深度神经网络知识蒸馏综述
知识蒸馏 综述

知识蒸馏综述知识蒸馏是一种被认为是有帮助的基于机器学习的技术,旨在从已经存在的神经网络模型中捕获有用的知识,以提高新模型的性能。
就其本质而言,知识蒸馏是指从一个大的神经网络模型(即源模型)中提取知识,然后用于构建另一个较小的模型(即目标模型)。
它可以被认为是一种“经典”机器学习技术,用于将知识从大型模型中提取到较小但仍然具有较高性能的模型中。
知识蒸馏的历史知识蒸馏技术最初被提出于2014年,由米娜贝南(Meina Bennan)和马克林奇(Mark Linsey)提出,目的是寻求一种定量测量过拟合模型的方法。
自那以来,它一直被用于各种机器学习应用程序中,并与其他技术结合,以提高模型的性能,如网络正则化,数据增强和贝叶斯优化。
知识蒸馏的应用:知识蒸馏技术已经成为机器学习领域中流行的技术,用于有效地传递知识,从而提高性能。
它可以用于多种机器学习场景,包括计算机视觉,自然语言处理,强化学习等等。
其中最常见的应用是用于计算机视觉。
计算机视觉是指机器学习在计算机中识别和理解图像的方面。
它已经成为深度学习领域的一大应用,用于识别人脸,识别文字,检测物体,识别行为等。
知识蒸馏的技术已经用于许多计算机视觉任务中,以提高模型的性能。
例如,在一项用于检测目标物体的任务中,可以将知识蒸馏技术用于提高模型的准确性,减少计算资源消耗,同时还可以在更复杂的数据集上取得更好的性能。
知识蒸馏法的优缺点知识蒸馏方法有很多优点。
首先,它支持从一个大规模的模型中提取知识,并将其用于构建更小但性能更高的模型,从而减少计算资源的消耗。
其次,它可以用于改进模型的性能,提高模型的泛化能力,以及避免模型过拟合。
此外,知识蒸馏技术可以有效地减少模型的计算复杂度,并使模型更加可扩展。
它也可以提高模型的可解释性,这对在实际应用中模型的理解和可信度非常有帮助。
然而,知识蒸馏也有一些缺点。
其中最重要的缺点是它需要一个非常大的训练集,以便提取模型中的有用知识。
对抗学习中的知识蒸馏和模型压缩方法

对抗学习中的知识蒸馏和模型压缩方法引言近年来,深度学习在计算机视觉、自然语言处理等领域取得了巨大的成功。
然而,深度神经网络通常具有数以千计的参数和复杂的结构,这导致了模型的尺寸过大,不仅占用了大量的存储空间,而且计算成本也较高。
为了解决这一问题,研究人员提出了一系列的模型压缩方法,其中对抗学习中的知识蒸馏技术得到了广泛的应用。
本文将介绍对抗学习中的知识蒸馏和模型压缩方法,探讨其原理、应用以及优缺点。
一、知识蒸馏的原理知识蒸馏是一种通过利用“教师网络”的知识来训练“学生网络”的技术。
通常情况下,“教师网络”是一个复杂的深度神经网络,具有很高的准确度和泛化能力。
而“学生网络”则是一个较为简单的模型,它通过学习“教师网络”中的知识来提高自身的性能。
知识蒸馏的基本原理是将“教师网络”的输出结果作为“学生网络”的目标标签进行训练。
在训练过程中,除了使用原始的训练数据进行传统的监督学习外,还引入了教师网络在训练数据上的概率分布。
通过最小化“学生网络”输出与教师概率分布之间的差距,可以有效地传递“教师网络”的知识。
此外,还可以通过调整损失函数的权重,使得“学生网络”更加关注“教师网络”在训练数据中的缓慢变化的概率分布,而不是完全模仿其输出。
知识蒸馏的核心思想是通过软标签进行训练,从而使得“学生网络”可以学习到更加鲁棒的表示。
此外,知识蒸馏还能够降低模型的复杂度,提升推理速度,使得“学生网络”可以在计算资源有限的情况下运行。
二、模型压缩方法在知识蒸馏的基础上,研究人员还提出了一系列的模型压缩方法,旨在减小深度神经网络的尺寸和计算成本。
下面将介绍其中的几种常见方法。
1. 参数剪枝:参数剪枝通过减少网络中冗余的连接和节点来压缩模型。
