大数据库系统概论——查询优化实验报告材料
大数据库大数据查询实验报告材料
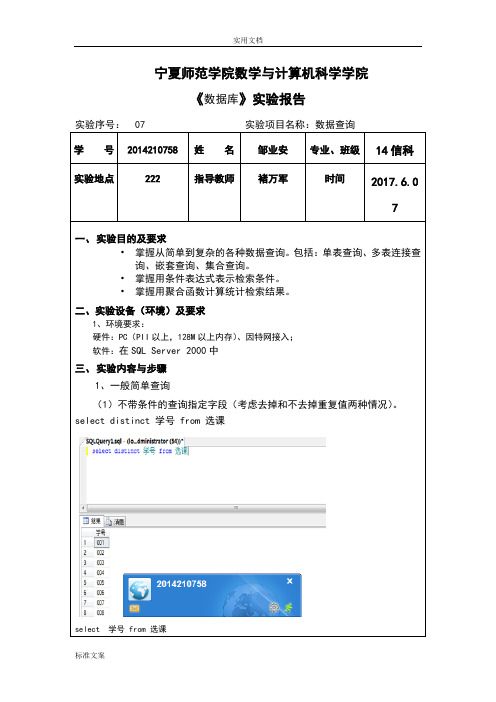
《数据库》实验报告
实验序号:07实验项目名称:数据查询
学 号
2014210758
姓 名
邹业安
专业、班级
14信科
实验地点
222
指导教师
褚万军
时间
2017.6.07
一、实验目的及要求
•掌握从简单到复杂的各种数据查询。包括:单表查询、多表连接查询、嵌套查询、集合查询。
•掌握用条件表达式表示检索条件。
select姓名,职称,课程名称,课程性质
from教师inner join课程
on教师.教师编号=课程.责任教师
(23)查询教师-课程信息,查询结果中包括教师姓名、职称、课程名称和课程性质等个字段,要求结果中列出所有教师信息(即包括不是任何课程责任教师的教师信息)
select姓名,职称,课程名称,课程性质
•掌握用聚合函数计算统计检索结果。
二、实验设备(环境)及要求
1、环境要求:
硬件:PC(P 以上,128M以上内存)、因特网接入;
软件:在SQL Server 2000中
三、实验内容与步骤
1、一般简单查询
(1)不带条件的查询指定字段(考虑去掉和不去掉重复值两种情况)。
select distinct学号from选课
(18)带其他查询条件的两个关系的连接查询
select学生.学号,院系,姓名,性别,生源,课程编号,成绩
from学生join选课
on选课.学号=学生.学号
(19)多个关系(三个以上)的连接查询
select * from学生,课程,选课
where学生.学号=选课.学号
and课程.课程编号=选课.课程编号
select教师.姓名
数据库查询的实验报告

数据库查询的实验报告数据库查询的实验报告引言:数据库查询是一项重要的技术,它可以帮助我们从庞大的数据集中提取所需的信息。
本实验旨在探索数据库查询的原理和实践,通过实际操作和分析,深入了解数据库查询的过程和技巧。
实验目的:1. 理解数据库查询的基本概念和原理;2. 掌握使用SQL语句进行数据库查询的方法;3. 分析不同查询语句的执行效率和优化策略。
实验步骤:1. 数据库准备:选择一个合适的数据库系统,并创建一个包含适当表结构和数据的数据库。
2. 查询语句编写:根据实际需求,编写不同类型的查询语句,包括基本查询、条件查询、排序查询、聚合查询等。
3. 查询语句执行:使用数据库管理系统提供的查询工具,执行编写好的查询语句,并观察查询结果。
4. 查询结果分析:根据查询结果,分析查询语句的执行效率和查询结果的准确性。
5. 优化策略实施:对于执行效率较低的查询语句,尝试优化策略,如索引的使用、查询语句的重写等。
6. 优化效果评估:比较优化前后查询语句的执行效率,并分析优化策略的有效性。
实验结果与讨论:通过实验,我们发现数据库查询的过程中,查询语句的编写和优化对查询效率有重要影响。
以下是我们的实验结果和讨论。
1. 基本查询:基本查询是最简单的查询方式,通过SELECT语句从数据库中选择所需的字段。
我们发现,基本查询的执行效率较高,查询结果准确。
然而,在处理大量数据时,查询时间可能会增加。
为了提高效率,我们可以使用LIMIT子句限制返回的记录数。
2. 条件查询:条件查询是根据特定条件筛选数据的查询方式。
我们使用WHERE子句来指定查询条件,并发现查询结果的准确性和效率与查询条件的选择有关。
使用索引字段作为查询条件可以大大提高查询效率。
3. 排序查询:排序查询是根据指定字段的顺序对查询结果进行排序的方式。
我们使用ORDER BY子句来指定排序字段,并观察到排序查询的执行效率较高。
然而,对于大规模数据集,排序操作可能会导致性能下降。
数据库查询性能优化的实践案例及经验总结

数据库查询性能优化的实践案例及经验总结引言数据库查询是数据库应用中最常见也是最关键的操作之一,它直接影响到系统的性能和用户的体验。
对于大型数据库或者高并发系统来说,优化查询性能尤为重要。
本文将分享一些数据库查询性能优化的实践案例和经验总结,帮助读者更好地理解和应用于实际项目中。
一、合理设计索引索引是数据库查询优化的基础,它可以大幅提高数据检索的速度。
在设计索引时,有以下几点需要注意:1.选择合适的字段作为索引:应优先选择经常用于查询、过滤和排序的字段作为索引字段,避免不必要的全表扫描。
