南邮编译原理报告实验二
南邮数据结构实验二

实验报告
( 2016 / 2017 学年第一学期)
课程名称数据结构A
实验名称二叉树的基本操作
及哈夫曼编码译码系统的实现
实验时间2017 年 5 月 1 日指导单位计算机学院计算机科学与技术系
指导教师邹志强
学生姓名吴爱天班级学号B15040916 学院(系) 计算机学院专业信息安全
实验报告
之后三步输出,对应的是三种遍历方式,应该输出的测试结果是:
先序:68 69 72 70 74 71 67 75 65 66
中序:72 69 74 70 71 75 67 68 65 66
后序:72 74 75 67 71 70 69 66 65 68
实验结果符合预期。
对于哈夫曼建树操作我自己又按照自己的想法重写了,里面也去学习了C++的字典类MAP,这个类非常好用,可以简单粗暴地提供一些方法和迭代器,让你将关键字和值绑定,这样我每新加入一个字母的数据块,我就可以记录下这对组合,不用之后搜索和解码的时
之后进行编码,其实也是一个搜索的过程,主要是调用了一个
测试:。
南邮微机原理第二次实验报告用户登录验证程序的实现

CODE ENDS
END BEG
实验截图:
实验报告
四、实验小结(一)实验中遇来自的主要问题及解决方法在题目设计时困难重重,总出现各种各样的问题,后来用Debug的方式,最终程序能够顺利运 行,这个过程很艰辛,因为不知道哪里会有错误,一句句仔细的查看,最后程序才跑通。其实这道题 的难点就在如何将用H输入的用户统和密码与已经设龙好的进行对比。通过分支结构判断输入的是否 正确,让用户有一个好的人机交互体验。仅仅一道题也是设计了有一天之久,在设计时有时想不起来 某些知识点导致不能正常编程,因此在查书和同学交流过后把程序设计了岀来,仅仅是字符串中字符 数的统计逻辑就花了很长时间思考,请教了老师后有了思路。
AU
实验报告
(2020/2021学年 第 一 学期)
课程名称
微型计算机原理与接口技术
实验名称
用户登录验证程序的实现
实验时间
2020年12月10日
指导单位计算机学院系统与网络教学中心
指导教师盛碧云
学生姓名
学院(系)理学院
班级学号
专 业
实验报告
实验名称
用户登录验证程序的实现指导教师
盛碧云
实验类型
设计实验学时2实验时间
MOV DS.AX
MOV AH.9
MOV DX.OFFSETMESG1
INT21H
MOV AH.OAH
MOV DX.OFFSET BUF3
INT21H
MOV BX.OFFSET BUF1
MOV SLOFFSET BUF3+2
MOV CX,USNM
NEXT1:MOVALJBX]
CMP [SIJ.AL
JNZ ERROR
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
南京邮电大学操作系统实验报告

通信与信息工程学院2015 / 2016学年第二学期实验报告课程名称:操作系统实验名称:1、LINUX及其使用环境2、进程管理3、进程间通信4、文件的操作和使用班级学号专业电子信息工程学生姓名指导教师赵建立实验名称试验一 LINUX及其使用环境实验类型验证实验学时1实验时间2016.6.2一、实验目的和要求1、了解UNIX的命令及使用格式。
2、熟悉UNIX/LINUX的常用基本命令。
3、练习并掌握UNIX提供的vi编辑器来编译C程序。
4、学会利用gcc、gdb编译、调试C程序。
二、实验环境Windows XP + VMWare + RedHat Enterprise Linux(RHEL) 4三、实验原理及内容1、熟悉LINUX的常用基本命令。
如ls、mkdir、grep等,学会使用man、help等其它命令,掌握vi编辑器的使用。
(1)显示目录文件 ls例:ls -al 显示当前目录下的所有文件(2)建新目录 mkdir例:mkdir test 新建一个test目录(3)删除目录rmdir(4)改变工作目录位置 cd例:cd test 更改工作目录至test目录下(5)显示当前所在目录pwd(6)查看目录大小du(7)文件属性的设置 chmod(8)命令在线帮助 man2、设计一个实现文件拷贝功能的shell程序。
(1)在文本编辑器里输入shell程序:#!/bin/shecho “please enter source file:”read soucecho please enter destination file:”read destcp $souc $destls $dest将程序保存在主目录下,命名为shell.(2)打开终端,输入ls -l,显示目录下所有文件的许可权、拥有者、文件大小、修改时间及名称。
输入 ./shell,运行shell程序。
输入源文件hello.c,目标文件B13011206.c。
编译原理实验报告模版-语义分析 (2) (1)
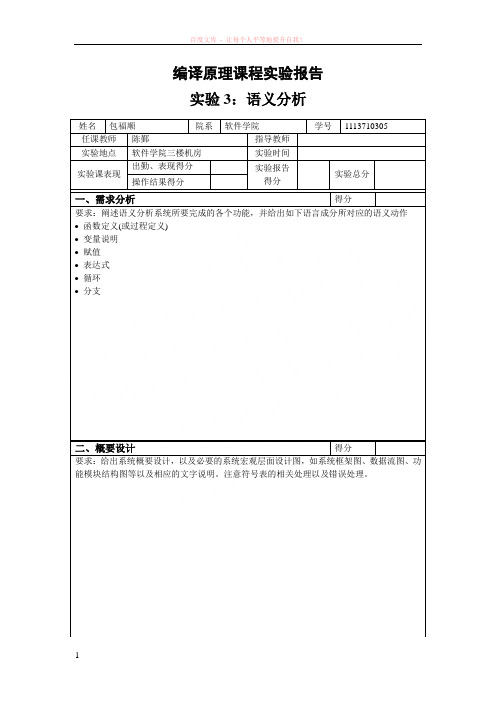
编译原理课程实验报告
实验3:语义分析
姓名包福顺院系软件学院学号1113710305 任课教师陈鄞指导教师
实验地点软件学院三楼机房实验时间
实验课表现出勤、表现得分实验报告
得分
实验总分操作结果得分
一、需求分析得分
要求:阐述语义分析系统所要完成的各个功能,并给出如下语言成分所对应的语义动作•函数定义(或过程定义)
•变量说明
•赋值
•表达式
•循环
•分支
二、概要设计得分
要求:给出系统概要设计,以及必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
注意符号表的相关处理以及错误处理。
三、详细设计及实现得分
要求:对如下工作进行展开描述
(1) 核心数据结构的设计
(2) 主要功能函数说明
(3) 程序核心部分的程序流程图
四、实验结果及分析得分
要求:对实验结果进行描述和分析,基本内容包括:
(1)针对一测试程序输出其语义分析结果;
(2)输出针对此测试程序对应的语义错误报告;
(3)输出针对此测试程序经过语义分析后的符号表;
(4)对实验结果进行分析。
注:其中的测试样例需先用已编写的词法分析程序进行处理。
指导教师评语:
日期:。
编译原理实验报告

