Oracle体系结构简要介绍
oracle 体系架构

三、oracle 体系结构1、oracle内存由SGA+PGA所构成2、oracle数据库体系结构数据库的体系结构是指数据库的组成、工作过程与原理,以及数据在数据库中的组织与管理机制。
oracle工作原理:1)、在数据库服务器上启动Oracle实例;2)、应用程序在客户端的用户进程中运行,启用Oracle网络服务驱动器与服务器建立连接;3)、服务器运行Oracle网络服务驱动器,建立专用的服务器进程执行用户进程;4)、客户端提交事务;5)、服务器进程获取sql语句并检查共享池中是否有相似的sql语句,如果有,服务器进程再检查用户的访问权限;否则分配新的sql共享区分析并执行sql语句;6)、服务器从实际的数据文件或SGA中取得所需数据;7)、服务器进程在SGA中更新数据,进程DBWN在特定条件下将更新过的数据块写回磁盘,进程LGWR在重做日志文件中记录事务;8)、如果事务成功,服务器进程发送消息到应用程序中。
3、oracle服务器i、oracle服务器由oracle数据库和oracle实例组成。
ii、oracle数据库是一个数据的集合,存放在数据文件里,该集合被视为一个逻辑单元。
iii、oracle实例由管理数据库的后台进程和内存结构所构成。
4、oracle实例i、Oracle实例是内存结构和后台进程的集合ii、启动Oracle实例的过程,即:分配内存、启动后台进程iii、Oracle实例的内存包括SGA和PGA;当启动实例的时候分配SGA;当服务器进程建立时分配PGA;一般情况下,SGA:PGA=8:1分配内存。
iiii、Oracle实例的后台进程包括SMON、PMON、DBWR、LGWR、ARC、CKPT等。
5、SGA(System Global Area): 系统全局区i0、数据库信息存储于SGA,由多个数据库进程共享。
i1、SGA包括:共享池、数据缓冲区、日志缓冲区、Large池、Java池、Stream池。
描述oracle数据库体系结构的组成及其关系。

描述oracle数据库体系结构的组成及其关系。
Oracle数据库体系结构由以下几个部分组成:1. 实例(Instance):实例是在计算机内存中运行的一个进程,负责管理数据库的操作。
每个实例都有自己的内存空间和进程,可以同时运行多个实例。
2. 数据库(Database):数据库是一个存储数据的容器,包含了表、视图、索引等对象。
一个实例可以管理多个数据库,每个数据库由一个或多个数据文件组成。
3. 数据文件(Data File):数据文件是用来存储数据库的实际数据的文件,包含了表、索引等对象的数据。
一个数据库可以有多个数据文件,每个数据文件具有独立的文件名和路径。
4. 控制文件(Control File):控制文件是用来记录数据库的结构和状态信息的文件,包括数据库名、数据文件的路径、表空间的信息等。
一个数据库通常有一个或多个控制文件。
5. 日志文件(Redo Log File):日志文件是用来记录数据库的变化操作的文件,包括数据更改、事务回滚等。
日志文件用于实现数据库的恢复和数据的一致性。
每个数据库通常有多个日志文件。
6. 表空间(Tablespace):表空间是数据库中逻辑数据存储的单位,用来管理和组织对象。
每个表空间由一个或多个数据文件组成,不同表空间可以包含不同的数据对象。
7. 段(Segment):段是逻辑存储结构的基本单位,是指数据库中的一个连续空间。
每个表、索引等对象都占用一个或多个段。
8. 区(Extent):区是段的扩展单位,是一组连续的数据块。
一个段由多个区组成。
9. 块(Data Block):块是数据库存储的最小单位,通常是8KB大小。
每个数据文件由多个块组成。
以上组成部分之间的关系如下:- 实例与数据库:一个实例可以管理多个数据库,每个数据库都有自己的实例。
- 数据库与数据文件:一个数据库可以由一个或多个数据文件组成,每个数据文件存储数据库的实际数据。
