74汉明码编码原理

74汉明码编码
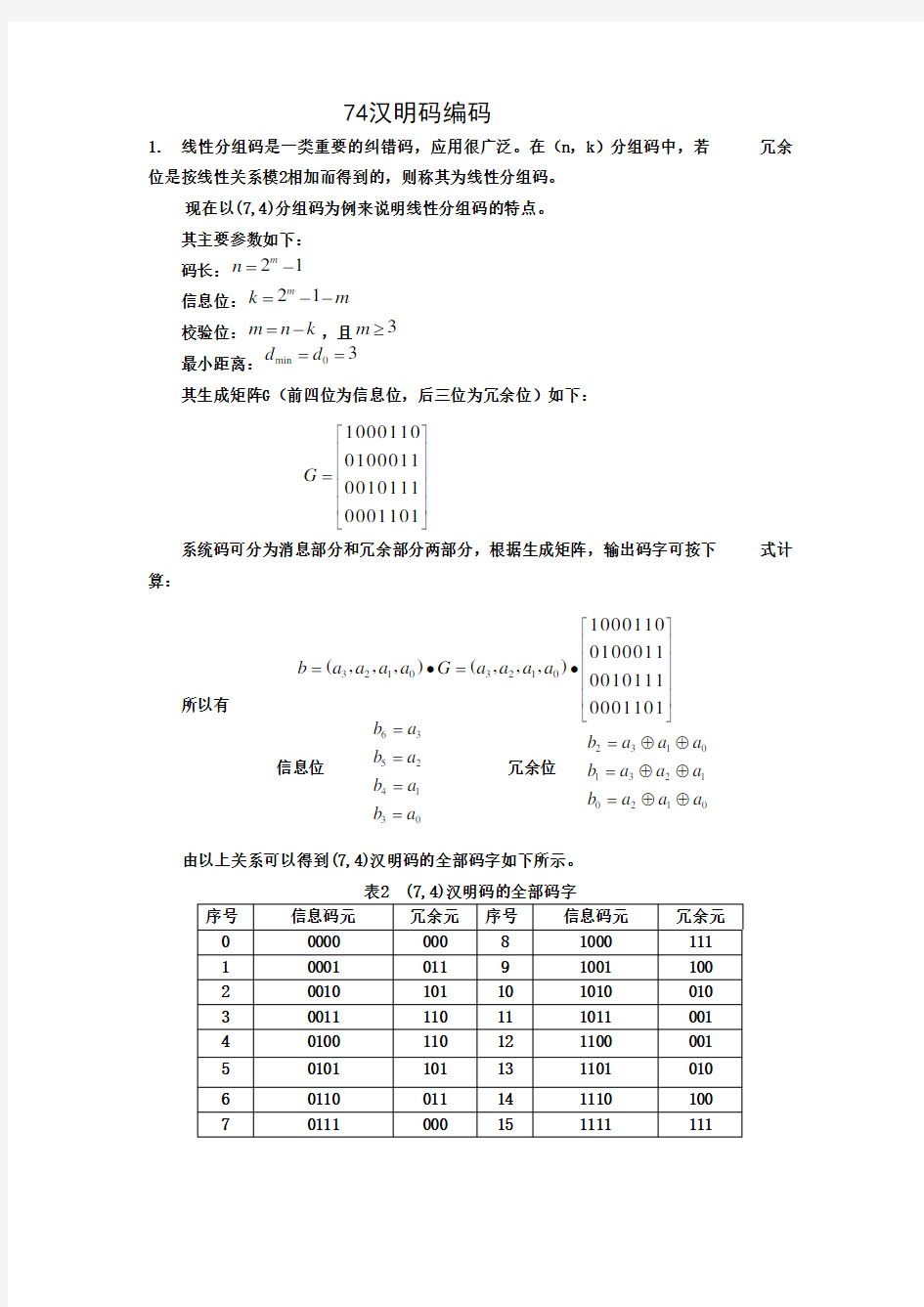
1. 线性分组码是一类重要的纠错码,应用很广泛。在(n ,k )分组码中,若 冗余
位是按线性关系模2相加而得到的,则称其为线性分组码。
现在以(7,4)分组码为例来说明线性分组码的特点。
其主要参数如下:
码长:21m n =-
信息位:21m k m =--
校验位:m n k =-,且3m ≥
最小距离:min 03d d ==
其生成矩阵G (前四位为信息位,后三位为冗余位)如下:
系统码可分为消息部分和冗余部分两部分,根据生成矩阵,输出码字可按下
式计
算:
所以有
信息位 冗余位
由以上关系可以得到(7,4)汉明码的全部码字如下所示。 表2 (7,4)汉明码的全部码字
序号 信息码元 冗余元 序号 信息码元 冗余元
0 0000 000 8 1000 111
1 0001 011 9 1001 100
2 0010 101 10 1010 010
3 0011 110 11 1011 001
4 0100 110 12 1100 001
5 0101 101 13 1101 010
6 0110 011 14 1110 100
7 0111 000 15 1111 111 1000110010001100101110001101G ?
?
??
??
=??
????
3210321010001100100011(,,,)(,,,)00101110001101b a a a a G a a a a ??
??
??=?=???
????
