区位码、汉字交换码和汉字机内码的概念和关系
什么是国标码什么是区位码什么是内码国标码、区位码、 内码 的关系

整个编码字符集应被表达为包含128(一个字节的低七位即27=128)个组,其中每个组表示256(28=256)个平面。每一平面包含256行,每行有256个字位。四个字节共32位足以包容世界上所有的字符,同时也符合现代处理系统的体系结构。
第一个平面(00组中的00平面)称为基本多文种平面,它包含字母文字、音节文字及表意文字等。它分成四个区:
如汉字的“大”国标码是3473H,在UCS的编码为00005927H,即在00组,00面,59H行,第27H字位上。
4. 汉字字形码
汉字字形码是表示汉字字形的字模数据,通常用点阵、矢量函数等方式表示,用点阵表示字形时,汉字字形码一般指确定汉字字形的点阵代码。字形码也称字模码,它是汉字的输出形式,随着汉字字形点阵和格式的不同,汉字字形码也不同。常用的字形点阵有16×16点阵、24×24点阵、48×48点阵等等。
1. 输入码
汉字的字数繁多,字形复杂,常用的汉字有6000—7000个,比英文的26个字母要多得多。在计算机系统中使用汉字,首先遇到的问题就是如何把汉字输入到计算机内。为了能直接使用西文标准键盘进行输入,必须为汉字设计相应的编码方法。汉字编码方法主要分为三类:数字编码、拼音编码和字形编码。
⑵拼音编码
拼音编码是以汉语读音为基础的输入方法。由于汉字同音字太多,输入重码率很高,因此,按拼音输入后还必须进行同音字选择,影响了输入速度。
⑶字形编码
字形编码是以汉字的形状确定的编码。汉字总数虽多,但都是由一笔一划组成,全部汉字的部件和笔划是有限的。因此,把汉字的笔划部件用字母或数字进行编码,按笔划书写的顺序依次输入,就能表示一个汉字,五笔字型、表形码等便是这种编码法,这种方法得缺点也是需要记忆很多的编码。五笔字型编码是最有影响的字形编码方法之一。
国标码、机内码、区位码、ASCⅡ

国标码、机内码、区位码国家标准代码:国标码国家标准代码,简称国标码。
是中华人民共和国的中文常用汉字编码集,亦为新加坡采用。
国家标准强制标准冠以“GB”,推荐标准冠以“GB/T”,国标码是一个四位十六进制数。
现时中华人民共和国官方强制使用GB 18030标准,但较旧的计算机仍然使用GB 2312。
“GB”在计算机领域中常常表示GB 2312-80或GB 18030-2005。
两者是汉语编码系统的标准,在中国大陆和新加坡用于简体中文。
机内码:国标码是不可能在计算机内部直接采用的,于是,;汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,如:由上面我们知道,“保”字的国标码为3123H,前字节为00110001B,后字节为00100011B,高位改1为10110001B和10100011B即为B1A3H,因此,“保”字的机内码就是B1A3H。
区位码1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
区位码是一个四位的十进制数,每个区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码。
ASCⅡ目前计算机中用得最广泛的字符集及其编码,是由美国国家标准局(ANSI)制定的ASCII码(American Standard Code for Information Interchange,美国标准信息交换码),它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。
区位码、汉字交换码和汉字机内码的概念和关系

