基于RHEL6的RHCS红帽集群套件应用
RHCS双机软件安装及配置

使用红帽群集软件实现应用服务双机安装配置操作系统版本:redhat linux AS 4U5群集软件版本:redhat cluster suite 4.5一、群集实施前期系统配置1.编辑/etc/hosts文件,加入IP地址和主机对应表,修改后的hosts示范如下: [root@app1 /]# cat /etc/hosts# Do not remove the following line, or various programs# that require network functionality will fail.127.0.0.1 localhost.localdomain localhost125.88.105.82 app1125.88.105.83 app2192.168.10.7 app1-priv192.168.10.8 app2-priv2.HP ILO卡配置(每个节点都执行)注:此次只是为ilo卡配指定的ip及新增一个管理用户开机自检时,按F8键进入iLO的设置界面:1.进入iLO的设置:这项是将所有的设置恢复为出厂值。
2.配置网络:分别设置IP 地址和DNS。
IP应在同一个网段中,注意子网掩码的一致。
(只有在DHCP被设为Disable时,才能设置IP address/Subnet Mask/Gateway IP address)DNS的名字在服务器前面带的卡片上,还包括管理员的账号和密码。
IP必须是静态的,所以DHCP需设置为OFF。
3.在这里可以添加、删除、更改远程访问User的密码,权限等。
Add userRemoveEdit4.Settings 的选项设置Keyboard的属性等,一般都为默认值。
5.About中为iLO的firmware version等一些信息。
3.建文件系统挂载点/data(每节点运行)[root@app1 root]# mkdir /data二、安装群集软件(每个节点运行)在AS4上配置红帽群集管理器需要安装cluster suite 4。
Redhat6.0+oracle 11G R2+RoseHA8.8成功案例
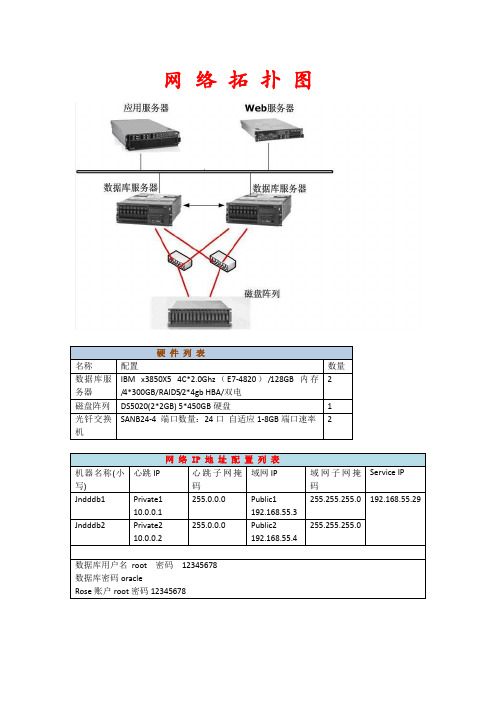
网络拓扑图第一部分系统的安装与存储柜的连接映射1.服务器安装操作系统光驱放入系统盘,选择光驱引导,如下图所示:系统分区要求:tmp 20GBhome 20GBopt 容量大点/ 50GB(可以分大点,其他均省略到)注意:必须选择【现在自定义】基本的组件包都要勾上,以免之后再次手动安装组件包!如下图所示操作系统安装完毕!2. 调试存储柜1).在管理站(笔记本)上安装storageManager连接管理站(笔记本)和DS5020管理口,每个控制器有两个管理端口A控制器:192.168.128.101和192.168.129.101B 控制器:192.168.128.102和192.168.129.102注意:需要通过交换机(不带DHCP服务)同时连通DS5020两个控制器上的管理端口。
确认连接正确:注意:请测试两个控制器是否都连接正确;2). DS Storage Manager窗口说明A.Enterprise Management 窗口的组成部分B.Subsystem Management 窗口SM各个窗口简单描述如下:●summary:DS5020 系统的总体情况。
●logica:逻辑卷相关的操作。
●physical:物理设备相关的操作。
●mapping:管理主机 - 卷映射之间的关系。
●setup:磁盘系统的一些基本设定。
●support:系统维护,故障排除相关的一些操作。
3).DS Storage Manager操作1.启动DS Storage Manager1)第一次运行,系统会自动弹出添加磁盘子系统的发现界面。
你可以选择自动发现或手动发现。
2)选择自动发现并点击 ok 等待系统发现完成3)发现完成后,将会显示您网络中可以管理的磁盘子系统。
4)双击你需要管理的磁盘子系统,进入 DS SM 管理界面(下面的操作以 DS5020 为例)注意:第一次管理DS5020会提示设置管理密码,请根据提示设置并牢记。
红帽RHCS(Red Hat Cluster Suite)集群维护

红帽RHCS(Red Hat Cluster Suite)集群维护1.启动RHCS集群 (1)2.关闭RHCS集群 (1)3.管理应用服务 (2)3.1.启动某个应用服务 (2)3.2.关闭某个应用服务 (2)3.3.重启某个应用服务 (2)3.4.切换某个服务 (3)4.监控RHCS集群状态 (3)1.启动RHCS集群RHCS集群的核心进程有cman和rgmanager,要启动集群,依次在集群的每个节点执行如下命令即可:service cman startservice rgmanager start需要注意的是,执行这两个命令是有先后顺序的,需要首先启动cman,然后再启动rgmanager(在集群所有节点成功启动cman 服务后,然后继续依次在每个节点启动rgmanager服务)。
如果用了GFS2集群文件系统,那么启动的方式为:service cman startservice qdiskd startservice clvmd startservice gfs2 startservice rgmanager start2.关闭RHCS集群与启动集群服务刚好相反,关闭RHCS集群的命令为:service rgmanager stopservice cman stop首先在集群的每个节点依次关闭rgmanager服务,等待所有节点的rgmanager服务成功关闭后,再依次关闭每个节点的cman服务即可完成整个集群服务的关闭。
有时在关闭cman服务时,可能会提示关闭失败,此时可以检查本机的共享存储GFS2文件系统是否已经卸载,还可以检查其它节点的rgmanager服务是否都已经正常关闭。
