python爬虫实战
Python爬虫技术的实践应用

Python爬虫技术的实践应用前言Python爬虫技术在当今的互联网时代被广泛应用,既有商业应用也有研究学术应用,前者可用于产品销售、网站广告、市场数据等,后者则可以用于学术研究、文本挖掘、情感分析等领域。
本文将分为两个部分,分别介绍爬虫技术的基本原理和实践应用,通过案例分析以帮助读者深入理解Python爬虫技术的实践应用。
一、爬虫技术的基本原理Python爬虫技术的本质是模拟人类浏览器行为,自动化得获取Web上的信息。
Python爬虫的工作流程包括两个关键步骤:发送请求、解析响应。
1.发送请求Python爬虫发送请求,即发送HTTP请求,采用该协议的原因是它是当今最常用的互联网协议。
Python爬虫通过发送HTTP请求获取Web上的信息。
这份请求由四个主要部分组成:方法、URL、头字段和空行。
方法表示该请求的目的是获取、修改、删除等。
通常情况下,Python爬虫发送的是GET请求。
URL表示该请求的目标位置。
头字段前面已经提到过。
空行告诉服务器请求头结束了,后面的内容是正文。
作为服务器的响应,也包括类似GET请求的响应头和响应正文两个部分。
2.解析响应Python爬虫解析响应,即将得到的响应解析为Python可以处理的对象。
解析响应的主要工具是正则表达式或者现成的第三方库,如lxml、BeautifulSoup、pyquery等。
这些工具有助于解析HTML,并从中提取只想要的信息。
另外,要注意几点,如响应数据可能是压缩的,需要用GZip解压;响应时可能需要登录以验证身份;响应可能来自反爬虫机制,需要伪装请求头。
二、本节将介绍爬虫技术在商业和学术领域中的实践应用。
对于商业应用,Python爬虫技术可以加速数据采集、开发大规模网站等。
对于研究学术领域,Python爬虫技术可以用于情感分析、文本挖掘等。
1.商业应用商业应用爬虫主要用于市场数据分析、竞争环境分析等。
大数据时代的到来,Python爬虫技术成为了数据分析重要的辅助工具。
Python爬虫实战教学

Python爬虫实战教学第一章:爬虫基础知识Python爬虫是一种自动爬取网站信息的技术,可以用来获取大量数据。
在进行Python爬虫实战前,我们首先需要了解一些基础知识。
1.1 爬虫的原理爬虫的原理是通过发送HTTP请求到目标网站,然后解析网页获取所需的信息。
可以使用Python的第三方库,如Requests库来发送HTTP请求,并使用正则表达式或者解析库(如BeautifulSoup、XPath等)来解析网页。
1.2 HTTP请求与响应在Python中,我们可以使用Requests库发送HTTP请求,并获取响应内容。
可以设置请求头、请求体、代理IP等信息,以模拟浏览器的行为。
1.3 网页解析网页解析是爬虫的核心部分,常用的解析方法有正则表达式、BeautifulSoup、XPath等。
使用这些方法可以从网页中提取出所需的信息。
这些解析方法各有特点,根据不同的场景选择合适的方法。
第二章:爬虫实战准备在进行爬虫实战之前,我们需要做一些准备工作。
2.1 安装Python和相关库首先,我们需要安装Python,并安装相关的第三方库,如Requests、BeautifulSoup等。
可以使用pip命令来安装这些库。
2.2 确定爬取目标在进行爬虫实战之前,我们需要明确我们要爬取的目标,确定目标网站的URL和需要提取的信息。
2.3 分析网页在确定目标网站后,我们需要分析网页的结构,找出目标信息所在的位置、标签等。
可以使用浏览器的开发者工具来分析网页。
第三章:实战案例一——爬取天气信息3.1 网页分析首先,我们需要分析天气网站的网页结构,找出所需的天气信息所在的位置。
可以使用浏览器的开发者工具来分析。
3.2 发送HTTP请求使用Requests库发送HTTP请求到天气网站,并获取响应内容。
3.3 解析网页使用解析库(如BeautifulSoup)来解析网页,提取出所需的天气信息。
3.4 数据处理与存储对提取出的天气信息进行数据处理(如去除空白字符、转换格式等),并将数据保存到本地文件或者数据库。
python爬虫的实验报告

