Centos7安装和配置hadoop2.7.3的流程和总结
centos7安装配置Hadoop集群

centos7安装配置Hadoop集群2、安装3台虚拟机并实现SSH免密登录(1)安装三台虚拟机centos7第⼀台正常安装,后两台做克隆。
配置好IP地址,关闭防⽕墙跟SELINUX。
106.14.69.185 server1121.5.218.141 server2(2)修改⽤户名以及对应的IP# vi /etc/hostname改为server1# vi /etc/hosts另外两台虚拟机也按同样的设置,例如:centos7 2 为server2设置完成后每台虚拟机都需要重启,重启⽣效。
配置完成后使⽤ping命令检查这3个机器是否相互ping得通,以server1为例,在什么执⾏命令:(3)进⾏SSH免密互登设置#ssh-keygen -t dsa在命令执⾏过程中敲击两遍回车,然后在/root/.ssh⽂件下⽣成id_dsa id_dsa.pub在该⽂件下建⽴⼀个authorized_keys⽂件,将id_dsa.pub⽂件内容拷贝到authorized_keys⽂件中另外两个虚拟机也执⾏ #ssh-keygen -t dsa操作,并分别将id_dsa.pub内容拷贝到第⼀台虚拟机的authorized_keys⽂件中。
将第⼀台的authorized_keys⽂件拷贝到另外两台虚拟机的/root/.ssh/ 下⾯3、给3台机器安装JAVA环境4、给3台机器安装Hadoop注意:以下搭建过程中的端⼝设置,请先检查个⼈服务器是否有端⼝冲突1 解压hadoop2新建⼏个⽬录在/root⽬录下新建⼏个⽬录,复制粘贴执⾏下⾯的命令:mkdir /root/hadoopmkdir /root/hadoop/tmpmkdir /root/hadoop/varmkdir /root/hadoop/dfsmkdir /root/hadoop/dfs/namemkdir /root/hadoop/dfs/data(3)修改etc/hadoop中的⼀系列配置⽂件/opt/hadoop/hadoop-3.2.0/etc/hadoop/修改core-site.xml在<configuration>节点内加⼊配置:<property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name></name><value>hdfs://server1:9000</value></property>注意:<value>hdfs://server1:9000</value>此处应与hostname保持⼀致修改hadoop-env.sh将export JAVA_HOME=${JAVA_HOME}修改为:export JAVA_HOME=/var/liangxiaodong/soft/jdk1.8.0_202修改hdfs-site.xml<property><name>.dir</name><value>/root/hadoop/dfs/name</value><description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> </property><property><name>dfs.data.dir</name><value>/root/hadoop/dfs/data</value><description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.permissions</name><value>false</value><description>need not permissions</description></property>说明:dfs.permissions配置为false后,可以允许不要检查权限就⽣成dfs上的⽂件,⽅便倒是⽅便了,但是你需要防⽌误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true新建并且修改mapred-site.xml在该版本中,有⼀个名为mapred-site.xml的⽂件,复制该⽂件,后改名mapred-site.xml.template,命令是:cp mapred-site.xml mapred-site.xml.template修改这个新建的mapred-site.xml⽂件,在<configuration>节点内加⼊配置:<property><name>mapred.job.tracker</name><value>server1:49001</value></property><property><name>mapred.local.dir</name><value>/root/hadoop/var</value></property><property><name></name><value>yarn</value></property>注意:<value>server1:49001</value>修改worker⽂件(hadoop3.2版本没有slaves⽂件,之前版本修改slaves⽂件)修改worker⽂件,将⾥⾯的localhost删除,添加如下内容:server2server3第⼆台虚拟机添加如下内容:<property><name>yarn.resourcemanager.hostname</name><value>server1</value></property><property><description>The address of the applications manager interface in the RM.