dw的命名规范
[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念
![[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念](https://img.taocdn.com/s3/m/fdddbd730a1c59eef8c75fbfc77da26924c59650.png)
[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念前⾔:不是做数仓的,但是也需要了解数仓的知识。
其实分层好多因⼈⽽异,问了同事好多分层的区别也不是很清晰。
所以后续有机会还是跟数仓的同事碰⼀下吧~⼀. 各种名词解释1.1 ODS是什么?ODS层最好理解,基本上就是数据从源表拉过来,进⾏etl,⽐如mysql 映射到hive,那么到了hive⾥⾯就是ods层。
ODS 全称是 Operational Data Store,操作数据存储.“⾯向主题的”,数据运营层,也叫ODS层,是最接近数据源中数据的⼀层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装⼊本层。
本层的数据,总体上⼤多是按照源头业务系统的分类⽅式⽽分类的。
但是,这⼀层⾯的数据却不等同于原始数据。
在源数据装⼊这⼀层时,要进⾏诸如去噪(例如有⼀条数据中⼈的年龄是300 岁,这种属于异常数据,就需要提前做⼀些处理)、去重(例如在个⼈资料表中,同⼀ ID 却有两条重复数据,在接⼊的时候需要做⼀步去重)、字段命名规范等⼀系列操作。
1.2 数据仓库层DW?数据仓库层(DW),是数据仓库的主体.在这⾥,从 ODS 层中获得的数据按照主题建⽴各种数据模型。
这⼀层和维度建模会有⽐较深的联系。
细分:1. 数据明细层:DWD(Data Warehouse Detail)2. 数据中间层:DWM(Data WareHouse Middle)3. 数据服务层:DWS(Data WareHouse Servce)1.2.1 DWD明细层?明细层(ODS, Operational Data Store,DWD: data warehouse detail)概念:是数据仓库的细节数据层,是对STAGE层数据进⾏沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进⾏集中,明细层跟stage层的粒度⼀致,属于分析的公共资源数据⽣成⽅式:部分数据直接来⾃kafka,部分数据为接⼝层数据与历史数据合成。
pb 编码规范
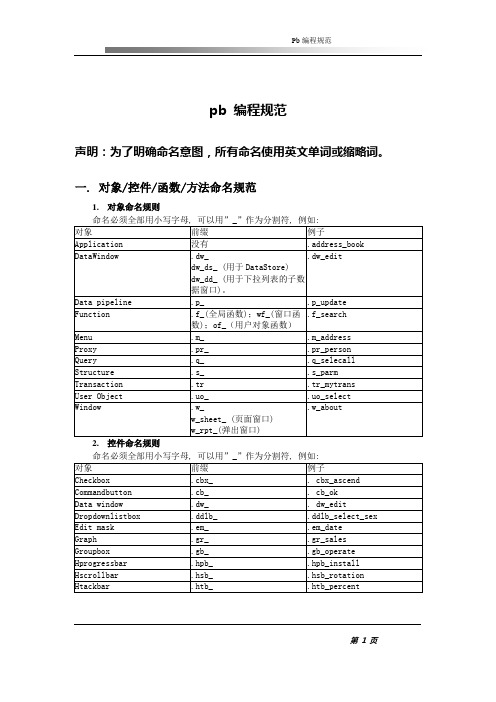
pb 编程规范声明:为了明确命名意图,所有命名使用英文单词或缩略词。
一. 对象/控件/函数/方法命名规范1.对象命名规则命名必须全部用小写字母, 可以用”_”作为分割符, 例如:2.控件命名规则3.方法/函数命名规则必须以小写字母开头, 采用大小写混合形式, 并且应足够长以描述它的作用. 而且, 方法名应以一个动词起首,如getUserRight()exitProgram()对于比较长的单词推荐使用缩略语以使名称的长度合理化. 当使用缩略语时, 要确保它在整个使用程序中的一致性. 如果一会儿使用Cnt, 一会儿使用 Count,将导致不必要的混淆。
二. 常量和变量命名约定1.常量必须全部大写, 如:constant int MAXVALUE=102.变量三. pb编码规范1.程序头注释约定所有类,接口的开始都要有关于这个类(接口)的注释:/*** Title: Pushclass* Description: function* Copyright: Copyright (c) 2000* Company: GE.Corp* @author: raogaohua* @version: 1.0*/2.函数/方法注释规范所有的函数/方法的开始都应该有描述这段代码的功能的一段简明注释. 但是这种描述不应该包括具体执行过程,因为这常常是随时间而变的,可能会成为错误的注释./*** Name: compString* Description: 找出一个String在一个String[]中位置index* Author: zhaoshouiang* @param strArray String数组* @param strFind 需要找的String* @return >=0:找到, 返回strDind在strArray中的index* -1: 没找到*/public int compString(String[] strArray, String strFind)在方法中的注释要求做到下列几点:A.每一个重要变量的声明应该包括一个嵌入注释,来描述变量的使用.B.变量、控件及函数/方法的命名应该足够清楚, 使得只有复杂的执行细节才需要嵌入注释.C.列举主要数据对象、函数/方法、算法、数据库及系统需求. 一段描述算法的伪代码能会有所帮助。
