NTSYS软件使用详细说明
StaMPS软件操作流程
注意:冒号后面都是解释,如果步骤。
没说更改目录就一直是前一步的目录。
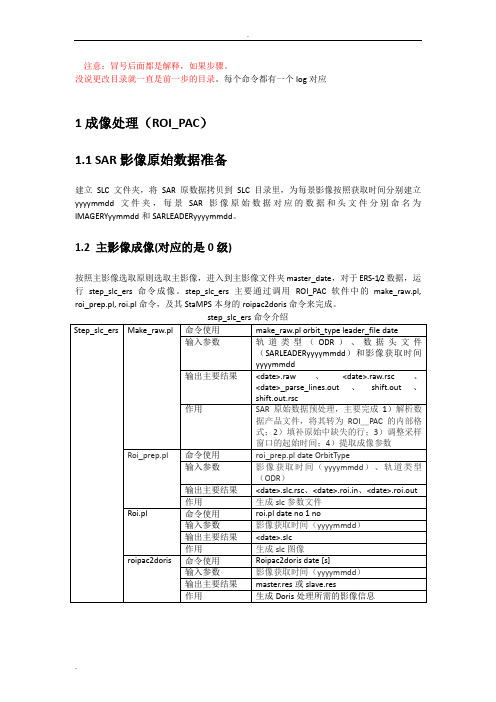
每个命令都有一个log对应1成像处理(ROI_PAC)1.1 SAR影像原始数据准备建立SLC文件夹,将SAR原数据拷贝到SLC目录里,为每景影像按照获取时间分别建立yyyymmdd文件夹,每景SAR影像原始数据对应的数据和头文件分别命名为IMAGERYyymmdd和SARLEADERyyyymmdd。
1.2 主影像成像(对应的是0级)按照主影像选取原则选取主影像,进入到主影像文件夹master_date,对于ERS-1/2数据,运行step_slc_ers命令成像。
step_slc_ers主要通过调用ROI_PAC软件中的make_raw.pl, roi_prep.pl, roi.pl命令,及其StaMPS本身的roipac2doris命令来完成。
1.3 选择主影像兴趣区域重新成像I yao观测主影像成像图像,确定研究区域,按照研究区域边界扩展1000像元的范围来编辑roi.proc。
重新运行step_slc_ers,按照兴趣区域重新成像。
step_slc_ers命令用法同1.2.//粗裁。
直接在SLC文件夹下生成有这个文件,在里面修改,别忘记去掉#号。
1.4 建立主影像精裁,观察主影像成像图像,编辑master_crop.in文件,再次确定裁剪区域。
运行step_master_setup命令建立主影像。
//从ROI_PAC_SCR中复制master_crop.in到主影像成像的文件夹中。
1.5 辅影像成像在SLC目录下,运行make_slcs_ers命令,对所有辅影像按照兴趣范围成像。
运行过程为逐个进行辅影像目录,执行step_slc_ers命令成像。
step_slc_ers用法同1.2.//注意其他辅影像成像的时候是按照粗裁的范围裁剪的,他不进行精裁,由于主影像又进行了精裁,一般辅影像比较大。
对应1级产品不用成像,直接仿照说明书,读取即可1建立连接并读取主影像link_slcs_路径(初始数据的)cd master_date(即是主影像日期文件夹)//进入主影像日期文件夹step read whole XXX (where XXX is ‘ERS’, ‘Envisat’, ‘RSAT’, or ‘TSX’)第一次对主影像读取,全部读取,不裁剪2裁剪主影像cp $MY SCR/master_crop.in 或者从安装文件里考并编辑3裁剪后主影像再次读取step_master_read4读取各个辅影像返回到SLC目录make_read2 差分干涉处理(DORIS)2.1 提取精密轨道信息(冒号后面的是此步骤的解释说明,不是让你这么操作)在insarmaster文件夹下step_master_orbit_ODR:主影像精密轨道信息提取。
思讯软件系统操作

软件:(1)供应商:打开软件→供应商→选择供应商类型(重点)→输入编码→输入供应商名称详细信息→保存(2)录资料:打开软件→基本档案→商品档案→选择类别→增加(注意:1.联营扣率:这个是扣点的供应商必录的如:18个点就输入0.18,9个点0.09 2. 商品类型:做捆绑的时候要注意这个,大箱的要换成捆绑类型 3.计价方式:这个零售价)→输入货号→价钱→供应商级以上注意事项→就可以保存了(3)捆绑商品:在做资料时把商品类型换成捆绑→保存之后→基本档案→组合商品→把等于换成含有→输入货号→选择查询→选择增加→输入小的条码→输入成分数→保存(4)入库:打开软件→采购管理→收货入库→选择供应商→输入货号→比对数量→无误→保存→审核(保存后选择是就会自动审核,没有确定无误的时候选择否,待以后在核对一下)(5)条码打印:打开软件→零售管理→条码打印→选择是(增强版)→标签设计→标签类型(价格标签/条码标签)要打那类的就选择哪个→商品列表→输入要打物品的货号→输入打印数量→打印输出(6)*日结:打开软件→零售管理→日结→数据日结→保存参数(十二点之前必须日结)(7)特价:打开软件→促销管理→促销特价→调整开始结束日期→输入商品货号→输入特价→无误→保存→审核(