MEGA计算序列间遗传距离

序列间遗传距离的计算
1. 导入比对好的“*.meg”格式数据。
2. 数据划分
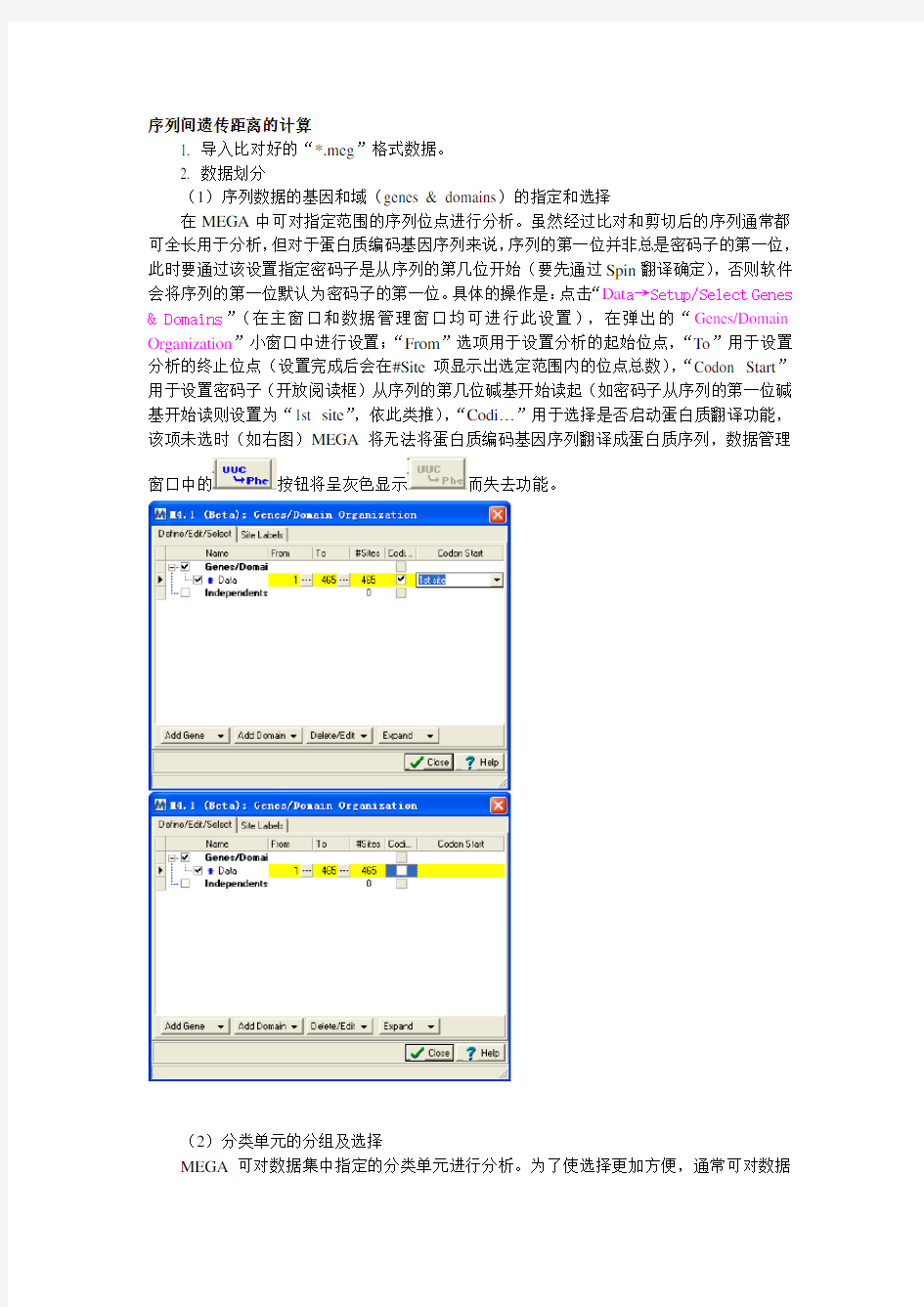
(1)序列数据的基因和域(genes & domains)的指定和选择
在MEGA中可对指定范围的序列位点进行分析。虽然经过比对和剪切后的序列通常都可全长用于分析,但对于蛋白质编码基因序列来说,序列的第一位并非总是密码子的第一位,此时要通过该设置指定密码子是从序列的第几位开始(要先通过Spin翻译确定),否则软件会将序列的第一位默认为密码子的第一位。具体的操作是:点击“Dat a→Setup/Select Genes & Domains”(在主窗口和数据管理窗口均可进行此设置),在弹出的“Genes/Domain Organization”小窗口中进行设置;“From”选项用于设置分析的起始位点,“To”用于设置分析的终止位点(设置完成后会在#Site项显示出选定范围内的位点总数),“Codon Start”用于设置密码子(开放阅读框)从序列的第几位碱基开始读起(如密码子从序列的第一位碱基开始读则设置为“1st site”,依此类推),“Codi…”用于选择是否启动蛋白质翻译功能,该项未选时(如右图)MEGA将无法将蛋白质编码基因序列翻译成蛋白质序列,数据管理
窗口中的按钮将呈灰色显示而失去功能。
(2)分类单元的分组及选择
MEGA可对数据集中指定的分类单元进行分析。为了使选择更加方便,通常可对数据
的分类单元进行分组(groups),分组的具体操作是:点击“Dat a→Setup/Select Taxa & Groups”(在主窗口和数据管理窗口均可进行此设置),在弹出来的“Setup/Select Taxa & Groups”小窗口中根据分析需要对分类单元进行分组,选择需要分析的数据组,点击右下角的“Close”按钮关闭小窗口,即可对选定的组进行相关分析。
(3)已分组数据的保存
为了保存已经指定的数据分组,在关闭活动数据文件(active data file;在主窗口中用“Fil e →Close Data……Alt+F5”关闭文件或直接关闭MEGA软件)前必须将数据输出另存,否则分组信息不会直接保存在原始序列文件中。
注意,在保存数据时必须确认数据中的所有分类单元都被选定(即在“Setup/Select Taxa & Groups”小窗口左边的“Taxa/Groups”框中选定“All”选项),否则输出的数据文件中将只能保存分析时选定的数据部分。
3. 成对序列遗传距离计算
点击“Distanc e→Compute Pairwise F7”菜单命令,弹出分析选择(Analasys Preference)窗口(也可称为参数设置窗口),可通过点击各选项右边的下拉菜单(pull-down menu)完成设置。各种参数的设置方法如下:
“Compute”参数设置:该设置有两个选项,选择“Distances only”时只计算遗传距离;选择“Distances & Std. Err.”时在计算遗传距离的同时还计算标准误差,此时会增加一项设置误差计算参数的选项,可以调节。一般选择“Distances only”即可。
“Include sites”参数设置:该设置包括“Gaps/Missing Data”和“Codon Positions”两项。“Gaps/Missing Data”用来设置空位处理原则:若选“Complete Deletion”则在计算遗传距离时凡有任一序列具空位的位点都不予计算;若选“Parwise Deletion”则在计算两条序列的遗传距离时仅不计算两条序列中的任一条具空位的位点,对于两条序列都不具空位的位点,即使数据集中的其它序列存在空位,也不删除;一般情况下都选“Parwise Deletion”。“Codon Positions”用来设置计算遗传距离时使用的密码子位点,可以根据需要选择使用密码子中的任意一位或几位或全部位点来计算遗传距离;通常可考虑用不同位点分别计算并进行对比。
“Substitution Model”参数设置:该设置包括“Model”和“Substitutions to Include”两项。“Model”选项用来选择计算遗传距离时使用的计算模型:点击“Model”选项右边的
图标,在下拉菜单(pull-down menu)“Nucleotid e→[距离模型,如p-distance、Kimura 2-parameter等]”中选择合适的计算遗传距离的模型(理论上应先用Modeltest检验各种模型,然后选择最适模型进行计算,但在通常情况下选择较简单的模型即可,如p-distance、K2P模型等;“Number of differences”是一种根据序列间不同碱基的数量来计算遗传距离的模型,选用此模型时则“Gaps/Missing Data”选项应设置为“Complete Deletion”)。“Substitutions to Include”用来选择计算遗传距离时使用的碱基替换信息:“d: Transitions+Transversions”表示同时利用转换和颠换值来计算遗传距离,“s: Transitions only”表示仅用转换值来计算遗传距离,“v: Transversions only”表示仅用颠换值来计算遗传距离,“R=s/v”表示用转换颠换比值来计算遗传距离(“L: No. of Valid Common Sites”表示用普通有效位点来计算遗传距离?)。
所有参数设置完成后点击窗口右下方的即开始计算,结果将在新窗口
中显示(该窗口最小化隐藏后可从主窗口上方
的“Windows”菜单中恢复),将结果另存备用即可。
* 利用窗口上方的快捷图标(shortcuts)可选择显示格式和保存格式,如点击图标可使
遗传距离值显示在左下方(lower left),点击图标可使使遗传距离值显示在右上方(upper right),利用图标可减少(decrease)或增加(increase)小数(decimal)的位数,
点击图标将以文本格式输出计算结果,点击图标将以Excel格式输出计算结果。点击任何一个输出格式选择图标都会弹出遗传距离输出选择窗口(Distance Write-out Options),点击的图标代表的格式为该窗口中的默认输出格式,若想改变输出格式,可点击该窗口中
Output Format选项框右边的按钮,在下拉菜单中选择其它输出格式。
4. 序列总体平均遗传距离:
点击“Distanc e→Compute Overall Mean”菜单命令,在弹出的分析选择(Analasys Preference)窗口(也可称为参数设置窗口)中设置各种参数,点击窗口右下方的
,保存计算结果备用。
5. 替换饱和性分析(重要)
(1)计算序列的校正遗传距离:在进行“成对序列遗传距离计算”时将“Substitution Model”
参数设置中的“Model”选项设置为Kimura 2-parameter(也可根据需要选用其它模型,但后面的颠转换、颠换遗传距离计算也要选用同一模型),“Substitutions to Include”
选项设置为“d: Transitions+Transversions”,计算所得的遗传距离作为替换饱和性分析的校正距离,以“*.xls”格式保存备用(输出时MEGA会自动将对角矩阵转换成一列数据)。
(2)计算序列的转换遗传距离:在进行“成对序列遗传距离计算”时将“Substitution Model”
参数设置中的“Model”选项设置为Kimura 2-parameter(一定要与计算校正距离时选用的模型相同),“Substitutions to Include”选项设置为“s: Transitions only”,计算所得的遗传距离即为替换饱和性分析的转换距离,以“*.xls”格式保存备用。
(3)计算序列的颠换遗传距离:在进行“成对序列遗传距离计算”时将“Substitution Model”
参数设置中的“Model”选项设置为Kimura 2-parameter(一定要与计算校正距离时选用的模型相同),“Substitutions to Include”选项设置为“v: Transversions only”,计算所得的遗传距离即为替换饱和性分析的颠换距离,以“*.xls”格式保存备用。
注意:以上分析可选择不同的模型进行比较,看结果是否有差异。
(4)Excel作图,用直观坐标图显示替换饱和性状态。
①导入数据:将上述三种遗传距离导入同一个Excel文件中,按相同的顺序排成三列,列与列之间不要留下空白列,每一列数据的标识符号(名称)放在该列的顶端(第一行),校正距离放在第一列(因为Excel作图时一般将第一列默认为横坐标)。
②作图:选定三列数据,点击主菜单中的“插入→图表”,在弹出的“图表向导-图表类型”窗口中选择“标准类型”中的“XY散点图”(在进行其它数据分析时可根据需要选择其它图表类型,包括“自定义”类型),点击“下一步”;在“图表源数据”窗口中点击“下一步”;在“图表选项”窗口中设置需要在图表中显示的各种选项:在“标题”标签中可设置“图表标题”、“数值(X)轴(A)”标题、“数值(Y)轴(V)”标题,在“坐标轴”标签中可设置“显示/隐藏坐标轴上的数值”,在“网格线”标签中可设置“显示/隐藏网格线”,在“图例”标签中可设置“显示/隐藏图例”以及图例与图表的相对位置(包括“底部、右上角、靠上、靠右、靠左”等选项),在“数据标志”标签中可设置“数据标签”(该项设置只有在数据较少时为了方便识别数据才选用,一般情况下均不予选择),点击“下一步”;在“图表位置”窗口选择图表插入的具体位置,一般选择默认选项“作为其中的对象插入(O)”,点击完成,即会在Excel表中插入一个生成的图表;该图表可直接复制插入到Word文档中使用,也可在Photoshop软件中转换成独立的“*.jpg”文件保存备用,需要时再插入Word 文档中。
注意:该项分析也可在其它一些软件中进行。如DAMBE,但可供选用的模型在不同软件中有所不同;选择不同密码子的方法是:点击命令“Sequence s→work on codon position 1/2/3/1+2”,用“Sequence s→Restore sequences”命令可恢复全序列进行分析;碱基替换饱和性分析的方法是:打开序列数据→点击命令“Graphics→transition and transversion versus divergence”,在弹出来的小窗口中选择参数设置,点击“Go”按钮,分析结果将显示在一个新的“Graph Tool”窗口中。图形文件的输出:在“Graph Tool”窗口中点击“File →Save file in metafile format”即可将分析结果保存为“*.WMF”格式的图形文件;若选择“File→Save file in bitmap format”,则保存为“*.bmp”格式的图形文件,文件较
