实时数据分析平台、大数据分析、MPP数据仓库
大数据分析的10种常见工具

大数据分析的10种常见工具近年来,大数据已成为全球互联网和信息技术的一个热门话题。
作为一种宝贵的资源,数据可以帮助企业做出更明智的决策和市场分析。
在大数据时代,分析大量的数据是至关重要的,但是这种工作不可能手工完成。
因此,人们需要运用一些专业的工具来进行大数据分析的工作。
本篇文章将介绍10种常见的大数据分析工具。
一、HadoopHadoop是目前最流行的大数据框架之一。
它可以快速处理大量的数据,而且具有良好的可扩展性和容错性。
Hadoop分为两部分:Hadoop分布式文件系统(HDFS)和MapReduce框架。
HDFS用于存储大量的数据,而MapReduce框架则用于处理这些数据。
同时,Hadoop也可以集成不同的工具和应用程序,为数据科学家提供更多的选择。
二、SparkSpark是一种快速的分布式计算框架,可以处理大规模的数据,而且在数据处理速度上比Hadoop更加快速。
Spark还支持不同类型的数据,包括图形、机器学习和流式数据。
同时,Spark还具有丰富的API和工具,适合不同级别的用户。
三、TableauTableau是一种可视化工具,可以快速创建交互式的数据可视化图表和仪表盘。
该工具不需要编程知识,只需要简单的拖放功能即可创建漂亮的报表。
它还支持对数据的联合查询和分析,帮助用户更好地理解大量的数据。
四、SplunkSplunk是一种可扩展的大数据分析平台,可以帮助企业监视、分析和可视化不同来源的数据。
它通过收集日志文件和可视化数据等方式,帮助企业实时监控其业务运营状况和用户行为。
Splunk还支持触发警报和报告等功能,为用户提供更好的数据驱动决策方案。
五、RapidMinerRapidMiner是一种数据分析工具,可以支持数据挖掘、文本挖掘、机器学习等多种数据处理方式。
快速而且易于使用,RapidMiner可以快速分析和处理不同种类的数据。
该工具还提供了大量的模块和工具,为数据科学家提供更多的选择。
starrocks特点和使用场景

starrocks特点和使用场景标题:StarRocks:新一代极速实时分析型数据库及其应用场景**一、StarRocks简介**StarRocks是一款专为实时数据分析打造的高性能MPP(大规模并行处理)列式数据库系统。
其以“极速”和“实时”为核心特点,致力于解决现代企业面临的海量数据实时分析难题,为企业提供实时洞察业务、辅助决策的强大支持。
**1. StarRocks的主要特点:**- **极速性能**:StarRocks通过深度优化的列存引擎和高度并行的执行框架,实现了对PB级数据进行亚秒级查询响应,尤其在高并发场景下仍能保持卓越性能。
- **实时更新**:StarRocks支持实时数据写入与查询,满足用户对于数据时效性的严苛需求,确保企业能够基于最新数据做出快速反应。
- **水平扩展**:StarRocks采用分布式架构设计,可实现无缝水平扩展,轻松应对数据规模增长带来的挑战。
- **灵活易用**:StarRocks提供SQL标准接口,兼容MySQL协议,同时支持多种BI工具,使得用户可以便捷地进行数据查询与分析。
**二、StarRocks使用场景****1. 实时大数据分析**:适用于金融风控、广告推荐、物联网设备监控等需要实时处理与分析大量数据流的场景,例如实时监测交易风险、实时调整广告投放策略或实时监控设备运行状态。
**2. 商业智能(BI)与报表系统**:StarRocks强大的查询性能和实时性使其成为构建高效BI系统和复杂报表的理想选择,能够满足企业内部各部门对海量数据实时查询分析的需求。
**3. 互联网运营分析**:在电商、社交网络、在线教育等领域,StarRocks可用于用户行为分析、流量统计、活动效果评估等场景,帮助产品经理和运营人员实时了解业务动态,精准制定产品策略。
**4. 数据仓库加速层**:作为现有数据仓库系统的加速层,StarRocks可大幅提升查询速度,尤其针对那些涉及大量明细数据、实时性要求高的复杂查询。
实时高效数据分析平台架构设计

