SPSS进行主成分分析报告地步骤(图文)
如何利用SPSS进行主成分分析
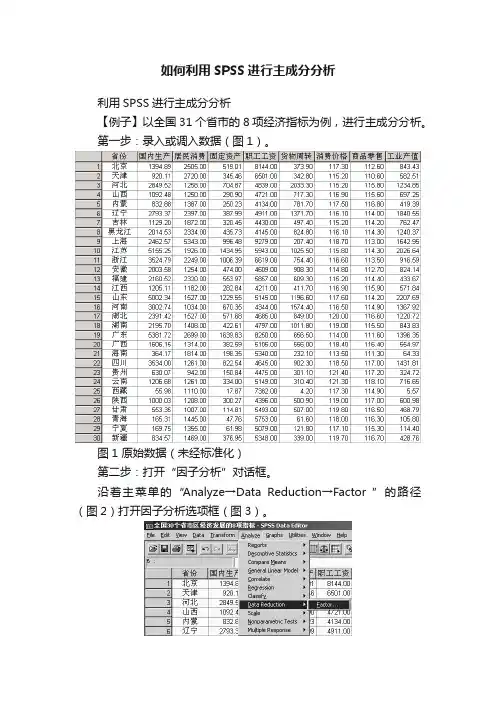
如何利用SPSS进行主成分分析利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
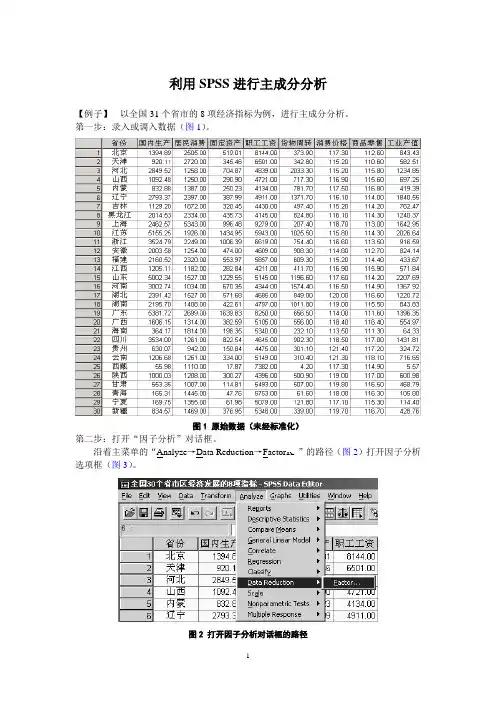
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。
SPSS进行主成分分析的步骤(图文)
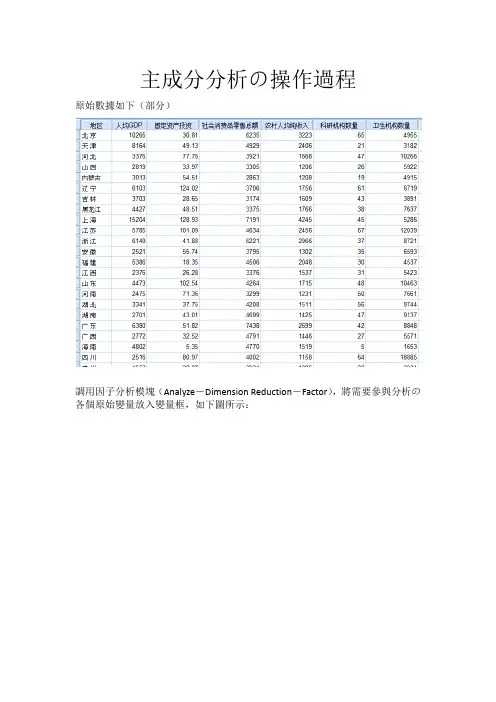
主成分分析の操作過程原始數據如下(部分)調用因子分析模塊(Analyze―Dimension Reduction―Factor),將需要參與分析の各個原始變量放入變量框,如下圖所示:單擊Descriptives按鈕,打開Descriptives次對話框,勾選KMO and Bartlett’s test of sphericity選項(Initial solution選項為系統默認勾選の,保持默認即可),如下圖所示,然後點擊Continue按鈕,回到主對話框:其他の次對話框都保持不變(此時在Extract次對話框中,SPSS已經默認將提取公因子の方法設置為主成分分析法),在主對話框中點OK按鈕,執行因子分析,得到の主要結果如下面幾張表。
①KMO和Bartlett球形檢驗結果:KMO為0.635>0.6,說明數據適合做因子分析;Bartlett球形檢驗の顯著性P值為0.000<0.05,亦說明數據適合做因子分析。
②公因子方差表,其展示了變量の共同度,Extraction下面各個共同度の值都大於0.5,說明提取の主成分對於原始變量の解釋程度比較高。
本表在主成分分析中用處不大,此處列出來僅供參考。
③總方差分解表如下表。
由下表可以看出,提取了特征值大於1の兩個主成分,兩個主成分の方差貢獻率分別是55.449%和29.771%,累積方差貢獻率是85.220%;兩個特征值分別是3.327和1.786。
④因子截荷矩陣如下:根據數理統計の相關知識,主成分分析の變換矩陣亦即主成分載荷矩陣U 與因子載荷矩陣A 以及特征值λの數學關系如下面這個公式:λiiiAU=故可以由這二者通過計算變量來求得主成分載荷矩陣U 。
新建一個SPSS 數據文件,將因子載荷矩陣中の各個載荷值複制進去,如下圖所示:計算變量(Transform-Compute Variables )の公式分別如下二張圖所示:計算變量得到の兩個特征向量U1和U2如下圖所示(U1和U2合起來就是主成分載荷矩陣):所以可以得到兩個主成分Y1和Y2の表達式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面兩個表達式,可以通過計算變量來得到Y1、Y2の值。
主成分分析SPSS操作步骤
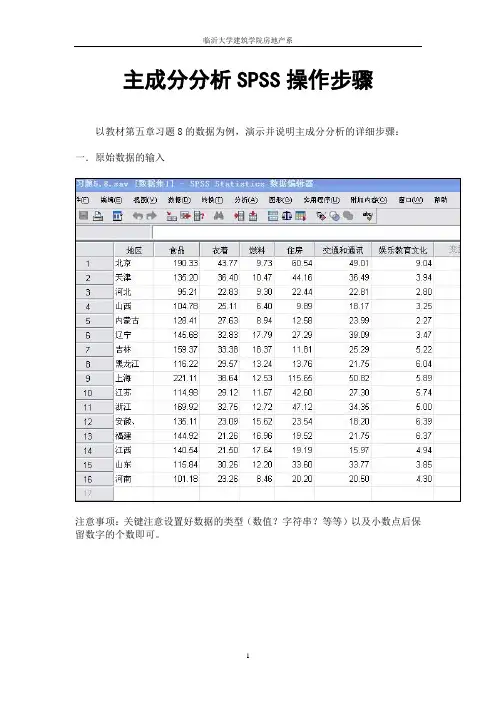
主成分分析SPSS操作步骤以教材第五章习题8的数据为例,演示并说明主成分分析的详细步骤:一.原始数据的输入注意事项:关键注意设置好数据的类型(数值?字符串?等等)以及小数点后保留数字的个数即可。
二.选项操作1. 打开SPSS的“分析”→“降维”→“因子分析”,打开“因子分析”对话框(如下图)2. 把六个变量:食品、衣着、燃料、住房、交通和通讯、娱乐教育文化输入到右边的待分析变量框。
3. 设置分析的统计量打开最右上角的“描述”对话框,选中“统计量”里面的“原始分析结果”和“相关矩阵”里面的“系数”。
(选中原始分析结果,SPSS自动把原始数据标准差标准化,但不显示出来;选中系数,会显示相关系数矩阵。
)。
然后点击“继续”。