3.管理应用服务集群系统启动后,默认是自动启动应用服务的,但是如果某个应用服务没有自动启动,就需要通过手工方式来启动。
管理应用服务的命令是clusvcadm,通过这个命令可以启动、关闭、重启、切换集群中的应用服务。
Red_Hat_Enterprise_Linux-6-Cluster_Suite_Overview-zh-CN

述,包括在群集环境中运行 LVM 的信息。 《全局文件系统 2:配置和管理》 — 提供安装、配置和维护红帽 GFS2(红帽全局文件系统 2)的
信息,它位于弹性存储附加组件中。 《设备映射器多路径》 — 提供关于使用 Red Hat Enterprise Linux 6 设备映射器多路径功能的信息
第一段突出的是要按的特定按键。第二段突出了两个按键组合(每个组合都要同时按)。下。
如果讨论的是源码、等级名称、方法、功能、变量名称以及在段落中提到的返回的数值,那么都会以上 述形式出现,即固定粗体。例如:
与文件相关的等级包括用于文件系统的 filesystem、用于文件的 file 以及用于目录的 dir。每个等级都有其自身相关的权限。
1.文档约定
本手册使用几个约定来突出某些用词和短语以及信息的某些片段。 在 PDF 版本以及纸版中,本手册使用在 Liberation 字体1套件中选出的字体。如果您在您的系统中安装 了 Liberation 字体套件,它还可用于 HTML 版本。如果没有安装,则会显示可替换的类似字体。请注 意:红帽企业 Linux 5 以及其后的版本默认包含 Liberation 字体套件。
1. 高可用性附加组件概述 1 1.1. 集群基础 .................................................................................................................... 1 1.2. 高可用性附加组件简介 ................................................................................................ 1 1.3. 集群基础结构 ............................................................................................................. 2 1.3.1. 集群管理 ......................................................................................................... 2 1.3.2. 锁管理 ............................................................................................................ 3 1.3.3. Fencing ............................................................................................................ 3 1.3.4. 配置管理 ......................................................................................................... 7 1.4. 高可用性服务管理 ...................................................................................................... 8 1.5. 集群管理工具 ........................................................................................................... 10
基于 CentOS 5.2 的RHCS 的高可用性解决方案

基于CentOS 5.2 的RHCS 的高可用性解决方案作者:liheng本文所参考的资源:史应生《红帽集群高可用性配置管理和维护之最强版》、《基于红帽RHEL5U2 GFS2+ISCSI+XEN+Cluster 的高可性解决方案-最新技术版》鸟哥Linux 私房菜:/ 网友分享区的《 MySQL on RHCS 》RedHat doc: /docs《 Cluster_Suite_Overview5.2 》、《 Cluster_Administration5.2 》感谢以上IT Pro的无私奉献,没有你们,我想我不可能体验到RHCS !简介:不间断的无故障的业务运行环境是每一个企业IT系统部署要求的重中之重。
任何一个发生在关键服务上的停顿故障都会导致直接和间接的企业经济损失以及客户的满意度下降。
虽然Linux操作系统已经提供高度的容错能力,但是关键业务系统仍旧需要成熟的技术来实现服务的高可用性,尽可能减少和缩短服务停顿的次数和时间。
传统的通过冗余和复制硬件设备的解决方式既昂贵且局限性大,用户只能通过这样的方式解决企业中最关键的业务应用对于可用性的要求。
因此很多企业内部的重要应用由于缺乏高性价比的方案而失去保护,面临着灾难后的长时间恢复和数据的丢失。
同样的情况下,当企业的IT部门需要对关键应用所处软硬件环境进行调整,或仅仅是作系统维护的时候,这种计划内的停机也会造成应用重新上线前的长时间服务停止以及潜在的数据丢失。
计算机集群作为一种技术近两年也越来越受到大家的关注,这也是因为海量信息的不断厂商要求计算机提升自己的性能,在不能有效的更换硬件设备的情况下,就要通过网络手段,将多台服务器通过高速的局域网连接,实现统一管理,分布式运算,提高整体系统的性能。
商业的 Unix 市场中,高可用性 ( High Availability ) 是销售Unix 服务器解决方案的关键。
