信息检索模型研究概述
用户信息检索中的相关性反馈模型研究
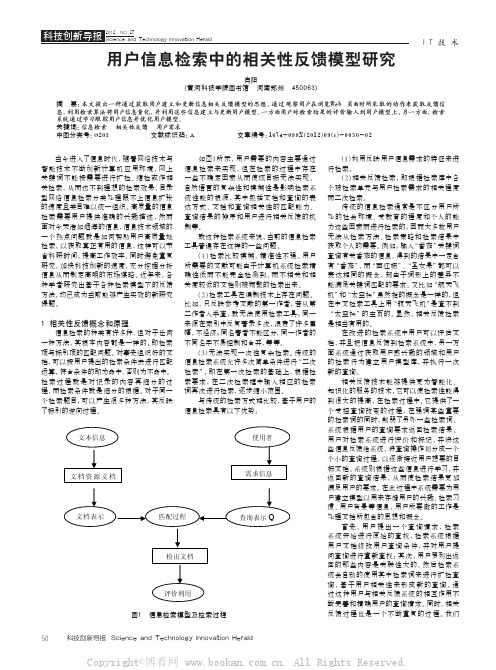
一种方法,其根本内容 都是一样的,即检 索 项与 标引项 的匹 配 问 题 。对事先 组 织 好 的 文 档,可 以 按 用户 提 出的 检 索条 件 去 进行匹 配 运算,符合条件的即为命中,否则为不命中。 检索过程就是对记录的内容再细分的过 程,而检 索条件就 是细分的根据。对于同一 个检 索题目,可以产生很多种 方法,其反 映 了标引的逆向过程。
科技创新导报 2012 NO.27 Science and Technology Innovation Herald 用户信息检索中的相关性反馈模型研究
IT技术
肖阳 (黄河科技学院图书馆 河南郑州 450063)
摘 要:本文提出一种通过获取用户建立和更新信息相关反馈模型的思想。通过观察用户在浏览Web 页面时所采取的动作来获取反馈信 息,利用检索算法将用户信息量化,并利用这些信息建立与更新用户模型。一方面用户对检索结果的评价输入到用户模型上,另一方面,检索 系统通 过学习跟 踪用户信息并优化用户模型。 关 键 词:信息检 索 相关性反馈 用户需求 中图分类号:G203 文献标识码:A 文章编号:1674-098X(2012)09(c) -0050 -02
传 统 的 信息检 索 通常是 不区 分用户所 处 的 社 会 环 境、受 教 育 的 程 度 和 个人 的 能 力 这 些因素 而 进行 检 索 的,因 而 大多 数 用户 无 法 从检 索 方 法、检 索 策 略和 检 索 结 果中 获取个人的需要。例如,输入“番茄”关键 词 查 询 有关 番 茄 的 信息,得 到 的 结 果中一定含 有“番茄”,而“西红柿”、“圣女果”都 可以 表 达 相 同 的 概 念,却由于 词 形上 的 差 异 不 能满足关键 词匹配的要求。又比如“航天飞 机”和“太 空 梭”虽 然 指 的 概 念 是 一样 的,但 在中文 检 索工具上用“航天飞机”是查不到 “太 空梭”的 主页的。显 然,相 关反馈检 索 是相当有用的。
信息检索基本原理

信息检索基本原理信息检索是指通过计算机技术获取、组织和利用文本信息的过程。
它是计算机应用领域中重要的研究方向之一,也是现代社会信息化进程中不可或缺的组成部分。
1. 信息需求分析信息需求分析是信息检索的第一步,也是最重要的一步。
它涉及识别用户的信息需求、确定检索策略、选择合适的检索语言等内容。
在这一阶段,需要对用户信息需求的主题、范围、领域等进行分析,以便更准确地确定检索规则和选择检索词语。
2. 信息检索模型信息检索模型是指描述和解释信息检索过程和结果的数学模型。
信息检索模型包括传统的布尔、向量空间和概率模型等。
布尔模型是最早的信息检索模型,它将文档看作是一个集合,用布尔运算符AND、OR、NOT进行查询。
向量空间模型则把文档看作是一个向量空间,用欧几里得距离或余弦相似度来计算文档之间的相似度。
概率模型则根据贝叶斯定理来计算文档的概率。
3. 检索语言检索语言是指在信息检索过程中用来表达信息需求的语言。
常见的检索语言包括人工语言、自然语言和形式语言。
人工语言是由人工定义的符号体系,例如机构名、作者名、出版社等。
自然语言则是人们日常使用的语言,例如英语、中文等。
形式语言是计算机可识别的语言体系,例如SQL、XPath等。
4. 检索策略检索策略是指根据信息需求制定的检索规则和方法。
它通常包括查询词语、检索模型、检索路径、检索结果排序等。
查询词语是检索语言中用来表达用户信息需求的关键词或短语。
检索路径则是指检索过程中所采用的搜索引擎或数据库,并对其应用检索模型。
5. 检索结果评价检索结果评价是对检索结果的量化评估。
常见的评价指标包括查准率、查全率、F-measure、平均准确率等。
