使用Office 2003自带的OCR程序进行文字识别
利用MS Office工具提取图片中的文字

利用MS Office工具提取图片中的文字如果你手头有一份试卷的图片版,或者自己用扫描仪、摄像头拍摄的试卷图片,那么就请按照下面的步骤,将它们中的文字部分提取到word中进行编辑。
(要求office 2003)1、开始-程序-Microsoft Office-Microsoft Office 工具-Microsoft Office Document scanning。
该工具是MS office 2003自带的,但是默认却没有安装,所以此时很可能会弹出对话框,要求放入office 2003的安装光盘,乖乖,按照要求去做就行;2、安装完毕后,会自动启动该工具,在出现的对话框中,点击“扫描”。
如果此时弹出提示,不要理会,一路确定即可;3、很快会出现一个预览框,觉得从摄像头出来的图像满足要求,点击“捕捉”按钮即可;4、再点击“发送”-“完成”,然后会打开MS的Document Image工具,打开刚才捕捉到的图片;5、在Document Image工具的工具栏上,点击“页面”左侧的按钮“将图片发送到word”;6、word会自动打开,出现的就是已经提取的文字段落了;如果是现成的图片,可以这样处理:7、选择该图片,右键-打开方式-windows图片和传真查看器;8、打印,一路回车,一直到出现打印机选项;9、在出现的打印对话框中,选择打印机类型为“Mic rosoft Office Document image writer”,选择适当路径存放;10、双击被保存的文件;11、重复第5~6点;图片文字提取方法集锦阅读(53) 评论(0) 发表时间:2008年09月17日 10:05本文地址:/blog/332664981-1221617149方法一:利用Office 2003从图片中提取文字Office在2003版中增加了Document Imaging工具,用它可以把文字给“抠”出来。
(1)打开传真图片,用抓图软件SnagIt对相关的内容进行抓取,然后在“文件”菜单中选择“复制到剪贴板”命令(也可以用其他抓图软件,当然最简单的是Windows中自带的Print Screen键来抓取整个屏幕,然后在“画图”程序中对不要的部分进行裁剪并保存,然后复制)。
使用Office 2003自带的OCR程序进行文字识别