635241
30
b a b a b a b a ====2310
1321
0210b a a a b a a a b a a a =⊕
⊕=⊕⊕=⊕⊕
2.用C++编写(7,4)汉明码的思路如下:
16个不同信息序列的产生:调用stidlib包中的rand()产生二进制伪随机序列,为了产生16个不同信息序列,共分两步产生:
第一步:先产生一个伪随机序列并保留,将它赋给第一个信息序列V[0];
i=0;
for(j=0;j<4;j++)
v[i][j]=rand()%2;
第二步:同样产生一个序列,产生后要与在它以前产生的信息序列相比较,如果产生的信息序列与前面的序列都不同,则保留这个信息序列,并进行产生下一个信息序列;如果产生的信息序列与前面的序列有相同的,则此次产生的序列无效,需从新产生信息序列。此过程中需定义一个比较函数进行比较,其代码如下:
for(i=1;i<16;i++){
Lable:for(j=0;j<4;j++)
v[i][j]=rand()%2;
for(k=0;k if( vedict( v[i],v[k])) continue; //如果产生的信息序列与前面的序列都不同,则保留这个信 息序列,并进行产生下一个信息序列 else goto lable; //如果产生的信息序列与前面的序列有相同的,则此次产生的 序列无效,跳转到标签lable处,从新产生信息序列} } 进行判断的函数为: bool vedict(int a[],int b[]){ int m; for(m=0;m<4;m++){ switch(m){ case 0:if(a[m]!=b[m]) return true; else continue; break; case 1:if(a[m]!=b[m]) return true; else continue; break; case 2:if(a[m]!=b[m]) return true; else continue; break; case 3:if(a[m]!=b[m]) return true; else return false; } } } 74汉明码的生成: 利用线性关系式 : 信息位 冗余位 用两个for 循环,并分两部分求解:前四位用信息位方程,后三位用 冗余位方程(通过异或运算求得);其代码如下: for(i=0;i<16;i++){ for(j=0;j<7;j++) { if(j<4) u[i][j]= v[i][j]; if(j==4) u[i][j]=(v[i][0]^v[i][2])^v[i][3]; if(j==5) u[i][j]=(v[i][0]^v[i][1])^v[i][2]; if(j==6) u[i][j]=(v[i][1]^v[i][2])^v[i][3]; cout << u[i][j] << " "; } cout << endl; } 3. 其总代码为: #include #include void main(){ int g[4][7]={{1,0,0,0,1,1,0},{0,1,0,0,0,1,1},{0,0,1,0,1,1,1},{0,0,0,1,1,0,1}};//声明生成矩阵 63 524130b a b a b a b a ====231013210210b a a a b a a a b a a a =⊕⊕=⊕⊕=⊕⊕ int v[16][4];//声明信息序列 int u[16][7]; int i,j,k; cout << "生成矩阵为:" << endl;//输出生成矩阵 for(i=0;i<4;i++) { for(j=0;j<7;j++) cout << g[i][j] << " "; cout << endl; } bool vedict(int a[],int b[]);//声明判断函数 cout << "消息序列:"<< endl;//随机产生信息位序列 i=0; for(j=0;j<4;j++) v[i][j]=rand()%2; for(i=1;i<16;i++){ lable:for(j=0;j<4;j++) v[i][j]=rand()%2; for(k=0;k continue; //如果产生的信息序列与前面的序列都不同,则保留这个信 息序列,并进行产生下一个信息序列 else goto lable; //如果产生的信息序列与前面的序列有相同的,则此次产生的 序列无效,跳转到标签lable处,从新产生信息序列} } for(i=0;i<16;i++){ //输出信息序列 for(j=0;j<4;j++) cout << v[i][j] << " "; cout << endl; } cout << "74汉明码为:" < for(i=0;i<16;i++){ for(j=0;j<7;j++) { if(j<4) u[i][j]= v[i][j]; if(j==4) u[i][j]=(v[i][0]^v[i][2])^v[i][3]; if(j==5) u[i][j]=(v[i][0]^v[i][1])^v[i][2]; if(j==6) u[i][j]=(v[i][1]^v[i][2])^v[i][3]; cout << u[i][j] << " "; } cout << endl; } } bool vedict(int a[],int b[]){ int m; for(m=0;m<4;m++){ switch(m){ case 0:if(a[m]!=b[m]) return true; else continue; break; case 1:if(a[m]!=b[m]) return true; else continue; break; case 2:if(a[m]!=b[m]) return true; else continue; break; case 3:if(a[m]!=b[m]) return true; else return false; } } } 编译、运行结果为: 实验四汉明码系统 一、实验原理和电路说明 差错控制编码的基本作法是:在发送端被传输的信息序列上附加一些监督码元,这些多余的码元与信息之间以某种确定的规则建立校验关系。接收端按照既定的规则检验信息码元与监督码元之间的关系,一旦传输过程中发生差错,则信息码元与监督码元之间的校验关系将受到破坏,从而可以发现错误,乃至纠正错误。 通信原理综合实验系统中的纠错码系统采用汉明码(7,4)。所谓汉明码是能纠正单个错误的线性分组码。它有以下特点: 码长n=2m-1 最小码距d=3 信息码位k=2n-m-1 纠错能力t=1 监督码位r=n-k 这里m位≥2的正整数,给定m后,既可构造出具体的汉明码(n,k)。 汉明码的监督矩阵有n列m行,它的n列分别由除了全0之外的m位码组构成,每个码组只在某列中出现一次。系统中的监督矩阵如下图所示: 1110100 H=0111010 1101001 其相应的生成矩阵为: 1000101 0100111 G= 0010110 0001011 汉明译码的方法,可以采用计算校正子,然后确定错误图样并加以纠正的方法。 