slab源码分析--setup_cpu_cache函数
动态添加系统调用

静态及动态添加系统调用――――――――摘之“Linux1.0核心游记”A2.系统调用的添加A2-1静态添加系统调用所谓的静态静态添加系统调用,是指我们直接通过修改核心的源代码而达到的。
只要我们知道Linux下系统调用实现的框架,添加(当然也可以修改)系统调用将会是件非常简单的事情。
该方法的缺点还是有的:1.修改好源代码后需要重新编译核心,这是个非常长和容易发生错误的过程。
2.对于你修改及编译好后所得到的核心,你所做的添加(修改)是静态的,无法在运行时动态改变(所以也就有了下面的动态方法)A2-1-1讨论Linux系统调用的体系在Linux的核心中,0x80号中断是所有系统调用的入口(当然你也可以修改,因为我们有源代码吗:),不过你改了之后只能自己玩玩,要不然人家0x80号中断的程序怎么执行呢?)。
但是还是有办法(可能还有其他办法)。
办法是在你看了下面的“动态添加系统调用”后就知道,这个就留给读者考虑了。
用0x80中断号功能作为所有的系统调用入口点,是系统编写者定义的(也可以说是Linus定义的)。
下面我们看一下其设置的代码(取之2.4核心,我们只看x386)定义于Arch/i386/kernel/traps.c(很简单,就一个函数调用)set_system_gate(SYSCALL_VECTOR,&system_call);!设置0x80号中断SYSCALL_VECTOR默认是0x80(你可以修改)system_call定义在Arch\i386\kernel\entry.Sset_system_gate定义在Arch/i386/kernel/traps.c,具体的代码分析这里就不做介绍了。
大致的功能是把system_call的地址(当然还有其他内容,比如类型值及特权级)设置到IDT (中断描述符表)的第0x80项中(请注意每项是8个字节,在基础有所介绍)。
当用了set_system_gate设置好中断号,并且已经开中断。
Linux内存管理之slab分配器分析
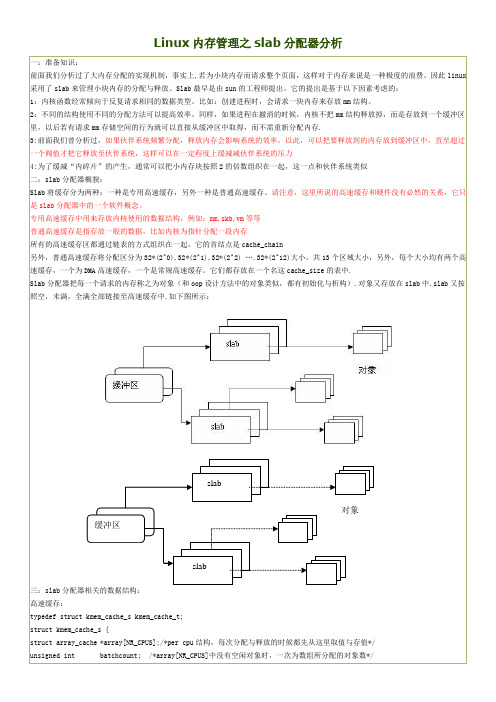
Linux内存管理之slab分配器分析一:准备知识:前面我们分析过了大内存分配的实现机制,事实上,若为小块内存而请求整个页面,这样对于内存来说是一种极度的浪费。
因此linux 采用了slab来管理小块内存的分配与释放。
Slab最早是由sun的工程师提出。
它的提出是基于以下因素考虑的:1:内核函数经常倾向于反复请求相同的数据类型。
比如:创建进程时,会请求一块内存来存放mm结构。
2:不同的结构使用不同的分配方法可以提高效率。
同样,如果进程在撤消的时候,内核不把mm结构释放掉,而是存放到一个缓冲区里,以后若有请求mm存储空间的行为就可以直接从缓冲区中取得,而不需重新分配内存.3:前面我们曾分析过,如果伙伴系统频繁分配,释放内存会影响系统的效率,以此,可以把要释放到的内存放到缓冲区中,直至超过一个阀值才把它释放至伙伴系统,这样可以在一定程度上缓减减伙伴系统的压力4:为了缓减“内碎片”的产生,通常可以把小内存块按照2的倍数组织在一起,这一点和伙伴系统类似二:slab分配器概貌:Slab将缓存分为两种:一种是专用高速缓存,另外一种是普通高速缓存。
请注意,这里所说的高速缓存和硬件没有必然的关系,它只是slab分配器中的一个软件概念。
专用高速缓存中用来存放内核使用的数据结构,例如:mm,skb,vm等等普通高速缓存是指存放一般的数据,比如内核为指针分配一段内存所有的高速缓存区都通过链表的方式组织在一起,它的首结点是cache_chain另外,普通高速缓存将分配区分为32*(2^0),32*(2^1),32*(2^2) ….32*(2^12)大小,共13个区域大小,另外,每个大小均有两个高速缓存,一个为DMA高速缓存,一个是常规高速缓存。
它们都存放在一个名这cache_size的表中.Slab分配器把每一个请求的内存称之为对象(和oop设计方法中的对象类似,都有初始化与析构).对象又存放在slab中.slab又按照空,末满,全满全部链接至高速缓存中.如下图所示:slab对象缓冲区slab三:slab分配器相关的数据结构:高速缓存:typedef struct kmem_cache_s kmem_cache_t;struct kmem_cache_s {struct array_cache *array[NR_CPUS];/*per cpu结构,每次分配与释放的时候都先从这里取值与存值*/unsigned int batchcount; /*array[NR_CPUS]中没有空闲对象时,一次为数组所分配的对象数*/unsigned int limit; //允许的空闲对象的最大值unsigned int batchcount; //一次要填充给数组的对象数,或者一次要释放的对象数unsigned int touched; //如果从该组中分配了对象,则把此值置为1}struct kmem_list3 {struct list_head slabs_partial; /*末满的slab链 */struct list_head slabs_full; /*满的slab链*/struct list_head slabs_free; /*完全空闲的slab链*/unsigned long free_objects; /*空链的对象数*/int free_touched;unsigned long next_reap;struct array_cache *shared; /*全局shar数组。
