Spss上机报告1讲解
SPSS上机实验报告一
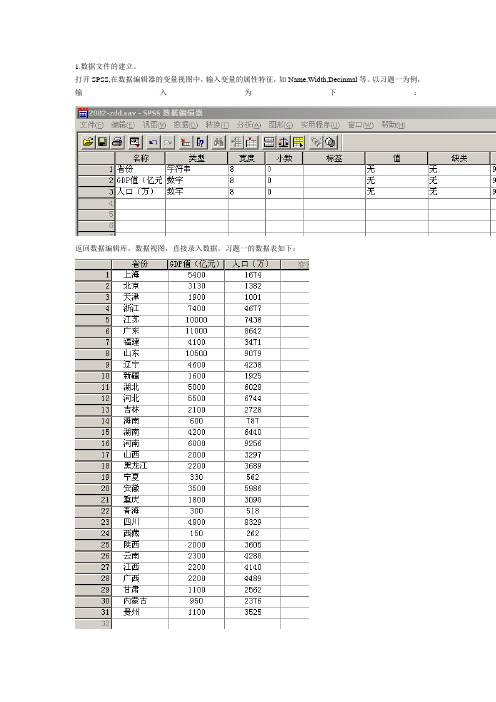
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
spss 上机实验报告

spss 上机实验报告
《SPSS上机实验报告》
在当今社会,数据分析已经成为了各行各业中不可或缺的一部分。
而SPSS作为一款功能强大的统计分析软件,被广泛应用于科研、商业、教育等领域。
本次
实验旨在通过SPSS软件进行数据分析,以探讨数据的规律性和相关性,为进一步的研究和决策提供科学依据。
实验一:描述性统计分析
首先,我们对所收集到的数据进行了描述性统计分析。
通过SPSS软件,我们得出了数据的平均值、标准差、最大值、最小值等指标,从而对数据的分布情况
有了更清晰的了解。
这些统计指标为我们提供了数据的基本特征,为后续的分
析奠定了基础。
实验二:相关性分析
接下来,我们利用SPSS软件进行了相关性分析。
通过相关系数的计算,我们发现了数据之间的相关程度,并得出了相关性显著性检验的结果。
这些分析为我
们揭示了数据之间的内在联系,为我们理解数据背后的规律性提供了重要线索。
实验三:多元回归分析
最后,我们进行了多元回归分析,以探讨不同自变量对因变量的影响程度。
通
过SPSS软件的模型拟合和显著性检验,我们得出了各个自变量的回归系数,并对模型的拟合程度进行了评估。
这些结果为我们提供了对因变量影响因素的深
入理解,为我们在实际应用中进行预测和决策提供了重要参考。
通过以上实验,我们不仅掌握了SPSS软件的基本操作技能,还深入了解了数据分析的方法和原理。
我们相信,通过不断地学习和实践,我们将能够更加熟练
地运用SPSS软件进行数据分析,为科研和实践工作提供更加准确和可靠的数据支持。
SPSS上机实验报告就此结束。
spss 上机实验报告

