java中的缓存
Java中的分布式缓存框架有哪些

Java中的分布式缓存框架有哪些随着互联网应用的快速发展,分布式缓存已经成为了提高系统性能和扩展性的关键技术之一。
在Java开发领域,也涌现了许多优秀的分布式缓存框架。
本文将介绍几个Java中常用的分布式缓存框架,并分析它们的特点和适用场景。
一、EhcacheEhcache是一个开源的Java缓存框架,被广泛应用于各种Java应用中。
它提供了基于内存和磁盘的缓存机制,支持分布式部署,能够满足大规模应用的缓存需求。
Ehcache具有轻量级、易于使用和快速的特点,适合用于小型和中型的应用系统。
二、RedisRedis是一种高性能的内存数据存储系统,支持多种数据结构,可以用作分布式缓存的解决方案。
Redis提供了持久化和复制机制,可以实现高可用性和数据持久化。
同时,Redis还具有丰富的功能,如发布订阅、事务管理等,使得它不仅可以作为缓存系统,还可以用于其他用途,如消息队列等。
Redis适用于各种规模的应用系统。
三、MemcachedMemcached是一个简单的高性能分布式内存对象缓存系统。
它使用键值对的方式存储数据,提供了多种API,支持分布式部署。
Memcached具有高速的读写性能和可扩展性,通常被用于缓存数据库查询结果、页面内容等。
它适用于大规模应用和高并发场景,但需要注意的是,Memcached不提供数据持久化功能。
四、HazelcastHazelcast是一个基于Java的开源分布式缓存框架,它提供了分布式数据结构和集群管理功能。
Hazelcast采用了集中式架构,能够实现多节点之间的数据共享和同步。
它具有简单易用的特点,并提供了多种数据结构和并发算法的支持。
Hazelcast适用于构建复杂的分布式应用系统。
五、CaffeineCaffeine是一个在Java中最受欢迎的缓存库之一,它提供了高性能、无锁的内存缓存解决方案。
Caffeine采用了分片策略来管理缓存对象,提供了各种缓存策略和配置选项,可以根据实际需求进行灵活配置。
如何清除java缓存
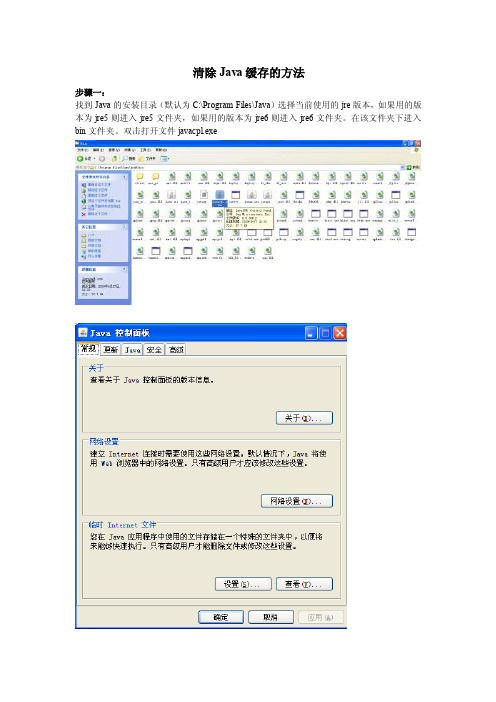
清除Java缓存的方法步骤一:找到Java的安装目录(默认为C:\Program Files\Java)选择当前使用的jre版本,如果用的版本为jre5则进入jre5文件夹,如果用的版本为jre6则进入jre6文件夹。
在该文件夹下进入bin文件夹。
双击打开文件javacpl.exe步骤二:在常规选项中的临时Internet文件点击“设置”按钮再点击“删除文件”按钮,删除所有的临时文件。
步骤三:删除完缓存之后,需要关闭所有浏览器。
再次打开浏览器进入虚拟实验系统即可。
文案编辑词条B 添加义项?文案,原指放书的桌子,后来指在桌子上写字的人。
现在指的是公司或企业中从事文字工作的职位,就是以文字来表现已经制定的创意策略。
文案它不同于设计师用画面或其他手段的表现手法,它是一个与广告创意先后相继的表现的过程、发展的过程、深化的过程,多存在于广告公司,企业宣传,新闻策划等。
基本信息中文名称文案外文名称Copy目录1发展历程2主要工作3分类构成4基本要求5工作范围6文案写法7实际应用折叠编辑本段发展历程汉字"文案"(wén àn)是指古代官衙中掌管档案、负责起草文书的幕友,亦指官署中的公文、书信等;在现代,文案的称呼主要用在商业领域,其意义与中国古代所说的文案是有区别的。
在中国古代,文案亦作" 文按"。
公文案卷。
《北堂书钞》卷六八引《汉杂事》:"先是公府掾多不视事,但以文案为务。
"《晋书·桓温传》:"机务不可停废,常行文按宜为限日。
" 唐戴叔伦《答崔载华》诗:"文案日成堆,愁眉拽不开。
"《资治通鉴·晋孝武帝太元十四年》:"诸曹皆得良吏以掌文按。
"《花月痕》第五一回:" 荷生觉得自己是替他掌文案。
"旧时衙门里草拟文牍、掌管档案的幕僚,其地位比一般属吏高。
Java本地缓存工具之LoadingCache的使用详解

Java本地缓存⼯具之LoadingCache的使⽤详解⽬录前⾔环境依赖代码演⽰⼀下总结前⾔在⼯作总常常需要⽤到缓存,⽽redis往往是⾸选,但是短期的数据缓存⼀般我们还是会⽤到本地缓存。
本⽂提供⼀个我在⼯作中⽤到的缓存⼯具,该⼯具代码为了演⽰做了⼀些调整。
如果拿去使⽤的话,可以考虑做成注⼊Bean对象,看具体需求了。
