哈夫曼编码步骤
哈夫曼编码过程

哈夫曼编码过程介绍在计算机科学中,哈夫曼编码是一种使数据能够有效压缩和传输的算法。
它是一种无损压缩算法,能够将原始数据以最小的比特数表示。
哈夫曼编码由大卫·哈夫曼于1952年提出,从此成为数据压缩领域的重要算法之一。
原理哈夫曼编码的原理基于两个关键思想:频率越高的字符用更小的比特表示,频率越低的字符用更大的比特表示。
这样可以确保编码后的字符串具有唯一可识别性。
哈夫曼编码是通过构建哈夫曼树来实现的,具体步骤如下:1.统计每个字符在原始数据中出现的频率;2.根据字符频率构建哈夫曼树;3.根据哈夫曼树为每个字符生成对应的编码表;4.使用编码表将原始数据进行编码;5.将编码后的数据进行传输或存储。
构建哈夫曼树构建哈夫曼树的过程涉及到两个基本概念:结点和权值。
在哈夫曼树中,每个字符被表示为一个叶子结点,而非叶子结点的权值则代表了字符的频率。
构建哈夫曼树的步骤如下:1.将每个字符及其频率放入一个优先队列中,按照频率从小到大排列;2.从优先队列中取出两个权值最小的结点,将它们合并为一个新的结点,权值为两个结点的权值之和;3.将新结点插入优先队列中;4.重复步骤2和3,直到优先队列中只剩下一个结点,即为构建好的哈夫曼树。
生成编码表生成编码表的过程是通过遍历哈夫曼树来实现的。
步骤如下:1.从根结点开始,沿着左子树遍历到叶子结点,并在路径上添加比特’0’到编码表;2.回溯到上一个结点,遍历右子树,并在路径上添加比特’1’到编码表;3.重复步骤1和2,直到遍历完整个哈夫曼树。
编码过程有了编码表,就可以将原始数据进行编码。
步骤如下:1.从原始数据中取出一个字符;2.根据编码表找到该字符对应的比特序列,并将其添加到编码后的字符串中;3.重复步骤1和2,直到将所有字符编码为比特序列。
解码过程解码过程是将编码后的字符串重新还原为原始数据的过程。
解码过程依赖于编码表和哈夫曼树。
步骤如下:1.从编码后的字符串中取出比特序列;2.从根结点开始,按照比特序列的值向下遍历哈夫曼树;3.如果遇到叶子结点,就输出对应的字符,并返回到根结点;4.重复步骤2和3,直到将所有比特序列解码为字符。
哈夫曼编码的方法

1.哈夫曼编码的方法编码过程如下:(1) 将信源符号按概率递减顺序排列;(2) 把两个最小的概率加起来, 作为新符号的概率;(3) 重复步骤(1) 、(2), 直到概率和达到1 为止;(4) 在每次合并消息时,将被合并的消息赋以1和0或0和1;(5) 寻找从每个信源符号到概率为1处的路径,记录下路径上的1和0;(6) 对每个符号写出"1"、"0"序列(从码数的根到终节点)。
2.哈夫曼编码的特点①哈夫曼方法构造出来的码不是唯一的。
原因·在给两个分支赋值时, 可以是左支( 或上支) 为0, 也可以是右支( 或下支) 为0, 造成编码的不唯一。
·当两个消息的概率相等时, 谁前谁后也是随机的, 构造出来的码字就不是唯一的。
②哈夫曼编码码字字长参差不齐, 因此硬件实现起来不大方便。
③哈夫曼编码对不同的信源的编码效率是不同的。
·当信源概率是2 的负幂时, 哈夫曼码的编码效率达到100%;·当信源概率相等时, 其编码效率最低。
·只有在概率分布很不均匀时, 哈夫曼编码才会收到显著的效果, 而在信源分布均匀的情况下, 一般不使用哈夫曼编码。
④对信源进行哈夫曼编码后, 形成了一个哈夫曼编码表。
解码时, 必须参照这一哈夫编码表才能正确译码。
·在信源的存储与传输过程中必须首先存储或传输这一哈夫曼编码表在实际计算压缩效果时, 必须考虑哈夫曼编码表占有的比特数。
在某些应用场合, 信源概率服从于某一分布或存在一定规律使用缺省的哈夫曼编码表有解:为了进行哈夫曼编码, 先把这组数据由大到小排列, 再按上方法处理(1)将信源符号按概率递减顺序排列。
(2)首先将概率最小的两个符号的概率相加,合成一个新的数值。
(3)把合成的数值看成是一个新的组合符号概率,重复上述操作,直到剩下最后两个符号。
5.4.2 Shannon-Famo编码Shannon-Famo(S-F) 编码方法与Huffman 的编码方法略有区别, 但有时也能编出最佳码。
简述哈夫曼编码的过程

简述哈夫曼编码的过程哈夫曼编码是一种常见的压缩算法,通过对源数据进行编码,使得数据所占用的位数变得更小,从而达到压缩的目的。
它的原理是根据出现频率较高的字符使用较短的编码来代替,而出现频率较低的字符用较长的编码来代替。
哈夫曼编码实现的过程可以分为三个步骤:统计字符的频率、构建哈夫曼树、生成编码表。
下面我们分别来详细看一下各个步骤。
1. 统计字符的频率在实现哈夫曼编码前,需要先统计出每种字符在源数据中出现的次数。
假设源数据是一段文本,通过扫描文本并记录每个字符出现的次数,可以得到一个字符频率的统计表,一般用数组来存储。
2. 构建哈夫曼树在统计出每个字符的频率后,需要将其构建成一棵哈夫曼树。