剪枝的原则是通过计算参数的重要性或敏感性来决定是否保留。
通常,剪枝可以分为结构化剪枝和非结构化剪枝两种。
结构化剪枝指的是按照某种规则删除整个通道或层,而非结构化剪枝则是直接删除某个参数。
知识蒸馏综述:蒸馏机制

知识蒸馏综述:蒸馏机制作者丨pprp来源丨GiantPandaCV编辑丨极市平台极市导读这一篇介绍各个算法的蒸馏机制,根据教师网络是否和学生网络一起更新,可以分为离线蒸馏,在线蒸馏和自蒸馏。
感性上理解三种蒸馏方式:•离线蒸馏可以理解为知识渊博的老师给学生传授知识。
•在线蒸馏可以理解为教师和学生一起学习。
•自蒸馏意味着学生自己学习知识。
1. 离线蒸馏 Offline Distillation上图中,红色表示pre-trained, 黄色代表To be trained。
早期的KD方法都属于离线蒸馏,将一个预训练好的教师模型的知识迁移到学生网络,所以通常包括两个阶段:•在蒸馏前,教师网络在训练集上进行训练。
•教师网络通过logits层信息或者中间层信息提取知识,引导学生网络的训练。
第一个阶段通常不被认为属于知识蒸馏的一部分,因为默认教师网络本身就是已经预训练好的。
一般离线蒸馏算法关注与提升知识迁移的不同部分,包括:知识的形式,损失函数的设计,分布的匹配。
Offline Distillation优点是实现起来比较简单,形式上通常是单向的知识迁移(即从教师网络到学生网络),同时需要两个阶段的训练(训练教师网络和知识蒸馏)。
Offline Distillation缺点是教师网络通常容量大,模型复杂,需要大量训练时间,还需要注意教师网络和学生网络之间的容量差异,当容量差异过大的时候,学生网络可能很难学习好这些知识。
2. 在线蒸馏 Online Distillation上图中,教师模型和学生模型都是to be trained的状态,即教师模型并没有预训练。
在大容量教师网络没有现成模型的时候,可以考虑使用online distillation。
使用在线蒸馏的时候,教师网络和学生网络的参数会同时更新,整个知识蒸馏框架是端到端训练的。
•Deep Mutual Learning(dml)提出让多个网络以合作的方式进行学习,任何一个网络可以作为学生网络,其他的网络可以作为教师网络。
知识蒸馏算法汇总

知识蒸馏算法汇总在人工智能领域,知识蒸馏算法是一种将深度神经网络(DNN)的知识以更简洁的方式传递给另一个模型的技术。
这种算法可以帮助我们将复杂的模型变得更加轻量化和高效,同时保持其性能。
知识蒸馏算法的基本原理是将一个复杂的模型(通常被称为“教师模型”)的知识转移到另一个更简单的模型(通常被称为“学生模型”)中。
这种转移过程可以通过多种方式实现,以下是几种常见的知识蒸馏算法:1. 软目标训练(Soft T arget Training):在软目标训练中,教师模型的输出被视为概率分布而不是单一的预测结果。
学生模型通过最小化与教师模型输出的交叉熵来学习。
这种方法可以帮助学生模型学习到教师模型的概率分布,从而更好地捕捉到数据的特征。
2. 知识蒸馏损失(Knowledge Distillation Loss):知识蒸馏损失是一种在学生模型中添加的额外损失函数,用于测量学生模型和教师模型之间的差异。
这种损失函数可以帮助学生模型更好地逼近教师模型的输出。
3. 温度参数(Temperature Parameter):温度参数是一种用于调整教师模型输出分布的参数。
通过增加温度参数,可以使教师模型的输出分布更加平滑,从而使得学生模型更容易学习到这种分布。
4. 知识蒸馏过程(Knowledge Distillation Process):知识蒸馏过程可以分为两个阶段。
首先,使用教师模型对训练数据进行预测,得到一组软目标。
然后,使用软目标和真实标签来训练学生模型。