Request_irq和setup_irq的区别

Linux 内核提供了两个注册中断处理函数的接口:setup_irq和request_irq。
这两个函数都定义在kernel/irq/manage.c里。
/** Internal function to register an irqaction - typically used to* allocate special interrupts that are part of the architecture.*/int setup_irq(unsigned int irq, struct irqaction *new);/** request_irq - allocate an interrupt line* This call allocates interrupt resources and enables the* interrupt line and IRQ handling.*/int request_irq(unsigned int irq,irqreturn_t (*handler)(int, void *, struct pt_regs *),unsigned long irqflags, const char *devname, void *dev_id)这两个函数有什么样的区别呢?先看看setup_irqSetup_irq通常用在系统时钟(GP Timer)驱动里,注册系统时钟驱动的中断处理函数。
下面举个列子, 如s3c2410 timer驱动:/* arch/arm/mach-s3c2410/time.c */static struct irqaction s3c2410_timer_irq = {.name = "S3C2410 Timer Tick",.flags = IRQF_DISABLED | IRQF_TIMER,.handler = s3c2410_timer_interrupt,};static void __init s3c2410_timer_init (void){s3c2410_timer_setup();setup_irq(IRQ_TIMER4, &s3c2410_timer_irq);}struct sys_timer s3c24xx_timer = {.init = s3c2410_timer_init,.offset = s3c2410_gettimeoffset,.resume = s3c2410_timer_setup};struct sys_timer s3c24xx_timer = {.init = s3c2410_timer_init,.offset = s3c2410_gettimeoffset,.resume = s3c2410_timer_setup};可以看到,setup_irq的使用流程很简单。
系统级性能分析工具perf的介绍与使用

系统级性能分析⼯具perf的介绍与使⽤测试环境:Ubuntu16.04 + Kernel:4.4.0-31系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化。
性能剖析的⽬标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。
代码优化的⽬标是针对具体性能问题⽽优化代码或编译选项,以改善软件性能。
在性能剖析阶段,需要借助于现有的profiling⼯具,如perf等。
在代码优化阶段往往需要借助开发者的经验,编写简洁⾼效的代码,甚⾄在汇编级别合理使⽤各种指令,合理安排各种指令的执⾏顺序。
perf是⼀款Linux性能分析⼯具。
Linux性能计数器是⼀个新的基于内核的⼦系统,它提供⼀个性能分析框架,⽐如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能。
通过perf,应⽤程序可以利⽤PMU、tracepoint和内核中的计数器来进⾏性能统计。
它不但可以分析制定应⽤程序的性能问题(per thread),也可以⽤来分析内核的性能问题,当然也可以同事分析应⽤程序和内核,从⽽全⾯理解应⽤程序中的性能瓶颈。
使⽤perf,可以分析程序运⾏期间发⽣的硬件事件,⽐如instructions retired、processor clock cycles等;也可以分析软件时间,⽐如page fault和进程切换。