查准率是检索系统返回的结果中正确的结果所占的比例,查全率是系统返回的正确结果与所有正确结果的比例。
F-measure则是查准率和查全率的加权平均值,平均准确率则是查准率的平均数。
综上所述,信息检索基本原理包括信息需求分析、信息检索模型、检索语言、检索策略和检索结果评价等方面。
信息检索模型

信息检索模型信息检索模型是指通过计算机系统从大规模信息中自动地检索出与用户需求相关的信息的一种技术。
它是信息检索领域的重要研究内容,旨在提高用户检索信息的效率和准确性。
一、信息检索的定义和基本原理信息检索是指根据用户输入的查询需求,在大规模信息库中自动地查找并返回与用户需求相关的信息的过程。
它基于一定的检索模型和算法,通过匹配和排序等过程,将最相关的信息呈现给用户。
信息检索的基本原理包括以下几个方面:1. 查询处理:用户输入的查询需求经过预处理和分析,提取关键词和特征,形成查询向量。
2. 文档表示:对于每个文档,通过特征提取和表示方法,将其转化为向量表示,以便与查询向量进行匹配。
3. 相似度计算:根据查询向量和文档向量之间的相似度计算方法,评估文档与查询的相关性。
4. 排序和评价:根据相似度计算结果,对文档进行排序,将最相关的文档排在前面,并根据评价指标对结果进行评估。
5. 结果呈现:将排序后的文档结果以列表或摘要的形式呈现给用户,用户可以根据需要进行浏览和选择。
根据不同的检索模型和算法,信息检索可以分为多种模型,常见的有布尔模型、向量空间模型和概率模型等。
1. 布尔模型布尔模型是最早的信息检索模型之一,它基于布尔代数,将查询和文档转化为布尔表达式,通过逻辑运算来匹配和检索文档。
布尔模型简单直观,适用于处理简单的查询需求,但不擅长处理复杂的查询语句和表达需求的语义。
2. 向量空间模型向量空间模型是一种基于向量表示的信息检索模型,它将查询和文档都表示为向量,通过计算向量之间的相似度来评估文档的相关性。
向量空间模型可以灵活地处理复杂的查询需求和语义表达,常用的相似度计算方法包括余弦相似度和欧氏距离等。
3. 概率模型概率模型是一种基于概率统计的信息检索模型,它通过建立查询和文档之间的概率模型,利用统计方法计算文档的相关性。
概率模型可以较好地处理查询的不确定性和语义的歧义,常用的概率模型包括BM25模型和语言模型等。
个性化信息检索系统的用户模型研究

用 户 的兴 趣 偏好 大 多是 不 同 的 , 息 系 统 必 须 高 度 个 性 化 以 服 信
的不 相关 文 档 。
成 为情 报界 研 究 的 热 点 问 题 。 个 性 化 信 息 服 务 包 括 个 性 化 内 容 定 制服 务 、 性 化信 息 检索 服 务 、 性 化 界面 定 制 服 务 、 性 个 个 个 化信 息 推荐 服 务 。本 文 主 要 探 讨 个 性 化 信 息 检 索 服 务 和 基 于
的要求 。 为 了解 决信 息 资 源 的 有 效 利 用 与 个 体信 息 需 求 差 异 之 间 的矛盾 , 个 性 化 信 息 服 务 ” 来 越 引 起 人 们 的 重 视 , “ 越 日益
认 知 其信 息 需求 的所有 内容 。在 进 行 信息 检索 时 , 户 是 否 了 用 解 搜 索 引擎 的机 制 及数 据库 的组 织 结 构 , 系 统 的 检 索 效 率 没 对 有 影 响 。b 系统 会 根 据 用 户 模 型 将 最 有 价 值 的 信 息 自动推 荐 、 给 用 户 , 时用 户 不 必 进 行 查 询 修 改 便 可 得 到 满 意 的 查 询 结 同 果 。C 系统 为用 户 提供 的信 息 更 有针 对 性 , 索 结 果 的 文 档 排 . 检 序 与 用户 需 求一 致 , 这样 , 户 就 不 必 浪 费 时 间 下 载 、 读 大量 用 阅