哈夫曼树实质上是一种优先级队列,每个节点都有一个权重(频率),根据权重从小到大构建成树,树的叶子节点是每个字符,其它节点是合并后的节点,每个节点的权重是该子树所有节点的权重之和。
构建哈夫曼树的过程可以简单描述为:将每个字符看做一棵树,将权重最小的两个树合并成一个树,合并后的树的权重是它们两个权重之和,然后将这个新的树插入到队列中。
不断重复这个合并的过程,直到队列中只剩下一棵树为止。
3. 生成编码表生成编码表的过程就是将哈夫曼树转换为每个字符的哈夫曼编码。
哈夫曼编码的特点是任何一个字符的编码都不是另一个字符的前缀,即没有一个字符的编码是另一个字符编码的前缀,这就使得哈夫曼编码可以通过前缀的方式来压缩数据。
生成编码表的过程可以通过遍历哈夫曼树的叶子节点得到每个字符的编码。
至此,我们已经完成了哈夫曼编码的整个过程。
通过使用哈夫曼编码,可以将源数据压缩成更小的字节流,从而节省存储空间和传输数据的时间。
它广泛应用于数据压缩和加密解密等领域。
哈夫曼编码简单例题

哈夫曼编码简单例题哈夫曼编码是一种用于编码数据的算法,它使用变长编码来把数据进行压缩编码。
哈夫曼编码基于一系列数学模型,以及相关编码字符的出现频率,为数据提供一种有效的编码模式,能够做到节省存储空间和传输时间。
关于哈夫曼编码,最简单的例题可能就是一张字典,比如下面这样:字符t出现频率At0.45Bt0.13Ct0.12Dt0.09Et0.08Ft0.07Gt0.07对于上面的字典,使用哈夫曼编码的步骤如下:第一步:将出现频率转换为权值,即将每个字符的出现频率转化为整数,并构建权值树。
At45Bt13Ct12Dt9Et8Ft7Gt7第二步:合并权值最小的两个字符,以及更新权值树:At45Bt13Ct12Dt9Et8F,Gt7第三步:给每个字符赋予编码,并将它们添加到哈夫曼编码表中。
在这里,A是编码中最长的字符,所以它将拥有最多的编码位0,而F和G是编码中最短的字符,它们共享最少的编码位1,最终得出的编码表如下:At0Bt100Ct101Dt1100Et1101F,Gt11第四步:编码字符串:接下来我们来编码一个字符串,比如“ABCDE”,根据上面的哈夫曼编码表,我们可以将每个字符的编码连接起来,最终得到一个01串“00010111001101”,这就是ABCDE 的哈夫曼编码。
可以看出,使用哈夫曼编码能够大大节省编码所需要的空间,使得传输和存储都变得更加有效率。
此外,由于哈夫曼编码可以获得更高的编码效率,因此它在数据编码领域受到了广泛的应用。
它已成为许多数据压缩、传输、存储标准的基础,比如说JPEG图像、MPEG视频和ICMP协议等。
由于哈夫曼编码是一种节省空间并增加传输效率的编码方式,它在许多行业中得到了广泛的应用,比如说在媒体、电信、计算机和安全等行业都有广泛的应用。
它能够压缩数据以节省传输时间和空间,同时保持数据的完整性。
此外,哈夫曼编码也被应用在视频编解码、数据压缩、网络通信协议等场景,发挥着重要作用。
c语言哈夫曼树的构造及编码

c语言哈夫曼树的构造及编码一、哈夫曼树概述哈夫曼树是一种特殊的二叉树,它的构建基于贪心算法。
它的主要应用是在数据压缩和编码中,可以将频率高的字符用较短的编码表示,从而减小数据存储和传输时所需的空间和时间。
二、哈夫曼树的构造1. 哈夫曼树的定义哈夫曼树是一棵带权路径长度最短的二叉树。
带权路径长度是指所有叶子节点到根节点之间路径长度与其权值乘积之和。
2. 构造步骤(1) 将待编码字符按照出现频率从小到大排序。
(2) 取出两个权值最小的节点作为左右子节点,构建一棵新的二叉树。
(3) 将新构建的二叉树加入到原来排序后队列中。
(4) 重复上述步骤,直到队列只剩下一个节点,该节点即为哈夫曼树的根节点。
3. C语言代码实现以下代码实现了一个简单版哈夫曼树构造函数:```ctypedef struct TreeNode {int weight; // 权重值struct TreeNode *leftChild; // 左子节点指针struct TreeNode *rightChild; // 右子节点指针} TreeNode;// 构造哈夫曼树函数TreeNode* createHuffmanTree(int* weights, int n) {// 根据权值数组构建节点队列,每个节点都是一棵单独的二叉树TreeNode** nodes = (TreeNode**)malloc(sizeof(TreeNode*) * n);for (int i = 0; i < n; i++) {nodes[i] = (TreeNode*)malloc(sizeof(TreeNode));nodes[i]->weight = weights[i];nodes[i]->leftChild = NULL;nodes[i]->rightChild = NULL;}// 构建哈夫曼树while (n > 1) {int