C语言版数据结构知识点汇总
数据结构_(严蔚敏C语言版)_学习、复习提纲.
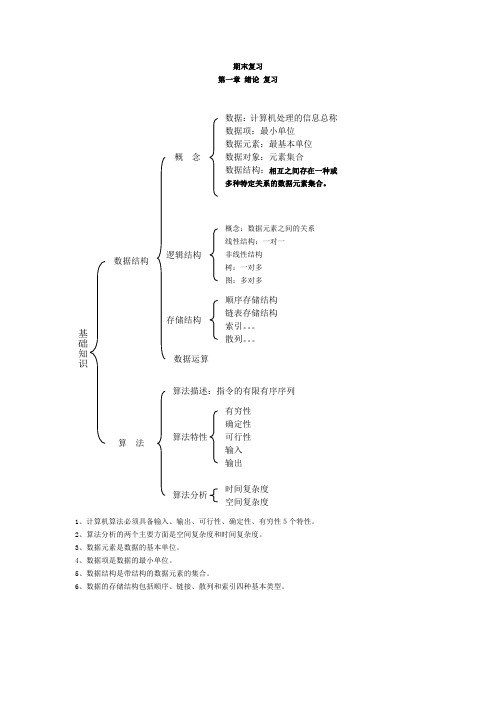
期末复习 第一章 绪论 复习1、计算机算法必须具备输入、输出、可行性、确定性、有穷性5个特性。
2、算法分析的两个主要方面是空间复杂度和时间复杂度。
3、数据元素是数据的基本单位。
4、数据项是数据的最小单位。
5、数据结构是带结构的数据元素的集合。
6、数据的存储结构包括顺序、链接、散列和索引四种基本类型。
基础知识数据结构算 法概 念逻辑结构 存储结构数据运算数据:计算机处理的信息总称 数据项:最小单位 数据元素:最基本单位数据对象:元素集合数据结构:相互之间存在一种或多种特定关系的数据元素集合。
概念:数据元素之间的关系 线性结构:一对一非线性结构 树:一对多 图:多对多顺序存储结构 链表存储结构 索引。
散列。
算法描述:指令的有限有序序列算法特性 有穷性 确定性 可行性 输入 输出 算法分析时间复杂度 空间复杂度第二章 线性表 复习1、在双链表中,每个结点有两个指针域,包括一个指向前驱结点的指针 、一个指向后继结点的指针2、线性表采用顺序存储,必须占用一片连续的存储单元3、线性表采用链式存储,便于进行插入和删除操作4、线性表采用顺序存储和链式存储优缺点比较。
5、简单算法第三章 栈和队列 复习线性表顺序存储结构链表存储结构概 念基本特点基本运算定义逻辑关系:前趋 后继节省空间 随机存取 插、删效率低 插入 删除单链表双向 链表 特点一个指针域+一个数据域 多占空间 查找费时 插、删效率高 无法查找前趋结点运算特点:单链表+前趋指针域运算插入删除循环 链表特点:单链表的尾结点指针指向附加头结点。
运算:联接1、 栈和队列的异同点。
2、 栈和队列的基本运算3、 出栈和出队4、 基本运算第四章 串 复习栈存储结构栈的概念:在一端操作的线性表 运算算法栈的特点:先进后出 LIFO初始化 进栈push 出栈pop队列顺序队列 循环队列队列概念:在两端操作的线性表 假溢出链队列队列特点:先进先出 FIFO基本运算顺序:链队:队空:front=rear队满:front=(rear+1)%MAXSIZE队空:frontrear ∧初始化 判空 进队 出队取队首元素第五章 数组和广义表 复习串存储结构运 算概 念顺序串链表串定义:由n(≥1)个字符组成的有限序列 S=”c 1c 2c 3 ……cn ”串长度、空白串、空串。
数据结构(C语言版)

数据结构(C语言版) 数据结构(C语言版)1.简介1.1 什么是数据结构1.2 数据结构的作用1.3 数据结构的分类1.4 C语言中的数据结构2.线性表2.1 数组2.2 链表a. 单链表b. 双链表c. 循环链表3.栈与队列3.1 栈a. 栈的定义b. 栈的基本操作3.2 队列a. 队列的定义b. 队列的基本操作4.树4.1 二叉树a. 二叉树的定义b. 二叉树的遍历4.2 AVL树4.3 B树5.图5.1 图的定义5.2 图的存储方式a. 邻接矩阵b. 邻接表5.3 图的遍历算法a. 深度优先搜索(DFS)b. 广度优先搜索(BFS)6.散列表(哈希表)6.1 散列函数6.2 散列表的冲突解决a. 开放寻址法b. 链地质法7.排序算法7.1 冒泡排序7.2 插入排序7.3 选择排序7.4 快速排序7.5 归并排序7.6 堆排序7.7 计数排序7.8 桶排序7.9 基数排序8.算法分析8.1 时间复杂度8.2 空间复杂度8.3 最好、最坏和平均情况分析8.4 大O表示法附件:________无法律名词及注释:________●数据结构:________指数据元素之间的关系,以及对数据元素的操作方法的一种组织形式。
●C语言:________一种通用的编程语言,用于系统软件和应用软件的开发。
●线性表:________由n个具有相同特性的数据元素组成的有限序列。
●栈:________一种特殊的线性表,只能在表的一端插入和删除数据,遵循后进先出(LIFO)的原则。
●队列:________一种特殊的线性表,只能在表的一端插入数据,在另一端删除数据,遵循先进先出(FIFO)的原则。
