八爪鱼xpath入门学习(以提取网页中公司名和地址为例)
八爪鱼采集器使用进阶教程共24页文档

一起使用 •使用循环
与文本循环配合使用,达到循环输 入文本效果 •自定义
设置Xpath路径表达式,根据用户 需求自定义流程步骤位置
识别验证码
基本信息:
•识别验证码 流程步骤名称
高级选项:
•执行前等待 流程步骤执行前等待时间
•或者出现元素 填写Xpath路径,配合执行前等待
循环本身不产生任何操作,只负责建立循环,与
循环产生联动的是勾选了使用循环的流程步骤,来达到 循环的效果 循环/提取数据
与上述类似,循环本身不会产生任何操作,真正 与循环产生联动的是勾选了使用循环的提取数据
流程结束图标,此图片代表一个任务执行完成到 循环 结束
提取数据
运行逻辑
循环Ⅰ
循环Ⅰ第一项 循环Ⅰ第二项 循环Ⅰ第三项
。
。
。
循环Ⅰ第N项 。
。
。
循环Ⅰ结束
循环Ⅱ第一项 循环Ⅱ第二项
一起使用 •验证码图片Xpath
填写Xpath路径,告诉八爪鱼验证 码图片位置 •验证码输入框Xpath
输入框Xpath,用于配合验证码图 片Xpath,正确输入验证码 当前验证码
用于流程设计时调试规则用
判断条件
基本信息:
•判断条件 判断条件分为此次判断条件整体,
和各具体条件分支 条件分支
按不同分支条件执行不同流程步骤
•或者出现元素 填写Xpath路径,配合执行前等待一
起使用,在等待时间内元素出现则不再继 续等待 •使用当前循环
与循环配合使用 •添加其他特殊字段
网页标题、时间、当前时间、固定 字段等特殊字段
自定义数据字段(修改抓取方式, 定位方式即XPath,格式化数据 删除选中字段 将选中字段上移、下移
八爪鱼xpath入门教程以及定位元素实例

xpath入门教程以及定位元素实例本文用来讲解xpath的入门基础,本教材是xpath入门2,建议大家从入门1教程开始学习Xpath的教程适合对八爪鱼已经有一些基础的用户来学习。
示例地址/tutorial?type=0&page=0&tag=%E8%BF%9B%E9%98%B6&version=otherXpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。
Html:超文本标记语言,是用来描述网页的一种语言。
主要用于控制数据的显示和外观。
HTML文档也被称为网页。
Xpath专用于xml中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对Html的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
xpath入门2-图1例如下图通过火狐的firebug、firepath查看网页源码。
查看方法参考“xpath入门1”教程xpath入门2-图2完整的HTML文件至少包括<HTML>标签、<HEAD>标签、<TITLE>标签和<BODY>标签,并且这些标签都是成对出现的,开头标签为<>,结束标签为</>,在这两个标签之间添加内容。
通过这些标签中的相关属性可以设置页面的背景色、背景图像等。
Html标签作为开始和结束的标记由尖括号包围的关键词,比如 <html>标签对中,第一个标签是开始标签,第二个标签是结束标签元素HTML的网页内容是由元素组成的,从开始标签到结束标签的所有代码。
元素的开始和结束都使用标签作为开始和结束的标记节点所有事物都是节点整个文档是一个文档节点每个 HTML 元素是元素节点HTML元素内的文本是文本节点每个 HTML 属性是属性节点注释是注释节点Html常见标签<a></a> 定义超链接,用于从一张页面链接到另一张页面<h1></h1> 文本标题标签,最大的标签。
【八爪鱼采集教程】提取数据如何使用备用位置
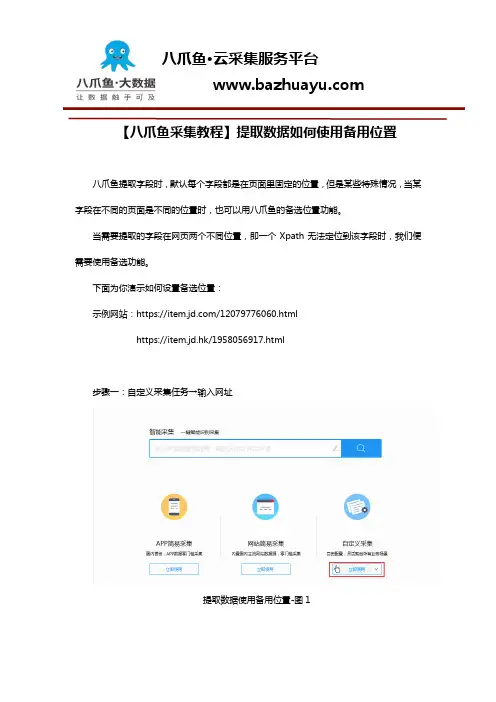
【八爪鱼采集教程】提取数据如何使用备用位置八爪鱼提取字段时,默认每个字段都是在页面里固定的位置,但是某些特殊情况,当某字段在不同的页面是不同的位置时,也可以用八爪鱼的备选位置功能。
当需要提取的字段在网页两个不同位置,即一个Xpath无法定位到该字段时,我们便需要使用备选功能。
