第一课数据结构 第7章 图2图的遍历
数据结构实验报告图的遍历讲解

数据结构实验报告图的遍历讲解一、引言在数据结构实验中,图的遍历是一个重要的主题。
图是由顶点集合和边集合组成的一种数据结构,常用于描述网络、社交关系等复杂关系。
图的遍历是指按照一定的规则,挨次访问图中的所有顶点,以及与之相关联的边的过程。
本文将详细讲解图的遍历算法及其应用。
二、图的遍历算法1. 深度优先搜索(DFS)深度优先搜索是一种常用的图遍历算法,其基本思想是从一个顶点出发,沿着一条路径向来向下访问,直到无法继续为止,然后回溯到前一个顶点,再选择此外一条路径继续访问。
具体步骤如下:(1)选择一个起始顶点v,将其标记为已访问。
(2)从v出发,选择一个未被访问的邻接顶点w,将w标记为已访问,并将w入栈。
(3)如果不存在未被访问的邻接顶点,则出栈一个顶点,继续访问其它未被访问的邻接顶点。
(4)重复步骤(2)和(3),直到栈为空。
2. 广度优先搜索(BFS)广度优先搜索是另一种常用的图遍历算法,其基本思想是从一个顶点出发,挨次访问其所有邻接顶点,然后再挨次访问邻接顶点的邻接顶点,以此类推,直到访问完所有顶点。
具体步骤如下:(1)选择一个起始顶点v,将其标记为已访问,并将v入队。
(2)从队首取出一个顶点w,访问w的所有未被访问的邻接顶点,并将这些顶点标记为已访问,并将它们入队。
(3)重复步骤(2),直到队列为空。
三、图的遍历应用图的遍历算法在实际应用中有广泛的应用,下面介绍两个典型的应用场景。
1. 连通分量连通分量是指图中的一个子图,其中的任意两个顶点都是连通的,即存在一条路径可以从一个顶点到达另一个顶点。
图的遍历算法可以用来求解连通分量的个数及其具体的顶点集合。
具体步骤如下:(1)对图中的每一个顶点进行遍历,如果该顶点未被访问,则从该顶点开始进行深度优先搜索或者广度优先搜索,将访问到的顶点标记为已访问。
(2)重复步骤(1),直到所有顶点都被访问。
2. 最短路径最短路径是指图中两个顶点之间的最短路径,可以用图的遍历算法来求解。
《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)

第1章4.答案:(1)顺序存储结构顺序存储结构是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言的数组类型来描述。
(2)链式存储结构顺序存储结构要求所有的元素依次存放在一片连续的存储空间中,而链式存储结构,无需占用一整块存储空间。
但为了表示结点之间的关系,需要给每个结点附加指针字段,用于存放后继元素的存储地址。
所以链式存储结构通常借助于程序设计语言的指针类型来描述。
5. 选择题(1)~(6):CCBDDA6.(1)O(1) (2)O(m*n) (3)O(n2)(4)O(log3n) (5)O(n2) (6)O(n)第2章1.选择题(1)~(5):BABAD (6)~(10):BCABD (11)~(15):CDDAC 2.算法设计题(1)将两个递增的有序链表合并为一个递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。
表中不允许有重复的数据。
[题目分析]合并后的新表使用头指针Lc指向,pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,依次摘取其中较小者重新链接在Lc表的最后。
如果两个表中的元素相等,只摘取La表中的元素,删除Lb表中的元素,这样确保合并后表中无重复的元素。
当一个表到达表尾结点,为空时,将非空表的剩余元素直接链接在Lc表的最后。
void MergeList(LinkList &La,LinkList &Lb,LinkList &Lc){//合并链表La和Lb,合并后的新表使用头指针Lc指向pa=La->next; pb=Lb->next;//pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点Lc=pc=La; //用La的头结点作为Lc的头结点while(pa && pb){ if(pa->data<pb->data){pc->next=pa; pc=pa; pa=pa->next;}//取较小者La中的元素,将pa链接在pc的后面,pa指针后移else