●树:________由n(n>=0)个有限节点组成的集合,其中有一个称为根节点,除根节点外,每个节点都有且仅有一个父节点。
●图:________由顶点的有穷集合和边的集合组成,通常用G(V, E)表示,其中V表示顶点的有穷非空集合,E表示边的有穷集合。
《数据结构(c语言版)》知识点概括

数据结构知识点概括第一章概论数据就是指能够被计算机识别、存储和加工处理的信息的载体。
数据元素是数据的基本单位,可以由若干个数据项组成。
数据项是具有独立含义的最小标识单位。
数据结构的定义:·逻辑结构:从逻辑结构上描述数据,独立于计算机。
·线性结构:一对一关系。
·线性结构:多对多关系。
·存储结构:是逻辑结构用计算机语言的实现。
·顺序存储结构:如数组。
·链式存储结构:如链表。
·索引存储结构:·稠密索引:每个结点都有索引项。
·稀疏索引:每组结点都有索引项。
·散列存储结构:如散列表。
·数据运算。
·对数据的操作。
定义在逻辑结构上,每种逻辑结构都有一个运算集合。
·常用的有:检索、插入、删除、更新、排序。
数据类型:是一个值的集合以及在这些值上定义的一组操作的总称。
·结构类型:由用户借助于描述机制定义,是导出类型。
抽象数据类型ADT:·是抽象数据的组织和与之的操作。
相当于在概念层上描述问题。
·优点是将数据和操作封装在一起实现了信息隐藏。
程序设计的实质是对实际问题选择一种好的数据结构,设计一个好的算法。
算法取决于数据结构。
算法是一个良定义的计算过程,以一个或多个值输入,并以一个或多个值输出。
评价算法的好坏的因素:·算法是正确的;·执行算法的时间;·执行算法的存储空间(主要是辅助存储空间);·算法易于理解、编码、调试。
时间复杂度:是某个算法的时间耗费,它是该算法所求解问题规模n的函数。
渐近时间复杂度:是指当问题规模趋向无穷大时,该算法时间复杂度的数量级。
评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度。
算法中语句的频度不仅与问题规模有关,还与输入实例中各元素的取值相关。
时间复杂度按数量级递增排列依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O(n^2)、立方阶O(n^3)、……k次方阶O(n^k)、指数阶O(2^n)。
数据结构c语言版知识点总结

数据结构c语言版知识点总结数据结构C语言版知识点总结数据结构是计算机科学中的一个重要分支,它研究的是数据的组织、存储和管理方式。
C语言是一种广泛使用的编程语言,也是数据结构中常用的编程语言之一。
本文将对数据结构C语言版的知识点进行总结,包括线性结构、树形结构、图形结构等。
一、线性结构线性结构是指数据元素之间存在一对一的线性关系,即每个数据元素只有一个直接前驱和一个直接后继。
常见的线性结构有数组、链表、栈和队列等。
1. 数组数组是一种线性结构,它由一组相同类型的数据元素组成,这些元素按照一定的顺序排列。
数组的特点是可以通过下标来访问元素,但是数组的长度是固定的,不能动态地增加或减少。
2. 链表链表是一种动态数据结构,它由一组节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表的特点是可以动态地增加或删除节点,但是访问元素需要遍历整个链表。
3. 栈栈是一种后进先出(LIFO)的线性结构,它只允许在栈顶进行插入和删除操作。
栈的应用非常广泛,例如表达式求值、函数调用等。
4. 队列队列是一种先进先出(FIFO)的线性结构,它只允许在队尾进行插入操作,在队头进行删除操作。
队列的应用也非常广泛,例如进程调度、消息传递等。
二、树形结构树形结构是一种非线性结构,它由一组节点组成,每个节点包含一个数据元素和若干个指向子节点的指针。
树形结构常用于表示层次关系,例如文件系统、组织结构等。
1. 二叉树二叉树是一种特殊的树形结构,它的每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉树的遍历方式有前序遍历、中序遍历和后序遍历。
2. 平衡树平衡树是一种特殊的二叉树,它的左右子树的高度差不超过1。
