c++单向链表的排序
c语言中linklist类型

c语言中linklist类型LinkList类型是C语言中常用的数据结构之一,它是一种线性链表的实现方式。
在计算机科学中,链表是一种常见的数据结构,用于存储和操作一系列元素。
链表由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表中的第一个节点称为头节点,最后一个节点称为尾节点。
链表可以根据需要动态地增加或删除节点,相比于数组,链表的大小可以根据实际需求进行调整。
链表的实现可以使用不同的方式,其中最常见的是单向链表。
在单向链表中,每个节点只有一个指针,指向下一个节点。
这种实现方式简单且高效,适用于大多数场景。
除了单向链表,还有双向链表和循环链表等其他实现方式。
链表的优点是可以快速在任意位置插入或删除节点,而无需移动其他节点。
这是由于链表中的节点通过指针相互连接,而不是像数组那样连续存储。
另外,链表的大小可以根据需要进行动态调整,而数组的大小是静态的。
这使得链表在处理动态数据集合时非常有用。
然而,链表也有一些缺点。
首先,访问链表中的任意节点都需要从头节点开始遍历,直到找到目标节点。
这导致了链表的访问时间复杂度为O(n),而数组的访问时间复杂度为O(1)。
其次,链表需要额外的内存空间来存储指针信息,这会占用更多的存储空间。
在C语言中,可以使用结构体来定义链表节点,例如:```typedef struct Node {int data;struct Node *next;} Node;typedef struct LinkedList {Node *head;Node *tail;} LinkedList;```上述代码定义了一个包含数据和指针的节点结构体Node,以及一个包含头节点和尾节点指针的链表结构体LinkedList。
通过这样的定义,可以方便地进行链表的操作,比如插入、删除和遍历等。
链表的插入操作可以分为三步:创建新节点、修改指针、更新链表的头尾指针。
例如,插入一个新节点到链表末尾的代码如下:```void insert(LinkedList *list, int data) {Node *newNode = (Node *)malloc(sizeof(Node));newNode->data = data;newNode->next = NULL;if (list->head == NULL) {list->head = newNode;list->tail = newNode;} else {list->tail->next = newNode;list->tail = newNode;}}```链表的删除操作也类似,可以分为三步:找到目标节点、修改指针、释放内存。
C语言八大排序算法
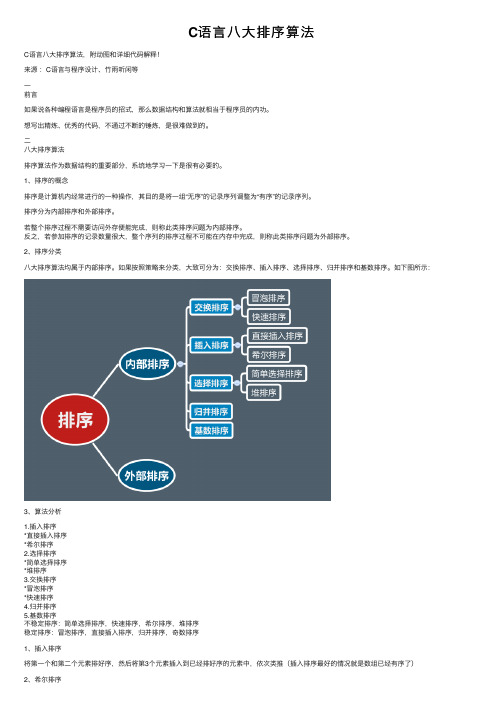
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
c语言链表排序算法

c语言链表排序算法在C语言中,链表的排序可以使用多种算法,如插入排序、归并排序、快速排序等。
以下是一个简单的插入排序算法的示例,用于对链表进行排序:C:#include<stdio.h>#include<stdlib.h>struct Node {int data;struct Node* next;};void insert(struct Node** head, int data) {struct Node* newNode= (struct Node*)malloc(sizeof(struct Node));newNode->data = data;newNode->next = NULL;if (*head == NULL) {*head = newNode;return;}struct Node* current = *head;while (current->next != NULL) {current = current->next;}current->next = newNode;}void sortList(struct Node** head) { struct Node* current = *head;while (current != NULL) {struct Node* next = current->next; while (next != NULL) {if (current->data > next->data) { int temp = current->data;current->data = next->data;next->data = temp;}next = next->next;}current = current->next;}}void printList(struct Node* head) { while (head != NULL) {printf("%d ", head->data);head = head->next;}}int main() {struct Node* head = NULL;insert(&head, 5);insert(&head, 2);insert(&head, 4);insert(&head, 1);insert(&head, 3);printf("Before sorting: ");printList(head);sortList(&head);printf("\nAfter sorting: ");printList(head);return0;}这个程序定义了一个链表节点结构体Node,其中包含一个整型数据data 和一个指向下一个节点的指针next。
链表排序(冒泡、选择、插入、快排、归并、希尔、堆排序)