- 实例与控制文件:一个实例通常有一个或多个控制文件,控制文件记录了数据库的结构和状态信息。
oracle体系架构与使用技巧

oracle体系架构与使用技巧Oracle是目前最为流行的关系数据库管理系统之一,其体系架构设计合理,功能强大,使用技巧独特。
本文将从Oracle体系架构和使用技巧两个方面进行阐述。
一、Oracle体系架构1. 逻辑架构Oracle的逻辑架构包括三层:用户层、逻辑层和物理层。
用户层是最上层,提供给用户进行数据操作的接口;逻辑层负责数据的处理和管理,包括SQL解析、查询优化、事务管理等;物理层负责数据的存储和访问,包括表空间、数据文件、段、块等。
2. 实例架构Oracle实例架构由后台进程和内存结构组成。
后台进程包括数据库启动进程、系统监控进程、后台管理进程等,负责数据库的管理和维护;内存结构包括共享池、数据字典缓冲区、重做日志缓冲区等,用于存储和管理数据库的数据和元数据。
3. 存储架构Oracle的存储架构包括表空间、段和块三个层次。
表空间是逻辑存储单位,由一个或多个数据文件组成;段是逻辑存储单位,由一组相邻的区域组成;块是最小的存储单位,每个块的大小一般为8KB。
二、Oracle使用技巧1. SQL优化为了提高查询效率,可以使用索引、合理设计SQL语句、避免全表扫描等技巧。
可以通过使用EXPLAIN PLAN命令分析SQL语句的执行计划,找出执行效率较低的地方进行优化。
2. 数据备份与恢复为了保证数据的安全性,需要定期进行数据备份。
可以使用Oracle 提供的工具如RMAN进行全量备份或增量备份,并定期测试备份数据的可恢复性,以防止数据丢失。
3. 数据库性能监控通过监控数据库的性能指标,可以及时发现并解决性能问题。
可以使用Oracle提供的AWR报表、ASH报表等工具进行性能分析,找出性能瓶颈,并进行调整和优化。
4. 事务管理Oracle提供了强大的事务管理功能,可以通过设置事务隔离级别、使用事务控制语句如COMMIT和ROLLBACK等来确保数据的一致性和完整性。
5. 高可用性和容灾为了保证系统的高可用性,可以使用Oracle提供的RAC集群技术,实现数据库的水平扩展和故障切换。
(参考资料)oracle 体系结构详解
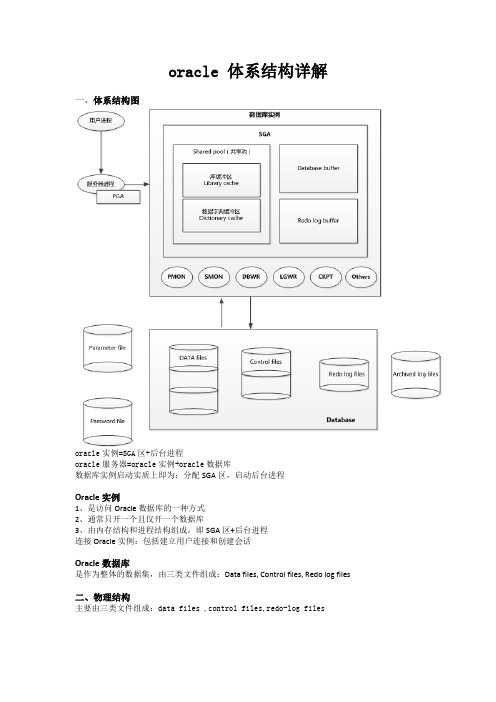
oracle 体系结构详解一、体系结构图oracle实例=SGA区+后台进程oracle服务器=oracle实例+oracle数据库数据库实例启动实质上即为:分配SGA区,启动后台进程Oracle 实例1、是访问Oracle 数据库的一种方式2、通常只开一个且仅开一个数据库3、由内存结构和进程结构组成,即SGA区+后台进程连接Oracle实例:包括建立用户连接和创建会话Oracle数据库是作为整体的数据集,由三类文件组成:Data files, Control files, Redo log files二、物理结构主要由三类文件组成:data files ,control files,redo-log files1.data files:数据文件,存放基本表信息(即表中数据等)、索引信息(系统内建有索引表)、回退信息(主要为数据的rollback)、临时信息(如有orderby 等操作时系统有临时信息)、系统引导信息(如数据字典等)2、control files:控制文件(二进制的)。
存放库物理结构、库名、库创建日期、序列号(存有同步信息);控制文件至少有两个一摸一样的,用做备份用参数Controlfiles=/../../文件名1,/../../文件名2;指定3、redo log files:回退日志文件,存放修改前后的信息,主要用于数据的恢复,一个数据库至少有两个redo log files文件,以便可以循环记录信息注:三类文件都有序列号,必须同步才能使用,且已Control files中的序列号为准,其他的必须与其保持一致除了上面三类文件还有:Parameter file(参数文件),Password file(口令文件),Archived log files(归档文件)等参数文件:有二进制、文本两种,用于设定参数的值。