8)权限:打开软件→系统管理→操作员管理→操作员管理(管理后台密码的)→收银员管理(收银员前台密码及权限,修改之后保存就可以了)→功能权限(设置后台权限的)→保存(9)改货号:打开软件→基本档案→商品档案→上边的改货号→输入原货号→下一排输入改正后的货号→修改(10)特价删除:打开软件→促销管理→当前促销查询→输入商品或者单号→选择删除(11)结账打单:打开软件→采购管理→收货入库→选择供应商→输入商品及数量→无误之后审核→选择打印→再选择打印电子秤:传秤:(1)打开软件→生鲜管理→电子秤→选择是→选择增加→输入货号→选择保存→选择下传→选择下传(一般常用)(2)打开软件→生鲜管理→选择是→选择快速选择→导出→退出→打开桌面的PLU→文件→打开→选择好又惠秤资料(双击打开)→选择红色向下的箭头→输入称号→选择确定→单品资料前打钩→选择确定→等一下就OK了资料:秤码都是五位数自己编排,计价方式只有计数/记重一般记重价钱都是以公斤价录入前台:(1)销售:先扫商品→扫完之后→按(+)结算→输入顾客给的钱数→按(-)人民币(2)删除:按上下键选择到顾客不需要的商品→按U键(3)退货:先按A键→(输入总工号,收银员没权限,所以得输入总工号)选择确定→选择取消→扫以交易过的商品→按(+)结算(4)故障:(1)卡屏:检查打印机一般是没纸或者没开电源或者线没接好(2)打印机:连续出纸检查UPS电源是否插着(一般绿灯亮着就可以了)(3)断网:检查交换机是否插好,后台主机打开没(5)日结:在销售界面按一下ESC→按上下键选择收银对账→确定→按F4→按左右键选择确定→确定→小票打印出来即可(关机之前,没有顾客结账的时候做这一步,然后关机就可以了)Welcome ToDownload !!!欢迎您的下载,资料仅供参考!(6)。
intersystems 操作手册

intersystems 操作手册(原创版)目录1.InterSystems 操作手册概述2.安装和配置 InterSystems3.使用 InterSystems 进行数据处理4.使用 InterSystems 进行数据分析5.InterSystems 的高级功能6.总结正文1.InterSystems 操作手册概述InterSystems 是一款功能强大的数据处理软件,它旨在为用户提供一个方便、高效的数据处理环境。
本手册将介绍如何安装和配置InterSystems,以及如何使用它进行数据处理、数据分析等操作。
2.安装和配置 InterSystems在安装 InterSystems 之前,需要确保您的计算机满足系统要求。
安装完成后,需要进行一些基本的配置,例如设置数据库连接等。
3.使用 InterSystems 进行数据处理InterSystems 可以处理各种类型的数据,包括文本、图像、音频等。
本节将介绍如何使用 InterSystems 进行数据处理的基本步骤。
4.使用 InterSystems 进行数据分析InterSystems 提供了强大的数据分析功能,可以帮助用户对数据进行深入的分析。
本节将介绍如何使用 InterSystems 进行数据分析的步骤和方法。
5.InterSystems 的高级功能除了基本的数据处理和分析功能外,InterSystems 还提供了许多高级功能,例如机器学习、人工智能等。
本节将介绍这些高级功能的使用方法和注意事项。
6.总结InterSystems 是一款功能强大的数据处理软件,它可以帮助用户高效地处理和分析数据。
NTSS企业操作指南

NTSS企业操作指南操作流程:安装程序及报表参数并打开报表任务――>录入数据――>审核――>上报数据(数据包如果更新,会及时下发到分局,再及时送达到企业。
)具体操作步骤:一、准备工作注:NTSS录入版是专门给企业录入税收调查数据之用的。
企业用户不需要安装税务版程序和税务版任务。
前提条件1、要把以前的NTSS系统全部清除干净:①点击“开始”—选择“设置”“控制面板”打开“添加删除程序”—选择“全国税收调查系统”点击“删除”,②点击“我的电脑”选择“C盘”“program files 文件夹”--选择“thunisoft文件夹”右键删除。