使用Office 2003自带的OCR程序进行文字识别用途:我们经常从期刊网下载的PDF文件或CAJ文件的文本都是不能直接复制出来的,遇到这种情况,我们可以使用Office 2003所自带的OCR程序进行识别。
操作步骤:1. 用CAJViewer打开准备要进行文字识别的文件,按“文件→打印”按钮打开打印选项对话框。
2. 在“打印”对话框中,首先在“名称”选择栏中必须选中“Microsoft Office Document Image2选择打印的范围3. 然后按确定选择保存的位置,保存在那里都不要紧,因为打印生成的文件只是一个暂时使用的文件,我们在使用完后可以把他删除了。
4. 打印成功后,系统会自动打开“Microsoft Office Document Imaging”软件打开刚才打印成功的文件。
5. “Microsoft Office Document Imaging”打开后,选择工具栏中的眼睛图标进行文字识别。
6. 等待识别完成后,在文档区拉动鼠标选择需要复制的文字,当文字出现亮蓝显示时,证明文字是可以复制出来的,然后按键盘的ctrl+c,或者按鼠标右键复制都可以把文字复制出来。
附如果你在第二步操作选择打印机时没有看到“Microsoft Office Document Image Writer”出现,表明你还没有按照Office 2003中的这个工具,我们可以按照以下的步骤安装。
1. 打开“控制面板”——“添加删除程序”。
2. 在“添加删除程序”列表框中选中Office 2003安装项目,选中它,然后点击“更改”按钮。
3. 在新打开的“Office 2003”安装对话框中,选择“添加删除功能”,然后按下一步。
4. 然后必须选择“选择应用程序的高级自定义”选项,再点击下一步按钮。
5. 拖动新开窗口的右侧滚动条,打开“office 工具”子菜单,选择“Microsoft Office Document Imaging”工具,然后点击鼠标左键,在弹出的选项框中选择“从本机运行”,然后按“更新”按钮。
(完整版)如何把纸质文件通过扫描转化成word文档巧用office2003实现...
巧用Office 2003实现OCR文字输入为了迎接市里的工作验收,领导拿来了许多存档文件,要求小王在三天内摘录并形成汇报文档。
看着厚厚的材料小王发愁了,这时有人提醒:你的笔记本电脑不是刚装上Office2003吗,里面的Microsoft Office Document Imaging不错。
它是一个光学字符识别(OCR)软件,可以用扫描仪扫入纸文档中的汉字,用它,摘录文件的速度可快多了。
○ 操作准备局里只有一台比较旧的F1210扫描仪,小王把它连接到笔记本电脑的并口,接通电源以后安装扫描仪驱动程序。
单击“开始”-->“所有程序”-->“Microsoft Office工具”中的“Microsoft Office Document Imaging”,将纸文档放入扫描仪,准备将其中的汉字输入Word。
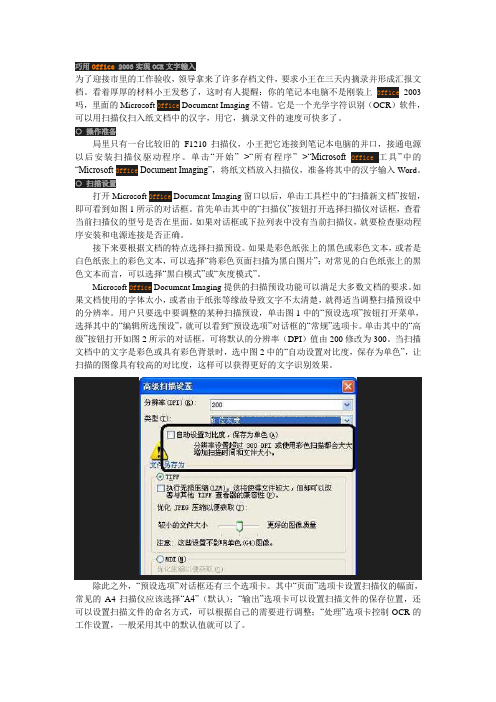
○ 扫描设置打开Microsoft Office Document Imaging窗口以后,单击工具栏中的“扫描新文档”按钮,即可看到如图1所示的对话框。
首先单击其中的“扫描仪”按钮打开选择扫描仪对话框,查看当前扫描仪的型号是否在里面。
如果对话框或下拉列表中没有当前扫描仪,就要检查驱动程序安装和电源连接是否正确。
接下来要根据文档的特点选择扫描预设。
如果是彩色纸张上的黑色或彩色文本,或者是白色纸张上的彩色文本,可以选择“将彩色页面扫描为黑白图片”;对常见的白色纸张上的黑色文本而言,可以选择“黑白模式”或“灰度模式”。
Microsoft Office Document Imaging提供的扫描预设功能可以满足大多数文档的要求。
如果文档使用的字体太小,或者由于纸张等缘故导致文字不太清楚,就得适当调整扫描预设中的分辨率。
用户只要选中要调整的某种扫描预设,单击图1中的“预设选项”按钮打开菜单,选择其中的“编辑所选预设”,就可以看到“预设选项”对话框的“常规”选项卡。
单击其中的“高级”按钮打开如图2所示的对话框,可将默认的分辨率(DPI)值由200修改为300。
Office软件的OCR文字识别

Office软件的OCR文字识别OCR(Optical Character Recognition)文字识别技术是一种通过计算机识别和理解图像中的文字信息的技术。
在Office软件中,OCR文字识别技术能够帮助用户将扫描或拍摄的图片文件中的文字内容转换成可编辑的文本文件,极大方便了用户对文字信息的处理和管理。
本文将从OCR文字识别的基本原理、Office软件中的应用、优缺点及未来发展方向等方面进行详细探讨,以便读者对该项技术有进一步的了解。
一、OCR文字识别的基本原理OCR文字识别的基本原理是通过对图像进行预处理,提取出图像中的文字信息,然后利用字符识别技术将提取出的文字信息转换成可编辑的文本文件。
其主要步骤包括图像预处理、文字分割和字符识别三个过程。
在图像预处理环节,需要对图像进行灰度化、二值化、去噪等操作,以便提高后续文字信息的识别效果。
文字分割环节即将提取出的文字进行切割,以便字符识别技术对每个文字进行识别。
最后是字符识别环节,利用模式识别和机器学习等算法对提取出的文字进行识别并转换成文本文件。
二、Office软件中的OCR文字识别应用在Office软件中,OCR文字识别技术主要应用于扫描仪和拍照文档的文字转换。
用户可以通过OCR文字识别功能将扫描或拍摄的图片文件中的文字内容直接转换成可编辑的文本文件,并进行编辑、修改或者复制粘贴等操作。
这一功能在处理扫描版合同、拍摄版书籍、图片版文件等方面具有很大的实用价值,也方便了用户对文字信息的管理和利用。
三、OCR文字识别的优缺点优点:1.方便用户处理图片文件中的文字信息,提高工作效率。
2.能够将图片文件中的文字信息转换为可编辑的文本文件,方便进行编辑和管理。
3.对于扫描版合同、拍摄版书籍等具有重要实用价值的文件起到了极大的便利作用。
缺点:1.对于复杂的图像和文字特征不明显的文档,识别效果可能不佳。
2.非结构化的文档识别困难,需要人工干预进行修正。
OFFICE2003里面有自带OCR软件

