Oracle 索引组织表与标准表
oracle索引的结构

oracle索引的结构Oracle索引的结构:了解索引对数据库性能的重要性引言:在数据库中,索引是一种数据结构,它可以加快数据的检索速度,提高数据库的性能。
Oracle作为一种关系型数据库管理系统,也使用索引来优化查询操作。
本文将详细介绍Oracle索引的结构以及其对数据库性能的影响。
一、什么是索引索引是一种数据结构,它类似于书籍的目录,可以帮助我们快速找到需要的数据。
在Oracle中,索引由一个或多个列组成,可以根据这些列的值快速定位到对应的行。
二、Oracle索引的结构1. B树索引B树索引是Oracle中最常见的索引类型。
它使用B树数据结构来组织索引数据,具有平衡性和高效性。
B树索引将索引数据存储在叶子节点中,并使用非叶子节点来加速查找过程。
B树索引适用于范围查询和精确查询。
2. B+树索引B+树索引是B树索引的一种变体,也是Oracle中常用的索引类型。
与B树索引不同,B+树索引将所有索引数据存储在叶子节点中,并使用非叶子节点来组织叶子节点之间的关系。
B+树索引适用于范围查询和排序操作。
3. 唯一索引唯一索引是一种特殊的索引类型,它要求索引列的值唯一,即不允许重复值。
唯一索引可以提高数据的完整性,并且可以通过快速查找来避免重复插入。
在Oracle中,唯一索引可以是B树索引或B+树索引。
4. 聚簇索引聚簇索引是一种特殊的索引类型,它将数据存储在物理上相邻的区域。
在Oracle中,表只能有一个聚簇索引,它可以加速范围查询和连接操作。
聚簇索引通常与主键约束一起使用。
三、索引对数据库性能的影响1. 提高查询速度索引可以加快查询操作的速度,尤其是在大型数据库中。
通过使用索引,数据库可以更快地定位到需要的数据,而不必扫描整个表。
2. 降低IO成本索引可以减少磁盘IO操作,提高数据库的IO性能。
当查询条件与索引列匹配时,数据库可以直接读取索引节点,而不必读取整个数据块。
3. 影响更新性能虽然索引可以提高查询性能,但对于更新操作,索引可能会带来额外的开销。
oracle主键索引和普通索引

oracle主键索引和普通索引在关系型数据库中,索引是提高查询效率的重要手段之一。
在Oracle数据库中,主键索引和普通索引是常见的两种索引类型。
本文将介绍它们的定义、特点以及适用场景,以帮助读者理解和正确使用这两种索引。
一、主键索引主键索引是一种用于唯一标识表中记录的索引类型。
在创建表时,可以通过定义主键来自动创建主键索引。
主键索引中的键值必须是唯一的,并且不能为空值。
1. 定义主键索引在创建表时,可以通过在列定义后使用PRIMARY KEY关键字来定义主键。
例如,创建一个名为"customer"的表,并为"customer_id"列定义主键索引,可以使用以下语句:CREATE TABLE customer (customer_id NUMBER PRIMARY KEY,first_name VARCHAR2(50),last_name VARCHAR2(50));2. 特点与优势- 主键索引的键值唯一且不能为空值,确保了表中记录的完整性。
- 主键索引物理上以B树的形式存储,查询速度较快。
- 主键索引可以被外键引用,用于维护表与表之间的引用完整性。
- 主键索引可以用于加速表的连接操作,提升查询性能。
3. 适用场景主键索引适合用于标识唯一记录的列,例如身份证号、学号等。
在高并发的系统中,主键索引的使用可以避免数据冲突和错误插入。
二、普通索引普通索引(也称为辅助索引)是一种非唯一索引类型,可以用于提高查询效率。
与主键索引不同,普通索引的键值可以重复且可以为空值。
1. 定义普通索引在创建表时,可以通过使用CREATE INDEX语句来定义普通索引。
例如,为"product_name"列创建一个普通索引,可以使用以下语句:CREATE INDEX idx_product_name ON products(product_name);2. 特点与优势- 普通索引可以加速查询速度,减少数据扫描的次数。
oracle查询表索引语句

oracle查询表索引语句Oracle是一种关系型数据库管理系统,可以使用SQL语言进行数据查询和操作。
在Oracle中,索引是一种特殊的数据库对象,它可以提高查询效率和数据访问速度。
索引可以根据一个或多个列值进行排序,并且可以通过索引来快速定位到满足查询条件的数据行。
下面列举了一些常用的Oracle查询表索引的语句。
1. 查看表的索引信息:```sqlSELECT index_name, table_name, column_nameFROM all_ind_columnsWHERE table_name = '表名';```这个语句可以查询指定表的所有索引,包括索引名称、索引所在的表以及索引列。