小,但分辨率较低,不能满足发表论文的需要。要编辑坐标轴则点击“Graphic→……”菜单进行选择。若要将分析结果以遗传距离的形式保存,则在“Graph Tool”窗口中点击“Edit →Copy data to EXCEL”,然后创建一个“*.xls”文档,将数据粘贴到新建的“*.xls”文档中即可。使用DAMBE进行碱基替换饱和性分析的优点是可以直接输出图形文件,对大型数据矩阵特别方便,缺点是以EXCEL格式输出遗传距离值时没有同时输出物种对名称;若要将遗传距离与物种对对应起来,需要使用其它命令或方法。
DNA序列组成及变异分析
* 这些分析通常可以在MEGA软件中进行,也可以在其它相关软件中实现,如DAMBE等。
用MEGA进行数据分析时,输入的数据必须是“*.meg”格式文件,否则不能识别,所以在分析数据前要先将其它格式文件转换成“*.meg”格式文件。MEGA可以将多种格式的序列文件(*.fasta、*.aln、*.nexus、*.phylip、*.phylip2、*.gcg、*.pir、*.nbrf、*.msf、*.ig和*.xml格式)转换成“*.meg”格式,不论其是否已经比对好。所以,用MEGA 转换序列数据格式之前要先将序列比对好并删除引物序列。许多人通常喜欢将比对整理好的序列保存为“*.fasta”格式,因为这种格式更加通用,而且其它格式的文件均可由此格式通过一定的软件或批处理文件转换生成。
* MEGA(Molecular Evolutionary Genetics Analysis; https://www.360docs.net/doc/fc16111374.html,/)是一个不断更新的软件,如果启动该软件时出现“The current test version of MEGA may be out of date (release #4104). We recommend that you obtain an updated version from https://www.360docs.net/doc/fc16111374.html, or https://www.360docs.net/doc/fc16111374.html,”, 可考虑重新下载新版本安装,也可点击“OK”后忽略。
一、转换文件格式
1. 运行MEGA 4.1。
2. 导入数据。点击MEGA 4.1主窗口左上角工具栏中的“Text Editor and Format Convertor”
图标(或点击“Fil e→Text Editor...F3”),在弹出来的“Text File Editor and Format Convertor”窗口中点击“Fil e→Open”或直接点击窗口左上角工具栏中的“Open a file
(Ctrl+0)”图标,选择并打开需要转换的序列文件。
* “Text Editor and Format Convertor”窗口最小化隐藏后可点击MEGA主窗口中的“Text Editor and Format Convertor”图标和随之显示在主窗口左下角的该窗口的最小化图标
来恢复,也可点击主窗口中的“Fil e→Text Editor (3)
菜单命令,然后点击显示在主窗口左下角的该窗口的最小化图标
来恢复。在用MEGA的数据处理窗口“View Sequence Data”进行统计分析时,若选择了“Statisti c→Display Results in Text Editor”设置,即在“Text Editor and Format Convertor”窗口中显示结果,窗口最小化隐藏后又需要重新使用时也是用同样的方法来激活恢复。
3. 点击“Text File Editor and Format Convertor”窗口左上角工具栏中的“Convert to MEGA
format (Contrl+M)
”图标或使用菜单命令“Utilitie s→Convert to MEGA format Contrl+M”,在弹出来的“Select File and Format”小窗口中点击“OK”即可完成文件转换。
* 一步转换的方法是:在MEGA 4.1主窗口中点击“Fil e→Convert To MEGA format”,在弹出来的“Select File and Format”小窗口中点击“Data file to convert”选项栏右侧的“open”
图标,然后在弹出来的“Choose a File to Convert”窗口中选择需要转换的序列文件,
点击“打开”按钮,再点击“Select File and Format”小窗口中的“OK”按钮即完成文件格式转化。
4. 检查文件内容,删除多余的符号如“#”和“*”等(这些多余信息通常出现在文件末尾,
若不检查删除,MEGA可能在导入文件时无法识别,从而出错),将文件保存到指定的文
件夹,关闭文件转化窗口。另外,序列名称或编号中也不能出现“?、-、*和#”等符号,
否则可能导致出现“序列长度不相等”之类的错误警报。
* 若在转化文件格式时确实忘记了检查删除多余信息而导致分析数据时打不开“*.meg”格
式的文件,可用下述方法重新检查:在主窗口中点击“Fil e→Text Editor… F3”打开
“Text File Editor and Format Convertor”窗口,点击工具栏中的快捷图标(Open a file (Ctrl+0))打开序列文件,检查数据并删除多余的干扰信息,保存并退出该窗口即可重
新导入数据进行后面的分析。
* 如果要省去文件格式转换的麻烦,在序列数目较少时可直接将“*.fasta”格式文件导入MEGA进行比对,然后以“*.meg”格式保存即可;具体操作见“用MEGA软件比对序列”。因这样做并没有使整个操作步骤简化多少,还要重新比对序列(而大多数人更习惯
在Clastal软件中比对序列),所以通常没有必要采用这种方法来转换文件格式。
二、DNA序列的碱基组成及变异分析
1. 导入数据
在MEGA主窗口中点击“File→Open Data F5”,打开待分析序列的“.meg”文件;
在弹出来的“Input Data”小窗口中选择“Data type”,如“Nucleotide Sequence”、“Protein Sequences”、“Pairwise Distance”等,点击“OK”按钮;在弹出来的(popped up)“Confirm”
小窗口中出现提问“Protein-coding nucleotide sequence data?”,若为蛋白质编码序列则点击“Yes”,若为非蛋白质编码序列则点击“No”按钮;在弹出来的“Select Genetic Code”小
窗口中选择“Invertebrate Mitochondial”,点击“OK”按钮,即出现“View Sequence Data”
窗口(数据处理窗口);该窗口最小化后可点击MEGA主窗口左上角工具栏中的“Explore active data(F4)”图标来恢复,也可点击主窗口上方主菜单中的“Dat a→Data explorer F4”来直接恢复。
* 除了上述方法(包括使用快捷键F5)外,还可点击主窗口中的链接
来打开数据文件,其它操作相同。
2. 计算保守位点(conserved sites)、变异位点(variable sites)、简约
信息位点(parsimony-informative sites)。
这些统计数值可以通过点击数据处理窗口工具栏中的相应图标来显示在窗口的最下方,也可以通过点击“Highlign t→……”菜单命令来显示,将显示结果记录下来备用即可。例如,将鼠标选中某一个碱基,在窗口的左下角就会显示该碱基所在序列的长度及该碱基在序列中的位置(1/465表示该序列长为465pb,选中的碱基是该序列的第一位碱基;Conserved: 278/465表示分析的序列长465bp,保守位点278个);其它统计类推。
* 工具栏中各快捷图标的含义分别为:保守位点Conserved sites—C,变异位点variable sites—V,简约信息位点parsimony-informative sites—Pi,自裔位点Singleton site—S,0-fold Degenerate sites—0,2-fold Degenerate sites—2,4-fold Degenerate sites—4。将鼠标移到相应的快捷图标上时,会短暂显示“Mark conserved sites”、……等字样,由此可知该图标的具体功能。
* Degeneracy(密码子的简并性)
0-fold degenerate sites are those at which all changes are nonsynonymous. (非简并性位点)
2-fold degenerate sites are those at which one out of three changes is synonymous. (All sites at which two out of three changes are synonymous also are included in this category.) (二重简并位点)
4-fold degenerate sites are those at which all changes are synonymous. (四重简并位点)
* Singleton Sites(自裔位点)
A singleton site contains at least two types of nucleotides (or amino acids) with, at most, one
occurring multiple times. MEGA identifies a site as a singleton site if at least three sequences
contain unambiguous nucleotides or amino acids.
