初级计量经济学试卷A卷带参考答案
计量经济学题库(有答案)

ˆ 表示 OLS 估计回归值,则下列哪项成立__________。D 13、设 Y 表示实际观测值, Y
2 x
ˆ 表示估计标准误差,r 表示相关系数,则有__________。D ˆ ˆ X +e ,以 8、对于 Yi = 0 1 i i
ˆ=0时,r=1 A ˆ=0时,r=-1 B ˆ=0时,r=0 C ˆ=0时,r=1或r=-1 D
ˆ =356 1.5X ,这说 9、产量(X,台)与单位产品成本(Y,元/台)之间的回归方程为 Y
1
C 滞后变量 D 前定变量 7、描述微观主体经济活动中的变量关系的计量经济模型是__________。A A 微观计量经济模型 B 宏观计量经济模型 C 理论计量经济模型 D 应用计量经济模型 8、经济计量模型的被解释变量一定是__________。C A 控制变量 B 政策变量 C 内生变量 D 外生变量 9、下面属于横截面数据的是__________。D A 1991-2003 年各年某地区 20 个乡镇企业的平均工业产值 B 1991-2003 年各年某地区 20 个乡镇企业各镇的工业产值 C 某年某地区 20 个乡镇工业产值的合计数 D 某年某地区 20 个乡镇各镇的工业产值 10、经济计量分析工作的基本步骤是__________。A A 建立模型、收集样本数据、估计参数、检验模型、应用模型 B 设定模型、估计参数、检验模型、应用模型、模型评价 C 个体设计、总体设计、估计模型、应用模型、检验模型 D 确定模型导向、确定变量及方程式、估计模型、检验模型、应用模型 11、将内生变量的前期值作解释变量,这样的变量称为__________。D A.虚拟变量 B.控制变量 C.政策变量 D.滞后变量
Yt 0 1 X t ut
计量经济学题库超完整版及答案

计量经济学题库超完整版及答案Company number【1089WT-1898YT-1W8CB-9UUT-92108】计量经济学题库一、单项选择题(每小题1分)1.计量经济学是下列哪门学科的分支学科(C)。
A.统计学 B.数学 C.经济学D.数理统计学2.计量经济学成为一门独立学科的标志是(B)。
A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来3.外生变量和滞后变量统称为(D)。
A.控制变量 B.解释变量 C.被解释变量D.前定变量4.横截面数据是指(A)。
A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。
A.时期数据 B.混合数据 C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。
A.内生变量 B.外生变量 C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。
A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型D.应用计量经济模型8.经济计量模型的被解释变量一定是( C )。
A.控制变量 B.政策变量 C.内生变量D.外生变量9.下面属于横截面数据的是( D )。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值B.1991-2003年各年某地区20个乡镇企业各镇的工业产值C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是( A )。
A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型11.将内生变量的前期值作解释变量,这样的变量称为()。
计量经济学试卷及答案

内蒙古工业大学2006——2007学年第1学期 《计量经济学》期末考试试卷(A )(课程代码:070403014)试卷审核人: 考试时间:2006.12.3注意事项:1. 本试卷适用于04级国贸、财管专业(本科层次)学生使用。
2. 本试卷共11页,满分100分。
答题时间120分钟。
班级: 姓名: 学号:一、填空题(具体要求。
本大题共5道小题,每小题2分,共10分)1.计量经济模型的计量经济检验通常包括随机误差项的序列相关检验、异方差性检验、解释变量的多重共线性检验。
2. 普通最小二乘法得到的参数估计量具有线性,无偏性,有效性统计性质。
3.对计量经济学模型作统计检验包括_拟合优度检验、方程的显著性检验、变量的显著性检验。
4.在计量经济建模时,对非线性模型的处理方法之一是线性化,模型βα+=X XY 线性化的变量变换形式为Y *=1/Y X *=1/X ,变换后的模型形式为Y *=α+βX *。
5.联立方程计量模型在完成估计后,还需要进行检验,包括单方程检验和方程系统检验。
二、单选题(具体要求。
本大题共20道小题,每小题1分,共20分)1.计量经济模型分为单方程模型和(C )。
A.随机方程模型B.行为方程模型C.联立方程模型D.非随机方程模型2.经济计量分析的工作程序(B )A.设定模型,检验模型,估计模型,改进模型B.设定模型,估计参数,检验模型,应用模型C.估计模型,应用模型,检验模型,改进模型D.搜集资料,设定模型,估计参数,应用模型3.对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的(B )。
A.iC (消费)iI 8.0500+=(收入)B.diQ (商品需求)iI 8.010+=(收入)iP 9.0+(价格)C.si Q (商品供给)iP 75.020+=(价格)D.iY (产出量)6.065.0iK =(资本)4.0iL (劳动)4.回归分析中定义的(B )A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量5.最常用的统计检验准则包括拟合优度检验、变量的显著性检验和(A )。
6套计量经济学试卷(附答案)!