③点击“任务”菜单下——注销任1、安装全国税收调查NTSS程序及数据包(建议将U盘中的全国税收软件、数据包复制并保存在桌面上,再双击左键,选择“税收调查企业税务版、企业版”。
或咨询身边对电脑操作比较熟练的人员)双击,双击,双击,双击,双击,点确定点完成双击,打开,找到信息表,开始填报。
数据包如果更新,先将下发的要更新的数据包下发到桌面上,打开全国税收调查系统NTSS----任务----安装任务如:宁乡豪德光彩贸易广场开发有限公司是房地产开发经营其他有限责任公司要选到最基础层,企业名称填全称,纳税人代码填正确。
企业代码:企业代码也就是纳税人识别号,分为三段,第一段为主管税务机关码,也可以直接输入,第二、三段为法人码,系统会自动对法人码进行IDC审核,审核不通过时系统会有所提示。
房产税缴纳方式和应税房产座落地代码 2 房产税纳税人且房产位于县城我们一般没有城市。
另外:信息表第30项,企业是哪一类调查类型,是重点企业还是抽样企业,企业自己并不知道,在培训的表一注明,企业自己看一看!31项自定义代码,信息表最后一项空着,省局这次答复是不用填,以前是填0000,应该也没问题填报完成后,按计算计算全部。
再审核,先详细当前表,在详细审核。
全部通过后,全部审核通过,选择上报数据。
(收发)上报时,要看到上报的路径。
Linux2 使用ntsysv命令配置服务

Linux2 使用ntsysv 命令配置服务
ntsysv 命令是一个在文本模式中,用来管理Linux 所有服务的工具。
执行ntsysv 时会透过选单让用户进行组态。
启动ntsysv 的语法如下:
其中的RUNLEVEL 代表要组态位在哪个Runlevel 的服务。
如果没有指定RUNLEVEL ,默认只会编辑目前的Runlevel 。
打开终端,执行“ntsysv ”命令,会进行配置服务界面,如图27所示。
在配置服务界面程序中,可以使用下面的按键进行操作,如表8所示:
图27 执行ntsysv 命令
如果用户想要启用某一个服务,只需要在ntsysv 里,使用箭头键移动画面上的光标到要启用的服务上,若显示[*],那表示这个服务已经启用;如果显示的是[ ],
那就表示这个服务被设定为停用。
此时用户可以按下空格键来切换服务启用的状态。
NTSYS软件进行聚类分析——UPGMA实例

NTSYS软件进行聚类分析——UPGMA实例第一部分说明文档Cluster analysis 聚合分析NTSYSpc最常见的使用是对某些相似或相异矩阵进行各种聚类分析。
以下是一个批处理例子;首先,标准化数据矩阵,其次,计算各列之间的距离系数,第三,采用单链路聚类方法,第四,计算表面值(超度量)矩阵和相关系数,第五,以散点图形式显示结果并同时输出距离矩阵。
" Standardize the variables*stand o=data.nts r=sdata.nts" Compute a distance matrix*simint o=sdata.nts r=dist.nts c=dist" Do a single-link cluster analysis of the distance matrix*sahn o=dist.nts r=tree.nts cm=single" Compute cophenetic values*coph o=tree.nts r=coph.nts" Compute the cophenetic correlation*mxcomp x=coph.nts y=dist.nts" Display phenogram*tree o=tree.nts" Display distance matrix*output o=dist.nts第二部分实例解析如果你的数据集包含量纲不一致的变量,则必须要先经过标准化处理,可以用STAND 组件完成。
如下图指明了标准化窗口。
Test.nts文件将被按行(意味着行为变量)标准化,并输出标准化文件名为teststand.nts。
如果你的变量量纲一致(如,基因序列)或者是定性数据则不需要标准化处理。
输出结果如下(5个变量的简单统计)下一步,相似或非相似矩阵数据集必须要在标准化后的数据集上构建,用来衡量各OTUS(列)两两之间的相似/非相似程度。
如何用NTsys构建0、1数据(AFLP)进化树

