用身高和体重数据进行性别分类的实验报告
模式识别第一次作业报告

模式识别第一次作业报告姓名:刘昌元学号:099064370 班级:自动化092班题目:用身高和/或体重数据进行性别分类的实验基本要求:用famale.txt和male.txt的数据作为训练样本集,建立Bayes分类器,用测试样本数据test1.txt和test2.txt该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
一、实验思路1:利用Matlab7.1导入训练样本数据,然后将样本数据的身高和体重数据赋值给临时矩阵,构成m行2列的临时数据矩阵给后面调用。
2:查阅二维正态分布的概率密度的公式及需要的参数及各个参数的意义,新建m函数文件,编程计算二维正态分布的相关参数:期望、方差、标准差、协方差和相关系数。
3.利用二维正态分布的相关参数和训练样本构成的临时数据矩阵编程获得类条件概率密度,先验概率。
4.编程得到后验概率,并利用后验概率判断归为哪一类。
5.利用分类器训练样本并修正参数,最后可以用循环程序调用数据文件,统计分类的男女人数,再与正确的人数比较得到错误率。
6.自己给出决策表获得最小风险决策分类器。
7.问题的关键就在于利用样本数据获得二维正态分布的相关参数。
8.二维正态分布的概率密度公式如下:试验中编程计算出期望,方差,标准差和相关系数。
其中:二、实验程序设计流程图:1:二维正态分布的参数计算%功能:调用导入的男生和女生的身高和体重的数据文件得到二维正态分布的期望,方差,标准差,相关系数等参数%%使用方法:在Matlab的命令窗口输入cansu(male) 或者cansu(famale) 其中 male 和 famale%是导入的男生和女生的数据文件名,运用结果返回的是一个行1行7列的矩阵,其中参数的顺序依次为如下:%%身高期望、身高方差、身高标准差、体重期望、体重方差、体重标准差、身高和体重的相关系数%%开发者:安徽工业大学电气信息学院自动化 092班刘昌元学号:099064370 %function result=cansu(file)[m,n]=size(file); %求出导入的数据的行数和列数即 m 行n 列%for i=1:1:m %把身高和体重构成 m 行 2 列的矩阵%people(i,1)=file(i,1);people(i,2)=file(i,2);endu=sum(people)/m; %求得身高和体重的数学期望即平均值%for i=1:1:mpeople2(i,1)=people(i,1)^2;people2(i,2)=people(i,2)^2;endu2=sum(people2)/m; %求得身高和体重的方差、%x=u2(1,1)-u(1,1)^2;y=u2(1,2)-u(1,2)^2;for i=1:1:mtem(i,1)=people(i,1)*people(i,2);ends=0;for i=1:1:ms=s+tem(i,1);endcov=s/m-u(1,1)*u(1,2); %求得身高和体重的协方差 cov (x,y)%x1=sqrt(x); %求身高标准差 x1 %y1=sqrt(y); %求身高标准差 y1 %ralation=cov/(x1*y1); %求得身高和体重的相关系数 ralation %result(1,1)=u(1,1); %返回结果 :身高的期望 %result(1,2)=x; %返回结果 : 身高的方差 %result(1,3)=x1; %返回结果 : 身高的标准差 %result(1,4)=u(1,2); %返回结果 :体重的期望 %result(1,5)=y; %返回结果 : 体重的方差 %result(1,6)=y1; %返回结果 : 体重的标准差 %result(1,7)=ralation; %返回结果:相关系数 %2:贝叶斯分类器%功能:身高和体重相关情况下的贝叶斯分类器(最小错误率贝叶斯决策)输入身高和体重数据,输出男女的判断%%使用方法:在Matlab命令窗口输入 bayes(a,b) 其中a为身高数据,b为体重数据。
SAS数据分析实验报告

SAS数据分析实验报告摘要:本文使用SAS软件对一组数据集进行了分析。
通过数据清洗、数据变换、数据建模和数据评估等步骤,得出了相关的结论。
实验结果表明,使用SAS软件进行数据分析可以有效地处理和分析大型数据集,得出可靠的结论。
1.引言数据分析在各个领域中都扮演着重要的角色,可以帮助人们从大量的数据中提取有用信息。
SAS是一种常用的数据分析软件,被广泛应用于统计分析、商业决策、运营管理等领域。
本实验旨在探究如何使用SAS软件进行数据分析。
2.数据集描述本实验使用了一个包含1000个样本的数据集。
数据集包括了各个样本的性别、年龄、身高、体重等多种变量。
3.数据清洗在进行数据分析之前,首先需要对数据进行清洗。