minIndex1 = -1, minIndex2 = -1;for (int i = 0; i < n; i++) {if (nodes[i] != NULL) {if (minIndex1 == -1 || nodes[i]->weight < nodes[minIndex1]->weight) {minIndex2 = minIndex1;minIndex1 = i;} else if (minIndex2 == -1 || nodes[i]->weight < nodes[minIndex2]->weight) {minIndex2 = i;}}}TreeNode* newNode =(TreeNode*)malloc(sizeof(TreeNode));newNode->weight = nodes[minIndex1]->weight + nodes[minIndex2]->weight;newNode->leftChild = nodes[minIndex1];newNode->rightChild = nodes[minIndex2];// 将新构建的二叉树加入到原来排序后队列中nodes[minIndex1] = newNode;nodes[minIndex2] = NULL;n--;}return nodes[minIndex1];}```三、哈夫曼编码1. 哈夫曼编码的定义哈夫曼编码是一种前缀编码方式,它将每个字符的编码表示为二进制串。
哈夫曼编码计算

哈夫曼编码是一种根据字符出现频率创建的编码方式,其中频率高的字符使用较短的编码,频率低的字符使用较长的编码。
以下是计算哈夫曼编码的步骤:
1. 创建一个森林,每个字符出现频率作为一棵树的权值,每个树只有一个节点。
2. 从森林中取出两棵权值最小的树,合并它们,生成一棵新的树。
新树的权值是这两棵树的权值之和,左子树是原来的左树,右子树是原来的右树。
3. 将新生成的树放回森林中。
4. 重复步骤2和3,直到森林中只剩下一棵树为止,这棵树就是哈夫曼树。
5. 哈夫曼编码是从哈夫曼树的根节点到叶节点的路径,按照从左到右的顺序,用0和1表示路径的方向。
举个例子,假设我们有4个字符(a、b、c、d),它们的出现频率分别为1、2、3、4。
根据这些频率,我们可以建立以下森林:
1. a -> 1
2. b -> 2
3. c -> 3
4. d -> 4
然后,我们按照上述步骤合并权值最小的两个节点,生成新的节点,并反复进行这个过程,直到得到一棵只有根节点的树。
最后,从根节点到每个叶节点的路径就是每个字符的哈夫曼编码。
需要注意的是,哈夫曼编码是一种无损压缩算法,它不会丢失原始数据的信息。
但是,它并不适用于所有情况,特别是当字符出现频率相差很大时,哈夫曼编码的效果可能会受到影响。
哈夫曼编码与解码

哈夫曼编码与解码
哈夫曼编码(Huffman coding)和哈夫曼解码(Huffman decoding)是一种用于数据压缩的技术,由美国计算机科学家 David A. Huffman 于 1952 年提出。
哈夫曼编码的基本思想是根据字符在文本中出现的频率来分配二进制编码的长度。
出现频率较高的字符将被分配较短的编码,而出现频率较低的字符将被分配较长的编码。
这样,通过使用较短的编码来表示常见字符,可以实现更有效的数据压缩。
哈夫曼编码的过程包括以下步骤:
1. 统计字符出现频率:对要编码的文本进行分析,统计每个字符出现的次数。
2. 构建哈夫曼树:根据字符出现频率构建一棵二叉树,其中频率较高的字符靠近树的根节点,频率较低的字符位于树的叶子节点。
3. 分配编码:从根节点开始,根据字符出现频率为每个字符分配二进制编码。
左子节点表示 0,右子节点表示 1。
4. 编码文本:将文本中的每个字符替换为其对应的哈夫曼编码。
哈夫曼解码是哈夫曼编码的逆过程,用于将已编码的数据还原为原始文本。
解码过程根据哈夫曼树的结构和编码规则,从编码中解析出原始字符。
哈夫曼编码与解码在数据压缩领域具有广泛的应用,例如图像、音频和视频压缩。
它通过有效地利用字符频率分布的不均匀性,实现了较高的压缩率,从而减少了数据传输和存储的开销。
需要注意的是,哈夫曼编码是一种无损压缩技术,意味着解码后可以完全还原原始数据。
但在实际应用中,可能会结合其他有损压缩技术来进一步提高压缩效果。
哈夫曼编码证明
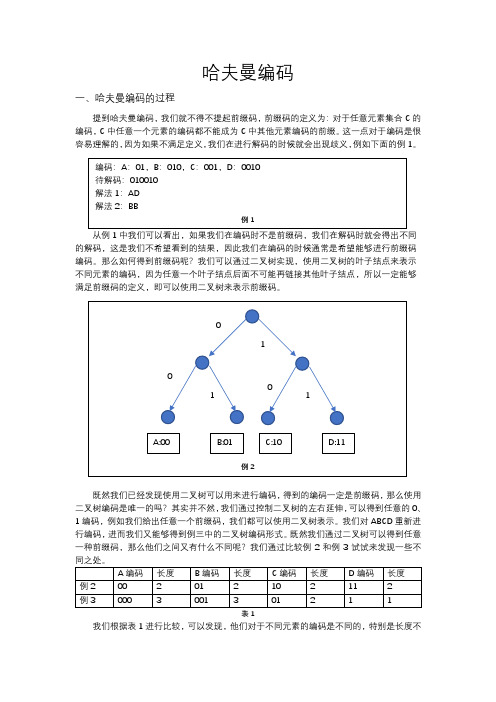
哈夫曼编码一、哈夫曼编码的过程提到哈夫曼编码,我们就不得不提起前缀码,前缀码的定义为:对于任意元素集合C的编码,C中任意一个元素的编码都不能成为C中其他元素编码的前缀。
这一点对于编码是很容易理解的,因为如果不满足定义,我们在进行解码的时候就会出现歧义,例如下面的例1。
从例1中我们可以看出,如果我们在编码时不是前缀码,我们在解码时就会得出不同的解码,这是我们不希望看到的结果,因此我们在编码的时候通常是希望能够进行前缀码编码。