链表排序(冒泡、选择、插⼊、快排、归并、希尔、堆排序)这篇⽂章分析⼀下链表的各种排序⽅法。
以下排序算法的正确性都可以在LeetCode的这⼀题检测。
本⽂⽤到的链表结构如下(排序算法都是传⼊链表头指针作为参数,返回排序后的头指针)struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}};插⼊排序(算法中是直接交换节点,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *insertionSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.if(head == NULL || head->next == NULL)return head;ListNode *p = head->next, *pstart = new ListNode(0), *pend = head;pstart->next = head; //为了操作⽅便,添加⼀个头结点while(p != NULL){ListNode *tmp = pstart->next, *pre = pstart;while(tmp != p && p->val >= tmp->val) //找到插⼊位置{tmp = tmp->next; pre = pre->next;}if(tmp == p)pend = p;else{pend->next = p->next;p->next = tmp;pre->next = p;}p = pend->next;}head = pstart->next;delete pstart;return head;}};选择排序(算法中只是交换节点的val值,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *selectSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//选择排序if(head == NULL || head->next == NULL)return head;ListNode *pstart = new ListNode(0);pstart->next = head; //为了操作⽅便,添加⼀个头结点ListNode*sortedTail = pstart;//指向已排好序的部分的尾部while(sortedTail->next != NULL){ListNode*minNode = sortedTail->next, *p = sortedTail->next->next;//寻找未排序部分的最⼩节点while(p != NULL){if(p->val < minNode->val)minNode = p;p = p->next;}swap(minNode->val, sortedTail->next->val);sortedTail = sortedTail->next;}head = pstart->next;delete pstart;return head;}};快速排序1(算法只交换节点的val值,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition我们参考(选取第⼀个元素作为枢纽元的版本,因为链表选择最后⼀元素需要遍历⼀遍),具体可以参考这⾥我们还需要注意的⼀点是数组的partition两个参数分别代表数组的起始位置,两边都是闭区间,这样在排序的主函数中:void quicksort(vector<int>&arr, int low, int high){if(low < high){int middle = mypartition(arr, low, high);quicksort(arr, low, middle-1);quicksort(arr, middle+1, high);}}对左边⼦数组排序时,⼦数组右边界是middle-1,如果链表也按这种两边都是闭区间的话,找到分割后枢纽元middle,找到middle-1还得再次遍历数组,因此链表的partition采⽤前闭后开的区间(这样排序主函数也需要前闭后开区间),这样就可以避免上述问题class Solution {public:ListNode *quickSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//链表快速排序if(head == NULL || head->next == NULL)return head;qsortList(head, NULL);return head;}void qsortList(ListNode*head, ListNode*tail){//链表范围是[low, high)if(head != tail && head->next != tail){ListNode* mid = partitionList(head, tail);qsortList(head, mid);qsortList(mid->next, tail);}}ListNode* partitionList(ListNode*low, ListNode*high){//链表范围是[low, high)int key = low->val;ListNode* loc = low;for(ListNode*i = low->next; i != high; i = i->next)if(i->val < key){loc = loc->next;swap(i->val, loc->val);}swap(loc->val, low->val);return loc;}};快速排序2(算法交换链表节点,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition,我们选取第⼀个节点作为枢纽元,然后把⼩于枢纽的节点放到⼀个链中,把不⼩于枢纽的及节点放到另⼀个链中,最后把两条链以及枢纽连接成⼀条链。
数据结构C语言版 线性表的单链表存储结构表示和实现