事实上每个 Unix 供货商都有他们自己的高可用性软件解决方案,例如IBM 的高可用性丛集软件解决方案,就是 AIX 上的HACMP ( High Availability Cluster Multi-Processing )。
RHEL_6.1做集群安装与配置(华为服务器)

Redhat6.1使用Luci搭建双机热备(虚拟机环境)一、环境准备T01 虚拟机准备2台Linux系统的虚拟机。
安装时要选自定义安装,最好安装桌面图形化支持的相关插件。
1台Openfile虚拟机,用来提供虚拟你双机热备的存储虚拟环境。
T02 主机端连接存储T02-0101 1.系统挂载tools(如果是VMware等虚拟化环境时,需要执行此步骤。
)mkdir /mnt 创建挂载点mount /dev/sr0 /mnt 拷贝文件到挂载点cd /mntlstar xvzf VM**.tar.gz 解压软件包lscd ./vmware-tools-dis**bls./vm**install.plT02-0102 (iscsi环境)建立连接确保主机与存储的网络已经连通。
(1) 运行命令rpm-qa|grep iscsi,检查Red Hat应用服务器是否已经安装了iSCSI启动器驱动程序。
如果应用服务器上已经安装iSCSI启动器驱动程序,则界面显示类似如下:iscsi-initiator-utils-6.2.0.868-0.7.el5如果没有安装iscsi启动器,则先安装。
根据具体操作系统版本选择相应的安装包。
例如:rpm -ivh iscsi-initiator-utils-6.2.0.742-0.5.el5.i386.rpm2. 配置目标器的IP地址。
[root@RHCS01 ~]# iscsiadm-m discovery-t st–p 10.20.30.63. 登录目标器。
[root@RHCS01 ~]# iscsiadm -m node -p 10.20.30.6 –l4. 设置目标器为自动启动模式。
设置目标器为自动启动模式后,每次应用服务器重新启动后会自动登录与其连接的目标器。
a.运行命令vi/etc/iscsi/iscsid.conf,打开“iscsid.conf”文件。
b.按“i”键,进入编辑模式,编辑“iscsid.conf”文件。
RHCS6配置操作文档(双机配置、双网卡绑定等)

9. 创建集群、添加节点
从服务器本机登录管理页面,用户名使用 root 用户
设置 test1 的 IP 地址: [root@test1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO=none NM_CONTROLLED="yes" ONBOOT=yes TYPE="Ethernet" UUID="ea73b5b6-e249-4cb8-b2b1-dc0d25cf432f" IPADDR=192.168.40.72 PREFIX=24 GATEWAY=192.168.40.1 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no
创建 cluster 之前,不要启动 cman 服务,待 cluster 创建后,已经生成了 cluster.conf 文件后再启动 cman 服务。如果此时启动 cman 会报错,提示找不到 cluster.conf, 属于正常现象,创建 cluster 后就可以成功启动 cman 了。
# service modclusterd start # service luci start # service ricci start # service rgmanager start # --service cman start
红帽集群套件RHCS四部曲(测试篇)

红帽集群套件RHCS四部曲(测试篇)集群配置完成后,如何知道集群已经配置成功了呢,下面我们就分情况测试RHCS提供的高可用集群和存储集群功能。
一、高可用集群测试在前面的文章中,我们配置了四个节点的集群系统,每个节点的主机名分别是web1、web2、Mysql1、Mysql2,四个节点之间的关系是:web1和web2组成web集群,运行webserver服务,其中web1是主节点,正常状态下服务运行在此节点,web2是备用节点;Mysql1和Mysql2组成Mysql集群,运行mysqlserver服务,其中,Mysql1是主节点,正常状态下服务运行在此节点,Mysql2为备用节点。
下面分四种情况介绍当节点发生宕机时,集群是如何进行切换和工作的。
1 节点web2宕机时宕机分为正常关机和异常宕机两种情况,下面分别说明。
(1)节点web2正常关机在节点web2上执行正常关机命令:[root@web2 ~]#init 0然后在web1节点查看/var/log/messages日志,输出信息如下:Aug 24 00:57:09 web1 clurgmgrd[3321]: <notice> Member 1 shutting downAug 24 00:57:17 web1 qdiskd[2778]: <info> Node 1 shutdownAug 24 00:57:29 web1 openais[2755]: [TOTEM] The token was lost in the OPERATIONAL state. Aug 24 00:57:29 web1 openais[2755]: [TOTEM] Receive multicast socket recv buffer size (320000 bytes).Aug 24 00:57:29 web1 openais[2755]: [TOTEM] Transmit multicast socket send buffer size (219136 bytes).Aug 24 00:57:29 web1 openais[2755]: [TOTEM] entering GATHER state from 2.