Kettle公司培训手册范本
Kettle用户操作手册1

Kettle用户操作手册1.kettle介绍1.1 什么是kettleKettle是“Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;它的名字起源正如该项目的主程序员MATT所说:希望把各种数据放到一个壶里然后以一种指定的格式流出。
Spoon是一个图形用户界面,它允许你运行转换或者任务。
1.2 Kettle 的安装要运行此工具你必须安装 Sun 公司的JAVA 运行环境1.4 或者更高版本,相关资源你可以到网络上搜索JDK 进行下载,Kettle 的下载可以到/取得最新版本。
1.3运行SPOON下面是在不同的平台上运行Spoon 所支持的脚本:Spoon.bat: 在windows 平台运行Spoon。
Spoon.sh: 在Linux、Apple OSX、Solaris 平台运行Spoon。
1.4 资源库一个Kettle资源库可以包含那些转换信息,这意味着为了从数据库资源中加载一个转换就必须连接相应的资源库。
在启动SPOON的时候,可以在资源库中定义一个数据库连接,利用启动spoon时弹出的资源库对话框来定义,如图所示:单击加号便可新增;关于资源库的信息存储在文件“reposityries.xml”中,它位于你的缺省home 目录的隐藏目录“.kettle”中。
如果是windows 系统,这个路径就是c:\Documents andSettings\<username>\.kettle。
如果你不想每次在Spoon 启动的时候都显示这个对话框,你可以在“编辑/选项”菜单下面禁用它。
admin 用户的缺省密码也是admin。
如果你创建了资源库,你可以在“资源库/编辑用户”菜单下面修改缺省密码。
1.5 定义1.5.1 转换主要用来完成数据的转换处理。
转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
kettle使用手册

kettle使用手册Kettle使用手册一、Kettle简介1.1 Kettle概述Kettle(也被称为Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,它能够从各种数据源中提取数据,并进行各种转换和加工,最后将数据加载到指定的目的地中。
Kettle具有强大的数据处理功能和友好的图形化界面,使得数据集成和转换变得简单而高效。
1.2 功能特点- 数据抽取:从多种数据源中提取数据,包括关系型数据库、文件、Web服务等。
- 数据转换:支持多种数据转换操作,如字段映射、类型转换、数据清洗等。
- 数据加载:将转换后的数据加载到不同的目的地,如数据库表、文件、Web服务等。
- 调度管理:支持定时调度和监控,可自动执行数据集成任务。
二、安装与配置2.1 系统要求在安装Kettle之前,请确保满足以下系统要求: - 操作系统:Windows、Linux、Unix等。
- Java版本:JDK 1.8及以上。
- 内存:建议至少4GB的可用内存。
2.2 安装Kettle最新版本的Kettle安装包,并按照安装向导进行安装。
根据系统要求和个人需求进行相应的配置选项,完成安装过程。
2.3 配置Kettle在安装完成后,需要进行一些配置以确保Kettle正常运行。
具体配置步骤如下:- 打开Kettle安装目录下的kettle.properties文件。
- 根据实际需要修改配置项,如数据库连接、日志路径、内存分配等。
- 保存修改并重启Kettle。
三、Kettle基础操作3.1 数据抽取3.1.1 创建数据源连接打开Kettle,左上角的“新建连接”按钮,在弹出的窗口中选择待抽取的数据源类型(如MySQL、Oracle等),填写相关参数并测试连接。
3.1.2 设计数据抽取作业- 打开Kettle中的“转换”视图。
- 从左侧的工具栏中选择适当的输入组件(如“表输入”或“文件输入”),将其拖拽到设计区域中。
kettle使用手册
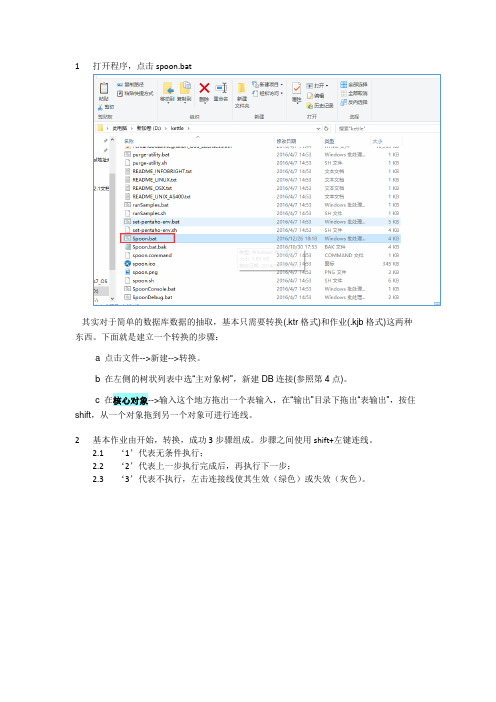
1打开程序,点击spoon.bat其实对于简单的数据库数据的抽取,基本只需要转换(.ktr格式)和作业(.kjb格式)这两种东西。
下面就是建立一个转换的步骤:a 点击文件-->新建-->转换。
b 在左侧的树状列表中选“主对象树”,新建DB连接(参照第4点)。
c 在核心对象-->输入这个地方拖出一个表输入,在“输出”目录下拖出“表输出”,按住shift,从一个对象拖到另一个对象可进行连线。
2基本作业由开始,转换,成功3步骤组成。
步骤之间使用shift+左键连线。
2.1‘1’代表无条件执行;2.2‘2’代表上一步执行完成后,再执行下一步;2.3‘3’代表不执行,左击连接线使其生效(绿色)或失效(灰色)。
3打开具体步骤中的转换流程,点击‘Transformation’跳转至相应具体转换流程,编辑此转换具体路径,双击转换,弹出窗口,‘1’为相对路径,点击‘2’选择具体Visit.ktr转换,为绝对路径。
