oracle基础
OracleSQL基础培训PPT课件93页
• 适用对象
• 学习过标准SQL,未使用过Oracle数据库的读者 • 适用过SQL Server或其他数据库,未使用过Oracle数据库的读者
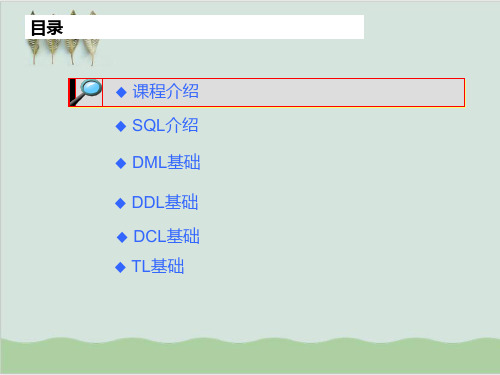
目录
课程介绍 SQL介绍 DML基础 DDL基础 DCL基础 TL基础
SQL介绍
目录
课程介绍 SQL介绍 DML基础 DDL基础 DCL基础 TL基础
课程介绍
• 教程概述
• 本教程假设读者已了解关系型数据库基本原理,明白表、视图、 主键、索引、外键、约束、关联等基本概念
• 本教程定位是Oracle SQL简明、实用教程,偏向于SQL开发,若 进一步学习Oracle数据库设计,请参阅其他教程或书籍文档
DML基础
• 逻辑运算符号
• AND 两个为真则结果为真 • OR 一个为真即为真 • NOT 取相反的逻辑值
DML基础
• SELECT语句
• 完整SELECT语句 • 基本SELECT语句 • ORDER BY从句 • DISTINCT从句 • WHERE从句 • AND条件 • OR条件 • AND、OR复合条件 • IN 与 NOT IN • BETWEEN 与 NOT BETWEEN • LIKE与NOT LIKE • EXISITS 与 NOT EXISITS • GROUP BY从句 • HAVING从句 • JOINS关联
• 示例
• SELECT * FROM suppliers WHERE (city = ‘Chicago’ AND name = ‘IBM’) OR (city = ‘Seattle’);
DML基础-SELECT语句-IN 与 NOT IN
• 用途
Oracle数据库基本知识

Oracle数据库基本知识Oracle数据库基本知识Oracle Database,又名OracleRDBMS,或简称Oracle。
是甲骨文公司的一款关系数据库管理系统。
本文为大家分享的是Oracle数据库的基本知识,希望对大家有所帮助!它是在数据库领域一直处于领先地位的产品。
可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。
它是一种高效率、可靠性好的适应高吞吐量的数据库解决方案。
介绍ORACLE数据库系统是美国ORACLE公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或B/S体系结构的数据库之一。
比如SilverStream 就是基于数据库的一种中间件。
ORACLE数据库是目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库它实现了分布式处理功能。
但它的所有知识,只要在一种机型上学习了ORACLE知识,便能在各种类型的机器上使用它。
Oracle数据库最新版本为OracleDatabase 12c。
Oracle数据库12c引入了一个新的多承租方架构,使用该架构可轻松部署和管理数据库云。
此外,一些创新特性可最大限度地提高资源使用率和灵活性,如Oracle Multitenant可快速整合多个数据库,而Automatic Data Optimization和Heat Map能以更高的密度压缩数据和对数据分层。
这些独一无二的技术进步再加上在可用性、安全性和大数据支持方面的主要增强,使得Oracle数据库12c 成为私有云和公有云部署的理想平台。
就业前景从就业与择业的角度来讲,计算机相关专业的大学生从事oracle 方面的技术是职业发展中的最佳选择。
其一、就业面广:ORACLE帮助拓展技术人员择业的广度,全球前100强企业99家都在使用ORACLE相关技术,中国政府机构,大中型企事业单位都能有ORACLE技术的工程师岗位,大学生在校期间兴趣广泛,每个人兴趣特长各异,不论你想进入金融行业还是电信行业或者政府机构,ORACLE都能够在你的职业发展中给你最强有力的支撑,成为你最贴身的金饭碗。
数据库oracle基础知识

数据库oracle基础知识数据库Oracle是一款企业级关系数据库管理系统,被广泛应用于大型企业和政府机构。
为了从事Oracle数据库开发工作,需要掌握以下基础知识。
1. SQL语言SQL语言是Oracle数据库最常用的查询和管理语言。
它可以用于创建、修改和删除表格、存储过程和函数等对象。
SQL语言可以通过命令行工具或GUI工具(如Oracle SQL Developer)使用。
2. 数据类型Oracle数据库支持多种数据类型,包括字符型、数值型、日期型和布尔型等。
掌握各种数据类型的特点和使用方法对于正确存储数据非常重要。
3. 约束在Oracle数据库中,约束是定义表列或表之间关系的规则。
包括主键、外键、唯一约束和检查约束等。
理解和正确使用约束可以有效维护数据完整性。
4. 触发器触发器是一种在表上执行的操作,例如在插入、更新和删除时。
掌握触发器的创建和使用可以帮助开发者增强数据的一致性和完整性。
5. 存储过程和函数存储过程和函数是一些预定义的SQL语句,封装起来方便被调用。
存储过程和函数类似,但存储过程是没有返回值的,而函数则需要返回一个值。
掌握存储过程和函数的使用可以提高数据库的性能和效率。
6. 高可用性Oracle数据库提供了许多机制,确保在故障时保持数据库高可用性。
这包括了备份和恢复、灾备等方案。
掌握这些机制可以帮助开发者保障数据可靠性和业务连续性。
通过学习以上基础知识,可以使Oracle数据库开发者理解Oracle数据库的基本原理和概念。
并且可以使用这些知识来开发高效、高可用性、可扩展的Oracle数据库应用程序。
Oracle数据库

Oracle数据库Oracle数据库是管理数据的一种软件系统,它可以帮助用户快速地存储、管理和检索大量的数据。
Oracle数据库由Oracle公司开发,它是世界上最强大、最可靠的数据库之一,被广泛用于企业级应用程序和数据库管理系统。
一、Oracle数据库的基础知识1. 数据库结构Oracle数据库由一个或者多个表空间组成,每个表空间包含一组数据文件。
一个表空间可以包含多个数据文件,但一个数据文件只能属于一个表空间。
2. 数据库对象Oracle数据库中的每个数据对象都具有一个唯一的名称,例如表(table)、视图(view)、序列(sequence)、索引(index)和存储过程(procedure)等。
它们都被保存在表空间中的数据文件中。
3. SQL语言Oracle数据库主要使用SQL语言来处理数据,包括数据增删改查等常用操作。
二、Oracle数据库的特点1. 效率高Oracle数据库采用高效的管理和存储技术,可以快速访问和操作大量数据。
它具有高速的缓存机制,可以快速地执行查询和更新操作。
2. 可靠性强Oracle数据库拥有高度稳定的系统架构和自动维护机制,可以保证数据的安全性和可靠性。
它可以实现多重备份,在数据发生意外错误时可以快速恢复。
3. Heterogeneous ConnectOracle数据库可以通过网络协议和连接程序实现异构连接,支持其它数据库软件,如MS SQL Server、IBM DB2等。
4. 扩展性强Oracle数据库可扩展性强,可以设计和构建分布式系统,支持跨平台分布式数据库。
5. 多功能性Oracle数据库提供多种功能,包括多种语言的支持,丰富的安全控制和数据库监视等。
6. 可伸缩性Oracle数据库可以支持大量的并发用户,可以处理多种不同的应用程序。
三、Oracle数据库的应用领域Oracle数据库被广泛应用于企业级应用程序和数据库管理系统,主要应用于以下几个领域:1. 金融领域Oracle数据库被广泛用于金融事务处理系统,包括银行、证券、保险和期货等金融机构的资金结算和清算等数据处理。
Oracle基础面试题

Oracle基础面试题什么是替换变量它有什么用答:在SQL*Plusk中用变量来替代列名或表达式,该变量称为替换变量。
执行带替换变量的语句时,用户会得到提示,要求输入具体的值。
用户输入的值存储在预定义的变量中。
什么是表空间表空间的作用是什么答:表空间是由一个或多个磁盘文件构成的,一个数据库中的数据被逻辑地存储在表空间上,表空间相当于操作系统中的文件夹,表空间实质上就是组织数据文件的一种途径。
主要用于管理逻辑对象。
在将数据插入Oracle数据库之前,必须首先建立表空间,然后将数据插入表空间的一个对象中。
什么是假脱机输出它有什么用答:假脱机只将信息写到磁盘文件的一个过程。
记录一系列命令和结果或者存储来自一个命令的大量输出结果。
什么是Oracle数据字典它有哪几种答:Oracle数据字典由一组表和视图构成,用于存储Oracle系统的活动信息和所有用户数据库的定义信息等。
根据所存储内容的不同,可以把数据字典划分为两大类:表态数据字典和动态性能表,数据字典是数据库系统的一部分,它所在的表空间为SYSTEM表空间,动态性能表是一组虚拟表,记录了当前数据库的活动情况和性能参数。
什么是同义词它有哪几种它有什么作用答:同义词是指用新的标识符来命名一个已经存在的数据对象,是数据库对象(表、视图、序列、过程、函数、包等)的别名。