OFFICE2003里面有自带OCR软件各种格式文件ocr成word文件的方法你还在为不同格式的文件怎么变成word文件发愁吗?各种识别软件各有缺陷,识别效率低,让你痛苦不堪,有的只能识别字,对表格和图形无能为力,识别完了,版面乱七八糟,无法使用。
现在好了,本文针对各种情况下文字识别进行总结,帮助大家掌握正确方法,节省时间,本文给出了所有情况下全文件表格、图形、文字识别的完美解决方案:1、PDF文件的识别:1)文件可以直接识别的(以文本形式保存的PDF文件):安装acrobat 7专业版,注意不是acrobat reader(下载/soft/4/136/2006/Soft_29430.html),直接另存为rtf 文件(识别整个文件),或者选择工具栏上的文字选择按钮,然后选择文字区域,然后复制到word等中。
2)文件不能直接识别的(以图片形式保存的PDF文件):安装office2003(下载/soft/188/215/2006/Soft_28356.html),并装上office工具Microsoft Office Document Imaging(完全安装此工具),然后在打印机里面会增加Microsoft Office Document Image Writer打印机,然后将PDF 文件打印到此打印机,选择打印形成的文件的保存位置,然后会自动形成一个MDI文件,并且自动用Microsoft Office Document Image打开此文件,然后选择“工具”菜单下的“使用ocr识别文本”,识别完成后,在选择“工具”下的,“将文本发送到word”,最后将把整个PDF文件识别输出到word文件中。
注意:Microsoft Office Document Image可以非常准确的全文件识别转化中文、英文、表格,但是无法将图形输出到word,而是把文件中的所有图形单独形成一个个独立的图片文件,放在相同位置的一个相同名称的文件夹中,因此可用snagit 软件将图形打开,然后复制到word中。
办公软件中的OCR文字识别软件怎样操作

现在的办公软件是越来越智能化了,在工作中使用办公软件的次数也是越来越多了。
就像前几天小编的室友给推荐了一个OCR文字识别软件,功能很齐全的软件,具体是怎样操作的?一起小编看一下吧!
接下来小编给大家介绍的是迅捷OCR文字识别软件中的语音转文字的操作,该工具的功能有很多,比如说图片转文字,文档翻译等。
步骤一:首先将我们提前准备好的语音文件上传到电脑上,然后再将电脑上的OCR文字识别工具给打开就可以了。
步骤二:打开OCR文字识别软件后,就可以看到桌面上弹出该工具的功能
页面了。
在多种功能中需要点击一下“语音识别”功能。
步骤三:在语音识别的功能页面中,需要添加一下语音文件,点击一下“上传音频文件”就可以将我们需要的音频文件给添加进去了。
步骤四:上传完音频文件后,在导出目录中,为识别出的文字文件调整一下存储的位置。
如桌面。
步骤五:调整完文字文件的存储位置之后,只需要点击一下“开始识别”,该功能就可以进行语音识别了。
以上简单的几步就是OCR文字识别软件中的语音转文字的操作了,大家学会了吗?有需要的小伙伴记得学学哦!。
文字识别,Office2003足矣

曼 只 . : … ~ ~E 旦:Ⅱ 1yt宴 嚣! ? 。 ~ 三Ⅲ曼 I 9e.c 一) _
B e
 ̄ n o s c iP . . idwMda1.
矗 =  ̄ E M l y r O X 7 , ) E B D(w P a e . C .
质 文件 , 须要 用扫 描仪 ( 数 码相 机 ) 形成 B 必 或 先 MP
位图文件。 第二步的准备工作就是用Widw 自带的 nos
画图程 序 打开待处 理 的图片文件 , 按 Cr A 先 t + 组合 键 l
全选 , Cr C 再 t+ 组合键 复制 , l 待用。
2 单 击打 开 “ . 开始 ” “ 有 程序 ” “ coot 一 所 一 Mi sf r
0 i ” “ eoo fc工 具” “ coo f c fc 一 Mi sf O f e e r l i 一 Mi sf 0 i r l e
4 电脑知识与技术 0
三 三 五 三量匹 一
目编辑
张薇 s f r@C C e n o t e C Cn t wa c
一
l
。 叠整
麓裁璎 整{ 霉
圆
耀
曩
一
景宏 刮
一 ~ 一
v。 ;
翅蝴 捃 l 宏cM磊 滠 曦 o ; 煳
安安垒悭
代瓣
通 ,
Hale Waihona Puke l … ’ … 一 ~
: _— 圈蝗 椎 g t 壶(} 插 童 。 ( 用 慧澜 8 。 加 璎 入 馘囊 戴 或 看幅
方 左 择“ ” 可 ( 图 )潮 , 键选 剪切 即 。 如 5
后 就会显示 出一个/Widw daPae播放器 窗 J n o sMei lyr  ̄ 口, 键单 击插 入 的Widw daPae播放 器窗 右 n o sMei l r y 口, 左键选 择 “ l , “ l 对 话框 中单击 “ 属 生” 在 属 生” 自定 义” 然后 接着单 击其 后边 那 个 带三个 点的 按 钮 , , 在 打开 的 “ n o sMei Pae属性 ” 口中单击 “ Widw da l r y 窗 浏 览”按 钮 找 到 并 打 开准 备 作 为 背 景 音 乐 的文件 , 点 “ 确定” 出并关 闭 “ 性” 话框 , 后单击 “ 退 屙 对 最 开发 工具” 选项卡下的 “ 计模 式” 钮 , 设 按 就可以播放音乐 了。 这样 保存 文档后 下次再打开该 文 档时就会 自动播
【VIP专享】扫描转化成word文档巧用Office2003实现OCR文字输入