python爬虫的实验报告一、实验目的随着互联网的迅速发展,大量有价值的数据散落在各个网站中。
Python 爬虫作为一种获取网络数据的有效手段,具有广泛的应用前景。
本次实验的目的是通过使用 Python 编写爬虫程序,深入理解网络爬虫的工作原理,掌握基本的爬虫技术,并能够成功获取指定网站的数据。
二、实验环境1、操作系统:Windows 102、开发工具:PyCharm3、编程语言:Python 3x三、实验原理网络爬虫的基本原理是模拟浏览器向服务器发送请求,获取服务器返回的 HTML 页面,然后通过解析 HTML 页面提取所需的数据。
在Python 中,可以使用`requests`库发送请求,使用`BeautifulSoup`或`lxml`库解析 HTML 页面。
四、实验步骤(一)安装所需库首先,需要安装`requests`、`BeautifulSoup4`和`lxml`库。
可以通过以下命令使用`pip`安装:```pip install requestspip install beautifulsoup4pip install lxml```(二)分析目标网站选择一个要爬取的目标网站,例如具体网站地址。
对该网站的页面结构进行分析,确定要获取的数据所在的位置以及页面的链接规律。
(三)发送请求获取页面使用`requests`库发送 HTTP 请求获取目标页面的 HTML 内容。
以下是一个简单的示例代码:```pythonimport requestsdef get_html(url):response = requestsget(url)if responsestatus_code == 200:return responsetextelse:print("请求失败,状态码:", responsestatus_code)return Noneurl =""html = get_html(url)```(四)解析页面提取数据使用`BeautifulSoup`或`lxml`库对获取到的 HTML 内容进行解析,提取所需的数据。
Python网络爬虫入门实战(爬取最近7天的天气以及最高最低气温)
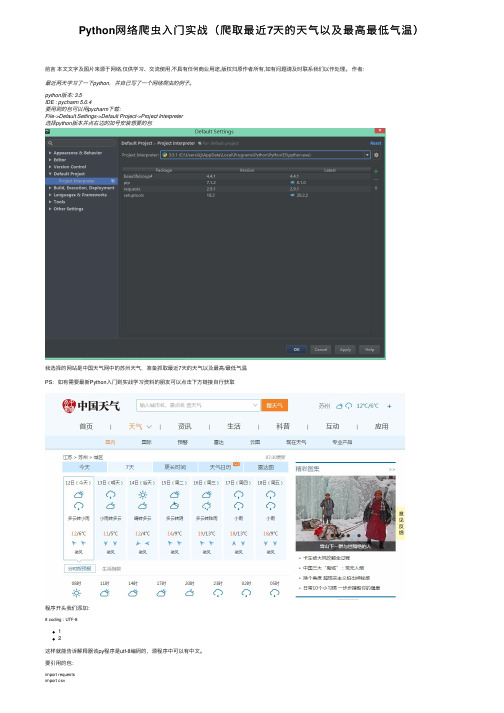
Python⽹络爬⾍⼊门实战(爬取最近7天的天⽓以及最⾼最低⽓温)前⾔本⽂⽂字及图⽚来源于⽹络,仅供学习、交流使⽤,不具有任何商业⽤途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:最近两天学习了⼀下python,并⾃⼰写了⼀个⽹络爬⾍的例⼦。
python版本: 3.5IDE : pycharm 5.0.4要⽤到的包可以⽤pycharm下载:File->Default Settings->Default Project->Project Interpreter选择python版本并点右边的加号安装想要的包我选择的⽹站是中国天⽓⽹中的苏州天⽓,准备抓取最近7天的天⽓以及最⾼/最低⽓温PS:如有需要最新Python⼊门到实战学习资料的朋友可以点击下⽅链接⾃⾏获取程序开头我们添加:# coding : UTF-812这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中⽂。
要引⽤的包:import requestsimport csvimport randomimport timeimport socketimport http.client# import urllib.requestfrom bs4 import BeautifulSoup12345678requests:⽤来抓取⽹页的html源代码csv:将数据写⼊到csv⽂件中random:取随机数time:时间相关操作socket和http.client 在这⾥只⽤于异常处理BeautifulSoup:⽤来代替正则式取源码中相应标签中的内容urllib.request:另⼀种抓取⽹页的html源代码的⽅法,但是没requests⽅便(我⼀开始⽤的是这⼀种)获取⽹页中的html代码:def get_content(url , data = None):header={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, sdch','Accept-Language': 'zh-CN,zh;q=0.8','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'}timeout = random.choice(range(80, 180))while True:try:rep = requests.get(url,headers = header,timeout = timeout)rep.encoding = 'utf-8'# req = urllib.request.Request(url, data, header)# response = urllib.request.urlopen(req, timeout=timeout)# html1 = response.read().decode('UTF-8', errors='ignore')# response.close()break# except urllib.request.HTTPError as e:# print( '1:', e)# time.sleep(random.choice(range(5, 10)))## except urllib.request.URLError as e:# print( '2:', e)# time.sleep(random.choice(range(5, 10)))except socket.timeout as e:print( '3:', e)time.sleep(random.choice(range(8,15)))except socket.error as e:print( '4:', e)time.sleep(random.choice(range(20, 60)))except http.client.BadStatusLine as e:print( '5:', e)time.sleep(random.choice(range(30, 80)))except http.client.IncompleteRead as e:print( '6:', e)time.sleep(random.choice(range(5, 15)))return rep.text# return html_text12345678910111213141516171819202122232425262728293031323334353637383940414243header是requests.get的⼀个参数,⽬的是模拟浏览器访问header 可以使⽤chrome的开发者⼯具获得,具体⽅法如下:打开chrome,按F12,选择network重新访问该⽹站,找到第⼀个⽹络请求,查看它的headertimeout是设定的⼀个超时时间,取随机数是因为防⽌被⽹站认定为⽹络爬⾍。
Python爬虫项目实战源代码集锦