perf是⼀款综合性分析⼯具,⼤到系统全局性性能,再⼩到进程线程级别,甚⾄到函数及汇编级别。
perf提供了⼗⼋般武器,可以拿⼤⼑⼤卸⼋块,也可以拿起⼿术⼑细致分析。
1. 背景知识1.1 tracepointstracepoints是散落在内核源码中的⼀些hook,它们可以在特定的代码被执⾏到时触发,这⼀特定可以被各种trace/debug⼯具所使⽤。
perf将tracepoint产⽣的时间记录下来,⽣成报告,通过分析这些报告,条有⼈缘便可以了解程序运⾏期间内核的各种细节,对性能症状做出准确的诊断。
kfree函数源码

kfree函数源码Kfree函数是Linux内核用于释放内存的函数。
本文将介绍kfree函数的源码实现。
一、函数说明kfree函数是Linux内核中的一个内存释放函数,其作用是释放一块已经分配的内存。
它通常配合kmalloc函数一起使用。
二、函数原型void kfree(void *obj);三、函数源码kfree函数的实现比较简单,但是重要的是它是如何释放内存的。
首先,它会检查参数是否为NULL。
如果为NULL,说明并没有需要释放的内存块,函数直接返回。
如果不为NULL,将指针转换为指向struct kmem_cache结构体的指针(该结构体描述了已分配内存块的具体信息)。
通过获取struct kmem_cache结构体指针来判断该内存块是否从kmalloc分配。
如果是从kmalloc分配的,会调用kmalloc的实现来释放该内存块。
否则,会调用kmem_cache_free函数来释放该内存块。
kfree函数的主要源码实现如下:void kfree(void *obj) {if (obj == NULL) {return;}struct kmem_cache *s = GET_CACHE_FROM_OBJ(obj);if (s->flags & SLAB_TYPESAFE_BY_RCU) {rcu_pointer_diff_t offset = s->rcu_free_offset;void **freeq = get_rcu_free_buffer(s, (void *)obj);freeq[offset++] = obj;if (offset == (1 << s->rcu_free_batch)) {call_rcu(&s->rcu_head, rcu_process_callbacks, s); } else {s->rcu_free_offset = offset;}} else if (s->flags & SLAB_DESTROY_BY_RCU) {call_rcu(&((struct page *)obj)->rcu, delayed_free, s); } else if (CpuEverSched) {s->cpu_slab[smp_processor_id()]->stats.frees++;}if (likely(slab_free(s, obj))) {return;}if (s->ctor) {s->ctor(obj);}kfree_debugcheck(obj, s);s->free(s, obj, s->size);}需要注意的是,kfree函数并不会修改obj指向的值。
ApacheArrow源码分析——内存池与缓冲区

ApacheArrow源码分析——内存池与缓冲区原⽂链接:引⾔内存管理⼀直是所有系统的设计重点和难点所在,有效的内存管理可以提⾼系统资源利⽤率,提升整体系统性能。
对于操作系统⽽⾔,内存管理在内核中表现为段页式管理,对上层应⽤仅仅提供mmap, sbrk等相对简单的系统调⽤,操作系统更多的是关注底层物理内存到虚拟内存之间的映射关系以及内存到cpu cache之间的映射关系。
然⽽,对于上层应⽤程序⽽⾔,仅仅只有mmap和sbrk是远远不够的,毕竟每次调⽤mmap需要由⽤户态切换到内核态,其开销还是很⼤的。
于是,在操作系统接⼝之上,便出现了通⽤内存池,像glibc库提供的ptmalloc,提供malloc和free接⼝来分配和释放内存,但实际上,应⽤程序调⽤free接⼝,不见得这块内存就归还给操作系统了,准确的说,free掉的内存是归还给ptmalloc内存池,什么时候归还给操作系统由ptmalloc内存池来决定。
通⽤内存池同样存在问题,这种通⽤的策略并不能满⾜上层应⽤⽇益增长的需求。
某些特定场景下,采⽤通⽤内存池可能会出现内存碎⽚,或者会出现内存分配和回收效率低下等问题。
例如,在多线程环境下,ptmalloc的分配回收效率低下,于是google提出了,另外BSD的效率也很不错。
所以对专⽤系统⽽⾔,在内存管理这⼀块⼉想要提升效率,就需要⾃⼰对内存管理这⼀块⼉进⾏封装与实现,Arrow对内存池有简单的封装,但是具体管理内存分配和释放的策略还是采⽤系统malloc和free,然⽽这种封装思想值得学习,在以后需要做到⾃定内存管理时,可以很快的进⾏扩展。