* 工具栏其它快捷图标的含义及对应的菜单命令如下:
对应于“Dat a→Export data”菜单命令,可将序列比对结果以“*.meg”格式文件输出保存。点击该图标后会弹出“Text File Editor and Format Convertor”窗口,点击“Save a file(Ctrl+S)”图标即可将文件保存到指定的位置,文件名可自己拟定。
与上面的图标功能相同。
对应于“Statistics→Desplay Results in Excel(XL)”菜单命令。
对应于“Statistics→Desplay Results in Comma-delimited(CSV)”菜单命令。
对应于“Dat a→Set up/Select Taxa & Groups”菜单命令,点击该图标后会弹出“Select/Edit Taxa Groups”窗口,在该窗口中可对需要分析的分类单元进行分组或选择已划分的全部或部分组进行分析。
对应于“Dat a→Set up/Select Genes & Domains”菜单命令。
对应于“Display→Use Identical Symbol”菜单命令;该图标凸显时导入的序列全部以碱基符号显示;
* 点击该图标使其凹显()时,导入的序列将会以第一条序列为参照,凡是与第一条序列相同的碱基则以一致性符号“.”显示,不相同的碱基以碱基符号显示;输出时可根据需要选择显示形式。
对应于“Dat a→Translate/Untranslate T”菜单命令,突出显示,表示序列正在以核苷酸的形式显示(如下图),点击该图标后可将核苷酸序列翻译成蛋白质序列显
示出来,图标变为凹陷显示。
对应于“Dat a→Translate/Untranslate T”菜单命令,凹陷显示,表示序列正在以氨基酸的形式显示,点击该图标后可将蛋白质序列恢复成核苷酸序列显示出来,图
标变为凸出显示形式。
对应于“Displa y→Find Sequence (Ctrl+F)”菜单命令,可以查找序列。
3. 计算DNA序列碱基组成
在“View Sequence Data”窗口(即数据处理窗口)中点击“Satistics→Desplay Results in Text Editor”,将统计结果设置为在“Text File Editor and Format Convertor”窗口中显示(也可以根据需要将统计结果设置为以“Excel”形式或“Comma-delimited format”形式显示);
点击“Satistics→Nucleotide Composition”,软件将会在内置文本编辑器(built-in text editor)“Text File Editor and Format Convertor”窗口中显示碱基组成分析结果,保存文件备用(分析结果包括碱基总数,每种碱基的百分比,各碱基在密码子第1位、第2位、第3位的使用频率)。
* “Text Editor and Format Convertor”窗口最小化隐藏后可点击MEGA主窗口中的“Text Editor and Format Convertor”图标和随之显示在主窗口左下角的该窗口的最小化图标
来恢复,也可点击主窗口中的“Fil e→Text Editor (3)
菜单命令,然后点击显示在主窗口左下角的该窗口的最小化图标
来恢复。
4. 计算密码子使用情况:
点击“Satistics→Codon Usage”,软件将会在“Text File Editor and Format Convertor”窗口中显示密码子使用分析结果,保存文件备用(分析结果包括碱基总数,每种碱基的百分比,各碱基在密码子第1位、第2位、第3位的使用频率)。
* 计算“密码子使用”情况时,必须先指定密码子在序列中的起点(第一位、第二位、第三位或其它位置),具体操作见“序列遗传距离的计算”中的“2. 指定序列数据的起始及终止位点”。
5. 计算碱基对频率(Nucleotide Pair Frequencies)
点击“Satistics→Nucleotide Pair Frequenc y→Directional(16 Pairs)或Undirectional (10 Pairs)”,统计结果将显示在“Text Editor and Format Convertor”窗口中,保存备用即可。
* 用此菜单命令计算获得的转换/颠换比值(R)将作为后面利用PAUP软件进行系统发育分析时确定是否对数据进行加权的参考依据。
* Directional (16 Pairs)是指定向的替换;Undirectional(10 Pairs)是指不定向的替换。
6. 碱基替换模式检验
用此数据处理窗口中的“Statistical→Nucleotide Pair Frequency→……”菜单命令计算的“转换/颠换值”是转换/颠换位点的数量比值,而用主窗口中的“Pattern→……”菜单命令可以计算有关碱基替换模型的一些其它统计数值(statistical quantities)
(1)序列间替换模式的同质性检验(Test of the homogeneity of Substitution Patterns between Sequences.)
点击“Pattern→Test Substitution Pattern Homogeneity……”菜单命令,在弹出来的分析选择(Analysis Preferences)窗口中设置相关选项:“Gap/Missing”选项一般选“Pairwise Deletion”,“Codon Positions”可根据需要选择密码子第一位、第二位、第三位或任意两位的组合或全选;设置完成后点击窗口右下角的“Compute”按钮,计算结果将会在一个新窗口中显示保存结果备用。
该菜单命令计算所得的数值(statistical quantities)表示:根据序列间碱基组成偏倚差异程度推断时拒绝零假说(null hypothesis,即序列以相同的替换模式进化)的概率。用Monte Carlo test (1000 replicates)估算P-值,P-值显示在表格的左下方(below the diagonal);P-值小于0.05使被认为显著(用黄色标记)。每对序列对的平均位点差异系数显示在表格的右上方(above the diagonal)[The probability of rejecting the null hypothesis that sequences have evolved with the same pattern of substitution, as judged from the extent of differences in base composition biases between sequences (Disparity Index test, [1]). A Monte Carlo test (1000 replicates) was used to estimate the P-values [1], which are shown below the diagonal. P-values smaller than 0.05 are considered significant (marked with yellow highlights) The estimates of the disparity index per site are shown for each sequence pair above the diagonal. ]
(2)序列间碱基组成偏倚差异估算(Estimates of Base Composition Bias Difference between Sequences)
点击“Pattern→Compute Composition Distance……”菜单命令,其它操作与“序列间替换模式的同质性检验”相同。
(3)序列间碱基组成净差估算(Estimates of Net Base Composition Bias Disparity between Sequences)
点击“Pattern→Compute Pattern Disparity Index……”菜单命令,其它操作与“序列间替换模式的同质性检验”相同。
(4)核苷酸替换模式的最大复合似然法估算(Maximum Composite Likelihood Estimate of the Pattern of Nucleotide Substitution)
点击“Pattern→Compute Substitution Pattern (4×4)……”或“Pattern→Compute Transition/Transversion Bias (R)……”菜单命令,其它操作与“序列间替换模式的同质性检验”相同。
* 用此菜单命令计算所得的“总体转换/颠换偏倚”(The overall transition/transversion bias)值R是根据转换/颠换速率(The transition/transversion rate tatios)计算出来的,与根据“碱基对频率”计算中的“转换/颠换”位点数计算出来的R值不同。
遗传学名词解释
1 Chromosomal disorders:染色体结构和数目异常而导致的疾病。如Down’s综合征(+21),猫叫综合征(5p-)。 2 Single gene disorders: 由于控制某个性状的等位基因突变导致的疾病称之。 3 Polygenic disorders:一些常见病和多发病的发生由遗传因素和环境因素共同决定,遗传因素中不是一对等位基因,而是多对基因共同作用于同一个性状。 4 Mitochondrial disorders:是指线粒体DNA上的基因突变导致所编码线粒体蛋白质结构和数目异常,导致线粒体病。线粒体是位于细胞质中的细胞器,故随细胞质(母系)遗传。 4 Somatic cell disorders: 体细胞中遗传物质突变导致的疾病。 5 分离律 (Law of segregation)基因在体细胞内成对存在,在生殖细胞形成过程中,同源染色体分离,成对的基因彼此分离,分别进入不同的生殖细胞。细胞学基础:同源染色体的分离。 6 自由组合律(law of independent assortment)在生殖细胞形成过程中,不同的非等位基因,可以相互独立的分离,有均等的机会组合到—个生殖细胞的规律性活动。 7 连锁与互换定律-(law of linkage and crossing over)位于同一染色体上的两个基因,在生殖细胞形成时,如果它们相距越近,一起进入同一生殖细胞的可能性越大;如果相距较远,它们之间可以发生交换。 8 Gene mutation: DNA分子中的核苷核序列发生改变,导致遗传密码编码信息改变,造成基因表达产物蛋白质的氨基酸变化,从而引起表型的改变。 9 Point mutation:指单个碱基被另一个碱基替代。转换(transition):嘧啶之间或嘌呤之间的替代。颠换(transversion):嘧啶和嘌呤之间的替代。 10 Same sense mutation:碱基替换后,所编码的氨基酸没有改变。多发生于密码子的第三个碱基。 11 Missense mutation:碱基替换后,改变了氨基酸序列。错义突变多发生于密码子的第一、二个碱基 12 Nonsense mutation:碱基替换后,编码氨基酸的密码子变为终止密码子(UAA、UGA、UAG),多肽链合成提前终止。 13 Frame shift mutation:在DNA编码序列中插入或丢失一个或几个碱基,造成插入或缺失点下游的DNA编码框架全部改变,其结果是突变点以后的氨基酸序列发生改变 14 dynamic mutation :人类基因组中的一些重复序列在传递过程中重复次数发生改变导致遗传病的发生,称动态突变。