二进制参数文件可以及时更改,即时生效;文本参数文件需重启口令文件:可用orapwd.exe 建口令文件。
Oracle体系结构简介

Oracle体系结构简介一、数据库(Database)数据库是一个数据的集合,不仅是指物理上的数据,也指物理、存储及进程对象的一个组合。
Oracle是关系型数据库治理系统(RDBMS)。
二、实例(Instance)数据库实例(也称为服务器Server)就是用来访问一个数据库文件集的一个存储结构及后台进程的集合。
它使一个单独的数据库可以被多个实例访问(也就是ORACLE并行服务器-- OPS)。
实例和数据库的关系如下决定实例的组成及大小的参数存储在init.ora文件中。
三、部结构表、列、数据类型(T able、Column、Datatype)Oracle中是以表的形式存储数据的,它包含若干个列;列是表的属性的描述;列由数据类型和长度组成;Oracle中定义的数据类型主要有CHAR、VARCHAR2、NUMBER、DATE、LONG、LOB、BFILE等,具体的数据类型情况将在本栏目的相关文档中具体介绍。
约束条件(Constraint)表中以及表间可以存在一些数据上的逻辑关系、限制,也就是约束。
Oracle中的约束主要有主键(PK)、外键(FK)、检查(CHECK)、唯一性(UNIQUE)等几种;拥有约束的表中每条数据均必须符合约束条件。
抽象数据类型(Abstract Datatype)可以利用CREATE TYPE命令创建自定义的抽象数据类型。
分区(Partition)可以利用分区将大表分隔成若干个小的存储单元,逻辑上仍然是一个完整的独立单一实体,以减小访问时数据的查找量,提高访问、存储效率用户(User)用户不是一个物理结构,但是它与数据库的对象拥有非常重要的关系--用户拥有数据库对象,以及对象的使用权。
模式(Schema)用户拥有的对象集合称为模式。
索引(Index)数据库中每行记录的物理位置并不重要,Oracle为每条记录用一个ROWID来标识,ROWID记录了记录的准确位置。
索引是供用户快速查找到记录的数据库结构。
Oracle数据库体系结构
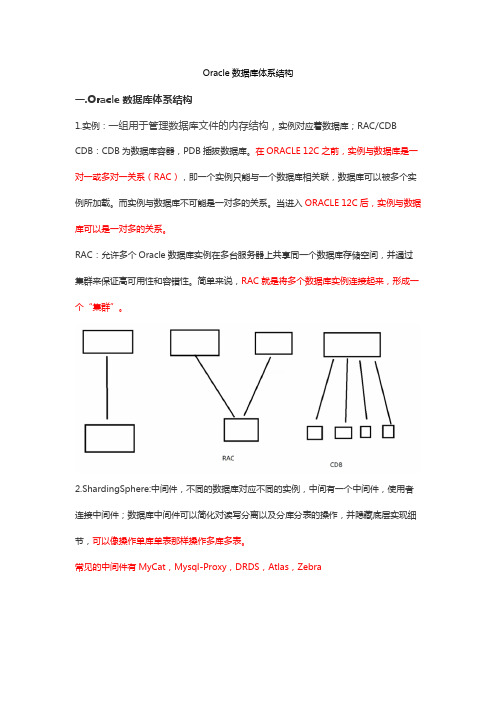
Oracle数据库体系结构一.Oracle数据库体系结构1.实例:一组用于管理数据库文件的内存结构,实例对应着数据库;RAC/CDB CDB:CDB为数据库容器,PDB插拔数据库。
在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC),即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。
而实例与数据库不可能是一对多的关系。
当进入ORACLE 12C后,实例与数据库可以是一对多的关系。
RAC:允许多个Oracle数据库实例在多台服务器上共享同一个数据库存储空间,并通过集群来保证高可用性和容错性。
简单来说,RAC就是将多个数据库实例连接起来,形成一个“集群”。
2.ShardingSphere:中间件,不同的数据库对应不同的实例,中间有一个中间件,使用者连接中间件;数据库中间件可以简化对读写分离以及分库分表的操作,并隐藏底层实现细节,可以像操作单库单表那样操作多库多表。