务 于 每个 用 户 。 2 个 性 化信 息 检 索 系统 2 1 个性 化 信 息检 索 系统 一般 原理 【 . l 其 原 理 可表 述 为 :
信息检索的定义

信息检索的定义信息检索的定义信息检索是指在大量的数据中寻找到用户所需要的信息。
这种寻找过程通常是通过计算机程序来实现的,其目的是帮助用户快速准确地获取所需信息。
一、信息检索的概述信息检索是一种基于计算机技术和信息科学理论的应用性研究领域。
它主要涉及到如何从海量数据中提取出用户需要的有用信息,以及如何优化检索效率和结果质量。
信息检索技术已经广泛应用于互联网搜索引擎、电子图书馆、数字化档案管理、社交网络分析等领域。
二、信息检索的基本原理1.建立索引建立索引是实现信息检索最基本的步骤之一。
它将文档中出现过的词语进行统计和分类,并为每个词语分配一个唯一标识符,以便后续查询时能够快速定位到相关文档。
2.查询处理查询处理是指将用户输入的查询语句转换成计算机可处理的形式,并根据查询条件匹配相应文档。
查询处理包括了分词、去停用词、词干提取等步骤,以保证查询语句与文档库中的内容能够准确匹配。
3.评价指标信息检索系统的评价指标通常包括召回率、准确率和F值等。
其中,召回率是指检索到的相关文档数占所有相关文档数的比例;准确率是指检索到的相关文档数占所有检索到的文档数的比例;F值是综合考虑了召回率和准确率的综合评价指标。
三、信息检索的主要技术1.分词技术分词技术是将一段连续的自然语言文本切分成一个个单独的词语,并为每个词语赋予相应的权重。
这种技术可以有效提高查询效率和结果质量。
2.向量空间模型向量空间模型是一种用于表示文本内容和查询语句之间相似度的方法。
它将每篇文档表示为一个向量,并通过计算两个向量之间的余弦相似度来判断它们之间是否存在相关性。
3.机器学习机器学习是一种通过训练数据来优化信息检索系统性能的方法。
它可以帮助系统自动调整参数,从而提高系统对用户需求的理解能力和搜索结果质量。
四、信息检索面临的挑战1.语义理解信息检索面临的最大挑战之一是如何理解用户的搜索意图和查询语句。
由于自然语言存在歧义性和多义性,因此需要开发出更加智能化的算法来实现语义理解。
新型信息检索模型发展研究

中图分类号 : G 2 5 2 . 7
文献 标 识 码 : A
d o i : 1 0 . 3 9 6 9 / j . i s s n . 1 0 0 5 — 8 0 9 5 . 2 0 1 3 . 0 4 . 0 2 3
Re s e a r c h o n De v e l o p me n t o f Ne w I n f o r ma t i o n Re t r i e v a l Mo d e l s
( 三 峡 大 学 图 书馆 湖 北 宜 昌
摘
4 4 3 0 0 0 )
要: 介 绍 了 3个 新 型 信 息 检 索 模 型 —— 信 念 网 络 模 型 、 粗 糙 集 理 论 检 索 模 型 和 遗 传 算 法 检索 模 型 。 认 为 信 念 网 络模 型 以
概率推理为基础 , 推理结果说服力强 , 并 采用 图形 化 网络 结 构 直 观 地 表 达 变 量 的 联 合 概 率 分 布 及 其条 件 独 立性 , 能 大 量 节 约 概 率 推理计算 ; 粗糙集理论检索模型通过不可分辨关系确定问题的近似域 , 对 问题 不 确 定 性 的 描 述 和 处理 具有 客 观 性 ; 遗 传 算 法 检 索
s h i p , S O t h a t i t c a n d e s c i r b e a n d h nd a l e w i t h he t u n c e r t a i n t y o b j e c t i v e l y ; g e n e t i c a l g o i r t h m m o d e l s i m u l a t e o r g a n i s m’ S g e n e t i c nd a e v o -
