第六讲 简单线性回
简单线性回归分析2

)
lXY lXX
a Y bX
03:56
24
b=0.1584,a=-0.1353
Yˆ 0.1353 0.1584X
03:56
25
回归直线的有关性质
(1) 直线通过均点 ( X ,Y )
(2) 各点到该回归线纵向距离平方和较到其它任何直线小。
(Y Yˆ)2 [Yˆ a bX ]2
03:56
残 差 0.0282 22 0.0013
总变异 0.0812 23
R2=SS回归/SS总=0.0530/0.0812=0.6527 说明在空气中NO浓度总变异的65.27%与车流量有关。
03:56
48
二、简单线性回归模型
两变量关系的定量描述 统计推断 统计应用
统计预测
Y 的均值的区间估计:总体回归线的95%置信带(相应X 取值水平下,) ;
回归模型 (regression model):
描述变量之间的依存关系的函数。
简单线性回归(simple linear regression):
模型中只包含两个有“依存关系”的变量,一个变量随 另外一个变量的变化而变化,且呈直线变化趋势,称之 为简单线性回归。
03:56
9
例如,舒张压和血清胆固醇的依存性
统计推断 通过假设检验推断NO平均浓度是否随着车 流量变化而变化;
统计应用 利用模型进行统计预测或控制。
03:56
13
两变量关系的定量描述
散点图 简单线性回归方程 回归系数的计算——回归系数的最小二乘估计 线性回归分析的前提条件
03:56
14
1. 散点图
0.25
0.2
NO浓度/×10-6
正态 (normal)假定是指线性模型的误差项服从正态 分布 。
简单回归方程

简单线性回归方程是一种基本的回归分析模型,它只涉及一个因变量和一个自变量,并且这两个变量之间呈线性关系。
简单线性回归方程的公式为:y=β0+β1x+ε,其中y是因变量,x是自变量,β0和β1是模型参数,ε是误差项。
这个公式表示的是,因变量y的期望值E(y)与自变量x和误差项ε之间的关系。
具体来说,E(y)=β0+β1x。
这个公式是通过最小二乘法等统计方法,根据样本数据拟合得到的。
简单线性回归方程的应用非常广泛,例如在经济学、生物学、医学等领域都有广泛的应用。
通过简单线性回归方程,我们可以分析两个变量之间的关联性,预测未来趋势,以及进行统计推断等。
简单线性回归

6.98020
15
a 224 (6.98020) 14.7 21.77393
15
15
Yˆ 21.77393 6.9802 X
除了图中所示两变量呈直线关系外,一 般还假定每个 X 对应 Y 的总体为正态分布, 各个正态分布的总体方差相等且各次观测 相互独立。这样,公式(12-2)中的 Yˆ 实际 上是 X 所对应 Y 的总体均数 Y |X 的一个样本 估计值,称为回归方程 的预测值(predicted value),而 a 、 b 分别为 和 的样本估计。
均数YY 是固定的,所以这部分变异由 Yˆi 的大小不同引起。
当 X 被引入回归以后,正是由于Xi 的不同导致了 Yˆi a bXi 不同,所以SS回 反映了在 Y 的总变异中可以用 X 与 Y 的直线关系解释的那部分变异。
b 离 0 越远,X 对 Y 的影响越大,SS回 就越大,说明 回归效果越好。
lXX
(X X )2
a Y bX
式 中 lXY 为 X 与 Y 的 离 均 差 乘 积 和 :
lXY
(X
X
)(Y
Y
)
XY
(
X
)( n
Y
)
本例:n=15 ΣX=14.7 ΣX2=14.81
ΣY=224 ΣXY=216.7 ΣY2=3368
216.7 (14.7)(224)
b
15 14.81 (14.7)2
儿子身高(Y,英寸)与父亲身高(X, 英寸)存在线性关
系:Yˆ 33.73 0.516 X 。
也即高个子父代的子代在成年之后的身高平均来 说不是更高,而是稍矮于其父代水平,而矮个子父代的子 代的平均身高不是更矮,而是稍高于其父代水平。Galton 将这种趋向于种族稳定的现象称之“回归”
线性相关与回归(简单线性相关与回归、多重线性回归、Spearman等级相关)

