数据库存储过程的使用案例及最佳实践
oracle 存储过程优秀例子

oracle 存储过程优秀例子Oracle存储过程是一种在数据库中存储并可以被重复调用的程序单元。
它可以用于实现复杂的业务逻辑,提高数据库的性能和安全性。
下面列举了十个优秀的Oracle存储过程例子。
1. 用户注册存储过程该存储过程可以用于用户注册过程的验证和处理。
它可以检查用户提交的信息是否有效,并将用户信息插入到用户表中。
如果有错误或重复信息,它会返回相应的错误消息。
2. 商品库存更新存储过程该存储过程用于处理商品出库和入库的操作。
它会更新商品表中的库存数量,并记录相应的操作日志。
如果库存不足或操作失败,它会返回错误消息。
3. 订单生成存储过程该存储过程用于生成订单并更新相关表的信息。
它可以检查订单的有效性,计算订单总金额,并将订单信息插入到订单表和订单明细表中。
如果有错误或重复订单,它会返回相应的错误消息。
4. 日志记录存储过程该存储过程用于记录系统的操作日志。
它可以根据传入的参数,将操作日志插入到日志表中,并记录操作的时间、操作人和操作内容。
这样可以方便后续的审计和故障排查。
5. 数据备份存储过程该存储过程用于定期备份数据库中的重要数据。
它可以根据预设的时间间隔,将指定表的数据导出到备份表中,并记录备份的时间和备份人。
这样可以保证数据的安全性和可恢复性。
6. 数据清理存储过程该存储过程用于定期清理数据库中的过期数据。
它可以根据预设的条件,删除指定表中的过期数据,并记录清理的时间和清理人。
这样可以减少数据库的存储空间和提高查询性能。
7. 权限管理存储过程该存储过程用于管理数据库中的用户权限。
它可以根据传入的参数,为指定用户或角色分配或撤销相应的权限。
同时,它可以记录权限的变更历史,以便审计和权限回溯。
8. 数据统计存储过程该存储过程用于统计数据库中的数据。
它可以根据预设的条件,查询指定表中的数据,并根据统计规则生成相应的统计报表。
这样可以方便用户对数据进行分析和决策。
9. 数据导入存储过程该存储过程用于将外部数据导入到数据库中。
mysql数据库实训综合案例

mysql数据库实训综合案例MySQL数据库实训综合案例可以涉及多个方面,包括数据库设计、数据操作、查询优化、存储过程和触发器等。
以下是一个简单的MySQL数据库实训综合案例,供您参考:案例:电子商务网站数据库设计任务1:设计数据库结构1. 设计数据库表:用户表(user)、商品表(product)、订单表(order)、订单明细表(order_detail)。
2. 确定表之间的关系:用户表与订单表通过用户ID关联,订单表与订单明细表通过订单ID关联,商品表与订单明细表通过商品ID关联。
任务2:插入数据1. 向用户表中插入若干用户数据。
2. 向商品表中插入若干商品数据。
任务3:查询数据1. 查询特定用户的订单信息。
2. 查询订单总金额大于某一阈值的订单。
3. 查询某一商品的销量。
任务4:优化查询性能1. 使用索引优化查询性能。
2. 使用JOIN操作优化多表查询。
3. 使用子查询优化复杂查询。
任务5:编写存储过程和触发器1. 编写存储过程:计算商品的总销量。
2. 编写触发器:在订单表中插入新记录时自动更新商品销量。
任务6:备份和恢复数据库1. 使用mysqldump命令备份数据库。
2. 使用mysql命令恢复数据库。
实训步骤1. 创建数据库和表结构。
2. 插入数据并验证数据完整性。
3. 执行查询操作并分析查询结果。
4. 优化查询性能并对比效果。
5. 编写存储过程和触发器并测试功能。
6. 备份和恢复数据库。
实训总结通过本次实训,学生可以掌握MySQL数据库的基本操作,包括数据库设计、数据操作、查询优化、存储过程和触发器等。
同时,学生可以了解在实际应用中如何优化数据库性能、如何备份和恢复数据库等重要技能。
通过实训,学生可以更好地理解数据库在电子商务网站中的作用,为未来的学习和工作打下坚实的基础。
oracle 存储过程优秀例子

oracle 存储过程优秀例子Oracle存储过程是一种在数据库中存储和执行SQL语句的过程。
它可以接受参数并返回结果,用于实现复杂的业务逻辑和数据操作。