常见的平衡树有AVL树、红黑树等,它们可以保证树的高度不超过logN,从而提高了树的查找效率。
3. 堆堆是一种特殊的树形结构,它满足堆序性质,即每个节点的值都大于等于(或小于等于)其子节点的值。
堆常用于实现优先队列等数据结构。
数据结构(c语言版)

目录第1章绪论第2章线性表第3章栈和队列第4章串第5章数组第6章树第7章图第8章查找第9章排序第10章文件第1章绪论1.1数据结构的基本概念和术语1.2算法描述与分析1.3实习:常用算法实现及分析习题11.1数据结构的基本概念和术语1.1.1引例首先分析学籍档案类问题。
设一个班级有50个学生,这个班级的学籍表如表1.1所示。
表1.1学籍表序号学号姓名性别英语数学物理0120030301李明男8691800220030302马琳男7683855020030350刘薇薇女889390个记录又由750我们可以把表中每个学生的信息看成一个记录,表中的每个数据项组成。
该学籍表由个记录组成,记录之间是一种顺序关系。
这种表通常称为线性表,数据之间的逻辑结构称为线性结构,其主要操作有检索、查找、插入或删除等。
又如,对于学院的行政机构,可以把该学院的名称看成树根,把下设的若干个系看成它的树枝中间结点,把每个系分出的若干专业方向看成树叶,这样就形成一个树型结构,如图1.1所示。
树中的每个结点可以包含较多的信息,结点之间的关系不再是顺序的,而是分层、分叉的结构。
树型结构的主要操作有遍历、查找、插入或删除等。
最后分析交通问题。
如果把若干个城镇看成若干个顶点,再把城镇之间的道路看成边,它们可以构成一个网状的图(如图1.2所示),这种关系称为图型结构或网状结构。
在实际应用中,假设某地区有5个城镇,有一调查小组要对该地区每个城镇进行调查研究,并且每个城镇仅能调查一次,试问调查路线怎样设计才能以最高的效率完成此项工作?这是一个图论方面的问题。
交通图的存储和管理确实不属于单纯的数值计算问题,而是一种非数值的信息处理问题。
图1.2交通示意图1.1.2数据结构有关概念及术语一般来说,数据结构研究的是一类普通数据的表示及其相1968 D.E.Knuth 教授开创了数据结“数据结构”是计算机专业的一门专业基础课。
它为操作关的运算操作。
数据结构是一门主要研究怎样合理地组织数据,建立合适的数据结构,提高计算机执行程序所用的时间效率和空间效率的学科。
数据结构(C语言)分享笔记:数据结构的逻辑层次、存储层次

数据结构(C语⾔)分享笔记:数据结构的逻辑层次、存储层次 数据结构,⼀个简单的定义:相互之间存在⼀种或多种特定关系的数据元素的集合。
即:数据结构 = 元素集合 + 元素间关系的集合。
在讨论数据结构时,可以基于两个不同的层次:1.逻辑层次 2.存储层次 ( 很多专业书中也写为:逻辑结构、存储结构。
但为了避免概念间的混淆,我认为 “层次” 这⼀表述⽅式更贴切 ) 。
逻辑层次,是指对描述对象的单纯的数学抽象。
例如:⼀个科研⼩组由1名导师、2名研究⽣和6名本科⽣构成,导师指导2名研究⽣,每个研究⽣分别指导3名本科⽣。
将这个⼩组视为⼀个数据结构,则从逻辑层次来看,这个数据结构是⼀个简单的树形结构。
存储层次,是指数据结构在计算机存储器中的映射,即通过特定的存储⽅法来反映数据结构中的逻辑关系。
[2] “程序员更常⽤到的” 数据结构的概念 我们在实际情况中很少能直接涉及到数据结构的存储层次:数据结构在存储器中的物理位置——这种很底层的技术。
我们更多地是基于⾼级语⾔来讨论数据结构的,如C语⾔。
⽐如:我们⽤C语⾔中的⼀维数组来描述存储层次中的顺序存储结构,⽤C语⾔中的指针来描述存储层次中的链式存储结构。
在这种情况下,我们可以把C语⾔抽象地看作⼀个执⾏C指令和C数据类型的虚拟处理器,则我们讨论的存储层次实际上是基于虚拟处理器的层次。
⽽这个层次才是和我们接触最多的。
[3] 学习数据结构时的注意点 “数据结构” 这门课程虽然常与计算机,程序设计等联系在⼀起,但其实它是⼀门独⽴的课程,是⼀门理论性很强的课程。
在学习的时候,经常要⽤到逻辑的、抽象的思维⽅式。
同时也要多通过写程序来练习,这样才能避免纸上谈兵,提⾼⾃⼰的编程⽔平。