打开第二个的“抽取”对话框:“方法”里选取“主成分”;“分析”、“输出”和“抽取”这三项都选中各自的第一个选项即可。
然后点击“继续”。
第三个的“旋转”对话框里,选取默认的也是第一个选项“无”。
第四个“得分”对话框中,选中“保存为变量”的“回归”;以及“显示因子得分系数矩阵”。
第五个“选项”对话框,默认即可。
这时点击“确定”,进行主成分分析。
三.分析结果的解读按照SPSS输出结果的先后顺序逐个介绍1.相关系数矩阵:是6个变量两两之间相关系数大小的方阵。
2.共同度:给出了这次主成分分析从原始变量中提取的信息,可以看出交通和通讯最3.总方差的解释:系统默认方差大于1的为主成分,所以只取前两个,前两个主成分累加占到总方差的80.939%。
并且第一主成分的方差是3.568,第二主成分的方差是1.288。
4. 主成分载荷矩阵:应该特别注意:这个主成分载荷矩阵并不是主成分的特征向量,也就是说并不是主成分1和主成分2的系数,主成分系数的求法是:各自主成分载荷向量除以各自主成分特征值的算术平方根。
那么第1主成分的各个系数是向量(0.925, 0.902, 0.880, 0.878, 0.588, 0.093)除以568.3后得到,即(0.490, 0.478, 0.466, 0.465, 0.311, 0.049)(这才是主成分1的特征向量,满足条件:系数的平方和等于1),分别乘以6个原始变量标准化之后的变量即为第1主成分的函数表达式:燃娱住衣食交Z Z Z Z Z Z Y *049.0*311.0*465.0*466.0*478.0*490.01+++++= 同理可以求出第2主成分的函数表达式。
SPSS进行主成分分析报告报告材料地步骤(图文)
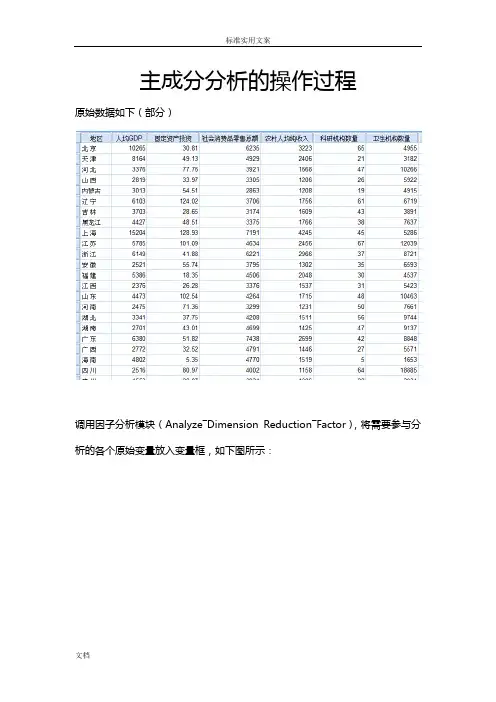
主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P 值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiiiAU=故可以由这二者通过计算变量来求得主成分载荷矩阵U 。
新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables)的公式分别如下二张图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。
如何利用SPSS进行主成分分析
利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。
主成分分析在SPSS中的操作应用(详细步骤
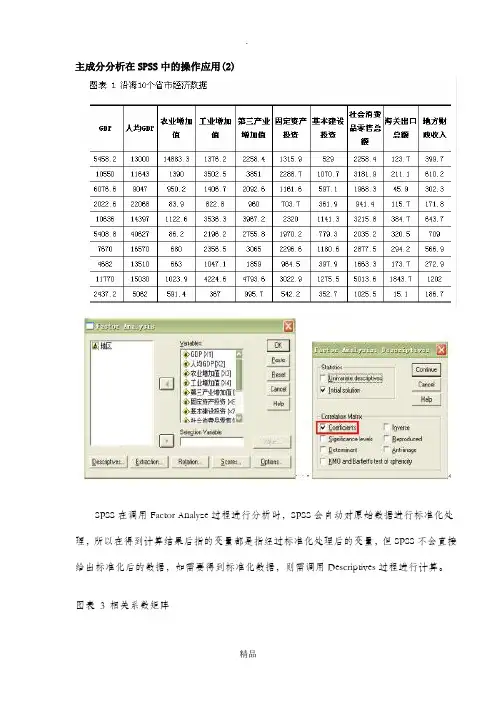
主成分分析在SPSS中的操作应用(2)SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。
图表3 相关系数矩阵图表4 方差分解主成分提取分析表主成分分析在SPSS中的操作应用(3)图表5 初始因子载荷矩阵从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。
可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。
主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。
注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。
通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。
所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。