下面是10个优秀的Oracle存储过程示例,展示了不同方面的功能和用法。
1. 创建表并插入数据```sqlCREATE PROCEDURE create_employee_table ASBEGINEXECUTE IMMEDIATE 'CREATE TABLE employee (id NUMBER, name VARCHAR2(100))';EXECUTE IMMEDIATE 'INSERT INTO employee VALUES (1, ''John Doe'')';EXECUTE IMMEDIATE 'INSERT INTO employee VALUES (2, ''Jane Smith'')';END;```这个存储过程创建了一个名为employee的表,并插入了两条数据。
2. 更新员工姓名```sqlCREATE PROCEDURE update_employee_name(p_id NUMBER,p_name VARCHAR2) ASBEGINUPDATE employee SET name = p_name WHERE id = p_id;COMMIT;END;```这个存储过程接受员工的ID和新的姓名作为参数,然后更新对应员工的姓名。
3. 删除员工记录```sqlCREATE PROCEDURE delete_employee(p_id NUMBER) AS BEGINDELETE FROM employee WHERE id = p_id;COMMIT;END;```这个存储过程接受员工的ID作为参数,然后删除对应的员工记录。
数据库实验报告:实验五

数据库实验报告:实验五一、实验目的本次数据库实验五的主要目的是深入了解和掌握数据库的高级操作,包括存储过程的创建与使用、视图的定义和应用、以及事务处理的原理和实践。
通过这些实验内容,提高我们对数据库系统的综合运用能力,为解决实际的数据库管理问题打下坚实的基础。
二、实验环境本次实验使用的数据库管理系统是 MySQL 80,开发工具为 Navicat Premium 12。
操作系统为 Windows 10 专业版。
三、实验内容及步骤(一)存储过程的创建与使用1、创建一个名为`get_student_info` 的存储过程,用于根据学生学号查询学生的基本信息(包括学号、姓名、年龄、性别和专业)。
```sqlDELIMITER //CREATE PROCEDURE get_student_info(IN student_id INT)BEGINSELECT FROM students WHERE student_id = student_id;END //DELIMITER ;```2、调用上述存储过程,查询学号为 1001 的学生信息。
```sqlCALL get_student_info(1001);```(二)视图的定义和应用1、创建一个名为`student_grade_view` 的视图,用于显示学生的学号、姓名和平均成绩。
```sqlCREATE VIEW student_grade_view ASSELECT sstudent_id, sname, AVG(ggrade) AS average_gradeFROM students sJOIN grades g ON sstudent_id = gstudent_idGROUP BY sstudent_id, sname;```2、查询上述视图,获取所有学生的平均成绩信息。
```sqlSELECT FROM student_grade_view;```(三)事务处理1、开启一个事务,向学生表中插入一条新的学生记录(学号:1005,姓名:_____,年龄:20,性别:男,专业:计算机科学)。
数据库实验存储过程、触发器和函数实验

存储过程、触发器和用户自定义函数实验实验内容一练习教材中存储过程、触发器和用户自定义函数的例子。
教材中的BookSales数据库,在群共享中,文件名为BookSales.bak。
实验内容二针对附件1中的教学活动数据库,完成下面的实验内容。
1、存储过程(1)创建一个存储过程,该存储过程统计“高等数学”的成绩分布情况,即按照各分数段统计人数。