数据结构(C语言版)——第1章绪论

正确性 可读性 健壮性 高时间效率 高空间效率
算法分析
• • 算法执行所耗费的时间,与该算法中所 有语句的执行总次数成正比 。 语句频度:算法中的所有语句的执行的 总次数 ,记为:T(n) 。 时间复杂度:把T(n)表示成同数量级函 数的形式:T(n)=O(g(n)),则O(g(n))称 为算法的时间复杂度 。描述了当n充分 大的时候算法的语句频度的数量级。
数据结构(C语言版)
第1章 绪论
本章主要知识点
• 数据结构的常用术语及基本概念
• 集合、线性结构、树型结构、图型结构 的逻辑特点 • 抽象数据类型 • 算法、算法描述及算法分析
常用术语和基本概念
• 数据:人们利用文字符号、数字符号以及其他规 定的符号对客观现实世界的事物及其活动所做的 抽象描述。 • 数据元素:表示一个事物的一组数据 ,是数据的 基本单位 。 • 数据项:数据的最小单位。 • 数据对象:性质相同的数据元素的集合。 • 数据类型:一组性质相同的值的集合以及定义在 这个集合上的一组操作的总称。
•
• 常见的时间复杂度有O(1), O(log n) , O(n),O(n2),O(n3), O(2n),分别称为常量 阶、对数阶、线性阶、平方阶、立方阶 和指数阶。 • O(1)<O(log n)<O(n)<O(n2)<O(n3)<O(2n)
• •
空间复杂度:在算法执行过程中需要
的辅助空间数量,记为:S(n) = O(f(n)) 。
常用术语和基本概念
• 数据基本结构: • 集合结构:数据元素之间无任何关系。 • 线性结构:元素之间存在一对一的线线 关系。 • 树形结构:数据元素之间存在着一对多 的关系。 • 图形结构:数据元素之间存在多对多的 关系。
严蔚敏数据结构(C语言版)知识点总结笔记课后答案

第1章绪论1.1复习笔记一、数据结构的定义数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科。
二、基本概念和术语数据数据(data)是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称,它是计算机程序加工的“原料”。
2.数据元素数据元素(data element)是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
3.数据对象数据对象(data object)是性质相同的数据元素的集合,是数据的一个子集。
4.数据结构数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
(1)数据结构的基本结构根据数据元素之间关系的不同特性,通常有下列四类基本结构:① 集合。
数据元素之间除了“同属于一个集合”的关系外,别无其它关系。
② 线性结构。
数据元素之间存在一个对一个的关系。
③ 树形结构。
数据元素之间存在一个对多个的关系。
④ 图状结构或网状结构。
数据元素之间存在多个对多个的关系。
如图1-1所示为上述四类基本结构的关系图。
图1-1 四类基本结构的关系图(2)数据结构的形式定义数据结构的形式定义为:数据结构是一个二元组Data_Structure==(D,S)其中:D表示数据元素的有限集,S表示D上关系的有限集。
(3)数据结构在计算机中的表示数据结构在计算机中的表示(又称映象)称为数据的物理结构,又称存储结构。
它包括数据元素的表示和关系的表示。
① 元素的表示。
计算机数据元素用一个由若干位组合起来形成的一个位串表示。
② 关系的表示。
计算机中数据元素之间的关系有两种不同的表示方法:顺序映象和非顺序映象。
并由这两种不同的表示方法得到两种不同的存储结构:顺序存储结构和链式存储结构。
a.顺序映象的特点是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系。
b.非顺序映象的特点是借助指示元素存储地址的指针(pointer)表示数据元素之间的逻辑关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
☆二叉树的遍历
先(根)序遍历