同义词可划分为两类:公用(PUBLIC)同义词和私有(PRIVATE)同义词使用同义词能够掩盖一个数据库对象的名字及其持有者,也可以为一个分布式数据库的远程对象提供位置透明性。
什么是序列它有什么用答:序列是以有序的方式创建一个不重复的整数值的数据库对象。
使用序列可以减少编写序列生成代码所需的应用代码的工作量,程序员经常用序列来简化一些程序的设计工作。
ORACLE EBS MRP计划基础

物料需求计划(MRP) -- 基本概念
影响计划订单数的因数
最小定单数 最大定单数 固定定单批量 固定定单批量增量 整数控制 损耗率 利用率
物料需求计划(MRP) -- 基本概念
计划参数
考虑采购 包括批准的请购,批准的采购定单 考虑制造 包括标准与非标准的作业 考虑的仓库 所有项目/只计划项目 从计划开始日期计算或从工序开始日期计算
计划标准流程
订单 预测
主需求计划 粗能力计划 主生产计划 库存模块 BOM模块
物料需求计划
能力需求计划 车间模块 采购模块
两个概念
需求/供应
依赖需求/独立需求
依赖需求/独立需求
概念 定义 由何决定 举例
需求的类型 -- 依赖需求/独立需求
独立需求 需求不依赖于其他物品 预测和销售订单 最终物品 依赖需求 需求依赖于其他物品 计划计算时生成 子装配,组件,未加工材料
提前期(Lead
Times) -- 续
总提前期
处理提前期加上预处理提前期
累计制造提前期
处理提前期加上关键子装配的处理提前期
累计总提前期
处理提前期加上关键子装配和采购组件的处理提前期
总提前期 装配:制造 子装配:制造 组件:采购 累计制造提前期 处理前提前期 处理提前期 处理后提前期
累计总提前期
到岸日期(采购) = 到期日期- 处理后提前期 到岸日期(制造) = 到期日期
开始日期 = 到期日期 - 提前期偏置
定单日期 = 开始日期 - 处理前提前期
物料需求计划(MRP) -- 基本概念
计划定单数量 = 毛需求-供应 = (总需求+安全库存)-(手头量+计划接收)
Oracle_基本建表语句
Oracle_基本建表语句--创建⽤户create user han identified by han default tablespaceusers Temporary TABLESPACE Temp;grant connect,resource,dba to han; //授予⽤户han开发⼈员的权利--------------------对表的操作----------------------------创建表create table classes(id number(9) not null primary key,classname varchar2(40) not null)--查询表select * from classes;--删除表drop table students;--修改表的名称rename alist_table_copy to alist_table;--显⽰表结构describe test --不对没查到-----------------------对字段的操作-------------------------------------增加列alter table test add address varchar2(40);--删除列alter table test drop column address;--修改列的名称alter table test modify address addresses varchar(40;--修改列的属性alter table test modicreate table test1(id number(9) primary key not null,name varchar2(34))rename test2 to test;--创建⾃增的序列create sequence class_seq increment by 1 start with 1 MAXVALUE 999999 NOCYCLE NOCACHE;select class_seq.currval from dual--插⼊数据insert into classes values(class_seq.nextval,'软件⼀班')commit;--更新数据update stu_account set username='aaa' where count_id=2;commit;--创建唯⼀索引create unique index username on stu_account(username); --唯⼀索引不能插⼊相同的数据--⾏锁在新打开的对话中不能对此⾏进⾏操作select * from stu_account t where t.count_id=2 for update; --⾏锁--alter table stuinfo modify sty_id to stu_id;alter table students drop constraint class_fk;alter table students add constraint class_fk foreign key (class_id) references classes(id);--外键约束alter table stuinfo add constraint stu_fk foreign key (stu_id) references students(id) ON DELETE CASCADE;--外键约束,级联删除alter table stuinfo drop constant stu_fk;insert into students values(stu_seq.nextval,'张三',1,sysdate);insert into stuinfo values(stu_seq.currval,'威海');select * from stuinfo;create table zhuce(zc_id number(9) not null primary key,stu_id number(9) not null,zhucetime date default sysdate)create table feiyong (fy_id number(9) not null primary key,stu_id number(9) not null,mx_id number(9) not null,yijiao number(7,2) not null default 0,qianfei number(7,2) not null)create talbe fymingxi(mx_id number(9) not null primary key,feiyong number(7,2) not null, //共7位数字,⼩数后有两位 class_id number(9) not null}create table card(card_id number(9) primary key,stu_id number(9) not null,money number(7,2) not null default 0,status number(1) not null default 0 --0表可⽤,1表挂失)--链表查询select c.classname||'_'||s.stu_name as 班级_姓名,si.address from classes c,students s , stuinfo si where c.id=s.class_id and s.id=si.stu_id;insert into students values(stu_seq.nextval,'李四',1,sysdate); insert into stuinfo values(stu_seq.currval,'南京');--函数select rownum,id,stu_name from students t order by id asc;--中间表实现多对多关联--(1 1, 1 n,n 1,n n )--1 n的描述 1的表不作处理 n的表有1表的字段--1 1的描述主外键关联--n n的描述中间表实现多对多关联create table course(course_id number(9) not null,couser_name varchar2(40) not null)alter table course to couse;create table stu_couse(stu_couse_id number(9) primary key,stu_id number(9) not null,couse_id number(9) not null)create unique index stu_couse_unq on stu_couse(stu_id,couse_id); --唯⼀学⽣create sequence stu_couse_seq increment by 1 start with 1 MAXVALUE 999999 NOCYCLE NOCACHE;create sequence couses_seq increment