第六套一、单项选择题1、计量经济学的研究方法一般分为以下四个步骤(B)A.确定科学的理论依据、模型设定、模型修定、模型应用B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、模型修定、结构分析、模型应用2、简单相关系数矩阵方法主要用于检验(D)A.异方差性 B.自相关性C.随机解释变量 D.多重共线性3、在某个结构方程恰好识别的条件下,不适用的估计方法是( DA .间接最小二乘法C.二阶段最小二乘法B.工具变量法D.普通最小二乘法)4、在利用月度数据构建计量经济模型时,如果一年里的12个月全部表现出季节模式,则应该引入虚拟变量个数为(C)A. 4B. 12C. 11D. 65、White检验可用于检验(B)A.自相关性C.解释变量随机性B.异方差性D.多重共线性6、如果回归模型违背了无自相关假定,最小二乘估计量是(A.无偏的,有效的C.无偏的,非有效的B.有偏的,非有效的D.有偏的,有效的C )7、假如联立方程模型中,第i个方程排除的变量中没有一个在第j个方程中出现,则第i个方程是(D)A.可识别的B.恰好识别C.过度识别D.不可识别8、在简单线性回归模型中,认为具有一定概率分布的随机变量是( AA.内生变量B.外生变量C.虚拟变量D.前定变量)9、应用DW检验方法时应满足该方法的假定条件,下列不是其假定条件的为(B)A.解释变量为非随机的B.被解释变量为非随机的C.线性回归模型中不能含有滞后内生变量D.随机误差项服从一阶自回归10、二元回归模型中,经计算有相关系数RA. X 2和X 3间存在完全共线性B. X 2和X 3间存在不完全共线性C. X 2对X 3的拟合优度等于0.9985D.不能说明X 2和X 3间存在多重共线性)X2X3= 0.9985,则表明( B11、在DW检验中,存在正自相关的区域是(A. 4 - dL< d < 4C. dU< d < 4 -dU B )B. 0 < d < dLD.dL < d < dU,4 - dU< d < 4 - dL12、库伊克模型不具有如下特点( D )A.原始模型为无限分布滞后模型,且滞后系数按某一固定比例递减B.以一个滞后被解释变量Y代替了大量的滞后解释变量X ,Xt -1 t -1 t -2,⋯,从而最大限度的保证了自由度C.滞后一期的被解释变量Y与Xt的线性相关程度肯定小于X ,X的相关程度,从而缓解了多重共线性的问题t -1 t -1D.由于Cov (Y ,u ) * tt -1 = 0,Cov (u ,u*t*t -1t -2,⋯) = 0,因此可使用OLS方法估计参数,参数估计量是一致估计量13、在具体运用加权最小二乘法时,如果变换的结果是则Var(u )是下列形式中的哪一种?(B)t2 A.οXt B.οXt222C.οXtYtX= β1t1X tu t+ β2+,X tD.οlog( X )2t14、下列是简化的三部门宏观经济计量模型,则模型中前定变量的个数为A)⎧Yt = Ct+ It+ G⎪ ⎨ ⎪ ⎩ C tI t= α+α Y + u= β+ β Y + β γ + u1t1t1t -1B. 42tC. 2(A. 3 2tD. 615、在异方差的情况下,参数估计值仍是无偏的,其原因是( D )A.零均值假定不成立C.无多重共线性假定成立B.序列无自相关假定成立D.解释变量与随机误差项不相关假定成立16、已知 DW 统计量的值接近于 2,则样本回归模型残差的一阶自相关系数ρ 近似等于( A )_A. 0B. -1C. 1D. 417、对美国储蓄与收入关系的计量经济模型分成两个时期分别建模,重建时 期是 1946—1954;重建后时期是 1955—1963,模型如下:重建时期:Y t = λ 1 + λ 2 X t + μ 1t重建后时期: Y t = λ 3 + λ 4 Xt + μ2t关于上述模型,下列说法不正确的是( D )A.