2. 查看表的主键索引:```sqlSELECT constraint_name, column_nameFROM all_cons_columnsWHERE table_name = '表名'AND constraint_name = 'PK_表名';```这个语句可以查询指定表的主键索引,包括主键约束名称以及主键列。
3. 查看表的唯一索引:```sqlSELECT index_name, table_name, column_nameFROM all_ind_columnsWHERE table_name = '表名'AND uniqueness = 'UNIQUE';```这个语句可以查询指定表的唯一索引,包括索引名称、索引所在的表以及索引列。
4. 查看表的非唯一索引:```sqlSELECT index_name, table_name, column_nameFROM all_ind_columnsWHERE table_name = '表名'AND uniqueness = 'NONUNIQUE';```这个语句可以查询指定表的非唯一索引,包括索引名称、索引所在的表以及索引列。
Oracle 索引簇
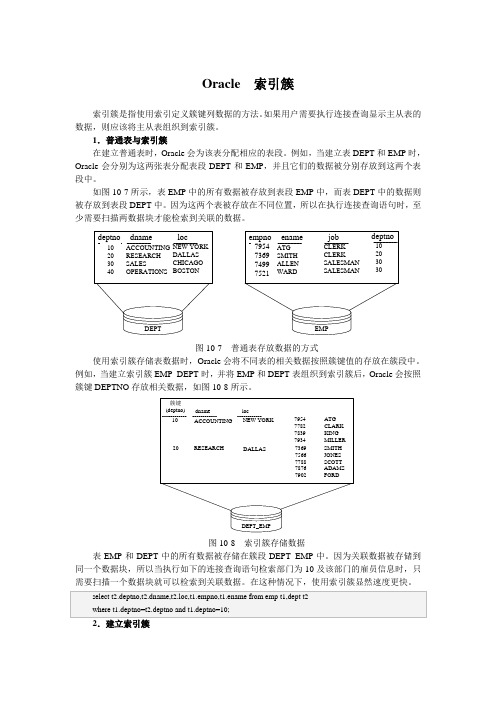
Oracle 索引簇索引簇是指使用索引定义簇键列数据的方法。
如果用户需要执行连接查询显示主从表的数据,则应该将主从表组织到索引簇。
1.普通表与索引簇在建立普通表时,Oracle 会为该表分配相应的表段。
例如,当建立表DEPT 和EMP 时,Oracle 会分别为这两张表分配表段DEPT 和EMP ,并且它们的数据被分别存放到这两个表段中。
如图10-7所示,表EMP 中的所有数据被存放到表段EMP 中,而表DEPT 中的数据则被存放到表段DEPT 中。
因为这两个表被存放在不同位置,所以在执行连接查询语句时,至少需要扫描两数据块才能检索到关联的数据。
empnoenamejob7954736974997521ATG SMITH ALLEN WARDCLERK CLERKSALESMAN SALESMANdeptnodnameloc10203040ACCOUNTING RESEARCH SALESOPERATIONSNEW YORK DALLAS CHICAGO BOSTONDEPT deptno10203030EMP图10-7 普通表存放数据的方式使用索引簇存储表数据时,Oracle 会将不同表的相关数据按照簇键值的存放在簇段中。
例如,当建立索引簇EMP_DEPT 时,并将EMP 和DEPT 表组织到索引簇后,Oracle 会按照簇键DEPTNO 存放相关数据,如图10-8所示。
簇键(deptno)107954778278397934ATG CLARK KING MILLER ACCOUNTINGdname NEW YORKloc20RESEARCH DALLAS73697566778878767902SMITH JONES SCOTT ADAMS FORDDEPT_EMP图10-8 索引簇存储数据表EMP 和DEPT 中的所有数据被存储在簇段DEPT_EMP 中。
因为关联数据被存储到同一个数据块,所以当执行如下的连接查询语句检索部门为10及该部门的雇员信息时,只需要扫描一个数据块就可以检索到关联数据。
Oracle数据库实用教程-第 2章 Oracle表

表TABLE
约束CONSTRAINT
索引INDEX
表空间TABLESPACE
视图VIEW
回退段ROLLBACK SEGMENT
序列生成器SEQUENCE 同义词SYNONYM
用户USER
数据库链路DATABASE LINK
聚簇CLUSTER 分区PARTITION 函数/过程/程序包 触发器TRIGER 对象OBJECT
DESC emp_old;
SELECT * FROM emp_old;
16
2.3.3 存储参数
带存储参数的CREATE TABLE命令的简要语法及说明如下
CREATE TABLE [schema.] table
( { COLUMN1 DATATYPE [DEFAULT EXPn]
[COLUMN_CONSTRAINT] | TABLE_CONSTRAINT }
INSERT
INTO emp(deptno,empno,ename,sal,comm) VALUES(10,1020,'Jordan',4800,500);
32
6.修改存储参数