(3)r与b的假设检验等价
4.相关与回归的区别和联系
(4) 可以用回归解释相关
r
2
SS回归 SS总
r2称为决定系数(coefficient of determination), 其越接近于1,回归直线拟和的效果越好。
例1 为研究中年女性体重指数和收缩压的关系,随机测量 了16名40岁以上的女性的体重指数和收缩压(见数据文件 p237.sav)。
ˆ a bX Y
ˆ :是Y(实测值)的预测值(predicted value), Y
是直线上点的纵坐标。对于每一个X值,根据直线 回归方程都可以计算出相应的Y预测值。
(具体计算过程参见《卫生统计学》第4版)。
2.b和a的意义 a:是回归直线在Y轴上的截距,即X=0时Y的预测值。 b:是回归直线的斜率,又称为回归系数。 表示当X改变一个单位时,Y的预测值平均改变|b| 个单位。 3.b和a的估计 最小二乘方法(the method of least squares): 各实测点到直线的纵向距离的平方和最小。
|r|越大,两变量相关越密切(前提:r有统计学意义)
2.相关类型 正相关:0<r1
负相关-1r<0
2.相关类型 零相关 r =0
曲线相关
3.r的假设检验 r为样本相关系数,由于抽样误差,实际工作中r一般都 不为0。要判断两变量之间是否存在相关性,需要检验 总体相关系数是否为0。 H0:=0 H1: 0
关于独立性:
所有的观测值是相互独立的。如果受试对象仅被随机 观测一次,那么一般都会满足独立性的假定。但是出 现下列三种情况时,观测值不是相互独立的:时间序 列、重复测量等情况。
SPSS软件在“Linear Regression:Statistics”对话 框中,提供了Durbin-Watson统计量d,以检验自相 关系数是否为0。当d值接近于2,则残差之间是不相 关的。
线性模型知识点总结

线性模型知识点总结一、线性模型概述线性模型是统计学中一类简单而又常用的模型。
在线性模型中,因变量和自变量之间的关系被描述为一个线性方程式。
线性模型被广泛应用于各种领域,如经济学、医学、社会科学等。
线性模型的简单和普适性使得它成为数据分析中的一种重要工具。
线性模型可以用来建立预测模型、对变量之间的关系进行建模和推断、进行变量选择和模型比较等。
在实际应用中,线性模型有多种形式,包括简单线性回归、多元线性回归、广义线性模型、岭回归、逻辑回归等。
这些模型在不同的情况下可以更好地满足数据的特点和要求。
二、线性回归模型1. 简单线性回归简单线性回归是最基本的线性模型之一,它描述了一个因变量和一个自变量之间的线性关系。
简单线性回归模型可以用如下的方程式来表示:Y = β0 + β1X + ε其中,Y是因变量,X是自变量,β0和β1分别是截距项和斜率项,ε是误差项。
简单线性回归模型基于最小二乘法估计参数,从而得到最优拟合直线,使得观测值和拟合值的离差平方和最小。
简单线性回归模型可以用来分析一个自变量对因变量的影响,比如身高和体重的关系、学习时间和考试成绩的关系等。
2. 多元线性回归多元线性回归是在简单线性回归的基础上发展而来的模型,它能够同时描述多个自变量对因变量的影响。
多元线性回归模型可以用如下的方程式来表示:Y = β0 + β1X1 + β2X2 + ... + βpXp + ε其中,X1、X2、...、Xp是p个自变量,β0、β1、β2、...、βp分别是截距项和各自变量的系数,ε是误差项。
多元线性回归模型通过估计各系数的值,可以得到各自变量对因变量的影响情况,以及各自变量之间的相关关系。
3. 岭回归岭回归是一种用来处理多重共线性问题的线性回归方法。
在多元线性回归中,如果自变量之间存在较强的相关性,会导致参数估计不准确,岭回归通过对参数加上一个惩罚项来避免过拟合,从而提高模型的稳定性和泛化能力。
岭回归模型可以用如下的方程式来表示:Y = β0 + β1X1 + β2X2 + ... + βpXp + ε - λ∑(β^2)其中,λ是岭参数,用来平衡参数估计和惩罚项之间的关系。
SPSS操作:简单线性回归(史上最详尽的手把手教程)
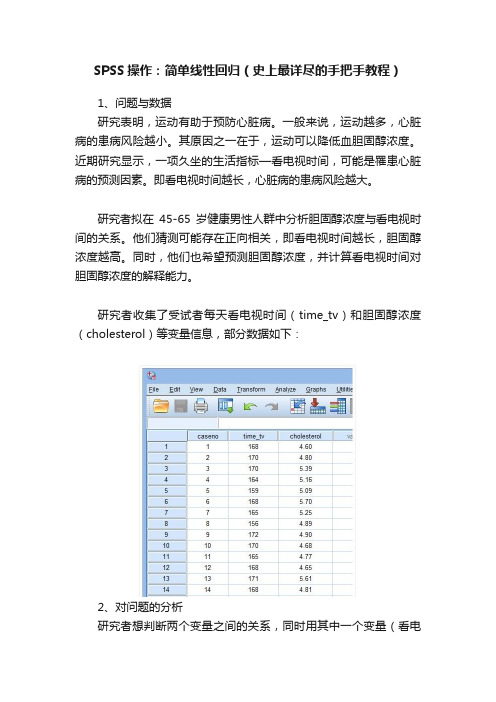
SPSS操作:简单线性回归(史上最详尽的手把手教程)1、问题与数据研究表明,运动有助于预防心脏病。
一般来说,运动越多,心脏病的患病风险越小。
其原因之一在于,运动可以降低血胆固醇浓度。
近期研究显示,一项久坐的生活指标—看电视时间,可能是罹患心脏病的预测因素。
即看电视时间越长,心脏病的患病风险越大。
研究者拟在45-65岁健康男性人群中分析胆固醇浓度与看电视时间的关系。
他们猜测可能存在正向相关,即看电视时间越长,胆固醇浓度越高。
同时,他们也希望预测胆固醇浓度,并计算看电视时间对胆固醇浓度的解释能力。
研究者收集了受试者每天看电视时间(time_tv)和胆固醇浓度(cholesterol)等变量信息,部分数据如下:2、对问题的分析研究者想判断两个变量之间的关系,同时用其中一个变量(看电视时间)预测另一个变量(胆固醇浓度),并计算其中一个变量(看电视时间)对另一个变量(胆固醇浓度)变异的解释程度。
针对这种情况,我们可以使用简单线性回归分析,但需要先满足7项假设:假设1:因变量是连续变量假设2:自变量可以被定义为连续变量假设3:因变量和自变量之间存在线性关系假设4:具有相互独立的观测值假设5:不存在显著的异常值假设6:等方差性假设7:回归残差近似正态分布那么,进行简单线性回归分析时,如何考虑和处理这7项假设呢?3、思维导图(点击图片可查看清晰大图)4、对假设的判断4.1 假设1和假设2因变量是连续变量,自变量可以被定义为连续变量。
举例来说,我们平时测量的反应时间(小时)、智力水平(IQ分数)、考试成绩(0到100分)以及体重(千克)都是连续变量。
在线性回归中,因变量(dependent variable)一般是指研究的成果、目标或者标准值;自变量(independent variable)一般被看作预测、解释或者回归变量。
假设1和假设2与研究设计有关,需要根据实际情况判断。
4.2 假设3简单线性回归要求自变量和因变量之间存在线性关系,如要求看电视时间(time_tv)和胆固醇浓度(cholesterol)存在线性关系。
简单线性回归模型PPT课件