λ 1 = λ 3 λ 2 = λ 4 时则称为重合回归B.λ 1 ≠ λ 3 λ 2 = λ 4 时称为平行回归C.λ 1 ≠ λ 3 λ 2 ≠ λ 4 时称为相异回归D.λ 1 ≠ λ 3 λ 2 = λ 4 两个模型没有差异18、对样本的相关系数γ ,以下结论错误的是( AA. γ 越接近 0, X 与Y 之间线性相关程度高B. γ 越接近 1, X 与Y 之间线性相关程度高C. -1 ≤ γ ≤ 1D 、γ = 0 ,在正态分布下,则 X 与Y 相互独立_ __)19、、对于二元样本回归模型Y i = β 1 + β 21X + β 3X + e ,下列不成立的有 2i 3i i D )A.∑ ie = 0C.∑ ie X = 03i (B.∑ ie X = 0D.∑e Y = 0i i2i 20、当联立方程模型中第 i 个结构方程是不可识别的,则该模型是(B )A.可识别的B.不可识别的C.过度识别的D.恰好识别的二、多项选择题1、关于自适应预期模型和局部调整模型,下列说法不正确的有( C E ) A. 它们都是由某种期望模型演变形成的 B. 它们最终都是一阶自回归模型 C. 它们都是库伊克模型的特例 D. 它们的经济背景不同E.都满足古典线性回归模型的所有假设,从而可直接用 OLS 进行估计 2、能够检验多重共线性的方法有( A B ) A.简单相关系数矩阵法 C. DW 检验法 E. White 检验B. t 检验与 F 检验综合判断法 D.ARCH 检验法3、有关调整后的判定系数 R 与判定系数 R 之间的关系叙述正确的有(B C )A. R 与 R 均非负B.模型中包含的解释个数越多, R 与 R 就相差越大.C.只要模型中包括截距项在内的参数的个数大于 1,则 R < R . 22 22 22 222E. R 有可能小于 0,但 R 却始终是非负4、检验序列自相关的方法是( C E ) A. F 检验法 C. 图形法 E. DW 检验法B. White 检验法 D. ARCH 检验法F. Goldfeld-Quandt 检验法2D. R 有可能大于 R22 5、对多元线性回归方程的显著性检验,所用的 F 统计量可表示为( B E )A.ESS (n - k ) RSS (k - 1) R 2B.C.(1- R ) (k -1)R 2 (k -1) (n - k ) 2 D.ESS (k - 1)RSS (n -k )ESSRSS (n - k )E.2(1- R ) (n - k )三、判断题(判断下列命题正误,并说明理由)1、在对参数进行最小二乘估计之前,没有必要对模型提出古典假定。
大学专业课-计量经济学-A卷-试卷及答案

REV does not Granger Cause GDP
26
3.17904
0.12663
GDP does not Granger Cause REV
1.84105
0.17907
根据上述输出结果,对REV和GDP进行Granger因果关系分析(显著性水平为0.05)
2.(5分)观察下列输出结果,分析变量间出现了什么问题?如何解决该问题?
A.F=1 ; B. F=0; C. F=-1 D. F=∞
5.判定系数r2=0.7,说明回归直线能解释被解释变量总变差的:( )
A.30% B.70% C.64% D.49%
6.DW的取值范围是:( )
A.-1≤DW≤0 B.-1≤DW≤1 C.-2≤DW≤2 D.0≤DW≤4
7.设个人消费函数 中,消费支出Y不仅与收入X有关,而且与消费者的性别、年龄构成有关,年龄构成可以分为老、中、青三个层次,假定边际消费倾向不变,该消费函数引入虚拟变量的个数为( )
Variable
Coefficient
Std. Error
t-Statistic
Prob.