执行存储过程:exec countpeople(2)创建一个存储过程,该存储过程有一个参数用来接收课程号,该存储过程统计给定课程的平均成绩。
执行存储过程:exec avg_score'C602'(3)创建一个存储过程,该存储过程将学生选课成绩从百分制改为等级制(即A、B、C、D、E)。
执行存储过程:exec alterscore(4)创建一个存储过程,该存储过程有一个参数用来接收学生姓名,该存储过程查询该学生的学号以及选修课程的门数。
执行存储过程:exec select_courses'李强'(5)创建一个存储过程,该存储过程有两个输入参数用来接收学号和课程号,一个输出参数用于获取相应学号和课程号对应的成绩。
执行存储过程:declare@score smallintexec select_socre'98601','C602',@score outputprint'成绩是'+convert(char(2),@score)+'分'2、触发器(1)为study表创建一个UPDATE触发器,当更新成绩时,要求更新后的成绩不能低于原来的成绩。
创建完触发器尝试进行更新数据:update study set score=60 where sno='98601'and cno='C601'执行完之后查询结果发现成绩仍然是90select score from study where sno='98601'and cno='C601'再更新一个高于90分的成绩则可以成功update study set score=91 where sno='98601'and cno='C601'select score from study where sno='98601'and cno='C601'(2)为study表创建一个DELETE触发器,要求一次只能从study表中删除一条记录。
达梦数据库存储过程 for循环实例

达梦数据库存储过程for循环实例全文共四篇示例,供读者参考第一篇示例:在数据库开发中,存储过程是一种存储在数据库中的一系列SQL 语句的集合,可以被调用和执行。
通过存储过程,开发人员可以实现复杂的业务逻辑和数据处理,并且提高数据库的性能和安全性。
在达梦数据库中,存储过程也是一项非常重要的功能,可以帮助开发人员更好地管理和操作数据库。
在很多情况下,我们需要在存储过程中使用循环来处理数据,特别是当需要对多条记录进行相同的操作时。
在本篇文章中,我们将介绍如何在达梦数据库存储过程中实现循环功能,以及如何使用for循环来实现一些常见的业务逻辑。
我们需要了解在达梦数据库中如何创建存储过程。
以创建一个简单的存储过程为例,语法如下:```CREATE PROCEDURE proc_exampleASBEGIN-- 在此处编写存储过程的SQL语句END```在上面的代码中,我们通过CREATE PROCEDURE语句创建了一个名为proc_example的存储过程。
存储过程的主体部分在BEGIN和END之间,可以包含任意数量的SQL语句。
接下来,我们将介绍如何在达梦数据库存储过程中使用for循环来处理数据。
for循环是一种常用的循环结构,可以重复执行一组语句,直到指定条件不再成立为止。
在存储过程中,我们可以使用for循环来遍历表中的记录,或者执行一定次数的操作。
下面是一个简单的示例,演示如何在存储过程中使用for循环来输出数字1到10:WHILE @i <= 10BEGINPRINT @iSET @i = @i + 1ENDEND```在上面的代码中,我们通过DECLARE语句声明了一个变量@i,用于保存循环变量的值。
然后通过WHILE语句指定了循环的条件@i <= 10,当条件成立时,执行循环体中的PRINT语句,并将@i的值递增1。
当循环变量@i的值大于10时,循环结束。
通过上面的例子,我们可以看到在达梦数据库存储过程中使用for 循环是非常简单的。
如何使用存储过程实现批量数据导入

如何使用存储过程实现批量数据导入引言随着互联网和信息技术的发展,数据量的爆炸性增长使得批量数据导入成为许多企业和组织日常工作中的需求。