by 1 start with 1 MAXVALUE 999999 NOCYCLE NOCACHE;insert into course values(couses_seq.nextval,'计算机原理');insert into course values(couses_seq.nextval,'编译原理');insert into course values(couses_seq.nextval,'数据库原理');insert into course values(couses_seq.nextval,'数据结构');insert into course values(couses_seq.nextval,'计算机基础');insert into course values(couses_seq.nextval,'C语⾔初步');commit;insert into stu_couse values(stu_couse_seq.nextval,1,1);insert into stu_couse values(stu_couse_seq.nextval,1,3);insert into stu_couse values(stu_couse_seq.nextval,1,5);insert into stu_couse values(stu_couse_seq.nextval,1,5);insert into stu_couse values(stu_couse_seq.nextval,2,1);commit;select * from stu_couse;select * from course;--select s.stu_name,sc.couse_id, c.couser_name from students s,course c,stu_couse sc where stu_id=1--select couse_id from stu_couse where stu_id=1select cl.classname,s.stu_name,c.couser_name from stu_couse sc, students s,course c,classes cl where s.id=sc.stu_id and sc.couse_id=c.course_id and s.class_id=cl.id and s.id=1;--班级——姓名select c.classname,s.stu_name from students s,classes c wheres.class_id=c.id and s.id=2;select * from students s where s.id=2--班级——姓名——课程select cl.classname,s.stu_name,c.couse_name from stu_couse sc,students s,classes cl,couse c where sc.stu_id=s.id and sc.couse_id=c.couse_id and s.id=26;--sql 语句的写法,现写出关联到的表,然后写出要查找的字段,第三写出关联条件,记住在写关联到的表时先写数据多的表,这样有助于提⾼sql的效率select c.couser_name,s.stu_name from stu_couse sc,students s,course c where c.course_id=1 and c.course_id=sc.couse_id and sc.stu_id=s.id;select s.stu_name from students s,stu_couse sc where s.id=sc.stu_id group by s.id,s.stu_name;select c.classname,count(sc.couse_id) from stu_couse sc,studentss,classes c where s.class_id=c.id and s.id=sc.stu_id group byc.classname;select s.stu_name, count(sc.couse_id) from stu_couse sc,studentss,classes cl where s.id=sc.stu_id group by s.id,s.stu_name having count(sc.stu_couse_id)>3;班级学⽣选课数量select cl.classname,count(sc.stu_couse_id) from stu_couse sc,students s,classes cl where s.id=sc.stu_id ands.class_id=cl.id group bycl.classname;--班级学⽣选课数量select cl.classname,s.stu_name,count(sc.stu_couse_id) from stu_couse sc,students s,classes cl where s.id=sc.stu_id and s.class_id=cl.id group by s.stu_name;select cl.classname,s.stu_name,count(sc.stu_couse_id) from stu_couse sc ,students s,classes cl where sc.stu_id=s.id and s.class_id=cl.id group by s.id;select cl.classname,s.stu_name,count(sc.stu_couse_id) from stu_couse sc,students s,classes cl where sc.stu_id=s.id and s.class_id=cl.id group by s.stu_name;--班级学⽣所选课程id 所选课程名称--创建试图⽬的把表联合起来然后看成⼀个表,在与其他的联合进⾏查询create view xsxk as select cl.classname,s.stu_name,c.couse_id,c.couse_name from stu_couse sc,students s,classes cl,couse c where sc.stu_id=s.id and sc.couse_id=c.couse_id and s.class_id=cl.id;select * from xsxkcreate view classstu as select s.id,c.classname,s.stu_name from students s,classes c where c.id=s.class_id;drop view classstu; --删除视图select * from classstu;create view stu_couse_view as select s.id ,c.couse_name from stu_couse sc,students s,couse c where s.id=sc.stu_id and sc.couse_id=c.couse_id; select * from stu_couse_view;create view csc as select cs.classname,cs.stu_name,scv.couse_name from classstu cs,stu_couse_view scv wherecs.id=scv.id;select * from csc;select * from classes cross join students; --全连接,相当于select * from classes,students;select * from classes cl left join students s on cl.id=s.class_id; --左连接不管左表有没有都显⽰出来select * from classes cl right join students s on cl.id=s.class_id; --右连接select * from classes cl full join students s on cl.id=s.class_id; --全连接insert into classes values(class_seq.nextval,'软件四班');create table sales(nian varchar2(4),yeji number(5));insert into sales values('2001',200);insert into sales values('2002',300);insert into sales values('2003',400);insert into sales values('2004',500);commit;select * from sales;drop table sale;select s1.nian,sum(s2.yeji) from sales s1,sales