计量经济学数据建模分析
计量经济学模型分析
农村居民消费水平影响因素分析摘要中国是一个农业大国,农民占总人口的大部分,农村居民的消费在国民消费总量中占有很大比重,农村居民的消费水平对整个国名经济的发展有重大的作用。
随着改革开放的深入及各项支农惠农政策的实施,农村居民的生活水平有了很大提高,面对农村这个巨大的消费市场,如何提高农村居民的消费水平就成了扩大内需、拉动经济所面对的重大问题。
本文运用计量经济学的方法,就农村居民的消费水平的主要影响因素进行了简单的分析。
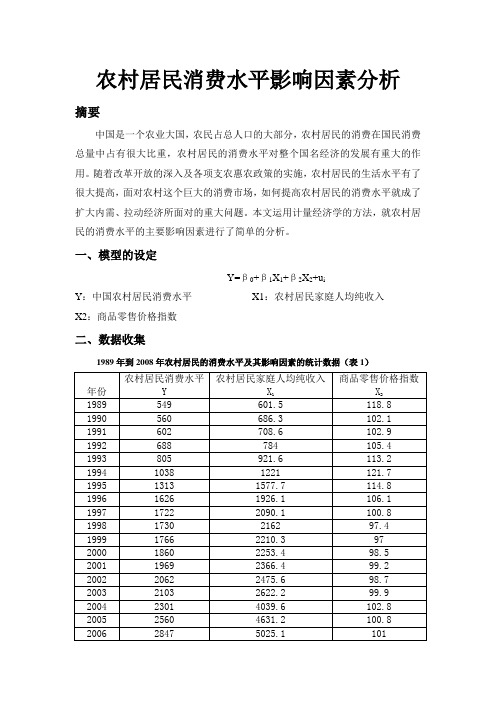
一、模型的设定Y=β0+β1X1+β2X2+u iY:中国农村居民消费水平X1:农村居民家庭人均纯收入X2:商品零售价格指数二、数据收集1989年到2008年农村居民的消费水平及其影响因素的统计数据(表1)三、散点图为分析“农村居民消费水平”Y与“农村居民家庭人均纯收入”X1和“商品零售价格指数”X2之间的关系,做如下散点图:从散点图可以看出,农村居民消费水平(Y)和农村居民家庭人均纯收入(X1)大体呈现为线性关系,农村居民消费水平(Y)和商品零售价格指数(X2)大体呈现为线性关系。
β0表示在没有任何因素影响下的农村居民消费水平;β1表示农村居民家庭人均纯收入对农村居民消费水平的影响;β2表示商品零售价格指数对农村居民的消费水平的影响;u i为随机扰动项。
四、回归分析Y^= 2020.904 + 0.477598X1 -14.13053X2(738.1351)(0.027251)(6.818890)t =(2.737851)(17.52564)(-2.072263)R2 = 0.955580 F = 182.8554 n = 20五、模型检验(一)经济意义检验所估计的参数β^1 =0.477598,β^ 2 = -14.13053,且0<β1<1,β2<0,符合变量参数中确定的参数范围。
说明农村居民家庭人均纯收入每增加1单位,平均说来可导致农村居民消费水平增加0.477598单位;商品零售价格指数每减少1单位,平均说来可导致农村居民消费水平增加14.13053单位。
计量建模的使用和技巧

计量建模的使用和技巧计量建模是指在计量经济学领域中,使用统计工具对数据进行建模和分析的方法。
它主要用于研究经济现象之间的关系和预测未来的变化。
计量建模的使用范围非常广泛。
在经济学中,它被用于衡量经济变量之间的关系,如消费与收入、利率与投资等。
在金融学中,它用于预测股票价格变动、汇率波动等。
在市场营销中,它可以帮助企业分析产品销售数据,并预测未来的需求。
在医学领域,它可以帮助研究者发现某种药物对疾病的治疗效果。
总之,计量建模可以应用于几乎所有需要对数据进行分析的领域。
下面将介绍一些计量建模的常用技巧。
首先,了解数据的特征是非常重要的。
在进行建模之前,我们需要对数据的属性、分布和相关性有一定的了解。
这样可以帮助我们选择适当的模型和变量,确保模型的有效性。
其次,我们需要选择合适的模型。
常见的计量建模模型包括线性回归模型、时间序列模型、面板数据模型等。
在选择模型时,我们要在理论和实践之间寻找平衡,根据数据的特点和研究目的选择适当的模型。
接着,我们需要选择合适的变量。
选择合适的变量对于模型的准确性和解释力至关重要。
一般来说,我们应该选择与研究问题相关的变量,并且排除不相关的变量。
此外,变量之间也应该尽量避免多重共线性,以避免结果的偏误。
然后,我们需要进行模型检验。
模型检验可以帮助我们评估模型的拟合度和稳健性。
常用的模型检验方法包括残差分析、异方差检验、多重共线性检验等。
通过模型检验,我们可以发现模型中存在的问题,并进行相应的修正和改进。
最后,我们需要进行模型解释和预测。
模型解释可以帮助我们理解变量之间的关系,发现影响因素和机理,为政策制定和决策提供参考。
模型预测可以帮助我们对未来的变化进行预测,提前做出相应的准备和应对。
在应用计量建模的过程中,我们还需要注意一些常见的问题和挑战。