NTSYS-PC使用说明NTSYS是一个聚类分析的软件,可以用来分析AFLP,RAPD等电泳带型,也可用于微生物群落多样性的相似性分析。
下面简单介绍一下其用法:1.先建立一个0,1构成的矩阵:在excel中,按如下规则输入数据,A1=1表示有带记为1,B1=535表示AFLP样本数, C1=19表示有19个带型,D1=0表示无带记为0。
第二行表示的是样本名称。
从第三行开始的A列表示带型名称。
见下图:2.选择另存为,在其中的保存类型中选择“文本文件(制表符分隔)”然后点保存,确认。
3.打开NTSYS软件点“Similarity”下拉选择”“Qualitative date”在“input file”中选择刚才保存的.txt文件,在“output file”中输入保存文件名。
“Byrows”一项不选×,“coefficient”中选择J,点compute进行运算。
4.点软件左边第二项选择“SAHN”在“input file”中选择上一步运算出来的文件在“output tree file”中输入保存文件名。
点compute进行运算。
5.选择左边第二项中的“Cophenetic Values”在“input tree file”中选择刚才计算的tree文件,输入output的文件名,点compute进行计算。
6.作Mat检测:点击左面第三项,选择“Matrix comparison plot”在“input file(1)”中选择“Qualitative date”计算出的结果,在“input file(2)”中选择“Cophenetic Valuess”计算出的结果。
点击compute进行计算,r值在0.7以上为可信。
NTsys-pc2.1图解使用说明

NTsys-pc2.01图解使用说明
1数据的录入方法:
1)利用Ntedit直接录入数据
0、1二元数据中的数据缺失记为2。
其中列标可以写为样品编号(条带编号),在No.rows
栏中写入0、1数据总数,No.cols 栏中写入样品总数。
文件另存为*.nts格式。
2)从excel表中直接读入数据
Excel表中输入数据格式如下图。
A1必须为1,B1为0、1数据总数,C1为样品总数。
打开Ntedit程序,选择从Excel表输入,结果见上图。
文件另存为*.Nts格式
3)从文本文件读取数据:
2.聚类分析
Ntsys-pc2.02界面如下
以下以图中数据为例介绍聚类过程:
2.1 首先用similarity程序组中的Qualitative data计算形似系数矩阵。
Coefficient通常选用SM 或DICE,结果输出到另一文件。
2.2 以上步的结果作为input file利用Clustering程序组中的SHAN或者Njoin进行计算,聚类分法选用UPGMA,ties选用FIND,Maximum no. tied trees至少大于样品数。
Njoin程序组界面如下,rooting method可以选用Outgroup,但需输入外元。
2.3 将SHAN或NJoin方法得到的tree file文件输入到Graphics程序组中的tree plot程序中计算
得到树图如下
利用options可以对树图进行描述与处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
软件使用详细说明
一. 数据处理方法
:excel5/95格式数据
1)首先得到0/1数据,输入excel中,格式如图所示:
其中1表示数据格式为rectangular data matrix,12表示数据共12行(本例中表示12个个体),30表示数据共30列(本例中表示30个位点),0表示无缺失数据(若有缺失,则用1表示,缺失值可用-999或其它数字代替)。
2)格式及数据输入正确后,点击另存为excel5/95格式,命名为。
3)采用NTedit数据编辑器打开所保存的文件file>open file in a grid,在文件类型中选择excel格式,找到要分析的文件并打开,查看是否有错误,或需要修改的地方,没有问题后,保存为.nts格式。
:txt格式数据