编译原理实验报告一、实验概述本次实验旨在设计并实现一个简单的词法分析器,即实现编译器的第一个阶段,词法分析。
词法分析器将一段源程序代码作为输入,将其划分为一个个的词法单元,并将其作为输出。
二、实验过程1.设计词法规则根据编程语言的规范和所需实现的功能,设计词法规则,以明确规定如何将源程序代码分解为一系列的词法单元。
2.实现词法分析器采用合适的编程语言,根据所设计的词法规则,实现词法分析器。
词法分析器的主要任务是读入源程序代码,并将其根据词法规则进行分解,生成对应的词法单元。
3.测试词法分析器设计测试用例,用于检验词法分析器的正确性和性能。
测试用例应包含各种情况下的源程序代码。
4.分析和修正错误根据测试过程中发现的问题,分析产生错误的原因,并进行修正。
重复测试和修正的过程,直到词法分析器能够正确处理所有测试用例。
三、实验结果我们设计了一个简单的词法分析器,并进行了测试。
测试用例涵盖了各种情况下的源程序代码,包括正确的代码和错误的代码。
经过测试,词法分析器能够正确处理所有的测试用例。
词法分析器将源程序代码分解为一系列的词法单元,每个词法单元包含了单词的种类和对应的值。
通过对词法单元的分析,可以进一步进行语法分析和语义分析,从而完成编译过程。
四、实验总结通过本次实验,我深入了解了编译原理的词法分析阶段。
词法分析是编译器的第一个重要阶段,它将源程序代码分解为一个个的词法单元,为后续的语法分析和语义分析提供基础。
在实现词法分析器的过程中,我学会了如何根据词法规则设计词法分析器的算法,并使用编程语言实现词法分析器。
通过测试和修正,我掌握了调试和错误修复的技巧。
本次实验的经验对我今后的编程工作有很大帮助。
编译原理是计算机科学与技术专业的核心课程之一,通过实践能够更好地理解和掌握其中的概念和技术。
我相信通过进一步的学习和实践,我能够在编译原理领域取得更大的成果。
汇编 南邮 实验报告