常见的中间件有MyCat,Mysql-Proxy,DRDS,Atlas,Zebra二.Orcal数据库体系结构:Orcal服务器=数据库+实例1.实例是暂时的,它只不过是一组逻辑划分的内存结构和进程结构,它会随着数据的关闭而消失数据库它就是一堆物理文件(控制文件、数据文件、日志文件等等)它呢是永久存在的数据库和实例是一对一的,这种结构我们一般称为单实例体系结构;既然有一对一,那就会有一对多,在复杂的分布式结构中,一个数据库可以对多个实例,多个实例之间可以通过网络来进行数据的一个交互或着交换2.PGA:程序全局区,为单独的服务器进程存储私有数据的内存区域(SAG属于公共资源,PAG是私有的)3.SGA:系统全局区,所有用户都可以访问的共享内存区域启动Oracle数据库时,系统先在内存内规划一个固定区域,用来储存用户需要的数据,以及Oracle运行时必备的系统信息4.后台进程结构,此处只罗列必须启动的5个后台进程系统监控器SMON:负载检查数据库一致性,有必要会在数据库打开时启动数据库恢复进程监视器PMON:负责一个Orcal数据库进程失败时清理资源,会定期唤醒或者被其他主动事务主动唤醒数据库写进程DBWR:负责将更改的数据从“数据库高速缓冲区”写入“数据文件”日志写进程LGWR:负载把日志数据写到练级日志文件检查点进程SKPT:负责检查点操作,主要检查数据库状态一致性和记录系统变更时间5.三个文件1)控制文件:存储数据库结构,一个控制文件只属于一个数据库,包含数据文件日志文件信息及相关状态归档信息,2)数据文件:存储数据,xxx.dbf文件存储着系统数据,数据字典数据,索引数据及用户存储的数据3)日志文件:存储与事务有关的重做日志三.逻辑存储结构1.块是Oracle用来管理存储的最小单元,也是最小的逻辑存储结构2.区是Oracle数据库分配空间的最小单位3.段由多个区组成,这些区可以是连续的,也可以是不连续的4.表空间是Oracle数据库的最大逻辑划分区域,通常用来存放数据表、索引、回滚段等数据对象。
Oracle体系结构介绍
Page 51
Redo log Database buffer buffer cache
Shared pool Library cache
Dictionary cache User global area
Server process
Control files
LGWR
ARCn
SQL> UPDATE employees 2 SET salary=salary*1.1
插入光盘或者解压oracle cpio包 ~database/runInstaller.sh Windows平台,运行setup.exe 按照向导一步一步安装。 指定安装路径 选择安装:企业版,标准版 选择只安装软件或者创建数据库。
Oracle patch 在oracle的metalink网站上下 载。 目前 11g的版本patch:11.2.0.2 下载后,上传到指定服务器上,解压后安装。 11g R2 patch ,直接作为数据库软件安装,这 个10g以前的版本不一样。
1.Oracle的起源 2.Oracle的发展 3.Oracle11g安装 4.体系结构概述 5.启动与关闭
源于1970年6月IBM公司的《大型共享数据库数据的关 系模型》- Edgar Frank Codd。是关系型数据库软件 的起源 1977年6月,Larry Ellison与Bob Miner和Ed Oates在 硅谷创办软件开发实验室(Software Development Laboratories,SDL)开始策划构建可商用的关系型数 据库管理系统(RDBMS)。 1979年,SDL更名为关系软件有限公司(Relational Software,Inc.,RSI),1983年,为了突出公司的核 心产品,RSI再次更名为ORACLE。ORACLE(字典里的 解释有“神谕, 预言”之意)是一切智慧的源泉。
简述oracle体系结构
简述oracle体系结构
Oracle体系结构
Oracle是一种支持分布式数据库管理系统,其体系结构主要包
括E-R图,表和索引,存储过程和视图, SQL,PL/SQL程序和组件,等等。
1. E-R图
E-R图是一种关系数据库管理系统的基本模型,其中实体表示客观事物,关系表示实体之间的联系。
E-R图可以被用来描述实体和它们之间的关系,以及实体的属性和它们之间的关系。
2.表和索引