if(pa->data>pb->data) {pc->next=pb; pc=pb; pb=pb->next;}//取较小者Lb中的元素,将pb链接在pc的后面,pb指针后移else //相等时取La中的元素,删除Lb中的元素{pc->next=pa;pc=pa;pa=pa->next;q=pb->next; delete pb ; pb =q;}}pc->next=pa?pa:pb; //插入剩余段delete Lb; //释放Lb的头结点}(5)设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B、C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)。
第7章图_数据结构

v4
11
2013-8-7
图的概念(3)
子图——如果图G(V,E)和图G’(V’,E’),满足:V’V,E’E 则称G’为G的子图
2 1 4 3 5 6 3 5 6 1 2
v1 v2 v4 v3 v2
v1 v3 v4
v3
2013-8-7
12
图的概念(4)
路径——是顶点的序列V={Vp,Vi1,……Vin,Vq},满足(Vp,Vi1),
2013-8-7 5
本章目录
7.1 图的定义和术语 7.2 图的存储结构
7.2.1 数组表示法 7.2.2 邻接表 ( *7.2.3 十字链表 7.3.1 深度优先搜索 7.3.2 广度优先搜索 7.4.1 图的连通分量和生成树 7.4.2 最小生成树
*7.2.4 邻接多重表 )
7.3 图的遍历
连通树或无根树
无回路的图称为树或自由树 或无根树
2013-8-7
18
图的概念(8)
有向树:只有一个顶点的入度为0,其余 顶点的入度为1的有向图。
V1 V2
有向树是弱 连通的
V3
V4
2013-8-7
19
自测题
7. 下列关于无向连通图特性的叙述中,正确的是
2013-8-7
29
图的存贮结构:邻接矩阵
若顶点只是编号信息,边上信息只是有无(边),则 数组表示法可以简化为如下的邻接矩阵表示法: typedef int AdjMatrix[MAXNODE][MAXNODE];
*有n个顶点的图G=(V,{R})的邻接矩阵为n阶方阵A,其定 义如下:
1 A[i ][ j ] 0
【北方交通大学 2001 一.24 (2分)】
数据结构课后习题答案第七章
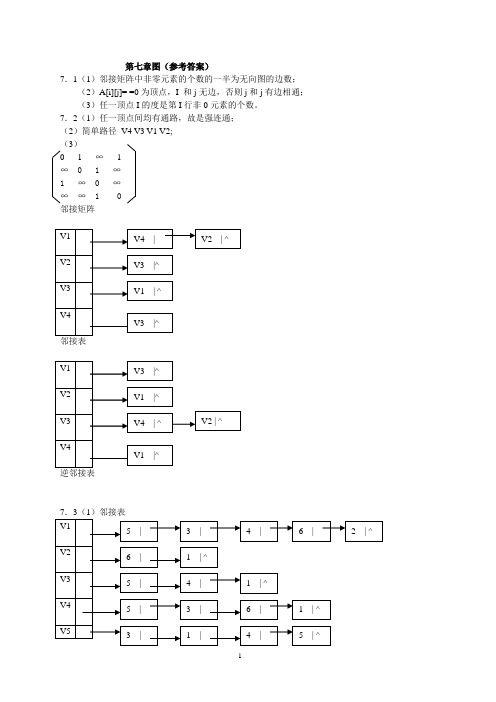
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
数据结构ppt课件

二叉树具有五种基本形态,即空二叉树、只有一个根节点的二叉树、只有左子树或右子 树的二叉树、以及左右子树均有的二叉树。此外,二叉树还具有一些重要性质,如二叉
树的第i层最多有2^(i-1)个节点(i>=1),深度为k的二叉树最多有2^k-1个节点 (k>=1)等。
二叉树的遍历算法
先序遍历
先访问根节点,然后遍 历左子树,最后遍历右
05
图论基础及图的存储结构
图论基础概念介绍
图的基本概念
由顶点(Vertex)和边(Edge)组成的数 据结构,表示对象及其之间的关系。
图的遍历
通过某种方式访问图中所有顶点的过程, 常见的遍历算法有深度优先遍历(DFS)和 广度优先遍历(BFS)。
有向图与无向图
根据边是否有方向,图可分为有向图和无 向图。
时间复杂度
平均时间复杂度和最坏时 间复杂度均为O(n)。
适用场景
适用于数据量较小或数据 无序的情况。
查找算法设计之二分查找法
算法思想
在有序数组中,取中间元素与目标元素比较,若相等则查找成功;若目标元素小于中间元素, 则在左半部分继续查找;若目标元素大于中间元素,则在右半部分继续查找。
时间复杂度
平均时间复杂度和最坏时间复杂度均为O(log n)。
连通图与连通分量
在无向图中,任意两个顶点之间都存在路 径,则称该图是连通图;否则,称该图的 极大连通子图为连通分量。
顶点的度
在无向图中,顶点的度是与该顶点相关联 的边的数目;在有向图中,顶点的度分为 入度和出度。
图的存储结构之邻接矩阵法
邻接矩阵表示法
用一个二维数组表示图中顶点之 间的关系,若顶点i与顶点j之间 存在一条边,则数组元素值为1
王道数据结构 第七章 查找思维导图-高清脑图模板
每次调整的对象都是“最小不平衡子树”
插入操作