4建立数据库连接,输入相应信息测试,成功即可图45转换具体设置,如图4,‘表输出’至‘文本文件输出’流程跳接线为错误处理步骤,当输出格式不能满足表输出的目的表结构类型时,将会将记录输出到‘文本文件输出’中的记录中。
5.1双击‘表输入’,输入相应的SSQL语句,选择配置数据库连接,或新增,预览查询生成的结果(如果数据库配置中使用变量获取,此处预览生成错误)。
5.2双击‘表输出’,选择数据库连接,‘浏览’选择相应目标表,(此处‘使用批量插入’勾选去除,目的是在错误处理步骤中无法使用批量处理,可能是插件兼容问题)6表输出插件定义a) Target Schema:目标模式。
要写数据的表的Schema的名称。
允许表明中包含“。
”对数据源来说是很重要的b) 目标表:要写数据的表名。
c) 提交记录数量:在数据表中用事物插入行。
如果n比0大,每n行提交一次连接。
否则不使用事务,速度会慢一些。
d) 裁剪表:在第一行数据插入之前裁剪表。
史上最强 Kettle 培训教程资料

表输入
功能描述:从数据库中按条件查找表的数据 注意事项:
可以使用变量替换的方式进行查询,请将“替换sql语句里的变量”勾选上 可以使用上一步结果中赋予值,请将“从步骤插入数据”选择上一步的名称 测试过程中发现如果上一个步骤设置的变量,在table input里面获取不到,
变量设置必须作为一个单独的转换先执行一次,然后才能获取到这个变量
例二:导出数据到文本文件
步骤: ⑥ 鼠标双击【文本文件输出】控件,弹出窗口编辑,如下图:
例二:导出数据到文本文件
步骤: ⑦ 鼠标点击左上角的图标 执行,如下图:
例三:表对表数据转换
• 新建一个转换:文件->新建建一个作业:文件->新建->作业 • 作业可以调用作业,这样方便流程控制
(2)创建作业 将已经创建好的转换和相关的作业组件串联起来, 形成一个整体的任务。
Kettle 的执行顺序
• 作业:分串行执行和并行执行,串行执行是先执行完其中一条线再执 行另一条线,并行是两条线同时执行,同一条线上的两个步聚会先执 行前面的再执行后面的。每个步骤执行结果分两种:true(成 功)/false(失败),根据返回结果可以控制流程走向。
作业的常用环节介绍:
Kettle主界面
说明:A: A:Kettle所使用到的菜单栏。 B:在使用Kettle时所涉及使用到的对象。 C:Kettle中所有的组件。 D:根据选择(B)或者(C)显示相应的结果。 E:Kettle设计界面。
Kettle界面-job
Kettle界面-transformation
47
例五:作业调用转换
• 作业也可以调用转换
48
作业的一个例子
指定job执行规则:是否重 复执行、设置重复执行的 间隔时间等
Kettle 公司培训手册(DOC 20页)

Kettle 培训手册一、Etl 介绍ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT 来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
二、kettle 部署运行将kettle2.5.1文件夹拷贝到本地路径,例如D 盘根目录。
双击运行kettle文件夹下的spoon.bat文件,出现kettle欢迎界面:稍等几秒选择没有资源库,打开kettle主界面创建transformation,job点击页面左上角的创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation 文件保存后后缀名为ktr点击页面左上角的创建一个新的job,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb 创建数据库连接在transformation页面下,点击左边的【Main Tree】,双击【DB连接】,进行数据库连接配置。
connection name自命名连接名称Connection type选择需要连接的数据库Method of access选择连接类型Server host name写入数据库服务器的ip地址Database name写入数据库名Port number写入端口号Username写入用户名Password写入密码例如如下配置:点击【test】,如果出现如下提示则说明配置成功点击关闭,再点击确定保存数据库连接。
Kettle使用培训文档-PPT课件

Kettle使用-运行
Kettle提供了资源库方式的方式来整合所 有的工作,但是因为资源库移植不方便, 所以选择没有资源库
Kettle使用-ktr&kjb
点击页面左上角的 创建一个新的 transformation,点击 保存到本地路径, 例如保存到D:/etltest下,保存文件名为 EtltestTrans,kettle默认transformation 文件保存后后缀名为ktr
Kettle使用培训文档
shenxiangl
Kettle使用-ETL&Kettle
ETL(Extract-Transform-Load的缩写, 即数据抽取、转换、装载的过程),对于 金融IT来说,经常会遇到大数据量的处理, 转换,迁移,所以了解并掌握一种etl工 具的使用,必不可少。 Kettle是一款国外开源的etl工具,纯java 编写,绿色无需安装,数据抽取高效稳定。 Kettle中有两种脚本文件,transformation 和job,transformation完成针对数据的基 础转换,job则完成整个工作流的控制。