镜头角度与距离计算方法
监控摄像头镜头可视角度表 镜头焦距搭配1/3" CCD搭配1/4" CCD二者的角度差异 2.8 mm89.9°75.6°14.3° 3.6 mm75.7°62.2°13.5° 4 mm69.9°57.0°12.9° 6 mm50.0°39.8°10.2° 8 mm38.5°30.4°8.1° 12 mm26.2°20.5° 5.7° 16 mm19.8°15.4° 4.4° 25 mm10.6°8.3° 2.3° 60 mm 5.3° 4.1° 1.2° 监控摄像头镜头可视距离表 镜头焦 距(毫米数) 距离5米 (宽×高) 距离10米 (宽×高) 距离15米 (宽×高) 距离20米 (宽×高) 距离30米 (宽×高) 2.8mm13×9.8米26×19.5米39×29.3米52×39米78×58.5米 3.6mm8.5×6.4米17×12.8米25.5×19米34×25.5米51×38.3米4mm8×6米16×12米24×18米32×24米48×36米
6mm 5.5×4.1米11×8.3米16.5×12.4米22×16.5米33×24.8米8mm 3.5×2.6米7×5.3米10.5×7.9米14×10.5米21×15.8米12mm2×1.5米4×3米6×4.5米8×6米12×9米16mm 1.5×1.1米3×2.3米 4.5×3.4米6×4.5米9×6.8米25mm 1.3×1米 2.5×1.9米 3.8×2.9米5×3.8米7.5×5.6米60mm0.5×0.4米1×0.75米 1.5×1.1米2×1.5米3×2.3米
摄像机选型、安装需要考虑的几个问题 摄像机选型、安装通常有八点需要考虑,具体如下(1)应根据监控目标的的照度选着不同灵敏度的摄像机。监控目标的最低环 境照度应高于摄像机最低照度的10倍。 监视目标的照度要求与摄像机的灵敏度密切相关,通常闭路 电视监控系统是由被监视视场所监视时刻的自然光,一般画 面的典型照度见表1-1 表1-1 一般画面的典型照度 各种天气下的自然光照度值照度估计值(lx) 直射阳光100000—130000 晴天(非阳光直射)10000—20000 阴天1000 工作场所内(白天)200—400 非常阴暗的白天100 黄昏(拂晓)10 入夜1 满月0.1 弦月0.01 没有月亮的晴朗夜空0.001 没有月亮的多云夜空0.0001 监视目标的最低环境照度应高于摄像机最低照度的10倍以上,
遗传学名词解释大全
autoregulation 自我调节:基因通过自身的产物来调节转录。 autosome 常染色体:性染色体以外的任何染色体。 auxotroph 营养缺陷型:微生物的一种突变体,它不能合成生长所需的物质,培养时必须在培养基中加入此物质才能生长。 back mutation 回复突变:见reversion bacteriophage (phage) 一种感染细菌的病毒。 balance model 平衡模型:关于遗传变异比例的一种模型,它认为自然选择维持了群体中大量遗传变异的存在。 balanced polymorphism 平衡多态现象:稳定的遗传多态现象是由自然选择来维持的。 Barr body 巴氏小体:在正常雌性哺乳动物的核中有一个高度凝聚的染色质团,它是一个失活的X染色体。 base analog 碱基类似物:一种化学物质,其分子结构和DNA的碱基相似,在DNA的代谢过程中有时会取代正常碱基,结果使DNA的碱基发生突变。 bead theory 串珠学说:已被否定的学说,认为基因附着在染色体上,就象项链上的串珠。它既是突变单位又是重组单位。 binary fission 二分分裂:一个细胞分裂为大小相近的两个子细胞的过程。binomial distribution 二项分布:具有两种可能结果的 biparental zygote 双亲合子:又称双亲遗传(biparental inheriance),衣藻(chlamydomonas) 的合子含有来自双亲的DNA。这种细胞一般很少见。 biochemical mutation 生化突变,见自发突变(autotrophic mutation)。bivalent 二价体:在第一次减数分裂时彼此联合的一对同源染色体。bottleneck effect 瓶颈效应:一种类型的漂变。当群体很小时产生这种效应,结果使基因座中有的基因丢失了。 branch-point sequence 分支点顺序:在哺乳动物细胞中的保守顺序:YNCURAY(Y: 嘧啶,R:嘌呤, N:任何碱基),位于核mRNA内含子和II 类内含子3'端附近,其中的A可通过5'-2'连接的方式和内含子5'端相连接,在剪接时形成套马索状结构。 broad-sense heritability 广义遗传力:表型方差中所含遗传方差的百分比。cotplot 浓度时间乘积图:一个样本单位单链DNA分子复性动力学曲线。以结合为双链的量为纵坐标,以DNA浓度和时间的乘积为横坐标作出的DNA复性动力学曲线 C value C值:生物单倍体基因所含的DNA总量。 CAAT element CAAT元件:真核启动子上游元件之一,常位于上游-80bp附近,其功能是控制转录起始频率,保守顺序是 5'-GGCCAATCT-3'。 cancer 癌:恶性肿瘤,细胞失控,异常分裂且在生物体内可播散。 5'-capping -5'加帽:在 mRNA加工的过程中在前体 mRNA分子的5'端加上甲基核苷酸的“帽子”。 catabolite repression (glucose effect) 分解代谢物阻遏(糖效应):当糖存在时能诱发细菌操纵子的失活,即使操纵子的诱导物存在也是如此。 cDNA 互补DNA:以mRNA为模板,以反转录酶催化合成的DNA的拷贝。 cDNA clone cDNA分子克隆:将cDNA片段装在载体上转化细菌扩增出多克隆的过程,最终可建立cDNA文库。
距离计算方法
1.欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离: (2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离: (3)两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的欧氏距离: 也可以用表示成向量运算的形式: 2.曼哈顿距离(Manhattan Distance) 从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)。 (1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离 (2)两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的曼哈顿距离 5.标准化欧氏距离(Standardized Euclidean distance ) (1)标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为:而且标准化变量的数学期望为0,方差为1。因此样本集的标准化过程(standardization)用公式描述就是: 标准化后的值= (标准化前的值-分量的均值) /分量的标准差 经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的标准化欧氏距离的公式: 如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。 7.夹角余弦(Cosine) 有没有搞错,又不是学几何,怎么扯到夹角余弦了?各位看官稍安勿躁。几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。 (1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式: (2)两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦 类似的,对于两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。 即:
遗传学名词解释