首先,我们要警惕因果关系的混淆。
虽然计量建模可以帮助我们发现变量之间的关系,但并不能确定其因果关系。
因此,在解释模型结果时,我们需要慎重考虑可能存在的潜在因果关系。
计量经济学建模案例

计量经济学建模案例在计量经济学中,建模是一项非常重要的工作。
通过建立合适的模型,我们可以对经济现象进行定量分析,揭示经济规律,为政策制定和预测提供有力的支持。
下面,我们将通过一个实际的案例来介绍计量经济学建模的过程。
首先,我们需要确定研究的问题。
在这个案例中,我们关注的是劳动力市场对经济增长的影响。
我们希望通过建立一个模型,来分析劳动力市场的变化对经济增长的影响程度。
接下来,我们需要收集相关数据。
在这个案例中,我们需要收集劳动力市场的就业率、失业率、劳动生产率等数据,以及经济增长率、投资率、消费率等数据。
这些数据可以通过国家统计局、国际组织的数据库等渠道获取。
然后,我们需要选择合适的模型。
在这个案例中,我们可以选择使用计量经济学中的时间序列模型,如VAR模型、ARIMA模型等,来分析劳动力市场和经济增长之间的关系。
我们还可以考虑使用面板数据模型,来控制个体和时间的固定效应。
接着,我们需要进行模型估计和检验。
在这个案例中,我们可以利用计量经济学中的OLS回归、固定效应模型、随机效应模型等方法,对模型进行估计,并进行参数显著性检验、模型拟合优度检验等。
最后,我们需要进行模型的解释和政策建议。
通过对模型的估计结果进行分析,我们可以得出劳动力市场对经济增长的影响程度,进而提出相应的政策建议,如促进就业、提高劳动生产率等。
通过以上案例,我们可以看到计量经济学建模的基本流程,确定研究问题、收集数据、选择模型、估计检验、解释政策建议。
在实际应用中,我们还需要根据具体问题灵活运用各种模型和方法,以期得出准确可靠的分析结论。
总之,计量经济学建模是一项复杂而又重要的工作。
通过建立合适的模型,我们可以更好地理解经济现象,为政策制定和预测提供有力的支持。
希望本文的案例分析能够对读者有所启发,进一步深入学习和应用计量经济学建模方法。
计量经济学数据分析实验报告
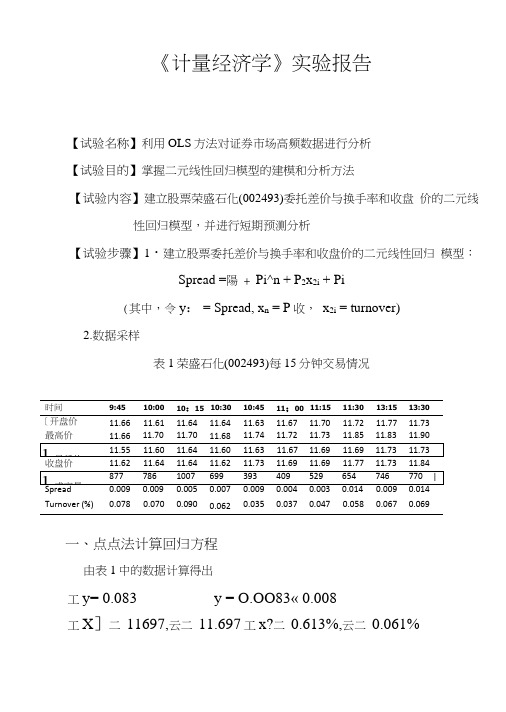
《计量经济学》实验报告【试验名称】利用OLS方法对证券市场高频数据进行分析【试验目的】掌握二元线性回归模型的建模和分析方法【试验内容】建立股票荣盛石化(002493)委托差价与换手率和收盘价的二元线性回归模型,并进行短期预测分析【试验步骤】1・建立股票委托差价与换手率和收盘价的二元线性回归模型:Spread =陽 + Pi^n + P2x2i + Pi(其中,令y: = Spread, x n = P收,x2i = turnover)2.数据采样表1荣盛石化(002493)每15分钟交易情况一、点点法计算回归方程由表1中的数据计算得出工y= 0.083 y = O.OO83« 0.008工X]二11697,云二11.697工x?二0.613%,云二0.061%(1) 编制工作表■ yx 2(%)• *> y_• • x :yX1X 2 0.001 -0.077 0.017 O.lxlO"55.9xl0~32 9x10"® 一7 7x10* 1.7x10“ -1.3xl0-5 0.001 -0.057 0.009 lxlO -6 3.2 xlO -38.1X10-9 -5.7xl0T9.0 xlO -8 -5.1x10^ 0003 -0.057 0.029 9x10^3.2x10^ 84x1 (T 81.7X1CT 4-8.7x10“ -1.7xlO -5 -0.001 -0.077 0.001 1x10"5.9x10-3lxlO -107.7 xlO -5 -l.OxlO -8 -7.7xl0? 