940 1030 1160 1300 1440 1520 1650
980 1080 1180 1350 1450 1570 1750
-
1130 1250 1400 -
1600 1890
-
1150 -
-
-
1620 -
2600 1500 1520 1750 1780 1800 1850 1910
y (消费)
出-
表2
1000 650 700 740 800 850 880 -
每月家庭收入支出表(元)
1200 1400 1600 1800 2000 2200 2400
790 800 1020 1100 1200 1350 1370
840 930 1070 1150 1360 1370 1450
900 950 1100 1200 1400 1400 1550
ui N (0, 2 ) (i 1,2,..., n)
或 Yi N (1 1X i , 2 ) (i 1,2,..., n)
以上假定也称高斯假定或古典假定。
二、普通最小二乘法
在不知道总体回归直线的情况下,利用样本信 息建立的样本回归函数应尽可能接近总体回归 函数,有多种方法。
普通最小二乘法(Ordinary Least Squares) 由德国数学家高斯(C.F.Gauss)提出。
Y
e1
Yˆi ˆ1 ˆ2 Xi e3
e4
e2
X1
X2
X
X3
X4
ei Yi Yˆi
Yi (ˆ1 ˆ2 Xi )
对于给定的 Y 和 X的观测值,我们希望这 样决定SRF,使得SRF上的值尽可能接近 实际的 Y。
就是使得残差平方和
计量经济学第六讲vvv