可 修 改 表 的 PCTFREE , PCTUSED , INITRANS 和MAXTRANS等存储参数。
例:修改表student的存储参数。
12
图2-4 table_properties的语法图
2.3 简单表的创建
2.3.1 简单表的创建语法
语法如下: CREATE TABLE 表名( 列名 类型 [NULL|NOT NULL] [PRIMARY KEY],
… 列名 类型 [NULL|NOT NULL][,[表级完整性约束]]);
13
oracle ebs标准表名

一、概述Oracle E-Business Suite(EBS)是一种集成的应用套件,可帮助企业管理他们的业务流程。
在EBS中,表名是特别重要的标识,它们用于存储各种业务数据。
在本文中,我们将介绍一些常见的Oracle EBS标准表名,这些表名对于理解和使用EBS系统非常重要。
二、常见表名1. FND表FND是Oracle EBS中的一个重要模块,包含了许多用于存储系统配置和元数据的表。
常见的FND表名包括FND_USER、FND_APPLICATION、FND_RESPONSIBILITY等,这些表存储了用户、应用程序、责任等信息,对于管理和维护EBS系统非常重要。
2. AR表AR模块是EBS中用于管理应收账款的模块,其中包含了许多与客户、发票、付款等相关的表。
常见的AR表名包括AR_CUSTOMERS、AR_INVOICES_ALL、AR_PAYMENT_SCHEDULES_ALL等,这些表存储了客户、发票、付款等信息,对于财务管理非常重要。
3. AP表AP模块是EBS中用于管理应付账款的模块,其中包含了许多与供应商、发票、付款等相关的表。
常见的AP表名包括AP_SUPPLIERS、AP_INVOICES_ALL、AP_PAYMENT_SCHEDULES_ALL等,这些表存储了供应商、发票、付款等信息,对于采购管理非常重要。
4. GL表GL模块是EBS中用于管理总账的模块,其中包含了许多与会计期间、账户、凭证等相关的表。
常见的GL表名包括GL_PERIODS、GL_ACCOUNTS、GL_JE_BATCHES等,这些表存储了会计期间、账户、凭证等信息,对于财务报告非常重要。
5. HR表HR模块是EBS中用于管理人力资源的模块,其中包含了许多与员工、岗位、薪酬等相关的表。
常见的HR表名包括HR_EMPLOYEES、HR_POSITIONS、HR_PAYROLL等,这些表存储了员工、岗位、薪酬等信息,对于人力资源管理非常重要。
oracle索引原理详解
oracle索引原理详解Oracle数据库中的索引是用于提高数据检索速度的重要工具。
了解Oracle索引的原理对于数据库管理员和开发人员来说是非常重要的。
一、索引的基本概念索引是Oracle数据库中的一个对象,它可以帮助数据库系统更快地检索数据。
索引类似于书籍的目录,可以快速定位到所需的数据。
二、索引的分类1. B-Tree索引:这是Oracle中最常用的索引类型,基于平衡多路搜索树(B-Tree)实现。
B-Tree索引适用于大多数数据类型,包括字符、数字和日期等。
2. Bitmap索引:位图索引主要用于处理包含大量重复值的列。
通过位图索引,可以更高效地处理这些列的查询。
3. 函数基索引:函数基索引允许在列上应用函数,然后对该结果进行索引。
这可以用于优化包含函数操作的查询。
4. 反转键索引:反转键索引是一种特殊类型的B-Tree索引,用于优化插入操作。
通过反转键顺序,可以更高效地处理插入操作。
三、索引的创建和维护1. 创建索引:创建索引的基本语法是“CREATE INDEX index_name ON table_name (column_name)”。
其中,index_name是索引的名称,table_name是要创建索引的表名,column_name是要索引的列名。
2. 维护索引:定期维护索引可以确保其性能和可靠性。
常用的维护操作包括重建索引(REBUILD INDEX)和重新组织索引(ORGANIZE INDEX)。
四、索引的优点和缺点1. 优点:使用索引可以显著提高数据检索速度,减少查询时间。
此外,索引还可以用于优化复杂查询的性能。
2. 缺点:虽然索引可以提高性能,但它们也会占用额外的磁盘空间。
此外,当表中的数据发生变化时,索引也需要更新,这可能会影响写操作的性能。
五、最佳实践1. 在经常用于搜索和排序的列上创建索引。
2. 根据查询模式和数据分布选择合适的索引类型。
3. 定期分析和维护索引,确保其性能和可靠性。
Oracle索引详解