1)另一种数据处理方法,首先在excel中得到数据,如下图(注意:第一行与第一种方法不同,1表示数据格式为rectangular data matrix;12B表示共12行(本例中表示12个个体,行标签位于数据主体的开始,B表示Beginning of each row),30L表示共30列(本例中表示30个位点,L:label表示列标签),0表示无缺失)。
或者如下图格式(其中第一行为1 12L 30L 0,解释略;第二行为每行的行标签;第三行为每列的列标签;第四行起为数据主体。
):
2)格式及数据都处理好之后,点文件另存为,保存为文本文件.txt格式。
3)得到txt格式文件后,即可直接用ntsys进行分析(只要格式正确,ntsys可以对txt文件进行分析,而不用再转换或保存成.nts格式)。
:直接采用NTedit进行数据的输入和保存
1)对于数据量不大的数据,可以直接采用NTedit进行数据的输入,如图所示:
2)数据输入好后,点击file>save file将数据保存.nts格式。
二. 计算遗传距离矩阵或相似性矩阵(distance matrix or similarity matrix)
对于0/1数据和定性数据:打开ntsys软件,在similarity模块中选择simqual,input file中输入要分析的文件名称,如,计算方法中矩阵系数coefficient选择dice,output file命名输出文件名称如aflp01-dice。
之后点compute,得到相似性矩阵。
注:1.本例中由于个体是按行排列的,所以要在By rows进行勾选(□表选中)。
如果个体是按列进行排列的,则不勾选。
2.系数可根据要求选择不同的系数,如DICE,J,SM,PHI等。
3. DICE,J只能得到相似性矩阵,可以采用1-dice系数,或者1-J系数得到距离矩阵。
只针对定性数据或二元数据(0/1),对于其它数据如DNA数据则采用simgend进行遗传距离计算,对于定量数据或间隔数据则采用simint计算距离矩阵。
三. 聚类分析(clustering)
SAHN进行upgma聚类分析
1)在得到相似性矩阵或距离矩阵文件之后,采用clustering模块中的SAHN,input file选择相似性矩阵文件,如,output file命名输出文件的名称,如,聚类方法中选择upgma,in case of ties选择find或者warn,点击compute得到结果,在程序左下角可以看到图标,点击即可得到聚类结果。
2)Upgma聚类结果如图所示,在该图中可点击options菜单对聚类图的文字格式和线条样式等进行修改,以得到满意的图片。
3)Cophenetic相关性检验
Upgma聚类分析之后,为了检验聚类结果的好坏,一般要进行cophenetic correlation 分析,操作如下:在clustering模块中选择Coph,如下图,input tree中输入聚类分析得到的结果文件,如,在输出文件中命名,点击compute,得到cophenetic值文件。
计算完成后在graphics模块中选择MxComp,在input file 1(x)中选择相似性矩阵文件,如,在input file 2(y)中选择coph计算得到的文件,如,number of permutation可选择1000次,或不选。
点击compute。
计算结束后得到分析结果,会出现矩阵比较图matrix comparison和correlation test 结果,如下面的两个图所示(相关性系数为r=,说明聚类结果较好)。
4)upgma聚类分析batch
上述的分析步骤可以采用batch进行批处理分析,命令如下(将下面的命令保存到文本文件,再保存成*.ntb格式):
" Compute a distance matrix
*simqual o= r= c=dice d=row
" Do a cluster analysis of the distance matrix
*sahn o= r= cm=upgma
" Display phenogram
*tree o=
" Compute cophenetic values
*coph o= r=
" Compute the cophenetic correlation