2.避免过多的索引:索引也会占用存储空间,并且会在插入、更新和删除数据时增加操作的开销。
因此,索引的数量应该适量,过多的索引反而会影响性能。
3.使用联合索引:对于多个字段组合查询的情况,可以使用联合索引来提高查询性能。
联合索引的列顺序也应该根据查询的频率进行合理排列。
实践案例:在一个电商网站的订单管理系统中,经常需要根据订单状态和用户ID查询订单。
优化方案是创建状态和用户ID的联合索引,使得查询按照这两个字段的组合进行优化。
二、合理拆分表和分区当数据库表中的数据量较大时,查询性能会受到影响。
为了提高查询效率,可以考虑将大表拆分成多个小表,或者使用分区表来优化查询。
1.拆分表:将一张大表按照业务逻辑和数据关联性进行拆分,每个子表都只包含部分数据。
这样可以减少查询时需要遍历的数据量,提高查询性能。
2.分区表:分区表是指将一张大表拆分成多个逻辑分区,每个分区可以存储一定范围的数据。
可以根据日期、地域、产品等特定字段进行分区,使得查询可以仅在需要的分区上进行,提高查询效率。
实践案例:在一个用户行为分析系统中,存在数量极大的用户行为记录表。
针对频繁查询某个时间段的用户行为数据的需求,通过按日期进行分区,将数据分散存储,从而提高查询性能。
三、适当使用缓存和特定查询方式1.缓存:通过在内存中缓存查询结果,可以避免频繁访问数据库。
数据分析及优化实验报告(3篇)

第1篇一、实验背景随着大数据时代的到来,数据分析已成为各个行业提高效率、优化决策的重要手段。
本实验旨在通过实际案例分析,运用数据分析方法对某一特定数据集进行深入挖掘,并提出相应的优化策略。
本实验选取了一个典型的电商数据集,通过对用户行为数据的分析,旨在提高用户满意度、提升销售业绩。
二、实验目的1. 熟练掌握数据分析的基本流程和方法。
2. 深入挖掘用户行为数据,发现潜在问题和机会。
3. 提出针对性的优化策略,提升用户满意度和销售业绩。
三、实验内容1. 数据收集与预处理实验数据来源于某电商平台,包含用户购买行为、浏览记录、产品信息等数据。
首先,对数据进行清洗,去除缺失值、异常值,确保数据质量。
2. 数据探索与分析(1)用户画像分析通过对用户性别、年龄、地域、职业等人口统计学特征的统计分析,绘制用户画像,了解目标用户群体特征。
(2)用户行为分析分析用户浏览、购买、退货等行为,探究用户行为模式,挖掘用户需求。
(3)产品分析分析产品销量、评价、评分等数据,了解产品受欢迎程度,识别潜力产品。
3. 数据可视化运用图表、地图等可视化工具,将数据分析结果直观展示,便于理解。
四、实验结果与分析1. 用户画像分析通过分析,发现目标用户群体以年轻女性为主,集中在二线城市,职业以学生和白领为主。
2. 用户行为分析(1)浏览行为分析用户浏览产品主要集中在首页、分类页和搜索页,其中搜索页占比最高。
(2)购买行为分析用户购买产品主要集中在促销期间,购买产品类型以服饰、化妆品为主。
(3)退货行为分析退货率较高的产品主要集中在服饰类,主要原因是尺码不合适。
3. 产品分析(1)销量分析销量较高的产品主要集中在服饰、化妆品、家居用品等类别。
(2)评价分析用户对产品质量、服务、物流等方面的评价较好。
五、优化策略1. 提升用户体验(1)优化搜索功能,提高搜索准确度。
(2)针对用户浏览行为,推荐个性化产品。
(3)加强客服团队建设,提高用户满意度。
实验报告_查询优化

一、实验目的1. 了解查询优化的基本概念和原理。
2. 掌握查询优化的常用方法和技巧。
3. 提高数据库查询效率,降低系统资源消耗。
二、实验环境1. 操作系统:Windows 102. 数据库:MySQL 5.73. 开发工具:Navicat for MySQL三、实验内容1. 查询优化原理2. 查询优化方法3. 查询优化实践四、实验步骤1. 查询优化原理(1)索引优化:索引是数据库查询中提高效率的关键因素。
通过为表创建索引,可以加快查询速度。
(2)查询语句优化:优化查询语句,包括使用合适的SQL语句、避免使用子查询、减少使用复杂的运算等。
(3)数据库设计优化:优化数据库设计,包括合理划分表结构、减少冗余字段、使用合适的字段类型等。
2. 查询优化方法(1)使用索引:为经常查询的字段创建索引,如主键、外键、常用查询字段等。
(2)简化查询语句:尽量使用简单的SQL语句,避免使用复杂的运算和子查询。
