均数抽样误差
(抽样检验)样本均数的抽样误差与置信区间

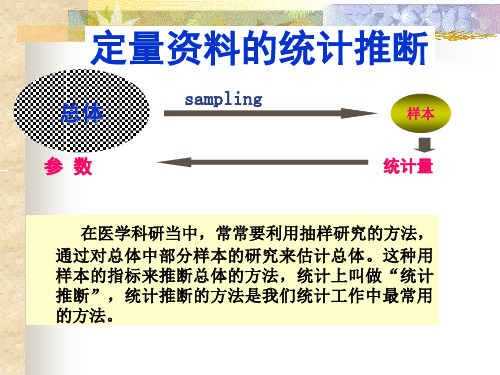
第三章 样本均数的抽样误差与置信区间 ★ 联系:3.1 样本均数的分布·从同一总体中独立抽取多份样本, 他们的均数常大小不一, 这说明样本均数存在变异。
通过电脑实验来认识样本均数的变异规律一、正态总体样本均数的分布实验 3.1 从正态分布总体抽样的实验 假定正常男子的红血球计数服从正态分布N(4.6602, 0.57462),随机抽取1000份样本, 每份含n =5个个体。
样本均数依然是一个随机变量, 且(1)(2)(3) 样本均数的分布很有规律,围绕着总体均数,中间多、两边少, 左右基本对称(对称、正态?);(4)(5) 随着样本量的增大,表3.1 从N(4.6602, 0.57462)中随机抽样, 样本量为5, 100份独立 12图3.1 从正态分布总体抽样的实验结果 23.7 4.1 4.5 4.9 5.3 5.7 3.7 4.1 4.5 4.9 5.3 5.7 3.7 4.1 4.5 4.9 5.3 5.7(a) (b) (c)* 由这份样本估计的95%置信区间实际上并未复盖总体均数表3.2 从N(4.6602, 0.57462)中随机抽取1000份独立样本, 其均数的频数分布组段下限(1012 /L) 频数 频率(%) 累积频率(%)3.60- 1 0.1 0.13.80- 5 0.5 0.64.00- 32 3.2 3.84.20- 117 11.7 15.54.40- 229 22.9 38.44.60- 304 30.4 68.84.80- 218 21.8 90.65.00- 76 7.6 98.25.20- 15 1.5 99.75.40- 3 0.3 100.0合计 1000 100.0·理论上可以证明, 从正态分布N(μ, σ2)的总体中随机抽取含量为n 的样本,其样本均数X ~N(μ, σ2 /n)。
·样本均数的标准差习惯上又称为样本均数的标准误(standard error),简称标准误。
抽样误差和可信区间-幻灯片(1)

均数之差可信区间的计算
正常组
肝炎组
1=?
2=? 1- 2 =?
均 数:273.18ug/dL 标准差:9.77ug/dL
均 数: 231.86ug/dL 标准差:12.17ug/dL
X1X242.32
合并方差与均数之差的标准误
❖ 合并方差(方差的加权平均)
sC 2 (n11n)1s 12 n2(n 221)s22
❖ 每一自由度下的t分布曲线都有其自身分布规律。t界值 表。
t分布曲线下的面积
f (x)
nn21n1
x2 n
n12
2
-t 0 t
t界值表
单侧:
P(t <-tα,ν)= α或 P(t >tα,ν)= α 双侧:
-t 0 t
P(t <-tα/2,ν)+ P(t >tα/2,ν)= α 即:P(-tα/2,ν<t <tα/2,ν)= 1-α [例] 查t界值表得t值表达式
可信区间的定义
❖ 按一定的概率或可信度(1-α)用一个区间 来估计总体参数所在的范围,该范围通 常称为参数的可信区间或者置信区间 (confidence interval,CI),预先给定的概 率(1-α)称为可信度或者置信度 (confidence level),常取95%或99%。
❖ 可信区间(CL, CU )是一开区间 CL、CU 称 为可信限
❖ 这里的95%,指的是方法本身!而不
是某个区间! ❖ 总体参数虽未知,但却是固定的值,
而不是随机变量值 。
95%可信区间的含义
按这种方法 构建的可信区 间,理论上平 均每100次,有 95 次 可 以 估 计 到总体参数。
4 第四章 均数的抽样误差与t分布