ABDFGCEH
中(根)序遍历
BFDGACHE
后(根)序遍历
FGDBHECA
☆例题分析
给出一棵二叉树的中序遍历:DBGEACHFI与后序遍历:DGEBHIFCA,画出此二叉树。
☆图
☆图的存储结构
邻接矩阵
有向图、无向图、带权图的邻接矩阵
J向左扫描[27 38 13 49 76 97 65 49]
(一次划分过程)
初始关键字[49 38 65 97 76 13 27 49]
一趟排序之后[27 38 13]49[76 97 65 49]
二趟排序之后[13]27[38]49[49 65]76[97]
三趟排序之后13 27 38 49 49[65]76 97
38 49 27 27 27 27 27 27
65 38 49 38 38 38 38 38
97 65 38 49 49 49 49 49
76 97 65 49 49 49 49 49
13 76 97 65 65 65 65 65
27 27 76 97 76 76 76 76
49 49 49 76 97 97 97 97
2.串的标准函数
在turbo pascal中有如下标准函数可实现串的运算:
copy(s,x,y):获取从s的第x个位置开始的y个字符
concat(s1,s2,...,sn):相等于s1+s2+...+sn
delete(s,x,y):将s中从第x个位置开始的y个字符删去
insert(s1,s,x):将s1插到s中的第x个位置
四、快速排序(Quick Sort)
1.基本思想:
在当前无序区R[1..H]中任取一个数据元素作为比较的"基准"(不妨记为X),用此基准将当前无序区划分为左右两个较小的无序区:R[1..I-1]和R[I+1..H],且左边的无序子区中数据元素均小于等于基准元素,右边的无序子区中数据元素均大于等于基准元素,而基准X则位于最终排序的位置上,即R[1..I-1]≤X.Key≤R[I+1..H](1≤I≤H),当R[1..I-1]和R[I+1..H]均非空时,分别对它们进行上述的划分过程,直至所有无序子区中的数据元素均已排序为止。
第一趟排序后13[38 65 97 76 49 27 49]
第二趟排序后13 27[65 97 76 49 38 49]
第三趟排序后13 27 38 [97 76 49 65 49]
第四趟排序后13 27 38 49 [49 97 65 76]
第五趟排序后13 27 38 49 49 [97 97 76]
☆队列
先进先出
允许插入的一端称为队尾(rear),允许删除的一端称为队头(front)。
☆循环队列
头指针指向队列中队头元素的前一个位置,尾指针指示队尾元素在队列中的当前位置。
☆树
根、叶子、子树
结点的度:结点拥有的子树数
二叉树
☆二叉树
特点:每个结点至多只有二棵子树,并且二叉树的子树有左右之分。
第i层至多有2i-1个结点(i>=1)
输入:i am ,a student
输出:4
3.编码解码:从键盘输入一个英文句子,设计一个编码、解码程序。(string)
编码过程:先键入一个正整数N(1<=N<=26)。这个N决定了转换关系。例如当N=1,输入的句子为ABCXYZ时,则其转换码为ABCXYZ不变。当N=2时,其转换码为BCDYZA,其它的非字母字符不变。为使编码较于破译,将转换码的信息自左而右两两交换,若最后仅剩单个字符则不换。然后,将一开始表示转换关系的N根据ascii表序号化成大写字母放在最前面。
☆排序
冒泡排序
选择排序
快速排序
希尔排序
一、插入排序(Insertion Sort)
1.基本思想:
每次将一个待排序的数据元素,插入到前面已经排好序的数列中的适当位置,使数列依然有序;直到待排序数据元素全部插入完为止。
2.排序过程:
【示例】:
[初始关键字] [49] 38 65 97 76 13 27 49
2.一个句子,只含英文字母,单词间用空格或逗号作为分隔符。统计句子中的单词数,如果含有其他的字符,则只要求输出错误信息及错误类型。(word2)
含有大写字母错误类型error 1
数字(0-9)错误类型error 2
其他非法字符错误类型error 3
如输入:It is 12!