(3)合理使用JOIN操作:在需要使用JOIN操作时,尽量使用INNER JOIN,避免使用LEFT JOIN或RIGHT JOIN。
(4)使用LIMIT语句:在需要获取部分数据时,使用LIMIT语句限制查询结果数量。
(5)优化存储引擎:根据实际需求选择合适的存储引擎,如InnoDB、MyISAM等。
3. 查询优化实践(1)创建实验数据库和表```sqlCREATE DATABASE query_optimization;USE query_optimization;CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50),age INT,class VARCHAR(50));```(2)插入实验数据```sqlINSERT INTO students (id, name, age, class) VALUES(1, '张三', 20, '计算机科学与技术'),(2, '李四', 21, '计算机科学与技术'),(3, '王五', 22, '软件工程'),(4, '赵六', 23, '软件工程'),(5, '孙七', 20, '数学与应用数学');```(3)查询优化实践①未优化查询```sqlSELECT FROM students WHERE age > 20;```②优化查询```sqlSELECT id, name, age, class FROM students WHERE age > 20;```③使用索引优化查询```sqlCREATE INDEX idx_age ON students (age);SELECT id, name, age, class FROM students WHERE age > 20;```五、实验结果与分析1. 实验结果(1)未优化查询:查询结果为5条记录,耗时约0.1秒。
数据库实验九_查询优化

数据库原理实验报告实验名称查询优化实验环境硬件平台:Intel Core i5-3210M操作系统:Windows 8.1数据库管理系统(DBMS):MySQL Server 5.5实验内容及步骤1.由于实验需要对不同情况下的查询效果进行评估,因此进行此实验的先行条件是需要有大量的数据条目,前面实验手动添加的数据库表内容由于数目太少而无法适用于本次实验。
我们通过运用上一次实验中JDBC的知识,编写一个程序来自动向表stu5000中添加5000条项目,用来存放5000名学生的信息,而每一名学生的信息都由程序随机生成。
程序代码如下:import java.sql.*;import java.util.Random;public class mainclass {public static void Insert_stu5000(){Connection conn = null;try{//注册驱动程序Class.forName("com.mysql.jdbc.Driver").newInstance();//获取连接,root用户,口令空conn = DriverManager.getConnection("jdbc:mysql:"+ "//localhost:3306/test?useUnicode=true&"+ "characterEncoding=gbk","root","");System.out.println("数据库连接成功!");Statement st=conn.createStatement();int numint=1000;String num = new String();String name = new String();String sex = new String();int age;String dept = new String();for(int i=0;i<5000;i++){num = Integer.toString(numint);name = randomName(6);sex = randomSex();age = randomAge();dept = randomDept();st.executeUpdate("insert into haoran.stu5000"+ " values('"+num+"','"+name+"','"+sex+"',"+age+",'"+dept+"');");System.out.println("添加项目"+numint+"成功!");numint++;}conn.close();}catch(Exception