T
0.195181
0.004367
44.69628
0.0000
C
4.887978
0.059875
81.63659
0.0000
R-squared
0.989598
Mean dependent var
7.230146
假定3无自相关假定,两个误差项之间不相关。即cov (ui,uj)=0i≠j。
这里,cov表示协方差,i和j表示任意的两个误差项。(如果I=j,则上式就给出了的方差的表达式)。无自相关假定表明误差项ui是随机的。
计量经济学期末考试A卷参考答案

《计量经济学》课程期末考试试卷参考答案及评分标准卷别: A 卷一、名词解释题(每小题 2 分,共 10 分)1、Time Series Data(时间系列数据):A time series is a set of observations on the values that a variable takes at different times. (3分)2. Unbiasedness(无偏性):The estimator of β, say^β, is said to be unbiased if its average or expected value, ^()E β, is equal to the true value of, β. (3分)3. Goodness of Fit(拟合优度): A measure of how “well ” the sample regression line fits the data. (3分)4. Point Estimator(点估计量):The estimator ^θ is said to be point estimator if it provides a single (point) estimate of θ. (2分) 5. Type Ⅰ Error (Ⅰ类错误): Reject the Null Hypothesis when it is, in fact, true. (3分)二、问答题(每小题 5分,共 20 分)1. Assumptions underline the method of least squares.(1) ()0E u = (1分)(2) 2(')E uu I σ= (1分)(3) X is non-stochastic (1分)(4) ()Rank X K n =< (1分)(5) 2(0,)u N I σ (1分)2. Given the assumptions of CLRM, the OLS estimators are best, linear, unbiased estimators (BLUE). (5分)3.(每空0.5分)4. ˆ1,025.3260.3215YX =-+ (2分) se= (257.5874) (0.0399) 2r =0.8775 (3分)三、证明题(第一小题5分,第二小题5分,第三小题15分,共 25 分)1. Prove: 111ˆ(')'(')'()(')'()X X X y X X X X u X X X u Linearity βββ---==+=+⇒ (5分) 2. Prove:111ˆ(')'ˆ()()[(')']ˆ()(')'()ˆ()()X X X u E E E X X X u E X X X E u E Unbiasedness ββββββββ---=+⇒=+⇒=+⇒=⇒ (5分)3. Prove:111112121ˆˆˆ()[()()'][(')''(')](')'(')(')(')'(')(')n V E E X X X uu X X X X X X E uu X X X X X X I X X X X X βββββσσ-------=--==== (2分)Linearity of ˆβ⇒111ˆ(')'(')'()(')'X X X y Ay X X X X u X X X u Au ββββ---===+=+=+ where, 1(')'A X X X -= (1分)Consider any other linear estimator say()Cy C X u ββ==+ That is also unbiased so()()()()()I E E Cy E CX Cu E CX E Cu CX ICX Cu Cuββββββββ==⇒+=+=⇒=⇒=+=+(2分)22()[()()']['](')''nI V E E Cuu C C E uu C CC σβββββσ=--===* (2分)To relate ()V β to ˆ()V β, let 11(')'(')'ˆK nD C A C X X X C D X X X Dy ββ-⨯-=-=-=+-= (2分)and recall that11((')')(')'0CX ID X X X X IDX X X X X IDX --=⇒+=⇒+=⇒= (2分)Replace C in * by 1(')'D X X X -+ and use 0DX = 22112212()'((')')((')')'ˆ'(')'()ˆ()()non negative definiteV CC D X X X D X X X DD X X DD V V V βσσσσσβββ-----==++=+=+⇒ (4分)ˆβ⇒ has minimum variance. 四、综合应用题(第一小题 15 分,第二小题25分,共 40分)1.