Python爬虫项目实战源代码集锦为了满足标题描述的内容需求,下面是一些Python爬虫项目实战的源代码示例,供参考和学习。
1. 爬取网页数据import requests# 发送HTTP请求获取网页内容response = requests.get(url)content = response.text# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...2. 爬取图片import requests# 发送HTTP请求获取图片资源response = requests.get(image_url)# 保存图片到本地with open('image.jpg', 'wb') as f:f.write(response.content)3. 爬取动态网页from selenium import webdriver # 启动浏览器驱动driver = webdriver.Chrome()# 打开动态网页driver.get(url)# 等待动态内容加载完成# ...# 提取所需信息# ...# 存储数据# ...4. 登录网站并获取数据import requests# 登录网站login_data = {'username': 'your_username','password': 'your_password'}session = requests.Session() session.post(login_url, data=login_data) # 发送登录后的请求response = session.get(url)# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...5. 反爬虫处理import requestsfrom fake_useragent import UserAgent # 构造随机HTTP请求头user_agent = UserAgent().random# 发送带有伪装的HTTP请求headers = {'User-Agent': user_agent}response = requests.get(url, headers=headers)# 解析网页内容# ...# 提取所需信息# ...# 存储数据# ...以上是一些Python爬虫项目实战源代码的简单示例,可以根据具体项目的需求进行修改和扩展。
Python爬虫技术【实战】(适合初学者的教程)课件PPT模板

第2章爬虫基础
2-7存储数据到redis 2-8处理json数据 2-8处理JSON数据
3
第
章 爬 例虫 应 用 案
第3章爬虫 应用案例
01 3-1电影评论数据 02 3-2分析猫眼数据
分析
接口
03 3-3获取评论数据 04 3-4粉丝位置分布 -
地理坐标图
05 3-5粉丝来源排行 06 3-6电影评分星级 -
榜-柱状图
饼图
202x
感谢聆听
02
1-
05
5jinja2
模板语法
04
1-4响应
03
1-3文件 上传
第1章flask框 架快速入门
2
第
章 爬 虫 基 础
第2章爬虫 基础
06
2-6存储数 介
05
2-5存储数 据到mysql
02
2-2获取数 据
04
2-4处理数 据
03
23beautifuls
oup用法
202x
python爬虫技术【实战】 (适合初学者的教程)
演讲人
2 0 2 x - 11 - 11
目录
01. 第1章flask框架快速入门 02. 第2章爬虫基础 03. 第3章爬虫应用案例
1 flask
第
快章 速 入 门框
架
1-1基础入 门
1-6使用蓝
01
图实现模
块 化 06
1-2请求参 数
Python网络爬虫实践教程