</description><name>yarn.resourcemanager.address</name><value>${yarn.resourcemanager.hostname}:8032</value></property><property><description>The address of the scheduler interface.</description><name>yarn.resourcemanager.scheduler.address</name><value>${yarn.resourcemanager.hostname}:8030</value></property><property><description>The http address of the RM web application.</description><name>yarn.resourcemanager.webapp.address</name><value>${yarn.resourcemanager.hostname}:8088</value></property><property><description>The https adddress of the RM web application.</description><name>yarn.resourcemanager.webapp.https.address</name><value>${yarn.resourcemanager.hostname}:8090</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>${yarn.resourcemanager.hostname}:8031</value></property><property><description>The address of the RM admin interface.</description><name>yarn.resourcemanager.admin.address</name><value>${yarn.resourcemanager.hostname}:8033</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value><discription>每个节点可⽤内存,单位MB,默认8182MB</discription></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>注意:端⼝号与⾥⾯的值,后期优化配置需要修改,第⼀次配可以全复制。
hadoop2.7.3安装和配置

hadoop2.7.3安装和配置一、安装环境硬件:虚拟机操作系统:Centos 6.4 64位IP:192.168.241.128主机名:admin安装用户:root二、安装JDK安装JDK1.8或者以上版本。
这里安装jdk1.8.0_121。
下载地址:/technetwork/java/javase/downloads/ind ex.html1,下载jdk-8u121-linux-x64.tar.gz,解压到/usr/Java/jdk1.8。
2,在/root/.bash_profile中添加如下配置:export JAVA_HOME=/usr/java/jdk1.8export PATH=$JAVA_HOME/bin:$PATH3,使环境变量生效,#source ~/.bash_profile4,安装验证# java -versionJava version "1.8.0_121"Java(TM) SE Runtime Environment (build 1.8.0_121-b13)Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)查看启动端口:netstat -ntpl 查看防火墙:iptables -L /-F关闭三,配置SSH无密码登陆ssh-keygen -t rsassh-keygen -t dsacat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys 注:> :重定向cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 注:>>:追加chmod 700 ~/.ssh/ 注:~/.ssh 目录的权限必须是700chmod 600 ~/.ssh/authorized_keys 注:~/.ssh/authorized_keys 文件权限必须是600#服务器配置1.修改sshd配置文件(su root -->> vi /etc/ssh/sshd_config)找到以下内容,并去掉注释符号"#"================================RSAAuthentication yesPubkeyAuthentication yesAuthorizedKeysFile .ssh/authorized_keys================================重启sshd:$ /etc/init.d/sshd restart验证ssh,# ssh localhost不需要输入密码即可登录。
centos 7+hadoop2.7.3详细安装教程
centos 7+hadoop2.7.3详细安装教程前言:Hadoop 运行在jar环境下,因此安装hadoop的前提是得在系统上安装好jdk。
