编译原理第七章 中间代码生成(1)
07-第7章-中间代码生成-编译原理PDF精讲课件-中国科技大学(共13讲)

中国科学技术大学 计算机科学与技术学院 陈意云
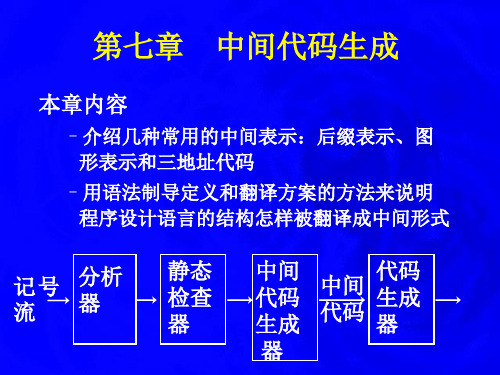
第七章 中间代码生成
记号 分析 流 器 本章内容
–介绍几种常用的中间表示:后缀表示、图形表示 和三地址代码 –用语法制导定义和翻译方案来说明源语言的各种 构造怎样被翻译成中间形式
静态 检查 器
中间 代码 中间 代码 生成 代码 生成 器 器
7.1 中 间 语 言
7.1.2 图形表示 • 语法树是一种图形化的中间表示 • 有向无环图也是一种中间表示
assign a + + a assign +
+ c uminus d uminus c c d d b b (b) DAG (a) 语法树 a = (b + cd) + cd的图形表示
7.1 中 间 语 言
7.1.4 静态单赋值形式 • 一种便于某些代码优化的中间表示 • 和三地址代码的主要区别
– 所有赋值指令都是对不同名字的变量的赋值 – 一个变量在不同路径上都定值的解决办法 if (flag) x = 1; else x = 1; y = x a; 改成 if (flag) x1 = 1; else x2 = 1; x3 = (x1, x2); //由flag的值决定用x1还是x2
E E1 E2 E.nptr = mkNode( ‘’, E1.nptr, E2.nptr) E.nptr = mkUNode( ‘uminus’, E1.nptr) E E1 E (E1) F id E.nptr = E1.nptr E.nptr = mkLeaf (id, id.entry)
符号表实例
7.2 声 明 语 句
• 符号表的特点
–各过程有各自的符号表 –符号表之间有双向链 –构造符号表时需要符号表栈 –构造符号表需要活动记录栈 sort var a:…; x:…; readarray var i:…; exchange quicksort var k, v:…; partition var i, j:…;
编译原理课件-第7章中间代码生成

● example
例2 suppose the function f has been defined in C as in the previous example. Then, the call
f ( 2+3, 4) 请写出the call三地址码。
解: translates to the three-address code begin_args t1 = 2 + 3 arg t1 arg 4 call f
2023/6/1
● If Statements if ( E ) S1 else S2
Three-Address Code :
If语句前的代码 If测试的代码
<code to evaluate E to t1>
条件
if_false t1 goto L1
<code for S1> goto L2
True情况下的代码
(sub, x, 1, t3 ) (asn, t3, x, _ ) (eq, x, 0, t4 ) (if_f, t4, L2, _) (wri, fact, _, _ ) (lab, L1, _ , _ ) halt, _, _, _ )
2023/6/1
例2 请写出TINY program三地址码的三元式表示。
7.4 Code Generation of Procedure and Function Calls 过程 和函数调用的代码生成
2023/6/1
7.1 Intermediate Code and Data Structures for Code Generation 中间代码和用于代码生成的数据结构
{ AddrKind kind; Union
编译原理 第七章——语义分析和中间代码生成

