Unicode字符集
字符编码(1)——Unicode,utf-8

字符编码(1)——Unicode,utf-8字符编码编码是⼀个将⼀组Unicode字符转换业个字节序列的过程。
⽽解码是将⼀个编码字节序列转换为⼀组Unicode字符的过程。
Unicode字符是什么?Unicode字符集可以简写为UCS,也就是Unicode charactor setUnicode编码是国际组织制定的可以容纳世界上所有⽂字和符号的字符编码⽅案。
它通过0到0x10FFFF来映射字符,最多可容纳1114112个字符(16进制的10FFFF的值是1114111,然后加⼀个0x000000就是1114112个)。
可以看⼀下1114112的⼆进制表⽰形式为:1 0001 00000000 00000000UTF是什么?UTF是Unicode转换格式的意思,是UCS Transformation Format的缩写。
Utf-8UTF-8以字节为单位对Unicode进⾏编码。
utf-8特点是对不同范围的字符⽤不同长度的编码。
从Unicode到UTF-8的编码⽅式如下:Unicode编码(16进制) ║ UTF-8 字节流(⼆进制)000000 - 00007F ║ 0xxxxxxx000080 - 0007FF ║ 110xxxxx 10xxxxxx000800 - 00FFFF ║ 1110xxxx 10xxxxxx 10xxxxxx010000 - 10FFFF ║ 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx例如:“赵”这个字的Unicode编码(16进制表⽰⽅法)是:8d 75这个编码在.net中可以通过ToString()⽅法来实现。
为了进⾏后边的说明。
这⾥先给出测试⽤的转换⽅法:public static class CharSetHelper{public static string TransCoding(this int iValue,eTrans eType){return Convert.ToString(iValue, (int)eType);}public static string GetCorrectCoding(this string selfChar, Encoding encoding, eTrans eType){int iUnicode = (int)char.Parse(selfChar);return iUnicode.TransCoding(eType);}}public enum eTrans{Binary=2,Octonary=8,Decimal=10,Hexadecimal=16}⼀个枚举,⽤于枚举数的进制,⼀个从字串转换到特定的字符编码,并以指定进制表⽰的⽅法。
Unicode字符编码表

注:除非有特别指明,否则以下符号皆属“半角”而非“全角”。
代码显示描述U+0020 空格U+0021 ! 叹号U+0022 " 双引号U+0023 # 井号U+0024 $ 价钱/货币符号U+0025 % 百分比符号U+0026 & 英文“and”的简写符号U+0027 ' 引号U+0028 ( 开圆括号U+0029 ) 关圆括号U+002A * 星号U+002B + 加号U+002C , 逗号U+002D - 连字号/减号U+002E . 句号U+002F / 由右上至左下的斜线U+0030 0 数字0U+0031 1 数字1U+0032 2 数字2U+0033 3 数字3U+0034 4 数字4U+0035 5 数字5U+0036 6 数字6U+0037 7 数字7U+0038 8 数字8U+0039 9 数字9U+003A : 冒号U+003B ; 分号U+003C < 小于符号U+003D = 等于号U+003E > 大于符号U+003F ? 