本次实验环境使用centos7进行安装。
需要安装的工具:1.虚拟机2.Centos 7镜像文件3.Filezilla(用于上传本地下载的hadoop镜像到centos系统,以及可以远程操作linux 文件系统)4.secureCrt(远程连接linux,敲指令方便。
本次安装的linux是没有图形界面的,命令窗口不能复制粘贴,因此使用secureCRT操作linux系统,方便后续修改hadoop 文件时可以复制粘贴)5.JDK镜像6.Hadoop2.7.3镜像文件一、虚拟机安装a)安装最新版本,具体安装方法比较简单,请上网自行搜索。
b)安装按虚拟机后,需要配置虚拟机的网络连接方式。
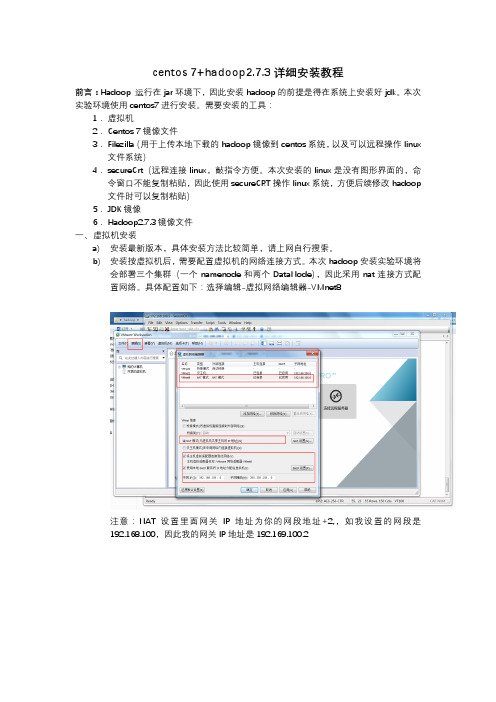
本次hadoop安装实验环境将会部署三个集群(一个namenode和两个DataNode),因此采用nat连接方式配置网络。
具体配置如下:选择编辑-虚拟网络编辑器-VMnet8注意:NAT设置里面网关IP地址为你的网段地址+2,,如我设置的网段是192.168.100,因此我的网关IP地址是192.169.100.2二、安装三台centos7(三台安装方式一样,仅是里面IP地址配置不一样。
具体安装多少台视各位看官需要配置多少集群而定)a)文件菜单选择新建虚拟机b)选择经典类型安装,下一步。
c)选择稍后安装操作系统,下一步。
d)选择Linux系统,版本选择CentOS7 64位。
e)命名虚拟机,给虚拟机起个名字,将来显示在Vmware左侧。
并选择Linux系统保存在宿主机的哪个目录下,应该一个虚拟机保存在一个目录下,不能多个虚拟机使用一个目录。
f)指定磁盘容量,是指定分给Linux虚拟机多大的硬盘,默认20G就可以,下一步。
g)点击自定义硬件,可以查看、修改虚拟机的硬件配置,这里我们不做修改。
centos安装配置hadoop超详细过程

1、集群部署介绍1.1 Hadoop简介Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。
以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。
一个HDFS集群是由一个NameNode和若干个DataNode组成的。
其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。
MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。
主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。
当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。
HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。
HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1.2 环境说明集群中包括4个节点:1个Master,3个Salve,节点之间局域网连接,可以相互ping通,具体集群信息可以查看"Hadoop集群(第2期)"。
节点IP地址分布如下:机器名称IP地址Master.Hadoo p 192.168.1 .2Salve1.Hadoo p 192.168.1 .3Salve2.Hadoo p 192.168.1 .4Salve3.Hadoo p 192.168.1 .5四个节点上均是CentOS6.0系统,并且有一个相同的用户hadoop。
hadoop-集群搭建步骤(centos7)

Hadoop集群搭建目录(注:此所有操作相关命令在CentOS7下)Hadoop集群搭建 (1)目录 (1)1、基础集群环境搭建 (1)1.1、安装JDK (1)1.2、修改主机名称,关闭防火墙 (2)1.3、添加内网域名映射 (2)1.4、配置免密码登录 (2)2、Hadoop集群环境安装 (3)2.1、Hadoop版本选择 (3)2.2、安装Hadoop (3)2.2.1、Hadoop伪分布式模式安装 (3)2.2.2、Hadoop分布式集群安装 (4)3、集群初步使用 (7)3.1、Hadoop集群启动 (7)3.2、HDFS集群初步使用 (7)4、Hadoop集群安装高级知识 (7)4.1、Hadoop HA安装 (7)1、基础集群环境搭建1.1、安装JDK1、上传jdk-8u151-linux-x64.tar.gz2、解压到usr目录下tar-zxvf jdk-8u151-linux-x64.tar.gz3、配置环境变量(1)vim/etc/profile(2)在最后加入:JAVA_HOME=/usr/java1.8PATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME PATH(3)保存退出4、source/etc/profile5、检测是否安装成功,输入命令:java-version做完以上步骤,可以开始克隆虚拟机。
因为以上系统的配置,都是一些基础性的操作。