(1)11223344i i i i i i Q QT QT QT South u αββββ=+++++ (4分)Where i Q represents quantity of car sold. 1i QT to 3i QT captures the factors of quarters. 4i South is adummy represent the regions in the country. i u is the random disturbance captures the factors that affectquantity of cars sold but out of the model.1i QT =1 if the quantity of cars sold in quarter 1=0 otherwise2i QT =1 if the quantity of cars sold in quarter 2=0 otherwise3i QT =1 if the quantity of cars sold in quarter 3=0 otherwise4i South =1 if the quantity of cars sold in the South of the country=0 otherwise(2) I use three dummy variables to represent the four quarters in a year and one dummy to represents the tworegions in a country. We can only introduce m-1 dummy variables if a qualitative variable has m categories.(4分)(3) If I use 4 dummy variables to indicate 4 quarters in a year and also an intercept in the model, perfectcollinearity would be result. However, if I use 4 dummy variables in absence of intercept, nothing will happen.(4分)(4) Quantity of cars sold in north in quarter 4. (3分)2.(1)(5分)ˆ3840.832.163423211.713328.696676.128435487.75243s l e e p t o t w r k e d u c a g e a g e s q m a l =---++ t= (16.34) (-9.01) (-2.00) (-0.78) (0.96) (2.56)P=(0.000) (0.000) (0.046) (0.438) (0.338) (0.011)2706,.1228n R ==(2)(5分) keep other constant, as number of totwrk increased by 1, the sleep will decrease by .163 minutes;keep other constant, as a person receive 1 more years of schooling, he tends to sleep about 11 min less per week; keep other constant, as people get 1 year older, he tends to sleep about 9 min less per week; keep other constant,a male tends to sleep 88 min more than female per week.(3) (5分)01:0H β= 1:0a H β≠Since the estimated 1β is -.1634 is located in the 95% confidence interval (-.199,-.128), therefore reject 0Hand conclude that totwrk significantly affects child ’s education at 95% confidence interval.(4) (5分)012345:0H βββββ==== :a H Not all slope coefficients are simultaneously 0Since P=0.000 for the test, thus reject 0H and conclude that not all slope coefficients are simultaneously 0.(5) (5分)2.1228R = means that about 12 percent of the variation in the sleep time per week is explained bytotwrk, educ,age, agesq,male.。
计量经济学试题及答案

计量经济学试题及答案(I )第一部分选择题一、单项选择题(本大题共30小题,每小题1分,共30分)在每小题列出的四个选项中只有一个选项是符合题目要求的,请将正确选项前的字母填在题后的括号内。
