spss多元回归分析案例讲解
SPSS多元回归分析实例
t i e an dl l t 多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y 与各自变量x j (j=1,2,3,…,n)之间的多元线性回归模型:其中:b 0是回归常数;b k (k =1,2,3,…,n)是回归参数;e 是随机误差。
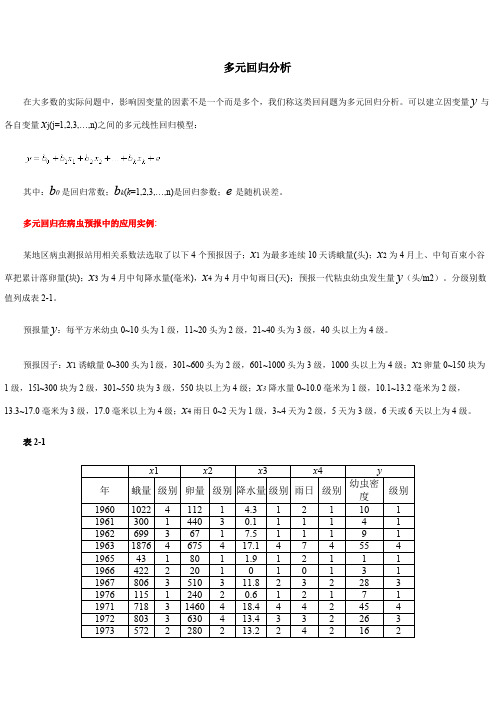
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x 1为最多连续10天诱蛾量(头);x 2为4月上、中旬百束小谷草把累计落卵量(块);x 3为4月中旬降水量(毫米),x 4为4月中旬雨日(天);预报一代粘虫幼虫发生量y (头/m2)。
分级别数值列成表2-1。
预报量y :每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x 1诱蛾量0~300头为l 级,301~600头为2级,601~1000头为3级,1000头以上为4级;x 2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x 3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x 4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x 1x 2x 3x 4y 年 蛾量 级别 卵量 级别 降水量 级别 雨日 级别 幼虫密度级别1960102241121 4.31211011961300144030.111141196269936717.511191196318764675417.14745541965431801 1.9121111966422220101013119678063510311.82322831976115124020.612171197171831460418.444245419728033630413.433226319735722280213.224216219742641330342.243219219751981165271.84532331976461214017.515328319777693640444.7432444197825516510101112数据保存在“DATA6-5.SAV”文件中。
SPSS多元回归分析报告实例
多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
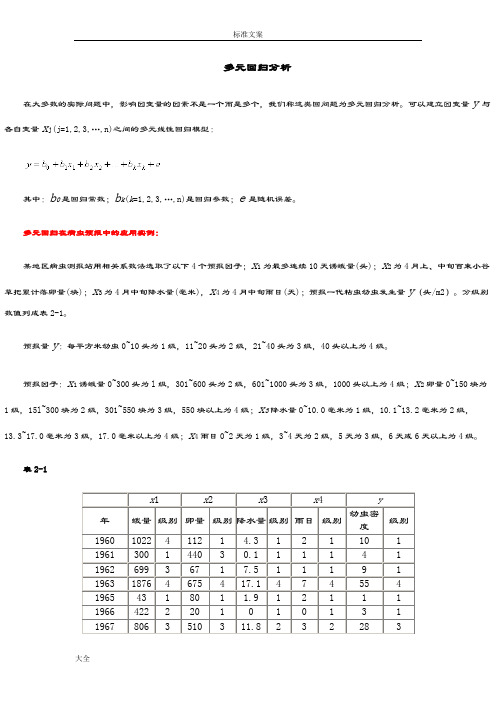
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3数据保存在“DATA6-5.SAV”文件中。
1)准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。
SPSS中多元回归分析实例解析

SPSS中多元回归分析实例解析多元回归分析是一种统计方法,用于研究一个因变量与多个自变量之间的关系。
在SPSS中,可以使用该方法来构建、估计和解释多元回归模型。
下面将以一个实例来解析SPSS中的多元回归分析。
假设我们想要研究一个教育投资项目的效果,该项目包括多个自变量,例如教育资金、教育设施、学生人数等,并且我们希望预测该项目对学生学习成绩的影响。
首先,我们需要准备好数据并导入SPSS中。