基于语义网的数字图书馆信息检索模型研究

收 稿 日期 :01— 2 0 2 0 0— l
; I :
基于语义 网的数 字 图书馆信 息检 索模 型研 究
袁 颖, 赵捧 未
( 西安 电子科技大学经济管理学院 , 陕西西安 ,10 1 707 ) 摘 要: 介绍 了语 义网的相关知识 , 针对数字 图书馆信 息检 索效率不高的问题 , 在现有
l 语 义网
19 9 8年 , b的创始 人 Tm B re — e 次 提 出 “ 义 We i en r Le首 s 语
We ” Smat b 的概 念 、 术路 线和 基本思 想 . 给 出定 b (e n cWe ) i 技 并
义 【。 l语义 We J b的知识表示具有创建上的分散性 , 义具有应用上 的通用性 , 需要一个统一框架 , 这个框架应 该能够满足这种分散 性以及由这种 分散性所带来 的安全性 , 满足这些知识跨应州 、 跨
X ML将提取的元数据组织存储在元数据 库中。而在元数据提取
过 程巾 , 可以参考 以下方 法 :( 1 分文档各部 分的重要标志 , ) 即对 文档具有重要意义的关键词可认为是元数据 提取过程的重要依
据; 对于许多文档巾的普遍 出现 的元数据信息 , 可预先提取 , . 如
图 l 语 义网体系结构 语 义 网体 系结 构 有 7层 : 底层 U IU i r eo r 最 R ( n o R suc fm e 计算查询 和文档之 间的相似度 的方法也有 局限。在 现有数字图
书馆信息检索模型 的基础上 , 引入语义网技术 。 以下就是基于语 义网的数字图书馆 信息检索模型( 图 3 。 ) 基于语 义网的数字 图书馆信息 检索模型 可分 为 3个模块 : 数字 图书馆信息资源处理 、 刚户接 口及查询信息处理 、 检索匹配
一种改进的向量空间信息检索模型研究

击 率 , 往 采 取 各 种欺 骗 手 段 , 如 在 网 页 J下 文 中加 大 量 与 网 往 例 页 背 景 色 相 同 的关 键 词 、在 图 片 的 < l 标 签 中加 人 大 量 关 键 at > 词 、 网 页 源码 注 释 中加 入 大量 的关 键 词 ( 然 注 释 不 会 在 浏 览 在 虽
常见 的信 息 检 索模 型有 : 1 布 尔模 型 : 是 基 于 特 征 项 的 严格 匹配 模 型 , 本 查询 的 ) 它 文
匹 配 规 则 遵循 布 尔 运 算 的 法 则 。布 尔 运 算 包 括 A ND、 OR、 T NO 三 种 , 别 表示 包 含 全 部 关 键 字 , 意 一 个 关 键 字 以及 不 能 含 有 分 任
检索模型是信鼬 索领域中广泛使用的一种信息检索模型。其
基本思路是 : 息检索 中, 在信 文档或者查询的基本含义都是通过
其所包含的词 ( 检索 单元 ) 来表述 的, 可以定义 由检 索单元组成 的向量来描述 每÷篇 文档和每一条检索 ,再通 过计算文 档与查
询 之 间 的 相关 程 度 来判 断 文 档 与 查 询 是 否 相关 ,与 某 一 特 定 的 查询 的相 关程 度越 高 者 被 认 为 是 与该 查 询 越 相 关 的 文档 。 V M 是 一 个 应 用 于 信 息 过 滤 , 息 撷 取 , 引 以 及 评 估 相 S 信 索
摘 要
传 统 的 信 息检 索 方法 忽 略 了文档 结构 对 词 的 重要 性 。在 此 基 础 上 , 出 了改进 的 向 量 空 间检 索模 型 , 用 该模 型进 行 提 利 相 似度 计 算 。 试 验表 明该 模 型 可 以提 高信 息 检 索 的 查 准率 和 查 全 率 不 高的 缺 点 。 关键 词 : 索 引擎 , 索模 型 , 全 率 , 准 率 搜 检 查 查