内存池的定义在Arrow中,内存池对外提供的接⼝很简单,就是分配和释放接⼝,所以对于接⼝MemoryPool的定义如下段代码所⽰:class MemoryPool {public:virtual ~MemoryPool();virtual Status Allocate(int64_t size, uint8_t** out) = 0;virtual void Free(uint8_t* buffer, int64_t size) = 0;virtual int64_t bytes_allocated() const = 0;};MemoryPool* default_memory_pool();如果需要⾃⼰实现内存池进⾏内存管理,只需要继承内存池基类,实现定义的接⼝即可,在arrow中,对默认内存池的实现如下:class InternalMemoryPool : public MemoryPool {public:InternalMemoryPool() : bytes_allocated_(0) {}virtual ~InternalMemoryPool();Status Allocate(int64_t size, uint8_t** out) override;void Free(uint8_t* buffer, int64_t size) override;int64_t bytes_allocated() const override;private:mutable std::mutex pool_lock_;int64_t bytes_allocated_;};Status InternalMemoryPool::Allocate(int64_t size, uint8_t** out) {std::lock_guard<std::mutex> guard(pool_lock_);*out = static_cast<uint8_t*>(std::malloc(size));if (*out == nullptr) {std::stringstream ss;ss << "malloc of size " << size << " failed";return Status::OutOfMemory(ss.str());}bytes_allocated_ += size;return Status::OK();}int64_t InternalMemoryPool::bytes_allocated() const {std::lock_guard<std::mutex> guard(pool_lock_);return bytes_allocated_;}void InternalMemoryPool::Free(uint8_t* buffer, int64_t size) {std::lock_guard<std::mutex> guard(pool_lock_);std::free(buffer);bytes_allocated_ -= size;}InternalMemoryPool::~InternalMemoryPool() {}MemoryPool* default_memory_pool() {static InternalMemoryPool default_memory_pool_;return &default_memory_pool_;}每次分配和释放的时候,调⽤的实际上是系统接⼝,变量bytes_allocated_ 记录该内存池分配出去的内存⼤⼩。
CACHE的工作原理
CACHE的工作原理缓存(Cache)是一种用于存储临时数据的高速存储器,位于计算机的中央处理器(CPU)和主存之间,用于提高计算机系统的数据访问速度。
缓存的工作原理基于局部性原理和存储等级原理。
1.局部性原理:缓存的工作原理是基于计算机应用中的局部性原理。
局部性原理分为时间局部性和空间局部性两种:-时间局部性:当一个数据被访问后,有较大的概率它在不久的将来会再次被访问。
例如,计算机程序中的循环结构使得特定的代码块会多次被执行。
-空间局部性:当一个数据被访问后,其附近的数据很可能也会在不久的将来被访问。
例如,数组的元素在内存中是连续存储的,因此访问一个数组元素时,它附近的元素通常也会被使用。
2.存储等级原理:存储等级原理指的是计算机系统中存储器的分层结构,从更快速但更小容量的存储器到更慢速但更大容量的存储器。
存储等级从高到低一般可分为:寄存器、缓存、主存、辅助存储器(如硬盘)。
不同层次的存储器之间交换数据会有一定的延迟,通过引入缓存,可以减少CPU与主存之间的数据交换次数,提高系统的访问速度。
基于以上原理,缓存的工作原理如下:1.缓存地址映射:2.缓存替换算法:当缓存中已满时,如果需要将新的数据加载进来,就需要选择一部分缓存数据替换出去。
常用的缓存替换算法有:先进先出(FIFO)、最近最少使用(LRU)、最不经常使用(LFU)等。
这些算法的目标是尽量预测未来的访问模式,将可能再次访问的数据保留在缓存中。