都是必须的1.2、修改主机名称,关闭防火墙1、root账号下使用命令:hostnamectl set-hostname hadoop022、Xshell关闭连接窗口,重新连接即可更改过来3、关闭防火墙(CentOS7)(1)firewall-cmd--state#查看防火墙状态(2)systemctl stop firewalld.service#停止firewall(3)systemctl disable firewalld.service#禁止firewall开机启动1.3、添加内网域名映射1、修改配置文件:vim/etc/hosts1.4、配置免密码登录1、在root登录状态下,输入命令ssh-keygen或者ssh-keygen-t rsa2、之后你会发现,在/root/.ssh目录下生成了公钥文件3、使用一个简单的方式,使用命令:ssh-copy-id hadoop02建立hadoop01到hadoop02的免密码登录2、Hadoop集群环境安装2.1、Hadoop版本选择1、Apache官方版本:1.X2.X 2.6.5 2.7.53.0.12、商业发行版本提供完善的管理系统,修复bug可能会领先于官方版本Cloudera公司的CDH:5.7.X2.2、安装Hadoop2.2.1、Hadoop伪分布式模式安装Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点即作为NameNode也作为DataNode,同时,读取的是HDFS中的文件。
详细步骤安装CentOS 7系统

详细步骤安装CentOS7系统目录目录 (I)第一章安装前准备 (1)1.1制作U盘启动盘 (1)第二章安装系统 (2)2.1安装CentOS7系统 (2)2.2网络配置 (19)2.3关闭防火墙 (23)2.4设置网卡开机启动 (23)第一章安装前准备1.1制作U盘启动盘CentOS7系统镜像下载,如:CentOS-7-x86_64-DVD-1611.iso 使用UltraISO工具将CentOS7的ISO镜像写入安装U盘。
1、如上图,打开UltraISO软件2、选择菜单“文件->打开”打开CentOS7的ISO镜像。
3、选择菜单“启用->写入硬盘映像”,单击写入,直到写入完成。
第二章安装系统2.1安装CentOS7系统在服务器上插入U盘启动盘后,设置操作系统为U盘启动(步骤略),开机后自动跳转到CentOS 系统安装界面,按以下步骤操作:第一步:CentOS7安装欢迎界面。
显示上图安装欢迎界面,直接按键盘“Enter”键进入到下一个页面。
第二步:如上图,按任意键继续。
第三步:见上图,自检加载系统文件。
第四步:见上图,选择安装语言,此处选择“中文”->“简体中文(中国)”,单击“继续”。
第五步:如上图,单击“软件选择(S)”。
第六步:见上图,选择基本环境为“带GUI的服务器”,单击“完成(N)”。
第七步:如上图,软件选择中显示“带GUI的服务器”。
第八步:如上图,单击“安装位置(D)”。
操作系统磁盘500GB数据盘(RAID5)55TB第九步:选择“我要配置分区(I)”,单击“完成(D)”,如上图。
进入磁盘配置界面,可以看到硬盘驱动器中当前的硬盘,现场安装时需按下表情况来配置。
第十步:如上图,操作“+”,添加分区。
第十一步::如上图,创建swap分区。
期望容量;8192MB为swap分区大小设备类型;统一选择标准分区文件系统;swap设备:注意这里为sda第十二步:如上图,创建系统盘,创建后与上图保持一致。
Hadoop2.7.3完全分布式集群搭建和测试

Hadoop2.7.3完全分布式集群配置和测试环境配置:虚拟机:vmware w orkstation 12系统:ubuntu 16.04 LTS(推荐使用原版,不要用kylin)节点:192.168.159.132 master192.168.159.134 node1192.168.159.137 node2j dk-8u101-L i nux-x64.g z(J a v a)h a doop-2.7.3.t a r.g z(H a doop包)安装步骤:1、安装虚拟机系统,并进行准备工作(可安装一个然后克隆)2.修改各个虚拟机的hostname和host3.创建用户组和用户4、配置虚拟机网络,使虚拟机系统之间以及和host主机之间可以通过相互ping通。
5.安装jdk和配置环境变量,检查是否配置成功6、配置ssh,实现节点间的无密码登录ssh node1/2指令验证时候成功7、master配置hadoop,并将hadoop文件传输到node节点8、配置环境变量,并启动hadoop,检查是否安装成功,执行wordcount检查是否成功。
1.安装虚拟机在V M上安装下载好的U bun t u的系统,具体过程自行百度。
可以安装完一个以后克隆,但是本人安装过程中遇到很多问题,经常需要删除虚拟机,重新安装,而被克隆的虚拟机不能删除,所以本人就用了很长时候,一个一个安装。
一共3台虚拟机:分配情况和IP地址如下:(注:查看ip地址的指令ifconfig)安装虚拟机时可以设置静态I P,因为过程中常常遇到网络连接问题,i f c on f i g找不到I P V4地址。
当然,也可以不设,默认分配。
参考h tt p://b l og.c s dn.n e t/w o l f_s ou l/a r ti c l e/d e t a il s/46409323192.168.159.132 master2.修改虚拟机的hostname 和hosts 文件以m a s t e r 上机器为例,打开终端,执行如下的操作,把ho s t n a m e 修改成m a s t e r ,ho s t s 修改成如下所示的样子: #修改hostname 的指令:sudo gedit /etc/hostname#修改hosts 指令:sudo gedit /etc/hosts#将以下内容添加到hosts 中192.168.159.132 master192.168.159.134 node1192.168.159.137 node2如下图所示:同样地,在node1和node2机器上做相似的操作,分别更改主机名为node1和node2,然后把hosts 文件更改和master 一样。