统计推断包括两个方面: 统计推断包括两个方面: 参数估计( 1、参数估计(总体均数的可信区 间估计) 间估计) 假设检验(均数的假设检验) 2、假设检验(均数的假设检验) 两样本均数必较( 检验、 ⑴、两样本均数必较(u检验、 检验) t检验) 多样本均数必较( 检验) ⑵、多样本均数必较(F检验)
t分布
(t - distribution) distribution)
从正态总体中随机抽取含量为n 从正态总体中随机抽取含量为n的若 干样本,由样本算得样本均数x 干样本,由样本算得样本均数x,x服从 正态分布, 则称为正态变量。若已知µ 正态分布,x则称为正态变量。若已知µ, 但未知σ 为了应用方便,可用s代替σ 但未知σ,为了应用方便,可用s代替σ, 求得σ 的估计值S 正态变量x 求得σx的估计值Sx,正态变量x可作变量 变换:t=(x变量变成t变量。 变换:t=(x-µ)/Sx, x变量变成t变量。每 个样本x可算得一个t变量, 个样本x可算得一个t变量,所有可能含量 的样本的t值构成t变量总体, 分布。 为n的样本的t值构成t变量总体,即t分布。
可信区间的两个要素
1.准确度 反映在可信度1 1.准确度:反映在可信度1–α的大 准确度: 小上,即区间包含总体均数的概率大小。 小上,即区间包含总体均数的概率大小。 概率越大越准确。 概率越大越准确。 2.精度 反映在可信区间的长度上。 2.精度:反映在可信区间的长度上。 精度: 长度越小越精密。 长度越小越精密。 在 n 确定的情况下,二者是矛盾的。 确定的情况下,二者是矛盾的。 (α ↓, tα.ν ↑) 如提高可信度 ,则区间变 在可信度确定的情况下, 长。在可信度确定的情况下,增加样本 减小区间长度, 例数 (SX ↓, tα,减小区间长度,提高 ↓) .ν 精度。 精度。
总体均数估计与假设检验
t 检验
t-test
三、t检验和Z检验(参数检验)
以t分布为基础的检验称为t检验。 t分布的发现使得小样本统计推断成为 可能。因而,它被认为是统计学发展历 史中的里程碑之一。
在医学统计学中,t检验是重要的 假设检验方法之一。常用于两个均数之 间差别的比较,并根据资料的分布情况 及设计类型,选择不同的t检验方法。
配对样本t检验
Paired design t-test
关系:随着样本含量增加,都减小。
联系:都是表示变异度的指标,当样本量一定时,两者成正比。
标准误用途
衡量样本均数的可靠性:标准误越小,表明 样本均数越可靠;
参数估计:估计总体均数的置信区间(区 域);
假设检验:用于总体均数的假设检验(比 较)。
二、t分布:
标准正态分布
开创了小样本统计的新纪元,t分布主要用于总体均数的 区间估计和t检验!
假设检验(Hypothesis test)
假设检验的推断原理 假设检验的基本步骤 t检验和Z检验 两样本总体方差齐性检验 正态性检验 假设检验的两类错误 注意事项
一、假设检验的推断原理
上面介绍过的区间估计方法是统计 推断的内容之一,假设检验是统计推 断的另一重要内容。正是应用统计推 断的理论和方法,人们才能顺利地通 过有限的样本信息去把握总体特征, 实现抽样研究的目的。
s / n 25.74 36
在H0成立的前提下,当前t值出现的概率有多 大???
如何给出这个量的界限?
小概率事件在一次试验 中基本上不会发生 !
从附表2中查出在显著性水平 =0.05(双侧),自由度为35所 对应的t界值=2.318,即为拒绝 域与接受域的界限。如果计算
5.1 样本均数的抽样分布与抽样误差