s2 wheres1.nian>=s2.nian group by s1.nian order by s1.nian desc;select s1.nian,sum(s2.yeji) from sales s1,sales s2 wheres1.nian>=s2.nian group by s1.nian;s年年业绩总和2001 2002002 5002003 9002004 1400create table test1(t_id number(4));create table org(org_id number(9) not null primary key,org_name varchar2(40) not null,parent_id number(9));create sequence org_seq increment by 1 start with 1 MAXVALUE 999999 NOCYCLE NOCACHE; drop sequence org_seq;insert into org values(1,'华建集团',0);insert into org values(2,'华建集团⼀分公司',1);insert into org values(3,'华建集团⼆分公司',1);insert into org values(4,'华建集团财务部',1);insert into org values(5,'华建集团⼯程部',1);insert into org values(6,'华建集团⼀分公司财务处',2);insert into org values(7,'华建集团⼀分公司⼯程处',2);select * from org;--不正确不能实现循环select /doc/5e8716366.html_id , /doc/5e8716366.html_name ,b.parent_id from org a,org b where/doc/5e8716366.html_id=7 and a.parent_id=/doc/5e8716366.html_id;select * from org connect by prior parent_id=org_id start with org_id=7 order by org_id;select * from org connect by prior org_id=parent_id start with org_id=1 order by org_id;create table chengji(cj_id number(9) not null primary key,stu_cou_id number(9) not null,fen number(4,1));insert into chengji values(1,1,62);insert into chengji values(2,2,90);insert into chengji values(3,3,85);insert into chengji values(4,4,45);insert into chengji values(5,5,68);insert into chengji values(6,6,87);commit;select * from chengji;select * from stu_couse;--在oracle 中好像不适⽤ alter table chengji change stu_cou_idstu_couse_id;alter table shop_jb change price1 price double;学⽣姓名平均分select s.stu_name,avg(cj.fen) from stu_couse sc,chengji cj,students s where s.id=sc.stu_id andsc.stu_couse_id=cj.stu_couse_id group bys.id,s.stu_name;select s.stu_name from students s,stu_couse sc,chengji cj wheres.id=sc.stu_id and sc.stu_couse_id=cj.stu_couse_id group bys.id,s.stu_name;select s.stu_name,cj.fen from students s,stu_couse sc,chengji cj where s.id=sc.stu_id and sc.stu_couse_id=cj.stu_couse_id and cj.fen>60;学⽣姓名科⽬成绩select s.stu_name,c.couse_name,cj.fen from stu_couse sc,studentss,couse c,chengji cj where sc.stu_id=s.id and sc.couse_id=c.couse_id and sc.stu_couse_id=cj.stu_couse_id and cj.fen>60 order by=;select * from stu_couse;--集合运算--选择了课程3的学⽣ union 选择了课程5的学⽣并集--选择了课程3 或者选择了课程5的学⽣select s.stu_name from students s,couse c,stu_couse sc wheres.id=sc.stu_id and sc.couse_id=c.couse_id and c.couse_id=3unionselect s.stu_name from students s,couse c,stu_couse sc wheres.id=sc.stu_id and sc.couse_id=c.couse_id and c.couse_id=5--选择了课程3,5,2 的学⽣ intersect 选择课程1,2,4的学⽣交集--求选择了课程 2 并且选择了课程 3 的学⽣交集select s.stu_name from students s,couse c,stu_couse sc wheres.id=sc.stu_id and sc.couse_id=c.couse_id and c.couse_id=2intersectselect s.stu_name from students s,couse c,stu_couse sc wheres.id=sc.stu_id and sc.couse_id=c.couse_id and c.couse_id=3;--选择了课程3,5,8的学⽣ minus 选择了课程1,7,8的学⽣ --差集-- 求所有课程的成绩都⼤于 60 的学⽣差集select distinct(s.stu_name) from stu_couse sc,students s,couse c,chengji cj where sc.stu_id=s.id andsc.couse_id=c.couse_id andsc.stu_couse_id=cj.stu_couse_id and cj.fen>60minusselect distinct(s.stu_name) from stu_couse sc,students s,couse c,chengji cj where sc.stu_id=s.id andsc.couse_id=c.couse_id andsc.stu_couse_id=cj.stu_couse_id and cj.fen<60;⼀、何謂分區表(索引)?分區表是⼀種數據庫的物理存儲機制,它將⼀個表的數據存儲在不同的存儲⽚段中,這些不同的存儲⽚稱為區(partition)。
oracle基础select查询语句
select dname "工资" from dept;--查询全部员工select * from emp;--查询指定的编号,姓名和职位select empno,ename,job from emp;--修改显示别名空格,数字和特殊符号(#$除外)做别名需要双引号select empno as "1" ,ename 员工姓名,job "职位" from emp;--去除重复行select distinct job from emp;--列拼接select concat(concat(concat(concat(concat(' 编号是:',empno ),'的雇员,姓名是:'),ename) ,'工作是:'),job) from emp;--oracle用简单办法||拼接select '编号:' || empno || '的雇员,姓名是:' || ename || ',工作是:' || job from emp;--使用nvl (v1,v2)处理空值v1不为空返回,v2为空返回v2select ename,sal,comm,sal*12 + nvl (comm,0) from emp;--使用decodeselect ename,sal,comm,sal*12 + decode(comm,null,0,comm)from emp;--单行单列虚拟表dualselect sysdate