为了提高数据导入的效率和准确性,使用存储过程成为一种常见的做法。
本文将探讨如何使用存储过程实现批量数据导入,并在这个过程中展示存储过程的优势和灵活性。
一、存储过程的概念和优势存储过程是一些预编译并存储在数据库中的SQL代码的集合,可以作为一个单独的单元来执行。
存储过程通常用于处理复杂的业务逻辑,并且可以被其他程序或脚本调用。
存储过程具有以下几个优势:1. 提高性能:存储过程在数据库服务器端进行执行,减少了网络传输的开销,提高了执行速度。
此外,存储过程还可以使用查询优化技术,如索引和分区,进一步提高查询效率。
2. 增强安全性:存储过程可以用来限制对数据库的访问权限,只允许授权用户执行特定的操作。
这样可以有效地保护数据的安全性,防止非法访问和误操作。
3. 降低开发成本:存储过程可以被多个应用程序共享,避免了重复编写相同的业务逻辑代码。
这样可以减少代码开发的工作量,提高开发效率。
二、批量数据导入的需求和挑战批量数据导入通常发生在以下情况下:从外部数据源导入数据到数据库,批量导入大量数据以减少网络传输时间,以及定期导入数据以更新数据库。
然而,批量数据导入也存在一些挑战:1. 数据的一致性:批量导入的数据通常是从外部数据源获取的,可能存在数据格式上的问题。
因此,需要对导入的数据进行数据转换和错误处理,以确保数据的一致性和完整性。
2. 导入的效率:批量导入大量数据可能需要较长的时间。
为了提高导入的效率,需要采用一些方法,如并行导入、批量提交和使用存储过程等。
三、使用存储过程实现批量数据导入的步骤下面将介绍使用存储过程实现批量数据导入的一般步骤。
具体的实现方式可以根据具体的业务需求和数据库系统的特性进行调整。
1. 创建存储过程:首先,需要在数据库中创建一个用于批量数据导入的存储过程。
实验七 过程式数据库对象的使用
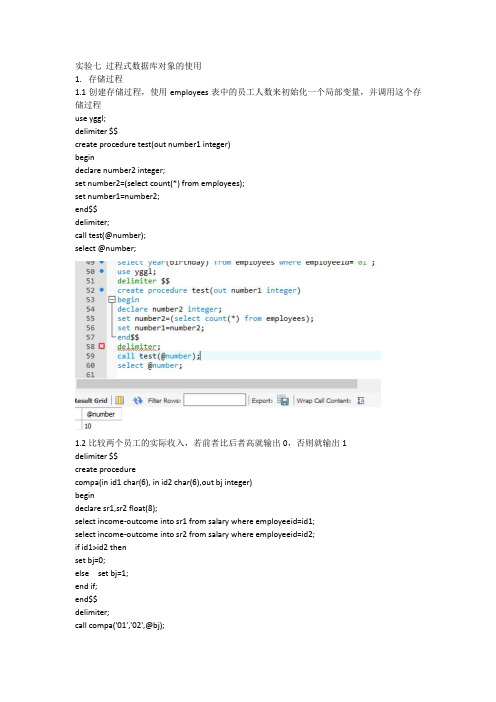
实验七过程式数据库对象的使用1.存储过程1.1创建存储过程,使用employees表中的员工人数来初始化一个局部变量,并调用这个存储过程use yggl;delimiter $$create procedure test(out number1 integer)begindeclare number2 integer;set number2=(select count(*) from employees);set number1=number2;end$$delimiter;call test(@number);select @number;1.2比较两个员工的实际收入,若前者比后者高就输出0,否则就输出1delimiter $$create procedurecompa(in id1 char(6), in id2 char(6),out bj integer)begindeclare sr1,sr2 float(8);select income-outcome into sr1 from salary where employeeid=id1;select income-outcome into sr2 from salary where employeeid=id2;if id1>id2 thenset bj=0;else set bj=1;end if;end$$delimiter;call compa('01','02',@bj);select @bj;1.3 使用游标定一个员工的实际收入是否排在前三名,结果为true表示是,结果为false表示否。
DELIMITER $$ CREATE PROCEDURE TOP3(IN EM_ID CHAR(6),OUT OK BOOLEAN )BEGIN DECLARE X_EM_ID CHAR(6);DECLARE SEQ INT; DECLARE ACT_IN FLOAT;DECLARE FOUND BOOLEAN;DECLARE SALARY_DIS CURSOR FOR SELECT EmployeeID, InCome-OutCome FROM Salary ORDER BY 2 DESC;DECLARE CONTINUE HANDLER