环境依赖先添加maven依赖<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30.1.1-jre</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.5.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency>代码不废话,上代码了。
package ai.guiji.csdn.tools;import cn.hutool.core.thread.ThreadUtil;import mon.cache.*;import lombok.extern.slf4j.Slf4j;import java.text.MessageFormat;import java.util.Map;import java.util.concurrent.TimeUnit;import java.util.function.Consumer;import java.util.function.Function;import java.util.stream.LongStream;/** @Author 剑客阿良_ALiang @Date 2021/12/30 17:57 @Description: 缓存⼯具 */@Slf4jpublic class CacheUtils {private static LoadingCache<Long, String> cache;/*** 初始化缓存⽅法** @param totleCount 缓存池上限* @param overtime 超时时间* @param unit 时间单位* @param handleNotExist 处理不存在key⽅法* @param handleRemove 移除主键消费*/private static void initCache(Integer totleCount,Integer overtime,TimeUnit unit,Function<Long, String> handleNotExist,Consumer<Long> handleRemove) {cache =CacheBuilder.newBuilder()// 缓存池⼤⼩.maximumSize(totleCount)// 设置时间对象没有被读/写访问则对象从内存中删除.expireAfterWrite(overtime, unit)// 移除监听器.removalListener(new RemovalListener<Long, String>() {@Overridepublic void onRemoval(RemovalNotification<Long, String> rn) { handleRemove.accept(rn.getKey());}}).recordStats().build(new CacheLoader<Long, String>() {@Overridepublic String load(Long aLong) throws Exception {return handleNotExist.apply(aLong);}});("初始化缓存");}/*** 存⼊缓存** @param key 键* @param value 值*/public static void put(Long key, String value) {try {("缓存存⼊:[{}]-[{}]", key, value);cache.put(key, value);} catch (Exception exception) {log.error("存⼊缓存异常", exception);}}/*** 批量存⼊缓存** @param map 映射*/public static void putMap(Map<Long, String> map) {try {("批量缓存存⼊:[{}]", map);cache.putAll(map);} catch (Exception exception) {log.error("批量存⼊缓存异常", exception);}}/*** 获取缓存** @param key 键*/public static String get(Long key) {try {return cache.get(key);} catch (Exception exception) {log.error("获取缓存异常", exception);return null;}}/*** 删除缓存** @param key 键*/public static void removeKey(Long key) {try {cache.invalidate(key);} catch (Exception exception) {log.error("删除缓存异常", exception);}}/*** 批量删除缓存** @param keys 键*/public static void removeAll(Iterable<Long> keys) {try {cache.invalidateAll(keys);} catch (Exception exception) {log.error("批量删除缓存异常", exception);}}/** 清理缓存 */public static void clear() {try {cache.invalidateAll();} catch (Exception exception) {log.error("清理缓存异常", exception);}}/*** 获取缓存⼤⼩** @return 长度*/public static long size() {return cache.size();}public static void main(String[] args) {initCache(Integer.MAX_VALUE,10,TimeUnit.SECONDS,k -> {("缓存:[{}],不存在", k);return "";},x -> ("缓存:[{}],已经移除", x));System.out.println(size());LongStream.range(0, 10).forEach(a -> put(a, MessageFormat.format("tt-{0}", a)));System.out.println(cache.asMap());ThreadUtil.sleep(5000);LongStream.range(0, 10).forEach(a -> {System.out.println(get(a));ThreadUtil.sleep(1000);});System.out.println(cache.asMap());ThreadUtil.sleep(10000);System.out.println(cache.asMap());}}代码说明1、在初始化loadingCache的时候,可以添加缓存的最⼤数量、消逝时间、消逝或者移除监听事件、不存在键处理等等。
Java中的缓存技术

Java中的缓存技术缓存技术在软件开发中起着至关重要的作用。
它可以提高系统性能、降低对底层资源的访问频率,从而减轻服务器负载并改善用户体验。
在Java开发中,有许多可供选择的缓存技术。
本文将介绍几种常见的Java缓存技术,以及它们的应用场景和原理。
一、内存缓存内存缓存是最常见的缓存技术之一,它将数据保存在内存中,以提高读取速度。
在Java中,可以使用集合框架中的Map接口的实现类来实现内存缓存,如HashMap、ConcurrentHashMap等。
这些类提供了快速的Key-Value存储,通过Key快速查找对应的Value,以实现快速访问缓存数据。
内存缓存适用于数据读取频繁但不经常更新的场景,例如字典数据、配置信息等。
需要注意的是,内存缓存的容量是有限的,当缓存数据超过容量限制时,需要采取一些策略来处理,如LRU(最近最少使用)算法将最久未访问的数据移出缓存。
二、分布式缓存分布式缓存是一种将数据存储在多台服务器节点上的缓存技术。
Java中有多种分布式缓存框架可供选择,如Redis、Memcached等。
这些框架提供了高性能、可扩展的分布式缓存服务,可以在集群中存储大量的数据,并提供分布式缓存的管理和查询接口。
分布式缓存适用于需要同时服务大量客户端并具有高并发读写需求的场景,例如电商网站的商品信息、社交网络的用户数据等。
通过将数据存储在多台服务器上,可以提高系统的可用性和扩展性。
三、页面缓存页面缓存是将网页内容保存在缓存中,以减少对数据库或后端服务的访问频率,从而提高页面的加载速度。