在插入操作,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
在A的左孩子的左子树中插入导致不平衡
由于在结点A的左孩子(L)的左子树(L)上插入了新结点,A的平衡因子由1增
至2,导致以A为根的子树失去平衡,需要一次向右的旋转操作。
LL
将A的左孩子B向右上旋转代替A成为根节点 将A结点向右下旋转成为B的右子树的根结点
RR平衡旋转(左单旋转)
而B的原左子树则作为A结点的右子树
在A的左孩子的右子树中插入导致不平衡
由于在结点A的左孩子(L)的右子树(R)上插入了新结点,A的平衡因子由1增
LR
至2,导致以A为根的子树失去平衡,需要两次旋转操作,先左旋转再右旋转。
将A的左孩子B的右子树的根结点C向左上旋转提升至B结点的位置
本质:永远保证 子树0<关键字1<子树1<关键字2<子树2<...
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺 当右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点 右(或左)兄弟结点的关键字还很宽裕,则需要调整该结点、右(或左)兄弟结 点及其双亲结点及其双亲结点(父子换位法)
LL平衡旋转(右单旋转)
而B的原右子树则作为A结点的左子树
在A的右孩子的右子树中插入导致不平衡
由于在结点A的右孩子(R)的右子树(R)上插入了新结点,A的平衡因子由-1
减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。
RR
将A的右孩子B向左上旋转代替A成为根节点 将A结点向左下旋转成为B的左子树的根结点
《数据结构图论部分》PPT课件
Page 4
2020/11/24
哥尼斯堡七桥问题
能否从某个地方出发,穿过所有的桥仅一次 后再回到出发点?
Page 5
2020/11/24
七桥问题的图模型
欧拉回路的判定规则:
1.如果通奇数桥的地方多于
C
两个,则不存在欧拉回路;
2.如果只有两个地方通奇数
桥,可以从这两个地方之一
A
B 出发,找到欧拉回路;
V4 是有向边,则称该图为有向图。
Page 9
2020/11/24
简单图:在图中,若不存在顶点到其自身的边,且同 一条边不重复出现。
V1
V2
V3
V4
V5
非简单图
V1
V2
V3
V4
V5
非简单图
V1
V2
V3
V4
V5
简单图
❖ 数据结构中讨论的都是简单图。
Page 10
2020/11/24
图的基本术语
邻接、依附
DeleteVex(&G, v); 初始条件:图 G 存在,v 是 G 中某个顶点。 操作结果:删除 G 中顶点 v 及其相关的弧。
Page 34
2020/11/24
InsertArc(&G, v, w); 初始条件:图 G 存在,v 和 w 是 G 中两个顶点。 操作结果:在 G 中增添弧<v,w>,若 G 是无向的,则还
Page 2
2020/11/24
• 知识点
– 图的类型定义 – 图的存储表示 – 图的深度优先搜索遍历和广度优先搜索遍历 – 无向网的最小生成树 – 拓扑排序 – 关键路径 – 最短路径
Page 3
图的遍历和搜索PPT课件

7
1
2 4
3 5
Dfs: 124356
6
2021/3/12
8
1
2 4
3
6
5
Bfs: 123645
2021/3/12
9
A
B
C
D
E
2021/3/12
10
A
AB
AC
ABC
ACD ACE
ABCD ABCE ACDE ACED
ABCDE ABCDE ACDEC
ACEDC
ABCDEC ABCDEC ACDECB
readln(f,ch1,ch2,ch3); data[ch1,ch3]:=1; data[ch3,ch1]:=1; end; close(f);assign(f,'wjx.out');rewrite(f); end;
2021/3/12
14
procedure main(ch:char;step:integer); var r:char; begin
2021/3/12
3
1
2
3
4
6
5
Dfs: 124563 Bfs: 123465
2021/3/12
4
1 2 4 5 6 3
Dfs: 124563
2021/3/12
5
1
2
3
4
6
5
Bfs: 123465
2021/3/12
6
1
2