数据应包含每个教育投资项目的多个观测值,以及与之相关的自变量和因变量。
例如,可以将每个项目作为一个观测值,并将教育资金、教育设施、学生人数等作为自变量,学生学习成绩作为因变量。
在SPSS中,可以通过选择“Analyze”菜单中的“Regression”选项来打开回归分析对话框。
然后,选择“Linear”选项来进行多元回归分析。
接下来,可以将自变量和因变量添加到对话框中。
在自变量列表中,选择教育资金、教育设施、学生人数等自变量,并将它们移动到“Independent(s)”框中。
在因变量框中,选择学生学习成绩。
然后,点击“OK”按钮开始进行分析。
SPSS将输出多元回归的结果。
关键的统计指标包括回归系数、显著性水平和拟合度。
回归系数表示每个自变量对因变量的影响程度,可以根据系数的大小和正负来判断影响的方向。
显著性水平表示自变量对因变量的影响是否显著,一般以p值小于0.05为标准。
拟合度指示了回归模型对数据的拟合程度,常用的指标有R方和调整后的R方。
在多元回归分析中,可以通过检查回归系数的符号和显著性水平来判断自变量对因变量的影响。
如果回归系数为正且显著,表示该自变量对因变量有正向影响;如果回归系数为负且显著,表示该自变量对因变量有负向影响。
此外,还可以使用其他方法来进一步解释和验证回归模型,例如残差分析、模型诊断等。
需要注意的是,在进行多元回归分析时,需要满足一些前提条件,例如自变量之间应该独立、与因变量之间应该是线性关系等。
多元回归分析SPSS案例39328讲课讲稿

多元回归分析S P S S 案例39328多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3 1976 115 1 240 2 0.6 1 2 1 7 1 1971 718 3 1460 4 18.4 4 4 2 45 4数据保存在“DATA6-5.SAV”文件中。
多元回归分析SPSS案例
多元回归分析在大多数得实际问题中,影响因变量得因素不就就是一个而就就是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间得多元线性回归模型:其中:b0就就是回归常数;b k(k=1,2,3,…,n)就就是回归参数;e就就是随机误差。
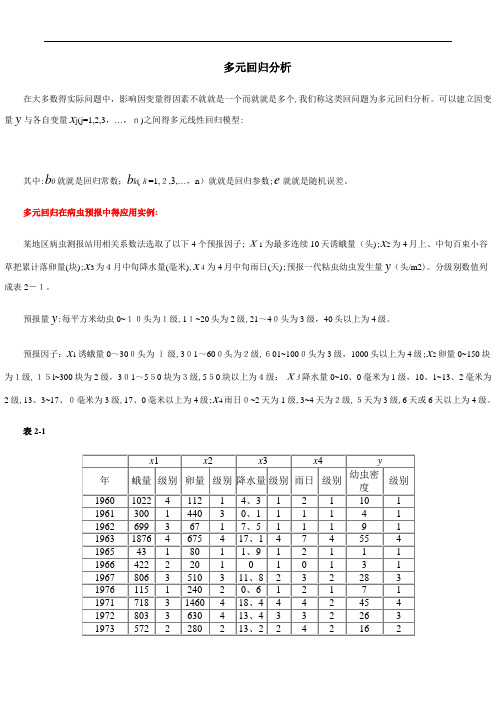
多元回归在病虫预报中得应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10、0毫米为1级,10、1~13、2毫米为2级,13、3~17、0毫米为3级,17、0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1数据保存在“DATA6-5、SAV”文件中。
1)准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”与“幼虫密度”变量,并输入数据。
再创建蛾量、卵量、降水量、雨日与幼虫密度得分级变量“x1”、“x2”、“x3”、“x4”与“y”,它们对应得分级数值可以在SPSS数据编辑窗口中通过计算产生。
编辑后得数据显示如图2-1。
图2-1或者打开已存在得数据文件“DATA6-5、SAV”。
2)启动线性回归过程单击SPSS主菜单得“Analyze”下得“Regression”中“Linear”项,将打开如图2-2所示得线性回归过程窗口。
SPSS多元回归分析实例共11页