from dual--得到一个32位的唯一guidselect sys_guid() from dual;--进行加减乘除运算select 1+3 from dual--oracle条件语句查询--查询出基本工资大于2000的所有雇员信息select * from emp where sal > 2000;--查询职位是办事员的所有雇员信息select * from emp where job ='CLERK'--查询工资在2000-3000之间的员工信息select * from emp where sal>2000 and sal < 3000;--查询工资在2000-3000之间的全部雇员信息*(包含)select * from emp where sal >= 2000 and sal <=3000;select * from emp where sal between 2000 and 3000;--查询职位是办事员或者销售人员的全部信息select * from emp where job='CLERK' or job='SALESMAN';select * from emp where job in ('CLERK','SALESMAN');--查询所用不是办事员的雇员信息select * from emp where job <>'CLERK';select * from emp where job != 'CLERK';select * from emp where not job = 'CLERK';--查询所有某段时间内入职的员工信息select * from emp where hiredate between to_date('1981/1/1','yyyy/mm/dd') and to_date('1982/1/1','yyyy/mm/dd');--查询所有有奖金的雇员select * from emp where comm is not null;--查询所有没有奖金的雇员select * from emp where comm is null;--查询出员工编号为7369.7499,7521的信息select * from emp where empno =7369 or empno=7499;select * from emp where empno in (7369,7499,7521)--查询出员工编号不为7369.7499,7521的信息select * from emp where empno not in (7369,7499,7521);--查询员工姓名中以字母A为开头的全部员工信息select ename from emp where ename like 'A%';--查询员工姓名中第二个字母是A的全部员工信息select ename from emp where ename like '_A%';--查询员工姓名中有A的全部员工信息select ename from emp where ename like '%A%';--oracle结果排序--查询所有员工,并按照要求工资升序排序select * from emp order by sal;--查询所有员工,并按照要求工资升序排序select * from emp order by sal desc;--按照工资从高到低排序,如果工资相同,则按照雇佣时间先后排序select * from emp order by sal desc, hiredate;--排序中的空值问题select * from emp order by comm desc;select * from emp order by comm desc nulls first;select * from emp order by comm desc nulls last;--oracle单行函数--字符函数--字符串大写upperselect upper('mingming')from dual;--字符串小写lowerselect lower(ename) from emp;--首字符大写initcapselect initcap(ename) from emp;--字符串取长度lengthselect ename,length(ename) from emp;--字符串替换replaceselect ename,replace(ename,'A','#')from emp;--字符串截取substrselect ename,substr(ename,0,2) from emp; select ename,substr(ename,1,2) from emp;select ename,substr(ename,-1) from emp;select ename,substr(ename,-2,1) from emp; select ename,substr(ename,-2,3) from emp;--两边去掉空格trimselect ename,trim(ename) from emp;--数字函数--四舍五入select round(987.6543) from dual;--988select round(987.6543,0) from dual;--988select round(987.6543,1) from dual;--987.7 select round(987.6543,2) from dual;--987.65 select round(987.6543,-1) from dual;--990select round(987.6543,-2) from dual;--1000--trunc舍弃内容select trunc(953.6286) from dual; --953select trunc(953.6286,0) from dual;--953select trunc(953.6286,1) from dual;--953.6select trunc(953.6286,2) from dual;--953.62 select trunc(953.6286,-1) from dual;--950select trunc(953.6286,-2) from dual--900--取模mod /余数select mod(10,3) from dual;--日期函数--获取当前时间sysdateselect sysdate from dual;--表示几天之后的日期+dayselect sysdate+3 from dual;--两个日期之间的天数差sysdate-hiredate select ename,hiredate,sysdate-hiredate from emp ; select trunc(sysdate-hiredate) from emp ;--本月的最后一天日期last_dayselect last_day(sysdate) from dual;--两个日期键的月份差months_betweenselect ename,hiredate ,trunc(MONTHS_BETWEEN(sysdate,hiredate)) from emp;--求出四个月后的日期add_montsselect add_months(sysdate,2)from dual;--转换函数--日期变为字符串to_char*(mi,hh24,yyyy,day)select to_char(sysdate,'yyyy-mm-dd')from dual;--2017-11--12select to_char(sysdate,'yyyy-mm-dd hh:mi:ss')from dual;--2017-11-12 05:07:00--数字变为字符串to_char(L999,999,999)数字代表长度SELECT TO_CHAR(89078907890,'L9999,9999,9999,9999') FROM dual;-- $89,078,907,890--字符串转日期to_date(yyyy-mm-dd hh:mi:ss)--字符串必须是日期格式的字符串select to_date('2017-11-12','yyyy/mm/dd') from dual;--2017/11/12--字符串转数字to_number('123'+4)select to_number('123'+4) from dual--127--通用函数--nvl(v1,v2)处理null 如果第一个数为null返回第二个数,如果第一个数不为空返回第一个数select nvl(1,2)from dual;--1select nvl(null,2) from dual;--2--nvl(v1,v2,v3)处理null; 如果v1为null返回v3,否则返回v2select nvl2(null,1,2) from dual;select nvl2(3,1,2) from dual;--decode()多值判断DECODE(数值| 列,判断值1,显示值1,判断值2,显示值2,判断值3,显示值3,…)--将职位信息转为汉字SELECT