0.001 0.033-0.026 lxlO -61.1x10-36 8x10"®3.3 xlO -5 -2.6x1 O'7 -8.6x1 OY ・0.004 -0.007 -0.024 1.6 xlO" 4.9 xlO -3 5.8X10-82.8x29.6x10-7 1.7x10“ -0.005 -0.007 -0.014 2.5 xlO -5 4.9 xlO -32.0 xW 83.5x10-5 7.0x10-7 9.8x10-7 | 0.006 0.073 •0.003 3 6x10*5.3x10—3 9xlO -10 4.4x107-1.8x10—7 -2.2x10“ 0.001 0.0330.006 lxlO^51.1 X 1 0"3 3.6 xlO -93 3x10*6X10-8 2.0 xlO -6 0.006 0.1430.0083.6 xlO"50.026 4x10"86x10*4.8 xlO"7l.lxlO"5(2) Ik 算统计量(3) 计算久、Dj 、D 2(4) 得出参数估计值A = —= 3.5xl0'3 Doa-y-\ • 0i — x? • 0? = -0.405综上所得,回归方程为:X =0.035x h +4.3x 21-0.405二、模型分析 (1)经济意义检验模型估计的结果说明,在假定其他变量不变的情况下,当收盘 价每增长1s ^=Ey2= 127x10-4S R =工£ =3.68x10“Sy?=工禺 y = 114x10"% =工衬=4.58xl0"2=x^y =L54x10'3 $2 =工若禺=-1.26xl0-5D.=S H %= 1.66x10“= 7.16xl0"s= 5.8xlO"10S“■ ■% S"元,委托差价(Spread)就会增长0.035元;在假定其他变量不变的情况下,当换手率(turnover)增长1个百分点时,委托差价(Spread)就会增长4.3元。
计量经济学模型应用分析

计量经济学模型应用分析计量经济学是一门以数据为基础,运用数学、统计学和经济学等相关学科分析和解释经济现象的学科。
在实践中,计量经济学主要通过建立各种经济模型来分析和预测现实经济问题。
在本文中,我们将探讨计量经济学模型的应用分析。
一、单因素模型单因素模型是一种简单的计量经济学模型,其特点是只考虑一个因素对经济变量的影响。
例如,研究公路通行费对公路使用量的影响,或者研究利率对消费者支出的影响。
在这种模型中,经济变量(因变量)被解释为一个单独的影响因素(自变量)的函数。
通常,单因素模型采用线性回归来描述变量之间的关系。
回归模型的基本形式为:Y= a + bX + ε其中,Y是因变量(例如,需求或价格),X是自变量(例如,收入或成本),a和b是常数,ε是误差项(通常性质是随机的)。
a反映了Y在X=0时的值,b反映了Y随X的变化。
单因素模型在经济学实践中应用广泛。
例如,研究收入水平对消费支出的影响,研究通货膨胀率对股票价格的影响,以及研究贸易政策对贸易流量的影响。
单因素模型提供了一个可靠的方法来评估影响因素对因变量的影响程度。
二、多重线性回归模型多重线性回归模型是一种计量经济学模型,它允许解释因变量在多个自变量(或因素)下的变化。
该模型的形式为:Y= a + b1X1 + b2X2 +......+ bnXn + ε在此模型中,Y是因变量,X1、X2、...、Xn是自变量(或因素),a、b1、b2等是回归系数,ε是观测误差。
回归系数反映了因变量与自变量之间的关系。
具体而言,回归系数越大,自变量对因变量的影响越大。
多重线性回归模型具有广泛的应用范围。
例如,它可以用于研究成本对价格的影响,对劳动力市场的影响以及对经济增长的影响。
此外,多重线性回归模型还可以用于评估因素之间的相互作用,这是单因素模型无法实现的。
三、时间序列模型时间序列模型是一种专门用于描述和预测时间序列数据的计量经济学模型。
时间序列数据是指按时间顺序收集的数据。
计量经济学建模案例

计量经济学建模案例计量经济学是一种运用数学和统计方法对经济现象进行定量分析的方法,可以帮助经济学家解释和预测经济现象,并制定相应的政策。
下面是一种计量经济学建模案例:假设我们要研究某个城市的房价与房屋面积之间的关系。