多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3 1976 115 1 240 2 0.6 1 2 1 7 1 1971 718 3 1460 4 18.4 4 4 2 45 4 1972 803 3 630 4 13.4 3 3 2 26 3数据保存在“DATA6-5.SAV”文件中。
spss多元回归分析案例
企业管理对居民消费率影响因素的探究---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。
居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。
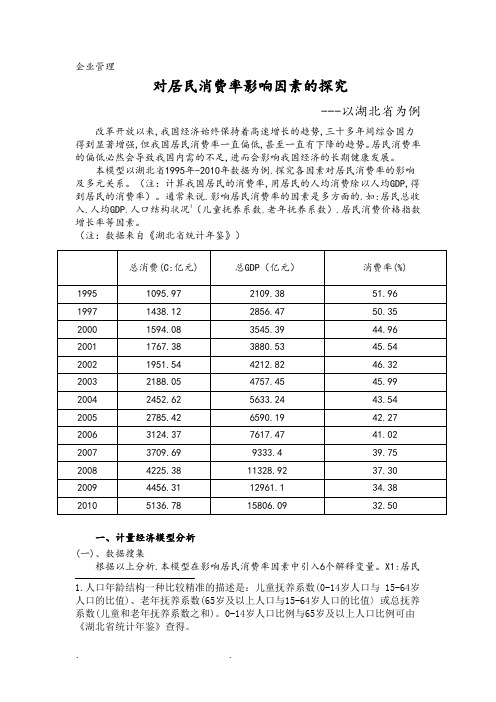
本模型以湖北省1995年-2010年数据为例.探究各因素对居民消费率的影响及多元关系。
(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。
通常来说.影响居民消费率的因素是多方面的.如:居民总收入.人均GDP.人口结构状况1(儿童抚养系数.老年抚养系数).居民消费价格指数增长率等因素。
(注:数据来自《湖北省统计年鉴》)总消费(C:亿元) 总GDP(亿元)消费率(%)1995 1095.97 2109.38 51.96 1997 1438.12 2856.47 50.35 2000 1594.08 3545.39 44.96 2001 1767.38 3880.53 45.54 2002 1951.54 4212.82 46.32 2003 2188.05 4757.45 45.99 2004 2452.62 5633.24 43.54 2005 2785.42 6590.19 42.27 2006 3124.37 7617.47 41.02 2007 3709.69 9333.4 39.75 2008 4225.38 11328.92 37.30 2009 4456.31 12961.1 34.38 2010 5136.78 15806.09 32.50一、计量经济模型分析(一)、数据搜集根据以上分析.本模型在影响居民消费率因素中引入6个解释变量。
X1:居民1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。
spss多元回归分析案例讲解

分析Coefficient表
四、得出各个模型中偏相关系数值: 1、B( 偏回归系数) ( 第2 列) 是控制了其他变量 后得到的。 2、除了两个模型的常数项系数显著性水平 >0.05,不影响。其他的系数的显著性水平为0. 000, 它们都<0. 05, 故属于小概率事件, 即拒 绝回归系数为零的假设, 即每个回归方程都有 意义。
y=-15038.574+1.365X1 +5859.585X219.553X3+154.698X4+539.642X5 注释:X1 初始工资、X2工作种类、X3过去经验、X4受 雇时间、X5受教育程度 注意:B( 偏回归系数) , 有一个缺点就是单位数量级不 一致时, 对它的比较毫无意义。 如:初始工资的单位为1, 而工作种类的单位为1 000 , 显然这时工作种类前面的回归系数可能很小。 故对它需要进行改进, 这就是Beta 系数。把所有 变量都事先进行标准化,消除偏回归系数带来的数 量单位的影响。
举例量474.所给变量共有6个:当前工资、初始 工资、工作种类、过去经验、受雇时间、受 教育程度。 准备建立一个以当前工资为因变量,其他变量 为自变量的回归方程。 判断哪些变量进入方程,并且给出对应系数。