数据仓库命名规范

数据仓库命名规范目录1. 概述 (2)2. 数据仓库命名规范 (4)2.1. 命名规范 (4)2.1.1. 表属性规范 (4)2.1.2. 索引 (9)2.1.3. 视图 (10)2.1.4. 物化视图 (10)2.1.5. 存储过程 (10)2.1.6. 触发器 (10)2.1.7. 函数 (10)2.1.8. 数据包 (10)2.1.9. 序列 (10)2.1.10. 普通变量 (10)2.1.11. 游标变量 (11)2.1.12. 记录型变量 (11)2.1.13. 表类型变量 (11)2.1.14. 数据库链接 (11)2.2. 命名 (11)2.2.1. 语言 (11)2.2.2. 大小写 (12)2.2.3. 单词分隔 (12)2.2.4. 保留字 (12)2.2.5. 命名长度 (12)2.2.6. 字段名称 (12)2.3. 数据类型 (13)2.3.1. 字符型 (13)2.3.2. 数字型 (13)2.3.3. 日期和时间 (13)2.3.4. 大字段 (14)2.3.5. 唯一键 (14)1.概述1.数据模型是数据管理的分析工具和交流的有力手段;同时,还能够很好地保证数据的一致性,是实现商务智能(Business Intelligence)的重要基础。
因此建立、管理一个企业级的数据模型,应该遵循标准的命名和设计规范。
2.数据仓库命名规范2.1.命名规范2.1.1.表属性规范2.1.1.1.表名2.1.1.1.1.ODS层表名前缀为ODS_应用系统名(缩写)_数据表名。
数据表名称必须以有特征含义的单词或缩写组成,中间可以用“_”分割,例如:ODS_FUN_CUSTOMERINFO。
表名称不能用双引号包含,表名长度不超过30个字符。
如果ODS设计采用贴源设计,数据表名应与源系统一致。
●系统和应用名规则如下:⏹核心COR⏹对公信贷CLN⏹个贷PLN⏹基金FUN⏹票据TIC⏹理财 FIN⏹报表 RPT⏹……⏹如有新系统,按规则添加前缀为DW_主题名(缩写)_功能描述。
几种常见的软件命名规则

几种常见的软件命名规则收藏今天终于有时间可以不用加班,回来看电影,听歌。
筹划已久的博客,今天终于也迎来了第一篇有意义的文章,参考了网络上的一些文章,写的不好,再努力。
实际上命名规范是有很多的,也不是见到的就可以说的清楚,这里就就简单的介绍三种:匈牙利命名规范,Pascal,Camel:一、匈牙利命名规范:广泛应用于象Microsoft Windows这样的环境中。
几年以前,Charles Simonyi(他后来成为微软的著名程序员)设计了一种以前缀为基础的命名方法,这种方法后来称为"匈牙利表示法"以记念他.他的思想是根据每个标识符所代表的含义给它一个前缀.微软后来采用了这个思想,给每个标识符一个前缀以说明它的数据类型.因此,整型变量的前缀是n,长整型变量是nl,字符型数组变量是ca,以及字符串(以空类型结尾的字符数组)以sz为前缀.这些名字可能会非常古怪.比如说:lpszFoo表示"Foo"是一个指向以空字符为结尾的字符串的长整型指针. 这种方法的优点是使人能够通过变量的名字来辨别变量的类型,而不比去查找它的定义.遗憾的是,这种方法不仅使变量名字非常绕口,而且使改变变量类型的工作变得十分艰巨.在Windows3.1中,整型变量为16为宽.如果我们在开始时采用了一个整型变量,但是在通过30---40个函数的计算之后,发现采用整型变量宽度不够,这时我们不仅要改变这个变量的类型,而且要改变这个变量在这30--40个函数中的名字. 因为不切实际,除了一些顽固的Windows程序员外已经没有人再使用"匈牙利表示法"了.毫无疑问,在某种场合它依然存在,但大部分人现在已经抛弃它了.一般而言,输入前缀是一种糟糕的想法,因为它把变量于其类型紧紧地绑在了一起. 对于30行以下的函数,匈牙利方法一般有优势。
尤其是对界面编程,有优势。
但对于有强烈的算法要求、尤其是有很多抽象类型的C++程序,匈牙利方法简直是一个灾难。
数据仓库规范

数据仓库规范一.数据仓库层次结构规范1.1 基本分层结构系统的信息模型从存储的内容方面可以分为,STAGE接口信息模型、ODS/DWD信息模型,MID信息模型、DM信息模型、元数据信息模型。