e){System.out.println("Error : " + e.toString());}}public static final String randomName(int length) {Random randGen = null;char[] numbersAndLetters = null;if (length < 1) {return null;}if (randGen == null) {randGen = new Random();numbersAndLetters = ("abcdefghijklmnopqrstuvwxyz" +"ABCDEFGHIJKLMNOPQRSTUVWXYZ").toCharArray();}char [] randBuffer = new char[length];for (int i=0; i<randBuffer.length; i++) {randBuffer[i] = numbersAndLetters[randGen.nextInt(51)];}return new String(randBuffer);}public static final String randomSex() {Random randGen = new Random();if(randGen.nextBoolean())return "男";elsereturn "女";}public static final int randomAge() {Random randGen = new Random();return randGen.nextInt(20)+15;}public static final String randomDept() {Random randGen = new Random();int i = randGen.nextInt(3);if (i==0)return "CS";else if(i==1)return "SE";else if (i==2)return "IS";elsereturn "AI";}public static void main(String args[]){Insert_stu5000();System.out.println("运行结束!");}}2.开始进行查询优化的实验。
大型数据库实验报告

大型数据库实验报告《大型数据库实验报告》摘要:本实验旨在通过对大型数据库的实际操作和测试,评估其性能和稳定性,并提出优化建议。
实验使用了一款知名的大型数据库软件,并通过模拟大量数据的插入、查询和更新操作,对数据库进行了全面的测试和分析。
实验结果表明,该数据库在处理大规模数据时性能表现良好,但在某些特定场景下仍存在一些瓶颈和优化空间。
一、实验背景随着互联网和大数据时代的到来,大型数据库的应用越来越广泛。
企业、政府和科研机构等各行各业都需要处理海量数据,并对数据进行高效的存储、检索和分析。
因此,大型数据库的性能和稳定性成为了关注的焦点。
二、实验目的本实验旨在通过对大型数据库的实际操作和测试,评估其性能和稳定性,并提出优化建议。
通过模拟大规模数据的插入、查询和更新操作,对数据库进行全面的测试和分析,以验证其在处理大规模数据时的性能表现。
三、实验过程1. 实验环境搭建:搭建了一台高性能的服务器作为数据库服务器,并安装了知名的大型数据库软件。
2. 数据导入:通过自动生成数据或从外部数据源导入大量数据,模拟真实的数据场景。
3. 性能测试:对数据库进行插入、查询和更新等操作,并记录相应的性能指标,如响应时间、吞吐量等。
4. 稳定性测试:模拟并发访问、故障恢复等场景,测试数据库的稳定性和可靠性。
四、实验结果1. 性能评估:数据库在处理大规模数据时,插入和查询性能良好,但在更新操作时性能有所下降。
2. 稳定性评估:数据库在面对并发访问和故障恢复时表现稳定,但在某些特定场景下存在一些瓶颈和优化空间。
五、实验结论本实验通过对大型数据库的实际操作和测试,评估了其性能和稳定性,并提出了优化建议。
在未来的应用中,可以针对数据库的更新操作进行性能优化,并加强对特定场景的稳定性测试,以提高数据库在处理大规模数据时的性能和稳定性。
六、实验建议1. 针对更新操作进行性能优化,提高数据库的更新性能。