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] entering GATHER state from 0.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] Creating commit token because I am the rep.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] Saving state aru 73 high seq received 73Aug 24 00:57:49 web1 openais[2755]: [TOTEM] Storing new sequence id for ring bc8Aug 24 00:57:49 web1 openais[2755]: [TOTEM] entering COMMIT state.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] entering RECOVERY state.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] position [0] member 192.168.12.230:Aug 24 00:57:49 web1 openais[2755]: [TOTEM] previous ring seq 3012 rep 192.168.12.230Aug 24 00:57:49 web1 openais[2755]: [TOTEM] aru 73 high delivered 73 received flag 1Aug 24 00:57:49 web1 openais[2755]: [TOTEM] position [1] member 192.168.12.231:Aug 24 00:57:49 web1 openais[2755]: [TOTEM] previous ring seq 3012 rep 192.168.12.230Aug 24 00:57:49 web1 openais[2755]: [TOTEM] aru 73 high delivered 73 received flag 1Aug 24 00:57:49 web1 openais[2755]: [TOTEM] position [2] member 192.168.12.232:Aug 24 00:57:49 web1 openais[2755]: [TOTEM] previous ring seq 3012 rep 192.168.12.230Aug 24 00:57:49 web1 openais[2755]: [TOTEM] aru 73 high delivered 73 received flag 1Aug 24 00:57:49 web1 openais[2755]: [TOTEM] Did not need to originate any messages in recovery. Aug 24 00:57:49 web1 openais[2755]: [TOTEM] Sending initial ORF tokenAug 24 00:57:49 web1 openais[2755]: [CLM ] CLM CONFIGURATION CHANGEAug 24 00:57:49 web1 openais[2755]: [CLM ] New Configuration:Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.230)Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.231)Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.232)Aug 24 00:57:49 web1 openais[2755]: [CLM ] Members Left:Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.240)Aug 24 00:57:49 web1 kernel: dlm: closing connection to node 1Aug 24 00:57:49 web1 openais[2755]: [CLM ] Members Joined:Aug 24 00:57:49 web1 openais[2755]: [CLM ] CLM CONFIGURATION CHANGEAug 24 00:57:49 web1 openais[2755]: [CLM ] New Configuration:Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.230)Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.231)Aug 24 00:57:49 web1 openais[2755]: [CLM ] r(0) ip(192.168.12.232)Aug 24 00:57:49 web1 openais[2755]: [CLM ] Members Left:Aug 24 00:57:49 web1 openais[2755]: [CLM ] Members Joined:Aug 24 00:57:49 web1 openais[2755]: [SYNC ] This node is within the primary component and will provide service.Aug 24 00:57:49 web1 openais[2755]: [TOTEM] entering OPERATIONAL state.Aug 24 00:57:49 web1 openais[2755]: [CLM ] got nodejoin message 192.168.12.230Aug 24 00:57:49 web1 openais[2755]: [CLM ] got nodejoin message 192.168.12.231Aug 24 00:57:49 web1 openais[2755]: [CLM ] got nodejoin message 192.168.12.232Aug 24 00:57:49 web1 openais[2755]: [CPG ] got joinlist message from node 3Aug 24 00:57:49 web1 openais[2755]: [CPG ] got joinlist message from node 4Aug 24 00:57:49 web1 openais[2755]: [CPG ] got joinlist message from node 2从输出日志可以看出,当web2节点正常关机后,qdiskd进程立刻检测到web2节点已经关闭,然后dlm锁进程正常关闭了从web2的连接,由于是正常关闭节点web2,所以RHCS认为整个集群系统没有发生异常,仅仅把节点web2从集群中隔离而已。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
毛毛雨:AM 3885999RHCS 基于 RHEL6.0 x86_64(实验教程) 实验说明:所用的RHEL 版本均为 6.0 x86_64,宿主机支持虚拟化,内存不小于4G。
实验拓扑如下:在本实验中,为了节省资源将 ISCSI-Target 也放到 manager 一个机器上了。
vmware 创建一个虚拟机,内存3G,按下图设置使得虚拟机也支持虚拟化,vmware workstation 版本不低于7:蓝狐Linux系统培训中心毛毛雨:AM 3885999毛毛雨:AM 3885999蓝狐Linux 系统培训中心毛毛雨:AM 3885999在这个虚拟机中装好 rhel6,ip192.168.0.200,作为 RHCS 的管理端,继续在其上安装 kvm,kvm 的安装请查看我之前写的关于 kvm 文档,kvm 安装好后,创建两 个 vm(virtual machine) ,桥接到 192.168.0.200 的物理网卡上,vm 上安装好 rhel6,ip 分别为192.168.0.201和 192.168.0.202,作为 RHCS 的节点,这样的拓扑设计 的原因是我们可以在 RHCS 中使用 fence-virsh 来fence 掉 kvm 管理的 RHCS 故障节点。
使用hostname 指令设置主机名,想重启之后生效别忘了/etc/sysconfig/network,因为本环境中没有使用DNS,所以在manager 上设置/etc/hosts 添加如下三行, 再 scp 到 web1 和web2。
[root@manager ~]# vim /etc/hosts 127.0.0.1 localhost.localdomain localhost ::1localhost6.localdomain6 localhost6192.168.0.200 manager 192.168.0.201 web1 192.168.0.202web2manager、web1、web2 均关闭selinux、iptables。
毛毛雨:AM 3885999在 manager上建 1个 target,2 个lun,用作导出 iscsi存储给节点使用。
主要步骤及指令如下:fdisk 分出来两个分区sda5、6,大小为1G、10M,fdisk 之后使用 partx -a /dev/sda 重读分区,可以不用重启系统。
[root@manager ~]# yum install scsi-target-utils -y 安装iscsi-target 端[root@manager ~]# chkconfig tgtd on ; /etc/init.d/tgtd start 随机启动;启动服务[root@manager ~]# tgtadm -L iscsi -m target -o new -t 1 -T .sswans:disk1 创建target[root@manager ~]# tgtadm -L iscsi -m logicalunit -o new -t 1 -l 1 -b /dev/sda5 创建lun1,对应sda5 分区[root@manager ~]# tgtadm -L iscsi -m logicalunit -o new -t 1 -l 2 -b /dev/sda6 创建lun2,对应sda6 分区[root@manager ~]# tgtadm -L iscsi -m target -o bind -t 1 -I ALL 设置ACL 访问控制,ALL 为任意访问[root@manager ~]# tgt-admin --dump > /etc/tgt/targets.conf dump 保存配置,以后每次重启都会生效 安装luci工具,RHCS 管理端,请配置好yum仓库,RHCS 相关的包在 iso 镜像中的 HighAvailability 和ResilientStroage中[root@manager ~]# yum install luci -y[root@manager ~]# chkconfig luci on ; /etc/init.d/luci startPoint your web browser to https://:8084 to access luci 等节点安装好 ricci 后,可以使用这个 url 对节点进行管理和配置 节点web1、web2 上都执行如下动作,以web1为例:[root@web1 ~]# yum install rgmanager -y 会自动安装 ricci、cman 等包[root@web1 ~]# chkconfig ricci on ; /etc/init.d/ricci start[root@web1 ~]# chkconfig NetworkManager off ; /etc/init.d/NetworkManager stop[root@web1 ~]# chkconfig cman on ; chkconfig rgmanager on ; chkconfig modclusterd on[root@web1 ~]# /etc/init.d/cman start ; /etc/init.d/rgmanager start;/etc/init.d/modclusterd start使用浏览器打开luci的 url,新建一个集群,名为 sSWans,添加两个节点,一个名为web1,另一个名为 web2,因为之前在两个节点上都安装了 ricci、cman等包,蓝狐Linux系统培训中心毛毛雨:AM 3885999毛毛雨:AM 3885999所以单选 use locally installed packages,enable shared storage support 选项其实就是指的 gfs,我们在后面手动装包来实施,这里不勾选。
检查节点的服务状态,确定 cman、rgmanager、ricci、modcluster 服务处于 running 状态。
如有问题,请注意查看节点的/var/log/message 日志进行排错。
点击菜单中的Failover Domains,添加一个热备切换域,名为 web_FD,勾选 no Failback,勾选web1,web2 两个节点。
点击菜单中的 Resources,添加一个 ip address 资源,ip为 192.168.0.252,这个 ip就是提供服务的虚拟 ip,再添加一个 script,名为 http,脚本路径/ etc/init.d/httpd。
点击菜单中的Services,添加一个服务,名为apache,选择刚创建的热备切换域web_FD,添加资源,把刚创建的 ip 资源和脚本资源添加进来,如果服务需要使用的 资源具有先后关系,那么需要将前提资源以子资源(add a child resource)的形式添加。
在两个节点上针对httpd写一个index.html的页面,web1上 [root@web1 ~]# echo web1 > /var/www/html/index.html ,web2的index.html内容为web2, 这样待会服务启动后,我们去访问这个 apache 服务,可以通过访问到的内容来检测集群提供的服务是由哪个节点完成的。
在两个节点上都监控日志tail -f /var/log/message,启动这个apache服务,查看服务启动时节点的信息,有助于更好的理解 rhcs和增加排错经验。
如无意外,此时 应该可以看到apache 服务会在其中一个节点上启动,我的启动在 web1 上,在 Services 菜单可以看到,在任意节点上用指令clustat 查看更快更方便。
做到这里,我们完成了一个rhcs 的最小部署,也是一个特殊情况,也就是two_node 两节点模式,此时的集群可以提供设定的web 服务,在节点web1使用init指令关机 或重启,apache服务都能正常迁移到节点web2,但是,如果提供服务的web1节点网卡故障,我们可以使用指令模拟网卡故障 [root@web1 ~]# ifdown eth0 ,那么蓝狐Linux系统培训中心毛毛雨:AM 3885999毛毛雨:AM 3885999集群无法将 web服务迁移到 web2 节点上,从日志可以看到 web2 要fence掉 web1,但是没有fence method,此时,我们在正常节点web2 上使用指令[root@web2 ~]# fence_ack_manual web1About to override fencing for web1.Improper use of this command can cause severe file system damage.Continue [NO/absolutely]? absolutelyDone意思是告诉正常节点 web2,已经成功fence掉故障节点 web1,web2 可以抢夺原本运行在web1 上的apache 服务了,注意看日志,这原本就是fence设计的原理。
如果你没有使用 fence_ack_manual 而将 web1 的网卡重新开启或者重启 web1,那么 web2 的 cman服务会被停止掉,留意 web2 的日志,这种情况下,web2 的 cman 服务重启不了啦,你只能选择重启系统。
因此,我们的集群是需要fence 设备的,下面开始添加 fence 设备,在节点 web1 和 web2 上做如下动作:[root@web1 ~]# mv /usr/sbin/fence_apc{,.bak}[root@web1 ~]# ln -s /usr/sbin/fence_virsh /usr/sbin/fence_apc因为在 luci 的Fence Devices 菜单中,添加fence 设备,下拉菜单中并没有fence_virsh 项,所以上面的动作就是用fence_virsh 替换 fence_apc。
“偷龙转凤”之后,我们选择下拉菜单中的 fence_apc,其实这时候调用的是 fence_virsh,name填 virsh_fence,ip填 192.168.0.200,login填 root,password 填上对应的密码,这样子,我们就成功添加了一个可以fence kvm 节点的fence设备,接下来,将这个fence设备应用到节点上,web1为例,luci中点击 web1节点, 添加fence_method,名为web_fence,再添加fence instance,选择刚创建的virsh_fence,port 填web1,此处的web1不是web1的hostname,而是kvm 上的vm名;节点web2 上 port 换成 web2,其他跟 web1 设置一样。