在训练过程中,软目标起到了一种正则化的作用,帮助学生模型更好地泛化。
知识蒸馏算法在许多领域都有广泛的应用。
例如,在自然语言处理任务中,教师模型可以是一个复杂的语言模型,学生模型可以是一个轻量级的文本分类器。
通过使用知识蒸馏算法,我们可以将教师模型的语言知识传递给学生模型,从而实现更高效的文本分类。
知识蒸馏算法还可以用于模型压缩和加速。
通过将复杂的模型转化为更简单的模型,可以减少模型的存储空间和计算资源的需求,从而提高模型的运行速度和效率。
对抗学习中的知识蒸馏和模型压缩方法

对抗学习中的知识蒸馏和模型压缩方法引言在深度学习领域中,模型的大小和计算量一直是限制其在实际应用中广泛推广的主要障碍之一。
随着深度神经网络的不断发展,模型变得越来越复杂,参数数量也越来越庞大。
为了解决这一问题,学术界提出了许多方法来压缩和蒸馏深度神经网络。
其中,对抗学习中的知识蒸馏和模型压缩方法是一种被广泛研究和应用的技术。
主体一、知识蒸馏方法知识蒸馏是指通过将大型复杂模型中所包含的知识转移到小型简化模型中,以提高小模型性能的技术。
这种方法通过将大模型(教师网络)在训练集上得到的软标签(概率分布)作为小模型(学生网络)训练集上的监督信号来实现。
1.1 软标签生成在知识蒸馏过程中,生成软标签是其中一个关键步骤。
传统监督学习使用硬标签(one-hot编码),即将样本分成不同的类别,而软标签则是指将样本分成不同的类别并给出概率分布。
生成软标签的方法有多种,其中一种常见的方法是使用温度参数T对教师网络输出进行平滑化,使得概率分布更加平滑。
另外,还可以使用教师网络在训练集上得到的中间层特征作为软标签。
1.2 学生网络训练在生成了软标签之后,可以使用这些软标签作为学生网络训练集上的监督信号。
学生网络通常是一个较小和简化的模型,通过最小化学生网络输出与教师网络输出之间的差异来进行训练。
这种差异通常使用交叉熵损失函数来度量。
1.3 知识蒸馏效果通过知识蒸馏方法,在保持模型性能不损失太多情况下,可以大大减少模型参数和计算量。
研究表明,在一些任务中,知识蒸馏方法能够将模型压缩到原始模型大小的几十分之一,并且在测试集上取得了与原始模型相当甚至更好的性能。
二、对抗学习方法对抗学习是一种通过让两个模型相互竞争来提高模型性能的方法。
在对抗学习中,通常包含两个模型:生成器和判别器。
生成器的目标是生成逼真的样本,而判别器的目标是尽可能准确地区分真实样本和生成样本。
2.1 对抗训练过程在对抗学习中,生成器和判别器通过交替训练来提高性能。
知识蒸馏演变综述

知识蒸馏演变综述知识蒸馏是一种将深层神经网络模型转化为浅层模型的技术,旨在将复杂模型的知识传递给简化模型。
本文将对知识蒸馏的演变进行综述,从最早的模型压缩方法到现代的知识蒸馏技术,为读者介绍知识蒸馏的发展历程和应用领域。
1. 模型压缩模型压缩是知识蒸馏的前身,早期的研究主要集中在如何通过减少模型参数来降低模型复杂度。
这包括剪枝(pruning)、量化(quantization)和低秩分解(low-rank decomposition)等技术。
剪枝通过将权重较小的连接删除来减少模型参数,量化则是将浮点数参数转化为较低位数的定点数表示,低秩分解则是将权重矩阵分解为多个较低秩的矩阵。
这些方法可以在一定程度上减少模型的存储空间和计算量,但对于模型性能的影响较大。
2. 知识蒸馏的提出知识蒸馏的概念最早由Hinton等人在2015年提出,他们将深层神经网络的知识传递给浅层网络,从而提升浅层网络的性能。
具体而言,他们通过将深层网络的输出作为教师信号,与浅层网络的输出进行比较,利用教师信号的“软目标”指导浅层网络的训练。
这种方法可以提高浅层网络的泛化能力,同时减少过拟合的风险。
3. 知识蒸馏的改进随着研究的深入,学者们对知识蒸馏进行了进一步的改进和拓展。