3
4
5
6
Dfs: 124356 Bfs: 123645
2021/3/12
2021/3/12
22
一. 递归算法:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3
其中实线表示下一层递归,虚线 4 5 6
7
表示递归返回,箭头旁边数字表
示调用的步骤。遍历序列为 7, 3, 1, 2, 4, 8, 5, 6。
8 无向图 G7
DFS1(7) 1 DFS1(3) 2 14
DFS1(1) 3 DFS1(2)
13
12
4 DFS1(4) 5 DFS1(8) 6 DFS1(5)
{ if (!visited[p->adjvex]){
visit(head[p->adjvex].vertex;
visited[p->adjvex]=1; r++;q[r]=p->adjvex ;
} p=p->next;}}}
邻接表的广度优先搜索演示
3. 非连通图的广度优先搜索
可以在每个连通分量或每个强连通分量中都选一个顶点,进行 广度优先搜索遍历,最后将每个连通分量或每个强连通分量的 遍历结果合起来,则得到整个非连通图或非强连通图的广度优 先搜索遍历序列。具体可以表示如下:
算法描述为下面形式:
void dfs1(int i) { link *p; visit(head[i]) ; //输出访问顶点
visted[i]=1; //全局数组访问标记置为1表示已访问
p=head[i].link;
while (p!=NULL) {
if (!visited[p->adjvex])
7
11
10
8 DFS1(6)
9
邻接表深度优先搜索示意图
3. 非连通图的深度优先搜索
在每个连通分量或每个强连通分量中都选一个顶点, 进行深度优先搜索遍历,最后将每个连通分量或每个 强连通分量的遍历结果合起来,则得到整个非连通图 的遍历结果。
遍历算法实现与连通图的只有一点不同,即对所有顶 点进行循环,反复调用连通图的深度优先搜索遍历算 法即可。具体实现如下:
邻接矩阵存储时的算法描述为下面形式:
void dfs (int i) // 从顶点i 出发遍历 {
int j; visit(i); //输出访问顶点 visited[i]=1; //全局数组访问标记置1表示已经访问 for(j=1; j<=n; j++)
if ((A[i][j]= =1)&&(!visited[j])) dfs(j);
在无向图G7中,从顶点1出发的广度优先 搜索遍历序列举三种为:
1
1, 2, 3,Biblioteka 4, 5, 6, 7, 81, 3, 2, 7, 6, 5, 4, 8
2
3
1, 2, 3, 5, 4, 7, 6, 8
4
5
6
7
8 无向图 G7
和深度优先搜索类似,在遍历的过程中也需要一个访问标志数 组。并且,为了顺次访 问路径长度为2、3、…的顶点,需附设 队列以存储已被访问的路径长度为1,2,…的顶点。广 度优先 遍历的算法如下所示。 void bfs(Graph g ,vtx * v) {
dfs1(p->adjvex);p=p->next;
}
邻接表深度优先搜索演示
}
而当以邻接表作图的存储结构时,找邻接点所需
时间为O(e),其中e为无向图中边 的数或有向图
中弧的数。由此,当以邻接表作存储结构时,深
度优先搜索遍历图的时间复 杂度为O(n+e)。
1
用刚才算法,可以描述从顶点7
2
出发的深度优先搜索遍历示意图,
}
用上述算法和无向图G7,可以描述从顶点1出发的 深度优先搜索遍历过程,其中实线表示下一层递 归调用,虚线表示递归调用的返回。
可以得到从顶点1的遍历结果为 1, 2, 4, 8, 5, 6, 3, 7。 同样可以分析出从其它顶点出发的遍历结果。
DFS(1)
DFS(2)
DFS(4)
DFS(8)
DFS(5)
根据该算法用及图7-14中的邻接矩阵,可以得到图G7的 广度优先搜索序列,若从顶点1 出发,广度优先搜索序 列为:1,2,3, 4,5, 6,7,8。若从顶点3出发,广 度优先搜索序列为:3, 1, 6, 7, 2, 8, 4, 5。
算法描述如下:
void bfs( int i) //从顶点i出发遍历
visit(v); visited[v]=1; INIQUEUE(Q); ENQUEUE(Q,v); while (!EMPTY(Q)) { DLQUEUE(Q,v); //队头元素出队