下面为你演示如何设置备选位置:示例网站:https:///12079776060.htmlhttps://item.jd.hk/1958056917.html步骤一:自定义采集任务→输入网址提取数据使用备用位置-图1提取数据使用备用位置-图2步骤二:提取元素字段(商品名、店铺名)提取数据使用备用位置-图3步骤三:保存并启动 直接单机运行可以看到第二个网页店铺名空白,提取不到提取数据使用备用位置-图4这时我们回到流程界面,手动运行一下规则。
提取数据使用备用位置-图5提取数据使用备用位置-图6发现第一个网页的字段2可以提取到,第二个网页则为空白,提取不到。
说明两个网页店铺名的字段Xpath不一样,我们用第一个网页的Xpath提取不到第二个网页的信息。
这时我们需要用到备用位置。
步骤四:选中店铺名字段→点击自定义字段→自定义定位元素方式→设置备用位置提取数据使用备用位置-图7 提取数据使用备用位置-图8提取数据使用备用位置-图9提取数据使用备用位置-图10说明:点击需要设置备用位置的元素,选择将这个元素设为备选即可。
也可以自己通过Xpath 进行修改。
提取数据使用备用位置-图11提取数据使用备用位置-图12单机运行一次,发现可以采集到,设置备用位置成功。
提取数据使用备用位置-图13相关采集教程:淘宝评论采集新浪微博数据采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
如何利用八爪鱼爬虫抓取数据

如何利用八爪鱼爬虫抓取数据听说很多做运营的同学都用八爪鱼采集器去抓取网络数据,最新视频,最热新闻等,但还是有人不了解八爪鱼爬虫工具是如何使用的。
所以本教程以百度视频为例,为大家演示如何采集到页面上的视频,方便工作使用。
常见场景:1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。
2、当视频链接在标签中,可切换标签进行采集。
3、当视频链接在标签中,也可采集源码后进行格式化数据。
操作示例:采集要求:采集百度视频上综艺往期视频示例网址:/show/list/area-内地+order-hot+pn-1+channel-tvshow操作步骤:1、新建自定义采集,输入网址后点击保存。
注:点击打开右上角流程按钮。
2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。
在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
3、创建循环点击列表。
点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片)继续选择循环点击每个元素4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。
手动更换为A标签:更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。
5、所有操作设置完毕后,点击保存。
然后进行本地采集,查看采集结果。
6、采集完成后将URL导出,使用视频URL批量下载工具将视频下载出来就完成了。
相关采集教程:公告信息抓取/tutorial/hottutorial/qita/gonggao网站源码抓取/tutorial/hottutorial/qita/qitaleixing网页抓取工具新手入门/tutorial/xsksrm八爪鱼网站抓取入门功能介绍/tutorial/xsksrm/rmgnjsajax网页数据抓取/tutorial/gnd/ajaxlabel模拟登录并识别验证码抓取数据/tutorial/gnd/dlyzmxpath抓取网页文字/tutorial/gnd/xpath八爪鱼抓取AJAX滚动页面爬虫教程/tutorial/ajgd_7网页采集提取数据教程,以自定义抓取方式为例/tutorial/zdytq_7八爪鱼——90万用户选择的网页数据采集器。
最全的八爪鱼循环提取网页数据方法

最全的八爪鱼循环提取网页数据方法在八爪鱼中,创建循环列表有两种方式,适用于列表信息采集、列表及详情页采集,是由八爪鱼自动创建的。