表是由一系列列组成的逻辑结构,它们包含每行和每列的数据。
索引是一种特别的表,可以被用来提高表的搜索速度和性能。
3.存储过程和视图
存储过程是一种特定类型的程序,它们可以被用来完成某些操作,比如查询和更新。
视图是一种准备好的查询,它们可以被用来返回数据库中的数据。
4.SQL,PL/SQL程序和组件
SQL(Structured Query Language)是一种用于在数据库中执行查询和更新操作的语言,是一种面向关系型数据库的核心语言。
PL/SQL是一种可以嵌入SQL语句的程序设计语言,用来定义复杂的
查询,更新和实现回调函数。
组件是一种模块化的程序,用来构建更复杂的系统。
Oracle体系结构
Oracle体系结构⼀、Oracle DB服务器体系结构概览。
Oracle DB 服务器体系结构包含以下三种主要结构:内存结构、进程结构和存储结构。
基本的 Oracle DB 系统由 Oracle DB 和数据库实例组成。
数据库包括物理结构和逻辑结构。
由于物理结构和逻辑结构是分开的,因此管理数据的物理存储时不会影响对逻辑存储结构的访问。
实例由与该实例关联的内存结构和后台进程构成。
每当启动⼀个实例时,都会分配⼀个称为系统全局区 (SGA) 的共享内存区,并启动后台进程。
进程是在计算机的内存中运⾏的作业。
进程被定义为操作系统中可运⾏⼀系列步骤的“控制线程”或机制。
启动数据库实例后,Oracle 软件会将该实例与特定数据库相关联。
该操作称为“装载数据库”。
之后⽤户可以打开数据库,即授权⽤户可以对其进⾏访问。
注:Oracle ⾃动存储管理 (ASM) 在管理内存和进程组件时使⽤实例概念,不与特定数据库关联。
访问数据库⽤户并不是数据库⽤户,是某⼀个⽤户下⾯acount表。
连接:⽤户进程和实例之间的通信。
会话:⽤户通过⽤户进程与实例之间建⽴的特定连接。
会话中包含很多事务,事物的状态是commit、rollback。
1.Oracle内存结构Oracle DB 创建并使⽤内存结构来满⾜多种需要。
例如,使⽤内存来存储正在运⾏的程序代码、在各⽤户之间共享的数据以及所连接的每个⽤户的专⽤数据区域。
⼀个实例有两个关联的基本内存结构:程序全局区 (PGA) :包含某个服务器进程或后台进程的数据及控制信息的内存区域。
PGA 是 Oracle DB 在服务器进程或后台进程启动时创建的⾮共享内存。
服务器进程对PGA 的访问是独占式的。
每个服务器进程和后台进程都具有⾃⼰的 PGA。
PGA主要⽤于存放会话连接信息,排序操作(order by)帮助数据库减轻处理SQL的压⼒。
系统全局区 (SGA) :⼀组共享的内存结构(称为 SGA 组件),其中包含⼀个 Oracle DB 实例的数据和控制信息。
NO.1Oracle数据库体系结构简单概念
1:Oracle数据库体系结构(Oracle服务器)由Oracle实例和Oracle数据库组成。
Oracle实例:内存结构+进程结构Oracle数据库:Oracle存储结构1.1:内存结构主要组成部分:共享池,大池,流池,数据库缓冲区高速缓存,重做日志缓冲区,JAVA池1.1.1:数据库高数缓存区:是Oracle用户执行SQL的工作区域,有了这个区域可以提高用户的访问速度(可以动态调整大小,也可以自动管理)1.1.2:重做日志缓冲区:是存放更改矢量的短暂的临时区域。
(大小固定不变,实例启动时就被固定,无法自动管理)1.1.3:共享池:是库缓存,数据字典缓存,PL/SQL区域,SQL查询和PL/SQL 函数结果缓存。
这个区域比较复杂,说简单点就一个大的共享区,用户提高各种SQL语句解析,解析PL/SQL对象的速度。
(共享池的大小是可以动态调整的,也可以知道管理)1.1.4:大池:主要是供共享服务器进程使用,跟一些需要大内存的进程使用。
本区域是可选区域。
(大小是可以动态调整跟自动管理)1.1.5:JAVA池:只有应用程序需要运行数据库中的JAVA存储过程时,才需要JAVA池。