1 .对联立方程模型进行参数估量的方法可以分两类,即:( )A.间接最小二乘法和系统估量法B.单方程估量法和系统估量法C.单方程估量法和二阶段最小二乘法D.工具变量法和间接最小二乘法2 .当模型中第i 个方程是不行识别的,则该模型是( )A.可识别的B.不行识别的C.过度识别D .恰好识别3 .结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( )A.外生变量B.滞后变量C.内生变量D.外生变量和内生变量4 .己知样本回归模型残差的一阶自相关系数接近于-1,则DW 统计量近似等于( ) A.0B.lC.2D.45 .假设回归模型为其中Xi 为随机变量,Xi 与Ui 相关则的一般最小二乘估量量( )A.无偏且全都B.无偏但不全都C.有偏但全都D.有偏且不全都6 .假定正确回归模型为,若遗漏了解释变量X2,且XI 、X2线性相关则的一般最小二乘法估量量()B.无偏但不全都C.有偏但全都D.有偏且不全都7 .对于误差变量模型,模型参数的一般最小二乘法估量量是( )A.无偏且全都的B.无偏但不全都C.有偏但全都 8 .戈德菲尔德-匡特检验法可用于检验( )A.异方差性B.多重共线性C.序列相关9 .对于误差变量模型,估量模型参数应采纳( )A.一般最小二乘法B.加权最小二乘法C.广义差分法10 .设无限分布滞后模型满意koyck 变换的假定,则长期影响乘数为()A.B.C.D.IL 系统变参数模型分为( )A.截距变动模型和斜率变动模型B.季节变动模型和斜率变动模型C.季节变动模型和截距变动模型D.截距变动模型和截距、斜率同时变动模型 12.虚拟变量()A.主要来代表质的因素,但在有些状况下可以用来代表数量因素B.只能代表质的因素C.只能代表数量因素A.无偏且全都D.有偏且不全都 D.设定误差 D.工具变量法D.只能代表季节影响因素 13.单方程经济计量模型必定是()A.行为方程B.政策方程C.制度方程D.定义方程14用于检验序列相关的DW 统计量的取值范围是()A.O≤DW≤1B.-1≤DW≤1C.-2≤DW≤2D.0≤DW≤415 .依据判定系数R2与F 统计量的关系可知,当R2=l 时有( )A.F=1B.F=-∣C.F=∞D.F=O16 .在给定的显著性水平之下,若DW 统计量的下和上临界值分别为dL 和du,则当dL<DW<du时,可认为随机误差项()A.存在一阶正自相关B.存在一阶负相关C .不存在序列相关D.存在序列相关与否不能断定17 .设P 为总体相关系数,I •为样本相关系数,则检验H:P=O 时,所用的统计量是()A. C.18 .经济计量分析的工作程序(19 .设k 为回归模型中的参数个数,n 为样本容量。
计量经济学练习题带答案版
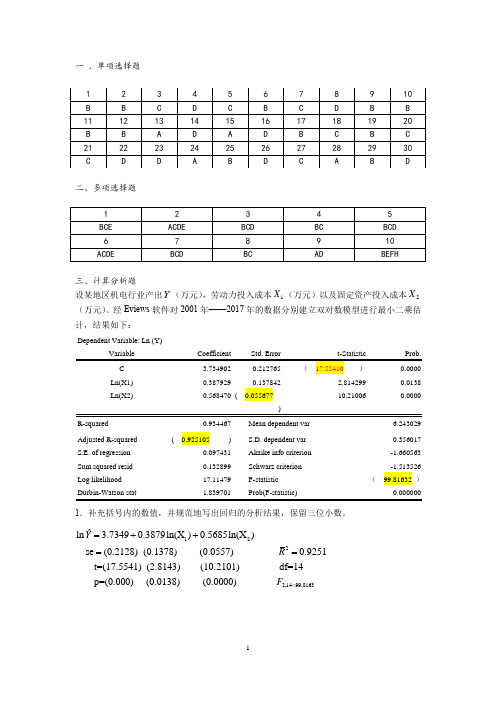
一 、单项选择题二、多项选择题三、计算分析题设某地区机电行业产出Y (万元),劳动力投入成本1X (万元)以及固定资产投入成本2X (万元)。
经Eviews 软件对2001年——2017年的数据分别建立双对数模型进行最小二乘估计,结果如下:Dependent Variable: Ln (Y)Ln(X1) 0.3879290.1378422.814299 0.0138 Ln(X2)0.568470 ( 0.05567710.210060.0000R-squared 0.934467 Mean dependent var6.243029 Adjusted R-squared ( 0.925105 ) S.D. dependent var0.356017 S.E. of regression 0.097431 Akaike info criterion -1.660563 Sum squared resid 0.132899 Schwarz criterion -1.513526 Log likelihood 17.11479 F-statistic ( 99.81632 )1.补充括号内的数值,并规范地写出回归的分析结果,保留三位小数。
122ˆln 3.73490.3879ln(X )0.5685ln(X ) se (0.2128) (0.1378) (0.0557) 0.9251t=(17.5541) (2.8143) (10.2101) df=14 p=(0.000) (0.0138)Y R =++==2,1499.8163(0.0000) F =2. 对模型的估计结果进行偏回归系数和整体显著性检验。
(t0.025(14)=2.145;t0.025(15)=2.131;F0.05(2,14)=3.74;F0.05(3,14)=3.34)。
(注意运用临界值法!!)样本量为17,临界值选取t0.025(14)=2.145F临界值选取F0.05(2,14)=3.743. 如果有两种可供选择的措施以提高机电行业产出,措施一是加大劳动力的投入,措施二是增大固定资产的投入,你认为哪个措施效果更明显,为什么?选择措施二,因为劳动力成本增长1个百分点,机电行业产增长0.39个百分点,而固定资产投入成本增长1个百分点,机电行业销售额仅增长0.57个百分点四、分析题根据我国31个细分制造业的数据,得到生产函数的如下估计结果:ln(Ŷi)=1.168+0.37ln(K i)+0.61ln(L i)se= (0.331) ( a) (0.1293)t= (3.53) ( 4.23) ( b )R2=0.94其中,Y为总产出,K为资本投入,L为劳动投入。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