区位码,汉字交换码和汉字机内码的概念是什么?它们之间有什么关系?区位码:1981年国家颁布了GB2312汉字标准共有6763个,其中一级3755,二级3008,还有682非汉字字符。
并为每个字符规定了标准编码,便于在计算机内部相互转换。
作为GB2312标准只是定义了一张94×94的二维表。
其中行为区号,列为位号。
这样可以利用区号和位号来找到其中的汉字。
这种编码就是我们所说的区位码。
比如陈(1934) 区号:19 位号:34,为了处理与存储的方便,每个汉字的区号和位号在计算机内部分别用一个字节来表示区位码无法于汉字进行通信,因为ASCII码中规定了OOH-1F作为控制码使用,这样就发生了冲突。
由于计算机不是中国人发明的所以只能听从于国际标准ISO2022规定区号和位号都加上32(20H),这样就防止冲突。
经过加上32以后的编码称为国际交换码陈-区号:19+32= 5100010011+00100000=00110011位号:34+32=6600100010+00100000=01000010即5166 16进制3342由于文本中通常混合使用汉字和西文字符,汉字信息如果不予以特别标识,就会与单字节的ASCII码混淆。
此问题的解决方法之一是将一个汉字看成是两个扩展ASCII码,使表示GB2312汉字的两个字节的最高位都为1。
这种高位为1的双字节汉字编码即为GB2312汉字的机内码,简称为“内码”.00110011最高位变为1则从33变为B301000010最高位变为1则从42变为C2这样一来,陈的机内码应该为B3C2这里要说明的是不管你是采用什么样的输入法输入汉字,其汉字的机内码都是相同的。
如果要从一个汉字的机内码转换为区位码,其实就是相反的方向进行运算.。
2汉字信息在计算机内部的表示

§4 常用汉字编码字符集 GB2312-80 BIG-5 内码识别问题 ISO10646/Unicode GB13000 GBK GB18030-2000
2011年7月21日2时22分 25/70
4.1 GB2312-80
GB2312-80:信息交换用汉字编码字符集(基本 集) 双字节内码 每个字节使用低7位 从“0000,0001”---“0101,1110” 即1-0x5E(1-94) 内码的空间:94*94=8836 收录汉字6763个,符号682个
高位:0x81-0xfe 低位:0x40-0x70,0xa1-0xfe
2011年7月21日2时22分
30/70
4.2 BIG-5(续) Big5编码空间在一个94*157的矩阵中。 Big5有94个区,每个区有157个位,因此最 多可以容纳14758个码元。 Big5中收录了13494个字符(其中,13053 个汉字和441个非汉字图形字符)。
2011年7月21日2时22分
31/70
4.2 Big-5-代码空间图
2011年7月21日2时22分
32/70
4.2 Big-5-代码分布
2011年7月21日2时22分
33/70
4.2 Big5-问题
Big5中2级汉字的排列都采用按笔画数由少到多排 列。 Big5的设计者实际上是从JIS C 626-1978中抄了 很多汉字。因为很多汉字既用于中文,又用于日 文和韩文。 Big5的许多字形与其说是中国汉字,倒不如说与 日本汉字更象。 另外,在Big5中出现了重复定义的字符:“兀”, 编码为A461,C94A;
2011年7月21日2时22分 23/70
5.7 汉字编码字符集
国标码 区位码等的区别

即GB国标码:中文内码之一,代表中文简化字,在中国大陆广泛使用,影响所及,使用量渐见普及。
“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是指1980年中国制定的用于不同的具有汉字处理功能的计算机系统间交换汉字信息时使用的编码。
国际码是二字节码, 用两个七位二进制数编码表示一个汉字。
目前国标码收入6763个汉字, 其中一级汉字(最常用)3755个, 二级汉字3008个, 另外还包括682个西文字符、图符。
例如“巧”字的代码是39H 41H, 在机内形式如下: 0 1 1 1 0 0 1 1 第一字节0 0 0 0 0 1第二字节在计算机内部,汉字编码和西文编码是共存的,如何区分它们是个很重要的问题,因为对不同的信息有不同的处理方式。
方法之一是对于二字节的国标码,将二个字节的最高位都置成“1”, 而ASCII码所用字节最高位保持“0”,然后由软件(或硬件)根据字节最高位来作出判断。
字符代码化是指用户从键盘上输入代表某个汉字的编码。
我们把采用不同的编码系统以代表汉字进行输入的方案(如数字码、拼音码和字形码),称为汉字的输入法,区位码、五笔字型码、拼音码、智能ABC、微软拼音输入法等都是其中的具体代表。
汉字通过编码输入计算机后,在其后的处理过程中,不同阶段使用不同的代码,首先通过键盘管理程序将接收到的输入编码转换为0和1构成的机内码,实现计算机的存储、加工和传输处理。
同样,存储在计算机内部的机内码也必须经转换后才能恢复汉字的“本来面目”。
这种转换通常是由计算机的输入/输出设备来实现的, 有时还需要软件来参与这种转换过程。
这个阶段的汉字代码称为字形码,用以显示和打印输出。
区位码:1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
国标、区位、汉字内码的区别