问号U+0040 @ 英文“at”的简写符号U+0041 A 拉丁字母AU+0043 C 拉丁字母CU+0044 D 拉丁字母DU+0045 E 拉丁字母EU+0046 F 拉丁字母FU+0047 G 拉丁字母GU+0048 H 拉丁字母HU+0049 I 拉丁字母IU+004A J 拉丁字母JU+004B K 拉丁字母KU+004C L 拉丁字母LU+004D M 拉丁字母MU+004E N 拉丁字母NU+004F O 拉丁字母OU+0050 P 拉丁字母PU+0051 Q 拉丁字母QU+0052 R 拉丁字母RU+0053 S 拉丁字母SU+0054 T 拉丁字母TU+0055 U 拉丁字母UU+0056 V 拉丁字母VU+0057 W 拉丁字母WU+0058 X 拉丁字母XU+0059 Y 拉丁字母YU+005A Z 拉丁字母ZU+005B [ 开方括号U+005C \ 由左上至右下的斜线U+005D ] 关方括号U+005E ^ 抑扬(重音)符号U+005F _ 底线U+0060 ` 重音符U+0061 a 拉丁字母aU+0062 b 拉丁字母bU+0063 c 拉丁字母cU+0064 d 拉丁字母dU+0065 e 拉丁字母eU+0067 g 拉丁字母gU+0068 h 拉丁字母hU+0069 i 拉丁字母iU+006A j 拉丁字母jU+006B k 拉丁字母kU+006C l 拉丁字母l(L的小写)U+006D m 拉丁字母mU+006E n 拉丁字母nU+006F o 拉丁字母oU+0070 p 拉丁字母pU+0071 q 拉丁字母qU+0072 r 拉丁字母rU+0073 s 拉丁字母sU+0074 t 拉丁字母tU+0075 u 拉丁字母uU+0076 v 拉丁字母vU+0077 w 拉丁字母wU+0078 x 拉丁字母xU+0079 y 拉丁字母yU+007A z 拉丁字母zU+007B { 开卷曲括号U+007C | 直棒U+007D } 关卷曲括号U+007E ~ 波浪纹拉丁字母-1代码显示描述U+00A1 ? 倒转的叹号U+00A2 ? (货币单位)分钱、毫子U+00A3 ? (货币)英镑U+00A4 ¤(货币)当货币未有符号时以此替代U+00A5 ? (货币)日圆U+00A6 ? 两条断开的直线U+00A7 §文件分不同部分U+00A8 ¨(语言)分音U+00A9 ? 版权符U+00AA ? (意大利文、葡萄牙文、西班牙文)阴性序数U+00AB ? 双重角形引号U+00AC ? 逻辑非U+00AE ?? 商标U+00AF ? 长音U+00B0 °角度U+00B1 ±正负号U+00B2 ? 二次方U+00B3 ? 三次方U+00B4 ? 锐音符U+00B5 ? 百万分之一,10?6U+00B6 ? 文章分段U+00B7 ·间隔号U+00B8 ? 软音符U+00B9 ? 一次方U+00BA ? (意大利文、葡萄牙文、西班牙文)阳性序数U+00BB ? 指向右的双箭头U+00BC ? 四分之一U+00BD ? 二分之一U+00BE ? 四分之三U+00BF ? 倒转的问号U+00C1 ? 在拉丁字母A 上加重音符U+00C2 ? 在拉丁字母A 上加抑扬符“^”U+00C3 ? 在拉丁字母A 上加“~”U+00C4 ? 在拉丁字母A 上加分音符“..”U+00C5 ? 在拉丁字母A 上加角度符“°”U+00C6 ? 拉丁字母A、E 的混合U+00C7 ? 在拉丁字母C 下加软音符U+00C8 ? 在拉丁字母E 上加重音符U+00C9 ? 在拉丁字母E 上加锐音符U+00CA ? 在拉丁字母E 上加抑扬符U+00CB ? 在拉丁字母E 上加分音符U+00CC ? 在拉丁字母I 上加重音符U+00CD ? 在拉丁字母I 上加锐音符U+00CE ? 在拉丁字母I 上加抑扬符U+00D0 ? 古拉丁字母?,现只有法罗文和冰岛文使用U+00D1 ? 在拉丁字母N 上加波浪纹“~”U+00D2 ? 在拉丁字母O 上加锐音符U+00D3 ? 在拉丁字母O 上加重音符U+00D4 ? 在拉丁字母O 上加抑扬符U+00D5 ? 