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息检索模型研究概述
【摘要】随着信息量的日益增长,用户要在巨大的信息海洋中查找自己所需的信息就变得复杂,这就需要对信息进行相关性选择,以提高查询的检全率和检准率。
为此,人们提出了一系列检索模型,本文介绍了这些检索模型以及在此基础上的发展。
【关键词】信息检索;检索模型;认知心理学;综述
一、引言
信息检索是寻找相关信息的过程,而检索过程始终都涉及相关性问题。
相关性是信息需求内容与文献内容之间的一种关系,为了正确地解释检索过程,就必须给相关性一个合理的衡量。
为此,人们提出了一系列检索模型,本文就讨论介绍了这些信息检索模型研究的进展。
文中笔者将检索模型分为基于系统的检索模型、基于认知心理学的检索模型和基于本体的检索模型三大类。
二、基于系统的信息检索模型
在基于系统的检索模型中,可以分为逻辑模型、模糊模型、向量空间模型和概率模型。
1.逻辑模型及其发展
1957年,巴-希列尔(Y.Bar-Hille)提出布尔逻辑模型。
布尔逻辑式构造简单,但其不易全面反映用户的需求,匹配标准存在某些不合理的地方,且检索结果不能按照用户定义的重要性排序输出,很难控制输出量的大小,对用户的素质有很高的要求。
为了克服传统布尔逻辑模型的一些缺陷,Waller和Kraft在1979年提出了加权布尔逻辑检索模型。
加权布尔逻辑检索模型通过对标引词进行加权,解决了传统布尔逻辑检索模型的一些缺点,比如无法排序、不能区分检索词的重要程度,但同时也带来了一个问题,即布尔逻辑操作算符在不加权布尔逻辑查询情形下的许多算律(如交换律、结合律等)已不再成立。
在Waller和Kraft之后,Salton于1983年提出扩展布尔模型。
扩展模型是传统布尔逻辑检索模型完全匹配的严格性和向量模型提问的无结构性的折中,在保持布尔逻辑检索的结构式提问的同时,也吸取了模糊检索和向量检索模型的长处。
而且该模型中巧妙地引入了一个模型参数p,通过适当调节这个参数,Salton 模型可以分别表现为布尔模型、向量空间模型和模糊模型。
2.模糊模型及其发展
布尔模型和扩展的布尔模型主要是基于康托(Contor)的经典集合论,但经典集合论容不得模糊的概念,这对于信息检索过程中所存在的模糊性的解释造成一定的困难,用户对检索结果的满意程度也具有不确定性。
为了解决这种模糊性引起的不确定问题,人们引入模糊集合理论来构建模糊集合模型。
模糊集合模型是基于美国自动控制专家扎得(L.A.Zadeh)的“模糊集合”理论,模糊检索将文献看成是与某提问在一定程度上相关,对于每一个标引词,都存在一个模糊的文献集合与之相关;对于某一给定的标引词,用隶属函数表示每一文献与该词相关的程度,即隶属度,其取值在[0,1]上。
在模糊集合检索中,对于布尔模型的用户信息需求的处理通常是把表达用户需求的布尔逻辑式转换成析取范式的形式。
基于模糊集合模型的检索结果是建立在文献集上的,且其隶属度就是文献集对用户提问的相关程度的模糊子集。
但目前而言,还无法十分精
确、有效地确定这个隶属函数。
3.向量空间模型及其发展
向量空间模型(VSM)由Salton等人提出,向量空间模型把用户的查询要求和数据库文档信息表示成由检索项构成的向量空间中的点。
而通过计算向量之间的距离来判定文档和查询之间的相似程度。
然后,根据相似程度排列查询结果。
向量空间模型的关键在于特征向量的选取和特征向量的权值计算两个部分。
作为对向量空间模型的一种改进,S.K.M.Wong建立了广义向量空间模型,其中考虑了词与词之间的相依性。
该模型在没有假设词与词之间互相独立的前提下,把词向量用一组适当选择的正交基向量来表示,这样,词之间的关系可以直接由其向量表示给出较为精确的计算。
但是广义向量空间(GVSM)模型本身比传统的向量空间模型复杂,难于理解,计算复杂性和代价远高于传统的向量空间模型。