1、原核细胞:没有核膜包围的核细胞,其遗传物质分散于整个细胞或集中于某一区域形成拟核。如:细菌、蓝藻等。 2、真核细胞:有核膜包围的完整细胞核结构的细胞。多细胞生物的细胞及真菌类。单细胞动物多属于这类细胞。 3、染色体:在细胞分裂时,能被碱性染料染色的线形结构。在原核细胞内,是指裸露的环状DNA分子。 4、姊妹染色单体:一条染色体(或DNA)经复制形成的两个分子,仍由一个着丝粒相连的两条染色单体。 5、同源染色体:指形态、结构和功能相似的一对染色体,他们一条来自父本,一条来自母本。 6、染色体组:在通常的二倍体的细胞或个体中,能维持配子或配子体正常功能的最低数目的一套染色体。或者说是指细胞内一套形态、结构、功能各不相同,但在个体发育时彼此协调一致,缺一不可的染色体。 7、一倍体:具有一个染色体组的细胞或个体,如,雄蜂。 8、单倍体:具有配子(精于或卵子)染色体数目的细胞或个体。如,植物中经花药培养形成的单倍体植物。 9、二倍体:具有两个染色体组的细胞或个体。绝大多数的动物和大多,数植物均属此类 10、二价体:一对同源染色体在减数分裂时联会配对的图象。 11、联会:在减数分裂过程中,同源染色体建立联系的配对过程。 12、染色质或染色体:指细胞间期核内能被碱性染料(洋红、苏木精等)染色的纤细网状物质,现在是指真核细胞间期核中DNA、组蛋白、非组蛋白、以及少量RNA组成的一串念珠状的复合体。当细胞分裂时,核内的染色质便螺旋化形成一定数目和形状的染色体。 13、超数染色体:有些生物的细胞中出现的额外染色体。也称为B染色体。 14、联会复合体:是同源染色体联会过程中形成的非永久性的复合结构,主要成分是碱性蛋白及酸性蛋白,由中央成分(central element)向两侧伸出横丝,使同源染色体固定在一起。 15、姊妹染色单体:二价体中一条染色体的两条染色单体,互称为姊妹染色单体。 16、反应规范:遗传型对环境反应的幅度(某一基因型在不同环境条件下反应的范围。) 17、交叉的端化:交叉向二价体的两端移动,并且逐渐接近于末端的过程叫做交叉端化。 18、受精:雄配子(精子)与雌配子(卵细胞)融合为1个合子过程。 19、双受精: 1个精核(n)与卵细胞(n)受精结合为合子(2n),将来发育成胚。另1精核(n)与两个极核(n+n)受精结合为胚乳核(3n),将来发育成胚乳的过程。 20、胚乳直感:在3n胚乳的性状上由于精核的影响而直接表现父本的某些性状,这种现象称为胚乳直感或花粉直感。 21、果实直感:种皮或果皮组织在发育过程中由于花粉影响而表现父本的某些性状,则另称为果实直感。 22、无融合生殖:雌雄配子不发生核融合的一种无性生殖方式。认为是有性生殖的一种特殊方式或变态。 23、细胞周期:从一次有丝分裂结束到下一次有丝分裂开始的时期。 25、无性生殖:通过亲本营养体的分割而产生许多后代个体,这一方式也称为营养体生殖。例如,植物利用块茎、鳞茎、球茎、芽眼和枝条等营养体产生后代,后代与亲代具有相同的遗传组成。 26、性状:生物体所表现的形态特征和生理特性。 27、单位性状:把生物体所表现的性状总体区分为各个单位,这些分开来的性状称为。 28、显性性状:当两个具有相对性状的纯合亲本杂交时,子一代出现的一个亲本性状。
遗传学名词解释
Explaining of genetics nouns 一、Explain the following terms and concepts. 1、heredity;(遗传)transmission of traits from one generation to another 2、transmission genetics;(传递遗传学)is the brand dealing with the transmission of genes and genetic traits from generation to generation,and how genes recombine 3、centromeres; (着丝点)each chromosome often has a constriction along its length 4、zygote;(合子)the cell produced by the fusion of male are female gametes 5、autosomes; (常染色体)chromosomes other than sex chromosome 6、sister chromatid; (姐妹染色单体)a chromatud denved from replication of one chromosome during interphase of the cell cycle 7、chromatin; (染色质)the mixture of DNA and protein 8、semiconservative replication;(半保留复制)a model of DNA replication in which a double-stranded molecule replocates in such a way that the daughter moleculars are composed of one parental(dd)and one nemly synthesized serand 9、the replication fork; (复制叉)the region where the helix unwinds and new DNA 10、replicon; (复制子)DNA replicated from a single origin 11、codon; (密码子)the DNA sequence of a gene is divided into a series of units of three bases 12、degeneracy; (简并)the number of codons is greater,all of the amino acids,with the exception of methionine and typtophan,are encodoned by more that one codon 13、hereditary traits; (遗传性状)the characteristics of an individual that one transmitted from one generation to another 14、Genotype; (基因型)the genetic constitution of an organism 15、phenotype; (表现型)is the observable properties(structural and functional)of organism produced by the interaction between its genotype and the environment 16、pure-breeding lines; (纯种品系)this refers to organisms which have been inbred for many generations in which a certain phenotype remains the same 17、dominance;(显性)in hybrids between two individuals with different phenotypes only ine phenotype may be observed 18、testcross; (测交)is a cross of an individual of unknown genetype (usually expressing the dominant phenotype)with a known homozygous recessive individual in order to determine the unknown genetype 19、the dihybrid cross;(双因子杂交)a cross involving two pairs of contrasting traits 20、complete dominance; (完全显性)is the phenoment in which one alleles is dominant to another,so that the neterozygote(F1)is the same as that of the homozygous dominant 21、incomplete dominance; (不完全显性)expression of heterozygous(F1)phenotype which is distinct from and often intermediate to that of either parent 22、multiple alleles; (复等位基因)three or more alleles of the same gene 23、epistasis; (上位作用)is a from of gene interaction in which one gene masks the phenotypic expression of another 24、linkage; (连锁)is the tendency of for alleles of two or more genes to be passed together from one generation to the next
遗传学名词解释
遗传学名词解释 11、性状:生物体或其组成部分所表现的形态、生理或行为特征称为性状(character/trait) 13、相对性状:不同生物个体在单位性状上存在不同的表现,这种同一单位性状的相对差异 称为相对性状 14、显性(dominate)性状:在子一代中出现来的某一亲本的性状。 15、隐性 (recessive)性状:在子一代中未出现来的某一亲本的性状。 17、基因型(genotype):指生物个体基因组合,表示生物个体的遗传组成,又称遗传型; 18、表现型(phenotype):指生物个体的性状表现,简称表型。 19、纯合基因型:具有一对相同基因的基因型称为纯合基因型(homozygous genotype),如 CC和cc;这类生物个体称为纯合体(homozygote)。 ●显性纯合体(dominant homozygote), 如:CC. ●隐性纯合体(recessive homozygote), 如:cc. 21、基因的分离定律:一对等位基因在杂合体中各自保持其独立性,在配子形成时,彼此分 开,随机地进入不同的配子,在一般情况下:F1杂合体的配子分离比 为1:1,F2表型分离比是3:1,F2基因型分离比为1:2:1 22、测交(test cross)法:即把被测验的个体与隐性纯合亲本杂交,根据侧交子代(Ft)的 表现型和比例测知该个体的基因型。 23、独立分配定律:支配两对(或两对以上)不同性状的等位基因,在杂合状态时保持其独 立性。配子形成时,各等位基因彼此独立分离,不同对的基因自由组合。 24、系谱分析法:用图解表明一个家族中某种性状(或遗传疾病)发生的情况,进而判断该 性状(或遗传疾病)的遗传方式。 27、外显率(penetrance):指在特定环境中,某一基因型(常指杂合子)个体显示出预期表型 的频率(以百分比表示)。就是说同样的基因型在一定的环境中有的 个体表达了,而有的个体可能没有表达,这样外显率就小于100% ——不完全外显。外显率为100%——完全外显 28、表现度(expressivity):是指具有相同基因型的个体之间基因表达的变化程度。 29、共显性/并显性:一对等位基因的两个成员在杂合体中都表达的遗传现象。 30、镶嵌显性:由于等位基因的相互作用,双亲的性状在子代同一个体的不同部位表现的镶 嵌图式。 31、隐性致死基因:在杂合时不影响个体的生活力,但在纯合时有致死效应的基因。 32、显性致死基因(dominant lethal gene):在杂合状态下即表现致死作用的致死基因 33、复等位基因:在群体中占据某同源染色体同一座位的两个以上的决定同一性状的基因 34、基因互作:基因在决定同一生物性状表现时,所表现出来的相互作用。 35、互补基因:两对非等位的显性基因同时存在并影响生物的某同一性状时才使之表现该性 状,其中任一基因发生突变都会导致同一突变性状出现,这类基因称为互补基因。 37、叠加效应:不同基因对性状产生相同影响,只要两对等位基因中存在一个显性基因,表 现为一种性状;双隐性个体表现另一种性状;F2产生15:1的性状分离比例。 这类作用相同的非等位基因叫做叠加基因 38、上位效应:影响同一性状的两对非等位基因中的一对基因(显性或隐性)掩盖另一对显 性基因的作用时,所表现的遗传效应称为上位效应,其中的掩盖者称为上位 基因,被掩盖者称为下位基因。 39、显性上位:在上位效应中,起掩盖作用的是一个显性基因,使另一个显性基因的表型被 抑制,孟德尔F2表型比率被修饰为12:3:1