数据清洗包括缺失值处理、异常值处理和重复值处理等步骤。
通过使用SAS软件中的相应函数和命令,我们对数据集进行了清洗,确保数据的质量和准确性。
4.数据变换在进行数据分析之前,还需要对数据进行变换。
数据变换包括数据标准化、数据离散化和数据归一化等操作。
通过使用SAS软件中的变换函数和操作符,我们对数据集进行了变换,使其符合分析的需要。
5.数据建模数据建模是数据分析的核心过程,包括回归分析、聚类分析和分类分析等。
在本实验中,我们使用SAS软件的回归、聚类和分类函数,对数据集进行了建模分析。
首先,我们进行了回归分析,通过拟合回归模型,找到了自变量对因变量的影响。
通过回归模型,我们可以预测因变量的值,并分析自变量的影响因素。
其次,我们进行了聚类分析,根据样本的特征将其分类到不同的群组中。
通过聚类分析,我们可以发现样本之间的相似性和差异性,从而做出针对性的决策。
最后,我们进行了分类分析,根据样本的特征判断其所属的类别。
通过分类分析,我们可以根据样本的特征预测其所属的类别,并进行相关的决策。
6.数据评估在进行数据分析之后,还需要对结果进行评估。
评估包括模型的拟合程度、变量的显著性和模型的稳定性等。
通过使用SAS软件的评估函数和指标,我们对数据分析的结果进行了评估。
SPSS统计分析实验指导

>1000
图 1-4 变量值标签定义对话框
2 数据的输入
(1)直接从数据编辑窗口的输入数据:先将变量定义好后,变量名就会在每列的上面显示,可以看到 其格式如 Excel,其实输入及编辑方法也和 Excel 相当。请同学们自己练习。数据输入及编辑窗口如图 1-5 所示(见 Excel 表 1-2),是将表 1-2 所示数据建立成 SPSS 文件。
(二)信息的输入和输出 1 统计变量的定义
(1)变量:SPSS 中的变量与数学中的变量定义相同,即其值可变的量称为变量。SPSS 中变量的属性 主要有四个:变量名、变量类型、变量标签、变量长度。定义变量时至少要有变量名和变量类型。变量定义 窗口如图 1-2 所示。
图 1-2 变量定义窗口
(2)变量类型:SPSS 中有三种基本类型:Numeric(数值型),String(字符型),Date(日期型)。数 值型变量按不同要求可分为五种,再加上自定义型,所以可以定义的类型变量有八种。系统默认的变量类型 为标准数值型,长度为 8,小数占两位。变量类型对话框如 1-3 所示,每种变量的具体定义请参阅相关参考 资料。
2) 变量值标签(Value Labels) 变量值标签是对变量的取值所附加的进一步说明。对分类变量往往要定义其取值的标签。如对收入以 500 的间距进行分类,如表 1-1 定义变量的值标签:
表 1-1 变量值标签的定义实例
变量名
变量值
变量值标签
1
<=500
C
2
501-1000
3
定义变量值标签的对话框如图 1-4 所示
图 1-1 SPSS 11.5 for Windows 主环境
3 SPSS for Windows 功能介绍
Python与机器学习-- 身高与体重数据分析(分类器)I

逻辑回归:三、数据可视化:分类
Car 情报局
xcord11 = []; xcord12 = []; ycord1 = []; xcord21 = []; xcord22 = []; ycord2 = []; n = len(Y)
for i in range(n): if int(Y.values[i]) == 1: xcord11.append(X.values[i,0]); xcord12.append(X.values[i,1]); ycord1.append(Y.values[i]); else: xcord21.append(X.values[i,0]); xcord22.append(X.values[i,1]); ycord2.append(Y.values[i]);
逻辑回归:三、数据可视化:观察
import matplotlib.pyplot as plt X = df[['Height', 'Weight']] Y = df[['Gender']]
Car 情报局
plt.figure() plt.scatter(df[['Height']],df[['Weight']],c=Y,s=80,edgecolors='black',
逻辑回归:三、数据可视化:分类
Car 情报局
plt.figure()
plt.scatter(xcord11, xcord12, c='red', s=80, edgecolors='black', linewidths=1, marker='s')
应用统计学上机
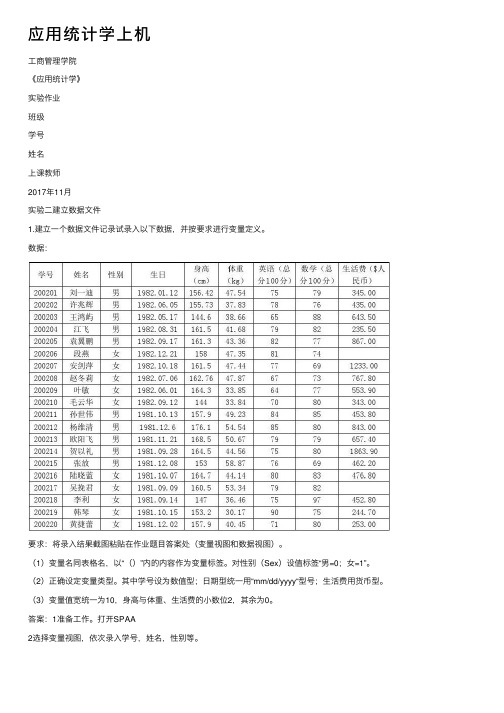