在Java中,可以通过使用Web服务器或反向代理服务器的缓存功能,例如Nginx、Varnish等,来实现页面缓存。
页面缓存适用于内容相对静态或者不经常变化的场景,例如新闻网站的文章、博客网站的页面等。
通过将网页内容保存在缓存中,可以避免每次请求都重新生成页面,大大提高响应速度和系统的并发能力。
四、数据库缓存数据库缓存是将数据库查询结果保存在缓存中,以减少对数据库的频繁查询,提高系统的响应速度和并发能力。
Java中常用缓存Cache机制的实现

Java中常用缓存Cache机制的实现Java 中常用缓存Cache机制的实现所谓缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例。
这样做可以减少系统开销,提高系统效率。
Java 中常用缓存Cache机制的实现缓存主要可分为二大类:一、通过文件缓存,顾名思义文件缓存是指把数据存储在磁盘上,不管你是以XML格式,序列化文件DAT格式还是其它文件格式;二、内存缓存,也就是实现一个类中静态Map,对这个Map进行常规的增删查.代码如下:1. packagelhm.hcy.guge.frameset.cache;2.3. importjava.util.*;4.5. //Description:管理缓存6.7. //可扩展的功能:当chche到内存溢出时必须清除掉最早期的一些缓存对象,这就要求对每个缓存对象保存创建时间8.9. publicclassCacheManager{10. privatestaticHashMapcacheMap=newHashMap();11.12. //单实例构造方法13. privateCacheManager(){14. super();15. }16. //获取布尔值的.缓存17. publicstaticbooleangetSimpleFlag(Stringkey){18. try{19. return(Boolean)cacheMap.get(key);20. }catch(NullPointerExceptione){21. returnfalse;22. }23. }24. publicstaticlonggetServerStartdt(Stringkey){25. try{26. return(Long)cacheMap.get(key);27. }catch(Exceptionex){28. return0;29. }30. }31. //设置布尔值的缓存32. publicsynchronizedstaticbooleansetSimpleFlag(Stringkey,boolea nflag){33. if(flag&&getSimpleFlag(key)){//假如为真不允许被覆盖34. returnfalse;35. }else{36. cacheMap.put(key,flag);37. returntrue;38. }39. }40. publicsynchronizedstaticbooleansetSimpleFlag(Stringkey,longse rverbegrundt){41. if(cacheMap.get(key)==null){42. cacheMap.put(key,serverbegrundt);43. returntrue;44. }else{45. returnfalse;46. }47. }48.49.50. //得到缓存。
Java缓存机制

在软件开发中,缓存是一种常用的优化技术,用于存储频繁访问的数据,使得下一次访问时可以更快地获取数据。
而在Java中,也存在着各种不同的缓存机制,用于提升程序的性能与效率。
一、内存缓存内存缓存是最常见的缓存机制之一。
在Java中,可以使用各种数据结构来实现内存缓存,比如Hashtable、HashMap、ConcurrentHashMap等。
使用内存缓存的好处是可以将数据存储在内存中,而不是频繁地访问数据库或者其他外部存储介质,从而提升访问速度。
同时,内存缓存还可以减轻数据库的负载,提高系统的并发能力。
二、CPU缓存CPU缓存是指CPU内部的高速缓存,用于暂时存储处理器频繁访问的数据。
在Java中,可以通过使用局部变量和静态变量来利用CPU缓存。
局部变量存储在方法栈帧中,相对于对象的实例变量来说,访问局部变量的速度更快。