中间语言
常见的中间语言的形式: 后缀式(逆波兰式) 三地址代码 - 三元式 - 四元式 - 间接三元式 DAG图
后缀式
又称逆波兰表示法,把运算量(操作数)写在前面,把算 符写在后面(后缀)。 如:a+b 写成 ab+ a+b*c 写成 abc*+ 定义: 1.如果表达式E是一个变量或常量,则E的后缀式是E自身; 2.如果E是E1 op E2形式的表达式 (op为二元操作符) ,则E的 后缀式为E1’E2’op。E1’ 、E2’分别为E1、E2的后缀式; 3.如果E式(E1)形式的表达式,则E1的后缀式就是E的后缀式。 •这种表达式不需要括号 这种表达式不需要括号
(0) (=[ ],x,i) (1) (:=,(0),y)
([ ]=,y,-,x[i]) //变址存数四元式
(0) ( [ ]=,y,i) (1) (:=,x,(0))
(=[ ],y[i] ,-,x) //变址取数四元式
如a:=b*-c+b*-c
四元式
op (0) (1) (2) (3) (4) (5) arg1 arg2 resul t T1 uminus C
如a*(b+c) 写成 abc+* (a+b)*(c+d) 写成 ab+cd+*
* a b + c a + b c *
+
d
将表达式翻译为后缀式的语义规则
产生式
E→E1 op E2 E→(E) E→id
语义规则
E.code:=E1.code||E2.code|| op E.code:=E1.code E.code:=id
a:=b*-c+b*-c的三地址代码为:
T1 := -c T2 :=b*T1 T3 := -c T4 :=b*T3 T5 :=T2 +T4 a := T5
编译原理第七章中间代码生成汇编
*
b
*
b
uminus
c
a= b*-c + b*-c
c abc uminus * bc numinus *+ assign
抽象语法树
• 构造赋值语句语法树的语法制导定义: 产生式
S→id = E E→E1 + E2 E→E1 * E2 E→- E1 E→(E1)
• param x1 • param x2 • …… • param x2 • call p, n n表示实参个数。return y中y为过程返回的一个值
– 形如x = y[i]及x[i] = y的索引赋值。
– 形如x = &y, x = *y和*x = y的地址和指针赋值。象形式。 • 这些语句可以以带有操作符和操作数域的记录 来实现。四元式、三元式及间接三元式是三种 这样的表示。
x = y op z
其中,x、y和z是名字,常量或编译器生成的临时变量 op代表任何操作符(定点运算符、浮点运算符、逻辑运算 符等)
• 像x+y*z这样的表达式要翻译为:
T1 = y * z
T2 = x + T1 其中T1 ,T2为编译时产生的临时变量。
三地址语句的类型
• 三地址语句类似于汇编语言代码。语句可以有 符号标号,而且存在各种控制流语句。
– 临时变量也要填入符号表中。
三元式
• 为了避免把临时变量填入符号表,可以通过计 算临时值语句的位置来引用该临时变量。 • 这样三地址代码的记录只需要三个域op, arg1 和arg。
• 对于单目运算符op, arg1和arg2只需用其一。
编译原理第7章-中间代码生成

-16-
表达式代码生成的例子
College of Computer Science & Technology
class[5].age + *ptr.age
typedef struct { char name[30]; int age; float height; }person;
int x[10]; person class[10]; person *ptr;
(cSlaUsBs[I5,]5, 0,t4t5) (MULTI, t5, 33, t6) cla(sAsA[5D].aDg,eclasst,1t6, t4) (AADD , t4, 30, t1) *p(t*Arp.astsgrieg,ptt7tr2, _, t7) (AADD , t7, 30, t2)
-7-
四元式
• 表达式运算符 College of Computer Science & Technology
– ADDI, ADDF, SUBI, SUBF, MULTI, MULTF,
– DIVI, DIVF, MOD,
– AND, OR, EQ, NE, GT, GE, LT, LE
• I/O 操作
Compiler Construction Principles & Implementation Techniques
-12-
7.2 表达式的四元式代码
College of Computer Science & Technology
• 表达式的运算分量可以很复杂:
– 多维数组下标变量:A[i][j][k] – 结构体域名变量:st.address.city – 函数调用:f(x,y) – 指针引用:*(p+1) – ……
编译原理中间代码生成7

7.1 中 间 语 言
7.1.4 静态单赋值形式 • 一种便于某些代码优化的中间表示 • 和三地址代码的主要区别
– 所有赋值指令都是对不同名字的变量的赋值 – 一个变量在不同路径上都定值的解决办法
if (flag) x = 1; else x = 1; y = x a; 的条件语句改成 if (flag) x1 = 1; else x2 = 1;
assign
assign
a
+
a
+
+
+
uminus c
d
uminus
c
d
c
d
b (a) 语法树
b (b) dag
a = (b + cd) + cd的图形表示
7.1 中 间 语 言
构造赋值语句语法树的语法制导定义
产生式
语义规则
S id =E S.nptr = mkNode(‘assign’, mkLeaf (id, id.entry), E.nptr)
a = (b + cd ) + cd 语法树的代码
t1 = b t2 = c d t3 = t1 + t2 t4 = c d t5 = t3 + t4 a = t5
uminus
7.1 中 间 语 言
三地址代码是语法树或dag的一种线性表示
a = (b + cd ) + cd
语法树的代码 dag的代码
7.2 声 明 语 句
P M D; S {addWidth (top (tblptr), top (offset) ); pop(tblptr); pop (offset) }
编译原理中的中间代码生成