应⽤统计学上机⼯商管理学院《应⽤统计学》实验作业班级学号姓名上课教师2017年11⽉实验⼆建⽴数据⽂件1.建⽴⼀个数据⽂件记录试录⼊以下数据,并按要求进⾏变量定义。
数据:要求:将录⼊结果截图粘贴在作业题⽬答案处(变量视图和数据视图)。
(1)变量名同表格名,以“()”内的内容作为变量标签。
对性别(Sex)设值标签“男=0;⼥=1”。
(2)正确设定变量类型。
其中学号设为数值型;⽇期型统⼀⽤“mm/dd/yyyy“型号;⽣活费⽤货币型。
(3)变量值宽统⼀为10,⾝⾼与体重、⽣活费的⼩数位2,其余为0。
答案:1准备⼯作。
打开SPAA2选择变量视图,依次录⼊学号,姓名,性别等。
2.对⼤学⽣创业问题设计⼀份调查问卷。
要求格式正确,题⽬类型包括开放题、封闭题(单选、多选都有)、半封闭题三种类型,题⽬个数10-15个。
答案:3.⽤第2题得到的调查问卷进⾏模拟调查(10份),并将得到的结果录⼊到SPSS中,(1)将录⼊结果保存为xxx.sav⽂件,并将录⼊结果截图粘贴在作业题⽬答案处(变量视图和数据视图)。
答案:实验三数据的整理1. 某地区农科所为了研究该地区种植的两个⼩麦品种“中麦9号”、“豫展1号”产量的差异,从该地区的两个村庄各选5块⽥地,分别种植两个品种⼩麦,使⽤相同的⽥间管理,收获后,测得各个地块⽣产的⼩麦的千粒重(g)数据资料如表3-1所⽰。
表3-1 某地区⼩麦种植要求:量,并建⽴数据⽂件,完成分类汇总⼯作。
步骤:1.准备⼯作。
打开3-1⽂件,通过⽂件--打开,将⽂件放⼊打开窗⼝。
2.选择数据---分类汇总。
3.打开分类汇总窗⼝,将⼩麦品种放⼊分组变量对话框中,将千粒重放⼊变量摘要对话框中。
4.选择函数选项,在函数对话框中选择均值选项5.选择继续--确定,得出结果。
以此⽅式得出村对⼩麦千粒重的分类汇总。
2.某地20家企业的情况如表3-2所⽰。
表3-2 企业年产值与年⼯资总额要求:根据上述资料建⽴数据⽂件,并完成下列统计整理⼯作,并回答有关问题:(1)调⽤排序命令对企业按部门、年产值的主次顺序进⾏排序。
Fisher分类算法(无程序)

12%
分析:用训练样本得到的分类器测试测试样本时错误率低,测试结果较好,但测试训练样本
时,其错误率较高,测试结果不好。
2、Fisher 判别方法图像
分析:从图中我们可以直观的看出对训练样本 Fisher 判别比最大似然 Bayes 判别效果更好。
六、总结与分析
本次实验使我们对加深 Fisher 判别法的理解。通过两种分类方法的比较,我们对于同 一种可以有很多不同的分类方法,各个分类方法各有优劣,所以我们更应该熟知这些已经 得到充分证明的方法,在这些方法的基础上通过自己的理解,创造出更好的分类方法。所 以模式识别还有很多更优秀的算法等着我们去学习。
三、实验内容
试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分类器进行比较。 同时采用身高和体重数据作为特征,用 Fisher 线性判别方法求分类器,将该分类器应用 到训练和测试样本,考察训练和测试错误情况。将训练样本和求得的决策边界画到图上,同 时把以往用 Bayes 方法求得的分类器(例如: 最小错误率 Bayes 分类器)也画到图上,比较 结果的异同。
四、原理简述、程序流程图
1、Fisher 线性判别方法
∑ mi
首先求各类样本均值向量
=
1 Ni
x, i
x∈ωi
= 1,2
,
si = ∑ (x − mi )(x − mi )T ,i = 1,2
然后求各个样本的来内离散度矩阵
x∈wi
,
( ) ( ) s 再求出样本的总类内离散度 ω = p ω1 s1 + p ω2 s2 ,
2、流程图
求各类样本均 值向量
求类内离散度 矩阵
用公式求最好 的变换向量W*
数据挖掘实例实验报告(3篇)

第1篇一、实验背景随着大数据时代的到来,数据挖掘技术逐渐成为各个行业的重要工具。
数据挖掘是指从大量数据中提取有价值的信息和知识的过程。
本实验旨在通过数据挖掘技术,对某个具体领域的数据进行挖掘,分析数据中的规律和趋势,为相关决策提供支持。
二、实验目标1. 熟悉数据挖掘的基本流程,包括数据预处理、特征选择、模型选择、模型训练和模型评估等步骤。
2. 掌握常用的数据挖掘算法,如决策树、支持向量机、聚类、关联规则等。
3. 应用数据挖掘技术解决实际问题,提高数据分析和处理能力。
4. 实验结束后,提交一份完整的实验报告,包括实验过程、结果分析及总结。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据挖掘库:pandas、numpy、scikit-learn、matplotlib四、实验数据本实验选取了某电商平台用户购买行为数据作为实验数据。
数据包括用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业等。