3.缓存写策略:缓存的写策略包括写回(Write Back)和写直通(Write Through)两种:-写回:当CPU对缓存数据进行写操作时,只同时修改缓存中的数据,不立即写回主存。
当被修改的数据被替换出缓存时,再将缓存的数据写回主存。
-写直通:当CPU对缓存数据进行写操作时,同时修改缓存和主存中的数据。
这样做的好处是确保主存的数据始终与缓存一致,但也会导致频繁的主存访问,增加了延迟。
4.缓存一致性:缓存一致性是指多个缓存之间的数据一致性。
slabtop原理
slabtop原理Slabtop原理解析Slabtop是一个用于查看Linux内核slab分配器(slab allocator)状态的命令行工具。
它可以显示系统中各个slab缓存的详细信息,帮助我们了解内存的使用情况,优化内存管理。
一、slab分配器的作用在Linux内核中,为了高效地管理内存,采用了一种称为slab分配器的机制。
该机制通过将内存划分为多个等大小的slab块,用于缓存一些常用的数据结构,如inode、dentry等。
这样可以提高内存的利用率,减少内存碎片,并加速内存的分配和释放操作。
二、slabtop的使用使用slabtop命令可以实时查看系统中各个slab缓存的使用情况。
运行命令后,会显示一个表格,表格的每一行代表一个slab缓存,包括缓存名称、分配的对象数量、每个对象的大小、空闲对象数量等信息。
通过观察这些信息,我们可以判断是否存在内存泄漏、内存碎片等问题,以及针对性地进行优化。
三、slabtop的原理1. slabtop通过读取/proc/slabinfo文件获取slab分配器的信息。
该文件记录了系统中每个slab缓存的详细信息,包括缓存名称、对象大小、分配的对象数量、空闲对象数量等。
2. slabtop使用proc文件系统提供的接口,与内核进行通信。
通过读取/proc/slabinfo文件,获取到内核中各个slab缓存的信息。
3. slabtop将读取到的信息进行整理和统计,生成一个表格,并实时更新显示在终端上。
用户可以通过查看表格中的信息,了解系统中各个slab缓存的使用情况。
四、slabtop的使用示例下面是一个使用slabtop的示例:```$ slabtop -o```这个命令会按照分配的对象数量进行排序,并显示详细的slab缓存信息。
通过观察表格中的信息,我们可以看到每个slab缓存的名称、对象大小、分配的对象数量、空闲对象数量等。
此外,我们还可以使用其他参数来控制slabtop的显示方式,例如使用"-s"参数可以按照缓存名称进行排序。
Linux系统分析工具之slabtop
一、简介slabtop - display kernel slab cache information in real time(实时的显示内核slab缓存信息,透过/proc/slabinfo)内核的模块在分配资源的时候,为了提高效率和资源的利用率,都是透过slab 来分配的。
通过slab的信息,再配合源码能粗粗了解系统的运行情况,比如说什么资源有没有不正常的多,或者什么资源有没有泄漏。
linux系统透过/proc/slabinfo来向用户暴露slab的使用情况。
Linux所使用的slab 分配器的基础是Jeff Bonwick 为SunOS 操作系统首次引入的一种算法。
Jeff 的分配器是围绕对象缓存进行的。
在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。
Jeff 发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。
因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。
Linux slab 分配器使用了这种思想和其他一些思想来构建一个在空间和时间上都具有高效性的内存分配器。
保存着监视系统中所有活动的slab缓存的信息的文件为/proc/slabinfo二、用法slabtop-实时显示内核slab内存缓存信息slabtop [options]描述:slabtop displays detailed kernel slab cache information in real time. It displays a listing of the top caches sorted by one of the listed sort criteria. It also displays a statistics header filled with slab layer information.选项:—delay=n, -d n #每n秒更新一次显示的信息,默认是每3秒—sort=S, -s S #指定排序标准进行排序(排序标准,参照下面或者man 手册)—once, -o #显示一次后退出—version, -V #显示版本—help #显示帮助信息排序标准:a: sort by number of active objects b: sort by objects per slabc: sort by cache sizel: sort by number of slabsv: sort by number of active slabs n: sort by nameo: sort by number of objectsp: sort by pages per slabs: sort by object sizeu: sort by cache utilization输出界面可用的命令::刷新显示内容Q:退出三、数据分析。
