共线性的可能性越大。 提供三种处理方法: 1:从有共线性问题的变量里删除不重要的变量 2:增加样本量或重新抽取样本。 3:采用其他方法拟合模型,如领回归法,逐步回归法,主成分分析法。 再点击“绘制”选项,如下所示:SPSS线性回归分析案例
案例分析报告(一元线性回归模型)
白盒测试实验报告-范例
软件测试案例三角形白盒测试
一般线性回归分析案例
白盒测试和黑盒测试
多元线性回归实例分析
最新白盒测试实验报告-范例
多元线性回归模型案例分析.doc
多元线性回归分析案例
软件测试-实验2-白盒测试案例分析
(完整word版)利用Excel进行线性回归分析实例
第二章一元线性回归案例分析
白盒测试和黑盒测试实验报告
软件测试案例分析完整版
多元线性回归实例分析