当手动创建的循环不能满足需求的时候,则需要我们手动创建或者修改循环,以满足更多的数据采集需求。
循环的高级选项中,有5大循环方式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。
一、URL循环适用情况:在多个同类型的网页中,网页结构和要采集的字段相同。
示例网址:https:///subject/26387939/https:///subject/6311303/https:///subject/1578714/https:///subject/26718838/https:///subject/25937854/https:///subject/26743573/ 操作演示:具体请看此教程:/tutorialdetail-1/urlxh_7.html二、文本循环适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。
实现方式:通过文本循环方式,实现循环输入关键词,采集关键词搜索结果。
示例网址:https:///操作演示:具体请看此教程:/tutorialdetail-1/wbxh_7.html注意事项:有的网页,点击搜索按钮后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需放在文本循环内。
例:https:///如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。
经过调整,将打开网页步骤,放到循环内,则可以提取到两个关键词的搜索结果文本,文本循环流程可正常执行。
具体情况此教程::/tutorialdetail-1/urlxh_7.html三、单个元素循环适用情况:需循环点击页面内的某个按钮。
例如:循环点击下一页按钮进行翻页。
实现方式:通过单个元素循环方式,达到循环点击下一页按钮进行翻页目的。
八爪鱼提取网页数据的方法

视频教程PPT
提取数据
一、添加特殊字段、上移下移、抓取模板导入导出
二、找不到时如何处理
三、自定义抓取方式 四、自定义定位元素方式 五、备用位置 六、格式化数据
七、自定义合并方式
一、 添加特殊字段、上移下移、抓取模板导入导出
1、添加特殊字段 当前时间 固定字段 空字段 当前页面信息 2、字段上移下移 3、抓取模板导入导出 示例网址: /fang1/
五、备用位置
八爪鱼提取字段时,默认每个字段都是在页面里固定的位置。 但是某些特殊情况,当某字段在不同的页面,是处于不同的位置时,可以用八爪鱼 的备选位置功能。 示例网址: https:///item.htm?spm=a1z10.1-c-s.w1201073114573359259.1.1c3577c8vTygcq&id=566814688341(淘宝商品详情页) https:///item.htm?spm=a230r.1.14.27.2e932897hyfHKC&id= 565712872904&ns=1&abbucket=4(天猫商品详情页)
二、找不到时如何处理
找不到数据时的三种处理办法 使用默认值 在找不到数据时默认填写一个字段,以补充没有采集到的内容 该字段留空 可以在结果中明显的看到哪里有数据没采集到 该步骤所有字段留空 一个字段找不到数据时,便忽略该信息所有字段,相当于跳过该条信息的采集 示例网址:https:///subject/25862578/ https:///subject/1858513/
六、格式化数据
利用格式化数据对需要的字段进行修改 替换 正则表达式替换 去除空格 添加前缀 添加后缀 日期时间格式化 Html转码 示例网址: https:///subject/25862578/
八爪鱼获取数据的内容和方法
八爪鱼是一种网络爬虫工具,可以帮助用户快速获取网页上的数据。
以下是使用八爪鱼获取数据的内容和方法:
确定目标数据源:首先需要确定要获取数据的网站或数据源,了解网站的结构、数据存储方式以及是否存在反爬机制等信息。
选择合适的采集模板:八爪鱼提供了多种采集模板,可以根据目标数据源的结构和数据特点选择合适的模板,如列表页采集、详情页采集等。