cache工作原理
cache工作原理1. 概述Cache是计算机系统中的一种高速缓存存储器,用于提高数据访问速度。
它位于主存和CPU之间,用于存储最常用的数据和指令。
Cache工作原理是通过在高速缓存中存储最常访问的数据,以便CPU能够更快地访问这些数据,从而提高系统的整体性能。
2. Cache的结构Cache通常由多级结构组成,其中包括L1、L2、L3等多级缓存。
每一级缓存都有不同的大小和访问速度,越靠近CPU的缓存级别越小且速度越快。
一般来说,L1缓存是最小且最快的,L3缓存是最大且最慢的。
3. Cache的工作原理当CPU需要访问数据时,它首先会检查L1缓存。
如果数据在L1缓存中找到,CPU就可以直接从缓存中读取数据,这样可以大大提高访问速度。
如果数据不在L1缓存中,CPU会继续检查更大的L2缓存,以此类推,直到找到数据或者最后一级缓存。
如果数据在任何一级缓存中找到,CPU会将数据加载到更靠近CPU的缓存级别中,并从缓存中读取数据。
如果数据在所有缓存中都找不到,CPU将从主存中读取数据,并将其加载到L1缓存中,以备将来的访问。
4. Cache的命中和未命中当CPU在缓存中找到所需的数据时,称为“命中”。
如果数据不在缓存中,称为“未命中”。
命中率是衡量缓存性能的重要指标。
高命中率意味着大部分数据都能够从缓存中读取,从而提高系统性能。
未命中率高则意味着缓存无法满足CPU的需求,导致频繁从主存中读取数据,降低系统性能。
5. Cache的替换策略当缓存满时,如果需要将新的数据加载到缓存中,就需要替换掉一部分已有的数据。
常用的替换策略有最近最少使用(LRU)、随机替换等。
LRU策略是指替换最近最长时间未被访问的数据,以便为新的数据腾出空间。
6. Cache的写策略Cache的写策略包括写回(Write Back)和写直达(Write Through)两种方式。
写回策略是指当CPU修改缓存中的数据时,只会更新缓存数据,不会立即写回主存,而是等到缓存被替换出去时才写回主存。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
slab源码分析--setup_cpu_cache函数之前剖析过了slab 的初始化,以及kmem_cache_create() 函数,留下了一个setup_cpu_cache() 函数没有处理,今天来分析一下。
说明:本文缓存器指kmem_cache 结构,slab 三链即kmem_list3。
setup_cpu_cache() 函数和slab 分配器的初始化状态是息息相关的。
我们知道,slab 分配器初始化会经历以下状态:首先提一下arraycache_init 结构体,之前都没说过。
/** bootstrap: The caches do not work without cpuarrays anymore, but the* cpuarrays are allocated from the generic caches...*/#define BOOT_CPUCACHE_ENTRIES 1struct arraycache_init {struct array_cache cache;void *entries[BOOT_CPUCACHE_ENTRIES];};就是上面那样的,由于array_cache 结构体末尾是一个柔性数组,我们需要把该柔性数组和array_cache 包装起来,因为它们组合而成了本地缓存。
否则单独的array_cache 结构体是不会包含entries 数组的,这是柔性数组的特性,它只是一个占位符。
所以,本地缓存的缓存器真正要缓存的对象是arrarcache_init 结构体。
该结构体在初始化前期,采用静态初始化,如BOOT_CPUACHE_ENTRIES。