汇编南邮实验报告一、实验目的了解汇编语言的基本概念和基本语法,学会使用汇编指令编写简单的汇编程序。
二、实验内容1. 学习汇编语言的基本概念和基本语法;2. 编写一个简单的汇编程序。
三、实验原理汇编语言是计算机中最底层的一种语言,它直接操作计算机的硬件资源。
汇编语言使用面向机器的指令,利用指令的组合和操作数的变化实现各种功能。
在编写汇编程序时,需要注意寄存器的使用、内存的操作以及指令执行流程的控制。
四、实验步骤1. 学习汇编语言的基本概念和基本语法,了解常用的寄存器、指令和标志位等;2. 编写一个简单的汇编程序,要求实现将一个字节的数据存入内存中,并读取出来进行显示的功能。
五、实验代码assemblySECTION .textGLOBAL _start_start:mov al, 65 ; 将字节数据65存入al寄存器mov byte [data], al ; 将al寄存器中的值存入内存中的data变量mov dl, [data] ; 从内存中读取data变量的值到dl寄存器add dl, 30h ; 将dl寄存器的值加上30h,将结果存回dl寄存器add dl, 0 ; 非必要指令,用于演示指令执行流程的控制add dl, 0 ; 非必要指令,用于演示指令执行流程的控制add dl, 0 ; 非必要指令,用于演示指令执行流程的控制mov ah, 0eh ; 设置显示模式int 10h ; 控制显示mov al, 0 ; 程序退出mov ah, 0x4cint 0x21SECTION .datadata db 0 ; 定义一个字节的变量data六、实验结果运行该汇编程序后,屏幕上显示出字符"A"。
七、实验总结通过此次实验,我了解了汇编语言的基本概念和基本语法,学会了使用汇编指令编写简单的汇编程序。
汇编语言是一种底层的语言,能够直接操作计算机的硬件资源,具有高效性和灵活性。
在编写汇编程序时,需要注意寄存器的使用、内存的操作以及指令执行流程的控制。
编译原理实验报告

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
a=first[s][tmp];
if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入
first[r].append(1,a);
}
}
if(!empty[s]) break;//若Y1不能推导到空,结束
}
if(P[i][j]==' ')
实验报告
(2015/ 2016学年第二学期)
课程名称
编译原理
实验名称
语法分析器的构造
实验时间
2016
年
5
月
26
日
指导单位
计算机软件教学中心
指导教师
黄海平Байду номын сангаас
学生姓名
班级学号
学院(系)
计算机学院、软件学院
专业
计算机科学
与技术
实验报告
实验名称
语法分析器的构造
指导教师
黄海平
实验类型
验证
实验学时
4
实验时间
2016.5.26
string* first=new string[n];
char a;
int step=100;//最大推导步数
while(step--){
// cout<<"step"<<100-step<<endl;
for(i=0;i<k;i++)
{
//cout<<P[i]<<endl;
r=U.find(P[i][0]);
for(i=0;i<20&&U[i]!=' ';i++)
{ flagg=0;
arfa=beta="";
for(j=0;j<100&&P[j][0]!=' ';j++)
{
if(P[j][0]==U[i])
{
if(P[j][4]==U[i])//产生式j有左递归
{
flagg=1;
for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);
{
int i,j,r;
char a;
string fir;
for(i=0;i<s.length();i++)
{
if(s[i]=='^') fir.append(1,'^');
if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环
//C记录()后跟的字符,将C添加到()中所有字符串后面
}
if(G[i][j]==')') {j++;flag=0;}
*/
if(G[i][j]=='|')
{
//if(flag==1) P[k][r++]=C;
k++;j++;
P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';
{
int i=0;//计数
char ch='y';
while(ch=='y'){
cin>>G[i++];
cout<<"继续输入?(y/n)\n";
cin>>ch;
}
}
void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,
if(G[i][j]!='|'&&G[i][j]!='^')
//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')
u[t++]=G[i][j];
}
}//终结符集合,t为终结符个数
for(i=0;i<n;i++)
{
flag=0;r=4;
if(first[r].find('^')==string::npos)
first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号
}
}
}
return first;
}
string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集
if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归
}
else
{
for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);
if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");
for(j=4;j<G[i].length();j++)
{
P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';
/* if(G[i][j]=='(')
{ j++;flag=1;
for(temp=j;G[i][temp]!=')';temp++);
C=G[i][temp+1];
{
for(i=0;i<k;i++)
{
r=U.find(P[i][0]);
if(P[i][4]=='^') empty[r]=1;//直接推导到空
else
{
for(j=4;P[i][j]!=' ';j++)
{
if(U.find(P[i][j])!=string::npos)
{
if(empty[U.find(P[i][j])]==0) break;
以上实验要求可分两个同学完成。例如构建分析表一个同学完成、构建分析程序并分析符号串另一个同学完成。
二、实验环境(实验设备)
硬件:计算机
软件:Visual C ++6.0
二、实验原理及内容
实验内容:
设计并实现一个LL(1)语法分析器,实现对算术文法
G[E]:E->E+T|T
T->T*F|F
F->(E)|i
一、实验目的和要求
实验目的:
设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
实验要求:
1、检测左递归,如果有则进行消除;
2、求解FIRST集和FOLLOW集;
3、构建LL(1)分析表;
4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
for(n=0;!G[n].empty();n++)
{ U[n]=G[n][0];
}//非终结符集合,n为非终结符个数
for(i=0;i<n;i++)
{
for(j=4;j<G[i].length();j++)
{
if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos)
else GG[m].append(arfa);
GG[m].append(1,C);GG[m].append("|^");
m++;
C++;
}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,
}
return flag;
}
int* ifempty(string* P,string U,int k,int n)
{
int i,j,r,temp;//计数
char C;//记录规则中()后的符号
int flag;//检测到()
n=t=k=0;
for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)
U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a)
if(U.find(s[i])!=string::npos)//X1是非终结符
{
r=U.find(s[i]);
for(j=0;first[r][j]!='\0';j++)