(大小是可以动态调整跟自动管理)1.1.6:流池:供Oracle流使用。
(大小是可以动态调整跟自动管理)1.2:进程结构:主要组成部分:SMON, PMON, DBWn, LGWR,ARCn,CKPT1.2.1:SMON(系统监视区):从数据库打开阶段时验证数据文件和联机日志文件,打开数据库后执行各种内部管理任务。
所以此进程对数据的安全与数据库的性能有很关键的作用。
1.2.2:PMON(进程监视区):监视所以服务器进程,如用户回话退出,注销,都由PMON进程来负责监控。
1.2.3: DBWN(数据写入器):用于将数据库高速缓存区的脏数据写入数据文件中。
使用极懒的算法来执行写入操作(DBW,会执行写入操作的情况:1:没有任何缓冲区(全新不脏的),2:脏缓冲区过多(内部阈值FAST_START_MTTR_TARGET决定),3:遇到3秒超时,4:遇到检查点的时候(完全检查点还是增量检查点?)1.2.4:LGWR(日志写入器):用于将重做日志缓存区的数据写入联机日志文件中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle体系结构简要介绍1.o racle数据库软件介绍oracle数据库包括:oracle数据库和oracle实例两个东西。
Oracle实例指的是:oracle 启动后占用的内存和后台进程的总称;oracle数据库是实例和数据文件的总称。
数据库关闭后数据库实例就不存在了,数据库文件一直存在。
Oracle是由oracle软件和oracle数据库组成,oracle数据库主要指的是三类文件,分别是控制文件(*.ctl)、日志文件(*.log)、数据文件(*.dbf)。
2.o racle中内存结构介绍oracle数据库启动起来后有两大内存结构,一是SGA(系统全局区),二是PGA,其中SGA 是用来共享的,PGA是用来给进程使用的。
2.1SGA介绍Sga是就是oracle系统的全局区,在linux和nuix中用ipcs -m命令来查看占用的共享内存。
Sga包括:共享池(shared pool)、stream池(stream pool)、大型池(large pool)、java 池、数据库缓冲区高速缓存(buffer cache)、重做日志缓冲区(log buffer)。
其中主要的缓冲区包括:共享池(shared_pool)、数据库高速缓存区(db_cache)、重做日志缓冲区(log_buffer),最容易出问题的也是这三个。
在plsql中可以通过show parameters sga 或者show sga 来查看sga的参数配置。
2.1.1共享池(shard pool)共享池(shard pool)主要用来缓存SQL语句以及所对应的SQL执行计划。
参数是shared_pool_size。
SQL语句的执行计划存放在shard pool中,下次去执行的时候先到shard pool中去找,这样大大减少资源的消耗。
SQL语句的解析以及执行计划的缓存、shard pool的访问,都是有server process 来做的。
2.1.2数据库缓冲区高速缓存(buffer cache)数据库缓冲区高速缓存(buffer cache)主要用来缓存DBF的数据,这些数据通过SQL语句的执行计划得来的。
参数是db_cache_size 。
数据库缓存区高速缓存对应的是数据库写进程(DBWN),数据库写进程(DBWN)对应的是数据文件和控制文件。
2.1.3重做日志缓冲区(log buffer)重做日志缓冲区(log buffer)主要用来存放日志的。
参数是log_buffer。
重做日志缓冲区对应的是日志写进程(LGWR),日志写进程(LGWR)对应的数据文件是重做日志文件,也就是日志文件。
2.1.4stream 池(stream pool)stream 池(stream pool)是由oracle的stream来使用的。
参数是streams_pool_size。