输出:error 1 2 3
(5)当记录本身信息量较大时,为避免耗费大量时间移动记录,可以用链表作为存储结构。
线性结构:串、栈、队列
串
一、串的概念
串又称为字符串,是由0个或多个字符组成的有限序列。长度为0的串称为空串,它不包含任何字符。
串用'和'括起来。
二、串的运算
1.串的定义:
一般用一维数组实现串的运算,由此串的定义也用数组的形式来实现:
(2)若文件的初始状态已按关键字基本有序,则选用直接插入或冒泡排序为宜。
(3)若n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序。快速排序是目前基于比较的内部排序法中被认为是最好的方法。
(4)在基于比较排序方法中,每次比较两个关键字的大小之后,仅仅出现两种可能的转移,因此可以用一棵二叉树来描述比较判定过程,由此可以证明:当文件的n个关键字随机分布时,任何借助于"比较"的排序算法,至少需要O(nlog2n)的时间。
引言
用计算机解决问题一般步骤:
一般来说,用计算机解决一个具体问题时,大致经过以下几个步骤:首先要从具体问题抽象出一个适当的数学模型,然后设计一个解此数学模型的算法,最后编出程序进行测试调整知道的到最终解答。寻求数学模型的实质就是分析问题,从中提取操作的对象,并找出这些操作对象之间含有的关系,然后用数学的语言加以描述。
J=7(27) [13 27 38 49 65 76 97] 49
J=8(49) [13 27 38 49 49 65 76 97]
二、选择排序
1.基本思想:
每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
2.排序过程:
【示例】:
初始关键字[49 38 65 97 76 13 27 49]
type
strivar
s:stringtype;
另外,还有一种更简便的定义方法,利用turbo pascal中的string类型:
var
s:string;
但是string类型有一个限制:运用string类型定义的数据长度只能是1——255,也就是说不能超过255个字符。
☆二维数组与线性表
如果某一线性表,它的每一个数据元素分别是一个线性表,这样的二维表在数据实现上通常使用二维数组。
二维数组的一个形象比喻——
多个纵队形成的方块m * n
☆数组地址计算问题
题目描述:已知N*(N+1) / 2个数据,按行的顺序存入数组b[1],b[2],…中。其中第一个下标表示行,第二个下标表示列。若aij (i>=j ,j=1,2,…,,n)存于b[k]中,问:k,i,j之间的关系如何表示?给定k值,写出能决定相应i,j的算法。
第六趟排序后13 27 38 49 49 76 [76 97]
第七趟排序后13 27 38 49 49 76 76 [ 97]
最后排序结果13 27 38 49 49 76 76 97
三、冒泡排序(BubbleSort)
1.基本思想:
两两比较待排序数据元素的大小,发现两个数据元素的次序相反时即进行交换,直到没有反序的数据元素为止。
栈顶——表尾
栈底——表头
空栈
☆栈(考题分析)
(1998)栈S初始状态为空,现有5个元素组成的序列{1,2,3,4,5},对该序列在栈S上一次进行如下操作(从序列中的1开始,出栈后不再进栈):进栈、进栈、进栈、出栈、进栈、出栈、进栈。问出栈的元素序列是______D
(A) {5,4,3,2,1} (B) {2,1} (C) {2,3} (D) {3,4}
如:abcABCxyzXYZ-/,1. n=3
①cdeCDEzabZAB-/,1. {根据N的值转换}
②dcCeEDazZbBA/-1,. {两两交换}
③CdcCeEDazZbBA/-1,. {最后编码}
解码过程为编码的逆过程。
栈
1.栈的特点:
栈是一种线性表,对于它所有的插入和删除都限制在表的同一端进行,这一端叫做栈的“顶”,另一端则叫做栈的“底”,其操作特点是“后进先出”。
J=2(38) [38 49] 65 97 76 13 27 49
J=3(65) [38 49 65] 97 76 13 27 49
J=4(97) [38 49 65 97] 76 13 27 49
J=5(76) [38 49 65 76 97] 13 27 49
J=6(13) [13 38 49 65 76 97] 27 49
Ki≤K2i Ki≤K2i+1(1≤I≤[N/2])
六、几种排序算法的比较和选择
1.选取排序方法需要考虑的因素:
(1)待排序的元素数目n;
(2)元素本身信息量的大小;
(3)关键字的结构及其分布情况;
(4)语言工具的条件,辅助空间的大小等。
2.小结:
(1)若n较小(n <= 50),则可以采用直接插入排序或直接选择排序。由于直接插入排序所需的记录移动操作较直接选择排序多,因而当记录本身信息量较大时,用直接选择排序较好。