第五章 参数估计基础一、样本均数的抽样分布与抽样误差内 容1. 抽样误差和抽样分布2. 样本均数抽样分布和抽样误差1. 抽样误差和抽样分布n误差泛指实测值和真实值之差。
按其产生原因与性质分两 大类:系统误差和随机误差。
抽样误差是一种随机误差。
n抽样误差由于生物固有的个体变异,从某一总体中随机抽取一个样 本,所得样本统计量与相应总体参数往往是有差异的,这种 差异称为抽样误差(sampling error)。
n误差产生的原因n系统误差:由受试对象、研究者、仪器设备、研究方法等确定性 原因造成,有倾向性,可避免。
n随机误差:由多种无法控制的偶然因素引起的,无倾向性,不可 避免。
n抽样误差:产生的根本原因是个体变异、产生的直接原因是抽样。
n抽样分布n由于抽样误差存在,从同一总体中随机抽取若干份样本, 所得样本统计量是不一致的,差异无法避免但其存在一定的分布规律。
n 正态分布总体样本均数抽样分布的电脑试验n假定某年某地所有13岁女生的身高服从总体均数为155.4 cm ,总 体标准差为5.3cm 的正态分布 。
用计算机从该总体中 随机抽样,每次抽取30例组成一份样本,重复抽样100次,计算 每份样本的平均身高。
() 2 155.4,5.3 N 2. 样本均数抽样分布和抽样误差n电脑试验表明,正态分布总体样本均数抽样分布具有以 下特点:n样本均数恰好等于总体均数极其罕见;n样本均数之间存在差异;n样本均数围绕总体均数,中间多、两边少,左右基本对称,呈 近似正态分布;n样本均数间的变异小于原始变量值间的变异。
PERCENT30x MIDPOINT0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 1 . 1 1 . 2 1 . 3 1 . 4 1 . 5 1 . 6 1 . 7 1 . 8 1 . 9 2 . 0 2 . 1 2 . 2 2 . 3 2 . 4 2 . 5 2 . 6 2 . 7 2 . 8 2 . 9 3 . 0 3 . 1 3 . 2 3 . 3 3 . 4 3 . 5 3 . 6 3 . 7 3 . 8 3 . 9 4 . 0 4 . 1 4 . 2 4 . 3 4 . 4 4 . 5 4 . 6 4 . 7 4 . 8 4 . 9 5 . 0n 非正态分布总体样本均数抽样分布的电脑实验n图 (a ) 是正偏峰分布原始数据对应的直方图,用计算机随机抽取 样本量分别为5, 10, 30和50的样本各1000份,计算样本均数并绘 制4个直方图。
均数的抽样误差和总体均数估计

在医学、生物学、经济学和社会科学 等领域中,均数的抽样误差和总体均 数估计都是重要的统计工具,用于指 导研究和决策。
02
均数的抽样误差
抽样误差的定义
抽样误差是由于从总体中随机抽取样本而产生的误差,它反映了样本均数 与总体均数之间的差异。
抽样误差是不可避免的,因为每个样本都是独特的,不可能完全复制总体。
研究结论
01
抽样误差是衡量样本均数与总体均数接近程度的重要
指标,其大小直接影响到总体均数的估计精度。
02
在大样本条件下,样本均数的抽样误差通常较小,能
够较好地反映总体均数的真实情况。
03
通过增加样本量或提高样本代表性,可以减小抽样误
差,提高总体均数估计的准确性。
对未来研究的建议
01
进一步研究不同抽样方法对均数抽样误差的影响,以便在实际 应用中选择合适的抽样方法。
市场调研
市场调研中,企业通过抽样调查了解 消费者需求、市场趋势等信息,进而 估计总体均数,制定营销策略。
医学研究中均数估计的应用
临床试验
在临床试验中,研究者通过随机抽样方 法选取一定数量的患者作为样本,根据 样本数据估计总体均数,进而评估药物 疗效。
VS
流行病学研究
流行病学研究中,研究者通过抽样调查方 法了解疾病在人群中的分布情况,估计总 体均数,为制定疾病防控策略提供依据。
均数的抽样误差和总体均 数估计
• 引言 • 均数的抽样误差 • 总体均数的估计 • 样本大小与均数估计精度 • 实际应用案例 • 结论与展望
01
引言
主题简介
均数的抽样误差
指通过样本均数来估计总体均数时所存在的误差范围。
总体均数估计
均数的抽样误差和标准误

x
x Sx
t值的分布是以0为中心,两侧对称的类似正态 分布的一种分布,即t分布。 自由度越大,t分布曲线峰越高 ,反之越低 自由度趋向于无穷时,t分布曲线即为正态分 布曲线 。
t值的意义:举例
双侧t0.05(9) =2.262, t<-2.262及t>2.262的
概率是0.05
t0.05, 24 1.711
H 0 : 0 , 72 H1 : 0 , 72
0.05单侧
今n 25, x 74.2, s 6.5, 0 72 x 0 74.2 72 t 1.692 s 6.5 25 n n 1 25 1 24 查表t0.05, t0.05, 24 1.711 t t0.05, 24 , P 0.05 ,不拒绝H 0
标准误 x , x2 ,… 1
x100
样本均数总体的特点
如果原分布是正态分布,新分布呈正态。 如果原分布呈偏态,当样本含量足够大时, 新分布也呈正态。 样本均数的均数等于总体均数。 样本均数的标准差称为标准误, x = n S s
x
n
标准误与标准差的区别与联系
x - t 0.05, v t 0.05, v Sx
x
- t0.05,v
S x ﹤﹤ x
,
+ t0.05,v
Sx
x ±1.96 S x
x ±2.58 S x
总体均数可信区间与正常值范围的区别
总体均数可信区间
意义
正常值范围
在某个预先给定的范围 正常个体的某些 (如95%)内包括总体均 生理、生化等指 数的可能性的大小,或说 标的波动范围 该范围有多大的把握度包 含了总体均数
统计学课堂练习题4