在各个信息模型中存储的内容如下描述:1) SRC接口层信息模型:提供业务系统数据文件的临时存储,数据稽核,数据质量保证,屏蔽对业务系统的干扰,对于主动数据采集方式,以文件的方式描述系统与各个专业子系统之间数据接口的内容、格式等信息。
与该模型对应的数据是各个专业系统按照该模型的定义传送来的数据文件。
STAGE是生产系统数据源的直接拷贝,由ETL过程对数据源进行直接抽取,在格式和数据定义上不作任何改变。
与生产系统数据的唯一不同是,STAGE层数据具有时间戳。
STAGE层存在的意义在于两点:(1)对数据源作统一的一次性获取,数据仓库中其他部分都依赖于STAGE层的数据,不再重复进行抽取,也不在生产系统上作运算,减小生产系统的压力;(2)在生产系统数据已经刷新的情况下,保存一定量的生产系统的历史数据,以便在二次抽取过程中运算出错的情况下可以进行回溯。
2) ODS/DWD层(对应原模型的ODS和DW层)信息模型:简称DWD层是数据仓库的细节数据层,是对STAGE层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中。
为企业进行经营数据的分析,系统将数据按分析的主题的形式存放,跟STAGE层的粒度一致,属于分析的公共资源。
3) MID 信息模型:轻度综合层是新模型增加的数据仓库中DWD层和DM层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计。
轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并为满足一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀。
4) DM信息模型:为专题经营分析服务,系统将数据按分析的专题组织成多维库表的形式存放,属于分析目标范畴的数据组织与汇总,属于分析的专有资源。
dw 新建文字格式规则

dw 新建文字格式规则
在DW平台中,新建文字格式规则是非常重要的,它能够确保文章的可读性和一致性。
在以下几个方面,我们可以制定一些文字格式规则:
1.字体和大小:为了保持统一,可以规定文章中的字体和大小。
在DW中,常见的字体包括Arial、Calibri、Times New Roman等。
同时,可以设定正文的字体大小为12号,标题可以设置为16号或者加粗。
2.行间距和段间距:一致的行间距和段间距可以提高文章的可读性。
建议设置正文的行间距为1.5倍,段间距为1.5倍至2倍的正常字号。
3.标题格式:为了突出文章结构和层次感,可以规定标题的格式。
一般而言,可以使用层级标题,例如一级标题使用大写字母,二级标题使用罗马数字,三级标题使用阿拉伯数字等。
4.引用和强调:当引用他人观点或者强调文字时,可以规定相应的格式。
一般来说,可以使用引号或者斜体来突出引用的内容,同时要注意在使用他人观点时注明出处。
5.列表和编号:在列举事项时,可以规定使用符号列表或者编号列表。
符号列表适用于无特定顺序的事项,编号列表适用于有特定顺序的事项。
6.排版和对齐:在排版方面,可以规定文章的对齐方式。
通常情况下,左对齐是最常见的选择,可以使得文章整齐、易读。
总之,在DW平台中,新建文字格式规则是非常必要的。
它能够确保文章的整体风格一致,同时提高文章的可读性和专业性。
通过规定字体、大小、行间距、段间距、标题格式、引用和强调格式、列表和编号格式以及排版和对齐方式,我们可以更加方便地撰写高质量的文章。
C语言变量命名规则

1、严格采用阶梯层次组织程序代码:各层次缩进的分格采用VC的缺省风格,即每层次缩进为4格,括号位于下一行。
规定相匹配的大括号在同一列,对继行则规定再缩进4格。
例如:2、提醒信息字符串的位置在程序中需要给出的提醒字符串,为了支持多种语言的开发,除了一些给调试用的临时信息外,其他所有的提醒信息必须定义在资源中。
3、对变量的定义,尽量位于函数的开始位置。
二、命名规则:1、变量名的命名规则①、变量的命名规则规定用“匈牙利法则”。
即开头字母用变量的类型,其余部分用变量的英文意思或其英文意思的缩写,尽量避免用中文的拼音,规定单词的第一个字母应大写。
即:变量名=变量类型+变量的英文意思(或缩写)对非通用的变量,在定义时加入注释说明,变量定义尽量也许放在函数的开始处。