镜头角度与距离计算方法
专用的镜头角度计算方法 镜头焦距的计算 1公式计算法:视场和焦距的计算视场系指被摄取物体的大小,视场的大小是以镜头至被摄取物体距离,镜头焦头及所要求的成像大小确定的。 1、镜头的焦距,视场大小及镜头到被摄取物体的距离的计算如下; f=wL/W 2、f=hL/h f;镜头焦距 w:图象的宽度(被摄物体在ccd靶面上成象宽度) W:被摄物体宽度 L:被摄物体至镜头的距离 h:图象高度(被摄物体在ccd靶面上成像高度)视场(摄取场景)高度 H:被摄物体的高度 ccd靶面规格尺寸:单位mm 规格 W H 1/3" 1/2" 2/3" 1" 由于摄像机画面宽度和高度与电视接收机画面宽度和高度一样,其比例均为4:3,当L不变,H或W增大时,f变小,当H或W不变,L增大时,f增大。 2视场角的计算如果知道了水平或垂直视场角便可按公式计算出现场宽度和高度。水平视场角β(水平观看的角度)β=2tg-1= 垂直视场角q(垂直观看的角度) q=2tg-1= 式中w、H、f同上水平视场角与垂直视场角的关系如下: q=或=q 表2中列出了不同尺寸摄像层和不同焦距f时的水平视场角b的值,如果知道了水平或垂直场角便可按下式计算出视场角便可按下式计算出视场高度H和视场宽度W. H=2Ltg、W=2Ltg 例如;摄像机的摄像管为17mm(2/3in),镜头焦距f为12mm,从表2中查得水平视场角为40℃而镜头与被摄取物体的距离为2m,试求视场的宽度w。W=2Ltg=2×2tg= 则H=W=×= 焦距f越和长,视场角越小,监视的目标也就小。 图解法如前所示,摄像机镜头的视场由宽(W)。高(H)和与摄像机的距离(L)决定,一旦决定了摄像机要监视的景物,正确地选择镜头的焦距就由来3个因素决定; *.欲监视景物的尺寸 *.摄像机与景物的距离 *.摄像机成像器的尺士:1/3"、1/2"、2/3"或1"。图解选择镜头步骤:所需的视场与镜头的焦距有一个简单的关系。利用这个关系可选择适当的镜头。估计或实测视场的最大宽度;估计或实测量摄像机与被摄景物间的距离;使用1/3”镜头时使用图2,使用1/2镜头时使用图3,使用2/3”镜头时使用图4,使用1镜头时使用图5。具体方法:在以W和L为座标轴的图示2-5中,查出应选用的镜头焦距。为确保景物完全包含在视场之中,应选用座标交点上,面那条线指示的数值。例如:视场宽50m,距离40m,使用 1/3"格式的镜头,在座标图中的交点比代表4mm镜头的线偏上一点。这表明如果使用4mm镜头就不能覆盖50m的视场。而用的镜头则可以完全覆盖视场。 f=vD/V 或 f=hD/H 其中,f代表焦距,v代表CCD靶面垂直高度,V代表被观测物体高度,h代表CCD靶面水平宽度,H代表被观测物体宽度。 举例:假设用1/2”CCD摄像头观测,被测物体宽440毫米,高330毫米,镜头焦点距物体2500毫米。由公式可以算出: 焦距f=440≈36毫米或 焦距f=330≈36毫米
遗传学名词解释
一、名词解释:(每小题3分,共18分) 1、外显子:把基因内部的转译部分即在成熟mRNA中出现的序列叫外显子。 2、复等位基因:在种群中,同源染色体的相同座位上,可以存在两个以上的等位基因,构成一个等位基因系列,称为复等位基因。 3、F因子:又叫性因子或致育因子,是一种能自我复制的、微小的、染色体外的环状DNA分子,大约为大肠杆菌全长的2%,F因子在大肠杆菌中又叫F质粒。 4、F'因子:把带有部分细菌染色体基因的F因子叫F∕因子。 5、母性影响:把子一代的表型受母本基因型控制的现象叫母性影响。 6、伴性遗传:在性染色体上的基因所控制的性状与性别相连锁,这种遗传方式叫伴性遗传。 7、杂种优势:指两个遗传组成不同的亲本杂交产生的杂种一代在生长势、生活力、繁殖力、抗逆性以及产量和品质等性状上比双亲优越的现象。 8、隔裂基因:真核类基因的编码顺序由若干非编码区域隔开,使阅读框不连续,这种基因称为隔裂基因,或者说真核类基因的外显子被不能表达的内含子一一隔开,这样的基因称为隔裂基因。 9、细胞质遗传:在核外遗传中,其中由细胞质成分如质体、线粒体引起的遗传现象叫细胞质遗传。 10、同源染色体:指形态、结构和功能相似的一对染色体,他们一条来自父本,一条来自母本。 11、跳跃基因(转座因子):指细胞中能改变自身位置的一段DNA序列。 12、基因工程:狭义的遗传工程专指基因工程,更确切的讲是重组DNA技术,它是指在体外将不同来源的DNA进行剪切和重组,形成镶嵌DNA分子,然后将之导入宿主细胞,使其扩增表达,从而使宿主细胞获得新的遗传特性,形成新的基因产物。 13、性导:利用F∕因子形成部分二倍体叫做性导(sex-duction)。 14、转导:以噬菌体为媒介,将细菌的小片断染色体或基因从一个细菌转移到另一细菌的过程叫转导。 15、假显性:(pseudo-dominant):一个显性基因的缺失致使原来不应显现出来的一个隐性等位基因的效应显现了出来,这种现象叫假显性。 16、核外遗传:由核外的一些遗传物质决定的遗传方式称核外遗传或非染色体遗传。 17、常染色质与异染色质:着色较浅,呈松散状,分布在靠近核的中心部分,是遗传的活性部位。着色较深,呈致密状,分布在靠近核内膜处,是遗传的惰性部位。又分结构异染色质或组成型异染色质和兼性异染色质。前者存在于染色体的着丝点区及核仁组织区,后者在间期时仍处于浓缩状态. 18、等显性(并显性,共显性):指在F1杂种中,两个亲本的性状都表现出来的现象。 19、限性遗传与从性遗传:限性遗传:是指位于Y染色体(XY型)或W染色体(ZW型)上的基因所控制的遗传性状只限于雄性或雌性上表现的现象。从性遗传:指常染色体上的基因控制的性状在表型上受个体性别影响的现象。 20、连锁群:存在于一个染色体上的各个基因经常表现相互联系,并同时遗传于后代,这种存在于一个染色体上在遗传上表现一定程度连锁关系的一群基因叫连锁群。 21、核型与核型分析:通常把有丝分裂中期染色体的形态、大小和数目称为核型,通过细胞学观察,取得分散良好的细胞分裂照片,就可测定染色体数目、长度、着丝粒位置、臂比、随体有无等特征,对染色体进行分类和编号,这种测定和分析称为核型分析。 22、位置效应:基因由于变换了在染色体上的位置而带来的表型效应改变的现象。 23、平衡致死品系:两个连锁的隐性致死基因,以相斥相的形式存在于一对同源染色体上,由于倒位抑制交换作用,永远以杂合状态保存下来,表型不发生分离的品系叫做平衡致死品系,也叫永久杂种。24、基因突变:是染色体上一个座位内的遗传物质的变化,从一个基因变成它的等位基因。也称点突变。从分子水平上看,基因突变则为DNA分子上具有一定遗传功能的特定区段内碱基或碱基顺序的变化所引起的突变,最小突变单位是一个碱基对的变化,是产生新基因的源泉,生物进化的重要基础,诱变育种的理论依据。 25、部分二倍体:含一个亲本的全部基因组和另一亲本部分基因组的合子叫部分二倍体或部分合子。 26、移码突变:在DNA复制中发生增加或减少一个或几个碱基对所造成的突变。 27、镶嵌显性:指在杂种的身体不同部位分别显示出显性来的现象. 28、表型模写(拟表型):有时环境因子引起的表型改变和某基因突变引起的表现型改变很相似,这叫表型模拟或拟表型。 29、等位基因:等位基因是指位于同源染色体上,占有同一位点,但以不同的方式影响同一性状发育的两个基因。
遗传学名词解释
名词解释: 1、遗传与变异:生物通过繁殖的方式来繁衍种族,保持生命在世代间的连续,保持子代与亲代的相似与类同,这种现象叫遗传,遗传的本质就是遗传物质通过不断地复制和传递,保持亲代与子代间的相似与类同,与此同时,亲代与子代之间,子代个体之间总存在着不同程度的差异,包括环境差异与遗传物质差异,这种差异就是变异。 2、遗传变异:变异不一定都能遗传,只有由遗传物质改变导致的变异可以传递给后代,这种变异叫遗传变异。 3、遗传学: 经典定义:研究生物的遗传和变异现象及其规律的一门学科。 现代定义: (1)在生物的群体、个体、细胞和基因等层次上研究生命信息(基因)的结构、组成、功能、变异、传递(复制)和表达规律与调控机制的一门科学--基因学。 (2)研究基因和基因组的结构与功能的学科。 名词解释: 1、性状:在遗传学上,把生物表现出来的形态特征和生理特征统称为性状。 2、相对性状:同一性状的两种不同表现形式叫相对性状。 3、显性性状:孟德尔把F1表现出来的性状叫显性性状,F1不表现出来的性状叫隐性性状。 4、性状分离现象:孟德尔把F2中显现性状与隐性性状同时表现出来的现象叫做性状分离现象。 5、等位基因与非等位基因:等位基因是指位于同源染色体上,占有同一位点,但以不同的方式影响同一性状发育的两个基因。非等位基因指位于不同位点上,控制非相对性状的基因。 6、自交:F1代个体之间的相互交配叫自交。 7、回交:F1代与亲本之一的交配叫回交。 8、侧交:F1代与双隐性个体之间的交配叫侧交。 9、基因型和表型 基因型是生物体的遗传组成,是性状得以表现的内在物质基础,是肉眼看不到的,要通过杂交试验才能检定。如cc,CC,Cc。 表型是生物体所表现出来的性状,是基因型和内外环境相互作用的结果,是肉眼可以看到的。如花的颜色性状。 10、纯合体、杂合体 由两个同是显性或同是隐性的基因结合的个体,叫纯合体,如CC,cc。由一个显性基因与一个隐性基因结合而成的个体,叫杂合体,如Cc。 11、真实遗传 指纯合体的物种所产生的子代表型与亲本表型相同的现象。纯合体所产生的后代性状不发生分离,能真实遗传,杂合体自交产生的后代性状要发生分离,它不能真实遗传。 名词解释: 1、染色体与染色质:是指核内易于被碱性染料着色的无定形物质,是由DNA、组蛋白、非组蛋白及少量RNA组成的复合体,以纤丝状存在于核膜内面。当细胞分裂时,核内的染色质便螺旋化形成一定数目和形状的染色体。两者是同一物质在细胞分裂过程中表现的不同形态。核内遗传物质就集中在这染色体上。 2、常染色质与异染色质:着色较浅,呈松散状,分布在靠近核的中心部分,是遗传的活性部位。着色较深,呈致密状,分布在靠近核内膜处,是遗传的惰性部位。又分结构异染色质或组成型异染色质和兼性异染色质。前者存在于染色体的着丝点区及核仁组织区,后者在间期时仍处于浓缩状态, 3、核小体:是染色质的基本结构单位,直径10nm,其核心是由四种组蛋白(H2A、H2B、H3、H4各2分子共8分子)构成的扁球体。 4、同源染色体:指形态、结构和功能相似的一对染色体,他们一条来自父本,一条来自母本。 5、联会:分别来自父母本的同源染色体逐渐成对靠拢配对,这种同源染色体的配对称为联会。