centos7 教程

centos7 教程CentOS 7 是一种基于企业级 Linux 发行版的操作系统。
CentOS(Community Enterprise Operating System)是由CentOS 项目团队开发的,可免费使用并且具有长期维护支持。
在本教程中,我们将介绍 CentOS 7 的一些常见操作和配置。
1. 安装 CentOS 7a. 下载 CentOS 7 ISO 镜像文件。
b. 创建启动盘或虚拟机并加载镜像。
c. 启动计算机或虚拟机并按照安装程序的指导完成安装。
2. 连接到网络a. 使用命令 `ifconfig` 检查网络接口的状态。
b. 使用命令 `nmcli` 配置网络连接。
例如,`nmcli con add ifname eth0 type ethernet autoconnect yes`。
3. 更新软件包a. 执行命令 `yum update` 来更新系统和安装的软件包。
4. 安装软件包a. 使用命令 `yum install` 安装软件包。
例如,`yum install httpd` 安装 Apache Web 服务器。
5. 配置防火墙a. 使用命令 `firewall-cmd` 配置防火墙规则。
例如,`firewall-cmd --permanent --zone=public --add-service=http` 允许 HTTP 流量通过防火墙。
6. 设置 SELinuxa. 使用命令 `sestatus` 检查 SELinux 状态。
b. 使用命令 `setenforce` 设置 SELinux 模式。
例如,`setenforce 0` 设置 SELinux 为宽容模式。
7. 配置用户和权限a. 使用命令 `useradd` 添加用户。
例如,`useradd -m -s/bin/bash username` 添加一个新用户。
b. 使用命令 `passwd` 设置用户密码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CentOS7安装完整流程及总结一、前言配置一台master服务器,两台(或多台)slave服务器,master可以无密码SSH登录到slave。
卸载centos7自带的openjdk,通过SecureCRT的rz命令上传文件到服务器,解压安装JDK,解压安装Hadoop,配置hadoop的、、、文件。
配置好之后启动hadoope服务,用jps命令查看状态。
再运行hadoop自带的wordcount程序做一个Hello World实例。
二、准备工作我的系统:windows 10 家庭普通中文版cpu:intel i5内存:8G《64位操作系统需要准备的软件和文件(全部是64位安装包)1.虚拟机:VMware 12 Pro 官网下载:选择DVD ISO(标准版) 及以上,官网下载:下载地址:version 三、安装过程提示:先创建一台虚拟机,安装好centos7系统,使用VMware 的克隆功能,克隆另外两台虚拟机。
这样可以节省时间。
虚拟机设置当三台虚拟机安装好之后,获得它们的IP地址,并设置主机名,(根据实际IP地址和主机名)修改/etc/hosts文件内容为:^1、vi /etc/hosts命令修改,然后保存(vi的相关命令见引用来源16)2、more /etc/hosts查看3、重启后,hosts生效。
命令: reboot now[SSH免密码登录提示:我全程用的都是root用户,没有另外创建用户。
每台服务器都生成公钥,再合并到authorized_keys。
1)CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置,2)#RSAAuthentication yes3)#PubkeyAuthentication yes4)输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置,5)合并公钥到authorized_keys文件,在master服务器,进入/root/.ssh目录,通过SSH命令合并,(~/.ssh/ 是省略的写法,要根据实际路径来确定)6)cat >> authorized_keys7)ssh root@ cat ~/.ssh/ >> authorized_keys8)ssh. cat ~/.ssh/ >> authorized_keys9)把master服务器的authorized_keys、known_hosts复制到slave服务器的/root/.ssh目录scp -r /root/.ssh/authorized_keys root@:/root/.ssh/scp -r /root/.ssh/known_hosts root@:/root/.ssh/《scp -r /root/.ssh/authorized_keys root@:/root/.ssh/scp -r /root/.ssh/known_hosts root@:/root/.ssh/10)完成后,ssh root@、ssh root@或者(ssh 、ssh ) 就不需要输入密码直接登录到其他节点上。
Secure CRT连接虚拟机1、在VMware中把三台虚拟机启动,如下图所示:,2、打开SecureCRT,在一个session里连接三台虚拟机,就可以登录实现操作。