见下表:bool(BOOL) 用b开头bIsParentbyte(BYTE) 用by开头byFlagshort(int) 用n开头nStepCountlong(LONG) 用l开头lSumchar(CHAR) 用c开头cCountfloat(FLOAT) 用f开头fAvgdouble(DOUBLE) 用d开头dDetavoid(VOID) 用v开头vVariantunsigned int(WORD)用w开头wCountunsigned long(DWORD) 用dw开头dwBroadHANDLE(HINSTANCE)用h开头hHandleDWORD 用dw开头dwWordLPCSTR(LPCTSTR) 用str开头strString用0结尾的字符串用sz开头szFileName对未给出的变量类型规定提出并给出命名建议给技术委员会。
②、指针变量命名的基本原则为:对一重指针变量的基本原则为:“p”+变量类型前缀+命名如一个float*型应当表达为pfStat对多重指针变量的基本规则为:二重指针:“pp”+变量类型前缀+命名三重指针:“ppp”+变量类型前缀+命名......③、全局变量用g_开头,如一个全局的长型变量定义为g_lFailCount,即:变量名=g_+变量类型+变量的英文意思(或缩写)④、静态变量用s_开头,如一个静态的指针变量定义为s_plPerv_Inst,即:变量名=s_+变量类型+变量的英文意思(或缩写)⑤、成员变量用m_开头,如一个长型成员变量定义为m_lCount;即:变量名=m_+变量类型+变量的英文意思(或缩写)⑥、对枚举类型(enum)中的变量,规定用枚举变量或其缩写做前缀。
Dreamweaver命名锚记如何使用

2、我们点击新建
3、创建一个html文件
5、比如我们在的第二章前面这插入命名锚记
6、起个名字叫abc
7、选中文件然后链接是#abc 就搞定了
8、我们点击第二章,自动跳转第二章,这只是示范,章数多了就好了
dreamweaver设计网页的时候我们会使用到很多功能以下是小编为大家搜索整理的dreamweaver命名锚记如何使用希望能给大家带来帮助
Dreamweaver命名锚记如何使用
Dreamweaver命名锚记如何mweaver设计网页的时候我们会使用到很多功能,以下是店铺为大家搜索整理的Dreamweaver命名锚记如何使用,希望能给大家带来帮助!
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DW的命名规则
头:header
内容:content/container
尾:footer
导航:nav
侧栏:sidebar
栏目:column
页面外围控制整体布局宽度:wrapper
左右中:left right center
登录条:loginbar
标志:logo
广告:banner
页面主体:main
热点:hot
新闻:news
下载:download
子导航:subnav
菜单:menu
子菜单:submenu
搜索:search
友情链接:friendlink
页脚:footer
版权:copyright
滚动:scroll
内容:content
标签页:tab
文章列表:list
提示信息:msg
小技巧:tips
栏目标题:title
加入:joinus
指南:guild
服务:service
注册:regsiter
状态:status
投票:vote
合作伙伴:partner
(二)id的命名:
(1)页面结构
容器: container
页头:header
内容:content/container
页面主体:main
页尾:footer
导航:nav
侧栏:sidebar
栏目:column
页面外围控制整体布局宽度:wrapper 左右中:left right center
(2)导航
导航:nav
主导航:mainbav
子导航:subnav
顶导航:topnav
边导航:sidebar
左导航:leftsidebar
右导航:rightsidebar
菜单:menu
子菜单:submenu
标题: title
摘要: summary
(3)功能
标志:logo
广告:banner
登陆:login
登录条:loginbar
注册:regsiter
搜索:search
功能区:shop
标题:title
加入:joinus
状态:status
按钮:btn
滚动:scroll
标签页:tab
文章列表:list
提示信息:msg
当前的: current
小技巧:tips
图标: icon
注释:note
指南:guild
服务:service
热点:hot
新闻:news
下载:download
投票:vote
合作伙伴:partner 友情链接:link
版权:copyright。