t检验的与习题
卫生统计学习题

《预防医学》练习题——统计学方法一、判断题:1.对称分布资料的均数和中位数的数值一致。
()2.标准误是表示个体差异分布的指标。
()3.标准差大,则抽样误差也必然大。
()4.在抽样研究中,当样本含量趋向无穷大时,x趋向等于μ,Sx趋向等于σx。
()5.用频数表法计算均数,各个组段的组距必须相等。
()6.t 检验是对两个样本不同样本均数的差别进行假设检验的方法之一。
()7.t检验结果t=1.5,可认为两总体均数差别无意义。
()8.两次t检验都是对两个不同样本均数的差别进行假设检验,一次p<0.01,一次0.01<p<0.05,就表明前者两样本均数差别大,后者两样本均数差别小。
()9.在配对t检验中,用药前数据减去用药手数据和用药后数据减去用药前数据,作t检验后的结论是相同的。
()10.确定假设检验的概率标准后,同一资料双侧t检验显着,单侧t检验必然显着。
()11.某医师比较甲乙两种治疗方法的疗效,作假设检验,若结果p<0.05 ,说明其中某一疗法优于另一疗法;若p<0.01,则说明其中某一疗法非常优于另一疗法。
(? )12.若甲地老年人的比重比标准人口的老年人比重大,那么甲地标准化后的食管癌死亡率比原来的率高。
(? )13.比较两地胃癌死亡率,如果两地粗的胃癌死亡率一样,就不必标化。
(? )?14.同一地方30年来肺癌死亡率比较,要研究是否肺癌致病因子在增强,应该用同一标准人口对30年来的肺癌死亡分别作标化。
()15.某地1956年婴儿死亡人数中死于肺炎者占总数的16%,1976年则占18%,故可认为20年来该地婴儿肺炎的防治效果不明显。
()16.小学生交通事故发生次数为中学生的两倍,这是小学生不遵守交通规则所致。
()17.若两地人口的性别、年龄构成差别很大,即使某病发病率与性别、年龄无关,比较两地该病总发病率时,也应考虑标准化问题。
()18.计算率的平均值的方法是:将各个率直接相加来求平均值。
()19.某年龄组占全部死亡比例,1980年为11.2%,1983年为16.8%,故此年龄组的死亡危险增加。
t检验得资料与习题

t检验得资料与习题第四章:定量资料得参数估计与假设检验基础1抽样与抽样误差抽样⽅法本⾝所引起得误差。
当由总体中随机地抽取样本时,哪个样本被抽到就是随机得,由所抽到得样本得到得样本指标x与总体指标µ之间偏差,称为实际抽样误差。
当总体相当⼤时,可能被抽取得样本⾮常多,不可能列出所有得实际抽样误差,⽽⽤平均抽样误差来表征各样本实际抽样误差得平均⽔平。
σ x=σ/S x=S/2 t分布t分布曲线形态与n(确切地说与⾃由度v)⼤⼩有关。
与标准正态分布曲线相⽐,⾃由度v越⼩,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈⾼;⾃由度v愈⼤,t分布曲线愈接近正态分布曲线,当⾃由度v=∞时,t分布曲线为标准正态分布曲线。
t = X-u/Sx=X-u/(S/),V=N-1正态分布(normal distribution)就是数理统计中得⼀种重要得理论分布,就是许多统计⽅法得理论基础。
正态分布有两个参数,µ与σ,决定了正态分布得位置与形态。
为了应⽤⽅便,常将⼀般得正态变量X通过u变换[(X-µ)/σ]转化成标准正态变量u,以使原来各种形态得正态分布都转换为µ=0,σ=1得标准正态分布(standard normal distribution),亦称u分布。
根据中⼼极限定理,通过上述得抽样模拟试验表明,在正态分布总体中以固定n,抽取若⼲个样本时,样本均数得分布仍服从正态分布,即N(µ,σ)。
所以,对样本均数得分布进⾏u变换,也可变换为标准正态分布N (0,1) 由于在实际⼯作中,往往σ就是未知得,常⽤s 作为σ得估计值,为了与u 变换区别,称为t变换,统计量t 值得分布称为t分布。
假设X服从标准正态分布N(0,1),Y服从χ2(n)分布,那么Z=X/sqrt(Y/n)得分布称为⾃由度为n得t分布,记为 Z~t(n)。
特征:1.以0为中⼼,左右对称得单峰分布;2.t分布就是⼀簇曲线,其形态变化与n(确切地说与⾃由度ν)⼤⼩有关。
第5章 SPSS的参数检验-t检验练习题N

第5章SPSS的参数检验-t检验练习题1、给出配对T检验和两组独立样本分别适用的条件,并叙述其主要操作流程。
2、思考在工作学习中,还有哪些问题与本章案例相似?将它写成本书的案例形式,并给出操作过程和输出结果说明。