图2.4.1和图2.42给出汉明编码器和译码器电原理图。 a6 a5 a4 a3 a2 a1 a0 a a a a 图2.4.1汉明编码器电原理图 a a a a a a a3 图2.4.2汉明译码器电原理图 表2.4.1 (7,4)汉明编码输入数据与监督码元生成表 a6bit,其次是a5、a4……,最后输出a0位。 汉明编译码模块实验电路功能组成框图见图2.4.4和图2.3.5所示。 汉明编码模块实验电路工作原理描述如下: 1、输入数据:汉明编码输入数据可以来自ADPCM1模块的ADPCM码字,或来自同 汉明码编译码 一设计思想 汉明码是一种常用的纠错码,具有纠一位错误的能力。本实验使用Matlab平台,分别用程序语言和simulink来实现汉明码的编译码。用程序语言实现就是从原理层面,通过产生生成矩阵,错误图样,伴随式等一步步进行编译码。用simulink实现是用封装好的汉明码编译码模块进行实例仿真,从而验证程序语言中的编译码和误码性能分析结果。此外,在结合之前信源编码的基础上,还可实现完整通信系统的搭建。 二实现流程 1.汉明码编译码 图 1 汉明码编译码框图 1)根据生成多项式,产生指定的生成矩阵G 2)产生随机的信息序列M 得到码字 3)由C MG 4)进入信道传输 S RH得到伴随式 5)计算=T 6)得到解码码流 7)得到解码信息序列 2.汉明码误码性能分析 误码率(SER)是指传输前后错误比特数占全部比特数的比值。 误帧率(FER)是指传输前后错误码字数占全部码字数的比值。 通过按位比较、按帧比较可以实现误码率和误帧率的统计。 3. 构建完整通信系统 图 2 完整通信系统框图 三 结论分析 1. 汉明码编译码 编写了GUI 界面方便呈现过程和结果。 图 3 汉明码编译码演示GUI 界面 以产生(7,4)汉明码为例说明过程的具体实现。 1) 根据生成多项式,产生指定的生成矩阵G 用[H,G,n,k] = hammgen(3,'D^3+D+1')函数得到系统码形式的校验矩阵H 、G 以及码字长度n 和信息位数k 100101101011100010111H ????=?????? 1 10100001101001 1100101 010001G ????? ?=?? ?? ?? 2) 产生随机的信息序列M 输入信息序列 Huffman 编码 Hamming 编码 信道Hamming 译码 Huffman 译码输出信息序列噪声 重庆工程学院 电子信息学院 实验报告 课程名称:_ 数据通信原理开课学期:__ 2015-2016/02_ 院(部): 电子信息学院开课实验室:实训楼512 学生姓名: 舒清清梁小凤专业班级: 1491003 学号: 149100308 149100305 重庆工程学院学生实验报告 课程名 称 数据通信原理实验项目名称汉明码编译实验 开课院系电子信息学院实验日期 2016年5月7 日 学生姓名舒清清 梁小凤 学号 149100308 149100305 专业班级网络工程三班 指导教 师 余方能实验成绩 教师评语: 教师签字:批改时间: 一、实验目的和要求 1、了解信道编码在通信系统中的重要性。 2、掌握汉明码编译码的原理。 3、掌握汉明码检错纠错原理。 4、理解编码码距的意义。 二、实验内容和原理 汉明码编码过程:数字终端的信号经过串并变换后,进行分组,分组后的数据再经过汉明码编码,数据由4bit变为7bit。 三、主要仪器设备 1、主控&信号源、6号、2号模块各一块 2、双踪示波器一台 3连接线若干 四、实验操作方法和步骤 1、关电,按表格所示进行连线 2、开电,设置主控菜单,选择【主菜单】→【通信原理】→【汉明码】。 (1)将2号模块的拨码开关S12#拨为10100000,拨码开关S22#、S32#、S42#均拨为00000000;(2)将6号模块的拨码开关S16#拨为0001,即编码方式为汉明码。开关S36#拨为0000,即无错模式。按下6号模块S2系统复位键。 3、此时系统初始状态为:2号模块提供32K编码输入数据,6号模块进行汉明编译码,无差错插入模式。 4、实验操作及波形观测。 (1)用示波器观测6号模块TH5处编码输出波形。 (2)设置2号模块拨码开关S1前四位,观测编码输出并填入下表中: 五、实验记录与处理(数据、图表、计算等) 校对输入0000,编码0000000 输入0001,编码0001011 输入0010,编码0010101 输入0011,编码0011110 输入0100,编码0100110 输入0101,编码0101101 输入0110,编码0110011输入0111,编码0111000 通信原理课程设计报告书 课题名称 基于MATLAB 的(7,4)汉明码编 译码设计与仿真结果分析 姓 名 学 号 学 院 通信与电子工程学院 专 业 通信工程 指导教师 ※※※※※※※※※ ※ ※ ※※ ※ ※ 2009级通信工程专业 通信原理课程设计 2011年 12月 23日 一、设计任务及要求: 设计任务: 利用MATLAB编程,实现汉明码编译码设计。理解(7,4)汉明码的构造原理,掌握(7,4)汉明码的编码和译码的原理和设计步骤。并对其性能进行分析。要求: 通过MATLAB编程,设计出(7,4)汉明码的编码程序,编码后加入噪声,然后译码,画出信噪比与误比特数和信噪比与误比特率的仿真图,然后对其结果进行分析 指导教师签名: 2011年12月23日 二、指导教师评语: 指导教师签名: 年月日 三、成绩 验收盖章 年月日 基于MATLAB 的(7,4)汉明码编译码设计 与仿真结果分析 1 设计目的 (1)熟悉掌握汉明码的重要公式和基本概念。 (2)利用MATLAB 编程,实现汉明码编译码设计。 (3)理解(7,4)汉明码的构造原理,掌握(7,4)汉明码的编码和译码的原理和设计步骤。 (4)对其仿真结果进行分析。 2 设计要求 (1)通过MATLAB 编程,设计出(7,4)汉明码的编码程序。 (2)编码后加入噪声,然后译码,画出信噪比与误比特数和信噪比与误比特率的仿真图。 (3)然后对其结果进行分析。 3 设计步骤 3.1 线性分组码的一般原理 线性分组码的构造 3.1.1 H 矩阵 根据(7, 4)汉明码可知一般有 现在将上面它改写为 上式中已经将“⊕”简写成“+”。 上式可以表示成如下矩阵形式: ??? ??=⊕⊕⊕=⊕⊕⊕=⊕⊕⊕0 000346 13562456a a a a a a a a a a a a ?? ? ?? =?+?+?+?+?+?+?=?+?+?+?+?+?+?=?+?+?+?+?+?+?010011010010101100010111012345601234560123456a a a a a a a a a a a a a a a a a a a a a (1) (2) 汉明码编译码实验 一、实验目的 1、掌握汉明码编译码原理 2、掌握汉明码纠错检错原理 二、实验内容 1、汉明码编码实验。 2、汉明码译码实验。 3、汉明码纠错检错能力验证实验。 三、实验器材 LTE-TX-02E通信原理综合实验系统----------------------------------------------模块8 四、实验原理 在随机信道中,错码的出现是随机的,且错码之间是统计独立的。