FOR NOT FOUNDSET FOUND=FALSE;SET SEQ=0; SET FOUND=TRUE;SET OK=FALSE;OPEN SALARY_DIS;FETCH SALARY_DIS INTO X_EM_ID,ACT_IN;WHILE FOUND AND SEQ<3 AND OK=FALSE DOSET SEQ=SEQ+1;IF X_EM_ID=EM_ID THENSET OK=TRUE;END IF;FETCH SALARY_DIS INTO X_EM_ID,ACT_IN;END WHILE;CLOSE SALARY_DIS;END$$ DELIMITER ;CALL TOP3('01',@OUT1);1.4创建存储过程,要求当一个员工的工作年份大于6年时将其转到经理办公室工作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库存储过程的使用案例及最佳实践
数据库存储过程是一种在数据库中创建和执行的可重复使用的代码块。
它们在数据库管理系统中扮演着重要的角色,能够提供更高效、更可靠的数据操作和业务逻辑处理。
在这篇文章中,我们将探讨数据库存储过程的使用案例以及最佳实践,帮助您充分发挥存储过程的优势。
一、数据库存储过程的使用案例
1. 数据验证与完整性约束
存储过程可以用于数据验证和保证数据完整性。
例如,当向数据库插入或更新数据时,存储过程可以根据特定的业务规则来验证数据的有效性。
如果数据不符合规定的条件,存储过程可以阻止对数据的修改,从而保护数据库的完整性。
2. 数据聚合与分析
存储过程可以用于聚合和分析数据库中的数据。
通过存储过程,我们可以编写复杂的查询逻辑,对数据库中的数据进行统计分析。
例如,我们可以创建一个存储过程来计算某个时间段内的销售总额或平均订单数量,以便更好地了解业务的发展趋势和规模。
3. 业务逻辑与事务处理
存储过程还可以用于处理数据库中的复杂业务逻辑,将多个数据库操作捆绑到一个事务中执行。
通过存储过程,我们可以确保所有相关的操作要么全部执行成功,要么全部回滚。
这有助于维护数据的完整性,并提供良好的错误处理机制。
4. 数据访问控制
存储过程可以用于实现数据访问控制,确保只有授权的用户或角色可以执行特定的操作。
通过存储过程,我们可以定义访问数据库的权限,并在存储过程中实施必要的身份验证和授权机制,从而保护数据免受非法访问或修改。
二、数据库存储过程的最佳实践
1. 避免过于复杂的存储过程
尽量避免编写过于复杂的存储过程,因为复杂的存储过程难以维护和调试。
应该把存储过程的功能分解成多个简单的存储过程,并通过调用这些简单的存储过程来构建复杂的业务逻辑。
2. 参数的使用和传递
在定义存储过程时,应该明确定义和使用参数。
通过参数的使用,可以增加存储过程的灵活性和重用性。
同时,在调用存储过程时,要注意参数的正确传递,保证数据的准确性和完整性。
3. 错误处理和异常处理
在存储过程中,应该尽量处理可能发生的错误和异常。
可以使用TRY-CATCH块来捕获和处理异常,并使用RAISERROR语句来向用户返回有用的错误信息。
良好的错误处理机制有助于提升系统的可用性和用户体验。
4. 编写清晰的注释和文档
在编写存储过程时,应该为每个存储过程编写清晰的注释和文档。
注释应该解释存储过程的功能、输入和输出参数,以及逻辑的实现方式。
这样可以帮助他人理解并正确使用存储过程。
5. 合理使用事务
在处理需要保证数据一致性的操作时,应该使用事务。
通过将相关的数据库操作放在一个事务中,可以确保这些操作要么全部执行成功,要么全部回滚。
这有助于维护数据的完整性和一致性。
6. 定期优化和评估存储过程
存储过程不是一成不变的,应该定期进行优化和评估。
数据库的数据量和业务需求可能随时间的推移而发生变化,存储过程也需要相应地调整和优化,以保证性能和稳定性。
结论
数据库存储过程是数据库管理系统中强大而功能丰富的一部分。
通过使用存储过程,我们可以提高数据库的性能、可靠性和灵活性。
本文探讨了数据库存储过程的使用案例和最佳实践,希望能帮助读者更好地理解和应用存储过程的优势,提高数据库应用的质量和效率。