在拉丁字母O 上加波浪纹“~”U+00D6 ? 在拉丁字母O 上加分音符U+00D7 ×乘号,亦可拖按“Alt”键,同时按“41425”五键U+00D8 ? 在拉丁字母O 由右上至左下加对角斜线“/”U+00D9 ? 在拉丁字母U 上加重音符U+00DA ? 在拉丁字母U 上加锐音符U+00DB ? 在拉丁字母U 上加抑扬符U+00DC ? 在拉丁字母U 上加分音符U+00DD ? 在拉丁字母Y 上加锐音符U+00DE ? 古拉丁字母?,现已被“Th”取替U+00DF ? 德文字母?U+00E0 à在拉丁字母a 上加重音符U+00E1 á在拉丁字母a 上加锐音符U+00E2 ? 在拉丁字母a 上加抑扬符U+00E3 ? 在拉丁字母a 上加波浪纹“~”U+00E4 ? 在拉丁字母a 上加分音符U+00E5 ? 在拉丁字母a 上加角度符“°”U+00E6 ? 拉丁字母a、e 的混合U+00E7 ? 在拉丁字母c 上加软音符U+00E8 è在拉丁字母e 上加锐音符U+00E9 é在拉丁字母e 上加重音符U+00EA ê在拉丁字母e 上加抑扬符U+00EB ? 在拉丁字母e 上加分音符U+00EC ì在拉丁字母i 上加重音符U+00ED í在拉丁字母i 上加锐音符U+00EE ? 在拉丁字母i 上加抑扬符U+00EF ? 在拉丁字母i 上加分音符U+00F0 ? 古拉丁字母?的小写U+00F1 ? 在拉丁字母n 上加波浪纹“~”U+00F2 ò在拉丁字母o 上加重音符U+00F4 ? 在拉丁字母o 上加抑扬符U+00F5 ? 在拉丁字母o 上加波浪纹“~”U+00F6 ? 在拉丁字母o 上加分音符U+00F7 ÷除号,亦可拖按“Alt”键,同时按“41426”五键U+00F8 ? 在拉丁字母o 由右上至左下加对角斜线“/”U+00F9 ù在拉丁字母u 上加重音符U+00FA ú在拉丁字母u 上加锐音符U+00FB ? 在拉丁字母u 上加抑扬符U+00FC ü在拉丁字母u 上加分音符U+00FD ? 在拉丁字母u 上加锐音符U+00FE ? 古拉丁字母?,现已被“th”取替U+00FF ? 在拉丁字母u 上加分音符拉丁字母(扩展A)代码显示描述U+0100 ? 在拉丁字母A 上加长音符U+0101 ā 在拉丁字母a 上加长音符U+0102 ? 在拉丁字母A 上加短音符U+0103 ? 在拉丁字母a 上加短音符U+0104 ? 在拉丁字母A 上加反尾形符U+0105 ? 在拉丁字母a 上加反尾形符拉丁字母(扩展C)代码显示描述U+2C60 ? 在拉丁字母“L”中间加两条横线“=”U+2C61 ? 在拉丁字母“l”(L 的小写)中间加一条横线“-”U+2C62 ? 在拉丁字母“L”(大写)中间加一条波浪线“~”U+2C63 ? 在拉丁字母“P”中间加一条横线“-”U+2C64 ? 在拉丁字母“R”下加一条尾巴U+2C65 ? 在拉丁字母“a”上加一条对角斜线“/”U+2C66 ? 在拉丁字母“t”上加一条对角斜线“/”U+2C67 ? 在拉丁字母“H”下加一条尾巴U+2C68 ? 在拉丁字母“h”下加一条尾巴U+2C69 ? 在拉丁字母“K”下加一条尾巴U+2C6A ? 在拉丁字母“k”下加一条尾巴U+2C6B ? 在拉丁字母“Z”下加一条尾巴U+2C6C ? 在拉丁字母“z”下加一条尾巴U+2C74 ? 在拉丁字母“v”的起笔加一个弯勾U+2C75 ? 拉丁字母“H”的左半部U+2C76 ? 拉丁字母“h”的左半部U+2C77 ? 希腊字母“φ”的上半部彝文字母拉丁字母(扩展D)代码显示描述U+A720 ? 强调音调音昂的改造字母U+A721 ? 强调音调低沉的改造字母特殊代码显示描述U+FFFC 取代无法显示字符的“OBJ”U+FFFD ? 