DB连接:显示当前transformation中的 数据库连接,每一个transformation的 数据库连接都需要单独配置。
Steps:一个transformation中应用到的 环节列表
Hops:一个transformation中应用到的 节点连接列表
Kettle使用-transformation
类别 Input
Kettle使用-Job
菜单介绍
Main Tree菜单列出的是一个Job 中基本的属性,可以通过各个节点 来查看。
DB连接:显示当前Job中的数据库连 接,每一个Job的数据库连接都需要单 独配置。 Job entries:一个Job中引用的环节列 表
Kettle使用培训文档

KETTLE使用-TRANSFORMATION
菜单介绍
Core Objects菜单列出的是 transformation中可以调用的环节列 表,可以通过鼠标拖动的方式对环 节进行添加。
Input:输入环节 Output:输出环节 Lookup:查询环节 Transform:转化环节 Joins:连接环节 Scripting:脚本环节
KETTLE使用案例
KETTLE使用案例
KETTLE使用案例
数据库连接选择数据仓库的数据库,目标表选 择对应的infortaotal表,在查询关键字里,表 字段写name(表示仓库表里的字段),流里的字 段1里写入NAME(即上一个步骤输入的内容里 的NAME)。比较符用”=”号。点击Edit mapping 按钮,将表字段,与流利的字段进行对应,即 流里字段里的值输入到表里的哪个字段里去。
会根据查询条件中字段进行判断更新根据处理结果对数据库进行更新若需要更新的数据在数据库表中无记录则会报错停止删除根据处理结果对数据库记录进行删除若需要删除的数据在数据库表中无记录则会报错停止lookup数据库查询根据设定的查询条件对目标表进行查询返回需要的结果字段流查询将目标表读取到内存通过查询条件对内存中数据集进行查询调用db存储过程调用数据库存储过程transform字段选择选择需要的字段过滤掉不要的字段也可做数据库字段对应过滤记录根据条件对记录进行分类排序记录将数据根据某以条件进行排序空操作无操作增加常量增加需要的常量字段scriptingmodifiedjavascriptvalue扩展功能编写javascript脚本对数据进行相应处理mapping映射子转换数据映射jobsatvariables设置环境变量getvariables获取环境变量kettlekettle使用使用jobjob菜单介绍maintree菜单列出的是一个job中基本的属性可以通过各个节点来查看
KETTLE使用培训

• 使用原则
采集demo
• 采集demo1和采集demo2说明 两个demo实现的业务是一样的,区别 是demo2多用了几个step去实现连接功能。 意在说明两点:1、如果一条sql实现不了的, 可以通过Kettle提供的step实现。2、Kettle 很灵活,所以从性能上考虑,对开发人员 的要求也是挺高的,下面一节会给出一些 原则。
使用原则???能使用truncatetable的时候就不要使用deleteallrow这种类似sql合理的分区如果删除操作是基于某一个分区的就不要使用deleterow这种方式不管是deletesql还是delete步骤直接把分区drop掉再重新创建尽量缩小输入的数据集的大小增量更新也是为了这个目的尽量使用数据库原生的方式装载文本文件oracle的sqlloadermysql的bulkloader步骤尽量不要用kettle的calculate计算步骤能用数据库本身的sql就用sql不能用sql就尽量想办法用procedure实在不行才是calculate步骤
常用Step介绍
• Table Input和Table Output a1表字段名:a,b A2表字段名:a,c 在这个demo中可以看出两点: 1、数据流(输入/出流)中的数据 字段名与生成该数据流的Step自动 获取。 2、表输出是按照数据流的数据自 动匹配并且插入到输出表中的。
常用Step介绍
采集demo
• 采集demo1
采集demo
• 采集demo2
使用原则
• • • • 目的 Kettle介绍 Kettle实战 使用原则
使用原则
• 尽量使用数据库连接池 • 尽量提高批处理的commit size • 尽量使用缓存,缓存尽量大一些(主要是文本文件和数据 流) • Kettle 是Java 做的,尽量用大一点的内存参数启动Kettle. • 可以使用sql 来做的一些操作尽量用sql Group , merge , stream lookup ,split field 这些操作都 是比较慢的,想办法避免他们.,能用sql 就用sql • 插入大量数据的时候尽量把索引删掉 • 尽量避免使用update , delete 操作,尤其是update , 如果 可以把update 变成先delete , 后insert .