编译原理中的中间代码生成编译原理是计算机科学中非常重要的一门课程,它研究的是将高级语言程序转化为低级语言程序,实现计算机能够理解和运行的目的。
但是高级语言相较于机器语言更为抽象和复杂,所以需要经过多个步骤的处理,其中中间代码生成就是其中的一个重要环节。
中间代码是指一种介于高级语言和机器语言之间的表示方式,它的作用是将高级语言程序转化为更容易被计算机处理的形式,同时它也提供了一种通用的平台,可以将同一份高级语言程序转化为多种低级语言程序,如汇编语言、机器语言等。
如今,多数编译器都采用中间代码进行转化和优化,它不仅可以提高代码执行效率,还可以提高程序的可移植性和可维护性。
那么,中间代码的生成是如何进行的呢?和编译器的其它部分一样,中间代码生成也是经过多个步骤的处理,其中最主要的步骤包括词法分析、语法分析、语义分析和中间代码生成。
词法分析的作用是将源程序的字符序列转换为单词序列。
它依靠的是正则表达式的特性,对源程序进行识别和划分,得到一系列单词。
这些单词包括关键字、标识符、常数、字符等,在很大程度上决定了接下来的语法分析和语义分析。
语法分析是将单词序列转化为抽象语法树的过程,它将程序以树的形式进行表示,更为直观和容易理解。
通过对抽象语法树的遍历,可以得到程序的各种信息,如变量名、函数名、常量、运算符和控制语句等。
对于每个节点,编译器会根据其语义和上下文信息,进行类型检查、错误检测和决策生成等操作,最终得到一个可运行的程序。
语义分析是识别程序中不符合语言规范或逻辑错误的部分,它是整个编译过程中最为复杂的一个环节。
在这个过程中,编译器需要根据程序的上下文信息,判断其意义和合理性,并进行正确的处理。
例如,当编译器遇到一个未定义的变量或函数时,它将会报错并停止编译。
语义分析可以避免很多程序运行时的错误,同时也是编译器优化的重要基础。
当编译器通过词法分析、语法分析和语义分析,得到一个完整、正确的程序后,就可以进行中间代码生成了。
编译原理课件-中间代码生成