那么如何得到前缀码呢?我们可以通过二叉树实现,使用二叉树的叶子结点来表示不同元素的编码,因为任意一个叶子结点后面不可能再链接其他叶子结点,所以一定能够满足前缀码的定义,即可以使用二叉树来表示前缀码。
既然我们已经发现使用二叉树可以用来进行编码,得到的编码一定是前缀码,那么使用二叉树编码是唯一的吗?其实并不然,我们通过控制二叉树的左右延伸,可以得到任意的0、1编码,例如我们给出任意一个前缀码,我们都可以使用二叉树表示。
我们对ABCD重新进行编码,进而我们又能够得到例三中的二叉树编码形式。
既然我们通过二叉树可以得到任意一种前缀码,那么他们之间又有什么不同呢?我们通过比较例2和例3试试来发现一些不表1我们根据表1进行比较,可以发现,他们对于不同元素的编码是不同的,特别是长度不同。
如果我们从存储角度来看,我们当然希望相同的A BCDA…元素集合尽量短,这样可以节省空间,这是与不同的编码方式有着很大的关系的,如果我们给出一个字符串:ABCD ,然后使用例2和例3中两种编码方式,这会发现例1:00011011(共占8位),例2:000001011(共占9位),那么就是例1更占有优势,但是我们也一定发现了,这里ABCD 都是仅仅出现了一次,所以这是不是也和出现频率有关呢?我们再给出一个字符串:ABCDDD ,然后使用例2和例3中两种编码方式,这会发现例1:000110111111(共占12位),例2:00000101111(共占11位),这时换成例2的编码方式更占有优势了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
哈夫曼编码步骤:一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F={T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。
(为方便在计算机上实现算法,一般还要求以Ti的权值Wi的升序排列。
)二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,直到集合F中只有一棵二叉树为止。
/*-------------------------------------------------------------------------* Name: 哈夫曼编码源代码。
* Date: 2011.04.16 * Author: Jeffrey Hill+Jezze(解码部分)* 在Win-TC 下测试通过* 实现过程:着先通过HuffmanTree() 函数构造哈夫曼树,然后在主函数main()中* 自底向上开始(也就是从数组序号为零的结点开始)向上层层判断,若在* 父结点左侧,则置码为0,若在右侧,则置码为1。
最后输出生成的编码。
*------------------------------------------------------------------------*/#include <stdio.h>#include<stdlib.h>#define MAXBIT 100#define MAXVALUE 10000#define MAXLEAF 30#define MAXNODE MAXLEAF*2 -1typedef struct {int bit[MAXBIT];int start;} HCodeType; /* 编码结构体*/typedef struct{int weight;int parent;int lchild;int rchild;int value;} HNodeType; /* 结点结构体*//* 构造一颗哈夫曼树*/void HuffmanTree (HNodeType HuffNode[MAXNODE], int n){/* i、j:循环变量,m1、m2:构造哈夫曼树不同过程中两个最小权值结点的权值,x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号。
*/int i, j, m1, m2, x1, x2;/* 初始化存放哈夫曼树数组HuffNode[] 中的结点*/for (i=0; i<2*n-1; i++){HuffNode[i].weight = 0;//权值HuffNode[i].parent =-1;HuffNode[i].lchild =-1;HuffNode[i].rchild =-1;HuffNode[i].value=i;//实际值,可根据情况替换为字母} /* end for *//* 输入n 个叶子结点的权值*/for (i=0; i<n; i++){printf ("Please input weight of leaf node %d: \n", i);scanf ("%d", &HuffNode[i].weight);} /* end for *//* 循环构造Huffman 树*/for (i=0; i<n-1; i++){m1=m2=MAXV ALUE;/* m1、m2中存放两个无父结点且结点权值最小的两个结点*/x1=x2=0;/* 找出所有结点中权值最小、无父结点的两个结点,并合并之为一颗二叉树*/ for (j=0; j<n+i; j++){if (HuffNode[j].weight < m1 && HuffNode[j].parent==-1) { m2=m1;x2=x1;m1=HuffNode[j].weight;x1=j;}else if (HuffNode[j].weight < m2 && HuffNode[j].parent==-1) {m2=HuffNode[j].weight;x2=j;}} /* end for *//* 设置找到的两个子结点x1、x2 的父结点信息*/HuffNode[x1].parent = n+i;HuffNode[x2].parent = n+i;HuffNode[n+i].weight = HuffNode[x1].weight + HuffNode[x2].weight; HuffNode[n+i].lchild = x1;HuffNode[n+i].rchild = x2;printf ("x1.weight and x2.weight in round %d: %d, %d\n", i+1, HuffNode[x1].weight, HuffNode[x2].weight);/* 用于测试*/printf ("\n");} /* end for *//*for(i=0;i<n+2;i++){printf("Parents:%d,lchild:%d,rchild:%d,value:%d,weight:%d\n",HuffNode[i].parent,HuffNode[i].l child,HuffNode[i].rchild,HuffNode[i].value,HuffNode[i].weight);}*///测试}/* end HuffmanTree *///解码void decodeing(char string[],HNodeType Buf[],int Num){int i,tmp=0,code[1024];int m=2*Num-1;char *nump;char num[1024]for(i=0;i<strlen(string);i++){if(string[i]=='0')num[i]=0;else num[i]=1;}i=0;nump=&num[0];while(nump<(&num[strlen(string)])){tmp=m-1;while((Buf[tmp].lchild!=-1)&&(Buf[tmp].rchild!=-1)){if(*nump==0){tmp=Buf[tmp].lchild ;}else tmp=Buf[tmp].rchild;nump++;}printf("%d",Buf[tmp].value);}}int main(void){HNodeType HuffNode[MAXNODE]; /* 定义一个结点结构体数组*/ HCodeType HuffCode[MAXLEAF], cd;/* 定义一个编码结构体数组,同时定义一个临时变量来存放求解编码时的信息*/int i, j, c, p, n;char pp[100];printf ("Please input n:\n");scanf ("%d", &n);HuffmanTree (HuffNode, n);for (i=0; i < n; i++){cd.start = n-1;c = i;p = HuffNode[c].parent;while (p != -1)/* 父结点存在*/{if (HuffNode[p].lchild == c)cd.bit[cd.start] = 0;elsecd.bit[cd.start] = 1;cd.start--;/* 求编码的低一位*/c=p;p=HuffNode[c].parent;/* 设置下一循环条件*} /* end while *//* 保存求出的每个叶结点的哈夫曼编码和编码的起始位*/ for (j=cd.start+1; j<n; j++){HuffCode[i].bit[j] = cd.bit[j];}HuffCode[i].start = cd.start;} /* end for *//* 输出已保存好的所有存在编码的哈夫曼编码*/for (i=0; i<n; i++){printf ("%d 's Huffman code is: ", i);for (j=HuffCode[i].start+1; j < n; j++){printf ("%d", HuffCode[i].bit[j]);}printf(" start:%d",HuffCode[i].start);printf ("\n");}/*for(i=0;i<n;i++){for(j=0;j<n;j++){printf ("%d", HuffCode[i].bit[j]);}printf("\n");}*/printf("Decoding?Please Enter code:\n");scanf("%s",&pp);decodeing(pp,HuffNode,n);getch();return 0;}解码#include "string.h"#include "stdio.h"#define MAXVALUE 1000 /*定义最大权值*/#define MAXLEAF 30 /*定义哈夫曼树叶结点个数*/#define MAXNODE MAXLEAF*2-1#define MAXBIT 30 /*定义哈夫曼编码的最大长度*/typedef struct{ int bit[MAXBIT];int start;} HCODETYPE;typedef struct{ int weight;int parent;int lchild;int rchild;} HNODETYPE;char *getcode1(char *s1,char *s2,char *s3) /*首先去掉电文中的空格*/{ char temp[128]="",*p,*q;p=s1;while ((q=strstr(p,s2))!=NULL){ *q='\0';strcat(temp,p);strcat(temp,s3);p=q+strlen(s2); }strcat(temp,p);strcpy(s1,temp);return s1;}/*再去掉重复出现的字符(即压缩电文),提取哈夫曼树叶结点*/ char * getcode (char *s1){ char s2[26],s5[26];char temp[200]="",*p,*q,*r,*s3="";int m,e,n=0;m=strlen(s1);while(m>0){ p=s1;s2[0]=s1[0];s2[1]='\0';r=s2;e=0;while((q=strstr(p,r))!=NULL){ *q='\0';strcat(temp,p);strcat(temp,s3);p=q+strlen(s2);e++; }m-=e;strcat(temp,p);strcpy(s1,temp);s5[n]=s2[0];n++;strcpy(temp,"");}s5[n]='\0';strcpy(s1,s5);printf(" 压缩后的电文(即叶结点): %s\n",s1);return s1;}HNODETYPE huffmantree(char *s2,char s3[]){ HNODETYPE huffnode[MAXNODE];HCODETYPE huffcode[MAXLEAF],cd;int sum,i,j,n1,n2,x1,x2,p,k,c;char s1[26]={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};char s5[MAXLEAF];int ww[26]={0},n=0;strcpy( s5,s2);sum=strlen(s2);for(i=0;i<26;i++) /*统计所有字符出现的频度*/for(j=0;j<sum;j++)if(s2[j]==s1[i]) ww[i]++;n=strlen(s3);for (i=0;i<2*n-1;i++){ huffnode[i].weight=0;huffnode[i].parent=-1;huffnode[i].lchild=-1;huffnode[i].rchild=-1; }for(i=0;i<n;i++) /*分配给各叶结点权值*/for(j=0;j<26;j++)if (s3[i]==s1[j]) huffnode[i].weight=ww[j];for (i=0;i<n-1;i++) /*构造哈夫曼树*/{ n1=n2=MAXVALUE;x1=x2=0;for(j=0;j<n+i;j++){ if (huffnode[j].parent==-1 && huffnode[j].weight<n1){ n2=n1;x2=x1;n1=huffnode[j].weight;x1=j; }elseif (huffnode[j].parent==-1 && huffnode[j].weight<n2){ n2=huffnode[j].weight; x2=j;}}huffnode[x1].parent=n+i;huffnode[x2].parent=n+i;huffnode[n+i].weight=huffnode[x1].weight+huffnode[x2].weight; huffnode[n+i].lchild=x1;huffnode[n+i].rchild=x2;}for(i=0;i<n;i++) /*求每个叶结点的哈夫曼编码*/{ cd.start=n-1;c=i;p=huffnode[c].parent;while (p!