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Kettle 培训手册
一、Etl 介绍
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT 来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种
etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高
效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
二、kettle 部署运行
将kettle2.5.1文件夹拷贝到本地路径,例如D 盘根目录。
双击运行kettle文件夹下的spoon.bat文件,出现kettle欢迎界面:
稍等几秒
选择没有资源库,打开kettle主界面
创建transformation,job
点击页面左上角的创建一个新的transformation,点击保存到本地路
径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation
文件保存后后缀名为ktr
点击页面左上角的创建一个新的job,点击保存到本地路径,例如保
存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb
创建数据库连接
在transformation页面下,点击左边的【Main Tree】,双击【DB连接】,进行
数据库连接配置。
connection name自命名连接名称
Connection type选择需要连接的数据库
Method of access选择连接类型
Server host name写入数据库服务器的ip地址
Database name写入数据库名
Port number写入端口号
Username写入用户名
Password写入密码
例如如下配置:
点击【test】,如果出现如下提示则说明配置成功
点击关闭,再点击确定保存数据库连接。
一个简单的ktr 例子
目的:
将一个数据库导入到另一个数据库中。
操作步骤:
创建一个transformation,命名为etlTestTrans.ktr,创建数据库连接ods,点击【Input】,选中【表输入】,拖到主窗口,释放鼠标,双击打开
如下图
点击【Transform】,选中【字段选择】,拖到主窗口,释放鼠标
点击【Output】,选中【表输出】,拖到主窗口,释放鼠标
建立【文本文件输入】和【字段选择】与【字段选择】和【表输出】的连接
双击【表输出】,目标表中写入ZT_TEST_KETTLE,,确定保存
双击【字段选择】,点击获取选择的字段,再点击Edlt Mapping,点击OK 确定,编辑所有字段对应关系,点确定。
点击运行这个转换。
,则将上一个ktr中生成的文本,导入到数据库当中。
一个简单的kjb例子
目的:
将上一个transformation在一个job里面调用执行。
操作步骤:
在etlTestJob页面,点击【Core Objects】,点击【Job entries】,选中【START】拖动到主窗口释放鼠标,再选中【Transformation】,拖动到主窗口释放鼠标,
建立【START】和【Transformation】之间的连接。
双击【Transformation 】,在Transformation filename 中写入
E:\kettleWorkspace\etlTestTrans.ktr,确定保存。
点击保存创建好的job。
点击运行这个转换。
待所有任务都显示成功,则为job调用transformation运行成功。
一个增量的例子
增量更新按照数据种类的不同大概可以分成:
1. 只增加,不更新,
2. 只更新,不增加
3. 即增加也更新
4. 有删除,有增加,有更新
下面针对前三种做一个增量的ETL抽取。
过程如下:
根据前面讲解的例子一样,首先建立源表(fina_test1)和目标表(fina_test2),整个设计流程如下:
其中第一个步骤(输入-目标表)的sql 大概如下模式:
select ifnull(max(date_seal),'1900-01-01 00:00:00') from fina_test2
你会注意到第二个步骤和第一个步骤的连接是黄色的线,这是因为第二个table input(输入-源表)步骤把前面一个步骤的输出当作一个参数来用,所有Kettle用黄色的线来表示,第二个table input(输入-源表)的sql 模式大概如下:SELECT * FROM fina_test1 where date_seal>?