(3) E→not E1 { E.true:= E 1.false; E.Codebegin:= E 1.codebegin; E.false:= E 1.true
(翻譯不是最優)
語句 if a<b or c<d and e<f then S1 else S2 的四元式
(1) if a<b goto (7) //轉移至(E.true )
(2) goto (3)
(3) if c<d goto (5)
(4) goto (p+1)
//轉移至(E.false)
(5) if e<f goto (7) (6) goto (p+1) (7)( S1的四元式
不同層次的中間代碼
源語言
中間代碼
(高級語言) (高級)
中間代碼 (中級)
中間代碼 (低級)
float a[10][20]; a[i][j+2];
t1 = a[i, j+2]
t1 = j + 2 t2 = i * 20 t3 = t1 + t2 t4 = 4 * t3 t5 = addr a t6 = t5 + t4 t7 = *t6
語義描述使用的變數和過程:
E.true : “真”鏈, E.false : “假”鏈
E.codebegin : E 的第一個四元式
Nextstat: 下一四元式地址
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
c
++*ad*bce
抽象语法树
由Token序列生成后缀式(1)
(1)初始化: S1和S2为空; (2) 读token: tk=ReadOne(); (3) Switch tk of (i) #: if (S1为空) exit; else while (S1不为空) /*产生剩余操作符的后缀表示*/ {op = pop(S1); (str1, str2)=pop(2); push(S2, str2 + str1+ “op”);} (ii)运算分量: push(tk, S2); goto (2); (iii)运算符: if (S1为空 || tk优先级大于Top(S1)) { push (tk, S1); goto(2);} else { while(tk小于等于Top(S1) && S1不为空)) { op = pop(S1); (str1, str2)=pop(2); push(S2, str2+str1 + “op”); } push(tk, S1); goto (2); }
+ +
a*c + a*c + e
e
+ +
e
* a
c a AST
* c a
* c
* a
DAG c
7.1 常见的中间表示
三地址中间代码
三地址:两个操作分量和一个结果的抽象地址; 为方便起见, 通常用变量名代替抽象地址; 三元式 No. (op, operand1, operand2) 编号 (操作符, 操作分量1, 操作分量2) 其中操作分量可以是变量名(抽象地址)或者编号 四元式 (op, operand1, operand2, result) (操作符, 操作分量1, 操作分量2, 结果) 其中操作分量可以是变量名(抽象地址)或者临时变量 (抽象地址)
通常用于表达式的中间表示
中缀 (运算符在操作数的中间) a*b 前缀式(运算符在操作数的前面) *ab 后缀式(运算符在操作数的后面) ab*
由抽象语法树生成后缀式
中缀式: a*d + b*c + e
+ + * a d b * e 后根遍历生成后缀式:
ad*bc*+e+
先根遍历生成前缀式:
操作分量
常量: 整数或者实数 标号: 标号名 变量: 需要更多信息用于形成其目标地址 函数/过程:需要更多信息用于得到其代码的目标地址
操作分量的ARG结构 --- 抽象地址结构
常量: (valKind, C) 标号: (labelKind, label) 变量: (varKind, level, offset, mode) 函数/过程:
由Token序列生成后缀式(2)
带括号表达式的后缀式例子
中缀式: (a + ( + b) * c ) + e #
后缀式: a d b + c * +e +
Operator stack 运算符栈 S1
Operand stack
运算分量栈 S2
7.1 常见的中间表示
抽象语法树-AST 无环有向图-DAG(共享的AST)
中间代码生成
M1
源程序
词 法 Token 分 析 序列 器
语 法 语法 分 分析 析 树 器
语 义 分 析 器
中 间 代 中间代码 码 生 成 器
…
Mn
7.1 常见的中间表示
后缀式,逆波兰式 抽象语法树 无环有向图 三元式
四元式
三地址中间代码
7.1 常见的中间表示
后缀式(逆波兰式)
生成后缀式的例子
中缀式: a * d + b * c + e #
运算符栈 S1
运算分量栈 S2
注意: 任何运算符的优先级都大于 ‘(’; (1)初始化: S1和S2为空; (2) 读token: tk=ReadOne(); (3) Switch tk of (i) #: if (S1为空) exit; else while (S1不为空) /*产生剩余操作符的后缀表示*/ {op = pop(S1); (str1, str2)=pop(2); push(S2, str2 + str1 + “op” );} (ii)operand: push(tk, S2); goto (2); ‘(’ : push(‘(‘, S1); goto (2); (iii)operator: if (S1为空 || tk优先级大于Top(S1)) { push (tk, S1);goto(2); } else { while(tk小于等于Top(S1) && Top(S1) ≠ ‘(’ && S1不为空))) { op = pop(S1); (str1, str2)=pop(2); push(S2, str2+str1 + “op”); } push(tk, S1); goto (2);} } (iv) ‘)’: while (Top(S1) ≠ ‘(’ ) {op = pop(S1); (str1, str2)=pop(2); push(S2, str2+str1 + “op”);} pop(S1); goto (2);
三地址代码的例子
a*d + b*c + e
三元式
四元式
(1) (*, a, d) (2) (*, b, c) (3) (+, (1), (2)) (4) (+, (3), e)
(*, a, d, t1) (*, b, c, t2) (+, t1, t2, t3) (+, t3, e, t4)
操作分量的抽象地址
中间代码生成在编译器中的作用
词法分析 目标代码生成
语法分析
中间代码优化
语义分析
中间代码生成
分析
合成
中间代码生成
中间代码生成是将源程序翻译成中间表示的 过程 目的:增强语言的可移植性、进行优化; 中间代码生成方法:
语法制导的翻译方法:属性文法和动作文法 基于Token序列
基于抽象语法树
实在函数/过程: (funKind, actual, label) 形参函数/过程: (funKind, formal, level, offset)