3、某学校想要测试一个英语新教学方案的效果,从一个班级中随机抽取15名学生,经过一个学期的教学,其测试前后成绩如下表所示,问该方案是否引起学生成绩的显著变化。
表15名学生测试前后的成绩第5章t检验(参数假设检验)应用练习以数据文件“gd95.xls”(1995年广州市中小学生体质原始数据)的数据为依据。
1、试比较广州市城乡男女7岁学生血红蛋白差异,并说明因此而得到的结果。
【以下是参考案例】复杂格式1(城乡男女7岁学生血红蛋白)男(150人) 女(150人) t值P值城乡13.221±1.05912.130±1.28413.077±1.02712.088±1.1071.195.303P=0.233>0.05P=0.762>0.05t值-8.030 -8.023P值P=0.000<0.05 P=0.000<0.0186说明:由于城市男女7岁学生血红蛋白均值T检验结果P= .23>0.05,差异没有显著性意义,可认为城市男女7岁学生血红蛋白没有差异;同时乡村男女7岁学生血红蛋白均值T检验结果P= .76>0.05,差异没有显著性意义,可认为乡村市男女7岁学生血红蛋白没有差异。
但,城乡7岁男生血红蛋白均值T检验结果P= .00<0.05,有显著性意义,可认为城乡7岁男生血红蛋白有差异;城乡7岁女生血红蛋白均值T检验结果P= .00<0.05,没有显著性意义,可认为城乡7岁男生血红蛋白有差异。
综上所述,7岁学生血红蛋白方面仅仅存在城乡差别而没有性别差异,而且城市学生优于乡村学生。
营养……2、试比较广州市城乡男女8岁、18岁学生下列指标的差异,并说明因此而得到的结果。
张勤主编的生物统计学方面的习题作业及答案

第一章绪论一、名词解释总体个体样本样本含量随机样本参数统计量准确性精确性二、简答题1、什么是生物统计?它在畜牧、水产科学研究中有何作用?2、统计分析的两个特点是什么?3、如何提高试验的准确性与精确性?4、如何控制、降低随机误差,避免系统误差?第二章资料的整理一、名词解释数量性状资料质量性状资料半定量(等级)资料计数资料计量资料二、简答题1、资料可以分为哪几类?它们有何区别与联系?2、为什么要对资料进行整理?对于计量资料,整理的基本步骤怎样?3、在对计量资料进行整理时,为什么第一组的组中值以接近或等于资料中的最小值为好?4、统计表与统计图有何用途?常用统计图、统计表有哪些?第三章平均数、标准差与变异系数一、名词解释算术平均数几何平均数中位数众数调和平均数标准差方差离均差的平方和(平方和)变异系数二、简答题1、生物统计中常用的平均数有几种?各在什么情况下应用?2、算术平均数有哪些基本性质?3、标准差有哪些特性?4、为什么变异系数要与平均数、标准差配合使用?三、计算题1、10头母猪第一胎的产仔数分别为:9、8、7、10、12、10、11、14、8、9头。
试计算这10头母猪第一胎产仔数的平均数、标准差和变异系数。
2、随机测量了某品种120头6月龄母猪的体长,经整理得到如下次数分布表。
试利用加权法计算其平均数、标准差与变异系数。
组别组中值(x)次数(f)80—84 288—92 1096—100 29104—108 28112—116 20120—124 15128—132 13136—140 33、某年某猪场发生猪瘟病,测得10头猪的潜伏期分别为2、2、3、3、4、4、4、5、9、12(天)。
试求潜伏期的中位数。
4、某良种羊群1995—2000年六个年度分别为240、320、360、400、420、450只,试求该良种羊群的年平均增长率。
5、某保种牛场,由于各方面原因使得保种牛群世代规模发生波动,连续5个世代的规模分别为:120、130、140、120、110头。
第8章思考与练习0801217
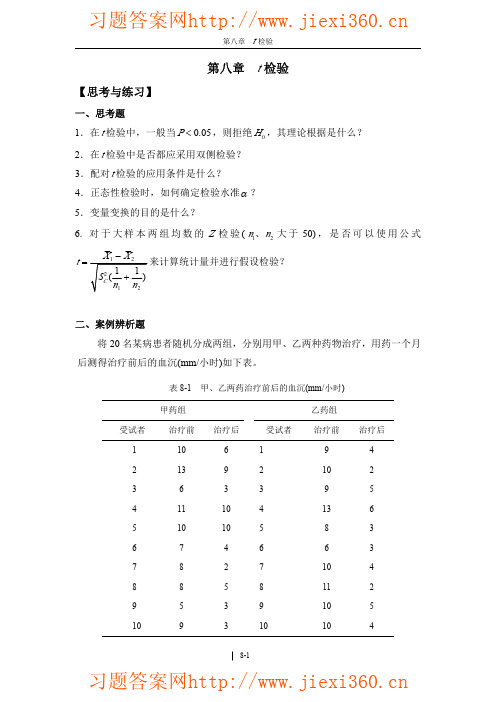
Z KURT = 0.360 1.334 < 1.96 Z KURT = 0.232 1.334 < 1.96
故,甲药,、乙药两组资料的差值 d1、d 2 均服从正态分布。 (2) 方差齐性检验 1) 建立检验假设,确定检验水准
2 ,两差值总体方差相等 H 0 :σ 12 = σ 2
2 ,两差值总体方差不等 H1:σ 12 ≠ σ 2
g d Valid N (listwise) d Valid N (listwise)