2. 加强对特定场景的稳定性测试,发现并解决数据库在特定场景下的瓶颈问题。
数据库查询优化实验报告_SQLServer2008

SQL Server 2008数据查询的优化方法研究摘要随着数据存储需求的日益增长,对关系数据的管理和访问就成为数据库技术必须解决的问题。
本文主要论述关系数据库查询优化技术,并从它的优化技术进行深入探讨,对系统实现做了一定的论述,并进行了部分的程序实现。
关键词:数据库查询系统优化引言SQLServer是是由微软公司开发的基于Windows操作系统的关系型数据库管理系统,它是一个全面的、集成的、端到端的数据解决方案,为企业中的用户提供了一个安全、可靠和高效的平台用于企业数据管理和商业智能应用。
目前,许多中小型企业的数据库应用系统都是用SQLServer作为后台数据库管理系统设计开发的。
设计一个应用系统并不难,但是要想使系统达到最优化的性能并不是一件容易的事。
根据多年的实践,由于初期的数据库中表的记录数比较少,性能不会有太大问题,但数据积累到一定程度,达到数百万甚至上千万条,全面扫描一次往往需要数十分钟,甚至数小时。
20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。
如果用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟。
而且我们知道,目前数据库系统应用中,查询操作占了绝大多数,查询优化成为数据库性能优化最为重要的手段之一。
影响查询效率的因素SQLServer处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给SQLServer的查询优化器,查询优化器通过检查索引的存在性、有效性和基于列的统计数据来决定如何处理扫描、检索和连接,并生成若干执行计划,然后通过分析执行开销来评估每个执行计划,从中选出开销最小的执行计划,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。
所以,SQLServer中影响查询效率的因素主要有以下几种:1.没有索引或者没有用到索引。
索引是数据库中重要的数据结构,使用索引的目的是避免全表扫描,减少磁盘I/O,以加快查询速度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库实验报告题目:查询优化:军毅日期:2016-5-14实验目的1.明确查询优化的重要性;2.理解代数优化与物理优化方法;3.学习在查询中使用较优的方法。
实验平台1.OS:Windows XP2.DBMS:SQLServer2008、VC6.0(或者visio studio)3.IDE:Eclipse实验用时:两次上机实验容一、数据库的恢复操作(导入数据)1.在【程序】中打开Microsoft SQL Server Management Studio。
新建数据库“FoodmartII”2.在数据库FoodmartII 上右键单击,选择【任务】【导入数据】。
3.在“导入和导出向导”对话框中,数据源选择“Microsoft Access”,单击“文件名”后面的【浏览】按钮,按你的存储路径找到Foodmart.mdb 文件。
单击【下一步】。
4.在“选择目标”部分,注意目标数据库的名称应为刚才建立的“FoodmartII”。
5.选择复制一个或多个数据库表。
6.在接下来的对话框中选择可能用到的数据表,根据需要勾选。
单击【下一步】并“立即执行”,成功导入数据后可以看到如下对话框。
单击【关闭】按钮。
观察数据库引擎中的FoodmartII,看一看数据库中有哪些表,表中有哪些数据,是否包含索引,是否建立了视图?二、理解索引对查询的影响1.新建查询,在查询窗口中输入一个查询命令。
2.在【查询】菜单中选择【显示估计的查询计划】,注意观察查询窗口下面的执行计划窗口。
执行该查询(使用工具栏上的“执行”按钮或者【查询】菜单上的“执行”命令),观察右侧【属性】窗口中“返回的行数”“占用时间”等关键信息。
3.为Customer 表建立索引。
建立Customer_id 列的非聚集索引。
执行查询,在【属性】窗口中观察查询时间。
三、分析查询条件对查询执行的影响1.新建查询,输入查询命令,再按上面的步骤,观察“估计的查询计划”和“占用时间”时间等信息,比较查询条件对查询执行的影响。