w=FIRSTADJ(g,v);//求v的邻接点 while (w!=0){
if (!visited[w]) { visit(w); visited[w]=1; ENQUEUE(Q,w); }
//定义队列
int f,r ; E_NODE *p ; //P为搜索指针
f=r=0 ; visit(head[i]) ; visited[i]=1 ; r++; q[r]=i ; //进队
while (f<r)
{ f++ ; i=q[f] ; p=head[i].link ;
while (p!=NULL)
for (j=1; j<=n; j++)
if ((A[i][j]==1)&&(!visited[j]))
{ visit(v[j]) ; visited[j]=1 ; r++; q[r]=j ;}
}}
2. 用邻接表实现图的广序优先搜索遍历
1
1
2
3
2
3
4
5
6
4
7
5
6
8
7
无向图 G7
8
2
3^
1
4
5^
1
6
7.3 图的遍历
在图中有回路,从图中某一顶点出发访问 图中其它顶点时,可能又会回到出发点, 而图中可能还剩余有顶点没有访问到。
我们可以设置一个全局型标志数组visited 来标志某个顶点是否被访问过,未访问的 值为0,访问过的值为1。
图的遍历有两种方法:深度优先搜索遍历 (DFS)和广度优先搜索遍历(BFS)。
w=NEXTADJ(g,v,w);//求下一邻接点 } } }//bfs
1. 用邻接矩阵实现图的广度优先搜索遍历
1
2
4
5
3
6 7
8
01100000 10011000 10000110 01000001 01000001 00100001 00100001 00011110
无向图 G7
无向图 G7 的邻接矩阵
例如,对下图所示无向图G7,从顶点1出发 的深度优先搜索遍历序列可有多种,下面仅 给出三种,其它可作类似分析。
1
1, 2, 4, 8, 5, 6, 3, 7 1, 2, 5, 8, 4, 7, 3, 6 1, 3, 6, 8, 7, 4, 2, 5
2
4
5
3
6 7
可以看出,从某一个顶点出发的遍 历结果是不唯一的。但是,若我们 给定图的存贮结构,则从某一顶点 出发的遍历结果应是唯一的。
w=NEXTADJ(G,v,w);//找下一邻接点 } }
1. 用邻接矩阵实现图的深度优先搜索
1
2
4
5
3
6 7
8 无向图 G7
01100000 10011000 10000110 01000001 01000001 00100001 00100001 00011110
邻接矩阵的深度优先搜索演示
无向图 G7 的邻接矩阵
1
2
4
5
3
6 7
8 无向图 G7
DFS(6)
DFS(3)
邻接矩阵深度优先搜索示意图
DFS(7)
2.用邻接表实现图的深度优先搜索
仍以无向图G7 为例,来说明算法的实现, G7的邻接表见下图:
1
1
2
2
3
3
4
5
6
4 75
6
8
7
无向图 G7
8
2
3^
1
4
5^
1
6
7^
2
8^
2
8^
3
8^
3
8^
4
5
6
7^
G7 的邻接表
for(int i=1;i<=n;i++)
if(!visited[i])
或者
dfs(i) ;
for(int i=1;i<=n;i++) if(!visited[i]) dfs1(i);
8.3.2 广度优先搜索遍历
1. 广度优先搜索的思想
广度优先搜索遍历类似于树的按层次遍历。设图 G的初态是所有顶点均未访问,在G 中任选一顶 点i作为初始点,则广度优先搜索的基本思想是: (1) 首先访问顶点i,并将其访问标志置为已被访 问,即visited[i]=1; (2) 接着依次访问与顶点i有边相连的所有顶点W1, W2,…,Wt; (3) 然后再按顺序访问与W1,W2,…,Wt有边 相连又未曾访问过的顶点; 依此类推,直到图中所有顶点都被访问完为止 。
for(int i=1;i<=n;i++) if(!visited[i]) bfs(i) ;
for(int i=1;i<=n;i++) 或 if(!visited[i])
bfs1(i);
分析上述过程,每个顶点至多进一次队列。遍历图的过程实 质上是通过边或弧找邻接 点的过程、因此广度优先搜索遍历 图的时间复杂度和深度优先搜索遍历相同,两者不同之 处仅 仅在于对顶点访问的顺序不同。