=-1){ if (huffnode[p].lchild==c)cd.bit[cd.start]=0;elsecd.bit[cd.start]=1;cd.start--;c=p;p=huffnode[c].parent;}for (j=cd.start+1;j<n;j++)huffcode[i].bit[j]=cd.bit[j];huffcode[i].start=cd.start;}printf(" 各叶结点对应哈夫曼编码: ");/*输出每个叶结点的哈夫曼编码*/for(i=0;i<n;i++){ for(j=huffcode[i].start+1;j<n;j++)printf("%d",huffcode[i].bit[j]);printf(" ");}printf("\n 电文的全部哈夫曼编码: ");/*输出电文的全部哈夫曼编码*/ for(k=0;k<sum;k++)for(i=0;i<n;i++)if(s2[k]==s3[i]){ for(j=huffcode[i].start+1;j<n;j++)printf("%d",huffcode[i].bit[j]);printf(" "); }printf("\n");}main(){char s1[MAXLEAF],s2[MAXLEAF];printf("\n 请输入电文: ");gets(s1);strcpy(s2,getcode1(s1," ",""));huffmantree(s1,getcode(s2));}nclude<string.h>#include<stdlib.h>#include<stdio.h>int m,s1,s2;typedef struct {unsigned int weight;unsigned int parent,lchild,rchild;}HTNode,*HuffmanTree; //动态分配数组存储哈夫曼树typedef char *HuffmanCode; //动态分配数组存储哈夫曼编码表void Select(HuffmanTree HT,int n) {int i,j;for(i = 1;i <= n;i++)if(!HT[i].parent){s1 = i;break;}for(j = i+1;j <= n;j++)if(!HT[j].parent){s2 = j;break;}for(i = 1;i <= n;i++)if((HT[s1].weight>HT[i].weight)&&(!HT[i].parent)&&(s2!=i))s1=i;for(j = 1;j <= n;j++)if((HT[s2].weight>HT[j].weight)&&(!HT[j].parent)&&(s1!=j))s2=j;}void HuffmanCoding(HuffmanTree &HT, HuffmanCode HC[], int *w, int n) {// 算法6.13// w存放n个字符的权值(均>0),构造哈夫曼树HT,// 并求出n个字符的哈夫曼编码HCint i, j;char *cd;int p;int cdlen;if (n<=1) return;m = 2 * n - 1;HT = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); // 0号单元未用for (i=1; i<=n; i++) { //初始化HT[i].weight=w[i-1];HT[i].parent=0;HT[i].lchild=0;HT[i].rchild=0;}for (i=n+1; i<=m; i++) { //初始化HT[i].weight=0;HT[i].parent=0;HT[i].lchild=0;HT[i].rchild=0;}puts("\n哈夫曼树的构造过程如下所示:");printf("HT初态:\n 结点 weight parent lchild rchild");for (i=1; i<=m; i++)printf("\n%4d%8d%8d%8d%8d",i,HT[i].weight,HT[i].parent,HT[i].lchild, HT[i].rchild);printf(" 按任意键,继续 ...");getchar();for (i=n+1; i<=m; i++) { // 建哈夫曼树// 在HT[1..i-1]中选择parent为0且weight最小的两个结点,// 其序号分别为s1和s2。