下面来主要谈一下初始化过程的步骤,这是在kmem_cache_init() 函数之中进行的:(1) 构建好了kmem_cache实例cache_cache(静态分配),且构建好了kmem_cache的slab分配器,并由initkmem_list3[0]组织, 相应的array为initarray_cache;(2) 构建好了kmem_cache实例(管理arraycache_init),且构建好了arraycache_init的slab 分配器,并由initkmem_list3[1]组织,相应的array为initarray_generic;(3) 构建好了kmem_cache实例(管理kmem_list3),此时还未构建好kmem_list3的slab分配器,但是一旦申请sizeof(kmem_list3)空间,将构建kmem_list3分配器,并由initkmem_list[2]组织,其array将通过kmalloc进行申请;(4) 为malloc_sizes的相应数组元素构建kmem_cache实例,并分配kmem_list3,用于组织slab链表,分配arraycache_init用于组织每CPU的同一个kmem_cache下的slab分配;(5) 替换kmem_cache、malloc_sizes[INDEX_AC].cs_cachep下的arraycache_init实例;(6) 替换kmem_cache、malloc_sizes[INDEX_AC].cs_cachep、malloc_sizes[INDEX_L3].cs_cachep下的kmem_list3实例;(7) g_cpucachep_up = EARL Y;问题:为什么需要initarray_cache 和initarray_generic 两个静态arraycache_init?它们静态初始化的内容不是一样的吗?因为initarray_cache 是为cache_cache 缓存器准备的本地缓存,而initarray_generic 是为arraycache_init 缓存器准备的本地缓存。
虽然静态初始化一样,它们最终要被kmalloc 申请的新内容替换掉,分别作为不同缓存器的本地缓存。
显然是不能共用的。
下面对kmem_cache_init() 函数中执行kmem_cache_create() 函数逐步分析(因为setup_cpu_cache() 函数就是在后者中调用的)。
先声明:#define INDEX_AC index_of(sizeof(struct arraycache_init))#define INDEX_L3 index_of(sizeof(struct kmem_list3))INDEX_AC 和INDEX_L3 分别是arraycache_init 和三链的大小,用于在malloc_sizes[] 表中进行查找。
首先第一次调用:为arraycache_init 构造缓存器。
sizes[INDEX_AC].cs_cachep = kmem_cache_create(names[INDEX_AC].name,sizes[INDEX_AC].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC, //#define ARCH_KMALLOC_FLAGS SLAB_HWCACHE_ALIGN,已经对齐过的标记NULL, NULL);kmem_cache_create() 函数尾部调用setup_cpu_cache() 进入该分支://如果程序执行到这里,那就说明当前还在初始化阶段//g_cpucache_up记录初始化的进度,比如PARTIAL_AC表示struct array_cache 的cache 已经创建//PARTIAL_L3 表示struct kmem_list3 所在的cache 已经创建,注意创建这两个cache 的先后顺序。
在初始化阶段只需配置主cpu的local cache和slab三链//若g_cpucache_up 为NONE,说明sizeof(struct array)大小的cache 还没有创建,初始化阶段创建sizeof(struct array) 大小的cache 时进入这流程//此时struct arraycache_init 所在的general cache 还未创建,只能使用静态分配的全局变量initarray_eneric 表示的local cacheif (g_cpucache_up == NONE) {/** Note: the first kmem_cache_create must create the cache* that's used by kmalloc(24), otherwise the creation of* further caches will BUG().*/cachep->array[smp_processor_id()] = &initarray_generic.cache; //arraycache_init的缓存器还没有创建,先使用静态的/** If the cache that's used by kmalloc(sizeof(kmem_list3)) is* the first cache, then we need to set up all its list3s,* otherwise the creation of further caches will BUG().