五、实验步骤1. 数据预处理(1)数据清洗:剔除缺失值、异常值等无效数据。
(2)数据转换:将分类变量转换为数值变量,如年龄、性别等。
(3)数据归一化:将不同特征的范围统一到相同的尺度,便于模型训练。
2. 特征选择(1)相关性分析:计算特征之间的相关系数,剔除冗余特征。
(2)信息增益:根据特征的信息增益选择特征。
3. 模型选择(1)决策树:采用CART决策树算法。
(2)支持向量机:采用线性核函数。
(3)聚类:采用K-Means算法。
(4)关联规则:采用Apriori算法。
4. 模型训练使用训练集对各个模型进行训练。
5. 模型评估使用测试集对各个模型进行评估,比较不同模型的性能。
六、实验结果与分析1. 数据预处理经过数据清洗,剔除缺失值和异常值后,剩余数据量为10000条。
2. 特征选择通过相关性分析和信息增益,选取以下特征:用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业。
第1单元 第3课《班级BMI数据测试--数据的收集与处理》教案【清华大学版2024】《信息科技》四上
思考:你知道全班同学的营养状况如何吗?如果想要收集他们的身体发育水平数据,你会采用什么方法呢?①问卷调查:收集饮食习惯和运动频率。
②身高体重测量:计算BMI评估营养状态。
③数据分析:识别整体和个体的发育趋势。
④隐私保护:确保数据安全,尊重学生隐私。
2.播放视频。
所示。
观察法是最直接的收集数据的方法,应用非常广泛,有时候会和调查法结合使用,以提高所收集信息的可靠性。
比如,想要知道学校门口每天早上的人流量,就可以使用观察法,还可以通过询问校门口的保安来获取数据。
调查法调查法是一种常见的数据收集方法,主要分为普查和抽样调查两大类。
普查就是为了某一特定目的而对所有考察对象进行的全面调查。
比如人口普查,就是对全国人民的人口、民族、年龄、性别等进行数据统计。
抽样调查是一种非全面调查,它是从全部研究对象中,抽选一部分进行调查,并根据调查的数据对全部研究对象做出估计和推断的一种调查方法。
比如在对学生餐饮满意度进行调查时,就只需要随机选取一部分学生进行调查询问即可,如图 1.3.2所示。
实验法实验法就是通过实验过程获取信息或结论,它需要在特定的实验场所、特殊的状态下,对调查对象进行实验。
例如,在实验室做化学实验时,我们可以通过实验结果得出结论,并记录相关的数据如图 1.3.3 所示。
网络信息收集法网络信息是指通过计算机网络发布、传递和存储的各种信息。
在互联网上输入信息的关键字,可以搜到所有相关联的内容。
这个数据收集的过程本来就具有筛选性和分析性,也就是说,网络收集所得到的数据,可能更接近我们想要的结果。
但是在使用网络信息收集法获取数据(见图1.3.4)时,我们仍然需要过滤和辨别信息,因为互联网的数据繁杂并且真假难辨。
课堂活动说一说,收集全班同学的体重和身高数据应该使用哪种方法?收集全班同学的体重和身高数据,应采用直接测量法,使用精确的体重秤和身高尺,在固定时间由专人操作测量,确保数据的准确性和一致性,同时记录和管理数据时需注意保护学生隐私,安全存储信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用身高和体重数据进行性别分类的实验报告(二)一、 基本要求1、试验非参数估计,体会与参数估计在适用情况、估计结果方面的异同。
2、试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分类器进行比较。
3、体会留一法估计错误率的方法和结果。
二、具体做法1、在第一次实验中,挑选一次用身高作为特征,并且先验概率分别为男生0.5,女生0.5的情况。
改用Parzen 窗法或者k n 近邻法估计概率密度函数,得出贝叶斯分类器,对测试样本进行测试,比较与参数估计基础上得到的分类器和分类性能的差别。
2、同时采用身高和体重数据作为特征,用Fisher 线性判别方法求分类器,将该分类器应用到训练和测试样本,考察训练和测试错误情况。
将训练样本和求得的决策边界画到图上,同时把以往用Bayes 方法求得的分类器也画到图上,比较结果的异同。
3、选择上述或以前实验的任意一种方法,用留一法在训练集上估计错误率,与在测试集上得到的错误率进行比较。
三、原理简述及程序框图1、挑选身高(身高与体重)为特征,选择先验概率为男生0.5女生0.5的一组用Parzen 窗法来求概率密度函数,再用贝叶斯分类器进行分类。
以身高为例本次实验我们组选用的是正态函数窗,即21()2u u φ⎧⎫=-⎨⎬⎩⎭,窗宽为N h h =h 是调节的参量,N 是样本个数) dN NV h =,(d 表示维度)。
因为区域是一维的,所以体积为N n V h =。
Parzen 公式为()ˆN P x =111N i i N N x x N V h φ=⎛⎫-⎪⎝⎭∑。