*mxcomp x= y=
NJ聚类分析-Njoin
1)得到距离矩阵:Simqual 只能得到各种相似性矩阵,如DICE或J相似性矩阵,但进行NJ聚类分析是,需要距离矩阵数据,可以采用1-相似性矩阵的方法得到距离矩阵(采用excel进行,但比较麻烦,还没有找到快捷的方法。
transf命令中好像没有1-矩阵的操作,只有矩阵-1的操作,好像也没有负值变成正值的操作)。
当然也可以采样其它的命令如simgend或simint得到DIST、欧式或其它距离矩阵之后进行NJ分析;或者采用其它的分析软件如Genalex软件得到距离矩阵用于ntsys分析。
2)打开ntsys的clustering模块,选择Njoin命令,input file中输入距离矩阵文件,命名保存的tree 和graph文件,in case of ties中选择find,maximum no. tied trees 中的数字不能小于OTUs的个数。
点击compute,即得到nj聚类树。
四. PCoA分析或PCA分析
PCoA分析
1)在得到相似性或距离矩阵之后,在output&transf模块中选择Dcenter命令,input 和output中分别输入要分析的数据和结果文件的名称。
点击compute进行分析,将数据进行Dcenter转换。
之后在ordination模块中选择eigen,选择要分析的文件,如,numer ofdimensions中选择3或者2(分别得到三维或二维图形,),命名eigenvactor和eigenvalue 文件名称,点击compute,得到分析结果。
分析完成后界面上会出现图标,点击进去可查看二维和三维图形,并可进行修改保存等操作。
2)在得到eigenvactor文件后,可采用graphics模块下的mod3d命令,显示pcoa分析图,input file中选择保存的eigenvactor文件,plot by rows 不选,进行分析,如下图所示。
3)进行mod3d分析时可以在plot symbol input file中可输入样本分组文件,如下图所示(其中1 1 20L 0表示数据类型为1;共1行,20列数据;0表无缺失,数据主体为1 1 1 1 1 1 1 2 2 2 2 2 2等,表示哪个个体定义的分组为1,那个为分组2等等)。
在定义分组进行分析后,得到的二维或三维plot图中,可以在plot option中对各个分组显示采用的图标以及字体大小等参数进行修改,如图所示。
当然plot symbol input file 也可以不输入,即全部个体为同一分组。
注:上述分析采用的是0/1或者定性数据,在采用数量或连续数据进行分析时,要先采用output&transf模块中的stand命令对数据进行标准化处理,然后在采用simint命令分析得到相似或不相似矩阵,然后采样Dcenter命令对数据进行中心化处理,之后在采用eigen 命令进行分析。
4)PCoA分析batch命令
五. 相关性分析(mantel test)
1)Mantel test可对两个矩阵的相关关系进行检验,这是由于对于某一特点的研究对象,可能有不同角度的特征描述,如根据表型数据得到表型距离矩阵,根据分子数据得到遗传距离矩阵,或者根据样本间地理位置得到地理距离矩阵,得到这些矩阵数据之后,我们可能会想了解不同描述间有没有相关关系(如遗传距离与地理距离之间相关性),这时即可进行矩阵的相关性分析。
2)具体操作如下:首先根据其它的软件如AFLPdat或Genalex等软件根据地理位置计算地理距离矩阵(例如X),打开ntsys软件,根据simint命令计算遗传距离矩阵(如Y),之后在graphics模块下选择MxComp,input file中选择要比较的距离矩阵文件,进行分析。
分析结果如下图所示:
3)mantel test分析batch命令:
" Compute morphological dissimilarity matrix
*simint o= c=dist r= d=row
" Compare mdist with gdist, 1000 random permutations *mxcomp x= y= np=1000。