Office在2003版中增加了Document Imaging工具,用它可以把文字给“抠”出来。
打开传真图片,用抓图软件SnagIt对相关的内容进行抓取,然后在“文件”菜单中选择“复制到剪贴板”命令(也可以用其他抓图软件,当然最简单的是Windows中自带的Print Screen键来抓取整个屏幕,然后在“画图”程序中对不要的部分进行裁剪并保存,然后复制)。
在“开始”菜单的“Microsoft Office工具”中打开Microsoft Office Document Imaging,在左侧窗口中单击鼠标右键,选择“粘贴页面”,把复制的图片粘贴---到Document Imaging中,在“工具”中选择“使用OCR识别文本”,Document Imaging的OCR识别程序就会对图片进行识别,完成后选择“工具”中的“将文本发送到Word”,程序会自动打开Word文档,展现在你面前的就是从图片中“抠”出来的文字。
提示:一般而言,识别的准确率可以达到95%以上,但对英文和数字的识别不是太好。
还有其他软件:一、汉王感觉比紫光好,可以识别表格,新版汉王5800,还没有装。
二、清华紫光以前7.5用过很多次,基本还可以,文科类书籍识别还不错,新版紫光9.0,应该有提高。
三、慧视小灵鼠号称很厉害,用手机拍得都行。
四、尚书有表格识别,大概很中庸,用的人不多。
五、丹青能识别繁体六、cajviewer 6.0不是专用识别软件,内部应该是汉王的核心。
七、Microsoft Office Document Imagingoffice2003中内含,2003装过一次,发现access到入数据不顺,就改回用2000,还没有注意到,不知道对公式识别是否有相当的作用,想想和word结合比较强,这是应该的。
八、FineReader v7.0 Professional据说很牛的英文识别软件,是俄国人搞的,天空软件有下,汉字也有,只是没有地方下到。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用Office 2003自带的OCR程序进行文字识别
用途:我们经常从期刊网下载的PDF文件或CAJ文件的文本都是不能直接复制出来的,遇到这种情况,我们可以使用Office 2003所自带的OCR程序进行识别。
操作步骤:
1. 用CAJViewer打开准备要进行文字识别的文件,按“文件→打印”按钮打开打印选项对话框。
2. 在“打印”对话框中,首先在“名称”选择栏中必须选中“Microsoft Office Document Image
2选择打印的范围
3. 然后按确定选择保存的位置,保存在那里都不要紧,因为打印生成的文件只是一个暂时使用的文件,我们在使用完后可以把他删除了。
4. 打印成功后,系统会自动打开“Microsoft Office Document Imaging”软件打开刚才打印成功的文件。
5. “Microsoft Office Document Imaging”打开后,选择工具栏中的眼睛图标进行文字识别。
6. 等待识别完成后,在文档区拉动鼠标选择需要复制的文字,当文字出现亮蓝显示时,证明文字是可以复制出来的,然后按键盘的ctrl+c,或者按鼠标右键复制都可以把文字复制出来。
附
如果你在第二步操作选择打印机时没有看到“Microsoft Office Document Image Writer”出现,表明你还没有按照Office 2003中的这个工具,我们可以按照以下的步骤安装。
1. 打开“控制面板”——“添加删除程序”。
2. 在“添加删除程序”列表框中选中Office 2003安装项目,选中它,然后点击“更改”按钮。
3. 在新打开的“Office 2003”安装对话框中,选择“添加删除功能”,然后按下一步。
4. 然后必须选择“选择应用程序的高级自定义”选项,再点击下一步按钮。
5. 拖动新开窗口的右侧滚动条,打开“office 工具”子菜单,选择“Microsoft Office Document Imaging”工具,然后点击鼠标左键,在弹出的选项框中选择“从本机运行”,然后按“更新”按钮。
6. 然后插入Office 2003安装光盘进行安装。