配置采集规则:根据目标数据源的特点和需求,配置相应的采集规则,如提取链接、提取字段等。
运行采集任务:配置完成后,可以运行采集任务,八爪鱼会自动按照配置的规则抓取数据。
处理和导出数据:八爪鱼支持将抓取的数据保存为多种格式(如Excel、CSV等),可以根据需要选择相应的格式导出数据。
优化采集规则:在实际使用中,可能需要不断调整和优化采集规则,以获取更准确、更完整的数据。
需要注意的是,在使用八爪鱼进行数据采集时,需要遵守相关法律法规和网站的使用协议,不要进行恶意爬取或滥用数据等行为。
同时,也要注意保护个人隐私和信息安全。
xpath提取链接写法
xpath提取链接写法XPath是一种在XML文档中查找信息的语言,它可以在XML文档中定位到特定的元素,并提取出其中的链接。
XPath在网页抓取、数据提取等领域有着广泛的应用。
下面将介绍一些常用的XPath提取链接的写法。
一、提取所有链接如果要提取一个XML文档中所有的链接,可以使用以下XPath表达式:```//a/@href|//link/@href```这个表达式会匹配所有的`<a>`和`<link>`元素,并提取其中的`href`属性值,即链接地址。
需要注意的是,如果文档中有其他类型的链接元素,例如`<img>`元素的`src`属性,也可以使用同样的XPath 表达式来提取。
二、提取指定元素的链接如果要提取XML文档中某个特定元素的链接,可以使用以下XPath表达式:```python//element_name[@attribute='value']/@href```这个表达式会匹配所有符合指定元素名和属性的链接元素,并提取其中的`href`属性值。
例如,如果要提取所有名为`<div>`的元素的链接地址,可以使用以下XPath表达式:```css//div[@id='div_id']/@href```三、提取HTML页面中链接如果要提取HTML页面中的链接,可以使用以下XPath表达式:```css//a/@href|//link/@href|//img[@src='']/@src```这个表达式会匹配所有的`<a>`,`<link>`和`<img>`元素,并提取其中的`href`和`src`属性值。
需要注意的是,如果要提取其他类型的链接元素,例如`<area>`元素的`href`属性,也可以使用同样的XPath 表达式来提取。
四、提取特定标签内部的链接如果要提取HTML页面中某个特定标签内部的链接,可以使用以下XPath表达式:```css//tag_name[text()='search_string']/@href```这个表达式会匹配所有符合指定标签名和文本内容的链接元素,并提取其中的`href`属性值。
八爪鱼爬虫详细使用教程
八爪鱼爬虫详细使用教程作为一款简单易用的网页数据采集工具,八爪鱼的强大功能早已深入人心。
为了让更多人学会使用八爪鱼,小编整理了一个以采集百度贴吧帖子内容为例的教程,提供给大家操作学习。
本文以采集百度贴吧帖子内容为例,介绍八爪鱼爬虫的使用教程。
在这里仅仅以其中一个帖子举例说明:旅行贴吧的某个帖子(【集中贴】2018年1、2月出发寻同行的请进来登记)采集内容包括:贴吧帖子内容,贴吧用户昵称使用功能点:●创建循环翻页●修改Xpath步骤1:创建百度贴吧帖子内容采集任务1)进入主界面,选择“自定义采集” 2)将要采集的网站URL复制粘贴到输入框中,点击“保存网址”步骤2:创建循环翻页1)网页打开以后,鼠标下拉到最底部,选择下一页,提示框中选择“循环点击下一页”2)鼠标选中帖子的回复,在右面的提示框中选择“选中全部”2)如果要采集贴吧的其他信息,也可以选择,这里选择的是贴吧昵称,贴吧昵称。
接着选择“采集元素”,把不必要的字段删除。
步骤3:修改XPATH1)保存采集后发现有些帖子内容没有正确采集,所以需要修改XPATH,打开右上角的流程按钮2)点击循环选项,“循环方式”选择“不固定元素列表”,“不固定元素列表”填入XPATH://div[@class="l_post j_l_post l_post_bright "]。
2)点击“提取数据”,修改贴吧帖子内容XPATH。