我们可以使用多元线性回归模型来建模,其中自变量是房屋面积,因变量是房价。
为了使模型更加准确,我们还可以引入其他可能影响房价的变量,如地理位置、房屋年龄、房屋类型等。
首先,我们需要收集相关的数据。
我们可以通过调查和市场价格来获得房屋面积、房价以及其他相关变量的数据。
假设我们收集了100个样本数据来建立模型。
接下来,我们需要进行数据的预处理。
这包括数据清洗、缺失值处理、异常值处理等。
我们可以使用统计软件进行数据处理和分析。
然后,我们可以使用多元线性回归模型来建立房价与房屋面积以及其他相关变量之间的关系。
模型的形式可以表示为:房价= β0 + β1 × 房屋面积+ β2 × 地理位置+ β3 × 房屋年龄 +β4 × 房屋类型+ ε其中,β0、β1、β2、β3、β4是模型的回归系数,表示不同变量对房价的影响程度。
ε是误差项,表示模型无法解释的部分。
接着,我们可以使用最小二乘法估计回归系数,并进行统计显著性检验和模型拟合度检验。
这可以帮助我们判断模型的准确性和可解释性。
最后,我们可以使用估计的回归模型来进行预测和分析。
通过对模型的解释和系数的分析,我们可以得出不同变量对房价的影响程度,并制定相应的政策措施。
总之,计量经济学建模能够帮助我们理解和预测经济现象,对于研究者和政策制定者具有重要意义。
以上是一个简单的计量经济学建模案例,实际的建模过程可能更加复杂,需要根据具体问题进行相应的分析和处理。
经济统计学中的统计建模方法
经济统计学中的统计建模方法统计建模是经济统计学中的重要方法之一,它通过对经济数据的分析和建模,帮助我们理解经济现象、预测未来趋势以及制定政策。
本文将介绍几种常见的经济统计学中的统计建模方法,并探讨其应用和局限性。
一、线性回归模型线性回归模型是经济统计学中最常用的建模方法之一。
它假设因变量与自变量之间存在线性关系,并通过最小二乘法来估计模型参数。
线性回归模型可以用来研究变量之间的因果关系,例如GDP与消费之间的关系、利率与投资之间的关系等。
然而,线性回归模型的一个局限是它对数据的线性关系假设过于简单,无法捕捉到非线性关系和复杂的相互作用。
二、时间序列模型时间序列模型是研究时间上连续观测数据的统计方法。
它假设数据的观测值之间存在某种时间依赖关系,可以用来预测未来的趋势和周期性。
常见的时间序列模型包括自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)等。
时间序列模型在经济学中的应用广泛,例如预测股票价格、通货膨胀率等。
然而,时间序列模型的一个局限是它对数据的平稳性假设较为严格,无法处理非平稳时间序列数据。
三、面板数据模型面板数据模型是同时考虑时间和个体(如国家、企业)维度的统计方法。
它可以用来研究个体间的异质性以及时间上的变化趋势。
面板数据模型常用的方法有固定效应模型和随机效应模型。
固定效应模型假设个体间存在固定的差异,而随机效应模型则假设个体间的差异是随机的。
面板数据模型在经济学中的应用广泛,例如研究教育对收入的影响、贸易对经济增长的影响等。
然而,面板数据模型的一个局限是它对数据的异质性和相关性的假设较为严格,可能存在内生性问题。
四、计量经济学方法计量经济学是经济学与数理统计学的交叉领域,主要研究经济理论的实证检验和政策评估。
计量经济学方法包括工具变量法、差分法、倾向得分匹配法等。
这些方法通过解决内生性和选择性偏误等问题,提高了经济统计建模的可靠性。
计量经济学方法在经济学研究中的应用广泛,例如评估教育政策的效果、估计劳动力市场的供需关系等。
计量经济学建模案例
计量经济学建模案例计量经济学是经济学的一个重要分支,它运用数理统计、数学经济学和经济计量学的方法,对经济现象进行定量分析和研究。
计量经济学建模是计量经济学的一个重要环节,通过建立合适的模型来对经济现象进行描述、预测和政策分析。
本文将通过一个实际的案例,介绍计量经济学建模的基本步骤和方法。
首先,我们需要确定研究的目的和问题。
在实际研究中,我们通常会针对某一经济现象或政策进行研究,比如通货膨胀对经济增长的影响。