实时高效数据分析平台架构设计随着信息技术的不断发展,数据分析成为了企业决策的重要手段。
实时高效数据分析平台架构设计是企业保持竞争优势和快速发展的关键因素。
本文从数据获取、数据处理、数据存储、数据分析和可视化展现五个方面探讨实时高效数据分析平台架构设计。
一、数据获取数据获取是整个数据分析链路的第一步,其质量和准确度对后续分析结果有着至关重要的影响。
目前常见的数据来源有自建数据库、第三方数据服务、传感器设备等。
自建数据库是较为传统的数据获取方式。
企业可利用自身的业务系统、客户数据、市场调研数据等建立自己的数据仓库。
而第三方数据服务则是指企业购买第三方提供的数据服务来满足自身的数据需求。
此外,企业也可以借助传感器设备来获取环境、生产、物流等方面的数据。
二、数据处理数据获取后,需要进行数据处理和转化以适应后续计算和分析。
数据处理部分包括数据清洗、数据归约、数据预处理等环节。
数据清洗是指去除无效数据,修正或删除异常数据,规范数据格式等。
数据归约则是指将大量的原始数据进行降维处理并对数据进行过滤,从而减少数据的复杂性和冗余性。
数据预处理则是为了使数据更适合进入分析环节,可进行数据变换、离散化、归一化等操作。
三、数据存储数据存储环节是将处理好的数据进行持久化存储。
目前常见的数据存储方式有关系型数据库、非关系型数据库和数据仓库。
关系型数据库是指以表格形式存储数据的数据库,其特点是数据结构很严谨、数据一致性很高,但对于复杂数据的存储和查询能力较差。
非关系型数据库则是相对于关系型数据库的一种新型存储方式,其灵活性较高,适用于存储非结构化数据。
数据仓库则是为了更好地支持决策分析而设计的一种专门的数据存储设备。
四、数据分析数据分析环节是对存储起来的数据进行分析和挖掘,输出有用的信息和知识。
数据分析包括数据挖掘、机器学习、统计分析等。
数据挖掘是指利用计算机技术从海量数据中自动发现隐藏信息、规则和模式,从而帮助人们做出决策。
大数据分析平台与传统数据库的性能比较探究

大数据分析平台与传统数据库的性能比较探究随着互联网技术的不断发展,数据量呈现爆炸式增长,数据分析已成为企业发展中不可或缺的组成部分。
而大数据分析平台与传统数据库的性能比较也成为了一个备受关注的话题。
本文将探讨这两者的性能比较,并分析它们各自的优缺点。
一、大数据分析平台大数据分析平台(Big Data)是一种基于分布式计算模型的数据处理平台。
它可以帮助用户提高数据分析的效率和准确性,并为用户提供可视化的分析结果。
大数据分析平台主要由以下组件构成:1.计算集群:由大量计算机节点组成,可同时执行多个任务,缩短数据处理时间。
2.存储系统:多个存储单元组成,用于存储海量数据,保证系统的可扩展性和高可靠性。
3.分布式文件系统:类似于Hadoop的分布式文件系统(HDFS)。
它将文件切分成多个块,存储在不同的节点上,使得文件的读写速度更加快速。
4.分布式计算框架:类似于MapReduce的分布式计算框架,用于实现并行计算和数据处理。
5.数据分析工具:支持数据分析、可视化分析等。
根据目前市场上的数据分析平台,主流的大数据分析平台有Apache Hadoop、Spark、Flink等。
优点:1.具有非常强大的数据处理和计算能力,适合处理海量的数据。
2.高度可扩展性,可以对系统进行相应扩展以满足数据处理的需求。
3.具有较高的容错性,能够在某些计算节点出现故障的情况下,仍能保证系统的正常运作。