例如,由高斯白噪声引起的错码就具有这种性质。因此,当信道中加性干扰主要是这种噪声时,就称这种信道为随机信道。由于信息码元序列是一种随机序列,接收端是无法预知的,也无法识别其中有无错码。为了解决这个问题,可以由发送端的信道编码器在信息码元序列中增加一些监督码元。这些监督码元和信码之间有一定的关系,使接收端可以利用这种关系由信道译码器来发现或纠正可能存在的错码。在信息码元序列中加入监督码元就称为差错控制编码,有时也称为纠错编码。不同的编码方法有不同的检错或纠错能力。有的编码就只能检错不能纠错。 那么,为了纠正一位错码,在分组码中最少要加入多少监督位才行呢?编码效率能否提高呢?从这种思想出发进行研究,便导致汉明码的诞生。汉明码是一种能够纠正一位错码且编码效率较高的线性分组码。下面我们介绍汉明码的构造原理。 一般说来,若码长为n,信息位数为k,则监督位数r=n?k。如果希望用r个监督位构造出r个监督关系式来指示一位错码的n种可能位置,则要求 2r? 1 ≥n 或2r ≥k + r + 1 (14-1)下面我们通过一个例子来说明如何具体构造这些监督关系式。 设分组码(n,k)中k=4,为了纠正一位错码,由式(14-1)可知,要求监督位数r≥3。若取r=3,则n= k + r =7。我们用α6α5…α0表示这7个码元,用S1、S2、S3表示三个监督关系式中的校正子,则S1 S2 S3的值与错码位置的对应关系可以规定如表14-1所列。 表14-1 汉明码编码原理和校验方法 当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错,简单的说,汉明码是一个错误 校验码码集,由Bell实验室的R.W.Hamming发明,因此定名 为汉明码。用于数据传送,能检测所有一位和双位差错并纠正 所有一位差错的二进制代码。汉明码的编码原理是:在n位有 效信息位中增加k为检验码,形成一个n+k位的编码,然后把 编码中的每一位分配到k个奇偶校验组中。每一组只包含以为 校验码,组内按照奇偶校验码的规则求出该组的校验位。 在汉明校验码中,有效信息位的位数n与校验位数K满足下列关系: 2^K-1>=n+k. 1. 校验码的编码方法 (1)确定有效信息位与校验码在编码中的位置 设最终形成的n+k位汉明校验码为Hn+k….H2H1,各位的位号按照从右到左的顺序依次为1,2,…,n+k,则每一个检验码Pi所在的位号是2^(i-1),i=1,2,…,k。有效信息位按照原排列顺序依次安排在其他位置上。 假如有七位有效信息位X7X6X5X4X3X2X1=1001101,n=7,可以得出k=4,这样得到的汉明码就是11位,四个校验码P4P3P2P1对应的位号分别是8,4,2,1(即2^3,2^2,2^1,2^0). 11位汉明码的编码顺序为: 位号 11 10 9 8 7 6 5 4 3 2 1 编码 X7 X6 X5 P4 X4 X3 X2 P3 X1 P2 P1 (2)将n+k位汉明码中的每一位分到k个奇偶组中。 对于编码中的任何一位Hm依次从右向左的顺序查看其Mk-1…M1M0的 每一位Mj(j=0,1,…,k-1),如果该位为“1”,则将Hm分到第j组.(如:位号是11可表示成二进制1011,第零位一位三位都是1,所以此编码应排在第0组第1组第3组) 把11~1写成4位二进制的形式,分组结果如下: 位号 11 10 9 8 7 6 5 4 3 2 1 二进制1011 1010 1001 1000 0111 0110 0101 0100 0011 0010 0001 编码 X7 X6 X5 P4 X4 X3 X2 P3 X1 P2 P1 第0组X7 X5 X4 X2 X1 P1 第1组X7 X6 X4 X3 X1 P2 第2组 X4 X3 X2 P3 第3组X7 X6 X5 P4 (3)根据分组结果,每一组按照奇或偶校验求出校验位,形成汉明校验码。若采用奇数校验,则每一组中“1”的个数为奇数,反之为偶数。(X7X6X5X4X3X2X1=1001101) 若用奇校验,则 _________________ P1=X7⊕X5⊕X4⊕X2⊕X1=X7⊙X5⊙X4⊙X2⊙X1=0; 同理可得 P2=1 ; P3=1 ; P4=0 将这些校验码与有效信息位一起排列(分别插入到1,2,4,8位),可以 汉明码编译码 汉明码编译码 一设计思想 汉明码是一种常用的纠错码,具有纠一位错误的能力。本实验使用Matlab平台,分别用程序语言和simulink来实现汉明码的编译码。用程序语言实现就是从原理层面,通过产生生成矩阵,错误图样,伴随式等一步步进行编译码。用simulink实现是用封装好的汉明码编译码模块进行实例仿真,从而验证程序语言中的编译码和误码性能分析结果。此外,在结合之前信源编码的基础上,还可实现完整通信系统的搭建。 二实现流程 1.汉明码编译码 生成矩阵G 信息序列M 产生码字C 信道 计算伴随式S接收码流R 校验矩阵H 解码码流C2 解码信息序列 M2 图 1 汉明码编译码框图 1)根据生成多项式,产生指定的生成矩阵G 2)产生随机的信息序列M 3)由C MG 得到码字 4)进入信道传输 三 结论分析 1. 汉明码编译码 编写了GUI 界面方便呈现过程和结果。 图 2 汉明码编译码演示GUI 界面 以产生(7,4)汉明码为例说明过程的具体实现。 1) 根据生成多项式,产生指定的生成矩阵G 用[H,G,n,k] = hammgen(3,'D^3+D+1')函数得到系统码形式的校验矩阵H 、G 以及码字长度n 和信息位数k 100101101011100010111H ????=?????? 1 10100001101001 1100101010001G ????? ?=?? ?? ?? 2) 产生随机的信息序列M 0010=01000111M ?? ???? ???? 3) 由C MG =得到码字 010001101101000010111C ?? ??=?? ???? 4) 进入信道传输 假设是BSC 信道,错误转移概率设定为0.1 传输后接收端得到的码流为 000011110100000111101R ?? ??=?? ???? 红色表示错误比特。 5) 计算=T S RH 得到伴随式 011=100001S ?? ???? ???? 错误图样 0000001 0000010 0000100 0001000 0010000 0100000 1000000 伴随式 101 111 011 110 001 010 100 查表可知第一行码字错误图样为0100000,第二行码字错误图样为1000000,第三行码字错误图样为0000001。 进行??=+C R E 即可得到纠错解码的码字C2。 6) 得到解码码流 0110100200000001110010C ?? ??=?? ???? MATLAB实现汉明码编码译码 汉明码的编码就是如何根据信息位数k,求出纠正一个错误的监督矩阵H,然后根据H求出信息位所对应的码字。 