因此,在开发过程中,应该尽量使用局部变量来存储频繁访问的数据。
静态变量是存储在方法区中的,与对象的实例无关。
由于静态变量只有一个副本,所以可以减少对CPU缓存的竞争,提高程序的性能。
三、磁盘缓存磁盘缓存是将数据存储在磁盘中,并使用相应的缓存算法来提高数据的读写速度。
在Java中,可以通过使用文件缓存或者数据库缓存来实现磁盘缓存。
文件缓存是将数据存储在本地文件系统中,比如将一些配置文件加载到内存中进行处理。
数据库缓存是将数据存储在数据库中,并使用缓存算法来提高数据的访问速度。
一般情况下,数据库缓存会使用LRU(最近最少使用)算法来决定何时移除某个数据。
四、网络缓存网络缓存是将数据存储在网络中,通过网络进行传输。
在Java中,可以通过使用HTTP缓存或者CDN来实现网络缓存。
HTTP缓存是浏览器和服务器之间的缓存,用于存储HTTP请求和响应的数据。
通过合理设定HTTP头信息,可以实现数据的缓存,减少带宽的消耗。
CDN(内容分发网络)是一种将数据分布到全球多台服务器的网络架构,用于存储静态文件,提供更快的数据访问速度。
java cache用法

java cache用法Java中的缓存是一种常用的数据结构,用于提高应用程序的性能和响应速度。
Java提供了多种缓存实现,如JavaCache、Ehcache、GuavaCache等,这些缓存可以存储数据并在需要时快速检索。
本篇文章将介绍JavaCache的使用方法。
JavaCache是一个简单的缓存实现,它提供了一个易于使用的API,可以方便地添加、获取和移除缓存数据。
JavaCache的设计目标是易于使用、高性能和可扩展性。
它支持通过多个存储引擎来扩展缓存,每个存储引擎都具有不同的性能特点。
1.添加缓存数据使用JavaCache添加缓存数据非常简单。
首先,需要创建一个Cache对象,并指定存储引擎的类型和名称。
然后,可以使用put方法将数据添加到缓存中。
例如:```javaCachecache=newCache("myCache",100);//创建一个缓存对象,存储引擎类型为Memory,容量为100个字节cache.put("key","value");//将数据添加到缓存中```2.获取缓存数据使用JavaCache获取缓存数据也非常简单。
可以使用get方法从缓存中获取数据。
如果数据不存在于缓存中,则返回null。
例如:```javaStringvalue=cache.get("key");//从缓存中获取数据```3.移除缓存数据使用JavaCache移除缓存数据也非常简单。
可以使用remove方法从缓存中移除指定的数据。
例如:```javacache.remove("key");//从缓存中移除数据```4.配置存储引擎和缓存容量JavaCache支持多个存储引擎,每个存储引擎具有不同的性能特点。
可以通过配置存储引擎的类型和名称来扩展缓存。
此外,还可以配置缓存的容量,以确保缓存不会因为存储空间不足而出现性能问题。
Java基于LoadingCache实现本地缓存的示例代码

Java基于LoadingCache实现本地缓存的⽰例代码⽬录⼀、添加 maven 依赖⼆、CacheBuilder ⽅法说明三、创建 CacheLoader四、⼯具类五、guava Cache数据移除⼀、添加 maven 依赖<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>27.1-jre</version></dependency>⼆、CacheBuilder ⽅法说明1 LoadingCache build(CacheLoader loader)2 CacheBuilder.maximumSize(long size)配置缓存数量上限,快达到上限或达到上限,处理了时间最长没被访问过的对象或者根据配置的被释放的对象3 expireAfterAccess(long, TimeUnit)缓存项在给定时间内没有被读/写访问,则回收。
请注意这种缓存的回收顺序和基于⼤⼩回收⼀样4 expireAfterWrite(long, TimeUnit)缓存项在给定时间内没有被写访问(创建或覆盖),则回收。
如果认为缓存数据总是在固定时候后变得陈旧不可⽤,这种回收⽅式是可取的。