缺点:1.对于一些数据量较小的场景,使用大数据分析平台反而会造成资源浪费。
2.由于其分布式架构的复杂性,需要较高的技术水平才能进行系统的维护和管理。
3.数据处理也需要耗费大量的计算资源。
二、传统数据库传统数据库是一种基于关系型模型的数据处理平台。
它的数据存储方式为表格形式,通过SQL语言进行数据操作和查询。
现如今应用比较广泛的数据库有MySQL、Oracle、SQL Server等。
优点:1.易于使用,有成熟的交互式管理工具,可以通过简单的命令或者GUI界面完成对已有数据表的操作。
数据库、数据仓库、大数据平台、数据中台、数据湖对比分析

数据库、数据仓库、大数据平台、数据中台、数据湖对比分析一、概况层出不穷的新技术、新概念、新应用往往会对初学者造成很大的困扰,有时候很难理清楚它们之间的区别与联系。
本文将以数据研发相关领域为例,对比分析我们工作中高频出现的几个名词,主要包括以下几个方面:•数据▪什么是大数据▪数据分析与数据挖掘的区别是什么•数据库▪什么是数据库▪数据库中的分布式事务理论•数据仓库▪什么是数据仓库▪什么是数据集市▪数据库与数据仓库的区别是什么•大数据平台▪什么是大数据平台▪什么是大数据开发平台•数据中台▪什么是数据中台▪数据仓库与数据中台的区别与联系•数据湖▪什么是数据湖▪数据仓库与数据湖有什么区别与联系希望本文对你有所帮助,烦请读者诸君分享、点赞、转发。
二、数据什么是大数据?麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
我们再往深处思考一下,为什么会有大数据(大数据技术)?其实大数据就是在这个数据爆炸增长的时代,业务需求增长促进技术迭代,技术满足需求后又形成闭环促进业务持续增长,从而形成一个闭环。
数据分析与数据挖掘的区别是什么?数据分析可以分为广义的数据分析和狭义的数据分析。
广义的数据分析就包括狭义的数据分析和数据挖掘。
我们在工作中经常常说的数据分析指的是狭义的数据分析。
三、数据库据库什么是数据库?数据库是按照数据结构来组织、存储和管理数据的仓库。
是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
一般而言,我们所说的数据库指的是数据库管理系统,并不单指一个数据库实例。
根据数据存储的方式不同,可以将数据库分为三类:分别为行存储、列存储、行列混合存储,其中行存储的数据库代表产品有Oracle、MySQL、PostgresSQL等;列存储的数据代表产品有Greenplum、HBASE、Teradata等;行列混合存储的数据库代表产品有TiDB,ADB for Mysql等。
MPP数据库对比
1概述随着海量数据问题的出现,海量管理能力,多类型,变化快,高可用性,低成本,高端可扩展性等需求给企业数据战略带来了巨大的挑战。
企业数据仓库、数据中心的技术选型变得尤其重要!所以在选型之前,有必要对目前市场上各种大数据量的解决方案进行分析。
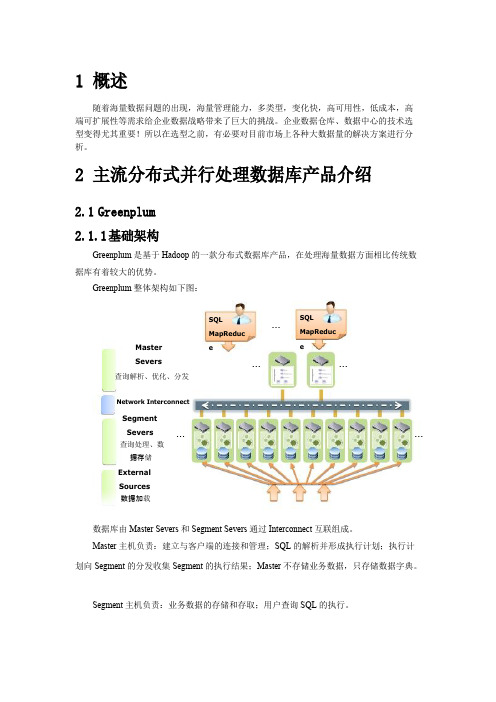
2主流分布式并行处理数据库产品介绍2.1Greenplum2.1.1基础架构Greenplum是基于Hadoop的一款分布式数据库产品,在处理海量数据方面相比传统数据库有着较大的优势。
Greenplum整体架构如下图:SQL MapReduc ...SQLMapReducMaster e eSevers查询解析、优化、分发Network InterconnectSegment......Severs......查询处理、数据存储ExternalSources数据加载数据库由Master Severs和Segment Severs通过Interconnect互联组成。
