基于向量空间模型的中文文本层次分类方法研究
基于张量空间模型的中文文本分类

Hale Waihona Puke 文本分 类是 文 本挖 掘 的一 个重 要 内容 , 泛 广
应用 于信息 检索 、 闻 即时分 类 、 新 文档管 理 系统及 垃圾 邮件判 定等领 域 。文本分 类 的任务 是按 照预 先 定义 的主 题类 别 , 文 档集 合 中 的每个 文 档 确 为 定 一个类 别 。特征 表示 是文本 分类 的主 要步骤 之
H E e 。 HU e ga W i Xu — ng,
XI Fe E i
( h o fCo p tra dI f r t n,H ee Unv riyo c n lg Sc o lo m u e n n o mai o fi ie st fTe h oo y,Hee 3 0 ,Chn ) fi2 0 09 ia
t n l e t r s a e mo e. I s s t e t r e o d r t n o o e p e s t e t x e s n x a d h — i a c o p c d 1 t u e h h e — r e e s r t x r s h e ts t ,a d e p n s t e k o v
第3 3卷 第 1 2期
2] 0 0年 l 2月
合肥 工 业 大 学 学报 ( 自然科 学版 )
J OURNAI OF HEFEIUNI VERS TY I OF TECHNOI , OGY
V o . 3 No 1 13 . 2
D e . 20 O e 1
D i1 . 9 9 jis. 0 35 6 . 0 0 1 . 1 o :0 3 6 /.sn 1 0 —0 0 2 1 . 2 0 1
向量空间方法在自然语言处理中的应用

向量空间方法在自然语言处理中的应用自然语言处理(Natural Language Processing,简称NLP)是计算机科学领域重要的研究方向之一,其旨在让计算机能够理解人类语言并作出相应反应。
NLP的应用场景极为广泛,如搜索引擎、智能客服、机器翻译、情感分析等。
近年来,向量空间方法在NLP领域中得到了广泛应用,本文将介绍向量空间方法在NLP中的应用。
一、向量空间模型向量空间模型(Vector Space Model, VSM)是一种将文本表示为向量的方法。
在VSM中,文本被表示为一个向量空间中的点,而每个单词则被表示为向量空间中的向量。
这些向量可以通过词频统计来构建,向量的每一维表示一个词在文档中出现的频率。
基于这种表示方式,我们可以利用向量进行文本之间的相似度比较、分类等任务。
二、词向量词向量(Word Embedding)是指将单词映射为一个向量的方法。
与VSM不同的是,词向量不再是稀疏向量,而是稠密向量。
这种表示方式不仅能够向量化单个单词,还可以提取整个句子的向量表示。
近年来,由于其在NLP领域中的出色表现,词向量成为了NLP的热门话题。
有许多方法可以生成词向量,其中比较流行的是基于神经网络的方法,如Word2vec、GloVe等。
这些方法利用神经网络模型对单词进行编码,并输出一个低维度的向量作为单词的词向量。
这种方法可以使得语义上相似的单词具有相似的向量表示。
三、文本分类文本分类是一项重要的NLP任务,其旨在给定一个文本,将其分配到一个预定义的类别中。
向量空间方法在文本分类中的应用极为广泛。
在该方法中,文本可以被看作是词向量的线性组合,而分类则可以被看作是在词向量空间中找到最近邻的标签向量。
这种方法称为K最近邻(K-Nearest Neighbor,KNN)分类法。
通过KNN分类法,我们可以解决许多文本分类问题,如垃圾邮件分类、情感分析等。
在SVM、决策树等其他分类方法中,向量空间方法也往往被广泛使用。
基于LPP和Rocchio的文本分类方法

基于LPP和Rocchio的文本分类方法提要:支持向量机(SVM)是最常用的文本分类算法之一,但文本特征空间维数巨大的问题会影响分类的效果。
为此,提出了一种提高SVM分类性能的方法。
本文利用LPP算法对特征空间的维数进行降维,然后用SVM算法进行分类。
实验结果证明,该算法能够有效地提高分类的准确率。
关键词:Rocchio算法;LPP算法;文本分类引言随着互联网的快速增长,信息资源也飞速的增多,形式也多种多样,其中文本占大多数。
那么怎样从大量的文本信息中搜索到自己想要的信息[1],就成为了人们关注的焦点。
文本分类技术在信息检索中起着重要的作用,因此,文本分类技术的成为了研究的对象。
本文是对特征维数在利用互信息进行特征提取的基础上,然后采用LPP进行降维,从而提高了Rocchio分类器的分类性能。
1.Rocchio算法Rocchio算法[2]又称为类中心最近距离判别算法,是基于向量空间模型和最小距离的算法,最早是由Hull提出来的,它是通过信息检索中用来计算“询问”与文本间的关联程度Rocchio公式改造而来的。
由于Rocchio分类器非常的直观和简单,使得它广泛应用于文本分类领域中。