Group Statist ic s Std. Error Std. Deviation Mean 1.93218 .61101 1.81353 .57349
g d
N 10 10
Mean 3.2000 5.8000
8-3
习题答案网
习题答案网
第八章
t 检验
7. 为研究两种方法的检测效果,将 24 名患者配成 12 对,采用配对 t 检验进行统 计分析,则其自由度为: A. 24 B. 12 C. 11 D. 23 E. 2 四、综合分析题 1. 大量研究表明健康成年男子脉搏的均数为 72 次/min。某医生在某山区随机调 查了 16 名健康成年男子,测得其脉搏(次/min)资料如下: 69 72 74 68 73 74 80 73 75 74 73 75 74 79 72 74
Z KURT = 1.403 1.334 < 1.96 Z KURT = 0.751 1.334 < 1.96
Z SKEW = 0.088 0.687 < 1.96
故,甲、乙两组资料均服从正态分布。 (2) 假设检验
2 2 由甲、乙两组数据得: X甲 = 5.5, X 乙 = 3.8, S甲 = 3.12 , S乙 = 1.32
t检验及方差分析练习题
采用SPSS统计软件进行操作。
1、某研究者检测了某山区16名健康成年男性的血红蛋白含量(g/L),检测结果见下表。
问:该山区健康成年男性的血红蛋白含量与一般健康成年男性血红蛋白含量的总体均数132 g/L 是否有差别。
编号血红蛋白含量(g/L)1 1452 1503 1384 1265 1406 1457 1358 1159 13510 13011 12012 13313 14714 12515 11416 1652、为研究老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量是否相等,现随机抽取老年慢性支气管炎病人14例和健康人11例,分别测定尿中17酮类固醇排出量,结果见下表。
老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量是否相等?表老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量(mg/24h)病人组健康人组2.90 4.97 5.41 4.24 5.48 4.36 4.60 2.724.03 2.375.10 2.09 5.92 7.10 5.18 5.60 8.79 4.57 3.14 7.716.46 4.99 3.726.644.013、将20名某病患者随机分为两组,分别用甲、乙两药治疗,测得治疗前与治疗后一个月的血沉(mm/小时)如下表。
试问:(1)甲、乙两药是否均有效?(2)甲、乙两药的疗效有无差别?表甲、乙两药治疗前后的血沉(mm/小时)甲药病人号 1 2 3 4 5 6 7 8 9 10 治疗前20 23 16 21 20 17 18 18 15 19 治疗后16 19 13 20 20 14 12 15 13 13 乙药病人号 1 2 3 4 5 6 7 8 9 10 治疗前19 20 19 23 18 16 20 21 20 20 治疗后16 13 15 13 13 15 18 12 17 144、对10例肺癌病人和12例矽肺0期工人用X光片测量肺门横径右侧距RD值(cm),结果见下表。
医药数理统计习题检验假设和t检验

第四章抽样误差与假设检验练习题一、单项选择题1. 样本均数的标准误越小说明A. 观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计总体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大2. 抽样误差产生的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当3. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布4. 假设检验的目的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L~9.1×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%答案:E D C D E二、计算与分析1.为了解某地区小学生血红蛋白含量的平均水平,现随机抽取该地小学生450人,算得其血红蛋白平均数为101.4g/L,标准差为1.5g/L,试计算该地小学生血红蛋白平均数的95%可信区间。