后面的一个问号就是表示它需要接受一个参数,你在这个table input(输入-源表)下面需要指定replace variable in script 选项和执行每一行为选中状态,这样,Kettle就会循环执行这个sql , 执行的次数为前面参数步骤传入的数据集的大小。
关于第三个步骤执行插入/更新步骤需要特别解释一下,
Kettle执行这个步骤是需要两个数据流对比,其中一个是目标数据库,你在目标表里面指定的,它放在用来查询的关键字左边的表字段里面的,另外一个数据流就是你在前一个步骤传进来的,它放在用来查询的关键字的右边,Kettle首先用你传进来的key 在数据库中查询这些记录,如果没有找到,它就插入一条记录,所有的值都跟你原来的值相同,如果根据这个key找到了这条记录,kettle会比较这两条记录,根据你指定update field 来比较,如果数据完全一样,kettle就什么都不做,如果记录不完全一样,kettle就执行一个update 步骤。
备注:主键被修改得数据认为是新记录
删除的数据由在仓库中需要保留无需考虑
然后点击新建-job,然后job的核心对象job entries拉出组建,进行执行抽取。
创建kettle资料库
资源库是用来保存转换任务的,用户通过图形界面创建的的转换任务可以保存在资源库中。
资源库可以是各种常见的数据库,用户通过用户名/密码来访问资源库中的资源,默认的用户名/密码是admin/admin
资源库并不是必须的,如果没有资源库,用户还可以把转换任务保存在 xml 文件中。
如果用户需要创建一个资源库,在资源库的登录窗口(PDI 启动时的第一个窗口)
中有【新建】按钮,点击该按钮弹出新建资源库窗口,
在该窗口中选择一个数据库连接,如果没有事先定义的数据库连接,则还要点击【新建】按钮,来创建一个数据库连接。
选择数据库连接后,要为该资源库命名,作为这个资源库的唯一标志,
最后选择【创建或更新】按钮来创建这个资源库。
资源库可以使多用户共享转换任务,转换任务在资源库中是以文件夹形式分组管理的,用户可以自定义文件夹名称。
如何使用kettle读取包含多行表的Excel文件
如果 Excel 工作表的表头只有一行,使用 Kettle 读取这样的文件是很容易的.
如果 Excel 工作表的表头是多行的, 或者是分级的就需要在容标签下正确设置列名所占
行数才可以读取.
考虑这样的一个工作表
如果想把里面的 12列数据都读出来, 就要考虑如何处理多级表头.
步骤设置的详细描述:
步骤一选择文件名,现在文件或目录里到所要添加的excel文档,然后点击,确定后,点击,
步骤二选择要读取的工作表名称和要读取的容在工作表里的起始位置, 也就是表头开始的行号和列号 (这里行号和列号是以 0 开始的)
步骤三设置要读取的容的一些属性, 这里要设置表头的所占行数是 4行.
步骤四错误处理, 选择如果有错误终止还是继续, 错误信息保存的文件等.
(图略)
步骤五选择字段, 如果前面的三个步骤(不包括错误处理步骤)都设置正确, 在这个页面选择 "获取字段" 字段按钮, 就会获得所有的列名称和数据类型.
这里我们可以看到: 多级表头中各级表头的名称被叠加起来, 形成了唯一的列名.
点击 [预览] 按钮可以预览到数据
对于表头跨连续的多行, 但不分级的情况也可以使用上述方式处理.
kettle注释:
1、kettle的控制流可以设置一些简单的时间,并且可以实现隔断天、周、月(三个只
能选一个,不能选那个月的那周那日),但是kettle工具不能关,如果关了,必须重新启动。
2、kettle里面缺少一个编辑的字段的插件,导致字段编辑很麻烦,这只能先sql中进
行手写,这个对写sql的要求很高。
一个kettle字段转换(截取)的例子
大致的流程是:
表输入还是正常的sql查询,没有添加参数。
字段转换(截取)是在进行修改。
具体样式如下:
具体的用法:
transform Functions 里面包括了字符、数字的一些函数方法,这些函数方法可以解决一些字段需要转化的问题。
Input fields和 Output fields 里面包括了从表输入进来的字段(数据)。
字段主要转化的操作界面:
注意下:substr(xxx,1,2) 中的1代表是第一位开始,2代表是取2位,在这里面还可以添加if等语句,进行编写。
在字段选择那里面要配置从js过来的字段,点击列映射(前提是已经和表输出连接上),这个字段对应要根据你实际从js倒过来的字段和目标表相对应的字段一一对应。