东北财经大学研究生期末考试试题课程名称:初级计量经济学类别:□必修□选修年级:2013级开课学院:数学与数量经济学院一、判断正误(每小题1分,共10分。
请将正确的答案填在下面对应的空格内,正确用T表示,错误用F表示)1.总体回归函数给出了与自变量每个取值相应的应变量的值。
错、应该是条件均值2.普通最小二乘法就是使误差平方和最小化的估计过程。
错误,残差平方和3.对数线性回归模型和双对数模型的判决系数可以相比较。
正确4.多元线性回归模型的总体显著性意味着模型中任何一个变量都是统计显著的。
错,5.在线性回归模型中解释变量是原因,被解释变量是结果。
错6.双对数模型的回归系数和弹性系数相同。
正确7.当存在自相关时,OLS估计量既是有偏的也是无效的。
错,无偏、线性8.在高度多重共线性情况下,估计量的标准误差减小,t值增大。
错,说反了9.如果分析的目的仅仅是为了预测,则多重共线性并无大碍。
正确10.无论模型中包括多少个解释变量,总平方和的自由度总为n-1。
正确二、填空题(每小题1分,共10分。
把正确答案填在空格内)。
1. 当回归系数t 统计量的绝对值大于给定的临界值时,表明该系数 显著 。
2.线性回归模型意味着模型中 参数 是线性的。
3.高斯马尔科夫定理说明如果线性回归模型满足古典假设,则OLS 估计量具有 最小方差 性。
即最优线性无偏性BLUE.4.多元回归的总体显著性检验的原假设为 02=R 。
5.如果对于二元线性回归模型在样本容量为11时有4500,90TSS RSS ==,则其校正的 判决系数=2R ()45442-11111504911k -n 1n 112=-⎪⎭⎫ ⎝⎛--=---R。
6.模型12ln t t y B B t u =++的参数2B 表示 t 的绝对量增加一个单位时,y 的相对量增加B2个单位 。
7. 倒数 模型最适合用来描述恩格尔消费曲线 。
8.在多元回归模型中较高的2R 值与多个不显著的t 值并存,表明模型可能存在 多重共线性 。
9 自相关 。
10.在分析季度数据的季节性时需要引入 3 个虚拟变量。
M-1 三、简答题(共15分)1、 简述经济计量分析的基本步骤。
(8分) 1.理论分析; 2.收集数据; 3.建立数学模型;4.建立统计或经济计量模型;5.经济计量模型的参数估计;6.检查模型的准确性;7.检验来自模型的假说;8.运用模型进行预测;2、以双变量线性回归模型为例简述普通最小二乘原理,并写出双变量线性回归模型参数的最小二乘估计量。
(7分)普通最小二乘法原理:残差平方和最小由随机样本回归函数:Yi=b1+b2Xi+ei 来估计总体回归函数:Yi=B1+B2Xi+μi 的一种方法。
它估计总体回归函数的原理是:选择B1,B2的估计量b1,b2,使得残差ei 尽可能的小(ei=iiY Y ˆ-(样本函数b1+b2xi))。
残差ei 的定义为ei=实际的Yi - 估计的Yi= Yi - Yˆ = Yi - b1- b2Xi OLS 估计过程的数学形式表示为:∑∑∑--=-=22122)()ˆ(:m ini ii ii X b b YY Ye 应用微积分求极值的方法,可得下面方程组,称为正规方程组,∑∑∑∑∑+=+=22121iiiiii Xb X b X Y Xb nb Y进一步可求得∑∑=-=2221iii xy x b X b Y b即最小二乘估计量i x =Xi-X i y = Yi- Y 即小写字母代表了变量与其均值之间的偏差四、(15分)如果考虑用居民的可支配收入INCOME (元),贷款购车的贷款利率R (%),汽油的价格P (元)来解释汽车的销售额SALE (万元),估计得到如下方程:96.0209)012.0()00041.0()035.0()32.0()ln(11.00017.0)ln(28.068.5)ˆln(2==--=--+=R n se P R INCOME LE AS如果给定显著性水平0.05α=,单边临界值为0.05 1.645t =,0.05 2.65F =。
回答:1. 方程中回归系数的含义(3分)0.28表示汽车销售额对居民可支配收入的弹性-0.0017表示贷款购车的贷款利率变动一个单位,汽车销售额的相对量变动0.0017单位 -0.11表示汽车的销售额对汽油的价格的弹性2. 利用显著性检验法检验每个回归系数的显著性。
(6分)对于回归系数0.28的显著检验,t 值为0.28/0.035=8>0.05 1.645t =,系数显著对于回归系数-0.0017的显著检验,t 值为0.0017/0.00041=4.14>0.05 1.645t =,系数显著 对于回归系数-0.11的显著检验,t 值为0.11/0.012=9.16>0.05 1.645t =,系数显著3. 如何检验自变量一起对汽车的销售额SALE 有显著的解释能力?请写出原假设及检验过程。
(注2211n k R F k R-=--)(4分) 020=R H 时为零,或:所有的偏斜率系数同对于总体显著性检验一般用F 检验,首先计算出F 值,2211n k R F k R -=--=164096.0-196.01-44-209=>0.05 2.65F =,拒绝原假设,所以,自变量一起对汽车的销售额SALE 有显著的解释能力。
4.你是否会在汽车销售额预测模型中包括汽油价格P 这一变量?为什么?(2分)会的,因为汽油和汽车属于互补商品,两者之间有较强的相互关系,因此模型应该包括此重要的变量。