无法显示的字符以它取代Unicode 编码表Unicode 编码表BMP SMP SIP SSP0000—0FFF 8000—8FFF 10000—10FFF 20000—20FFF 28000—28FFF E0000—E0FFF1000—1FFF 9000—9FFF 21000—21FFF 29000—29FFF2000—2FFF A000—AFFF 12000—12FFF 22000—22FFF 2A000—2AFFF 3000—3FFF B000—BFFF 23000—23FFF4000—4FFF C000—CFFF 24000—24FFF 2F000—2FFFF5000—5FFF D000—DFFF 1D000—1DFFF 25000—25FFF6000—6FFF E000—EFFF 26000—26FFF7000—7FFF F000—FFFF 1F000—1FFFF 27000—27FFF盲文图案。
汉字编码字符集

汉字编码字符集汉字编码字符集是指用于表示和存储汉字的一套编码系统。
在计算机领域,为了能够准确地表示和处理汉字,人们设计了多种不同的汉字编码字符集。
本文将介绍几种常见的汉字编码字符集,包括GB2312、GBK、Unicode以及UTF-8。
一、GB2312GB2312是中国国家标准局于1980年发布的一种汉字编码字符集,是最早被广泛使用的汉字字符集之一。
GB2312字符集包含了7445个汉字和682个非汉字字符,采用双字节表示每个字符。
其中,第一个字节的范围是0xB0至0xF7,第二个字节的范围是0xA1至0xFE。
GB2312字符集主要适用于简体中文。
二、GBK随着计算机技术的发展和汉字数量的增加,GB2312字符集的容量已经无法满足需求。
为了解决这个问题,国家标准局于1995年发布了GBK字符集,它是对GB2312字符集的扩充和改进。
GBK字符集兼容GB2312字符集,同时加入了21003个汉字,总计包含了21886个汉字。
GBK字符集同样采用双字节表示每个字符,第一个字节的范围是0x81至0xFE,第二个字节的范围是0x40至0xFE。
GBK字符集支持简体中文和繁体中文。
三、UnicodeUnicode是一种国际标准字符集,旨在为全球所有字符提供唯一的编码。
Unicode采用16位的编码方案,可以支持最多65536个不同的字符。
不仅包括了各个国家语言的文字,还包括了数学符号、技术符号、图形符号等。
Unicode字符集为各种语言的文字提供了一个统一的编码标准。
四、UTF-8UTF-8是一种可变长度的Unicode编码方案,更好地解决了存储效率和兼容性的问题。
UTF-8使用1至4个字节来表示一个字符,根据不同的字符而变化。
对于单字节的字符,编码和ASCII码相同,兼容ASCII码。
对于多字节的字符,第一个字节的高位标识了字节数。
UTF-8字符集可以表示Unicode字符集中的所有字符。
在计算机系统中,为了使不同的系统能够正确地处理汉字编码,一般需要统一选择一种字符集来使用。
Unicode字符全集
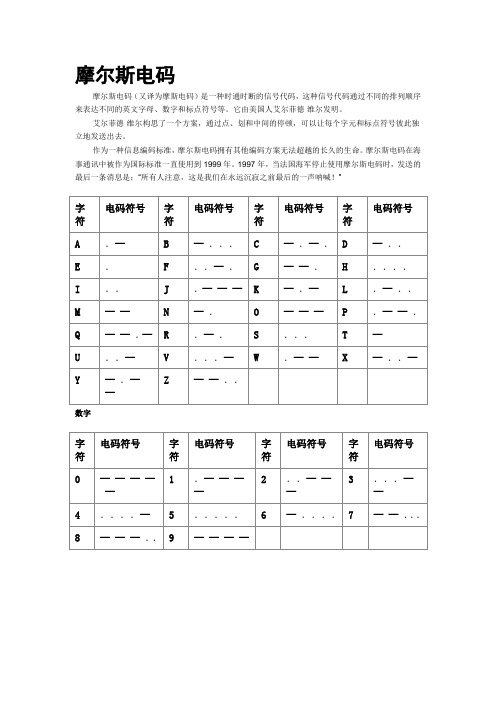
摩尔斯电码摩尔斯电码(又译为摩斯电码)是一种时通时断的信号代码,这种信号代码通过不同的排列顺序来表达不同的英文字母、数字和标点符号等。
它由美国人艾尔菲德·维尔发明。
艾尔菲德·维尔构思了一个方案,通过点、划和中间的停顿,可以让每个字元和标点符号彼此独立地发送出去。
作为一种信息编码标准,摩尔斯电码拥有其他编码方案无法超越的长久的生命。
摩尔斯电码在海事通讯中被作为国际标准一直使用到1999年。
1997年,当法国海军停止使用摩尔斯电码时,发送的最后一条消息是:“所有人注意,这是我们在永远沉寂之前最后的一声呐喊!”数字ASCII美国信息交换标准码(ASCII:American Standard Code for Information Interchange)起始于50年代后期,并最终在1967年定案。
最终的代码有26个小写字母,26个大写字母,10个数字,32个符号,33个控制代码和一个空格。
ASCII是一个真正的美国标准,所以他不能很好的满足其他将英语的国家的需要。
例如英国的英镑符号(£)就没有。