Master主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计划向Segment的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
Segment主机负责:业务数据的存储和存取;用户查询SQL的执行。
2.1.2主要特性Greenplum整体有如下技术特点:◆Shared-nothing架构海量数据库采用最易于扩展的Shared-nothing架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
◆基于gNet Software Interconnect数据库的内部通信通过基于超级计算的“软件Switch”内部连接层,基于通用的gNet (GigE,10GigE)NICs/switches在节点间传递消息和数据,采用高扩展协议,支持扩展到1000个以上节点。
◆并行加载技术利用并行数据流引擎,数据加载完全并行,加载数据可达到4。
5T/小时(理想配置)。
大数据分析的十个工具

大数据分析的十个工具在如今数字化的时代,数据变得越来越重要了。
数据不仅仅是一组数字,它代表了事实和现实生活中的情况。
但是,处理数据变得越来越困难。
若要快速高效地处理数据,需要工具的帮助。
本文将介绍大数据分析的十个工具。
1. HadoopHadoop是Apache Hadoop生态系统的核心项目,基于Java编写,主要用于存储和处理大数据集。
Hadoop可以处理来自无数来源的大数据集,包括文本、图形数据和孪生数据等。
2. Apache SparkApache Spark是一个高速的大规模数据处理引擎,它使用内存计算而不是磁盘计算,以显著提高处理速度和效率。
Spark支持多种语言,如Java,Scala和Python等。
3. Apache StormApache Storm是一个分布式流处理引擎,可用于处理数据流以及将数据流分析成有价值的信息。
它主要用于实时数据流处理,并且可扩展性非常好。
4. ElasticsearchElasticsearch是一个分布式搜索和分析引擎,可用于处理大量的非结构化和结构化数据。
Elasticsearch还提供了一些丰富的API,使开发人员能够更轻松地使用和管理数据。
5. TableauTableau是一个可视化工具,可用于创建数据可视化和分析。
该工具提供了丰富的功能和工具,可用于从各种数据源中获取数据,并将其视觉化展示给用户。
6. IBM Watson AnalyticsIBM Watson Analytics是一个智能分析工具,可用于透彻了解数据并提供见解。
该工具使用自然语言处理技术,使分析过程更加人性化和智能。
7. PigApache Pig是一种用于分析大型数据集的脚本语言。
它可以与Hadoop一起使用,支持广泛使用的语言和库。
8. Apache CassandraApache Cassandra是一个主要用于处理分布式的非结构化数据的开源NoSQL数据库。
Cassandra具有高可用性和可扩展性,可以为大型分布式数据存储提供高效的解决方案。
实时数据中心解决方案(

系统数据手工数据外部数据非结构化数据
系统间数据传输组织间数据传输内外部数据传输
系统间数据整合异构系统数据整合实时数据整合结构与非结构数据整合
接口数据层整合数据层汇总数据层面准实时数据层
数据共享数据分析数据智能数据服务
实时数据中心的背景与理解
企业实时数据中心——企业将数据视为资产,使其在企业整个组织内便利和有效的流通来,从企业自身数据中充分挖掘价值潜力,最终形成贯穿企业组织间、业务间、产业链伙伴间的完成数据生态系统。
实时数据中心-总体目标
企业实时数据中心
定标准
建体系
搭平台
立应用