遗传学名词解释及复习解答(部分)
名词解释 染色体chromosome是指细胞分裂过程中,由染色质聚缩而呈现为一定数目和形态的复合结构 细胞周期cell cycle是细胞分裂增殖的周期,细胞从上一次分裂结束到下一次分裂结束所经历的时期减数分裂miosis是性母细胞成熟时,配子形成过程中发生的一种特殊形式的有丝分裂,所形成的配子染色体数减半。 生活周期life cycle即个体发育过程或称生活史,有性生殖的动植物生活周期是指从合子到个体成熟再到死亡所经历的一系列发育阶段 半保留复制semiconservative replicationDNA复制时,形成的新链DNA分子一链来自原来的亲本DNA分子,一链来自于新合成的DNA分子,这种复制方式称为半保留复制 性状character是指生物体所表现的形态特征和生理特征的总称 测交test cross是指被测验个体与隐性纯合个体间的杂交 等位基因allele控制一对相对性状位于同源染色体上对应位点的两个基因 基因互作interaction of gene不同对基因间相互作用共同决定同一单位性状表现结果的现象 连锁遗传linkage指在统一同源染色体上的非等位基因连在一起而遗传的现象 连锁群linkage group存在于同一染色体上的基因群 基因突变gene mutation指基因内部发生了化学性质的变化,与原来的基因形成对性关系 野生型wild type自然群体中最常见的类型 整倍体euploid 染色体数目是x整数倍的个体或细胞 非整倍体aneuploid正常染色体数(2n)的基础上增加或减少1条或若干染色体的个体或细胞 基因组genome指一个生物单倍体的染色体的数目即生物体全部遗传物质的总和 数量性状quantitative trait表现连续变异的性状 遗传率heritability指遗传方差在总方差(表型方差)中所占的比值,可以作为杂种后代进行选择的一个指标。 近亲繁殖inbreeding指血统或亲缘关系相近的两个个体间的交配,其极端类型为自交 轮回亲本recurrent parent被用来连续回交的亲本 杂种优势heterosis指两个遗传组成不同的亲本杂交产生的杂种一代,在生长势、生活力、繁殖力、产量和品质上比其亲本优越的现象 细胞质遗传cytoplasmic inheritance由细胞内的基因即细胞质基因所决定的遗传现象和遗传规律 干细胞stem cell是一类具有自我复制能力的多潜能细胞,在一定条件下,它可以分化成多种功能细胞 孟德尔群体mendelian group在一个的群体内,个体间随机交配,遗传因子以各种不同的方式从一代传递到下一代,这种群体称为孟德尔群体 遗传漂变genetic drift在一个小群体内由于抽样误差造成的群体金银频率随机波动的现象 交换值crossing-over value指同源染色体的非姊妹染色单体间有关基因的染色体片段发生交换的频率 简答题: 1、有丝分裂和减数分裂的过程,遗传学意义。 有丝分裂的遗传学意义:P20 减数分裂的遗传学意义:P23-24 细胞有丝分裂的遗传学意义:(1)每个染色体准确复制分裂为二,为形成两个子细胞在遗传组成上与母细胞完全一样提供了基础。(2)复制的各对染色体有规则而均匀地分配到两个子细胞中去,使两个细胞与母细胞具有同样质量和数量的染色体。 细胞减丝分裂的遗传学意义:(1)雌雄性细胞染色体数目减半,保证了亲代与子代之间染色体数目
遗传学名词解释
遗传学名词解释 1.变异:指亲代与子代之间、子代个体之间存在的差异。 2.突变:DNA分子某些部分的基因能够发生改变,使生物产生性状 的差异。 3.原核细胞:指一类结构简单、没有细胞核(仅有拟核)以及没有 膜包被细胞器的细胞。 4.真核细胞:指一类结构复杂、具有细胞核和细胞器的细胞。 5.核仁:是真核细胞间期核中最明显的呈中圆形或椭圆形的颗粒状 结构,其组成成分有rRNA、rDNA和核糖核蛋白。 6.染色体:指细胞分裂过程中,由染色质聚缩而呈现为一定数目和 形态的复合结构。 7.染色质:指间期细胞核内由DNA、组蛋白、非组蛋白和少量RNA 组成的线性复合结构,因其易被碱性染料染色而得名,是间期细胞遗传物质存在的主要形式。 8.常染色体:与性别决定无关的染色体,是成对存在的,称为常染 色体。 9.性染色体:与性别决定有关的染色体。 10.常染色质:指间期细胞核内纤细处于伸展状态,并对碱性染料着 色浅的染色质。 11.异染色质:指间期核内聚缩程度高,并对碱性染料着色深的染色 质。 12.组成性染色质:指除复制期外均处聚缩状态的染色质。它是由相
对简单、高度重复DNA序列构成。 13.兼性染色质:指在某细胞外,或其发育的某阶段,原来的常染色 质卷缩、丧失转录活性而变为异染色质。 14.着丝粒:也叫着丝点。染色体的特定部位,细胞分裂时出现的纺 锤丝所附着的位置,此部位染色较浅。 15.端粒:存在于真核细胞线状染色体末端的一小段DNA-蛋白质复 合体,它与端粒结合蛋白一起构成了特殊的“帽子”结构,作用是保持染色体的完整性和控制细胞分裂周期。 16.复制原点:在基因组上复制起始的一段序列。 17.主缢痕:中期染色体上一个染色较浅而缢缩的部位,主缢痕处有 着丝粒,所以亦称着丝粒区,由于这一区域染色线的螺旋化程序低,DNA含量少,所以染色很浅或不着色。 18.次缢痕:指某些染色体臂上除主缢痕外还常含有另外缢缩区域。 19.随体:是位于染色体末端的、圆形或圆柱形的染色体片段,通过 次缢痕与染色体主要部分相连。 20.核仁组织中心:在细胞分裂时,次缢痕紧密相连核仁,也称为核 仁组织中心。 21.同源染色体:形态、结构、功能相同的一对染色体。 22.核型分析:又叫染色体组型分析,按照染色体的数目、大小和着 丝粒位置、臂比次缢痕、随体等形态特征,对生物核内的染色体进行配对、分组、归类、编号,这样进行分析过程称为核型分析。 23.染色单体:染色体通过复制形成,由同一着丝粒连接在一起的两
普通遗传学名词解释(英文)
遗传(heredity):指亲代与子代之间相似的现象。 变异(variation):指亲代与子代之间、子代个体之间存在的差异。 染色体(chromosome):指细胞分裂过程中,由染色质聚缩而呈现为一定数目和形态的复合结构。 有丝分裂(mitosis):又称间接分裂,是高等植物细胞分裂的主要方式,包含细胞核分裂和细胞质分裂两个紧密相连的过程。 减数分裂(meiosis):又称成熟分裂,是性母细胞成熟时,配子形成过程中发生的一种特殊的有丝分裂方式。由于形成子细胞内染色体数目比性母细胞减少一半,因此称为减数分裂。 联会(synapsis):减数分裂偶线期开始出现同源染色体配对现象,即联会。 姊妹染色单体(sister chromatid):二价体中一条染色体的两条染色单体,互称为姊妹染色单体。 同源染色体(homologous chromosome):指形态、结构和功能相似的一对染色体,他们一条来自父本,一条来自母本。 性状(character):生物体所表现的形态特征和生理特性的总称。 单位性状(unit character):把生物体所表现的性状总体区分为各个单位,这些分开来的性状称为单位性状。 相对性状(contrasting character) 等位基因(allele):位于同源染色体上,位点相同,控制着同一性状的基因。 测交(test cross):是指被测验的个体与隐性纯合体间的杂交。 基因型(genotype):也称遗传型,生物体全部遗传物质的组成,是性状发育的内因。表现型(phenotype):生物体在基因型的控制下,加上环境条件的影响所表现性状的总和。 染色单体(Chromatid)又称染色分体,是染色体的一部分。在减数分裂或有丝分裂过程中,复制了的染色体中的两条子染色体。 非姐妹染色单体(non-sister chromatid):两个同源染色体中由不同着丝点相连的染色单体,就叫非姐妹染色单体。 着丝粒(centromere):在细胞分裂时染色体被纺锤丝所附着的位置。一般每个染色体只有一个着丝点粒,少数物种中染色体有多个着丝粒,着丝粒在染色体的位置决定了染色体的形态。 基因(gene):指携带有遗传信息的DNA序列,是控制性状的基本遗传单位,亦即一段具有功能性的DNA序列。基因通过指导蛋白质的合成来表达自己所携带的遗传信息,从而控制生物个体的性状表现。 相对性状(contrasting character):是指同种生物的各个体间同一性状的不同表现类型。 突变型基因(Mutant gene)为DNA分子中发生碱基对的增添、缺失或改变,而引起的基因结构的改变 端粒(Telomeres)是线状染色体末端的DNA重复序列。端粒是线状染色体末端的一种特殊结构,在正常人体细胞中,可随着细胞分裂而逐渐缩短。 动粒(Kinetochore)是真核细胞染色体中位于着丝粒两侧的3层盘状特化结构,其化学本质为蛋白质,是非染色体性质物质附加物,与染色体的移动有关。 野生型基因(wild type gene):在自然群体中往往有一种占多数座位的等位基因,称为野生型基因。 自交(selfing):指来自同一个体的雌雄配子的结合或具有相同基因型个体间的交 配或来自同一无性繁殖系的个体间的交配。 纯合子(Homozygote) :是指同一位点 (locus) 上的两个等位基因相同的基因型个体 , 如AA,aa。相同的纯合子间交配所生后代不出现性状的分离。分为隐性纯合子和显性纯合子。 