1、根据已知的信息位数k,从汉明不等式中求出校验位数m=n-k; 2、在每个码字C: 3)用二进制数字表示2m-1列,得到2m-1列和m行监督矩阵H;4)用3步的H形成HCT =0,从而得出m个监督方程; 5)将已知的信息代入方程组,然后求出满足上述方程组的监督位c (i=0,1,?,m一1)。 例如,用以上方法,很容易求出[7,4,3]汉明码的监督矩阵: 11100 H 11010 clear 及编码所对应的码字为C=011001。 m=3; %给定m=3的汉明码 [h,g,n,k]=hammgen(m); msg=[0 0 0 1;0 0 0 1;0 0 0 1;0 0 1 1;0 0 1 1;0 1 0 1;0 1 1 0;0 1 1 1;1 0 0 0;1 0 0 1;1 0 1 0;1 0 1 1;1 1 0 0;1 1 0 1;1 1 1 0;1 1 1 1];code=encode(msg,n,k,'hamming/binary') %编码 C=mod(code*h',2) %对伴随式除2取余数 newmsg=decode(code,n,k,'hamming/binary') %解码 d_min=min(sum((code(2:2^k,: ))')) %最小码距运行结果: >> hangming code = 10001 10001 10001 11001 00111 11000 00110 10011 01110 1111 C = newmsg =111100 00 00 00 00 00 目录 前言...............................................................1第1章设计要求.................................................3第2章 QuartusⅡ软件介绍.......................................4第3章汉明码的构造原理........................................6 3.1 (7,4)汉明码的构造原理........................................6 3.2 监督矩阵H与生成矩阵G.........................................7 3.3 校正子(伴随式S)..............................................8第4章(7,4)汉明码编码器的设计............................10 4.1 (7,4)汉明码的编码原理及方法.................................10 4.2 (7,4)汉明码编码程序的设计...................................10 4.3 (7,4)汉明码编码程序的编译及仿真.............................11第5章(7,4)汉明码译码器的设计...........................12 5.1 (7,4)汉明码的译码方法......................................12 5.2 (7,4)汉明码译码程序的设计..................................13 5.3 (7,4)汉明码译码程序的编译及仿真............................15第6章(7,4)汉明码编译码器的设计........................17 6.1 (7,4)汉明码编译码器的设计..................................17参考文献.........................................................18体会与建议.......................................................19附录..............................................................20 南华大学电气工程学院 《通信原理课程设计》任务书 设计题目:(7, 4)汉明码编译码系统设计 专业:通信工程 学生姓名: 马勇学号:20114400236 起迄日期:2013 年12月20日~2014年1月3日指导教师:宁志刚副教授 系主任:王彦教授 《通信原理课程设计》任务书 《通信原理课程设计》设计说明书格式 一、纸张和页面要求 A4纸打印;页边距要求如下:页边距上下各为2.5 厘米,左右边距各为2.5厘米;行间距取固定值(设置值为20磅);字符间距为默认值(缩放100%,间距:标准)。 二、说明书装订页码顺序 (1)任务书 (2)论文正文 (3)参考文献,(4)附录 三、课程设计说明书撰写格式 见范例 引言(黑体四号) ☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆(首行缩进两个字,宋体小四号) 1☆☆☆☆(黑体四号) 正文……(首行缩进两个字,宋体小四号) 1.1(空一格)☆☆☆☆☆☆(黑体小四号) 正文……(首行缩进两个字,宋体小四号) 1.2 ☆☆☆☆☆☆、☆☆☆ 正文……(首行缩进两个字,宋体小四号) 2 ☆☆☆☆☆☆ (黑体四号) 正文……(首行缩进两个字,宋体小四号) 2.1 ☆☆☆☆、☆☆☆☆☆☆,☆☆☆(黑体小四号) 正文……(首行缩进两个字,宋体小四号) 2.1.1☆☆☆,☆☆☆☆☆,☆☆☆☆(楷体小四号) 正文……(首行缩进两个字,宋体小四号) (1)…… 图1. 工作波形示意图(图题,居中,宋体五号) ………… 5结论(黑体四号) ☆☆☆☆☆☆(首行缩进两个字,宋体小四号) 参考文献(黑体四号、顶格) 参考文献要另起一页,一律放在正文后,不得放在各章之后。只列出作者直接阅读过或在正文中被引用过的文献资料,作者只写到第三位,余者写“等”,英文作者超过3人写“et al”。 几种主要参考文献著录表的格式为: ⑴专(译)著:[序号]著者.书名(译者)[M].出版地:出版者,出版年:起~止页码. ⑵期刊:[序号]著者.篇名[J].刊名,年,卷号(期号):起~止页码. ⑶论文集:[序号]著者.篇名[A]编者.论文集名[C] .出版地:出版者,出版者. 出版年:起~止页码. ⑷学位论文:[序号]著者.题名[D] .保存地:保存单位,授予年. ⑸专利文献:专利所有者.专利题名[P] .专利国别:专利号,出版日期. ⑹标准文献:[序号]标准代号标准顺序号—发布年,标准名称[S] . ⑺报纸:责任者.文献题名[N].报纸名,年—月—日(版次). 附录(居中,黑体四号) 74汉明码编码 1. 线性分组码是一类重要的纠错码,应用很广泛。在(n ,k )分组码中,若 冗余 位是按线性关系模2相加而得到的,则称其为线性分组码。 现在以(7,4)分组码为例来说明线性分组码的特点。 