五、(10分)下面的模型研究的是金融业,消费品行业、公用事业和交通运输业等四个行业的CEO 薪水SALARY 和企业年销售额SALE ,股本回报率ROE 的关系。
估计的方程为:·()()()()()()1232log() 4.590.26log()0.0110.160.180.28 0.32 0.035 0.004 0.089 0.085 0.099209,0.49SALARY SALE ROE D D D se n R =++++-=== 其中11D =表示金融业,21D =表示消费品行业,31D =表示公用事业。
根据问题回答: 1.本模型的基准类是什么?(1分) 交通运输业2.为什么模型中没有引用4个虚拟变量来表示4个行业?(1分)为了避免出现多重共线性,应引入m-1个虚拟变量3.解释模型中虚拟变量系数的含义?哪个行业的CEO 的薪水最少?(2分) 0.16表示金融业的平均CEO 薪水比交通运输业高 0.18表示消费品行业的平均CEO 薪水比交通运输业高 -0.28表示公用事业的平均CEO 薪水比交通运输业低 公用事业最少4.虚拟变量系数都是统计显著的,这表示什么含义?你如何解释行业间CEO 薪水存在的这种显著差异?(3分)表示虚拟变量设置合理, 不同行业的效益不一样六、(15分)利用EViews 软件以2004年全国31个省市自治区的农业总产值Y (亿元)和农作物播种面积X (万亩)的数据为样本估计一元线性回归模型μ++=X B B Y 10,并对其进行怀结论?(4分)注意:此检验是针对异方差的检验。
原假设:不存在异方差 说明存在异方差2.当模型存在上述问题时将出现那些后果?(4分)即异方差的后果:必须知道 第一,OLS 估计量让然是线性的,无偏的第二,OLS 估计量不具有最小方差性,即不再是有效的,不再是BLUE 了第三,OLS 估计量的方差通常情况是有偏了,因为OLS 估计量可能会高估或者低估其方差 第四,建立在t 分布和F 分布的假设检验与置信区间不在可靠了。
因此往往寻找其他的检验方法,例如本题的怀特检验第五,由于以上四条的存在,往往导致模型预测精度下降甚至失效。
3.解决该问题的办法是什么?(2分)解决异方差的方法一般有:加权最小二乘法WLS (对模型进行加权,一般是所有变量除以i σ,是模型变成一个不存在异方差的模型,然后就可以再次使用OLS 估计其系数了),注意此方法是在i2σ已知的情况下,当i2σ未知时,通过观察误差项与i X 的关系或者与2i X 的关系来进行变换如果以上方法仍然解决不掉异方差,换一个模型试试吧,即重新设定模型4.如果通过检验知道,X E i 22)(σμ=,则如何进行修正?写出修正的步骤。
(5分)一般是方程各项除以X , 平方根变换XS P X X B X B X Y X B B Y i i μυυμ=---++=++=..11010七、(共25分)利用1970—1987年的纽约股票交易所的综合指数(Y )和美国GNP (X )的数据,对综合指数和国内生产总值之间的对数线性模型进行估计,具体结果如下:Dependent Variable: LOG(Y) Method: Least Squares Date: 03/11/07 Time: 16:48 Sample: 1970 1987 Included observations: 18VariableCoefficientStd. Error t-Statistic Prob.LOG(X) 0.652319 0.103454 6.305383 0.0000 C-0.8090620.80027-1.0109820.3271R-squared0.713045 Mean dependent var 4.227425 Adjusted R-squared 0.695110 S.D. dependent var 0.377945 S.E. of regression 0.208689 Akaike info criterion -0.191499 Sum squared resid 0.696821 Schwarz criterion -0.092569 Log likelihood 3.723495 F-statistic 39.75785 Durbin-Watson stat0.448152 Prob(F-statistic)0.000010(1) 根据以上结果,写出回归分析结果报告?(4分)LOG(Y)=-0.809062+0.652319LOG(X)S.e (0.103454) (0.80027)T (6.305383) (-1.010982)0.7130452=R F=39.75785(2)该模型是否存在自相关?为什么?(3分)存在正的自相关,因为 D.W.=0.448152,n=18,k=2 在5%的显著水平下1.535d 1.046d u L ==, d=0.448< 1.046d L =(3)自相关会给模型带来哪些后果?(4分)自相关的后果, 第一,OLS 估计量是线性的,无偏的 第二,OLS 估计量不再是有效的,第三,OLS 估计量的方差有偏的,通常是低估呀,这个一般考个选择题,不要和异方差搞混了 第四,t 检验和f 检验不再是有效的, 第五,2R 不能测度真实的2R第六,误差方差是真实的有偏估计量,原因是由于第三 第七,预测失效(4)在通常使用D —W 统计量需要有那些基础假设?(5分)p240 第一,回归模型应该包括截距项,过原点的回归模型第二,变量x 是非随机变量,即再重复抽样中,变量x 取值固定第三,扰动项生成机制t 1-t t u u υρ+= -1《ρ《1 其中vt 是满足古典假定的随机误差项。