#include 〈stdio.h>#include <malloc。
h>#include 〈stdlib.h>/*数据结构C语言版线性表的单链表存储结构表示和实现P28—31编译环境:Dev-C++ 4。
9。
9。
2日期:2011年2月10日*/typedef int ElemType;// 线性表的单链表存储结构typedef struct LNode{ElemType data; //数据域struct LNode *next;//指针域}LNode, *LinkList;// typedef struct LNode *LinkList;// 另一种定义LinkList的方法// 构造一个空的线性表Lint InitList(LinkList *L){/*产生头结点L,并使L指向此头结点,头节点的数据域为空,不放数据的。
void *malloc(size_t)这里对返回值进行强制类型转换了,返回值是指向空类型的指针类型.*/(*L)= (LinkList)malloc(sizeof(struct LNode) );if( !(*L))exit(0);// 存储分配失败(*L)-〉next = NULL;// 指针域为空return 1;}// 销毁线性表L,将包括头结点在内的所有元素释放其存储空间。
int DestroyList(LinkList *L){LinkList q;// 由于单链表的每一个元素是单独分配的,所以要一个一个的进行释放while(*L ){q = (*L)—〉next;free(*L );//释放*L = q;}return 1;}/*将L重置为空表,即将链表中除头结点外的所有元素释放其存储空间,但是将头结点指针域置空,这和销毁有区别哦。
不改变L,所以不需要用指针。
*/int ClearList( LinkList L ){LinkList p,q;p = L—〉next;// p指向第一个结点while( p ) // 没到表尾则继续循环{q = p—>next;free( p );//释放空间p = q;}L—>next = NULL; // 头结点指针域为空,链表成了一个空表return 1;}// 若L为空表(根据头结点L—〉next来判断,为空则是空表),则返回1,// 否则返回0.int ListEmpty(LinkList L){if(L—>next ) // 非空return 0;elsereturn 1;}// 返回L中数据元素个数。
(完整)《C语言程序设计课程设计》题目——软件工程2班

1 一元稀疏多项式的运算问题描述:设有两个带头指针的单链表表示两个一元稀疏多项式A、B,实现两个一元稀疏多项式的处理.实现要求:⑴输入并建立多项式;⑵输出多项式,输出形式为整数序列:n,c1,e1,c2,e2……cn,en,其中n是多项式的项数,ci,ei分别为第i项的系数和指数。
序列按指数降序排列;⑶多项式A和B相加,建立多项式A+B,输出相加的多项式;⑷多项式A和B相减,建立多项式A-B,输出相减的多项式;⑸多项式A和B相乘,建立多项式A×B,输出相乘的多项式;⑹设计一个菜单,至少具有上述操作要求的基本功能。
测试数据:(1) (2x+5x8-3.1x11)+(7—5x8+11x9)(2) (6x-3—x+4。
4x2-1。
2x9)-(-6x-3+5.4x2+7。
8x15)(3)(x+x2+x3)+0(4)(x+x3)—(-x—x-3)2 成绩排序假设某年级有4个班,每班有45名同学。
本学期有5门课程考试,每门课程成绩是百分制。
假定每个同学的成绩记录包含:学号、姓名各门课程的成绩共7项,其中学号是一个10位的字符串,每个学生都有唯一的学号,并且这4个班的成绩分别放在4个数组中,完成以下操作要求:⑴编写一个成绩生成函数,使用随机数方法,利用随机函数生成学生的各门课程的成绩(每门课程的成绩都是0∽100之间的整数),通过调用该函数生成全部学生的成绩;⑵编写一个平均成绩计算函数,计算每个同学的平均成绩并保存在成绩数组中;⑶用冒泡排序法对4个班的成绩按每个同学的平均成绩的以非递增方式进行班内排序;⑷用选择排序法对4个班的成绩按每个同学的平均成绩的以非递增方式进行班内排序;⑸对已按平均成绩排好序的4个班的同学的构造一个所有按平均成绩的以非递增方式排列的新的单链表;⑹设计一个菜单,至少具有上述操作要求的基本功能。
(本题⑸由2人完成)3 迷宫问题问题描述:以一个m×n的长方阵表示迷宫,0和1分别表示迷宫中的通路和障碍。
单链表的 基本操作