5 refreshAfterWrite(long duration, TimeUnit unit)定时刷新,可以为缓存增加⾃动定时刷新功能。
和expireAfterWrite相反,refreshAfterWrite通过定时刷新可以让缓存项保持可⽤,但请注意:缓存项只有在被检索时才会真正刷新,即只有刷新间隔时间到了再去get(key)才会重新去执⾏Loading,否则就算刷新间隔时间到了也不会执⾏loading操作。
因此,如果在缓存上同时声明expireAfterWrite和refreshAfterWrite,缓存并不会因为刷新盲⽬地定时重置,如果缓存项没有被检索,那刷新就不会真的发⽣,缓存项在过期时间后也变得可以回收。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
JA V A缓存1.Hibernate的缓存机制介绍缓存是介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了应用的运行性能。
缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
缓存的介质一般是内存,所以读写速度很快。
但如果缓存中存放的数据量非常大时,也会用硬盘作为缓存介质。
缓存的实现不仅仅要考虑存储的介质,还要考虑到管理缓存的并发访问和缓存数据的生命周期。
Hibernate的缓存包括Session的缓存和SessionFactory的缓存,其中SessionFactory的缓存又可以分为两类:内置缓存和外置缓存。
Session的缓存是内置的,不能被卸载,也被称为Hibernate的第一级缓存。
SessionFactory的内置缓存和Session的缓存在实现方式上比较相似,前者是SessionFactory对象的一些集合属性包含的数据,后者是指Session的一些集合属性包含的数据。
SessionFactory的内置缓存中存放了映射元数据和预定义SQL语句,映射元数据是映射文件中数据的拷贝,而预定义SQL语句是在Hibernate初始化阶段根据映射元数据推导出来,SessionFactory的内置缓存是只读的,应用程序不能修改缓存中的映射元数据和预定义SQL语句,因此SessionFactory不需要进行内置缓存与映射文件的同步。
SessionFactory的外置缓存是一个可配置的插件。
在默认情况下,SessionFactory不会启用这个插件。
外置缓存的数据是数据库数据的拷贝,外置缓存的介质可以是内存或者硬盘。
SessionFactory的外置缓存也被称为Hibernate的第二级缓存。
Hibernate的这两级缓存都位于持久化层,存放的都是数据库数据的拷贝,那么它们之间的区别是什么呢?为了理解二者的区别,需要深入理解持久化层的缓存的两个特性:缓存的范围和缓存的并发访问策略。
持久化层的缓存的范围缓存的范围决定了缓存的生命周期以及可以被谁访问。
缓存的范围分为三类。
1 事务范围:缓存只能被当前事务访问。
缓存的生命周期依赖于事务的生命周期,当事务结束时,缓存也就结束生命周期。
在此范围下,缓存的介质是内存。
事务可以是数据库事务或者应用事务,每个事务都有独自的缓存,缓存内的数据通常采用相互关联的的对象形式。
2 进程范围:缓存被进程内的所有事务共享。
这些事务有可能是并发访问缓存,因此必须对缓存采取必要的事务隔离机制。
缓存的生命周期依赖于进程的生命周期,进程结束时,缓存也就结束了生命周期。
进程范围的缓存可能会存放大量的数据,所以存放的介质可以是内存或硬盘。
缓存内的数据既可以是相互关联的对象形式也可以是对象的松散数据形式。
松散的对象数据形式有点类似于对象的序列化数据,但是对象分解为松散的算法比对象序列化的算法要求更快。
3 集群范围:在集群环境中,缓存被一个机器或者多个机器的进程共享。
缓存中的数据被复制到集群环境中的每个进程节点,进程间通过远程通信来保证缓存中的数据的一致性,缓存中的数据通常采用对象的松散数据形式。
对大多数应用来说,应该慎重地考虑是否需要使用集群范围的缓存,因为访问的速度不一定会比直接访问数据库数据的速度快多少。
持久化层可以提供多种范围的缓存。
如果在事务范围的缓存中没有查到相应的数据,还可以到进程范围或集群范围的缓存内查询,如果还是没有查到,那么只有到数据库中查询。