2.观察查询命令,在emplyee 表建立salary 列的非聚集索引。
再次观察上面这个查询命令的查询计划和执行情况。
四、分析连接条件对连接操作的影响1.对比下面查询的查询计划和查询执行情况2.在employee 表上对employee_id 列建立聚集索引.观察查询计划和执行情况的变化.五、视图的使用1.执行下面的查询命令,观察查询计划和执行情况。
2.建立视图“cust_prod_sales”,由product,customer , sales_fact_1998三个表组成,其中包含查询常用的列(选取的列可以多于查询Q51),再执行下面的查询,比较两个查询的执行情况。
六、查询优化测试1.数据准备,导入TPCH 数据集。
数据导入方法同前面Footmark 的导入类似。
2.对以下查询进行优化,写出你的优化方法. 实际执行这个查询, 记录你的执行时间(毫秒).实验中出现的问题实验容一、数据库的恢复操作(导入数据)1.在【程序】中打开Microsoft SQL Server Management Studio。
新建数据库“FoodmartII”打开Microsoft SQL Server Management Studio,如图:新建数据库“FoodmartII”,如图:2.在数据库FoodmartII 上右键单击,选择【任务】【导入数据】。
如图:3.在“导入和导出向导”对话框中,数据源选择“Microsoft Access”,单击“文件名”后面的【浏览】按钮,按你的存储路径找到Foodmart.mdb 文件。
单击【下一步】。
如图,选择“Microsoft Access”,找到Foodmart.mdb 文件:4.在“选择目标”部分,注意目标数据库的名称应为刚才建立的“FoodmartII”。
如图,选择我刚刚建立的“FoodmartII”数据库:5.选择复制一个或多个数据库表。
如图,勾选“复制一个或多个数据库表”:在接下来的对话框中选择可能用到的数据表,根据需要勾选。
我选择了全部的数据表,并单击下一步,如图:单击【下一步】后,选择“立即执行”,如图:如下图,可看到导入成功,单击【关闭】按钮:观察数据库引擎中的FoodmartII,我们可以看到数据库中有哪些表,例如account表,category表,currency表等,如图:我们点击cureency表中的索引,可以看到初始时并没有任何索引,如图:右键cuurency表,选择“编辑前200行”,可以看到表中的数据,如图:二、理解索引对查询的影响1.新建查询,在查询窗口中输入一个查询命令。
select customer_idfrom customerwhere customer_id>60002.在【查询】菜单中选择【显示估计的查询计划】,注意观察查询窗口下面的执行计划窗口。
如图,表扫描占100%:执行该查询(使用工具栏上的“执行”按钮或者【查询】菜单上的“执行”命令),观察右侧【属性】窗口中“返回的行数”“占用时间”等关键信息。
如图,我们可以看到返回的行数为4281行,占用的时间大约为2秒多:3.为Customer 表建立索引。
建立Customer_id 列的非聚集索引,如下图所示。
输入命令:create index ID_noncluson customer(customer_id);建立非聚集索引:在customer表中查看索引,可以看到我们已经建立好的非聚集索引,如图:建立好索引后,仍使用如下查询命令:select customer_idfrom customerwhere customer_id>6000在菜单栏中的“查询”下点击“显示估计的执行计划”,观察新的查询计划,如图,新的执行计划索引查找占100%:执行该查询,在【属性】窗口中观察查询时间。
如图,我们可以看到,建立好索引再进行查询,占用时间减少到不足1秒:三、分析查询条件对查询执行的影响1.新建查询,输入查询命令,再按上面的步骤,观察“估计的查询计划”和“占用时间”时间等信息,比较查询条件对查询执行的影响。