Rocchio算法的训练过程的目的是获得所有类别的中心向量,分类阶段是计算测试集文本与每一个类别中心向量的相似度,相似度最大的类别就是测试集文本所属的类别。
Rocchio算法对于类间距离较大而类内距离较小的类别分布情况能达到较好的分类效果。
这种算法计算简单、迅速,因此采用它有助于节省时间,提高效率。
其计算类中心向量Oj公式为:其中,Nj表示第Cj类中文本的总数,Yij表示类别Cj中的第i个文本向量。
向量相似度的度量方法有夹角余弦、向量内积、欧氏距离等,本文采用的是夹角余弦的方法,即总的来说,Rocchio算法分类原理简单,且在进行训练和分类时计算量也相对较小,分类速度较快。
2.LPP算法LPP算法具有保持数据集的局部非线性流行结构信息的能力,计算简单,处理速度快等特点,利用该算法可以大大减少参与比较的向量文本的数目,其基本思想是通过原始空间中离得近的点在降维后的低维空间中也保持较近,因此能保留原始数据的局部结构。
中文文本数据分类研究

上海师范大学硕士学位论文中文文本数据分类研究姓名:***申请学位级别:硕士专业:计算机应用技术指导教师:张功镀;吴海涛20040501坶帅托人学颂l:学位论义中文义.牟=数据分类研究摘要随着信息技术的不断发展,特别是Internet应用的普及,网上信息成指数级增长,如何自动处理这些海量的信息,有效的保留大的文本集合成为了目前重要的研究课题。
对文本进行有效管理方法之一就是将它们进行系统的分类,即文本数据分类。
文本数据分类是一项重要的智能信息处理技术,是文本检索技术的基础,在新闻机构分类、电子会议、电子邮件自动分类和信息过滤等方面极具应用价值。
文本数据分类在传统的情报检索、网站索引体系结构的建立和WEB信息检索等方面也占有重要地位。
文本数据分类以文本挖掘技术为基础与核心,是近年来数据挖掘和网络挖掘领域当中的一个研究热点。
本论文介绍了中文文本数据分类的信息处理基础、向量空间模型,探讨了自动分词技术,详细分析多种文本特征选择算法和贝叶斯文本数据分类模型,本论文通过大量实验深入研究了多种文本特征选择算法:互信息MI(Mutualinformation),信息增益(InformationGain),X2估计,文本证据权,并对互信息进行了改进。
鉴于朴素贝叶斯的分类效果不佳,本论文又提出将机器学习中的Boosting思想结合到朴素贝叶斯的分类模型中,对朴素贝叶斯模型进行提升,实验证明,改进的互信息和给合了Boosting思想的朴素贝叶斯分类模型均产生良好的分类效果一分准率、分全率及F1值。
戈踺词:文本数据分类,特征选择,向量空间模型,自动分词,朴素贝叶斯海帅范人学砸I:学位论文中文文本数据分类埘究AbstractWiththedevelopmentofInformationTechnologyandimprovementofInternetapplication,informationoninternetexponentiallyincreased,itwasanimportantresearchsubjecttodealwithlargenumbersofinformationandtostorebigtextsetautomatically.Oneofeffectivemethodtomanagementtextsistoclassifythem,alsocalledtextciassi矗cation.Automatictextsclassificationisanintelligenttechnologyofinformationprocessing,andthefoundationoftextretrieval,whichappliedtonewscategorization,electronicconference,e-mailcategorizationandinformationfilteringere.Automatictextsclassificationplaysanimportantroleintraditionalintelligenceretrieval,foundationofwebindexarchitecture,webinformationretrieval,andSOon.Basedonwebminingtechnology,automatictextclassificationhasbecomeahotresearchareainthefieldofdataminingandnetmining.ThisthesisintroducedthetechnicalfoundationofChinesetextsclassification,VectorSpaceModel,anddiscussedChinesewordsegmentation,analyzedmanytextfeatureselectionalgorithmsandBayescategorizationmodel.Withalotofexperiments,thethesisdeeplyresearchedandevaluatedmanytextsfeaturesclcctionalgorithmsuchasMutualInformation,InformationGain,Chi—squareevaluation,WeiightofEvidenceforText.ThethesisalsodidanimprovementonMutualInformation.BecauseofineffectivenessofNa'fveBayesmodelfortextclassificationthisthesisproposedintegratingBoostingtheoryofmachinelearninginclassificationprocess,boostNaiveBaycscategorizationmodelthroughmanytimestraining。
_情报学报_1999-2008年国内文本分类研究文献计量分析

1999-2008年国内文本分类研究文献计量分析*肖可奉国和(华南师范大学经济与管理学院信息管理系,广州 510006)摘要文本分类作为处理和组织大量文本数据的关键技术,在信息过滤、信息检索、搜索引擎、数字图书馆等领域有着广泛的应用前景。
基于文献计量法对1999-2008年间文本分类相关研究论文作了统计分析,按基础理论研究和应用研究两部分分别进行了深入的探讨,前者涉及了文本分类过程中的各种关键技术:文本预处理、文本表示、特征降维、分类算法、效果评估,后者则包括文本分类在各领域的应用研究和文本分类系统的设计与开发。
文章深入地揭示了文本分类研究内容、发展历程、研究热点和理论成果,并对未来的研究趋势进行了预测。
关键词文本分类自动分类文献计量统计分析A Statistical Analysis of Papers on Text Categorization from 1999 to 2008 in ChinaXiao Ke Feng Guohe(School of Economics & Management, South China Normal University, Guangzhou 510006)Abstract Being the key technology to process and organize substantial data, text classification is significant in information filtering, information retrieval, search engine, digital library and other areas. This article analyzes the papers of text categorization those published from 1999 to 2008 based on quantitative method, and analyzes fundamental research and applied research, the former includes the technologies in text classification: text preprocessing, text representation, feature reduction,classification algorithm, effect evaluation, the later includes the applied research of text classification in various fields and the design and development of text classification systems. The article reveals the contents of text classification, the development process, research hotspots, theoretical achievements and predicts the future trends.Keywords text categorization automatic categorization bibliometrics statistical analysis文本分类结合信息处理技术、机器学习和统计学习理论,在文本识别、搜索引擎、信息过滤、电子政务、数字图书馆等方面有着深入的应用,已经成为信息处理现代化的关键。
基于词向量空间模型的中文文本分类方法

第3 0卷 第 1 0期 20 0 7年 1 0月
合 肥 工 业 大 学 学 报 (自然科 学版 )
J OURNAL OF E H FEI NI U VERS TY I OF TECHNOLOGY
Vo. 0No 1 13 . 0
p e e t d me h d h sh g e r cso n fi in y r s n e t o a i h rp e ii n a d e f e c 。 c