其主要参数如下: 码长:21m n =- 信息位:21m k m =-- 校验位:m n k =-,且3m ≥ 最小距离:min 03d d == 其生成矩阵G (前四位为信息位,后三位为冗余位)如下: 系统码可分为消息部分和冗余部分两部分,根据生成矩阵,输出码字可按下 式计 算: 所以有 信息位 冗余位 由以上关系可以得到(7,4)汉明码的全部码字如下所示。 表2 (7,4)汉明码的全部码字 序号 信息码元 冗余元 序号 信息码元 冗余元 0 0000 000 8 1000 111 1 0001 011 9 1001 100 2 0010 101 10 1010 010 3 0011 110 11 1011 001 4 0100 110 12 1100 001 5 0101 101 13 1101 010 6 0110 011 14 1110 100 7 0111 000 15 1111 111 1000110010001100101110001101G ? ? ?? ?? =?? ???? 3210321010001100100011(,,,)(,,,)00101110001101b a a a a G a a a a ?? ?? ??=?=??? ???? 635241 30 b a b a b a b a ====2310 1321 0210b a a a b a a a b a a a =⊕ ⊕=⊕⊕=⊕⊕ ****************** 实践教学 ******************* 兰州理工大学 计算机与通信学院 2014年春季学期 通信系统仿真训练 题目:汉明码的编译码设计与仿真 专业班级: 姓名: 学号: 指导教师: 成绩: 摘要 与其他的错误校验码类似,汉明码也利用了奇偶校验位的概念,通过在数据位后面增加一些比特,可以验证数据的有效性。利用一个以上的校验位,汉明码不仅可以验证数据是否有效,还能在数据出错的情况下指明错误位置。在接收端通过纠错译码自动纠正传输中的差错来实现码纠错功能,成为前向纠错FEC。在数据链路中存在大量噪音时,FEC可以增加数据吞吐量。通过传输码列中假如冗余位(也称纠错位)。可以实现前向纠错。但这种方法比简单重传协议的成本要高。汉明码利用奇偶块机制降低了前向纠错的成本。利用汉明码(Hamming Code)是一种能够自动检测并纠正一位错码的线性纠错码,即SEC(Single Error Correcting)码,用于信道编码与译码中,提高通信系统抗干扰的能力。本文主要利用MATLAB中通信系统仿真模型库进行汉明码建模仿真,并调用通信系统功能函数进行编程,绘制编译码图。在此基础上,对汉明码的性能进行分析,得出结论。 关键词:MATLAB 汉明码性能 目录 1.前言 (1) 2.汉明码的构造原理 (2) 2.1 汉明码的构造原理 (2) 2.2 监督矩阵H和生成矩阵G (3) 2.3 校正子(伴随式)S (4) 3.汉明码编码器的设计 (6) 3.1 汉明码编码方法 (6) 3.2 汉明码编码程序设计 (6) 3.3 汉明码编码程序的编译及仿真 (7) 4.汉明码的译码器的设计 (10) 4.1 汉明码译码方法 (10) 4.2 汉明码译码程序的设计 (11) 4.3 汉明码译码程序的编译及仿真 (13) 5.总结 (17) 6.参考文献 (18) 7.附录 (19) 汉明码计算及其纠错原理详解 当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错,简单的说,汉明码是一个错误校验码码集,由Bell 实验室的R.W.Hamming 发明,因此定名为汉明码。 汉明码(Hamming Code),是在电信领域的一种线性调试码,以发明者理查德·卫斯里·汉明的名字命名。汉明码在传输的消息流中插入验证码,以侦测并更正单一比特错误。由于汉明编码简单,它们被广泛应用于内存(RAM )。其SECDED (single error correction,double error detection)版本另外加入一检测比特,可以侦测两个或以下同时发生的比特错误,并能够更正单一比特的错误。因此,当发送端与接收端的比特样式的汉明距离(Hamming distance)小于或等于1时(仅有1 bit发生错误),可实现可靠的通信。相对的,简单的奇偶检验码除了不能纠正错误之外,也只能侦测出奇数个的错误。 在数学方面,汉明码是一种二元线性码。对于每一个整数,存在一个编码,带有个奇偶校验位个数据位。该奇偶检验矩阵的汉明码是通过列出所有米栏的长度是两两独立。 汉明码的定义和汉明码不等式:设:m=数据位数,k=校验位数为,n=总编码位数=m+k,有Hamming不等式: a)总数据长度为N,如果每一位数据是否错误都要记录,就需要N位来存储。 b)每个校验位都可以表示:对或错;校验位共K位,共可表示2k种状态 c)总编码长度为N,所以包含某一位错和全对共N+1种状态。 d)所以2k≧N+1 e)数据表见下 无法实现2位或2位以上的纠错,Hamming码只能实现一位纠错。 以典型的4位数据编码为例,演示汉明码的工作 D8=1、D4=1、D2=0、D1=1, P1 =1,P2=0、P3=0。 汉明码处理的结果就是1010101 假设:D8出错,P3’P2’P1’=011=十进制的3,即表示编码后第三位出错,对照存储 clear all; close all; %-------------(7,4)循环汉明码的编码----------------- n=7; k=4; p=cyclpoly(n,k,'all'); [H,G]=cyclgen(n,p(1,:)); Msg=[0 0 0 0;0 0 0 1;0 0 1 0;0 1 0 0;0 1 0 1]; C=rem(Msg*G,2) M=input('M='); disp( '输入信源序列:'); Msg=input('Msg='); C=rem(Msg*G,2) %编码结果 R=7/4*log2(2) %计算码元信息率 %----------- (7,4)循环码的译码------------------- M=input('M='); disp( '输入接收序列:'); Msg=input('Msg='); S=mod(Msg*H',2) for i=1:M if S(i)==[0 0 0] disp('接收码元无错'); Rsg=Msg elseif S(i)==[1 0 0] disp('监督元a0位错'); if Msg(0)==0 Msg(0)=1; elseif Msg(0)==1 Msg(0)=0; end Rsg=Msg elseif S(i)==[0 1 0] disp('监督元a1位错'); if Msg(1)==0 Msg(1)=1; elseif Msg(1)==1 Msg(1)=0; end Rsg=Msg elseif S(i)==[0 0 1] disp('监督元a2位错'); if Msg(2)==0 汉明码编码原理和校验方法 可以利用汉明码来检测并纠错,简单的说,汉明码是一个错误 校验码码集,由Bell实验室的R.W.Hamming发明,因此定名 为汉明码。用于数据传送,能检测所有一位和双位差错并纠正 所有一位差错的二进制代码。