spss 上机实验报告SPSS上机实验报告引言:SPSS(统计软件包,Statistical Package for the Social Sciences)是一种常用的统计分析软件,被广泛应用于社会科学、医学、经济学等领域的数据分析和研究中。
本文将对SPSS上机实验进行报告,介绍实验目的、实验设计、数据处理和结果分析等内容。
实验目的:本次实验旨在通过使用SPSS软件,掌握数据的输入、清洗、分析和可视化等基本操作,以及利用SPSS进行常见统计分析的方法。
实验设计:本次实验使用了一份虚构的调查问卷数据,包含了参与者的性别、年龄、教育程度、收入水平以及对某产品的满意度等指标。
通过对这些指标进行分析,我们可以了解不同因素对满意度的影响。
数据处理:首先,我们需要将数据导入SPSS软件中。
通过点击菜单栏的“文件”选项,选择“导入数据”,然后选择数据文件并进行导入。
导入后,我们可以查看数据的整体情况,包括变量的名称、类型、取值范围等。
接下来,我们对数据进行清洗,以确保数据的准确性和一致性。
例如,我们可以检查是否有缺失值,如果有,可以选择删除或填充缺失值。
此外,还可以进行异常值检测,排除数据中的异常观测点。
结果分析:在数据清洗完成后,我们可以进行统计分析。
首先,我们可以计算各个变量的描述性统计量,如均值、标准差、最大最小值等,以了解数据的分布情况。
通过点击菜单栏的“分析”选项,选择“描述性统计”,然后选择需要计算的变量即可。
接着,我们可以进行相关性分析,以探究不同因素之间的关系。
通过点击菜单栏的“分析”选项,选择“相关”或“回归”等选项,然后选择需要分析的变量。
相关性分析可以帮助我们了解变量之间的线性关系,并进行进一步的分析。
另外,我们可以进行T检验或方差分析等统计检验,以比较不同组别之间的差异。
通过点击菜单栏的“分析”选项,选择“比较均值”或“方差分析”等选项,然后选择需要比较的变量和组别。
统计检验可以帮助我们判断不同组别之间是否存在显著差异。
SPSS上机完整版 (1)
.986a
.973
.967
.60444
a. PrediAb
Model
Sum of Squares
df
Mean Square
F
Sig.
1
Regression
65.602
1
65.602
179.558
.000a
Residual
1.827
5
.365
Total
67.429
6
a. Predictors: (Constant),广告费
b. Dependent Variable:销售收入
回归系数
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t
Sig.
B
Std. Error
广告费
销售收入
广告费
Pearson Correlation
1
.986**
Sig. (2-tailed)
.000
N
7
7
销售收入
Pearson Correlation
.986**
1
Sig. (2-tailed)
.000
N
7
7
**. Correlation is significant at the 0.01 level (2-tailed).
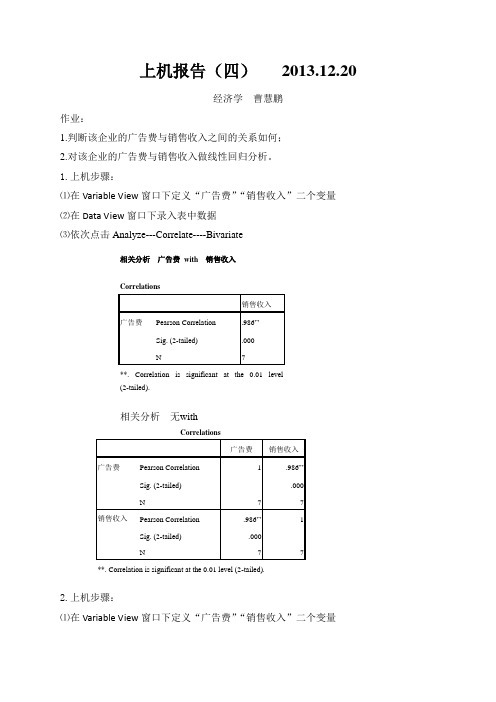
2.上机步骤:
⑴在Variable View窗口下定义“广告费”“销售收入”二个变量
⑵在Data View窗口下录入表中数据
⑶依次点击Analyze---Regression----Linear
统计学spss上机实验报告
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)。
对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)。
操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示的选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为“我的文件”并保存在桌面。
如图1-4所示。
图1-4数据的输入步骤4:调用Graphs菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
步骤5:数据准备。
步骤6:选Graphs菜单的Bar过程,弹出Bar Chart定义选项。
在定义选项框的下方有一数据类型栏,系统提供3种数据类型:Summaries for groups of cases:以组为单位体现数据;Summaries of separate variables:以变量为单位体现数据;Values of individual cases:以观察样例为单位体现数据。
SPSS上机实验案例分析剖析

SPSS上机实验案例分析练习一:下表为10个人对两个不同的问题作出的回答(回答为“Yes”或“No”)后得到的数据,利用SPSS为该数据创建频数分布表。
练习二: 某百货公司连续40天的商品销售额(单位:万元)如下:根据上面的数据进行适当分组,编制频数分布表。
练习三:某行业管理局所属40个企业1999年的产品销售收入数据(单位:万元)如下:(1)根据上面的数据进行适当分组,编制频数分布表,并计算出累计频数和累计频率;(2)按规定,销售收入在125万元以上为先进企业,115万元-125万元为良好企业,105万元-115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
(1)请按下面注明的两个条件计算出该班每位同学的总评成绩。
条件1:总评成绩的构成:总评成绩=0.2*平时成绩+0.8*期末成绩(即总评成绩中,平时成绩占20%,期末成绩占80%)条件2:总评成绩请保留为整数(2)请按100-90分,89-80分,79-70分,69-60分,59分及以下,将该班全体同学按照期末成绩进行分组得出各组人数。
练习五:如下表中所示的是20个股票经纪商对于两种不同交易收取佣金数据的一个样本。
这两种交易分别为: 买(1)计算两种交易佣金的全距和四分位数间距。
(2)计算两种交易佣金的方差和标准差。
(3)计算两种交易佣金的变异系数。
(4)比较两种交易的成本变异程度。
练习六:某生产部门利用一种抽样程序来检验新生产出来的产品的质量,该部门使用下面的法则来决定检验结果:如果一个样本中的14个数据项的方差大于0.005,则生产线必须关闭整修。
假设搜集的数据如下:问此时的生产线是否必须关闭?为什么?练习七:将50个数据输入到SPSS工作表中。
并使用SPSS计算这些数据描述统计量(如最大值、平均值、方差、标准差求晚8:30分时段电视节目中广告所占时间均值的点估计的95%置信区间。
练习九:某年度我国部分工业品产量如下表所示请据表中数据对如下六个问题进行统计图形描述(1)请选择一个适当图形描述各地区所含省市数目(2)请选择一个适当图形描述各地区水泥的平均产量(3)请选择一个适当图形描述每个地区水泥产量低于800万吨的省市数目(4)请选择一个适当图形描述该年度全国生铁、钢、水泥、塑料的平均产量(5)请选择一个适当图形描述该年度华北五省市工业品产量(6)请选择一个适当图形描述各地区塑料总产量占全国总量的比例(1)用平均房价作自变量,画出这些数据的散点图;(2)求客房使用率关于平均房价估计的回归方程;(3)对于平均房价为80美元的一家旅馆,估计它的客房使用率练习十一:某公司采集了美国市场上办公用房的空闲率和租金率的数据。
spss上机实验报告