[参考答案]样本含量为450,属于大样本,可采用正态近似的方法计算可信区间。
101.4X=, 1.5S=,450n=,0.07XS===95%可信区间为下限:/2.101.4 1.960.07101.26 XX u Sα=-⨯=-(g/L)上限:/2.101.4 1.960.07101.54 XX u Sα+=+⨯=(g/L)即该地成年男子红细胞总体均数的95%可信区间为101.26g/L~101.54g/L。
t检验

3.对于问题1Spss的实际操作过程
(1) H 0 : 1 2
H1 : 1 2
1)建立数据文件(定义变量,输入数据) 2)选择统计方法:
Analyze-compare mean-Independent Sample T test
3)结果显示
X GROU P A B N
二、 两个正态总体的均值检验与置 信区间
1.实际问题:随机地从A批导线中抽取4根, 从B批导线中抽取5根,测得其电阻为 A批导线:0.143,0.142,0.143,0.137 B批导线:0.140,0.142,0.136,0.138 0.140 测试数据分别服从正态分布
2
X ~ N ( 1 , ),Y ~ N ( 2 , )
3.分析问题 在总体 X ~ N ( , ) 用样本判断
2
(1) H 0 : 100
H1 : 100
X
X 100 100
当H 0: 100成立时,即等价于 与100很接近 X
X 100 | 比较小,则H 0成立,否则不成立 |
即 | X 100 | C时,拒绝H 0
(1) H 0 : 1 2
3.分析问题
H1 : 1 2
(2) P(c 1 2 d ) 95%
X 1 Y 2
X Y 1 2
H 0成立时,等价于| X Y | 很小,否则拒绝 0 H
即 | X Y | C时,拒绝H 0
2
问题:(1)这两批导线的平均电阻是 否有显著性差异?
(2)求
1 2 的95%置信区间。
2.转化为数学问题: 已知信息:总体X ~ N ( 1 , 2 ),样本x1 , x2 ,..., xm
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章:定量资料的参数估计与假设检验基础1抽样与抽样误差抽样方法本身所引起的误差。
当由总体中随机地抽取样本时,哪个样本被抽到是随机的,由所抽到的样本得到的样本指标x与总体指标μ之间偏差,称为实际抽样误差。
当总体相当大时,可能被抽取的样本非常多,不可能列出所有的实际抽样误差,而用平均抽样误差来表征各样本实际抽样误差的平均水平。
σx=σ/Sx=S/2t分布t分布曲线形态与n(确切地说与自由度v)大小有关。
与标准正态分布曲线相比,自由度v越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度v愈大,t分布曲线愈接近正态分布曲线,当自由度v=∞时,t分布曲线为标准正态分布曲线。
t=X-u/Sx=X-u/(S/),V=N-1正态分布(normaldistribution)是数理统计中的一种重要的理论分布,是许多统计方法的理论基础。
正态分布有两个参数,μ和σ,决定了正态分布的位置和形态。
为了应用方便,常将一般的正态变量X通过u变换[(X-μ)/σ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为μ=0,σ=1的标准正态分布(standardnormaldistribution),亦称u分布。
根据中心极限定理,通过上述的抽样模拟试验表明,在正态分布总体中以固定n,抽取若干个样本时,样本均数的分布仍服从正态分布,即N(μ,σ)。
所以,对样本均数的分布进行u 变换,也可变换为标准正态分布N(0,1)由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t值的分布称为t分布。
假设X服从标准正态分布N(0,1),Y服从χ2(n)分布,那么Z=X/sqrt(Y/n)的分布称为自由度为n的t分布,记为Z~t(n)。
特征:1.以0为中心,左右对称的单峰分布;2.t分布是一簇曲线,其形态变化与n(确切地说与自由度ν)大小有关。