1.查一下国标码、区位码、汉字内码一样么?有什么区别?答:国家标准汉字交换码(国标码):我国制定了“中华人民共和国国家标准信息交换汉字编码”,标准代号为GB2312—80,这种编码又称为国标码。
在国标码的字符集中共收录了一级汉字3755个,二级汉字3008 个,图形符号682个,三项字符总计7445个。
国标码是指1980年中国制定的用于不同的具有汉字处理功能的计算机系统间交换汉字信息时使用的编码。
国际码是二字节码, 用两个七位二进制数编码表示一个汉字。
目前国标码收入6763个汉字, 其中一级汉字(最常用)3755个, 二级汉字3008个, 另外还包括682个西文字符、图符。
一级汉字为常用字,按拼音顺序排列,二级汉字为次常用字,按部首排列。
国标码的范围是2121H—7E7EH。
区位码:国标码是一个四位十六进制数,区位码是一个四位的十进制数,每个国标码或区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码在国标GB2312—80中规定,所有的国标汉字及符号分配在一个94行、94列的方阵中,方阵的每一行称为一个“区”,编号为01区到94区,每一列称为一个“位”,编号为01位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。
区位码的前两位是它的区号,后两位是它的位号。
用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。
汉字“母”字的区位码是3624,表明它在方阵的36区24位,问号“?”的区位码为0331,则它在03区3l位。
所有的汉字和符号所在的区分为以下四个组:(1)01区到15区。
图形符号区,其中01区到09区为标准符号区,10区到15区为自定义符号区。
01区到09区的具体内容如下;1)01区。
一般符号202个,如间隔符、标点、运算符、单位符号及制表符;2)02区。
考点3文字编码知识梳理典型例题及训练解析
考点三文字编码基础再现1、ASCII码ASCII码全称为“美国国家信息交换标准代码”,通常用来对英文字符进行编码。
该编码使用7位二进制数,共可以表示128个字符。
一个ASCII码存储时占用1字节,存储ASCII时在最高位加“0”。
ASCII码中的数字、字母按顺序依次排列。
2、汉字编码汉字在计算机内采用二进制编码,我国最早采用的汉字编码是GB2312。
每个汉字用2个字节进行编码,每个字节的最高位用“1”填充。
汉字的输入码(外码):是利用汉字相关特征对指定汉字进行编制的输入代码,包括:音码、形码、音形结合码、自然码、流水码等。
汉字的输出码(字形码):用来存储汉字的字体形状汉字的交换码:计算机系统间交换汉字通常采用GB2312标准。
处理码又称内码,用UltraEdit或WinHex工具软件观察内码时,ASCII码只占1个字节,汉字占2个字节。
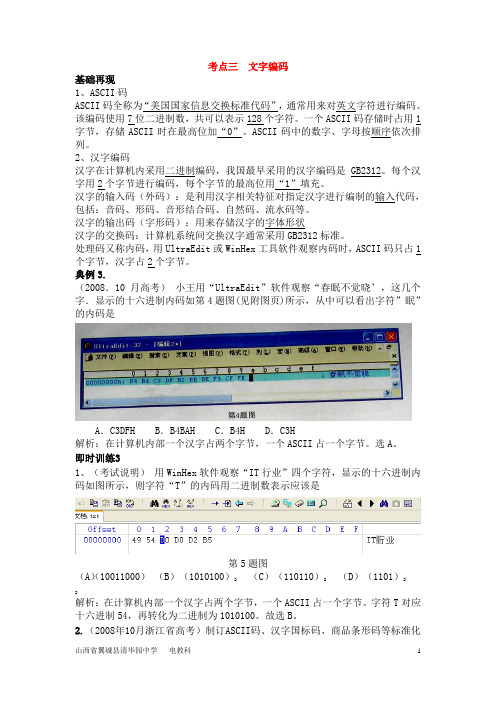
典例3.(2008.10月高考)小王用“UltraEdit”软件观察“春眠不觉晓’,这几个字.显示的十六进制内码如第4题图(见附图页)所示,从中可以看出字符”眠”的内码是A.C3DFH B.B4BAH C.B4H D.C3H解析:在计算机内部一个汉字占两个字节,一个ASCII占一个字节。
选A。
即时训练31、(考试说明)用WinHex软件观察“IT行业”四个字符,显示的十六进制内码如图所示,则字符“T”的内码用二进制数表示应该是第5题图(A)(10011000)2(B)(1010100)2(C)(110110)2(D)(1101)2解析:在计算机内部一个汉字占两个字节,一个ASCII占一个字节。
字符T对应十六进制54,再转化为二进制为1010100。
故选B。
2.(2008年10月浙江省高考)制订ASCII码、汉字国标码、商品条形码等标准化编码主要是为了信息表达的A.自由化 B.规范化 C.形象化 D.通俗化解析:考查信息标准化编码的意义,故选B。
3.(2009年3月浙江省高考)汉字点阵是一种用黑白两色点阵来表示汉字字形的编码,一个16×16点阵字模的存储容量为A.1字节B.16字节C.32字节D.64字节解析:一个点阵对应二进制1位(比特,bit或b),16×16÷8=32字节。
汉字编码系统汉字编码