Python网络爬虫实践教程一、什么是网络爬虫网络爬虫,也称为网络蜘蛛或网络机器人,是一种自动获取互联网信息的程序工具。
通过模拟浏览器行为,爬虫程序可以访问网页、提取网页中的数据,在大规模数据采集、搜索引擎、数据分析等领域发挥着重要作用。
二、网络爬虫的基本原理网络爬虫的基本原理是通过发送HTTP请求,并解析响应得到的HTML文档来获取网页数据。
首先,我们需要使用Python中的requests库发送网络请求,并获得服务器的响应。
然后,通过解析HTML文档,提取出我们需要的数据。
三、准备工作在开始编写网络爬虫之前,我们需要安装Python以及相关的库。
首先,需要安装Python解释器和pip包管理工具。
然后,使用pip安装requests、beautifulsoup和lxml等库。
四、发送HTTP请求在编写爬虫程序之前,我们需要了解如何使用Python发送HTTP请求。
使用requests库发送GET请求非常简单,只需要调用get方法,并提供目标网址即可。
如果需要发送POST请求,同样使用post方法,并在参数中传递需要提交的数据。
五、解析HTML文档解析HTML文档是爬虫中非常重要的一步。
Python提供了多种解析HTML的库,其中比较常用的是beautifulsoup和lxml。
通过指定解析器,我们可以轻松地提取出HTML文档中的各个元素,并进行进一步的处理。
六、处理反爬机制为了阻止爬虫程序的访问,许多网站采取了反爬机制,例如设置验证码、限制IP访问频率等。
对于这些反爬措施,我们可以通过使用代理IP、设置请求头信息、使用验证码识别技术等方法来绕过。
七、数据存储与分析在爬虫过程中,我们通常需要将获取的数据进行存储和分析。
常用的数据存储方式包括将数据保存到数据库、文本文件、Excel 表格或者CSV文件中。
而要对数据进行分析,可以使用Python中的数据分析库,如pandas、numpy等。
八、实践案例:爬取豆瓣电影数据为了更好地理解网络爬虫的实践过程,我们以爬取豆瓣电影数据为例进行讲解。
7个经典python爬虫案例代码分享

Python作为一种简单易学的编程语言,广受程序员和数据科学家的喜爱。
其中,用Python进行网络爬虫的应用也越来越广泛。
本文将共享7个经典的Python爬虫案例代码,希望能够给大家带来启发和帮助。
1. 爬取豆瓣电影排行榜数据在本例中,我们将使用Python的requests库和BeautifulSoup库来爬取豆瓣电影排行榜的数据。
我们需要发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析HTML文档,提取出我们需要的电影名称、评分等信息。
我们可以将这些数据保存到本地或者进行进一步的分析。
```pythonimport requestsfrom bs4 import BeautifulSoupurl = 'response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')for movie in soup.find_all('div', class_='item'):title = movie.find('span', class_='title').textrating = movie.find('span', class_='rating_num').textprint(title, rating)```2. 爬取博博用户信息在这个案例中,我们将利用Python的requests库和正则表达式来爬取博博用户的基本信息。
我们需要登录博博并获取用户主页的URL,然后发送HTTP请求获取用户主页的HTML文档。
我们可以使用正则表达式来提取用户的昵称、性别、位置区域等信息。
我们可以将这些信息保存到数据库或者进行其他处理。
```pythonimport requestsimport reurl = 'response = requests.get(url)pattern = repile(r'<title>(.*?)</title>.*?昵称:(.*?)<.*?性别:(.*?)<.*?地区:(.*?)<', re.S)result = re.search(pattern, response.text)if result:username = result.group(2)gender = result.group(3)location = result.group(4)print(username, gender, location)```3. 爬取新浪新闻在这个案例中,我们将使用Python的requests库和XPath来爬取新浪新闻的标题和信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python爬虫实战,多线程爬取京东jd html页面:无需登录的网
站的爬虫实战
2014-12-02 20:04:31
标签:网站爬虫python import
版权声明:原创作品,如需转载,请与作者联系。
否则将追究法律责任。
【前言】
【需求说明】
以京东为示例,爬取页面的,获取页面中得数据:记录到data.txt;获取页面中得图片,保存下来。
1、list的url如下
2、商品详情页的url如下:
【技术说明】
【代码逻辑说明】
1、run(获取最终要的结果)
2、parseListpageurl:返回list的总共的页面数量
3、judgelist:判断该list是否已经爬取完毕了,第一个list中的所有url、最后list 的所有url都爬取完毕了,那么久说明list的所有page爬取完毕了(实际上是一种弱校验)
4、getfinalurl_content:如果list没爬取完毕,每个list爬取,解析list中得每个html (判断html是否爬取过),获得内容和img
【坑说明】
1、需要设置超时时间,和重试,否则爬取一个url卡住的时候,整个线程都悲剧了。
2、有编码的坑,如果页面是gb2312的编码,需要转换为utf-8的编码:
httprestmp.decode('gbk').encode('utf-8')
3、parser.feed的内容,如果存在一些特殊字符,可能需要替换,否则解析出来会莫名不对
4、图片保存,根据url获取前面两个数字,保存。
以免一个目录下保存了过多的图片。
【执行结果】
1、console输出
2、data.txt存储解析出来的内容
3、judegurl.txt(保存已经爬取过的url)
4、图片(下载的图片)
【代码详情】。