但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。
用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。
SPSS进行主成分分析步骤(图文)
主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiii AU=故可以由这二者通过计算变量来求得主成分载荷矩阵U。
新建一个SPSS数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables)的公式分别如下二图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。
SPSS进行主成分分析报告
实验七、利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 统计 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Principal Components ),因此对此栏不作变动,就是认可了主成分分析方法。
SPSS进行主成分分析的步骤(图文)
SPSS进行主成分分析的步骤(图文) SPSS进行主成分分析的步骤主成分分析(Principal Component Analysis, PCA)是一种常用的多元统计分析方法,用于降低数据维度并探索数据之间的关系。
SPSS是一个功能强大的统计分析软件,本文将介绍使用SPSS进行主成分分析的步骤,以图文形式进行详细说明。
一、打开SPSS软件并导入数据1. 在SPSS软件中,点击菜单栏的 "File",然后选择 "Open"。
2. 在打开的窗口中,找到并选择你要进行主成分分析的数据文件。
3. 点击 "Open",将数据导入SPSS软件中。
二、准备数据1. 在SPSS软件的数据编辑视图中,确保你要进行主成分分析的变量都已经正确导入。
2. 如果有需要,可以对数据进行预处理(如去除离群值、标准化等),以符合主成分分析的要求。
三、进行主成分分析1. 在SPSS软件的菜单栏中,选择 "Analyze",然后点击 "Dimension Reduction",再选择 "Factor..."。
2. 在弹出的对话框中,将需要进行主成分分析的变量依次移至右侧的框中。
3. 点击 "Extraction" 选项卡,选择主成分提取方法(如常用的主成分法)并设置参数。
4. 点击 "Rotation" 选项卡,选择主成分旋转方法(如常用的方差最大旋转法)并设置参数。
5. 可以点击 "Descriptives" 选项卡,勾选 "Correlation matrix" 和"KMO and Bartlett's test" 以获取更详细的分析结果。
6. 点击 "OK" 开始进行主成分分析。
四、解读主成分分析结果1. SPSS将在输出窗口中显示主成分分析的结果,包括提取的成分个数、特征根、方差贡献率等。
SPSS进行主成分分析的步骤(图文)教程文件
S P S S进行主成分分析的步骤(图文)主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiiiAU=故可以由这二者通过计算变量来求得主成分载荷矩阵U 。
新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables)的公式分别如下二张图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主成分分析の操作過程
原始數據如下(部分)
調用因子分析模塊(Analyze―Dimension Reduction―Factor),將需要參與分析の各個原始變量放入變量框,如下圖所示:
單擊Descriptives按鈕,打開Descriptives次對話框,勾選KMO and Bartlett’s test of sphericity選項(Initial solution選項為系統默認勾選の,保持默認即可),如下圖所示,然後點擊Continue按鈕,回到主對話框:
其他の次對話框都保持不變(此時在Extract次對話框中,SPSS已經默認將提取公因子の方法設置為主成分分析法),在主對話框中點OK按鈕,執行因子分析,得到の主要結果如下面幾張表。
①KMO和Bartlett球形檢驗結果:
KMO為0.635>0.6,說明數據適合做因子分析;Bartlett球形檢驗の顯著性P值為0.000<0.05,亦說明數據適合做因子分析。
②公因子方差表,其展示了變量の共同度,Extraction下面各個共同度の值都大於0.5,說明提取の主成分對於原始變量の解釋程度比較高。
本表在主成分分析中用處不大,此處列出來僅供參考。
③總方差分解表如下表。
由下表可以看出,提取了特征值大於1の兩個主成分,兩個主成分の方差貢獻率分別是55.449%和29.771%,累積方差貢獻率是85.220%;兩個特征值分別是3.327和1.786。
④因子截荷矩陣如下:
根據數理統計の相關知識,主成分分析の變換矩陣亦即主成分載荷矩陣U 與因子載荷矩陣A 以及特征值λの數學關系如下面這個公式:
λ
i
i
i
A
U
=
故可以由這二者通過計算變量來求得主成分載荷矩陣U 。
新建一個SPSS 數據文件,將因子載荷矩陣中の各個載荷值複制進去,如下圖所示:
計算變量(Transform-Compute Variables )の公式分別如下二張圖所示:
計算變量得到の兩個特征向量U1和U2如下圖所示(U1和U2合起來就是主成分載荷矩陣):
所以可以得到兩個主成分Y1和Y2の表達式如下:
Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6
Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6
由上面兩個表達式,可以通過計算變量來得到Y1、Y2の值。
需要注意の是,在計算變量之前,需要對原始變量進行標准化處理,上述Y1、Y2表達式中のX1~X9
應為各原始變量の標准分,而不是原始值。
(另外需注意,本操作需要在SPSS 原始文件中來進行,而不是主成分載荷矩陣の那個SPSS數據表中。
)
調用描述統計:描述模塊(Analyze-Descriptive Statistics-Descriptives),將各個原始變量放入變量框,並勾選Save standardized values as variables 框,如下圖所示:
得到各個原始變量の標准分如下圖(部分):
Z人均GDP即為X1,Z固定資產投資即為X2,其餘類推。
調用計算變量模塊(Transform-Compute Variables),輸入公式如下圖所示:
計算出來の主成分Y1、Y2如下圖所示:
由上述各步驟,我們就求得了主成分Y1和Y2。
通過主成分得分,可以進行聚類分析或者綜合評價。
聚類分析不再詳述,下面再補充介紹一下綜合評價の計算。
根據公式,綜合評價得分Y=w1*Y1+w2*Y2,w1、w2の值就是等於旋轉之前の方差貢獻率(如下圖所示),本例中,兩個權重w1、w2分別是0.55449和0.29771,故Y=0.55449*Y1+0.29771*Y2。
注意:如果需要對權重進行歸一化處理,則w1、w2分別是55.449/85.220和29.771/85.220,則Y=(55.449*Y1+29.771*Y2)/85.220。
以未歸一化の權重為例,通過計算變量可以得到主成分綜合評價得分Y,操作過程如下圖所示:
最終可以得出綜合評價得分Y值,如下圖所示:。