解决方案为代码页。
在小型机开发初期,就已经严格建立了8位字节。
因此,如果使用一个字节来保存字符,则可以由128个附加的字符来补充。
最低的128个代码总是相同的,较高的128个代码则取决于定义代码页的语言。
如果用户为PC键盘,显示卡,和打印机指定了一个代码页,然后在PC上创建、编辑和打印文档,一切都很正常,每件事都会保持一致。
然而,如果用户试图与使用不同代码页的用户交换文件,就会产生问题。
当然,应用程序可以通过将代码页信息与文档一起保存的方式来解决问题,但是且慢,更糟的事情还在后头。
在中国、日本和韩国的象形文字符号大约有21000个,如何容纳这些语言而仍保持和ASCII的某种兼容性呢。
解决方案为双字节字符集双字节字符集(DBCS:double-byte character set)与其他代码页一样,最初的128个代码是ASCII,较高的128个代码中的某些总是跟随者第二个字节(称作首字节和跟随字节)。
计算机字符集

西欧语言的字符集
详细描述
ISO 8859-1是一种单字节字符集,主要支持西欧语言的字符编码,包括英语 、法语、德语、意大利语、西班牙语等。它是最早的国际标准字符集之一, 广泛应用于网页和文档处理等领域。
Macintosh字符集
总结词
苹果公司开发的字符集
详细描述
Macintosh字符集是苹果公司为Mac OS操作系统开发的一种多字节字符集,支持包括中文、日文、 韩文等东亚语言的字符编码。它使用Unicode编码方案,是现代计算机系统中常用的字符集之一。
UTF-16采用固定长度的编码方式,每个字符的编 码长度为2或4个字节,适合对内存占用要求较高 的场景。
UTF-8是目前使用最广泛的编码方式,它采用可 变长度的编码方式,每个字符的编码长度可以是 1~4个字节,适应了不同语言字符的编码需求。
UTF-32采用固定长度的编码方式,每个字符的编 码长度为4个字节,适合对精度要求较高的场景。
IBM字符集
总结词
IBM公司开发的字符集
详细描述
IBM字符集是IBM公司为自身产品开发的一种多字节字符集,支持包括多种语言字符编码,如英语、法语、德 语、意大利语、西班牙语、中文、日文、韩文等。它广泛应用于IBM公司的软件产品中,也受到其他软件系统 的支持。
THANKS
谢谢您的观看
字符集的分类与特点
单字节字符集
每个字符只占用一个字节,通常用于表示英文字 符和数字。常见的单字节字符集包括ASCII、ISO 8859系列等。
可变长编码字符集
这种字符集的特点是每个字符可以占用不同数量 的字节。UTF-8就是一种可变长编码字符集,它 根据不同的字符使用不同的编码长度。
多字节字符集
编码标准:ASCII、GBK、Unicode(UTF8、UTF16、UTF32)

编码标准:ASCII、GBK、Unicode(UTF8、UTF16、UTF32)
英⽂编码(单字节字符集,码值范围0~127):字节最⾼位是0
ASCII编码,⽤于英⽂字符。
中⽂编码(双字节字符集):⾸字节(8位)的最⾼位是1。
可依据⾸字节最⾼位来判断中英⽂。
GB2312,旧版,6763个汉字。
GBK,中⽂字符升级版,21000多个汉字。
国际编码:Unicode编码,各国语⾔字符
不同编码⽅式,值不同,如“中”的GBK编码:0xD6D0,Unicode编码:0x4E2D
Unicode编码的3种实现⽅式:UTF8、UTF16、UTF32。
UTF8变长编码,智能分配1-4个字节。
UTF16定长编码,2个字节。
UTF32定长编码,4个字节。
UTF16编码,中英⽂字符都占2个字节。
其定义的类型称为宽字符类型wchar_t,使⽤⽅式如下
wchar_t d[] = L"中国"; //宽字符类型
wcout.imbue(locale("chs"));//Windows系统,语⾔设置为简体中⽂。
Unicode转GBK
wcout << d; //宽字符输出,中国。
字符编码和字符集到底有什么区别?Unicode和UTF-8是什么关系?