一、名词解释抽样误差、均数的抽样误差、标准误、可信区间二、填空题1.参数估计可分为_____点估计____ 和__区间估计______ 。
2. 在抽样研究中,当样本含量趋向无穷大时,X 趋向等于__μ___,S 趋向等于__0__,t(0.05,v) 趋向等于________ 。
3、定量资料常用的假设检验方法有 t 检验 、 u 检验 、 方差分析 。
4、方差分析可用于两个或两个以上样本均数的比较,其应用时要求,(1)正态分布;(2)方差齐。
5、标准误是 均数 的标准差,与标准差的关系可用公式 n s表示。
6、假设检验时根据检验结果作出的判断, 可能发生两种错误, 第一类错误的概率为 α,第二类错误的概率为 β , 同时减少两类错误的唯一方法是 增加样本含量 。
7、t 检验的应用条件是 正态分布 和 方差齐 。
8. 配对设计差值的t 检验无效假设是 d =0 。
9、两样本比较t 检验要求资料(1) 正态分布 ;(2) 方差齐 。
10、样本量较小的二组数值变量资料进行t 检验时,要求二组资料呈 正态分布; 方差齐。
11、数值变量数据常用的参数统计方法有 t 检验、u 检验和方差分析。
三、是非题1.在假设检验中,无论是否拒绝H 0,都有可能犯错误。
( V )2.同类研究的两组资料,n 1=n 2,则标准差大的那一组 ,μ的95%可信区间范围也一定小。
( X )3.两个同类资料的t 检验,其中P 1<0.01, 0.01﹤P 2<0.05,说明前者两样本均数之差大于后者。
( X )4.均数比较的u 检验的应用条件是n 较大或n 虽小但σ已知。
(V )5.标准误越小,表示用样本均数估计总体均数的可靠性越大。
( V )6.统计的假设是对总体特征的假设,其结论是概率性的,不是绝对的肯定或否定。
( V )7.成组设计的两样本几何均数的比较;当n 足够大时,也可以用u 检验。
(V )8.在配对T 检验中,用药前数据减去用药后的数据和用药后的数据减去用药前的数据,作T 检验后的结论是相同的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
统计推断:由样本信息推断总体特征。
样本统计指标 (统计量)
总体统计指标 (参数)
正态(分布)总体:N ~ ( , 2 ) 推断 ! 说明! 为说明抽样误差规律,先用一个实例,后 引出理论。
2
例 3-1 若某市 1999 年 18 岁男生身高服从均 数μ =167.7cm、标准差 =5.3cm 的正态分布。对 该总体进行随机抽样,每次抽 10 人, ( n j =10) , 共抽得 100 个样本( g =100) ,计算得每个样本均 数 X 及标准差 S 如图 3-1 和表 3-1 所示。
图3-2 从正态分布总体N(167.7, 5.32)随机抽样所得样本均数分布
4
样本均数的抽样分布具有如下特点:
① X ,各样本均数 X 未必等于总体均数; ② 各样本均数间存在差异; ③ 样本均数的分布为中间多,两边少,左右基本 对称。 ④ 样本均数的变异范围较之原变量的变异范围大 大缩小。 可算得这100个样本均数的均数为167.69cm、标准 差为1.69cm。
j
j
X
j
Sj
167.41, 2.74 165.56, 6.57
=167.7cm =5.3cm X1,X2,X3,Xi,
168.20, 5.36 ┆ nj=10 165.61 1999年某市18岁男生身高N(167.7, 5.32)的抽样示意图
3
将此100个样本均数看成新变量值,则这100 个样本均数构成一新分布,绘制直方图。
X
n
(3-1)
实质:样本均数的标准差
7
数理统计证明:
X X ; X X 。
8
若用样本标准差S 来估计 ,
SX
S n
(3-2)
降低抽样误差的途径有: ①通过增加样本含量n;
②通过设计减少S。
9
第二节 t 分布 (t-distribution)
10
5
1、抽样误差:
由个体变异产生的、抽样造成的样 本统计量与总体参数的差别 均数的抽样误差:由于抽样造成的 样本均数与总体均数的差别
原因:1)抽样 2)个体差异
6
2、标准误(standard error, SE)
表示样本统计量抽样误差大小的统计 指标。 均数标准误: 说明均数抽样误差的 大小,总体计算公式