Fiel->Quick ConnectionProtocol:ssh2 前提条件是在中实现了ssh免密码登录Hostname: 连接的主机名Username: root 连接主机的用户名Connect依次连接好三台虚拟机<3、结果如下:4、上传windows系统中的文件到虚拟机中定位到要上传文件的目录下,输入命令:rz,回车后,弹出文件选择窗口,选择文件,点击add,再OK。
文件就上传到当前服务器的当前目录下。
rz命令如果没有安装,使用这个命令安装:yum install lrzsz安装JDK需要JDK7,由于我的CentOS自带了OpenJDK,所以要先卸载,然后解压下载的JDK并配置变量即可。
1)在/home目录下创建java目录,然后使用rz命令,上传“”到/home/java目录下,2)、3)解压,输入命令,tar -zxvf4)编辑/etc/profile—5)使配置生效,输入命令,source /etc/profile6)输入命令,java -version,完成安装提要1)secureCRT 上传“,放到/home/hadoop目录下2);3)只在master服务器解压,再复制到slave服务器(scp命令传输)4)解压,输入命令,tar -xzvf 在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name(文件中会用到)配置文件1、/home/hadoop/目录下的<configuration><property><name><value></property><property><name><value> /home/hadoop/tmp</value> </property><property><name><value>131702</value></property></configuration>2、配置/home/hadoop/目录下的<configuration><property><name><value></property><property><name><value></property><property><name></name><value>1</value></property><property><name><value>:50090</value></property><property><name><value>true</value></property></configuration>3、配置/home/hadoop/目录下的~<configuration><property><name> <value>yarn</value><final>true</final></property><property><name> <value>:50030</value></property>,<property><name> <value>:10020</value></property><property><name> <value>:19888</value></property><property><name> <value>:9001</value>$</property></configuration>4、配置/home/hadoop/目录下的<configuration><property><name> <value>mapreduce_shuffle</value></property><property> <name> <value> </property> (<property><name> <value>:8032</value></property><property><name> <value>:8030</value></property><property><name> <value>:8031</value>^</property><property><name> <value>:8033</value></property><property><name> <value>:8088</value></property><property>[<name> <value></value></property><property><name> <value>2048</value></property></configuration>提示:的值一定要注意,在最后的hello world程序运行时,会提示内存太小,(hadoop运行到: Running job后停止运行)我把它从1024改成了20485、配置/home/hadoop/目录下、的JAVA_HOME·取消注释,设置为export JAVA_HOME=/home/java/、配置/home/hadoop/目录下的slaves,删除默认的localhost,增加2个slave节点:7、将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp 传送scp -r /home/hadoop :/home/scp -r /home/hadoop :/home/启动hadoop提示:在master服务器启动hadoop,各从节点会自动启动,进入/home/hadoop/目录,hadoop的启动和停止都在master服务器上执行。
1)初始化,在目录下输入命令,bin/hdfs namenode –format2)?3)启动命令sbin/sbin/4)输入命令,jps,可以看到相关信息master上看到slave上{5)停止命令,依次执行:sbin/、sbin/至此,hadoop配置完成了。