2.1.5大型池(large pool)大型池(large pool)用于为某些大型的进程提供大量的内存分配,如数据备份等。
参数是:lorge_pool_size2.1.6java 池(java pool)java 池(java pool)用于java虚拟机中特定会话的所有java代码和数据,参数是:java_pool_size。
2.1.7修改SGA参数的语法:在10g和11g这2个版本中,空间的大小一般都是oracle自动划分出来的,也可以手动设置,它们都是动态的,所以更改后不会立即生效,需要重启,使用命令:alter system set sga_max_size=xxxM scope=spfile;和alter system set sga_target = xxxM scope=spfile;sga_max_size必须大于等于sga_target,并且在设置sga的值大小时候是根据总内存大小的60%的70%-80%,pga的大小是根据总内存大小的60%的20-30%。
2.2PGA介绍Pga是用来个进程使用的,在oracle10g中不仅前台进程分配了PGA空间,后台进程也分配了PGA空间。
它是私有全局区,主要用来存放每个进程来了后单独存放内存区域。
2.3oracle 实例介绍把oracle启动起来后分配的内存和进程统称为oracle实例,也就是说oracle启动起来后就会产生一个实例,当oracle数据库关闭后数据库实例就会消失了。
一个数据库可以对应多个实例,如oracle,一般是双数,如2、4、6、8,8台机器用的很少。
3. oracle中进程介绍oracle中有六大进程,分别是:检查点进程(CKPT)、系统监视器(SMON)、进程监视器(PMON)、数据库写进程(DBWN)、日志写进程(LGWR)、归档进程(ARCN)。
Oracle中进程共分为三类,分别是用户进程、服务进程、后台进程。
其中后天进程伴随实例的启动而启动,他们主要是维护数据库的稳定,相当于一个企业中的管理者及内部服务人员,他们并不直接给用户提供服务。
3.1 数据库写进程(DBWN)Database write(DBWN)数据库写进程,它的作用是把SGA中被修改的数据同步到磁盘文件中,保证Buffer cache 中有足够的空闲数据块的数量。
用来处理数据库缓冲区的数据写到硬盘。
触发条件是:1.检查点;2.一个服务进程在设定的时间内没有找到空闲块;3、每隔三秒钟自动唤醒一次。
设置:DB_WRITER_PROCESSES用来定义DBWn进程数量。
(commit命令只是把记录修改写入日志文件,不是把修改后的数据写入数据文件,下面还会提到。
)从buffer cache中将数据写入DBF的时候,是由DBWN进程来完成的。
3.2 日志写进程(LGWR)Log write(LGWR)日志写进程,它的作用是把log buffer中的日志内容写入联机的日志文件中,释放log用户的buffer空间。
触发条件是:1.用户发出commit命令。
(在oracle中称为快速提交机制(fast commit):把redo log buffer中的记录写入日志文件,写入一条已提交的记录);2.三秒钟定时唤醒;3.log buffer 超过1/3,或者日志数据量超过1M;4.DBWR进程触发:DBWR试图将脏数据写入磁盘先检查它的相关rode记录是否写入联机日志文件,如果没有就通知LGWR进程,在oracle中称为提交写机制(write ahead):redo记录先于数据记录被写入磁盘。
将rode log buffer中的日志写入到redo log日志文件里去,是由LGWR来完成的。
3.3 检查点进程(CKPT)Checkpoint(CKPT)检查点进程,它的作用是维护数据库的一致性状态,检查点时刻检查数据文件盒SGA中的内容一致,这不是一个单独的进程,要和前面两个进程一起工作,DBWR写入脏数据,同事触发LGWR进程。