第六讲 多重共线一、 数学准备:FWL 定理对于多元线性回归模型:112233i i i i i y a b x b x b x ε=++++ (1)在OLS 法下,各系数估计通过求解四个正规方程而获得。
事实上,如果只关注某一个斜率系数的估计结果,则通过构造一系列简单线性回归模型就能获得所关注的斜率系数的估计。
假设我们现在关注1ˆb ,那么构造系列简单线性回归模型的过程是:第一步:把1x 对其他解释变量进行回归(请注意,截距所对应的解释变量为1),即有:101223ˆˆˆˆi i i i x x x v βββ=+++ (2) 第二步:把y 也对(2)中的解释变量进行回归,即有:01223ˆˆˆˆi i i i y x x w ϕϕϕ=+++ (3)第三步:把ˆw 对ˆv 进行回归(因为ˆw 与ˆv 其均值都为零,所以该回归模型不必带有截距项),即有:ˆˆˆˆi i i v e w η=+ (4) 现在有两个结论,即,结论一:21ˆˆˆˆˆi i i wv v b η==∑∑;结论二:残差ˆi e 等于多元回归中的残差ˆi ε。
这两个结论就是著名的FWL 定理(Frisch-Waugh-Lovell theorem )。
关于FWL 定理的一个简单证明见附录1。
附录2涉及到该定理的应用。
笔记:1b 所反映的是,在控制其他因素后1x 对y 的影响(与“偏导数”概念对应)。
1x 与y 的相关关系可能是由于它们共同的“亲戚”—— 2x 与3x 所带来的。
在控制共同“亲戚”对1x 及其y 的影响后,我们所发现的1x 与y 的相关关系被称为偏相关关系。
在前述步骤中,第一步与第二步实际上是在剔除共同“亲戚”的影响。
练习:基于简单线性回归模型:i i i y a bx ε=++验证FWL 定理。
如果我们只需要结论一,则上述三步骤可以被简化为两步骤:首先把1x 对其他解释变量进行回归,得到残差ˆi v ,其次把y 对ˆv 进行回归:ˆˆ*ˆi i iv y ηξ=+ 可以验证:122ˆˆˆˆˆˆ*ˆˆi i i i i iy v wv b v v ηη====∑∑∑∑,但应该注意此时并不能保证ˆˆi i ξε=成立。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在应变量的样本总平方和中,一部分为回归平方和,另 一部分为残差平方和。这就意味着从已得的样本观测值来 看,应变量的变差一部分可以用解释变量来解释,而另一 部分则不能用解释变量来解释。显然能够用解释变量来解 释的部分占应变量的总变差的比例就是表示样本回归线对 应变量的样本值拟合程度的一个量度,我们称这个量度为 判定系数或决定系数,用R2表示。即
二、回归模型的总显著性检验(F检验)
解释变量对应变量的解释程度还可以从对回归平方和与残 差平方和的对比中说明。对简单线性回归模型而言,我们可 以构造一个F统计量
SSR/1 F SSE / (n-2)
ˆ
2 2
ˆ u
x
2 2i
2 i
/(n 2)
当F统计量的值较大时,我们就可以认为样本回归方程对应 变量的解释是显著的。在假设斜率系数为零的条件下,上述 F统计量服从第一个自由度为1,第二个自由度为的F分布。 我们可以构造一个F检验程序,用以说明回归方程对应变量 的影响是显著的。
F检验的程序
:
1 设置原假设与对立假设: 原假设 H 0 : 2 0
对立假设 H1 : 2 0
2 作统计量
F
SSR/1 SSE / (n-2) u i 2 /(n 2) ˆ
ˆ 2 2 x 2i 2
3 根据样本数据和原假设计算统计量F的值; 4 根据统计量F的值进行显著性判断: 如果统计量F的值小于某个临界值 F 不拒绝回归方程不显著的假设; 否则,拒绝假设,从而回归方程是显著的。 例子:理解EXcel中回归分析的输出结果。
三、R2、t和F的关系
(一) t和F的关系 仅对于简单线性回归模型有:t2=F (二) R2和F的关系
SSR (n 2) SSR/1 (n 2) R 2 SST F SSE SSE / (n-2) 1 R2 SST
四、方差分析表
将方差分解、 拟合优度和F统 计量及其关系, 用表格形式表 现在一张表格 中,即为方差 分析表:
df SST (11)
SS (12)
MS (13)=(12)/(11)
SSR
(21)
(22)
(23)=(22)1(21)
SSE
(31)
(32)
(33)=(32)/(31)
R2=(22)/(12)
F=(23)/(33)
五、作业
习题二:一、(14-18)
R2 SSR SST ˆ 2
2
拟合优度
x 2i
i 1 2
n
2
yi
i 1
n
1
ˆ2 ui
n
yi
i 1
i 1 n
1
2
SSE SST
评价
拟合优度的值是在
0与1之间的变动的,对简 单线性回归模型而言,其值能达到0.8是一个 相当不错的结果,如果其值达到0.9以上,一 般来说可能性不大。
第六讲 简单线性回归模型的评价
ˆ ˆ 本次课的分析基于模型: Yi 1 2 X 2i 一、方差分解与拟合优度 二、回归模型的总显著性检验(F检验) 三、R2、t和F的关系 四、方差分析表 五、作业 ˆ ui
一、方差分解与拟合优度
(一)方差分解 (二)拟合优度
方差分解
被解释变量Y的变异是由解释变量的 变化与残差的变异所造 成。 而变异是可以由其相应 的离差平方和表示: 被解释变量Y:其离差平方和称为总 平方和(SST) ; 解释变量:其离差平方 和称为回归平方和( ); SSR 残差:其离差平方和即 为残差平方和( ) SSE . 它们之间的关系是: SST SSR SSE 这说明: 总平方和可以分解为回 归平方和与残差平方和 . 我们称这个结论为方差 分解.