自由度ν越小,t分布曲线越低平;自由度ν越大,t分布曲线越接近标准正态分布(u分布)曲线,如图.t(n)分布与标准正态N(0,1)的密度函数对应于每一个自由度ν,就有一条t分布曲线,每条曲线都有其曲线下统计量t的分布规律,计算较复杂。
学生的t分布(或也t分布),在概率统计中,在置信区间估计、显着性检验等问题的计算中发挥重要作用。
t分布情况出现时(如在几乎所有实际的统计工作)的总体标准偏差是未知的,并要从数据估算。
教科书问题的处理标准偏差,因为如果它被称为是两类:(1)那些在该样本规模是如此之大的一个可处理的数据为基础估计的差异,就好像它是一定的(2)这些说明数学推理,在其中的问题,估计标准偏差是暂时忽略的,因为这不是一点,这是作者或导师当时的解释。
3.均数的参数估计可信区间按一定的概率或可信度(1-α)用一个区间来估计总体参数所在的范围,该范围通常称为参数的可信区间或者置信区间,预先给定的概率(1-α)称为可信度或者置信度,常取95%或99%。
1.点估计用样本统计量直接作为总体参数的估计值。
其方法简单,易于理解,但为考虑抽样误差的大小。
2.区间估计既按照预先给定的概率(1-a),确定的包含总体参数的可能范围。
该范围被称为总体参数的可信区间或置信区间。
假设检验基础假设检验的基本思想是小概率反证法思想。
小概率思想是指小概率事件(P<0.01或P<0.05)在一次试验中基本上不会发生。
反证法思想是先提出假设(检验假设H0),再用适当的统计方法确定假设成立的可能性大小,如可能性小,则认为假设不成立,若可能性大,则还不能认为不假设成立。
[2]假设检验假设是否正确,要用从总体中抽出的样本进行检验,与此有关的理论和方法,构成假设检验的内容。
设A是关于总体分布的一项命题,所有使命题A成立的总体分布构成一个集合h0,称为原假设(常简称假设)。
使命题A不成立的所有总体分布构成另一个集合h1,称为备择假设。
如果h0可以通过有限个实参数来描述,则称为参数假设,否则称为非参数假设(见非参数结果)。
如果h0(或h1)只包含一个分布,则称原假设(或备择假设)为简单假设,否则为复合假设。
对一个假设h0进行检验,就是要制定一个规则,使得有了样本以后,根据这规则可以决定是接受它(承认命题A正确),还是拒绝它(否认命题A正确)。
这样,所有可能的样本所组成的空间(称样本空间)被划分为两部分HA和HR(HA的补集),当样本x∈HA时,接受假设h0;当x∈HR时,拒绝h0。
集合HR常称为检验的拒绝域,HA称为接受域。
因此选定一个检验法,也就是选定一个拒绝域,故常把检验法本身与拒绝域HR基本步骤1、提出检验假设又称无效假设,符号是H0;备择假设的符号是H1。
H0:样本与总体或样本与样本间的差异是由抽样误差引起的;H1:样本与总体或样本与样本间存在本质差异;预先设定的检验水准为0.05;当检验假设为真,但被错误地拒绝的概率,记作α,通常取α=0.05或α=0.01。
2、选定统计方法,由样本观察值按相应的公式计算出统计量的大小,如X2值、t值等。
根据资料的类型和特点,可分别选用Z检验,T检验,3、根据统计量的大小及其分布确定检验假设成立的可能性P的大小并判断结果。
若P>α,结论为按α所取水准不显着,不拒绝H0,即认为差别很可能是由于抽样误差造成的,在统计上不成立;如果P≤α,结论为按所取α水准显着,拒绝H0,接受H1,则认为此差别不大可能仅由抽样误差所致,很可能是实验因素不同造成的,故在统计上成立。
P值的大小一般可通过查阅相应的界值表得到。
t检验若总体服从正态分布N(μ,σ),但σ未知,记,,则t=遵从自由度为n-1的t分布,可对μ有以下的水平为α的检验,其中tα为自由度为n-1的t分布的上α分位数。
这些检验称为t检验。
第五章:定量资料的t检验前言:T检验主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显着。
一、t检验分为单总体检验和双总体检验。
1.单总体t检验是检验一个样本平均数与一个已知的总体平均数的差异是否显着。
当总体分布是正态分布,如总体标准差未知且样本容量小于30,那么样本平均数与总体平均数的离差统计量呈t分布。
单总体t检验统计量为:t:为样本平均数与总体平均数的离差统计量:为样本平均数μ:为总体平均数σx:为样本标准差n:为样本容量2.双总体t检验是检验两个样本平均数与其各自所代表的总体的差异是否显着。