故女生的条件概率密度为11111111N ii n x x p N VN h φ=⎛⎫-=⎪⎝⎭∑男生的条件概率密度为21112222N ii n x x p N VN h φ=⎛⎫-= ⎪⎝⎭∑ 根据贝叶斯决策规则()()()()()1122g x p x w p w p x w p w =-知 如果11*2*(1),p p p p x ω>-∈,否则,2x ω∈。
流程图如下:2、要求是同时采用身高和体重数据作为特征,用Fisher 线性判别方法求分类器,将该分类器应用到训练和测试样本,考察训练和测试错误情况。
将训练样本和求得的决策边界画到图上,同时把以往用Bayes 方法求得的分类器也画到图上,比较结果的异同。
说明,取男生和女生的先验概率分别为0.5,0.5。
在设计贝叶斯分类器时,首先求各类样本均值向量,及2,1,1==∑∈i x N m ix ii ω,然后求各个样本的来内离散度矩阵,及()()2,1,=--=∑∈i m x m x s T iw x ii i,再求出样本的总类内离散度,及()()2211s p s p s ωωω+=,根据公式()211m m s -=-*ωω求出把二维X 空间投影到一维Y 空间的最好的投影方向。
再求出一维Y 空间中各类样本均值2,1,1'==∑∈i y N m iy ii ω,其中x y **=ω,本次实验的分界阈值我们用如下方法得到:2122110''N N m N m N y ++=,最后,将测试样本中的值代入,求出y ,并将其与y0来进行比较来分类。
根据课本对Fisher 线性判别法的介绍,得到的算法流程图如下:3、选择上述或以前实验的任意一种方法,用留一法在训练集上估计错误率,与在测试集上得到的错误率进行比较。
这里我们选择Fisher 线性判别法,用留一法来估计它在训练集上的错误率,并将结果与Fisher线性判别法对测试集进行判别时得到的错误率进行比较。
具体流程图如下:四、实验结果及分析总结1、得到结果如下表以身高作为特征h=4估计方法女生先验概率男生先验概率男生错误个数女生错误个数总错误男生错误率女生错误率总错误率以身高与体重作为特征h=7分析:通过比较可知,在用最大似然估计这种参数估计方法和Parzen这种非参数估计方法来进行分类时,最大似然估计判别的错误率低。
2、得到结果如下(1)、用Fisher线性判别方法求分类器,将分类器应用到训练和测试样本上,比较其错误率判别对象男生错误个数女生错误个数总错误男生错误率女生错误率总错误率测试样本27 2 29 10.8% 4% 9.67%训练样本8 4 12 16% 8% 12%分析:用训练样本得到的分类器测试测试样本时错误率低,测试结果较好,但测试训练样本时,其错误率较高,测试结果不好。
(2)、将训练样本和求得的决策边界画到图上先验概略为0.5,0.5从图中我们可以直观的比较出对训练样本Fisher判别比最大似然Bayes判别效果更好。
3、留一法测试结果如下:分析:用留一法在训练样本机上估计错误率时,错误率小于它在测试样本集上得到的错误率,且留一法在测试样本集上女生错误个数远低于男生错误个数。
五、体会这次实验,我们组用了接近三天的时间,首先,我们对题目要求进行认真分析,在确保对题目完全理解的基础上,开始一步一步分析,求解。
对每个小题,及其每一问,我们都经过查书,查资料,编代码这几个步骤,仔细分析每一步算法,得出流程图。
经过第一次作业的编程,本次编程我们都觉得轻松了很多,但还会出现一些细节上的错误,不过,这些在我们经过不断的调试之后都会被发现并解决。
总体而言,本次试验,让我们对Parzen窗法求类条件概率密度,以及Fisher 线性判别法都有了更大的了解。
代码:%特征是身高,先验概率为0.5、0.5时用Parzen窗法,贝叶斯分类器。
clc;clear all;[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f%f');[MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f%f');FA=[FH FW];MA=[MH MW];N1=max(size(FA));h1=4;hn1=h1/(sqrt(N1));VN1=h1/(sqrt(N1));N2=max(size(MA));h2=4;hn2=h2/(sqrt(N2));VN2=h2/(sqrt(N2));[tH tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f%f%*s');X=[tH tW];[M N]=size(X);s=zeros(M,1);A=[X(:,1) X(:,2) s];error=0;errorgirl=0;errorboy=0;errorrate=0;errorgirlrate=0;errorboyrate=0;girl=0;boy=0;bad=0;for