在确定研究问题后,我们需要收集相关的数据,这些数据通常包括宏观经济指标、产业数据、企业调查数据等。
在收集数据时,我们需要注意数据的质量和可靠性,确保数据的准确性和完整性。
接下来,我们需要对收集的数据进行描述性统计分析。
描述性统计分析可以帮助我们了解数据的分布特征、相关性和变化趋势,为后续的建模分析提供基础。
在描述性统计分析的基础上,我们可以利用计量经济学的方法,建立相应的经济模型。
比如,我们可以运用回归分析的方法,来探讨通货膨胀率对经济增长的影响,建立相应的经济增长模型。
建立模型后,我们需要进行模型的估计和检验。
模型的估计可以通过最小二乘法等方法来进行,通过估计得到的参数,我们可以对模型的拟合效果进行评估。
同时,我们还需要对模型的假设进行检验,确保模型的有效性和可靠性。
在估计和检验的基础上,我们可以对模型进行修正和改进,以提高模型的解释能力和预测精度。
最后,我们需要对建立的模型进行政策分析和预测。
通过建立的模型,我们可以对不同政策措施的影响进行评估和预测,为政策制定提供决策支持。
比如,我们可以利用建立的经济增长模型,来评估不同通货膨胀率下的经济增长效果,为货币政策的制定提供参考。
综上所述,计量经济学建模是一个系统的过程,需要从确定研究问题、数据收集、描述性统计分析、模型建立、模型估计和检验、政策分析和预测等多个环节进行。
通过本文的案例介绍,希望读者能够对计量经济学建模有一个清晰的认识,为实际研究和应用提供参考。
趋势与季节调整分析案例 计量经济学 EVIEWS建模课件
调整模型的形式初判
根据如下图示可以看出这十年间的CPI有明显的
趋势和三个长周期,由于是月份资料很可能存在着
季节波动的因素。同时因为图示的不平滑及波幅较
大,可以初步判断是一个乘法模型。
全国CPI
107 106 105 104 103 102 101 100
残差的单位根检验
通过残差的上述检验说明模型较好,基本符合 残差的最主要假设的要求。
残差的自相关图
该检验说明了静态模型的缺点。
YFT = 0.984 + 0.00045*T + C(i) + S(j) 其中:循环阶段i和j的确定,取决于如下两个函数:
i = T - 40*@FLOOR((T-1)/40); j = T - 12*@FLOOR((T-1)/12); 其中@FL00R(X)为X的取整函数。如: 当T=85时:CPIF120 = 0.984 + 0.00045×85 + C(5) + S(1)
31~40 1.006653 1.005229 1.005072 1.004243 1.014944 1.020676 1.020225 1.018706 1.023185 1.024111
短周期季节性波动的测量
⑴计算的基础数据 以YCSI/YC = YSI的数据,它只含有季节因素和随机 波动,如图所示:
循环比率数据表
11~20 0.992458 0.989409 0.987656 0.988845 0.986716 0.986565 0.987099 0.983423 0.985342 0.987524
21~30 0.992047 0.991942 0.991182 0.991706 0.993605 0.994539 0.993358 0.996803 0.995763 1.001225
计量经济学建模与分析
计量经济学建模与分析一、研究问题我国1998年各地区城镇居民平均每人全年家庭可支配收入与交通和通讯支出之间的相关性。
二、建立模型以我国1998年各地区城镇居民平均每人全年家庭交通和通讯支出(Y)为被解释变量,我国1998年各地区城镇居民平均每人全年家庭可支配收入(X)为解释变量,进行分析。
建立一元线性回归模型:Y =β1+β2X+μ其中:Y代表各地区城镇居民平均每人全年家庭交通和通讯支出(元);X代表各地区城镇居民平均每人全年家庭可支配收入(元);μ为随机干扰项。