选中帖子内容字段,依次点击“自定义数据字段”->“自定义元素定位方式”,并设置:元素匹配的XPATH://div[@class="l_post j_l_post l_post_bright "]//div[@class="d_post_content j_d_post_content clearfix"]相对XPATH://div[@class="d_post_content j_d_post_content clearfix"]选中帖子内容字段自定义数据字段位置帖子内容字段数据提取xpath设置3)修改贴吧用户昵称XPATH。
【八爪鱼v7采集教程】分页列表详细信息采集方法
【八爪鱼采集教程】分页列表详细信息采集方法很多网站有会这种模式,多个列表页面,点击列表中的一行链接会打开一个详细信息页面,本文给大家演示如何采集分页列表详情页面里的信息。
目的是让大家了解怎么创建循环翻页并能正常采集网页详情的数据信息。
本文教程里讲到的示例网站地址为:/guide/demo/moviespage1.html步骤1登陆八爪鱼7.0采集器→点击新建任务→自定义采集,进入到任务配置页面:然后输入网址→保存网址,系统会进入到流程设计页面并自动打开前面输入的网址。
分页列表详细信息采集-图1我们需要循环点击下图浏览器中电影名称,再提取子页面中的数据信息,所以我们需要先做一个翻页循环再做一个循环点击电影名称提取数据的列表。
步骤2点击下图浏览器页面中的“下一页”按钮,在弹出的对话框中选择“循环点击下一页”;分页列表详细信息采集-图2下面对电影名称创建循环点击步骤3 鼠标点击下图中第一个电影名称“教父:第二部”,在弹出的操作提示中选择“选中全部”选项, 然后选择“循环点击每个链接”选项分页列表详细信息采集-图3分页列表详细信息采集-图4接下来页面就自动跳转到详情页面中去了,我们再做提取数据步骤4 点击要提取的标题在弹出的提示框中选择“采集该元素的文本”,然后同样的方式选择点击浏览器中的其他字段,再选择“采集该元素的文本”分页列表详细信息采集-图5步骤5 这样提取完毕之后我们可以点一下流程按钮,然后修改字段名称。
在下面界面中修改字段名称,修改完成之后,点击“确定”保存分页列表详细信息采集-图6步骤6 点击“保存并启动”,再再弹出的对话框中选择“启动本地采集”。
系统会在本地开启一个采集任务并采集数据, 接下来选择导出数据,这里以选择导出excel2007为例,然后点击确定. 之后选择文件存放路径,再点保存即可分页列表详细信息采集-图7下面是数据示例分页列表详细信息采集-图8相关采集教程:黄页88数据采集赶集招聘信息采集大众点评评价采集八爪鱼——70万用户选择的网页数据采集器。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
xpath入门学习(以提取网页中公司名和地址为例)
本文用来讲解xpath的入门基础,适合对八爪鱼已经有一些基础的用户来学习。
文中示例地址为:/qiye2309554/
/qiye2275810/
提取两个网页中的公司名称和地址字段。
Xml和Html之间既有相似之处,又有很大区别。
Xml包含数据和对数据的描述,主要用来交换数据。
Html也包含了数据和对数据的描述,但只是针对描述网页这种用途,Html结构看起来和Xml类似,但并不严格遵循Xml标准,可以看做不标准的Xml。
Xpath是专门针对Xml设计的,在复杂结构化数据中查找信息的语言,而我们的网页实质上是Html的文档,那如何对网页执行Xpath查询呢?八爪鱼采集器内部有一套针对Html 的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
给大家介绍一个类似的工具,就是火狐浏览器里面firebug和firepath插件。
首先在电脑上先安装火狐浏览器,然后打开火狐浏览器右上角的打开菜单按钮,选择添加组件。
Xpath入门1-图1:附件组件
在弹出的对话框中搜索firebug组件,搜索出来之后选择安装。
Xpath入门1-图2:安装firebug
安装成功之后同样的方式搜索firepath进行安装。
小贴士:安装成功之后,浏览器需要重启一下才能完全安装成功。