1、选变量
要建立一个模型首先要选择变量,解释变量 和因变量之间要有一定的关系。 方法:散点图直接判断相关性和偏相关性系 数。 所要判断的变量:初始工资、工作种类、过 去经验、受雇时间、受教育程度
分析 ANOVA表
二、判断每一步模型总显著性 1、方差分析表显示了回归拟合过程中每一步的 方差分析结果。 2、F值的Sig.值均<0.001.每个模型都拒绝回归 系数均为0的假设,每个方程都是显著的。也 就是说一个新的变量进入模型后,模型仍然 显著,该模型不剔除某个变量,进入模型的 变量都包括。(逐步回归法)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
spss多元回归分析案例讲解
举例说明
本例给出的是某企业职员调查的数据。共有样 本量474.所给变量共有6个:当前工资、初始 工资、工作种类、过去经验、受雇时间、受 教育程度。
准备建立一个以当前工资为因变量,其他变量 为自变量的回归方程。
育程度不相关的假设。偏相关系数为0.161.变量和 因变量是相关的。 ❖ 其他分析变量操作同,初步判断得出变量均可进入 模型。
spss多元回归分析案例讲解
spss多元回归分析案例讲解
2、选数据
❖ 我们建立回归模型是在若干假定前提之下的, 即对数据是有要求的。因变量数据的要求。
❖ (1)是否满足“残差的方差齐性”要求
spss多元回归分析案例讲解
❖ 向后回归:将自变量一次纳入回归,然后根 据标准删除一个最不显著者,再做一次回归 判断其余变量的取舍,直至保留者都达到要 求。 逐步回归Stepwise:是向前回归法和向后回 归法的结合。
❖ 首先按自变量对因变量的贡献率进行排序, 按照从大到小的顺序选择进入模型的变量。 每将一个变量加入模型,就要对模型中的每 个变量进行检验,剔除不显著的变量,然后 再对留在模型中的变量进行检验。直到没有 变量可以纳入,也没有变量可以剔除为止。
spss多元回归分析案例讲解
spss多元回归分析案例讲解
逐步回归中不在方程中变量
一、判断模型中各个要进入变量的系数显著性: 1、注释中是模型已有的变量,表中是排除在回归方
程外变量。 2、举例分析第一步:
方程中已有的(第一个进入)变量是初始工资,还 有4个未进入模型。在这个方程的基础上,如果4个 变量中每一个单独进入这个方程,会形成一个新的 二元解释变量方程,这个二元方程的统计量结果如 表。通过判断Partial Correlation绝对值来确定哪个 是贡献率最大的,从而这个变量先进入模型。 3、第3 列是针对每一个变量前面的系数为零的假设的 t 检验值, 第四列给出了这个检验结果。从中可以看 出,sig.值均<0.05。故拒绝系数为零的假设, 即每一 个变量都对因变量s有pss多贡元回献归分,所析案以例讲都解 不剔除。 4、结论:第二个进入方程的变量是0.372的职务分类。
spss多元回归分析案例讲解
进行回归操作
❖ 进行回归操作:Analyze-Regression-Linear 选择自变量和因变量
❖ 选择回归方法: Stepwise
spss多元回归分析案例讲解
设置操作
Statistics: 系统默认选项:1、Estimates(输出回归系数,
标准化回归系数,回归系数为0的假设T值等) 2、 Model fit(要引入模型的和
spss多元回归分析案例讲解
简要回顾一些计量经济学知识
❖ T检验,F检验。都是对于系数为0假设检验。 ❖ T检验针对的假设是某一个系数为0。分布。 ❖ F检验针对的假设是所有的回归系数均为0.总显著性