三、估计参数利用普通最小二乘法,根据上表数据,可估计出该回归方程为:2. .6(45.9411)(0.0079)( 1.0464)(7.1461)0.739451.0672i ieY t F XSR∧=-+==-==4807220056四、 检验模型由于地区之间存在不同的人均可支配收入,因此各个地区家庭交通和通讯支出也会有所不同,这种差异使得模型很容易产生异方差。
故作出残差图如下:通过分析残差图可大致判断该模型很可能存在异方差。
但是否确实存在异方差还应通过更进一步的检验:22120122222220.050.05=+++14.788,=0.05=14.788=,i in n e v X X R R ααααχχχχ==>运用怀特检验,因为本例为一元回归,故无交叉乘积项,则相应的辅助回归为 由怀特检验知,在的情况下,查分布表,得临界值(2)5.9915。
比较计算的统计量与临界值,因为(2)5.9915所以拒绝原假设,表明模型存在异方差。
现运用加权最小二乘法来1/1/1/i i i ie w w X ===消除异方差,分别取权数,,得到估计结果分别如式(1)(2)(3)233.9985.40(1)(37.7364)(0.0075)(0.9009)(7.2209)0.0431=1.744152.1411i i eY t DW F X SR∧=-+==-==005229.0684 .29(2)(38.7023)(0.0083)(0.7511)(6.3688)0.7350=2.133140.5617i i eY t DW F X SR∧=-+==-==005235.0684 .40(3)(3.7056)(0.0074)(9.4639)(73.0966)0.9998=2.50755343.106i i eY t DW F X SR∧=-+==-==00532220.053.1047,= 3.1047(2) 5.9915,t F n n w R R αχ==<= 比较上面三种回归结果,发现用权数的效果最好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学数据建模分析
一、研究意义
试找出对外承包合同金额和外汇储备量二者与实际利用外资情况之间的关系,特此搜集了1985年至2011年的相关数据,来进一步分析三者的关系,即对外承包合同金额和外汇储备量对于实际利用外资情况有何影响。
二、计量模型分析
(一)变量的选取
影响实际利用外资情况的变量很多,在此只通过对外承包合同金额和外汇储备量这两个变量来进行分析影响实际利用外资情况的因素。
(二)理论模型的建立
建立一个二元的线性回归模型,即Y=β
0+β
1
X
1
+β
2
X
2
+μ
Y:实际利用外资情况;
X
1
:对外承包工程合同金额;
X
2
:外汇储备量。
通过这个建模来分析对外承包合同金额和外汇储备量对于实际利用外资情况的影响。
(三)数据收集
该数据选自于中国国家统计局的统计年鉴,并按照时间序列进行排列,数据完整、精准、可靠。
年份对外承包工程合同金额外汇储备量实际利用外资情况1985 11.16 26.44 47.60
1986 11.89 20.72 76.28
1987 16.48 29.23 84.52
1988 18.13 33.72 102.26 1989 22.12 55.50 100.60 1990 26.04 110.93 102.89 1991 36.09 217.12 115.54 1992 65.85 194.43 192.03 1993 68.00 211.99 389.60 1994 79.88 516.20 432.13 1995 96.72 735.97 481.33 1996 102.73 1050.29 548.05