empno,ename,job,DECODE(job,'CLERK','办事员','SALESMAN','销售人员','MANAGER','经理','ANALYST','分析员','PRESIDENT','总裁')FROM emp;--case when条件判断--将职位信息转为汉字select empno,ename,job,case jobwhen 'CLERK' then'业务员'when 'SALESMAN' then'销售人员'else'其他'endfrom emp;--oracle多行函数分组函数作用于一组数据,并对一组数据返回一个值--统计记录数count() 查询出所有员工的记录数select count(*) from emp;--不建议使用count(*),可以使用一个具体的列以免影响性能select count(empno) from emp;--最小值查询min()查询出来员工最低工资select min(sal) from emp;--最大值查询max()查询出来员工最高工资select max(sal) from emp;--查询平均值avg()查询出员工的平均工资select avg(sal) from emp;--求和函数sum()查询出某部门额员工工资总和select sum(sal) from emp where deptno=20;--分组汇合统计group by--查询每个部分的人数select deptno,count(*) from emp group by deptno;--查询出每个部分的平均工资select deptno,avg(sal)from emp group by deptno;--唯一字段做分组select ename,count(*) from emp group by ename;--过滤分组数据having--查询部分平均工资大于2000的部门,用having和where都可以实现select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;--第二天多表查询--笛卡尔集select * from emp,dept;--内连接--隐式内连接select e.empno,e.ename,e.job,d.dname from emp e,dept d where e.deptno = d.deptno;--显示内连接select e.empno,e.ename,e.job,d.dname from emp e inner join dept d on e.deptno =d.deptno; --左外连接select * from dept left join emp on dept.deptno = emp.deptno;--右外连接select * from emp e right join dept d on e.deptno=d.deptno;--oracle特有外连接--使用符号(+):放在作为补充显示的列后面select * from emp,dept where emp.deptno(+)=dept.deptno;--自连接--查询出员工的姓名,职位,领导姓名select * from emp a,emp b where a.mgr=b.empno;--使用左右外连接,找到没有领导的员工select * from emp a,emp b where a.mgr=b.empno(+);--多表联查--查询员工姓名,部门名称,领导姓名select e1.ename,e2.ename,d.dname from emp e1,emp e2,dept d where e1.mgr=e2.empno and e1.deptno=d.deptno;--查询员工姓名,部门名称,领导名称,员工工资等级select e1.ename,e2.ename,d.dname,s.grade from emp e1,emp e2,dept d,salgrade s where e1.mgr=e2.empno and e1.deptno=d.deptno and e1.sal between s.losal and s.hisal;--查询员工姓名、部门名称、领导名称、员工工资等级、领导工资等级select e1.ename, e2.ename, d.dname, s1.grade,s2.gradefrom emp e1, emp e2, dept d, salgrade s1,salgrade s2where e1.mgr = e2.empnoand e1.deptno = d.deptnoand e1.sal between s1.losal and s1.hisaland e1.sal between s2.losal and s2.hisal;--将工资等级转换为汉字select e1.ename, e2.ename, d.dname, decode(s1.grade,'1','第五级','2','第四级','3','第三级','4','第二级' ,'5','第一级'),decode(s2.grade,'1','第五级','2','第四级','3','第三级','4','第二级' ,'5','第一级')from emp e1, emp e2, dept d, salgrade s1,salgrade s2where e1.mgr = e2.empnoand e1.deptno = d.deptnoand e1.sal between s1.losal and s1.hisaland e1.sal between s2.losal and s2.hisal;--子查询--单行子查询(单行单列)--查询比员工7654工资高,并和7788相同职位的员工select e.ename from emp e where e.sal>(select sal from emp where empno=7654)and e.job=(select job from emp where empno =7788)Select * from emp where sal>(Select sal from emp where empno=7654)And job = (Select job from emp where empno=7788)--子查询放在select中--查询员工信息和部门名称select e.* ,(select d.dname from dept d where d.deptno=e.deptno)from emp e ;--多行子查询(多行多列和多行单列)--多行多列子查询实现--查询每个部门的最低工资,和最低工资的员工select e.ename,e.sal,d.dname from emp e,(select deptno ,min(sal) sal from emp group by deptno) dm,dept d where e.deptno = d.deptno and e.deptno = dm.deptno and e.sal= dm.sal;Select e.ename,e.sal,d.dnameFrom emp e,(Select deptno,min(sal) sal from emp group by deptno) dm,dept dWhere e.deptno=d.deptno and e.deptno=dm.deptno And e.sal = dm.sal--多行单列子查询实现--查询是领导的所有员工信息select * from emp where emp.empno in(select mgr from emp e where e.mgr is not null);--查询不是领导的所有员工信息select * from emp where empno not in (select nvl(mgr,0) from emp)--exists--判断结果集是否存在exists(sql语句)--用来判断结果集是否存在,如果存在返回true,如果不存在返回falseselect * from emp where exists (select * from dept)--查询有员工的部门select * from dept where deptno in (select deptno from emp where deptno is not null)select * from dept d where exists (select deptno from emp e where e.deptno= d.deptno )--查询是领导的所有的员工信息select * from emp e1 where exists (select e2.mgr from emp e2 where e2.mgr= e1.empno)--伪列rownumselect rownum, e.* from emp e;--查询员工信息的前三条select rownum, e.* from emp e where rownum<4;--排序后rownum乱序select rownum ,e.