Q1:select customer_idfrom customerwhere customer_id=2621;初始情况下未建立索引,输入命令后,在菜单栏中的“查询”项下选择“显示估计的执行计划”,表扫描占100%:然后点击执行,在属性栏中可以看到,返回的行数为1,占用的时间为7秒多,如图:然后建立非聚集索引,在新建查询中输入上述命令,选择“显示估计的执行计划”,如图,索引查找占100%:点击“执行”,在属性栏中可以看到,返回的行数为1,占用的时间为2秒多,如图:再把where 条件分别改写为:customer_id>2621 和customer_id<>2621,观察他们有什么异同。
总结查询命令书写的经验。
Q2:select customer_idfrom customerwhere customer_id>2621;显示估计的执行计划,表扫描占100%:点击“执行”,在属性栏中可以看到,返回的行数为7650行,占用的时间为3秒多,如图:建立非聚集索引后,显示估计的执行计划,可以看到,索引查找占100%:点击“执行”后,在属性栏中可以看到返回的行数为7650行,占用的时间为2秒多,如图:Q3:select customer_idfrom customerwhere customer_id!=2621;这里我使用的是!=而不是<>,显示估计的执行计划,表扫描占100%,如图:点击“执行”,在属性栏中可以看到,返回的行数为10260行,占用时间为3秒多,如图:建立索引后,显示估计的执行计划,可以看到,索引扫描占100%:点击“执行”,属性栏中可以看到,返回的行数为10260行,占用的时间为2秒多,如图:可以知道,不等于操作符是永远用不到索引的,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到“!=”,“<>”时,会转而用全表扫描,对a<>0的条件应写为a<0 or a>0.2.观察下面的查询命令:select full_name,salaryfrom employeewhere salary>30000;在未建立索引的情况显示估计的执行计划,表扫描占100%,如图:返回行数为8行,时间大约3秒多,如图:在emplyee 表建立salary 列的非聚集索引。
再次观察上面这个查询命令的查询计划和执行情况。
RID查找占87%,索引查找占13%,如图:执行后,返回行数为8,占用时间为2秒多,如图:(1)请写出你对以上容的分析或得到的经验。
尽量少用不等于查询条件当需要查找的数据特别多时,使用全表扫描或许比索引扫描还要好(2)试一试, 你还能得到哪些查询命令书写的经验? (不同查询语句导致不同查询计划)当插入的数据为数据表的记录数量10%以上时,首先需要删除该表的索引来提高数据的插入效率,当数据全部插入后再建立索引。
避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描,举例:低效:select * from table where salary*12>25000高效:select * from table where salary>25000/12索引列上用>=替代>,举例:高效:select * from table where Deptno>=4低效:select * from table where Deptno>3四、分析连接条件对连接操作的影响1.对比下面查询的查询计划和查询执行情况Q41:Select employee.employee_id,full_name,employee.salary,pay_date, salary_paidfrom employee,salary显示估计的执行计划,如图,嵌套循环96%,表假脱机4%:Q42:select employee.employee_id,full_name,employee.salary,pay_date, salary_paidfrom employee,salarywhere employee.employee_id=salary.employee_id显示估计的执行计划,哈希匹配50%,表扫描各占41%和9%:点击“执行”,返回行数为21252行,占用时间3秒多:Q43:Selectemployee.employee_id,full_name,employee.salary,pay_date,salary_paidfrom employee,salarywhere employee.employee_id>salary.employee_id显示估计的执行计划,嵌套循环占73%,索引假脱机27%:但是,点击“执行”,因为数据溢出,无法完成。