字符编码和字符集到底有什么区别?Unicode和UTF-8是什么关系?前⾔想必⼤家编写代码时肯定和我⼀样,也遇到过汉字乱码的问题。
特别是,有时候和上下游对接接⼝,不能统⼀编码格式的话,⼀堆乱码问题,让⼈头⽪发⿇。
那么为什么会有这么多的乱码问题?什么是字符编码?什么是字符集?他们之间有什么区别和联系?什么是 Unicode ? Unicode 和我们常说的 UTF-8 ⼜有什么关系?字符编码和解码要想搞清楚上⾯的问题,⾸先我们要知道,在计算机中,不管是⼀段⽂字、⼀张图⽚还是⼀段视频,最终都是以⼆进制的⽅式来存储。
也就是最终都会转化为0001 1011 0010 0110这样的格式。
换句话说,计算机只认识 0 和 1 这样的数字,并不能直接存储字符。
所以我们需要告诉它什么样的字符对应的是什么数字。
例如,我们的业务中有记录客户端的客户⾏为⽇志,然后导出⽂件来分析,字段间会以ESC来分隔。
我在编写代码的时候,就需要定义⼀下这个ESC字符应该对应什么数字,这样计算机才能识别并存储。
⽐如我把它定为0001 1011,这样计算机就把ESC这个字符存了下来。
等我下次需要查看的时候,根据对应关系把它解出来就可以了。
上边的两个过程就对应字符的编码和解码过程。
字符编码就是把字符按⼀定的规则,转换成数字。
字符解码是编码的逆过程,即把数字按规则转换成字符。
这样看来,貌似没有什么问题。
但是,这是我⾃⼰定义的编码规则,我同桌阿霄就不乐意了。
他⾮要认为ESC应该定义为1101 1000,好家伙正好和我定义的⼆进制数字顺序相反。
那结果肯定不⽤说了,我把0001 1011这串数字给他之后,按照他的编码规则来解,肯定是&$#!这样的东西。
所以,乱码问题说到底,就是编码和解码的规则对应不上导致的。
ASCII 码为了避免我和阿霄因为编码问题打起来,美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE) ANSI 组织发话了。
unicode字符大全

unicode字符大全Unicode字符大全。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode字符集目前已经包含了绝大部分世界上使用的字符,包括了文字、标点符号、符号、数字、图形、控制字符、格式控制字符等。
Unicode字符集的编码空间非常大,目前已经使用了17个代码级别,每个代码级别包含65536个码位,总共可以容纳1114112个字符。
其中,基本多文本平面(BMP)占据了第一个代码级别,包含了绝大部分常用的字符。
除了BMP之外,还有辅助平面(SMP)、辅助辅助平面(SIP)等,用于存放一些不常用的字符和特殊用途的字符。
Unicode字符集中的字符可以分为以下几类:1. 控制字符,这些字符用于控制文本的显示和处理,如换行符、回车符、制表符等。
2. 标点符号,包括了各种常见的标点符号,如句号、逗号、双引号、括号等。
3. 数字,包括了阿拉伯数字、罗马数字、汉字数字等。
4. 字母,包括了拉丁字母、希腊字母、西里尔字母、汉字等。
5. 符号,包括了各种数学符号、货币符号、箭头符号、几何图形符号等。
Unicode字符集的编码方式有多种,常见的编码方式包括UTF-8、UTF-16、UTF-32等。
其中,UTF-8是一种可变长编码方式,采用1~4个字节来表示一个字符,适合于存储英文和西欧语言;UTF-16采用2或4个字节来表示一个字符,适合于存储大部分常用字符;UTF-32采用4个字节来表示一个字符,适合于存储所有Unicode字符。
在使用Unicode字符集时,需要注意以下几点:1. 不同的编程语言和操作系统对Unicode的支持程度不同,需要根据具体情况选择合适的编程环境和工具。
2. 在处理Unicode字符时,需要考虑字符的长度、编码方式、显示方式等因素,以避免出现乱吗、显示异常等问题。