为了最终显示和打印汉字,还要由汉字的机内码来换取汉字的字形码。实际上,每一个汉字的机内码也就是指向该汉字字形码的地址。
(4)汉字输出码
输出码概念:汉字输出码又称汉字字形码或汉字字模,它是将汉字字形经过点阵数字化后形成的一串二进制数,用于汉字的显示和打印。
点阵字型编码是一种最常见的字型编码,它用一位二进制码对应屏幕上的一个像素点,字形笔划所经过处的亮点用1表示,没有笔划的暗点用0表示。
采用两个字节对每个汉字进行编码,每个字节各取七位,这样可对128×128=16384个字符进行编码。
③区位码: 国家标准码先把汉字排列在一个94行×94行的方阵(二维表格)中,在此正方形矩阵中,每一行称为“区”,每一列称为“位”,这样组成了一个共有94区,每个区有94位的字符集。由这个字符集矩阵表,引出了表示汉字的两种编码,一种称这区位码,另一种被称为国标码。这两种编码都是由两个字节组成,高字节表示“区”的代码,低字节表示“位”的代码。
常见的字库:由于输出的需要,人们设计了不同字体的字形,相应也有不同的字库。有宋体字库、楷体字库、隶书字库等。
2、汉字的输入
(1)汉字输入方法概述
目前常用的汉字输入方式有:键盘输入方式、语音输入方式、手写输入方式以及扫描识别方式等。
语音输入方式:是指人们对着话筒讲话,计算机自动在屏幕上显示出对应的语句。
种类:
流水码:根据汉字的排列顺序形成汉字编码,如区位码、国标码、电报码等。
音码:根据汉字的“音”形成汉字编码,如全拼码、双拼码、简拼码等。
形码:根据汉字的“形”形成汉字编码,如王码五笔、郑码、大众码等。
音形码:根据汉字的“音”和“形”形成汉字编码,如表形码、钱码、智能ABC等。