事务范围的缓存是持久化层的第一级缓存,通常它是必需的;进程范围或集群范围的缓存是持久化层的第二级缓存,通常是可选的。
持久化层的缓存的并发访问策略当多个并发的事务同时访问持久化层的缓存的相同数据时,会引起并发问题,必须采用必要的事务隔离措施。
在进程范围或集群范围的缓存,即第二级缓存,会出现并发问题。
因此可以设定以下四种类型的并发访问策略,每一种策略对应一种事务隔离级别。
事务型:仅仅在受管理环境中适用。
它提供了Repeatable Read事务隔离级别。
对于经常被读但很少修改的数据,可以采用这种隔离类型,因为它可以防止脏读和不可重复读这类的并发问题。
读写型:提供了Read Committed事务隔离级别。
仅仅在非集群的环境中适用。
对于经常被读但很少修改的数据,可以采用这种隔离类型,因为它可以防止脏读这类的并发问题。
非严格读写型:不保证缓存与数据库中数据的一致性。
如果存在两个事务同时访问缓存中相同数据的可能,必须为该数据配置一个很短的数据过期时间,从而尽量避免脏读。
对于极少被修改,并且允许偶尔脏读的数据,可以采用这种并发访问策略。
只读型:对于从来不会修改的数据,如参考数据,可以使用这种并发访问策略。
事务型并发访问策略是事务隔离级别最高,只读型的隔离级别最低。
事务隔离级别越高,并发性能就越低。
什么样的数据适合存放到第二级缓存中?1、很少被修改的数据2、不是很重要的数据,允许出现偶尔并发的数据3、不会被并发访问的数据4、参考数据不适合存放到第二级缓存的数据?1、经常被修改的数据2、财务数据,绝对不允许出现并发3、与其他应用共享的数据。
Hibernate的二级缓存如前所述,Hibernate提供了两级缓存,第一级是Session的缓存。
由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。
第一级缓存是必需的,不允许而且事实上也无法比卸除。
在第一级缓存中,持久化类的每个实例都具有唯一的OID。
第二级缓存是一个可插拔的的缓存插件,它是由SessionFactory负责管理。
由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此第二级缓存是进程范围或者集群范围的缓存。
这个缓存中存放的对象的松散数据。
第二级对象有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。
缓存适配器用于把具体的缓存实现软件与Hibernate集成。
第二级缓存是可选的,可以在每个类或每个集合的粒度上配置第二级缓存。
Hibernate的二级缓存策略的一般过程如下:1) 条件查询的时候,总是发出一条select * from table_name where …. (选择所有字段)这样的SQL 语句查询数据库,一次获得所有的数据对象。
2) 把获得的所有数据对象根据ID放入到第二级缓存中。
3) 当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;查不到,再查询数据库,把结果按照ID放入到缓存。
4) 删除、更新、增加数据的时候,同时更新缓存。
Hibernate的二级缓存策略,是针对于ID查询的缓存策略,对于条件查询则毫无作用。
为此,Hibernate 提供了针对条件查询的Query缓存。
Hibernate的Query缓存策略的过程如下:1) Hibernate首先根据这些信息组成一个Query Key,Query Key包括条件查询的请求一般信息:SQL, SQL需要的参数,记录范围(起始位置rowStart,最大记录个数maxRows),等。
2) Hibernate根据这个Query Key到Query缓存中查找对应的结果列表。
如果存在,那么返回这个结果列表;如果不存在,查询数据库,获取结果列表,把整个结果列表根据Query Key放入到Query缓存中。
3) Query Key中的SQL涉及到一些表名,如果这些表的任何数据发生修改、删2.java中的缓存技术该如何实现看一粒沙中的世界,一朵野花中的天堂。
把无限握于掌中,把永恒握于瞬间。