一.索引介绍1.1 索引的创建语法:CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>ON <schema>.<table_name>(<column_name> | <expression> ASC | DESC,<column_name> | <expression> ASC | DESC,...)TABLESPACE <tablespace_name>STORAGE <storage_settings>LOGGING | NOLOGGINGCOMPUTE STATISTICSNOCOMPRESS | COMPRESS<nn>NOSORT | REVERSEPARTITION | GLOBAL PARTITION<partition_setting>相关说明1) UNIQUE | BITMAP:指定UNIQUE为唯一值索引,BITMAP为位图索引,省略为B-Tree索引。
2)<column_name> | <expression> ASC | DESC:可以对多列进行联合索引,当为expression 时即“基于函数的索引”3)TABLESPACE:指定存放索引的表空间(索引和原表不在一个表空间时效率更高)4)STORAGE:可进一步设置表空间的存储参数5)LOGGING | NOLOGGING:是否对索引产生重做日志(对大表尽量使用NOLOGGING来减少占用空间并提高效率)6)COMPUTE STATISTICS:创建新索引时收集统计信息7)NOCOMPRESS | COMPRESS<nn>:是否使用“键压缩”(使用键压缩可以删除一个键列中出现的重复值)8)NOSORT | REVERSE:NOSORT表示与表中相同的顺序创建索引,REVERSE表示相反顺序存储索引值9)PARTITION | NOPARTITION:可以在分区表和未分区表上对创建的索引进行分区1.2 索引特点:第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
oracle的索引类型
oracle的索引类型
Oracle数据库中常见的索引类型包括:1. B树索引(B-tree Index):是Oracle 默认的索引类型,适用于等值查找和范围查找。
2. 唯一索引(Unique Index):确保索引列的值在表中是唯一的。
3. 聚集索引(Cluster Index):按照表的物理存储顺序进行索引,适用于频繁进行范围查找的列。
4. 位图索引(Bitmap Index):将索引列的不同值分组为位图,并对每个位图使用压缩算法,适用于低基数列(取值范围较小)。
5. 函数索引(Function-Based Index):基于表达式或函数的结果构建的索引,适用于计算、转换或覆盖列的查询。
6. 虚拟列索引(Virtual Column Index):基于虚拟列(由表达式计算而来)构建的索引。
7. 全文索引(Full-Text Index):适用于对文本数据进行全文搜索的场景。
8. 空间索引(Spatial Index):适用于对地理位置和空间数据进行查询和分析。
9. 哈希索引(Hash Index):根据哈希函数计算的值来构建索引,适用于等值查询的索引。
10. 反向索引(Reverse Key Index):逆序存储索引键的位模式,适合于高度并发且插入操作有序的情况。
需要根据具体业务和查询需求选择合适的索引类型,以提高查询性能。
oracle 命令复制表结构及数据 主键 索引 注释
oracle 命令复制表结构及数据主键索引注释In Oracle, there are several ways to copy a table's structure, data, primary keys, indexes, and comments. Here are the methods you can use:1. Using CREATE TABLE AS SELECT statement:You can use the CREATE TABLE AS SELECT statement to create a new table with the same structure and data as an existing table.Example:CREATE TABLE new_table AS SELECT * FROM existing_table;This command will create a new table called "new_table" with the same structure and data as "existing_table".使用CREATE TABLE AS SELECT语句:您可以使用CREATE TABLE AS SELECT语句来创建一个具有与现有表相同的结构和数据的新表。