一方面,他们提出了一些新的蒸馏方法,如FitNets、AT和SP等。
FitNets利用深层网络的中间表示来指导浅层网络的训练,AT则通过教师网络的注意力机制传递知识,SP则是通过自适应对抗训练来提升模型性能。
另一方面,他们探索了不同领域的应用,如语音识别、图像分类和自然语言处理等。
这些改进和应用拓展使得知识蒸馏成为一个具有广泛应用前景的研究方向。
4. 知识蒸馏的应用知识蒸馏在许多领域都取得了令人瞩目的成果。
在语音识别领域,研究人员利用知识蒸馏技术将大型语音识别模型的知识传递给小型模型,从而在保持准确率的同时大幅减少模型的计算资源消耗。
在图像分类领域,知识蒸馏可以将大型卷积神经网络的知识传递给小型网络,从而在保持准确率的同时提高模型的推理速度。
knowledge distillation 综述

knowledge distillation 综述
知识蒸馏(knowledge distillation)是一种模型压缩的技术,它通过训练一个较大、更复杂的模型(称为教师模型)来指导和优化一个较小、更简单的模型(称为学生模型)。
这种方法的目标是将教师模型的知识传递给学生模型,并使学生模型能够以较低的计算资源和存储要求,同时保持较好的性能。
知识蒸馏的基本思想是通过训练学生模型来拟合教师模型的输出。
通常情况下,教师模型会生成一个软目标分布作为学生模型的目标。
通过这种方式,学生模型可以学习到教师模型在不同类别上的置信度和相对权重等细微信息。
知识蒸馏的过程可以分为两个阶段:训练教师模型和训练学生模型。
在训练教师模型阶段,通常使用大型、复杂的模型,如深度神经网络或集成模型,以最大化模型性能。
在训练学生模型阶段,使用教师模型的输出作为指导,训练一个较小的模型来拟合教师模型的预测结果。
知识蒸馏已经在多个领域取得了显著的成功,包括物体识别、自然语言处理、语音识别等。
它不仅能够提高模型的推理速度和计算效率,还可以帮助解决低资源环境下的任务和领域知识传递的问题。
总而言之,知识蒸馏是一种模型压缩的方法,通过训练一个较大的教师模型来指导一个较小的学生模型,以传递教师模型的知识并在计算和存储上实现性能优化。
这种技术在机器学习领域中具有广泛的应用潜力。
知识蒸馏综述:知识的类型
知识蒸馏综述:知识的类型知识蒸馏综述: 知识的类型【GiantPandCV 引⾔】简单总结⼀篇综述《Knowledge Distillation A Survey 》中的内容,提取关键部分以及感兴趣部分进⾏汇总。
这篇是知识蒸馏综述的第⼀篇,主要内容为知识蒸馏中知识的分类,包括基于响应的知识、基于特征的知识和基于关系的知识。
定义:知识蒸馏代表将知识从⼤模型向⼩模型传输的过程。
作⽤:可以⽤于模型压缩和训练加速 ⼿段。
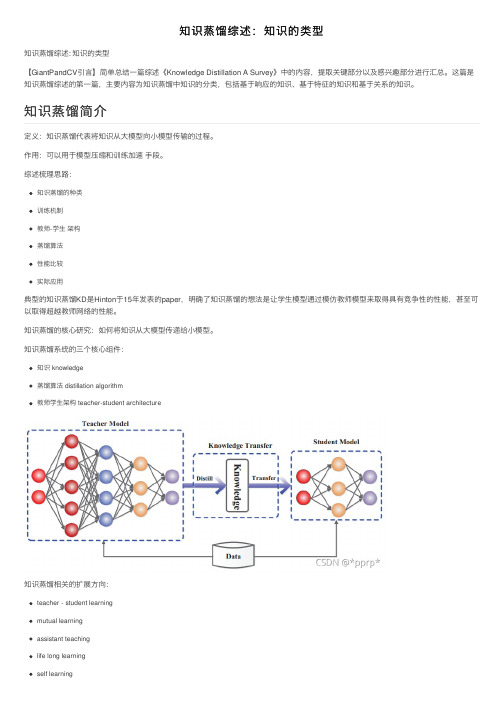
综述梳理思路:知识蒸馏的种类训练机制教师-学⽣ 架构蒸馏算法性能⽐较实际应⽤典型的知识蒸馏KD 是Hinton 于15年发表的paper ,明确了知识蒸馏的想法是让学⽣模型通过模仿教师模型来取得具有竞争性的性能,甚⾄可以取得超越教师⽹络的性能。
知识蒸馏的核⼼研究:如何将知识从⼤模型传递给⼩模型。
知识蒸馏系统的三个核⼼组件:知识 knowledge蒸馏算法 distillation algorithm教师学⽣架构teacher-student architecture 知识蒸馏相关的扩展⽅向:teacher - student learning mutual learning assistant teaching life long learning self learning知识蒸馏简介在知识蒸馏中,我们主要关⼼:知识种类、蒸馏策略、教师学⽣架构最原始的蒸馏⽅法是使⽤⼤模型的logits 层作为教师⽹络的知识进⾏蒸馏,但知识的形式还可以是:激活、神经元、中间层特征、教师⽹络参数等。