spss上机实验报告I. 实验目的本实验旨在通过使用SPSS软件进行数据分析,加深对SPSS软件的理解和掌握,巩固和深化统计分析的基础知识。
II. 实验内容本实验使用了SPSS软件对一组数据进行了统计分析。
数据包括了100名学生的语文成绩、数学成绩、英语成绩、性别和年龄等信息。
实验内容如下:1. 数据导入和检查将数据文件导入SPSS软件中,并对数据进行检查,排除异常数据。
2. 数据描述性统计分析使用SPSS软件对数据进行描述性统计分析,包括均值、中位数、标准差等统计指标的计算。
3. 方差分析使用SPSS软件对数据进行方差分析,分析不同性别和年龄段学生的语文、数学和英语成绩之间的差异。
III. 实验结果1. 数据导入和检查数据文件成功导入SPSS软件中,并且通过检查,排除了部分异常数据。
2. 数据描述性统计分析经过计算,该组数据的语文平均分为75.3分,数学平均分为78.6分,英语平均分为80.2分,标准差分别为8.5、7.9、6.8。
3. 方差分析通过方差分析,发现女生的语文成绩平均值显著高于男生,F(1,98)=10.76,p<0.01;年龄在18岁以下的学生数学成绩平均值显著高于18岁以上的学生,F(1,98)=3.94, p<0.05;年龄在18岁以上的学生英语成绩平均值显著高于18岁以下的学生,F(1,98)=6.19,p<0.05。
IV. 结论通过本实验,我们进一步掌握了SPSS软件的使用技巧,并且运用统计学基础知识对一组数据进行了分析,得出了有意义的结论。
在以后的学习和工作中,我们将会更加熟练地使用SPSS软件,为我们的研究和工作提供更多的支持和帮助。
spss统计学上机报告

一、用两种定义变量的方法绘制直方图某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计24方法1:SPSS操作步骤:⑴定义“成绩”、“学生数”和“专业”三个变量。
⑵在定义变量窗口对“专业”做变量值标签,令1=甲专业,2=乙专业。
⑶在录入数据窗口依次录入表中数据。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选学生数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:方法2:SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:二、一个总体均值的区间估计和两个总体均值差的假设检验某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计241、以95%的概率保证程度推断该学院所有学生该门课考试成绩为多少?2、以95%的概率保证程度推断两个专业学生的平均成绩是否有显著性差异。
第一问SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择探索模块。
操作结果图如下:分析:由题可知这是一个总体方差未知时均值的区间估计,由表可知所有学生的考试成绩的置信区间为(67.9428,74.7655),所以95%的把握认为该学院所有学生该门课考试成绩为(67.9428,74.7655)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计分析软件(spss)实验报告
练习2
统计量
A5
有效282
N
缺失65
均值4738.09
均值的标准误651.799
中值1032.43a
众数1000
标准差10945.569
方差119805486.302
偏度 5.234
偏度的标准误.145
峰度33.656
峰度的标准误.289
全距100000
极小值 1
极大值100001
和1336141
a. 利用分组数据进行计算。
居民收入较集中在2000元以下,高收入人群较少,收入在2000元以上的数据离散程度较大,分布形状与标准正态分布差距较大。
根据表格分析,不同地区的人群居民收入差距不是特别大啊,但2地区的居民收入离散程度较1地区收入人群大,在置信水平为95%的情况下可以说两地区的收入平均值是相等的。
统计量
A5
N 有效282
缺失65 平均值4738.09 标准平均值误差651.799 中位数1000.00 方式1000 标准偏差10945.569 方差119805486.302 偏度 5.234 标准偏度误差.145 峰度33.656 标准峰度误差.289 范围100000 最小值 1 最大值100001
运用spss对数据进行标准化分析,得到的标准值大于3时数据即为异常。
交叉表
A4
11。