检验。分布。 ❖ Sig.值significance即eviews中的p值。小于设置的
显著性水平如0.05,则拒绝原假设,统计量显著。 ❖ R2、调整R2 指标揭示拟合程度。随着进入模型的变
❖ 检验偏相关系数,控制其他的变量对两个变 量相关关系的影响。
❖ 由偏相关系数和对应T值可以判断,这些变量 和因变量的有关,可以建立一个以它们为自 变量的回归模型。
spss多元回归分析案例讲解
偏相关系数检验线性关系
❖ 操作:Analyze-Correlate-Partial Correlation ❖ 选择分析变量:当前工资、受教育程度 ❖ 选择控制变量:其他变量 ❖ 结论:T值的显著性水平为0,拒绝当前工资和受教
❖
方法:散点图
❖ 操作在后面做回归模型建立时一同分析。
spss多元回归分析案例讲解
P—P图检验正态性
❖ (2)因变量数据是否满足正态性要求 ❖ 方法:P—P图。所有点聚集在直线上,则说
明该变量的数据分布是服从于所要检测的分 布的
spss多元回归分析案例讲解
P—P图检验正态性
❖ 操作:Analyze-Descriptive Statistics❖ P-Pplots ❖ 检验变量:当前工资 ❖ 检验分布:正态分布Normal ❖ 结论:满足正态性假设要求
spss多元回归分析案例讲解
spss多元回归分析案例讲解
3、进行回归
❖ 介绍回归方法: ❖ Enter:强行进入法。所有变量直接全部进入
模型。只有一个模型。ຫໍສະໝຸດ ❖ 向前回归:根据自变量对因变量的贡献率,
首先选择一个贡献率最大的自变量进入,一 次只加入一个进入模型。然后,再选择另一 个最好的加入模型,直至选择所有符合标准 者全部进入回归。
散点图检验线性关系
❖ 散点图可以很直观地判断是否存在线性关系。 ❖ 操作:Graphs-Legacy Dialogs-Scatter/Dot-
Simple Scatter
spss多元回归分析案例讲解
结论:当前工资 和初始工资存在 线性关系。
spss多元回归分析案例讲解
偏相关系数检验线性关系
❖ 各因素之间有相互作用,仅仅看每个自变量 分别和因变量之间觉得相关系数不能反映出 各个变量之间的真实情况。
判断哪些变量进入方程,并且给出对应系数。
spss多元回归分析案例讲解
1、选变量
❖ 要建立一个模型首先要选择变量,解释变量 和因变量之间要有一定的关系。
❖ 方法:散点图直接判断相关性和偏相关性系 数。
❖ 所要判断的变量:初始工资、工作种类、过 去经验、受雇时间、受教育程度
spss多元回归分析案例讲解
SPSS多元线性回归 模型建立——基于
逐步回归法
spss多元回归分析案例讲解
多元线性回归模型
回归:区别相关。因变量对解释变量的依赖关系,意 义在于通过已知后者的值去预测前者的均值。
线性:用于研究一种特殊的关系,即用直线或多维直 线描述其依赖关系。
多元:解释变量大于等于两个。 建立一个模型: Y = 0 + 1 X 1 + 2 X 2 + ......... + i X i 确定一些标准,判断进入的变量,和得出对应的系数。
要从模型中剔除的变量, 每一步模型R2 调整 R2 、ANOVA方差分析表。
spss多元回归分析案例讲解
设置操作
❖ Plots制图,检查方差齐性, ❖ Y:ZRESID(标准化残差) ❖ X:ZPRED(标准化预测值)
spss多元回归分析案例讲解
❖ 残差的方差齐性 ❖ 分析依据:如果 ❖ 它的大部分都落 ❖ 在( - 3, 3) 范围之 ❖ 内, 就可以认为 ❖ 它满足这个条件。