汉明码的编码原理是:在n位有 效信息位中增加k为检验码,形成一个n+k位的编码,然后把 编码中的每一位分配到k个奇偶校验组中。每一组只包含以为 校验码,组内按照奇偶校验码的规则求出该组的校验位。 在汉明校验码中,有效信息位的位数n与校验位数K满足下列关系: 2^K-1>=n+k. 1. 校验码的编码方法 (1)确定有效信息位与校验码在编码中的位置 设最终形成的n+k位汉明校验码为Hn+k….H2H1,各位的位号按照从右到左的顺序依次为1,2,…,n+k,则每一个检验码Pi所在的位号是2^(i-1),i=1,2,…,k。有效信息位按照原排列顺序依次安排在其他位置上。 假如有七位有效信息位X7X6X5X4X3X2X1=1001101,n=7,可以得出k=4,这样得到的汉明码就是11位,四个校验码P4P3P2P1对应的位号分别是8,4,2,1(即2^3,2^2,2^1,2^0). 11位汉明码的编码顺序为: 位号 11 10 9 8 7 6 5 4 3 2 1 编码 X7 X6 X5 P4 X4 X3 X2 P3 X1 P2 P1 (2)将n+k位汉明码中的每一位分到k个奇偶组中。 对于编码中的任何一位Hm依次从右向左的顺序查看其Mk-1…M1M0的 每一位Mj(j=0,1,…,k-1),如果该位为“1”,则将Hm分到第j组.(如:位号是11可表示成二进制1011,第零位一位三位都是1,所以此编码应排在第0组第1组第3组) 把11~1写成4位二进制的形式,分组结果如下: 位号 11 10 9 8 7 6 5 4 3 2 1 二进制1011 1010 1001 1000 0111 0110 0101 0100 0011 0010 0001 编码 X7 X6 X5 P4 X4 X3 X2 P3 X1 P2 P1 第0组X7 X5 X4 X2 X1 P1 第1组X7 X6 X4 X3 X1 P2 第2组 X4 X3 X2 P3 第3组X7 X6 X5 P4 (3)根据分组结果,每一组按照奇或偶校验求出校验位,形成汉明校验码。若采用奇数校验,则每一组中“1”的个数为奇数,反之为偶数。(X7X6X5X4X3X2X1=1001101) 若用奇校验,则 _________________ P1=X7⊕X5⊕X4⊕X2⊕X1=X7⊙X5⊙X4⊙X2⊙X1=0; 同理可得 P2=1 ; P3=1 ; P4=0 将这些校验码与有效信息位一起排列(分别插入到1,2,4,8位),可以 (7,4)汉明码编译码原理程序说明书 1、线性分组码 假设信源输出为一系列二进制数字0和1.在分组码中,这些二进制信息序列分成固定 长度的消息分组(message blocks )。每个消息分组记为u ,由k 个信息位组成。因此共有2k 种不同的消息。编码器按照一定的规则将输入的消息u 转换为二进制n 维向量v ,这里n>k 。 此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。因此,对应于2 k 种不同的消息,也有2k 种码字。这2k 个码字的集合就叫一个分组码(block code )。 一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF (2)上所有n 维向量空间的一个k 维子空间时被称为线性(linear )(n ,k )码。 对于线性分组码,希望它具有相应的系统结构(systematic structure ),其码字可分 为消息部分和冗余校验部分两个部分。消息部分由k 个未经改变的原始信息位构成,冗余校 验部分则是n-k 个奇偶校验位(parity-check )位,这些位是信息位的线性和(linear sums )。 具有这样的结构的线性分组码被称为线性系统分组码(linear systematic block code )。 本实验以(7,4)汉明码的编译码来具体说明线性系统分组码的特性。 其主要参数如下: 码长:21m n =- 信息位:21m k m =-- 校验位:m n k =-,且3m ≥ 最小距离: min 03d d == 由于一个(n ,k )的线性码C 是所有二进制n 维向量组成的向量空间n V 的一个k 维子 空间,则可以找到k 个线性独立的码字,0,1,1k g g g -…… ,使得C 中的每个码字v 都是这k 个码字的一种线性组合。 (7,4)汉明码的生成矩阵如下,前三位为冗余校验部分,后四位为消息部分。 0123 1 1 0 1 0 0 00 1 1 0 1 0 01 1 1 0 0 1 01 0 1 0 0 0 1g g G g g ????????????==??????????? ????? 如果()0123u u u u u =是待编码的消息序列,则相应的码字可如下给出: MATLAB 实现汉明码编码译码 汉明码的编码就是如何根据信息位数k ,求出纠正一个错误的监督矩阵H ,然后根据H 求出信息位所对应的码字。 1、根据已知的信息位数k ,从汉明不等式中求出校验位数m=n-k ; 2、在每个码字C :(C1,C2,? ,C2m -1)中,用c02 ,c12 ,cn-12作为监督位,剩下的位作为信息位; 3)用二进制数字表示2m-1 列,得到2m-1列和m 行监督矩阵H ; 4)用3步的H 形成HCT =0,从而得出m 个监督方程; 5)将已知的信息代入方程组,然后求出满足上述方程组的监督位c (i=0,1,? ,m 一1)。 例如,用以上方法,很容易求出[7,4,3]汉明码的监督矩阵: 及编码所对应的码字为C=011001。 clear m=3; %给定m=3的汉明码 [h,g,n,k]=hammgen(m); msg=[0 0 0 1;0 0 0 1;0 0 0 1;0 0 1 1;0 0 1 1;0 1 0 1;0 1 1 0;0 1 1 1;1 0 0 0;1 0 0 1;1 0 1 0;1 0 1 1;1 1 0 0;1 1 0 1;1 1 1 0;1 1 1 1]; code=encode(msg,n,k,'hamming/binary') %编码 C=mod(code*h',2) %对伴随式除2取余数 newmsg=decode(code,n,k,'hamming/binary') %解码 d_min=min(sum((code(2:2^k,:))')) %最小码距 运行结果: >> hangming code = 1 0 1 0 0 0 1 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 1 1 1 0 0 1 0 1 1 0 0 0 1 1 0 0 0 1 0 1 1 1 ???? ??????=101100111010101110100H 科信学院 通信系统仿真二级项目设计说明书 (2013/2014学年第二学期) 课程名称:通信系统仿真二级项目 题目:基于M语言的数字通信仿真— 采用Hamming码技术 专业班级:通信工程12-02班 学生姓名: 学号: 指导教师: 设计周数:1周 设计成绩: 2014年6月25日 目录 1、设计目的和意义 (2) 2、设计原理 (3) 2.1 汉明编码 ................................................. 