可以将其归类为下图中三种类型。
基于响应的知识⼀般指的是神经元的响应,即教师模型的最后⼀层逻辑输出。
响应知识的loss:L ResD z t ,z s =R z t ,z s 其核⼼想法是让学⽣模型模仿教师⽹络的输出,这是最经典、最简单、也最有效的处理⽅法Hinton 提出的KD 是将teacher 的logits 层作为soft label.p z i,T =exp z i /T ∑j exp z j /T T 是⽤于控制soft target 重要程度的超参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Computer Science and Application 计算机科学与应用, 2020, 10(9), 1625-1630Published Online September 2020 in Hans. /journal/csahttps:///10.12677/csa.2020.109171深度神经网络知识蒸馏综述韩宇中国公安部第一研究所,北京收稿日期:2020年9月3日;录用日期:2020年9月17日;发布日期:2020年9月24日摘要深度神经网络在计算机视觉、自然语言处理、语音识别等多个领域取得了巨大成功,但是随着网络结构的复杂化,神经网络模型需要消耗大量的计算资源和存储空间,严重制约了深度神经网络在资源有限的应用环境和实时在线处理的应用上的发展。
因此,需要在尽量不损失模型性能的前提下,对深度神经网络进行压缩。
本文介绍了基于知识蒸馏的神经网络模型压缩方法,对深度神经网络知识蒸馏领域的相关代表性工作进行了详细的梳理与总结,并对知识蒸馏未来发展趋势进行展望。
关键词神经网络,深度学习,知识蒸馏A Review of Knowledge Distillationin Deep Neural NetworksYu HanThe First Research Institute, The Ministry of Public Security of PRC, BeijingReceived: Sep. 3rd, 2020; accepted: Sep. 17th, 2020; published: Sep. 24th, 2020AbstractDeep neural networks have achieved great success in computer vision, natural language processing, speech recognition and other fields. However, with the complexity of network structure, the neural network model needs to consume a lot of computing resources and storage space, which seriously restricts the development of deep neural network in the resource limited application environment and real-time online processing application. Therefore, it is necessary to compress the deep neural network without losing the performance of the model as much as possible. This article introduces韩宇the neural network