k=1:M %测试集x=A(k);p=0.5;%p为属于女生的先验概率,则1-p为男生的先验概率for i=1:N1pp(i)=1/sqrt(2*pi)*exp(-0.5*(abs(x-FA(i)))^2/(hn1^2));%pp(i)是窗函数endp1=sum(1/VN1*pp');y1=1/N1*p1;%是女生的条件概率密度函数for j=1:N2qq(j)=1/sqrt(2*pi)*exp(-0.5*(abs(x-MA(j)))^2/(hn2^2));endq1=sum(1/VN2*qq');y2=1/N2*q1;%男生的概率密度函数,即其条件概率g=p*y1-(1-p)*y2;%g为判别函数if g>0if k<=50s(k,1)=0;%判为女生girl=girl+1;elseerrorboy=errorboy+1;endelseif g<0if k<=50errorgirl=errorgirl+1;elses(k,1)=1;%判为男生boy=boy+1;endelses(k,1)=-2;%不能判别是指等于0时的情况bad=bad+1;endenderrorgirlerrorboybadgirl=errorboy+girlboy=boy+errorgirlerror=errorgirl+errorboyerrorgirlrate=errorgirl/50errorboyrate=errorboy/250errorrate=error/M%特征是身高与体重,先验概率为0.5、0.5时用Parzen窗法,贝叶斯分类器。
clc;clear all;[FH FW]=textread('C:\Users\xuyd\Desktop\homework\FEMALE.txt','%f%f'); [MH MW]=textread('C:\Users\xuyd\Desktop\homework\MALE.txt','%f%f');FA=[FH FW];MA=[MH MW];N1=max(size(FA));h1=7;hn1=h1/(sqrt(N1));VN1=hn1^2;N2=max(size(MA));h2=7;hn2=h2/(sqrt(N2));VN2=hn2^2;[tH tW]=textread('C:\Users\xuyd\Desktop\homework\test2.txt','%f%f%*s'); X=[tH tW];[M N]=size(X);s=zeros(M,1);error=0;errorgirl=0;errorboy=0;errorrate=0;errorgirlrate=0;errorboyrate=0;girl=0;boy=0;bad=0;for k=1:MA=[X(k,1) X(k,2)];x=A;p=0.5;%p为属于女生的先验概率,则1-p为男生的先验概率pp=0;for i=1:N1fa=[FA(i,1) FA(i,2)];n=1/sqrt(2*pi)*exp(-0.5*abs((x-fa)*(x-fa)')/(hn1^2)); pp=pp+n;endp1=1/VN1*pp';y1=1/N1*p1;%是女生的条件概率密度函数qq=0;for j=1:N2ma=[MA(j,1) MA(j,2)];m=1/sqrt(2*pi)*exp(-0.5*abs((x-ma)*(x-ma)')/(hn2^2)); qq=m+qq;endq1=sum(1/VN2*qq');y2=1/N2*q1;%男生的概率密度函数,即其条件概率g=p*y1-(1-p)*y2;%g为判别函数if g>0if k<=50s(k,1)=0;%判为女生girl=girl+1;elseerrorboy=errorboy+1;endelseif g<0if k<=50errorgirl=errorgirl+1;elses(k,1)=1;%判为男生boy=boy+1;endelses(k,1)=-2;%不能判别是指等于0时的情况bad=bad+1;endenderrorgirlerrorboybadgirl=errorboy+girlboy=boy+errorgirlerror=errorgirl+errorboyerrorgirlrate=errorgirl/50errorboyrate=errorboy/250errorrate=error/M%用fisher线性判别法求阈值function [w,y0]=fisher(AA,BB)A=AA';B=BB';[k1,l1]=size(A);[k2,l2]=size(B);M1=sum(AA);M1=M1';M1=M1/l1;%男生均值向量M2=sum(BB);M2=M2';M2=M2/l2;%女生均值向量S1=zeros(k1,k1);%建立矩阵S2=zeros(k2,k2);for