*///chuangjian struct kmem_list3 所在的cache是在struct array_cache所在cache之后//所以此时struct kmem_list3 所在的cache 也一定没有创建,也需要使用全局变量initkmem_list3//#define SIZE_AC 1,第一次把arraycache_init的缓存器和initkmem_list3[1]关联起来//下一次会填充set_up_list3s(cachep, SIZE_AC);//执行到这里struct array_cache所在的cache 创建完毕,//如果struct kmem_list3和struct array_cache 的大小一样大,那么就不用再重复创建了,g_cpucache_up表示的进度更进一步if (INDEX_AC == INDEX_L3)g_cpucache_up = PARTIAL_L3; //更新cpu up 状态elseg_cpucache_up = PARTIAL_AC;}第一次调用kmem_cache_create,填充了initkmem_list3[0],该类链表上挂载了kmem_cache 类型的slab分配器.kmem_cache_create() 中会第一次调用setup_cpu_cache,initkmem_list3[1]将被分配给与arraycache_init匹配的kmem_cache,但是由于arraycache_init的slab分配器(三链)还未构建好,因此,在第一次申请sizeof(arraycache_init)空间时,会把arraycache_init的slab 分配器挂入initkmem_list3[1]类的链表下.第二次:为kmem_list3(三链)构造缓存器if (INDEX_AC != INDEX_L3) {//如果struct kmem_list3 和struct arraycache_init对应的kmalloc size索引不同,即大小属于不同的级别,//则创建struct kmem_list3所用的cache,否则共用一个cachesizes[INDEX_L3].cs_cachep =kmem_cache_create(names[INDEX_L3].name,sizes[INDEX_L3].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL, NULL);}setup_cpu_cache() 函数进入该分支:else {//g_cache_up至少为PARTIAL_AC时进入这流程,struct arraycache_init所在的general cache已经建立起来,可以通筸kalloc分配了。
cachep->array[smp_processor_id()] =kmalloc(sizeof(struct arraycache_init), GFP_KERNEL);//struct kmem_list3 所在的cache仍未创建完毕,还需使用全局的slab三链if (g_cpucache_up == PARTIAL_AC) {set_up_list3s(cachep, SIZE_L3);g_cpucache_up = PARTIAL_L3;}第二次调用kmem_cache_create,填充了initkmem_list3[1],该类链表上挂载了arraycache_init 类型的slab分配器.这已是第二次调用kmem_cache_create.在第二次调用时,arraycache_init的kmem_cache已初始化,但是arraycache_init的slab分配器(三链)还未构建好(相当于都为空),而setup_cpu_cache中将开始通过kmalloc申请sizeof(arraycache_init)空间**,此时将同kmem_cache分配器初始化过程一样,填充arraycache_init分配器.主要区被在于kmem_cache_create最后调用setup_cpu_cache,setup_cpu_cache中将设置g_cpucache_up,以标志初始化的不同阶段.这时有一句:slab_early_init = 0;此时我们已经做到了:构建好了kmem_cache实例cache_cache,且构建好了kmem_cache的slab分配器,并由initkmem_list3[0]组织, 相应的array为initarray_cache.构建好了kmem_cache实例(管理arraycache_init),且构建好了arraycache_init的slab分配器,并由initkmem_list3[1]组织,相应的array为initarray_generic.构建好了kmem_cache实例(管理kmem_list3),此时还未构建好kmem_list3的slab分配器,但是一旦申请sizeof(kmem_list3)空间,将构建kmem_list3分配器,并由initkmem_list[2]组织,其array将通过kmalloc进行申请. 此时,所有的包括前两步中的三链都是由静态的kmem_list3组织,不过已经足以创建其他大小的缓存器了。