model compression method based on knowledge distillation, combs and sum-marizes the relevant representative works in the field of deep neural network knowledge distilla-tion in detail, and prospects the future development trend of knowledge distillation. KeywordsNeural Network, Deep Learning, Knowledge DistillationCopyright © 2020 by author(s) and Hans Publishers Inc. This work is licensed under the Creative Commons Attribution International License (CC BY 4.0)./licenses/by/4.0/1. 引言近年来,随着人工智能的不断兴起,深度神经网络已经被广泛应用在计算机视觉、自然语言处理、语音识别等多个领域,并取得了巨大的成功。
然而随着深度学习模型性能增加,网络结构越来越深,模型参数越来越多,导致模型需要消耗大量的计算资源和存储空间,这给模型的训练和使用带来了很大的困难。
网络结构加深使得模型训练周期变长,且需要大量的数据和强大性能的机器进行支撑;在模型的使用过程中,许多实际应用场景(如自动驾驶、智能对话等)对实时性有较高的要求,并且许多设备(如移动终端)不具备很高的存储条件,这严重制约了深度神经网络在资源有限的应用环境和实时在线处理的应用上的发展。
因此,如何在尽量不损失复杂深度神经网络模型的性能的情况下,对模型进行压缩与加速从而有效减小模型的计算量和存储空间,成为了深度神经网络模型有效利用的一个重要问题。
主流的深度神经网络压缩与加速的方法主要分为三类[1] [2]:1) 在已有的网络结构基础上进行参数的剪枝、共享、和低秩分解等操作来压缩模型的大小[3]-[9];2) 通过设计更加紧密的网络结构来进行模型压缩[10] [11][12];3)使用知识迁移的方式,将大模型中的知识蒸馏到小模型中,从而提升小模型的性能[13]-[28]。
剪枝、量化等参数压缩方法应用在硬件上时往往达不到很好的效果,而基于知识蒸馏的方法能够有效地对模型进行压缩,同时不显著地改变模型的性能。
目前,基于知识蒸馏的压缩方法已经被广泛应用于复杂深度学习模型的压缩与加速。
本文主要对基于知识蒸馏的神经网络模型压缩方法进行详细地介绍。
Figure 1. Typical deep neural network knowledge distillation framework图1. 典型的深度神经网络知识蒸馏框架韩宇Hinton 等人[13]在NIPS 2014中提出了知识蒸馏(Knowledge Distillation, KD)的概念,知识蒸馏是一种常见的模型压缩方法,其将复杂模型或多个模型集成学习到的知识迁移到另一个轻量级的模型之中,使得模型变轻量的同时尽量不损失性能。
典型的深度神经网络知识蒸馏框架如图1所示,将原始较大的或者集成的深度网络称为教师网络,用于获取知识;将轻量级的模型称为学生网络,用于接收教师网络的知识,并且训练后可用于前向预测。
知识蒸馏方法中的“知识”可以宽泛和抽象地理解成模型参数、网络提取的特征和模型输出等。
现有的深度神经网络蒸馏方法根据学习位置的不同可分为基于最后输出层的蒸馏方法、基于中间结果层的蒸馏方法以及基于激活边界的蒸馏方法;根据学习方式的不同可分为基于自我学习的蒸馏方法和基于对抗学习的蒸馏方法。