* fROM emp e where rownum<20 order by sal desc ;--解决办法,先排序再生成rownumselect * from emp order by sal desc;select rownum ,e.* from (select * from emp order by sal desc)e where rownum <4;select * from(Select rownum rm, t.* from (select * from emp order by sal desc) t) where rm<4--找到员工表中薪水大于本部门平均薪水的员工--本部门平均薪水select deptno,avg(sal) from emp group by deptno;select * from emp e,(select deptno,avg(sal)avs from emp group by deptno)m where e.sal>m.avs and e.deptno=m.deptno;--统计每年入职的员工个数select to_char(e.hiredate,'yyyy')hire_year,count(*) from emp e group by to_char(hiredate,'yyyy');SelectSum(hire_count) total,sum(decode(t.hire_year,'1980',t.hire_count)) "1980",sum(decode(t.hire_year,'1981',t.hire_count)) "1981",sum(decode(t.hire_year,'1982',t.hire_count)) "1982",sum(decode(t.hire_year,'1987',t.hire_count)) "1987"from(Select to_char(hiredate,'yyyy') hire_year,count(*) hire_countFrom emp group by to_char(hiredate,'yyyy')) trowidRowid是oracle数据库插入数据时给数据分配的真实物理地址,唯一不变Rownum 是伪列,在查询数据时才会生成的临时数值--集合运算--并集--查询工资大于1500或是20号部分的员工select * from emp where sal>1500 or deptno=20;--union实现select * from emp where sal>1500unionselect * from emp where deptno =20;--union all实现(没有去重)select * from emp where sal>1500union allselect * from emp where deptno =20;--交集*(intersect 取两个集合共同的部分)select * from emp where sal >1500 and deptno=20;select * from emp where sal >1500intersectselect * from emp where deptno=20;--差集(minus 从一个集合中去掉另一个集合剩余的部分)--1981年入职的普通员工,不包含总裁和经理select * from emp where to_char(hiredate,'yyyy')='1981'and job not in ('MANAGER','PRESIDENT')select * from emp where to_char(hiredate,'yyyy')='1981'minusselect * from emp where job in ('MANAGER','PRESIDENT')。
ORACLE-EBS-基础设置要点简介
ORACLE-EBS-基础设置要点简介概述Oracle E-Business Suite(简称EBS)是一款企业级应用软件,它的设计目标是为企业提供全面的业务解决方案,包括财务、人力资源、供应链管理、客户关系管理等多个模块。
在使用EBS之前,需要进行一些基础设置,以确保系统的正常运作和最好的性能效果。
本文将介绍EBS基础设置的要点,包括语言支持、日期和货币、服务器配置、访问控制等。
语言支持EBS支持多种语言,用户可以根据需要进行自由切换。
在设置中,需要将语言设置为“负载均衡(HTTP)”或“标准”的形式。
此外,还可以针对特定用户设置语言,具体方法如下:1.在“用户维护”中进行如下设置用户界面语言:英语报表语言:英语2.在“用户个人设置”中进行如下设置首选语言:英语日期和货币对于日期和货币的设置,需要根据不同的国家和地区进行选择。
在EBS中,可以通过运行“日期和货币设置”的功能来进行设置,具体步骤如下:1.找到“运行窗口”或“应用程序菜单”,输入“日期和货币设置”和相应的国家或地区。
2.选择适当的日期格式和货币符号。
3.点击“提交”按钮,保存设置。
服务器配置针对不同的业务需求和规模,EBS的服务器配置需要进行适当的调整。
其中,包括以下几个方面:1.并发管理:EBS支持多个并发事务的同时运行,但需要进行相关的实时监控和限制。
2.内存和磁盘:对于大型企业,需要将EBS的内存和磁盘空间适当地进行扩展,以确保系统的正常运作和快速响应。
3.网络:在分布式环境中,不同的应用服务器需要进行适当的网络配置,以确保数据的安全传输和高效访问。
访问控制为了保护EBS系统的安全性,必须进行严格的访问控制。
安全策略应包括以下要点:1.密码策略:设置密码长度、复杂度等特性,规定用户更改密码的频率,以尽可能保障系统安全。
2.角色权限:为不同的用户设置不同的应用程序权限、菜单权限、功能权限和数据权限,以确保资源的合理分配和使用。
Oracle11g数据库基础教程-参考答案资料
SMON进程的主要功能包括:在实例启动时负责对数据库进行恢复;回收不再使用的临
时空间;将各个表空间的空闲碎片合并。
PMON进程的主要功能包括:负责恢复失败的用户进程或服务器进程,并且释放进程所
占用的资源; 清除非正常中断的用户进程留下的孤儿会话, 回退未提交的事务, 释放会话所
占用的锁、 SGA、 PGA 等资源;监控调度进程和服务器进程的状态,如果它们失败,则尝试
修改右侧对话框中
第 2 章 Oracle 数据库管理与开发工具
1.简答题
(1)
实现对 Oracle 运行环境的完全管理, 包括 Oracle 数据库、 Oracle 应用服务器、 HTTP 服务器等的管理;
实现对单个 Oracle 数据库的本地管理,包括系统监控、性能诊断与优化、 对象管理、存储管理、安全管理、作业管理、数据备份与恢复、数据移植等;
适合于工作组或部门级
的应用程序: 个人版数据库服务器只提供基本数据库管理功能和特性,
适合单用户的开发环
境,为用户提供开发测试平台。
(2)
常用数据库类型包括事务处理类、 数据仓库类以通用类型。 其中事务处理类型主要针对
具有大量并发用户连接, 并且用户主要执行简单事务处理的应用环境。 事务处理数据库的典 型应用有银行系统数据库、 Internet 电子商务数据库、证券交易系统数据库等。对于需要较 高的可用性和事务处理性能、 存在大量用户并行访问相同数据以及需要较高恢复性能的数据
Oracle 数据库物理结构包括数据文件、控制文件、重做日志文件、初始化参数文件、归 档文件、 口令文件等。 在控制文件中记录了当前数据库所有的数据文件的名称与位置、 日志文件的名称与位置,以及数据文件、重做日志文件的状态等。 (3)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第1章OraCIe 9i基础1.1关系型数据库系统简介111什么是关系型数据关系型数据是以关系数学模型来表示的数据。
关系数学模型中以二维表的形式来描述数据, 如表1.1和表1.2所示。
表Ll研究生信息二维表表1.2导师信息二维表1.1.2什么是关系型数据库L什么是主码(主键)能够唯一表示数据表中的每个记录的【字段】或者【字段】的组合就称为主码。
2.什么是外码(外键)表1.2的【编号】字段和表1.1的【导师编号】字段是对应的。
表1.2中的【编号】字段是表1.2的主码。
表1.2中的【编号】字段又可以称为是表1.1的外码。
1.1.3什么是关系型数据库系统一个完整的关系型数据库系统包含5层结构,如图U所示。
图1.1关系型数据库系统的层次结构1.硬件硬件指安装数据库系统的计算机,包括两种。
服务器客户机2.操作系统操作系统指安装数据库系统的计算机采用的操作系统。
3.关系型数据库管理系统、数据库关系型数据库是存储在计算机上的、可共享的、有组织的关系型数据的集合。
关系型数据库管理系统是位于操作系统和关系型数据库应用系统之间的数据库管理软件。
4.关系型数据库应用系统关系型数据库应用系统指为满足用户需求,采用各种应用开发工具(如VB、PB和DelPhi 等)和开发技术开发的数据库应用软件。
5.用户6户指与数据库系统打交道的人员,包括如下3类人员。