实现企业自上而下的数据管理规范与标准的顶层设计跨业务、跨组织、跨领域统一标准与规范
建设企业经营监管的决策与管控分析体系、多层级、多角色、多领域实现由“数据驱动”的企业经营与管控目标
建设企业级的数据管理平台,实现“实时数据中心”的数据生产、数据传输、数据采集、数据整合、数据存储全过程,为数据应用奠定平台基础
财务
人力
供应链
资金
成本
预算
售楼
商务
其他
业务系统
音频
视频
SNS
网站
文本
微信
微博
行业
其他
非结构化半结构化
UDH(低价值密度数据)
流处理技术
ODS
DW
元数据管理
主数据管理
数据质量
数据安全
ODS
ODS
DM
DM
DM
ETL
ETL
ETL
CDC
ETL
MQ
存储
建模
……
数据仓库
统一数据服务 统一数据应用
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据分析平台
分析平台
实时加载 & 查询
高级库内分析
数据设计 & 管理工具
列式存储 & 执行
强劲的数据压缩
扩展的MPP架构
自动的高可用性
优化器, 执行引擎 & 负载管理
内在的 BI, ETL, & Hadoop/MapReduce 集成
Vertica的分析平台为特定目的建造的,以使公司从他们的数据中提取价值,他们需要在今天的经济环境中茁壮成长的速度和规模。
不像大多数其它的数据仓库供应商正试图改造21世纪的技术,几十年的老基础设施,Vertica的设计和建造自成立以来,为当今最苛刻的分析工作负载。
此外,每一个的Vertica的成分是由设计,能够充分利用其他。
Vertica分析平台关键特性
实时查询 & 加载 »通过不断加载的信息,获取数据的时间
价值,同时允许立即进行丰富的分析。
高级的库内分析 »不断增长的特点和功能库,展示和处理
更多和CPU内核紧密结合的数据,而无需解压。
数据设计 & 管理工具 »强大的设置,调整和控制以达到使
用最小的管理工作,就可以进行持续改进,而系统仍然保
持在线。
列式存储 & 执行 »执行查询快50 - 1000倍,消除了昂贵的
磁盘I / O,没有的索引和物化视图的麻烦和开销。
强劲的数据压缩 »我们的引擎,以较少的资本性支出完成
更多的压缩数据,同时提供卓越的性能。
可扩展的MPP架构 »Vertica的自动和无限线性扩展,只需
在网格中添加行业标准x86服务器
自动的高可用性 »不间断地运行与优化,提供卓越的查询
性能,良好的自动冗余,故障切换和恢复。
优化器执行引擎 & 负载管理 »获得最大的性能,而无需担
心它如何工作的细节。
用户只思考有关的问题,我们快速
地提供答案。
内在的 BI, ETL, & Hadoop/MapReduce 集成 »一个强大和
不断增长的生态系统的分析解决方案的无缝集成。
今天,世界各地的信息是连续产生的。
因此,隔夜批量加载
数据已经成为奢侈的过去。
组织必须能够不停顿地加载到信
息到他们的分析平台,同时允许进行数据丰富的分析。
信息的时间价值是非常重要的,在数据产生后,用户越早处理就越有价值。
对于零售商来说,这可能意味着即时的
促销和库存的摆放。
对于金融公司,这会影响到及时的交易
决策。
对于网络游戏公司,这提供了更加个性化和引人入胜
的游戏体验。
这个最小延迟的量是不容易的壮举。
因为从网
络源,用户鼠标点击,金融交易,传感器网络和越来越多的
其他来源的信息量是压倒性的挑战。
混合的主存中/磁盘上架构
当加载数据的时候,与传统的、管理者繁重的锁的关系数据库系统不同,Vertica设计了一个独特的时间旅行实务模型,以确保极高的并发查询,同时把新的数据加载到系统中。
Vertica通常是传统的行存储数据库加载速度的10多倍。
此外,Vertica的为特定目的建造的混合主存内/磁盘上架构,以确保近实时的信息可用性。