杂合子(heterozygote) :是指同一位点上的两个等位基因不相同的基因型个 体 , 如Aa。杂合子间交配所生后代会出现性状的分离。 分离定律(law of segregation):为孟德尔遗传定律之一。决定相对性状的一对等位基因同时存在于杂种一代(F1)的个体中,但仍维持它们各自的个体性,在配子形成时互相分开,分别进入一个配子细胞中去。 相引相(coupling phase)两个显性性状连接在一起遗传,而两个隐性性状连接在一起遗传的杂交组合。 相斥相(repulsion phase)两个性状分别为甲和乙,甲显性性状与乙隐性性状连接在一起遗传,而乙显性性状和甲隐性性状连接在一起遗传的杂交组合。 选择(select):改变基因频率的最重要因素,也是生物进化的驱动力量。包括自然选择和人工选择。 宋体的是在汉语的遗传学书上的;黑体的是老师说的;华文新魏的是百度的。 遗传距离(genetic distance):两个基因在同一染色体上的相对距离,通常以交换值来表示。 两点测验(two-point testcross):是基因定位最基本的方法。首先通过一次杂交和一次用隐性亲本来测交来确定两对基因是否连锁,然后再根据其交换值来确定它们在同一染色体上的位置。 三点测验(three-point testcross):是基因定位最常用的方法,它是通过1次杂交和1次用隐性亲本测交,同时确定3对基因在染色体上的位置。 常染色体(autosome):生物多对染色体中,除性染色体外的其余各对染色体统称为常染色体。 性染色体(sex chromosome):在生物多对染色体中,直接与性别决定有关的一条或一对染色体。 常染色质(euchromatin):常染色质是指间期核内染色质纤维折叠压缩程度低,处于伸展状态,用碱性染料染色时着色浅的那些染色质。 异染色质(heterochromatin):在细胞周期中,间期、早期或中、晚期,某些染色体或染色体的某些部分的固缩常较其他的染色质早些或晚些,其染色较深或较浅,具有这种固缩特性的染色体称为异染色质。 限性遗传(sex-limited inheritance):指位于Y染色体(XY型)或W染色体(ZW 型)上的基因所控制的遗传性状只局限于雄性或雌性上表现的现象。 性别影响遗传(sex-influenced inheritance,又称从性遗传sex-controlled inheritance):与限性遗传不同,它是位于常染色体上的基因所控制的性状,是由于内分泌及其他关系使某些性状或只出现于雌雄一方;或在一方为显性,另一方为隐性的现象。 连锁强度 数量性状(quantitative trait):表现连续变异的遗传性状。(指在一个群体内的各个体间表现为连续变异的性状) 质量性状(qualitative trait/discrete characters):表现不连续变异的遗传性状。(指属性性状,即能观察而不能量测的性状,是指同一种性状的不同表现型之间不存在连续性的数量变化,而呈现质的中断性变化的那些性状。) 基因座(locus):一个特定的基因在染色体上的特定位置。 遗传率(又叫遗传力,heritability):指遗传方差在总方差(表型方差)中所占的比值,可以作为杂种后代进行选择的一个指标。 广义遗传率h2B(heritability in the broad sense):指遗传方差占总方差(表型方差)的比值。 狭义遗传率h2N(heritability in the narrow sense):指基因加性方差占总方差的比值。现实(选择)遗传率(Reality(select) heritability):通过选择结果也可以估算群体的遗传率,这个遗传率叫做现实遗传率,用hR表示。 选择反响(Select response)the degree of respond to mating the selected parent 选择差(selection difference):选择强度即标准化的选择差)指的是要留种的个体表型均值与畜群表型平均数之差。 杂种优势(heterosis):指两个遗传组成不同的亲本杂交产生的杂种一代,在生长势、生活力、繁殖力、产量和品质上比其双亲优越的现象。 超亲遗传(transgressive inheritance):指在数量性状的遗传中,杂种第二代及以后的分离世代群体中,出现超越双亲性状的新表型的现象。 复等位基因(multiple allele):同一位点的基因可能有两种以上的形式,遗传学把同源染色体相同位点上存在的3个或3个以上的等位基因称为复等位基因。 连锁群(linkage group):存在于同一染色体上的基因群。(位于同一条染色体上的所有基因座) 互补群(Complementation group):能与其它的互补群发生互补反应、同一个野生型基因产生的一系列(所有的)突变基因。除野生型外其它位点统称为一个互补群。整倍体(euploid):染色体数是x整倍数的个体或细胞称为整倍体。 非常整体(?) 非整倍体(aneuploid):在正常合子染色体数(2n)的基础上增加或减少1条或若干条染色体的个体或细胞。 单倍体(haploid):指具有配子染色体数(n)的个体或细胞。 多倍体(polyploid):三倍和三倍以上的整倍体统称为多倍体。 同源多倍体(autopolyploid):染色体组相同的多倍体叫做同源多倍体。所有染色体组来自同一物种,一般是由二倍体经染色体数目加倍形成的。 异源多倍体(allopolyploid):染色体组不同的多倍体叫做异源多倍体,其染色体组来自不同物种,一般是由不同种、属间的杂交种经染色体数目加倍形成的。 双二倍体(amphidiploid):异源四倍体中,由于两个种的染色体各具有两套,因而又叫做双二倍体。 单体(monosomic);在亚倍体中,染色体数比正常2n少一条的个体或细胞叫做单体,其染色体组成为2n-1=(n-1)II+I。 单倍体(haploid);单倍体是指具有配子染色体数(n)的个体或细胞。 单价体(univalent);本应联会而未联会的染色体。 二价体(bivalent);一对配对的同源染色体称二价体 三价体(trivalent);在减数分裂中,发生联会的三个染色体配成一组的多价体,称为三价体或三价染色体 缺体(nullisomic);对染色体的两条全部丢失了的个体或细胞成为缺体,其染色体组成为2n-2=(n-1)II。 四体(tetrasomic);在正常2n基础上,某一对染色体多了两个成员的个体或细胞称为四体,其染色体组成为2n+2=(n-1)II+IV。 双单体(double monosomic);两对染色体各缺少一条的个体或细胞称为双单体。 三体(trisomic);在正常2n的基础上,增加一条染色体的个体或细胞称为三体,其染色体组成为2n+1=(n-1)II+III。 双三体(double trisomic):在正常2n基础上,有两对染色体各自都增加一条的个体或细胞称为双三体。 超倍体(hyperploid);染色体数多于2n的非整倍体称为超倍体。 亚倍体(hypoploid);染色体数少于2n的非整倍体称为亚倍体。 缺失(deficiency);缺失是指染色体的某一片段丢失了。 重复(duplication);重复是指染色体多了自身的某一区段。 易位(translocation);异位是指染色体上某一区段移接到其非同源染色体上。 倒位(inversion);倒位指染色体中发生了某一区段倒转。 缺失圈(deficiency loop);中间缺失杂合体在偶线期和粗线期可能观察到二价体上形成环状或瘤状突起——缺失圈或缺失环 重复圈(duplication loop);重复杂合体在减数分裂联会时,如果重复区段较长,重复区段会被排挤出来,成为二价体的一个突出的环或瘤——重复圈或重复环。 感受态(competence);细胞处于能够吸收外源DNA的状态称感受态,处于感受态的细胞称作感受态细胞。 原养型(prototroph);能在矿物培养基上合成自身必需的有机化合物的细菌。 辅养型(auxotroph);一个细菌失去了合成一种至数种有机化合物的能力从而导致其不能再矿物培养基上生长。 接合(conjugation);接合是指遗传物质从供体——“雄性”转移到受体——“雌性”的过程。 转化(transformation);转化是指某些细菌(或其他生物)通过其细胞膜摄取周围供体的DNA片段,并将此外源DNA片段通过重组整合到自己染色体组的过程。 性导(sexduction);性导是指接合时由F’因子所携带的外源DNA转移到细菌染色体的过程。 转导(transduction);转导是指以噬菌体为媒介所进行的细菌遗传物质重组的过程。 质粒(plasmid);质粒是指存在于细胞中能独立进行自主复制的染色体外遗传因子。F细胞(F cells);F因子为致育因子,含有F因子的细胞即为F细胞。 F+细胞(F+cell);含有自主状态的F因子的细胞。 高频率重组(hfr)细胞(high frequency recombination);带有一个整合的F因子的细胞叫做高频重组细胞,即hfr细胞。 群体遗传学(population genetics);群体遗传学是研究群体的遗传结构及其变化规律的遗传学分支学科。应用数学和统计学方法研究群体中基因频率和基因型频率以及影响这些频率的选择效应和突变作用。 基因型频率(genotype frequency);指某一特定基因型的个体占群体的百分率。基因频率(gene frequency)。某一特定基因占该基因座基因总数的百分率。 隐性性状(recessive character):孟德尔把在子一代未表现出来的性状称为隐性性状。 显性作用() 不完全显性(incomplete dominance):杂种F1的性状表现是双亲性状的中间型。 共显性(codominance)一对等位基因的两个成员在杂合体中都表达的遗传现象。 加性(additive allelic effect) 在多基因决定的数量性状中,各基因独自产生的效应。 干扰(interference,I)一个单交换发生后,在它邻近再发生第二次单交换的机会就会减少的现象。 正干扰(positive interference):一个单交换发生后,对它临近位置再发生第二个单交换有抑制或减弱的作用为正干扰。 负干扰(negative interference) 一个单交换发生后,对它临近位置再发生第二个单交换有促进或增强的作用为正干扰。 连锁遗传(linkage inheritance)在同一同源染色体上的非等位基因连在一起而遗传的现象。 连锁(linkage)指位于同一对染色体上的非等位基因总是联系在一起遗传的现象。