错误!未定义书签。 2.1.1汉明码编码.................................................................................... 错误!未定义书签。 2.1.2 汉明码的定义: (3) 2.1.3 汉明码的构造特点: (3) 2.1.4 汉明码编码的主要算法 (3) 2.1.5 汉明码的编码原理 (4) 2.1.6 汉明码的纠错原理 (6) 2.2高斯噪声原理................................................ 错误!未定义书签。 3、Matlab仿真实现 (12) 3.1 仿真思路 (12) 3.2仿真详细过程及图形分析 ........................ 错误!未定义书签。 3.3 仿真结果分析 ........................................... 错误!未定义书签。 4、设计心得体会 (21) 5、参考文献 (21) 1、设计目的和意义 技术要求及原始数据: 1)对数字通信系统主要原理和技术进行研究,包括Hamming编码技术和高斯噪声信道原理等。 2)建立完整的基于Hamming码技术的通信系统仿真模型。 3)对系统进行仿真、分析。 主要任务: 1)建立数字通信系统模型。 2)利用Matlab的m语言建立数字通信系统仿真模型。 汉明码(Hamming)的编码和译码算法 本文所讨论的汉明码是一种性能良好的码,它是在纠错编码的实践中较早发现的一类具有纠单个错误能力的纠错码,在通信和计算机工程中都有应用。例如:在“计算机组成原理”课程中,我们知道当计算机存储或移动数据时,可能会产生数据位错误,这时可以利用汉明码来检测并纠错。简单的说,汉明码是一个错误校验码码集,由Bell实验室的R.W.Hamming发明,因此定名为汉明码。如果对汉明码作进一步推广,就得出了能纠正多个错误的纠错码,其中最典型的是BCH码,而且汉明码是只纠1bit错误的BCH码,可将它们都归纳到循环码中。 各种码之间的大致关系显示如下。 一、汉明码的编码算法 输入:信源消息u(消息分组u) 输出:码字v 处理: 信源输出为一系列二进制数字0和1。在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks)。每个消息分组记为u,由k个信息位组成。因此共有2k种不同的消息。编码器按照一定的规则将输入的消息u转换为 二进制n 维向量v ,这里n >k 。此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。 因此,对应于2k 种不同的消息,也有2k 种码字。这2k 个码字的集合就叫一个分组码(block code )。若一个分组码可用,2k 个码字必须各不相同。因此,消息u 和码字v 存在一一对应关系。由于n 符号输出码字只取决于对应的k 比特输入消息,即每个消息是独立编码的,从而编码器是无记忆的,且可用组合逻辑电路来实现。 定义:一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF(2) 上所有n 维向量组成的向量空间的一个K 维子空间时被称为线性(linear )(n, k)码。 汉明码(n ,k ,d )就是线性分组(n, k)码的一种。其编码算法即为使用生成 矩阵G :v = u ·G 。 例1-1:针对汉明码Hamming (7,4,3)而言,u =(u 0,u 1,u 2,u 3), v =(v 0,v 1,v 2,v 3,v 4,v 5,v 6),则我们有 (v 0,v 1,v 2,v 3,v 4,v 5,v 6)=(u 0,u 1,u 2,u 3) ·G 。 Hamming (7,4,3) 的生成矩阵G 为: G =????? ???? ???11 1 01101001 1100101010001, (v 0,v 1,v 2,v 3,v 4,v 5,v 6) =(u 0,u 1,u 2,u 3) ·????? ???? ???11 1 01101001 110010 1010001, 所以我们有: v 0= u 0, v 1= u 1, v 2= u 2, v 3= u 3, v 4= u 0+u 1+u 2, v 5= u 1+u 2+u 3, v 6=u 0+u 1+u 3, (7,4)汉明码编解码器的设计 序言 VHDL语言具有功能强大的语言结构,可用明确的代码描述复杂的控制逻辑设计,并且具有多层次的设计描述功能,支持设计库和可重复使用的元件的生成。近几十年来,EDA技术获得了飞速发展。它以计算机为平台,根据硬件描述语言VHDL,自动地完成逻辑编译、化简分割、综合及优化,布局布线,仿真直至对特定目标芯片的适配编译,逻辑映射和编程下载等工作。以自顶向下的设计方法,使硬件设计软件化,摆脱了传统手工设计的众多缺点。随着EDA技术的深入发展基于硬件描述语言的方法将有取代传统手工设计方法的趋势。 EDA ( Elect ronics Design Automation) 技术是随着集成电路和计算机技术飞速发展应运而生的一种高级、快速、有效的电子设计自动化工具。目前,VHDL语言已经成为EDA的关键技术之一,VHDL 是一种全方位的硬件描述语言,具有极强的描述能力,能支持系统行为级、寄存器传输级和逻辑门级三个不同层次的设计,支持结构、数据流、行为三种描述形式的混合描述,覆盖面广,抽象能力强,因此在实际应用中越来越广泛。 汉明码是在原编码的基础上附加一部分代码,使其满足纠错码的条件。它属于线性分组码,由于汉明码的抗干扰能力较强,至今仍是应用比较广泛的一类码。 本文用VHDL语言实现了(7,4)汉明码的编码和译码,并通过实例来说明利用VHDL语言实现数字系统的过程。在介绍(7,4)汉明码编码和译码原理的基础上,设计出了(7,4)汉明码的编码器和译码器,写出了基于VHDL实现的源程序,并通过QUARTUSⅡ软件进行仿真验证。 第1章QuartusⅡ与VHDL简介 1.1 QuartusⅡ软件简介 QuartusⅡ是Altera公司推出的CPLD/FPGA的开发工具,QuartusⅡ提供了完全集成且与电路结构无关的开发环境,具有数字逻辑设计的全部特性。 ?/P> Quartus Ⅱ设计软件提供完整的多平台设计环境,可以很轻松地满足特定设计的需要。实验四 汉明码系统
汉明码编译码
汉明码编码实验报告
基于MATLAB的(7_4)汉明码编译码设计与仿真结果分析
汉明码编译码实验
汉明码原理和校验
汉明码编译码
MATLAB实现汉明码编码译码
通信原理设计报告(7_4)汉明码的编解码设计
(7,4)汉明码编译码系统设计.doc
74汉明码编码原理
汉明码的编译码设计与仿真
汉明码计算及其纠错原理详解
74循环汉明码编码及译码
汉明码原理和校验
(7,4)汉明码编译码程序说明
MATLAB实现汉明码编码译码
汉明码
汉明码的编码和译码算法
基于VHDL的(7,4)汉明码编解码器的设计