单向链表单向链表的基本操作,创建一个由6个节点组成的单向链表,显示链表中每个节点的数据,并且做增加、删除、查找节点以及计算单链表的长度等处理。
➢需求分析:1.功能(1)用尾插法创建一带头结点的由6个节点组成的单向链表:从键盘读入一组整数,作为单链表中的元素,输入完第6个结点后结束;将创建好的单链表元素依次输出到屏幕上。
(2)显示链表中每个节点的数据(3)从键盘输入一个数,查找在以上创建的单链表中是否存在该数;如果存在,显示它的位置,即第几个元素;如果不存在,给出相应提示如“No found node!”。
(4)在上述的单链表中的指定位置插入指定数据,并输出单链表中所有数据。
(5)删除上述单链表中指定位置的结点,并输出单链表中所有数据。
(6)求单链表的长度并输出.2.输入要求先输入单链表中结点个数n,再输入单链表中所有数据,在单链表中需查找的数据,需插入的数据元素的位置、值,要删除的数据元素的位置。
3。
测试数据单链表中所有数据:12,23,56,21,8,10在单链表中需查找的数据:56;24插入的数据元素的位置、值:1,28;7,28;0,28要删除的数据元素的位置:6➢概要设计:1.算法思想:由于在操作过程中要进行插入、删除等操作,为运算方便,选用带头结点的单链表作数据元素的存储结构.对每个数据元素,由一个数据域和一个指针域组成,数据域放输入的数据值,指针域指向下一个结点。
2.数据结构:单链表结点类型:typedef struct Liistnode {int data;struct Listnode *next;}NODE;3.模块划分:a)用尾插法建立带头结点的单链表*CreateList函数;b)显示链表中每个结点的数据PrintList函数;c)从键盘输入一个数,查找单链表中是否存在该数FoundList函数;d)在单链表中指定位置插入指定数据并输出单链表中所有数据InsertList函数;e)删除单链表中指定位置的结点并输出单链表中所有数据DeleteList函数;f)计算单链表的长度并在屏幕上输出LengthList函数;g)主函数main(),功能是给出测试数据值,建立测试数据值的带头结点的单链表,调用PrintList函数、FoundList函数、InsertList函数、DeleteList函数、LengthList函数实现问题要求。
c语言数据结构及算法

C语言是一种广泛应用于编程和软件开发的编程语言,它提供了一系列的数据结构和算法库,使得开发者能够在C语言中使用这些数据结构和算法来解决各种问题。
以下是C语言中常用的数据结构和算法:数据结构:1. 数组(Array):一组相同类型的元素按顺序排列而成的数据结构。
2. 链表(Linked List):元素通过指针连接而成的数据结构,可分为单向链表、双向链表和循环链表等。
3. 栈(Stack):具有后进先出(LIFO)特性的数据结构,可用于实现函数调用、表达式求值等。
4. 队列(Queue):具有先进先出(FIFO)特性的数据结构,可用于实现任务调度、缓冲区管理等。
5. 树(Tree):一种非线性的数据结构,包括二叉树、二叉搜索树、堆、A VL树等。
6. 图(Graph):由节点和边组成的数据结构,可用于表示网络、关系图等。
7. 哈希表(Hash Table):基于哈希函数实现的数据结构,可用于高效地查找、插入和删除元素。
算法:1. 排序算法:如冒泡排序、插入排序、选择排序、快速排序、归并排序等。
2. 查找算法:如线性查找、二分查找、哈希查找等。
3. 图算法:如深度优先搜索(DFS)、广度优先搜索(BFS)、最短路径算法(Dijkstra、Floyd-Warshall)、最小生成树算法(Prim、Kruskal)等。
4. 字符串匹配算法:如暴力匹配、KMP算法、Boyer-Moore 算法等。
5. 动态规划算法:如背包问题、最长公共子序列、最短编辑距离等。
6. 贪心算法:如最小生成树问题、背包问题等。
7. 回溯算法:如八皇后问题、0-1背包问题等。
这只是C语言中常用的一部分数据结构和算法,实际上还有更多的数据结构和算法可以在C语言中实现。
开发者可以根据具体需求选择适合的数据结构和算法来解决问题。
同时,C语言也支持自定义数据结构和算法的实现,开发者可以根据需要进行扩展和优化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
河北联合大学 2011-2012 第 2 学期《 软 件 设 计 基 础 -C++》课程设计报告设计名称:设计一个处理单向链表的程序:链表的排序 姓 名:王学增 学 号:201005100206专业班级:土木工程 1 班 学 院:建筑工程学院设计时间:2012-5-31 设计地点:机房指导教师评语: 教师评定: 自评成绩;75指导教师签字:年 年 月 月 日 日《软件设计基础-C++》课程设计报告第2页,共16 页目录1.课程设计目的···································· ···································· ···································· 2.课程设计任务与要求 ································ ································ ······························· 3.课程设计说明书··································· ··································· ·································· 4.课程设计成果···································· ···································· ···································· 5.程序调试过程···································· ···································· ···································· 6.设计问题的不足和改进方案 ···························· ···························· ··························· 7.课程设计心得···································· ···································· ···································· 8.参考文献······································· ······································· ······································《软件设计基础-C++》课程设计报告第3页,共16 页1.课程设计目的《软件设计基础-C++》课程设计是这门课程的实践性教学环节之一,本次设计结合实际应用的要求, 使课程设计既覆盖 C++的知识点,又接近工程实际需要。