i=1:l1S1=S1+(A(:,i)-M1)*((A(:,i)-M1).');%男生的类内离散度矩阵endfor i=1:l2S2=S2+(B(:,i)-M2)*((B(:,i)-M2).');%女生的类内离散度矩阵endSw=0.5*S1+0.5*S2;%总类内离散度矩阵,先验概率0.5w=inv(Sw)*(M1-M2);%两列wT=w';%wT就是使Fisher准则函数JF(w)取极大值时的解,也就是d维X空间到1维Y空间的最好的投影方向for i=1:l1Y1(i)=wT(1,1)*A(1,i)+wT(1,2)*A(2,i);%求出二维男生样本集映射到一维时的量endfor i=1:l2Y2(i)=wT(1,1)*B(1,i)+wT(1,2)*B(2,i);%求出二维女生样本集映射到一维时的量endm1=sum(Y1)/l1;m2=sum(Y2)/l2;y0=(l1*m1+l2*m2)/(l1+l2);%%用fisher线性判别函数来判断clcclear all[filename,pathname,filterindex] = uigetfile('*.txt', '请读入男生训练集'); fileAddrs = [pathname,filename];[A1 A2]=textread(fileAddrs,'%f%f');[filename,pathname,filterindex] = uigetfile('*.txt', '请读入女生训练集'); fileAddrs = [pathname,filename];[B1 B2]=textread(fileAddrs,'%f%f');AA=[A1 A2];BB=[B1 B2];[w,y0]=fisher(AA,BB);wT=w';girl=0;boy=0;bad=0;errorgirl=0;errorboy=0;error=0;errorgirlrate=0;errorboyrate=0;errorrate=0;[filename,pathname,filterindex] = uigetfile('*.txt', '请读入测试集'); fileAddrs = [pathname,filename];[T1 T2]=textread(fileAddrs,'%f%f%*s');TT=[T1 T2];T=TT';[k3 l3]=size(T);for k=1:50y(k)=wT*T(:,k);if y(k)>y0errorgirl=errorgirl+1;else if y(k)<y0girl=girl+1;elsebad=bad+1;endendendfor k=51:300y(k)=wT*T(:,k);if y(k)>y0boy=boy+1;else if y(k)<y0errorboy=errorboy+1;elsebad=bad+1;endendenderrorgirlerrorboybadgirl=errorboy+girlboy=boy+errorgirlerror=errorgirl+errorboyerrorgirlrate=errorgirl/50errorboyrate=errorboy/250errorrate=error/l3%画图[filename,pathname,filterindex] = uigetfile('*.txt', '请读入男生训练集'); fileAddrs = [pathname,filename];[A1 A2]=textread(fileAddrs,'%f%f');[filename,pathname,filterindex] = uigetfile('*.txt', '请读入女生训练集'); fileAddrs = [pathname,filename];[B1 B2]=textread(fileAddrs,'%f%f');AA=[A1 A2];BB=[B1 B2];A=AA';B=BB';[k1,l1]=size(A);[k2,l2]=size(B);[w,y0]=fisher(AA,BB);for i=1:l1x=A(1,i);y=A(2,i);%x是身高,y是体重plot(x,y,'R.');hold onendfor i=1:l2x=B(1,i);y=B(2,i);plot(x,y,'G.');hold onenda1=min(A(1,:));%男生身高最小值a2=max(A(1,:));%男生身高最大值b1=min(B(1,:));%女生身高最小值b2=max(B(1,:));%女生身高最大值a3=min(A(2,:));%男生体重最小值a4=max(A(2,:));%男生体重最大值b3=min(B(2,:));%女生体重最小值b4=max(B(2,:));%女生体重最大值if a1<b1a=a1;elsea=b1;%a是所有人中身高最小值endif