——威廉• 布莱克开始讨论缓存之前,让我们先来讨论讨论另外一个问题:理论和实践.从ahuaxuan接触的程序员来看,有的程序员偏实践,有的程序员偏理论,但是这都是不好的行为,理论和实践同样重要,我们在做很多核心的算法的时候,没有理论根本无从下手,而在我们多年的实践中,不总结理论就不能加深自己的理解.所以理论和实践同等重要.缓存是当今各种软件或者硬件系统中不可缺少的技术之一,所以对每个程序员来说都显得异常重要,对ahuaxuan来说亦是如此.如果说用dfa实现文字过滤是从理论到实践,那么本文便是从实践中总结出得理论.在讨论缓存功能之前,我们首先来了解一下缓存这个东西本身.ahuaxuan根据自己的经验把缓存问题细分为4类小问题.1缓存为什么要存在?2缓存可以存在于什么地方?3缓存有哪些属性?4缓存介质?搞清楚这4个问题,那么我们就可以随意的通过应用的场景来判断使用何种缓存了.下面ahuaxuan和大家一一分析这4个问题.1. 缓存为什么要存在?一般情况下,一个网站,或者一个应用,它的一般形式是,浏览器请求应用服务器,应用服务器做一堆计算后再请求数据库,数据库收到请求后再作一堆计算后把数据返回给应用服务器,应用服务器再作一堆计算后把数据返回给浏览器.这个是一个标准流程.但是随着互连网的普及,上网的人越来越多,网上的信息量也越来越多,在这两个越来越多的情况下,我们的应用需要支撑的并发量就越来越多.然后我们的应用服务器和数据库服务器所做的计算也越来越多,但是往往我们的应用服务器资源是有限的,数据库每秒中接受请求的次数也是有限的(谁叫俺们的硬盘转速有限呢).如果利用有限的资源来提供尽可能大的吞吐量呢,一个办法:减少计算量,缩短请求流程(减少网络io或者硬盘io),这时候缓存就可以大展手脚了.缓存的基本原理就是打破上图中所描绘的标准流程,在这个标准流程中,任何一个环节都可以被切断.请求可以从缓存里取到数据直接返回.这样不但节省了时间,提高了响应速度,而且也节省了硬件资源.可以让我们有限的硬件资源来服务更多的用户.2 缓存可以存在于什么地方?Java代码1.数据库◊分过层的app-◊浏览器和app之间---◊浏览器---数据库◊分过层的app-◊浏览器和app之间---◊浏览器---在上图中,我们可以看到一次请求的一般流程,下面我们重新绘制这张图,让我们的结构稍微复杂一点点.(将app分层)数据库◊分过层的app-◊浏览器和app之间---◊浏览器---理论上来将,请求的任何一个环节都是缓存可以作用的地方.第一个环节,浏览器,如果数据存在浏览器上,那么对用户来说速度是最快的,因为这个时候根本无需网络请求.第二个环节,浏览器和app之间,如果缓存加在这个地方,那么缓存对app来说是透明的.而且这个缓存中存放的是完整的页面.第三个节点,app中本身就有几个层次,那么缓存也可以放在不同的层次上,这一部分是情况或者场景比较复杂的部分.选择缓存时需要谨慎.第四个环节,数据库中也可以有缓存,比如说mysql的querycache.那么也就是说在整个请求流程的任何一点,我们都可以加缓存.但是是所有的数据都可以放进缓存的吗.当然不是,需要放进缓存的数据总是有一些特征的,要清楚的判断数据是否可以被缓存,可以被怎样缓存就必须要从数据的变化特征下手.数据有哪些变化特征?最简单的就是两种,变和不变.我们都知道,不会变化的数据不需要每次都进行计算.问题是难道所有的数据理论上来讲都会变化,变化是世界永恒的主题.也就是说我们把数据分为变和不变两种是不对的,那么就让我们再加一个条件:时间.那么我们就可以把数据特征总结为一段时间内变或者不变.那么根据这个数据特征,我们就可以在合适的位置和合适的缓存类型中缓存该数据.3缓存有哪些属性从面向对象的角度来看,缓存就是一个对象,那么是对象,必然有属性.那么下面我们来探讨一下缓存有哪些属性.以下列举我们常用到的3个属性.(1) 命中率命中率是指请求缓存次数和缓存返回正确结果次数的比例.比例越高,就证明缓存的使用率越高.命中率问题是缓存中的一个非常重要的问题,我们都希望自己缓存的命中率能达到100%,但是往往事与愿违,而且缓存命中率是衡量缓存有效性的重要指标.(2) 最大元素缓存中可以存放得最大元素得数量,一旦缓存中元素数量超过这个值,那么将会起用缓存清空策略,根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率.从而更有效的时候缓存.(3) 清空策略1 FIFO ,first in first out ,最先进入缓存得数据在缓存空间不够情况下(超出最大元素限制时)会被首先清理出去2 LFU , Less Frequently Used ,一直以来最少被使用的元素会被被清理掉。