本文将对知识蒸馏各个类别的代表性研究成果进行详细介绍。
2. 基于最后输出层的蒸馏方法基于最后输出层的模型蒸馏方法的主要思想是以教师模型的输出结果作为先验知识,结合样本真实类别标签来共同指导学生模型的训练。
2014年Hinton 等人[13]在NIPS 上提出了一种基于教师-学生网络的知识蒸馏框架,该文章是知识蒸馏的开山之作。
Hinton 等人提出的知识蒸馏框架通过软化教师网络的输出来指导学生网络,将学生模型的优化目标分为两部分:1) 硬目标(Hard Target):学生模型输出的类别概率与样本真实的类别标签(One-hot)之间的交叉熵;2) 软目标(Soft Target):学生与教师模型软输出结果之间的交叉熵,软输出为经过带温度参数的Softmax 的输出结果,带温度参数的softmax 如公式(1)所示: ()()exp exp i i j j z T q z T =∑ (1)其中T 为温度参数,i z 是神经网络得到的概率分布,i q 为软输出。
将这两个优化目标进行组合,使得学生模型能够模仿教师模型输出的概率分布,并具有与教师模型相近的拟合能力。
为了使学生模型能够更好地理解教师模型,Kim 等人[14]提出了一种相关因子迁移法(Factor Transfer, FT)来进行知识蒸馏,其主要思想为对模型的输出进行编码和解码。
该模型利用卷积运算对教师模型的输出进行编码,并为学生模型添加一个卷积操作,用来学习翻译后的教师知识,最后通过FT 损失函数来最小化教师和学生网络之间的因子差异。
Passalis 等人[15]提出一种概率分布学习法,该方法让学生模型学习教师模型的概率分布。
将教师模型中的知识使用概率分布进行表示,通过最小化教师和学生之间概率分布的散度指标来进行知识迁移,使得学习更加容易。
传统的蒸馏学习方法直接最小化教师和学生模型输出值之间的相似性损失,使得学生模型的输出能够尽量接近教师模型的输出。
文献[16]和[17]认为这些方法使得学生模型只能学习到教师模型的输出表现,无法真正学习到结构信息。
因此,Park 等人[16]提出了一种关系型蒸馏学习法(RKD),利用多个教师模型的输出构成结构单元,使用关系势函数从结构单元中提取关系信息,并将信息从教师模型传递给学生模型,从而更好的指导学生模型的训练。
Peng 等人[17]认为传统的知识蒸馏只关注于教师和学术网络之间的实例一致性,他们提出了相关一致性知识蒸馏方法(CCKD),该方法不仅考虑了实例一致性,还设计了一个样本间的相关性损失函数约束来实现多个实例之间的相关一致性。
目前以BERT 为代表的一系列大规模的预训练语言模型成为了自然语言处理领域的流行方法,它们在许多自然语言处理任务上能够取得非常优异的成果,但是这些模型结构十分庞大,且需要大量的数据和设备资源来完成训练过程。
2019年Tang 等人[18]提出了一种对Bert 模型进行知识蒸馏的方法,将Bert 模型蒸馏成Bi-LSTM 模型。
该方法与经典的蒸馏网络类似,其损失函数由两部分组成:Bi-LSTM 与真实韩宇标签之间的交叉熵以及教师和学生网络的概率分布(Logits)之间的均方误差。
3. 基于中间结果层的蒸馏方法在深度学习中,一般将网络隐藏层的输出看作模型所学习到的特征。
基于中间结果层的模型蒸馏方法利用网络中间隐藏层学习到的特征作为知识,指导学生模型学习。
Romero等人[19]首次提出了基于教师模型中间层进行知识蒸馏的方法FitNets,该方法不仅让学生模型拟合教师模型的软输出(Soft Targets),还关注于教师网络隐藏层所抽取的特征。
FitNets方法训练分成两个阶段,第一阶段利用中间层的监督信号指导学生网络,使得学生网络中间层输出拟合教师网络中间层输出;第二阶段使用教师网络的输出作为软目标(Soft Target)对学生网络整体进行蒸馏。