a2>b2b=a2;elseb=b2;%b是所有人中身高最大值endif a3<b3c=a3;elsec=b3;%c是所有人中体重最小值endif a4>b4d=a4;elsed=b4;%d为所有人中体重最大值endx=a:0.01:b;y=(y0-x*w(1,1))/w(2,1);plot(x,y,'B');hold on;%身高体重相关,判别测试样本%手动先验概率P1=0.5;P2=0.5;FA=A;MA=B;a=cov(FA')*(length(FA)-1)/length(FA); b=cov(MA')*(length(MA)-1)/length(MA); W1=-1/2*inv(a);W2=-1/2*inv(b);Ave1=(sum(FA')/length(FA))';Ave2=(sum(MA')/length(MA))';w1=inv(a)*Ave1;w2=inv(b)*Ave2;w10=-1/2*Ave1'*inv(a)*Ave1-1/2*log(det(a))+log(P1);w20=-1/2*Ave2'*inv(b)*Ave2-1/2*log(det(b))+log(P2);syms x ;syms y ;h=[x y]';h1=h'*W1*h+w1'*h+w10;h2=h'*W2*h+w2'*h+w20 ;h=h1-h2;ezplot(h,[130,200,30,100])%功能:应用Fisher准则判断一个身高体重二维数据的性别vector=[x;y];yy=(w.')*vector;if yy>y0value=2;%表示样本是男生elsevalue=1;%表示样本是女生end%功能:使用留一法求训练样本错误率[A1 A2]=textread('C:\Users\Administrator\Desktop\模式识别\homework\MALE.txt','%f%f');[B1 B2]=textread('C:\Users\Administrator\Desktop\模式识别\homework\FEMALE.txt','%f%f');AA=[A1 A2];BB=[B1 B2];A=AA';B=BB';m1=2;m2=2;n1=50;n2=50;tempA=zeros(m1,n1-1);count=0;for i=1:n1for j=1:(i-1)tempA(:,j)=A(:,j);endfor j=(i+1):n1tempA(:,j-1)=A(:,j);end[w,y0]=fisher((tempA.'),BB);flag=classify_CH(A(1,i),A(2,i),w,y0); if flag==1count=count+1;endendtempB=zeros(m2,n2-1);for i=1:n2for j=1:(i-1)tempB(:,j)=B(:,j);endfor j=(i+1):n2tempB(:,j-1)=B(:,j);end[w,y0]=fisher(AA,(tempB.'));flag=classify_CH(B(1,i),B(2,i),w,y0); if flag==2count=count+1;endenderror_ratio=count/(n1+n2)%使用留一法求测试样本错误率[T1 T2]=textread('C:\Users\Administrator\Desktop\模式识别\homework\test2.txt','%f%f%*s');TT=[T1 T2];T=TT';[k3 l3]=size(T);TG=zeros(2,50);TB=zeros(2,250);for i=1:50TG(:,i)=T(:,i);endfor j=51:l3TB(:,j-50)=T(:,j);endm1=2;m2=2;n1=50;n2=250;tempA=zeros(m1,n1-1);count=0;for i=1:n1for j=1:(i-1)tempA(:,j)=TG(:,j);endfor j=(i+1):n1tempA(:,j-1)=TG(:,j);end[w,y0]=fisher((tempA.'),TB');flag=classify_CH(TG(1,i),TB(2,i),w,y0);if flag==1count=count+1;endendtempB=zeros(m2,n2-1);for i=1:n2for j=1:(i-1)tempB(:,j)=TB(:,j);endfor j=(i+1):n2tempB(:,j-1)=TB(:,j);end[w,y0]=fisher(TG',(tempB.'));flag=classify_CH(TB(1,i),TB(2,i),w,y0); if flag==2count=count+1;endenderror_ratio=count/(n1+n2)。