1997 113.56 1398.90 644.08 1998 117.73 1449.59 585.57 1999 130.02 1546.75 526.59 2000 149.43 1655.74 593.56 2001 164.55 2121.65 496.72 2002 178.91 2864.07 550.11 2003 209.30 4032.51 561.40 2004 276.98 6099.32 640.72 2005 342.16 8188.72 638.05 2006 716.48 10663.40 670.76 2007 853.45 15282.49 783.39 2008 1130.15 19460.30 952.53 2009 1336.82 23991.52 918.04 2010 1430.92 28473.38 1088.21 2011 1423.32 31811.48 1176.98
(四)参数估计
假定所建模型及随机扰动项μ满足古典假定,可以用普通最小二乘法OLS来估计其参数,运用Eviews软件做计量经济分析,回归结果如图:
Dependent Variable: Y
Method: Least Squares
Date: 05/14/13 Time: 15:25
Sample: 1985 2011
Included observations: 27
Variable Coefficient Std. Error t-Statistic Prob.
C 307.5122 46.23063 6.651697 0.0000
X1 0.476315 0.527375 0.903181 0.3754
X2 0.005230 0.026276 0.199035 0.8439
R-squared 0.718381 Mean dependent var 499.9830
Adjusted R-squared 0.694912 S.D. dependent var 320.4771
S.E. of regression 177.0147 Akaike info criterion 13.29478
Sum squared resid 752020.6 Schwarz criterion 13.43876
Log likelihood -176.4795 Hannan-Quinn criter. 13.33759
F-statistic 30.61072 Durbin-Watson stat 0.202864
Prob(F-statistic) 0.000000
(五)统计检验
1、拟合优度检验
在本组数据中,R2=0.718381,调整后的可决系数R2=0.694912,表明模型拟合程度较好,对外承包合同金额和外汇储备量二者与实际利用外资情况之间确实存在线性关系。
2、T检验
|T1|=0.903181|T2|=0.199035,在给定显著性水平α=0.05,查t分
(24)=2.064,可见,两个布表中自由度为24的相应临界值,得到t
α/2
变量的T值都小于该临界值,所以接受原假设,即模型中引入的两个解释变量都在95%的水平下影响并不显著,没有通过变量的显著性检验。
3、F检验
运用Eviews软件计算得出F=30.61072,给定显著性水平α=0.05,查F分布表,得到临界值F0.05,(2,24)=3.40,显然有F>Fα(k, n-k-1),表明该模型的线性关系在95%的置信水平下显著成立。
4.D.W.检验
由于D.W.=0.202864,给定显著性水平α=0.05,查D.W.分布表,
D L=1.27 ,D U=1.45,因为0<D.W.= 0.202864<D L,所以存在正自相关。
三、结论
对于所建的二元线性回归模型中不难看出,对外承包合同金额和外汇储备量二者与实际利用外资情况之间存在着正相关的线性关系。
二者金额的增加都会导致实际利用外资情况的增加,这种关系是合理的。
因为实际利用外资情况本来就是通过对外承包合同、外汇储备以及其他诸多因素变量的变动所变化的。
随着时间的推移,我国对外经济贸易的发展呈现出良好的态势,从而使得实际利用外资的情况逐年增长,其中体现于对外承包合同金额和外汇储备量的逐年增长。
这种正相关的关系会带动整个经济的逐年发展。