4.概率模型及其发展
①贝叶斯网络模型。
贝叶斯网络模型是概率信息检索模型的扩展,在信息检索领域,主要是利用贝叶斯网络模型表示术语间的关系以及对查询与文档间的相似度进行预测。
因为贝叶斯网络模型能很好地处理信息检索中的不确定性,并存储术语间的条件概率和概念语义,所以可以实现基于语义概念的查询。
②信任度网络模型。
1996年,Riberio-Neto和Muntz提出的信任度网络模型也是基于贝叶斯网络,模型采用一个明确定义的样本空间。
用户查询被模型化为一个二值随机变量,构成查询概念的标引词结点指向该二值随机变量,文献也与用户查询进行相同的处理。
在该模型中,将网络中的文献和查询分割开来,方便了附加的证据源,且由于文献和查询空间的分开,当逆命题不正确时,信任度网络模型可以重新产生由推理网络模型生成的任何排序策略。
三、基于认知心理学的信息检索模型
基于认知心理学的信息检索模型主要就是基于语义的信息检索模型,下面我们就介绍这样一些语义检索模型。
1.潜在语义索引模型
S.T.Dumais等人提出了潜在语义检索模型,是将文献和查询向量映射到与概念相关的维数较低的空间,可以通过把标引词向量映射到维数较低的空间来实现。
它认为在维数降低了的空间的检索可能优于在集合中的检索。
2.二元语义检索模型
二元语义检索模型是基于二元语义的信息检索模型。
该模型包含文档的表示、查询语句的表示、文档和查询的匹配三个部分。
在这个模型中,文件的表示使用索引词权重的形式,在查询语句中引入阈值权重,这样,用户对检索词表示文档内容时的重要程度提出了要求,匹配函数使用二元语义的匹配函数,通过自下而上的匹配过程,最终得到了每篇文档的检索值,对于传统的基于查询关键词精确匹配的信息检索模型,该模型能较好地满足用户查询要求中的灵活性。
四、本体模型及其发展
在对本体进行研究的基础之上,我国很多学者提出了一些基于本体的信息检索模型。
首先是中科大的王进、陈恩红等人研究的基于本体的跨语言信息检索模型,该模型利用本体来刻画不同语言中对应的领域知识,解决从查询语言到检索语言之间转换过程中出现的语义损失和曲解等问题,从而保证在检索过程中能够有效地遵循用户的查询意图,获得预期的检索信息。
之后不久,国防科技大学的宋峻峰、张维明等人提出另外一种基于本体的信息检索模型,它使用较好的兼顾了知识表达能力和推理效率的描述逻辑来构建本体,利用tableau算法和只含有原子角色情况下个体间的等价关系分别生成概念集和个体集的商集,从而得到具有语义的索引项集合,利用这些具有语义的索引项来生成较好地反映文档和用户信息需求语义的文档逻辑视图和用户信息需求逻辑视图。
五、结语
由此可见,各种检索模型都有自己的特征、优势和不足之处。
它们的发展并不是同步的,而是交叉、互补的,特别是许多检索模型还处于理论探索和实验系统阶段,在应用上还各有侧重,即使有实验数据,由于采集的样本不同(由于适用范围不尽相同),也很难对各种模型进行定量比较和评价。
总之,随着计算机技术、网络技术、多媒体技术、人工智能技术等的发展,信息检索模型已由传统的布尔逻辑模型发展到了定量化阶段,并不断向智能化、网络化方向发展,未来的检索模型将发展成为智能化、网络化、综合性的多媒体检索模型。
参考文献:
[1]刘红泉,张亮峰.布尔逻辑检索模型的分析探讨[J].现代情报,2004(9):4-6.
[2]袁鼎荣,谢扬才,陆广泉,刘星.一种新的基于软集合理论的文本分类方法[J].广西师范大学学报(自然科学版),2011(1):129-132.
[3]张荐硕,方钰.基于向量空间模型的Web服务发现方法[J].计算机工程,2011(3):36-38.
[4]李振东,费翔林.基于概念的信息检索模型研究[J].南京大学学报(自然科学),2002,38(1):99-109.
[5]武兴龙,刘新旺.二元语义信息检索模型[J].现代图书情报技术,2006(6):43-46.。