用于将数据库当前的状态写在控制文件和数据文件的头部。
CKPT更新控制文件中检查点的记录。
触发条:日志切换(log switch)会触发检查点。
3.4 进程监视器(PMON)Process monitor (PMON)维护用户进程或者进程监视器,它的作用是1、发现用户进程异常终止,并进行清理。
释放占用资源。
(清理异常终止用户使用的锁)。
2、向监听程序动态注册实例。
触发条件是:定时被唤醒,其他进程也会主动唤醒它。
3.5 系统监视器(SMON)System monitor(SMON)实例维护或者系统监视器,它的作用是1、负责实例恢复,前滚(Roll Forward)恢复到实例关闭时刻的状态,使用最后一次检查点后的日志进行重做。
这时包括提交和未提交的事务。
打开数据库进行回滚(roll back),回滚未提交的事务。
(oracle承诺commit之后的数据不会丢失,现在我们可以大致的了解oracle 是如何实现这个承诺的,以及在数据安全性和数据库性能之间的平衡选择);2、负责清理临时段,已释放空间。
触发条件是:定期被唤醒或者被其他事务主动唤醒。
3.6 归档进程(ARCN)Archive (ARCN)归档操作或归档进程,它的作用是发生日志切换时把写满的联机日志文件拷贝到归档目录中。
触发条件是:日志切换时被LGWR唤醒。
4.o racle中三大文件介绍oracle中的三大文件分别是:数据库文件(*.dbf)、控制文件(*.ctl)和日志文件(*.log)。
数据文件。
4.1 数据文件(dbf)数据文件中存放的是用户提交后的相关数据,都是commit提交后实实在在的数据。
4.2 控制文件(ctl)控制文件中存放了一个数据库的物理结构信息(包括数据库有多少个数据文件,分别存放在哪里等信息),数据库当前运行的状态信息等。
4.3 日志文件(log)日志文件中存放的是oracle用户对数据库所做的所有的操作,全部会以日志的方式记录到数据文件中,也就是说日志文件里面记录着数据文件的每一个数据库所有变化的过程。
5.用户进程介绍(server process)当用户访问数据库的时候就会创建一个server process,并且为server process 创建一个PGA内存。
Server process 是实例的一个进程。
从DBF中将数据读取到buffer cache中这个过程是由server process来完成的。
DBWN和LGWR都是后台进程,server process 是前台进程,也就是说server process只是负责将数据从DBF中读取出来存放在内存中进行修改,将内存(buffer cache)中的数据写回DBF不是server process来完成的,而是由有DBRN来完成的。
Server process是直接为用户服务的,用户把SQL语句给了server process,然后server process做了以下几件事情:第一、对SQL语句进行解析,将SQL语句变为执行计划;第二、然后去执行解析好的执行计划;第三、获取相关数据,将数据存放在buffer cache中;第四、将获取到存放在buffer cache 中,最后将buffer cache中的数据返回给用户。
SQL语句对标的修改都是在内存里面修改的,通过server process来完成,所有的日志都是server process产生的。
将修改完成的数据从内存(buffer cache)写入到数据文件DBF中是由DBWn来完成的,DBWN进程负责将server process修改的数据写回磁盘,DBWN是后台进程,server process 是前台进程。
Server process 只负责读取数据,server process是直接给用户提供服务的,要是server process慢的话用户就会感觉数据库比较慢,所以我们希望server process做最有意义的事情,后台进程能做的事情尽量给后台进程来完成,不要给server process来完成。