双总体t检验又分为两种情况,一是独立样本t检验,一是配对样本t检验。
独立样本t检验统计量为:S 1和S2为两、样本方差;n1和n2为两样本容量。
(上面的公式是1/n1+1/n2不是减!)1/n1-1/n2的话无法计算相同的样本空间配对样本t检验统计量为:二、适用条件(1)已知一个总体均数;(2)可得到一个样本均数及该样本标准差;(3)样本来自正态或近似正态总体。
三、t检验步骤以单总体t检验为例说明:问题:难产儿出生体重n=35,=3.42,S=0.40,一般婴儿出生体重μ=3.30(大规模调查获得),问相同否?解:1.建立假设、确定检验水准αH:μ=μ0(零假设,nullhypothesis)H1:μ≠μ0(备择假设,alternativehypothesis,)双侧检验,检验水准:α=0.052.计算检验统计量3.查相应界值表,确定P值,下结论查附表1,t0.05/2.34=2.032,t<t0.05/2.34,P>0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义当总体呈正态分布,如果总体标准差未知,而且样本容量<30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t分布。
检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显着。
检验分为单总体t检验和双总体t检验。
四、t检验注意事项1、选用的检验方法必须符合其适用条件(注意:t检验的前提是资料服从正态分布)。
理论上,即使样本量很小时,也可以进行t检验。
(如样本量为10,一些学者声称甚至更小的样本也行),只要每组中变量呈正态分布,两组方差不会明显不同。
如上所述,可以通过观察数据的分布或进行正态性检验估计数据的正态假设。
方差齐性的假设可进行F检验,或进行更有效的Levene's检验。
如果不满足这些条件,只好使用非参数检验代替t检验进行两组间均值的比较。
2、区分单侧检验和双侧检验。
单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ错误的可能性大。
t检验中的p值是接受两均值存在差异这个假设可能犯错的概率。
在统计学上上,当两组观察对象总体中的确不存在差别时,这个概率与我们拒绝了该假设有关。
一些学者认为如果差异具有特定的方向性,我们只要考虑单侧概率分布,将所得到t-检验的P值分为两半。
另一些学者则认为无论何种情况下都要报告标准的双侧t检验概率。
3、假设检验的结论不能绝对化。
当一个统计量的值落在临界域内,这个统计量是统计上显着的,这时拒绝虚拟假设。
当一个统计量的值落在接受域中,这个检验是统计上不显着的,这是不拒绝虚拟假设H0。
因为,其不显着结果的原因有可能是样本数量不够拒绝H0,有可能犯第Ⅰ类错误。
4、正确理解P值与差别有无统计学意义。
P越小,不是说明实际差别越大,而是说越有理由拒绝H0,越有理由说明两者有差异,差别有无统计学意义和有无专业上的实际意义并不完全相同。
5、假设检验和可信区间的关系结论具有一致性差异:提供的信息不同区间估计给出总体均值可能取值范围,但不给出确切的概率值,假设检验可以给出H0成立与否的概率。
6、涉及多组间比较时,慎用t检验。
科研实践中,经常需要进行两组以上比较,或含有多个自变量并控制各个自变量单独效应后的各组间的比较,(如性别、药物类型与剂量),此时,需要用方差分析进行数据分析,方差分析被认为是T检验的推广。
在较为复杂的设计时,方差分析具有许多t-检验所不具备的优点。
(进行多次的T检验进行比较设计中不同格子均值时)。
第六章定量资料的方差分析6.1方差分析的基本思想和应用条件1.总变异各样本数值与总均数不同。
总变异反映所有观察值的变异,量化值所有数据的均方MS总来表示。
SS总=Σ(X-?)2MS总=SS总/v总v总=N-12.组间变异各组别间的均数不相同。
包括了变量影响和随机误差。
SS组间=Σn i(?i-?)2MS组间=SS组间/v组间v组间=k-1 3.组内变异组内的个数值不同。
反映随机误差,又称误差变异。
SS组内=SS总-SS组间MS组内=SS组内/v组内V组内=N-kF=MS组间/MS组内1、各样本相互独立切随机,服从正态分布。
2、总体方差相等,即方差齐性。
6.2完全随机设计资料的方差分析(1)建立假设检验,确定检验水准。