最终用户数点库应用系统开发员数据库管理员113什么是关系型数据库管理系统1.数据定义语言及翻译程序DDL2.数据操纵语言及编译(解释)程序DML3.数据库管理程序1.2网络关系型数据库的代表OraCIe 9i1.2.1 Oracle 9i数据库1.企业片反(Enterprise Edition)2.标准版(StandardEdition)3.个人版(PerSOnalEdiIiOn)1.2.2 Oracle 9i应用服务器Oracle 9应用服务器有两种版本。
1.企业版(EnterPriSeEdilion)企业版主要用于构建互联网应用,面向企业级应用,,2.标准版(Standard Edition)标准版用于建立面向部门级的Web应用。
1.2.3 Oracle 9i开发工具套件Oracle 9i开发工具套件是一整套的OraCIe 9i应用程序开发工具。
1.3Oracle 9i的特点Oracle 9i在集群技术、高可用性、商业智能、安全性、系统管理等方面都实现了新的突破, 其特点主要包括如下内容。
1.3.1 集群技术集群的原理如图所示。
1.3.2 联机分析处理、数据挖掘和分析技术1 .什么是联机分析处理当今的数据处理大致可以分成两大类:联机事务处理OLTP (on-line transaction processing)、联机分析处理OLAP (On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
2 .什么是数据仓库图1.3数据仓库的体系结构3 .什么是数据挖掘和分析数据分析是从大量的数据中获取所需要的决策数据的技术。
数据挖掘是从数据仓库中由数据分析工具主动发现并提取隐藏在数据仓库内部的信息的新技术。
1.3.3智能管理 1.3.3分布式第2章 构建环境一安装OraCIe 9i1.1 安装数据库服务器采用Windows 2000 Server 作为安装的网络操作系统平台,数据库服务器采用Oracle 9i Database for Windows 2000 的企业版。
1.1.1安装的硬件环境需求下列从5个主要的方面阐述OraCIe9i 对硬件环境的要求。
1 .对CPU 的要求CPU 最低配置到Pentium 166就可以。
2 .对内存的要求内存容量最低为63MB,最好在256MB 以上。
3 .对硬盘的要求建议配置8GB 容量以上硬盘。
3 .对光驱的要求建议选用快速光驱,16倍速以上。
5 .对网卡的要求一般可以选用Ion(X)MB 自适应网卡。
图1.3分布式网络数据库上海数据库系统 (Linux)用庆数据库系 统!windows)2.1.2安装的软件环境需求下列从两个主要的方面阐述OraCIe9i对软件环境的要求。
1.对操作系统的要求建议在全新安装的Windows 2000 Server上安装数据库服务器,在Windows 2000 SerVer或Windows 98上安装管理客户机。
2.对虚拟内存的要求建议可以将虚拟内存适当进行调整以加快安装速度。
1.1.3安装的网络环境需求安装Oracle"数据库服务器,至少需要有两台计算机,通过交换机或集线器构成局域网。
1.1.4用(Ping]命令测试网络是否连通(1)输入“ping 10.1.1.10-t”命令行,单击按钮。
1.1.5安装步骤(1)出现如图2.3所示的【安装】界面。
单击【开始安装】按钮。
OraCIC9i SCrVCr浏氮信息2.2安装管理客户机2.2.1安装步骤Oracle NetConfigUratiOnASSiStant(C)rack 网络配置助手)。
输入全局数据库名选择TCP协议输入数据库服务器IP地址选择使用标准端口号1521∙∙√network∕admin∕tnsname. ora erp =(DESCRIPTION = (ADDRESS_LIST = (ADDRESS =(PROTOCOL = TCP)(Host = 10. 1. 1. 12)(Port = 1521)))(CONNECT_DATA = (SID = cxdbl) ) )2.2.2安装结果客户机的程序组。
2.3数据库服务器的体系结构2.3.1进程结构Oracle 9i网络环境里共有两大类进程。
1.用户进程用户进程是在客户机内存上运行的程序,如客户机上运行的【SQL Plus】、【企业管理器】等。
用户进程向服务器进程提出操作请求。
2.服务器进程Oracle 9i的主要后台支持进程2.3.2内存结构1.系统全局区(SGA) SGA的作用2.程序全局区(PGA)PGA是数据库服务器内存中为单个用户进程分配的专用的内存区域,是用户进程私有的,不能共享。
2.3.3数据库的逻辑结构Oracle 9i数据库的逻辑结构主要指从数据库使用者的角度来考查的数据库的组成,自下向上,数据库的逻辑结构共有6层。
数据库的逻辑结构L 数据块(DataBk)Ck)2.数据区间(DataExtent)3.数据段(Data Segment)4.逻辑对象(LOgiC Object)5.表空间(TabIeSPaCe)6.数据库(Database)2.3.3数据库的存储结构数据库的存储结构指逻辑结构在物理上是如何实现的,共有3层。
L物理块2.物理文件每个物理文件由若干个物理块组成,主要包括数据文件、控制文件和口志文件3类。
数据文件:用于存放所有的数据,以DBF为扩展名。
日志文件:记录了对数据库进行的所有操作,以LoG为扩展名。
控制文件:记录了数据库所有文件的控制信息,以CTL为扩展名。
2.3.5数据库服务器的总体结构Oracle 9i数据库服务器的总体结构。
用户进程用户进程用户进程数据库OraClC数据数据库的存储结构第3章SQL3.1SQL概述3.1.1SQL是什么SQL (Structured Query Language,译为结构化查询语言)在关系型数据库中的地位就犹如英语在世界上的地位。
它是数据库系统的通用语言,利用它,用户可以用几乎同样的语句在不同的数据库系统上执行同样的操作。
比如"select * from数据表名”代表要从某个数据表中取出全部数据,在OraCle 9i、SQLServer 2000. FOXPrO等关系型数据库中都可以使用这条语句。
SQL己经被ANSI (美国国家标准化组织)确定为数据库系统的工业标准。
SQL语言按照功能可以分为3大类。
数据查询语言DQL:查询数据。
数据定义语言DDL:建立、删除和修改数据对象。
数据操纵语言DML:完成数据操作的命令,包括查询。
数据控制语言DCL:控制对数据库的访问,服务器的关闭、启动等。
3.1.2SQL的主要特点SQL语言简单易学、风格统一,利用简单的儿个英语单词的组合就可以完成所有的功能。
在SQLPlllS WOrkShCet环境下可以单独使用的SQL语句,几乎可以不加修改地嵌入到如VB、PB 这样的前端开发平台上,利用前端工具的计算能力和SQL的数据库操纵能力,可以快速建立数据库应用程序。
3.1.3Oracle 9i使用SQL的工具在OraCIe9i中为使用SQL语言提供了两个主要的工具。
[SQLPI US][SQLPI US Worksheet]两种工具在使用上功能都相同,但在可操作性上,【SQLPlus Worksheet】更适合初学者。
3.1.4SQL中访问数据表的方法在SQL语言中访问数据表是通过“用户名.数据表”的形式来进行的。
比如在Oracle 9i数据库服务器安装过程中,默认建立有scott用户,该用户对dept数据表和emp数据表有数据查询的权限,因此访问数据表的语句为SeIeCt * from scotLemp。
当然,如果用户是用scott用户本身登录的,则访问数据表的语句可以简化为select * from emp,实质是一样的。
3.2用SQL进行单表查询单表查询是相对多表查询而言的,指从一个数据表中查询数据。
321查询所有的记录select * from scott. emp;3.2.1查询所有记录的某些字段select empno, enamc, job from scott. emp;3.2.2查询某些字段不同记录job字段中,可以发现有相同的数据,为了查询有多少种不同的job。
select distinct job from scott. emp;3.2.3单条件的查询select empno, ename, job from scott. emp where job", MANAGER; select empno, ename, sal from scott. emp where sal<=2500;比较运算符Iikeffnot Iike适合字符型字段的查询,%代表任意长度的字符串,一下划线代表一个任意的字符。
Iike 'm%'代表m开头的任意长度的字符串,like 代表m开头的长度为3的字符串。
3.2.4组合条件的查询(1)select empno,ename,job from scott.emp where job>=,CLERK, and sal<=2000:(2)select empno,ename,job from scott.emp where job>=,CLERK, or sak=20(X);(3)select empno,ename,job from scott.emp where not job=,CLERK,;“not job=,CLERK,w等价于“job<>'CLERK'"。