重新打开浏览器中,可以看到多了一个昆虫按钮,代表安装成功。
在浏览器中打开一个网页,再点击浏览器中的firebug按钮,就弹出了可以用xpath的firepath工具。
Xpath入门1-图3:firepath工具
按照下面的操作可以找到数据的精确位置。
点击firepath工具中“查看页面中的元素”按钮→选择网页中要提取的字段→可以看到firepath工具中显示出了xpath路径
Xpath入门1-图4:“查看页面中的元素”按钮
Xpath入门1-图5:字段与其对应的xpath路径
这种定位方式在八爪鱼采集器里面也是通用的,例如:
步骤1 点击新建任务→自定义采集,进入到任务配置页面:
然后输入要采集的两个网址→保存网址,系统会进入到流程设计页面并自动打开前面输入的网址。
Xpath入门1-图6:打开网页
步骤2然后进行数据字段的提取,鼠标点击页面中要提取的“公司地址”字段,这里字段就被选中了并通过红色框表示,然后在弹出的提示框中选择“采集该元素的文本”表明要采集的是页面中的文本数据
Xpath入门1-图7:提取字段
同样的方式提取“公司名称”字段
Xpath 入门1-图8:提取字段
步骤3 这样提取完毕之后我们可以点一下流程按钮,然后修改字段名称。
这里的字段名称相当于表头,便于采集时区分每个字段类别。
在下面界面中修改字段名称,修改完成之后,点击“确定”保存
Xpath 入门1-
图9:修改字段名称
步骤4点击“保存并启动”,再在弹出的对话框中选择“启动本地采集”
系统会在本地电脑上开启一个采集任务并采集数据,任务采集完毕之后会弹出一个采集结束的提示,可以看到采集完之后第二条数据的公司地址采集是错误的,采集到的并不是公司地址而是主营产品。
Xpath入门1-图10:启动采集
Xpath入门1-图11:第二条数据出错
步骤5 这时候回到客户端上手动执行这个规则,选择第二条URL,再点提取数据可以公司地址就本身提取到的是主营产品。
Xpath入门1-图12:选择第二条URL
Xpath入门1-图13:提取数据步骤,提取的是主营产品
步骤6 这里可以把八爪鱼生成的xpath复制到火狐浏览器中去看,可以看到在第一个URL 中匹配是对的,但是在第二个网页中匹配就是错误的
Xpath入门1-图14:点击自定义定位元素方式
Xpath 入门1-图15:复制八爪鱼自动生成的xpath
Xpath
入门
1-图16:第一个URL 中,可正确匹配到公司地址
Xpath入门1-图17:第二个URL中,不可正确匹配到公司地址
这时就说明是xpath出了问题。
我们可以在第二个URL中,通过火狐生成一条可正确匹配到公司地址的xpath,如下图所示:
Xpath入门1-图18:火狐生成的xpath
第二个URL中通过火狐生成的xpath,如果没有问题,可以直接复制到八爪鱼里。
但是这条xpath,仅适用于第二个URL,换到第一个URL中依旧存在问题。
这时候,需要手动到火狐里进行调试了。
我们需要一条,在两个URL中,都能正确匹配到公司地址的xpath。
查看下面的源码,可以看到都有“公司地址:”这几个字
Xpath入门1-图19:源码中都有“公司地址:”
通过“公司地址:”这个共同点,可以手动写一条xpath。
在xpath中匹配文本的函数是text()
//代表所有html里面所有的节点作为对象选择//li代表匹配所有li标签,注意后面的[]里面的条件是对所选择对象特征的进一步限制,所以整个//li[text()='公司地址:']的意思就是选择包含文本为公司地址:的所有节点,由于这个网页就只有一个,所以就匹配了这一个节点。
Xpath入门1-图20:在第二条URL中,可正确匹配
Xpath入门1-图21:在第一条URL中,也可正确匹配
然后把这条xpath复制到八爪鱼中去即可。
可以看到数据就正常的跑出来了,而且是需要的公司地址数据。
Xpath入门1-图22:将手写的xpath,复制到八爪鱼中Xpath入门1-图23:提取数据步骤,正常
Xpath入门1-图24:数据采集,正常
相关采集教程:
天猫商品信息采集
黄页88数据采集
搜狗微信文章采集
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。