在分析操作中,我们会自动地查询在内存中和磁盘中的位置,并返回请求的单一结果。
Vertica’s FlexStore™
Vertica的FlexStore技术使用户能够控制每列数据不同的存储介质。
这允许Vertica的管理员可以很容易地把最频繁的列放在一个更快的存储层,
例如固态硬盘驱动器或Fusion-io驱动器。
开始加载时,数据在数据库中最佳的层和位置是自动分配的。
实时数据分析平台、大数据分析、MPP数
据仓库 - vertica (三)高级库内分析
Vertica的提供了一个强大和不断增长的先进的数据库内分析功能,客户可以进行数据紧密的分析计算,并可以从一个地方立即得到答案,而不需要把信息抽取到一个单独的环境。
把数据保持在数据库中是特别关键的,因为数据集的大小从TB到PB级及以后的变化。
更重要的是,Vertica的原生解析函数和UDF还专门设计可以充分利用我们独特的MPP并行机制,列存储和执行,比其他任何平台上执行得更快。
Vertica的提供完整的ANSI标准SQL的支持,SQL分析功能,规则的文本表达式,原生SQL的扩展和用户定义函数(UDF)框架。
UDF正在迅速扩大,超出今天我们提供的SQL宏的UDF。
所有这些提供给业务分析师,开发人员和管理员的灵活性和简单性,使他们能够利用大量的信息,在并行处理上而无需博士学位。
他们
可以简单地使用他们喜欢的工具提问。
Vertica高级分析特性包括:
原生空白填补
插补
事件窗口功能
图形遍历
序列化
Vertica的简洁SQL语法扩展,使用这些SQL语句的扩展是非常简单的,因此不存在需要学习和使用另一种语言。
谈NoSQL的有很多,但真正的问题是不是SQL语法。
传统的RDBMS性能表现不佳。
就拿社会网络端点分析中图的遍历来说,传统的RDBMS会使用连接和痛苦多路自联接得到一个答案,这通常会使系统过载,且无法返回最终结果。
另外,可以使用自定义的数据结构和程序语言,但不幸的是,这些往
往不是企业级的,缺乏简单,可扩展性和高效率的并行化。
另一方面,使用我们的MPP操作和有效的列链接,执行排序与标准的SQL语法,Vertica能够提供这些强劲的功能和简单性。
最重要的是,Vertica 的优化和执行引擎喂你处理所有的规划和并行。
基于事件的窗口
您还可以使用Vertica基于事件的窗口,把时间序列数据放入运行的窗口中。
特别是财务相关的数据分析可能会集中在特定事件触发其他活动。
sessionization,一个特殊的情况下,基于事件的窗口,是一种经常用来分析点击流的功能,如标识在一个特定的时间内从记录的Web 点击web浏览的会话。
暴力的过程方法,可以实现这一点,但Vertica简单,高效,大规模并行,Web会话以一个即席查询的方式与不同的运行窗口中确定的参数完成。
举例来说,30秒可能就不会是一个平均的web 访问会话。
Vertica可以自动地分析同一IP地址会话的时间间隔,以确定平均会话时间,然后根据这个参数或会话数据自动地进行标记。
Vertica投入巨资研发更强大的数据库内分析,使我们的客户能够以执行额外的统计,地理空间,决策树和几个其他先进的分析。
让他们的数据以更多的方式,更快地使用SQL或他们喜欢的程序编程或脚本语言。
进一步阅读
更多Vertica库内分析, 在我们的博客上检查这些链接:
Sessionize with Style – Part 1
Sessionize with Style – Part 2
More Time Series Analytics: Event-Based Window
Functions
Gap Filling and Interpolation (GFI)
Reading between the Lines with Vertica 4.0。