Ke r s t x ae o iain;v co p c o e;K — e r s eg b r y wo d :e tc tg r to z e t rs a em d l n a e tn ih o ;wo d v co p c d l r e t rs a emo e
似度 。实验证 明, ;向量空 间模型 ;K_ 最近邻 居 ; 向量空间模型 词
中图 分 类 号 : P 8 T 12 文献标识码 : A 文 章 编 号 :0 35 6 (0 7 1—2 10 10 —0 0 2 0 )01 6 —4
摘
要: 大多文本分类方法是基于 向量空间模 型的 , 基于这一模型 的文本 向量维数较高 , 导致分类器效率难 以
提高 。针对这一不足 , 该文提出基于词 向量空间模 型的文本 分类 方法 。其 主要思想是把文本 的特征词表示成 空间向量 , 通过训练得到词一 类别支持度 矩阵 , 据待分文 本的词 和词— 根 类别 支持度 矩 阵计 算文本 与类 别 的相
文本 分类 是指把 一组 预先 由专家 分类 过 的文 本 作为训 练集 , 对训 练集进 行分 析得 出分类 模式 , 用 导 出的分类模 式对其 他 文本加 以分 类 _。它 主 1 ] 要应 用于信 息检 索 、 机器 翻译 、 自动文 摘及信 息过
一种基于KNN的文本分类算法

一种基于KNN的文本分类算法
余悦蒙; 黄小斌
【期刊名称】《《电脑知识与技术》》
【年(卷),期】2012(008)007
【摘要】KNN(K—Nearest Neighbor)是向量空间模型中最好的文本分类算法之一。
但是,当样本集较大以及文本向量维数较多时,KNN算法分类的效率和准确率就会大大降低。
该文提出了一种提高KNN分类效率的改进算法,并且改进了相似度的计算方法,能更准确的判断维数高且样本集大的文本向量。
算法在训练过程中计算出各类文本在向量空间中的分布范围,在分类过程中,根据待分类文本向量在样本空间中的分布位置,缩小其K最近邻搜索范围。
实验证实改进的算法可以在保持KNN分类性能基本不变的情况下,显著提高分类效率。
【总页数】3页(P1564-1566)
【作者】余悦蒙; 黄小斌
【作者单位】厦门大学信息科学与技术学院福建厦门361005
【正文语种】中文
【中图分类】TP301
【相关文献】
1.一种基于Canopy和粗糙集的CRS-KNN文本分类算法 [J], 姚彬修;倪建成;于苹苹;曹博;李淋淋
2.一种基于中心文档的KNN中文文本分类算法 [J], 鲁婷;王浩;姚宏亮
3.一种基于密度的改进KNN文本分类算法 [J], 茅剑;刘晋明;曹勇
4.一种基于粗糙集的改进KNN文本分类算法 [J], 苟和平;景永霞;冯百明;李勇
5.一种基于KNN的文本分类算法 [J], 余悦蒙;黄小斌
因版权原因,仅展示原文概要,查看原文内容请购买。
向量空间模型VSM
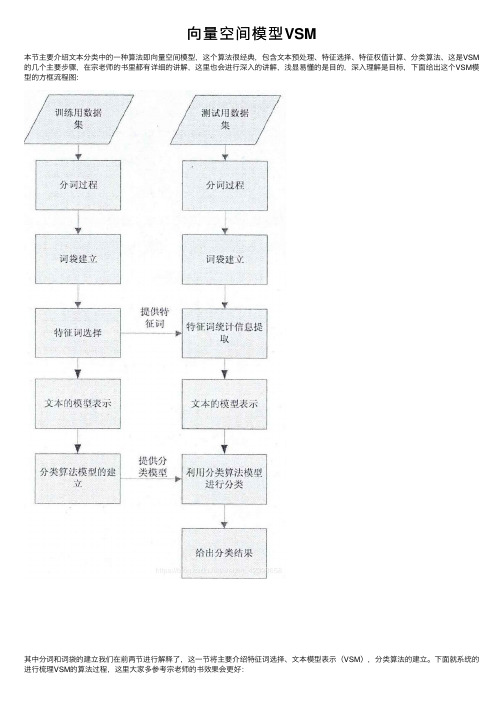
向量空间模型VSM本节主要介绍⽂本分类中的⼀种算法即向量空间模型,这个算法很经典,包含⽂本预处理、特征选择、特征权值计算、分类算法、这是VSM 的⼏个主要步骤,在宗⽼师的书⾥都有详细的讲解,这⾥也会进⾏深⼊的讲解,浅显易懂的是⽬的,深⼊理解是⽬标,下⾯给出这个VSM模型的⽅框流程图:其中分词和词袋的建⽴我们在前两节进⾏解释了,这⼀节将主要介绍特征词选择、⽂本模型表⽰(VSM),分类算法的建⽴。
下⾯就系统的进⾏梳理VSM的算法过程,这⾥⼤家多参考宗⽼师的书效果会更好:⽂本分类就是在给定的分类模型下,由计算机根据⽂本内容⾃动判别⽂本类别的过程。
随着⽂本分类技术的发展,不同的⽂本表⽰模型逐渐出现多种⽂本分类算法,使得⽂本挖掘领域道路越来越宽。
⽬前已经出现多种中⽂⽂本表⽰⽅法,如布尔模型、向量空间模型、潜在语义模型和概率模型等。
所以在构造⾃动⽂本分类器时,⾯临的选择也越来越多。
空间向量模型是⼀种出现较早的⽂本表⽰模型,但现在仍然在⼴泛的使⽤。
本篇的重点是对已经出现的基于向量空间模型的⽂本分类算法进⾏研究分析。
⽂本分类的定义Sebastiani(2002)以如下数学模型描述⽂本分类任务。
⽂本分类的任务可以理解为获得这样的⼀个函数:其中,表⽰需要进⾏分类的⽂档,表⽰预定义的分类体系下的类别集合。
T值表⽰对于来说,⽂档属于类,⽽F值表⽰对于⽽⾔⽂档不属于类。
也就是说,⽂本分类任务的最终⽬的是要找到⼀个有效的映射函数,准确地实现域D×C到值T或F的映射,这个映射函数实际上就是我们通常所说的分类器。
因此,⽂本分类中有两个关键问题:⼀个是⽂本的表⽰,另⼀个就是分类器设计。
⼀个⽂本分类系统可以简略地⽤下图所⽰:⽂本表⽰中⽂⽂本信息多数是⽆结构化的,并且使⽤⾃然语⾔,很难被计算机处理。
因此,如何准确地表⽰中⽂⽂本是影响⽂本分类性能的主要因素。
经过多年发展,如下图所⽰,研究⼈员提出了布尔模型、向量空间模型、潜在语义模型和概率模型等⽂本表⽰模型,⽤某种特定结构去表达⽂本的语义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