示例:CREATE TABLE new_table AS SELECT * FROM existing_table;这个命令将创建一个名为“new_table”的新表,该表的结构和数据与“existing_table”相同。
2. Using the EXPDP/IMPDP utility:You can use the Oracle Data Pump utility (EXPDP/IMPDP) to export and import tables with their structures, data, primary keys, indexes, and comments.Example:To export the table:expdp system/password@database_name tables=table_name directory=directory_name dumpfile=dumpfile_name.dmplogfile=log_file.logTo import the table:impdp system/password@database_name tables=table_name directory=directory_name dumpfile=dumpfile_name.dmplogfile=log_file.log使用EXPDP/ IMPDP实用程序:您可以使用Oracle Data Pump实用程序(EXPDP/ IMPDP)导出和导入带有其结构、数据、主键、索引和注释的表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle 索引组织表与标准表
索引组织表也称为IOT ,索引组织表实际上一个表,不过它的存储结构不像普通的表那样采用堆组织方式,而是采用索引的组织方式。
对于普通表而言,其存储结构是将记录无序地存放在数据段中,而索引化组织表是将记录按照某个主键列进行排序后,再以B 树的组织方式存放在数据段中。
由于整条记录都被保存在索引中,所以索引组织表不需要使用ROWID 来确定记录的位置。
在索引组织表中只需要知道主键列的值,就能够直接找到相应记录的完整内容。
因此,索引组织表提供了快速的、基于主键的对表中数据快速访问。
但是,这是以牺牲插入和更新性能为代价的。
图9-6所示示意性地列出了索引组织表与标准表之间的区别。
ROWID
普通表索引索引表
主键行头非主键列
图9-6 索引组织表与标准堆表的对比
对于普通表而言,表、索引数据是分别存放在表段、索引段,要占用更多空间;而对于索引表而言,主键列和非主键列的数据都被存放在主键索引段中。
当经常要使用主键列定义表数据时,应该建立索引表。
使用索引表,一方面降低了磁盘和内存空间占用。
另一方面也可以提高访问性能。
建立索引表也是使用CREATE TABLE 语句完成的。
需要注意,建立索引组织表时,必须指定ORGANIZATION INDEX 关键字,并且在索引组织表中必须定义主键约束。
例如,下面的语句建立一个索引组织的EMPLOYEES 表: SQL> create table employees(
2 empno number(5) primary key,
3 ename varchar2(15) not null,
4 job varchar2(10),
5 hiredate date default (sysdate),
6 sal number(7,2),
7 deptno number(3) not null
8 ) organization index
9 tablespace users;
表已创建。
如果向索引组织表中添加数据,Oracle会根据主键列进行对其排序,然后再将数据写入磁盘。
这样在使用主键列查询时,在索引组织表上可以得到更好的读取性能。
在标准堆表上进行相同的查询时,需要首先读取索引,然后再判断数据块在磁盘上的位置,最后Oracle 必须将相关的数据块放入内存中。
而索引组织表将所有数据都存储在索引中,所以不需要再去查找存储数据的数据块。
这样相同的查询,在索引组织表中执行的效率是标准堆表的两倍。
虽然索引组织表的查询执行效率比堆表高,但时索引组织表比堆表更难于维护。
当向堆表中添加数据时,Oracle只需要简单地在表的盘区中找到一个可用空间保存数据。
而索引组织表由于需要对数据按照B树结构进行组织,所以Oracle要根据所添加数据的主键将数据写合适的数据块。
这就不可避免的要在数据块中移动已经存在的行,以提供足够的空间存放新行。