rs e tv l .F n l , e p r n s ls s o t a h e p r a h,p p s d i h s p p r o t e o ms pan o e e c e p ciey ial y x i e me tr u t h w h tt e n w a p c e o o r o e n t i a , u p r r li r g n r e f i he a c ia t o swi mp o e c u a y ir rh c meh t i r v d a c r c . l d h
维普资讯
第2 6卷 第 5期
20 0 6年 5 月
文 章 编 号 :0 1— 0 1 20 ) 5—12 0 10 9 8 (0 6 0 15— 2
计 算机应 用
Co utrAp l ains mp e p i t c o
V l2 o 5 o _ 6 N .
Hir r h c lc tg rz t n meh d fC i ee tx a e n v co p c d l e a c ia a e o iai t o so hn s e tb s d o e t r s a emo e o
XI e HE Z o g s i AO Xu , h n —h
bt f tr sl t n a d ct o zt n m to , e e o , et e D a Slc o F S , nd a grh f o e ue e ci a gr a o ehd h a e o n e i i a nw m t d h F a r u -eetn( D ) a a o t o u l i n l i m
Heaci et a gr a o( T )bsdo et ae o e w s rpsd F Si t pr r a r slco ah i r h a T x C t o z inH C ae nvc r pc d l a ooe . D ef m f t e eet ni ec r c l e i t os m p so o e u i n
Ma 0 y 2 06
基 于 向量 空 间模 型 的 中文文本 层次 分 类 方 法研 究
肖 雪 , 中市 何
( 重庆 大 学 计 算机 学院 ,重庆 404 ) 004
(a ee 6 .o ) zi r@1 3 cr h n
摘 要 : 文本 分类 的 类别数 量庞 大的情 况下 , 次分 类是 一种有 效 的分类 途径 。针 对层 次分类 在 层 的结构特点, 考虑到不同的层次对特征选择和分类方法有不 同的要求, 出了新的基于向量空间模型 提 的二重特征选择方法 F S以及层次分类算法 H C D T 。二重特征选择 方法对每 一层均进行一次特征选 择, 并逐层 改 变特 征数 量和 权 重计 算方 法 ; T H C算 法把 分 别对 粗 分 和 细 分 更 有效 的 类 中心 向量 法 与 S M 方法相 结合 。 实验 表 明 , 方法相 对 于平 面分 类和一般 的层 次分 类 方法 , V 该 有较 高的准确 率。 关键词 : 次分 类 ; 层 向量 空间模 型 ; 重特征选 择 ; 重计 算 二 权 中 图分 类号 : P 9 文 献标识 码 : T31 A
( ol efC m u r cec,C og i n e i,C og i O O4 hn ) C lg o p t i e hn q gU i rt h nq g4O 4 ,C i e o eS n n v sy n a
Ab t a t n lr e a u t o d t n f e tq a t y ir r hc l e t ae o z t n w sa f ci ea p o c .Ai i g sr c :O a g mo n n i o so x u n i ,he a c ia x tg r ai a n e e t p r a h c i t t t c i o v mn a t c u a h r ce s c fhe a c ia e tc tg rz t n a d c n i e n a o s d ma d ftx s i i e e tl v l o t r t rlc a a tr t so ir r h c tx ae o ai , n o s r g v r u e n s o t n df r n e es n su i i l i o di i e
Ke o d : i aci a grai ;vco saem e;F Sfa r u - l t n ;tct o zt n etr pc o l D (et ed a s e i ) e w i i r c l e i o d u l e co m hn
c s fai to dSp ot et cieS M ,w i rvs oeeet ef r dc s ct nadsbiio l s ct nme d a u prV c r hn( V ) hc p e r f c v r o l i a o udv in ai o i h n o Ma ho m i ob a a f i n s i s