第七章ARCH模型的计量步骤
第七章ARCH模型的计量步骤
实验目的:考察2000~2010 上证指数的集群波动现象,以对数形式进行分析。
1.建工作文档: new file,选择非均衡数据( unstructured/undated ),录入样本数:2612
2.录入数据: object—— new object
3.由于股票价格指数序列常常表现出特殊的单位根过程——随机游走过程
( Random Walk),所以本例进行估计的基本形式为:
ln( sz t )ln(sz t 1 )u t
首先利用最小二乘法,估计了一个普通的回归方程,结果及过程如下:
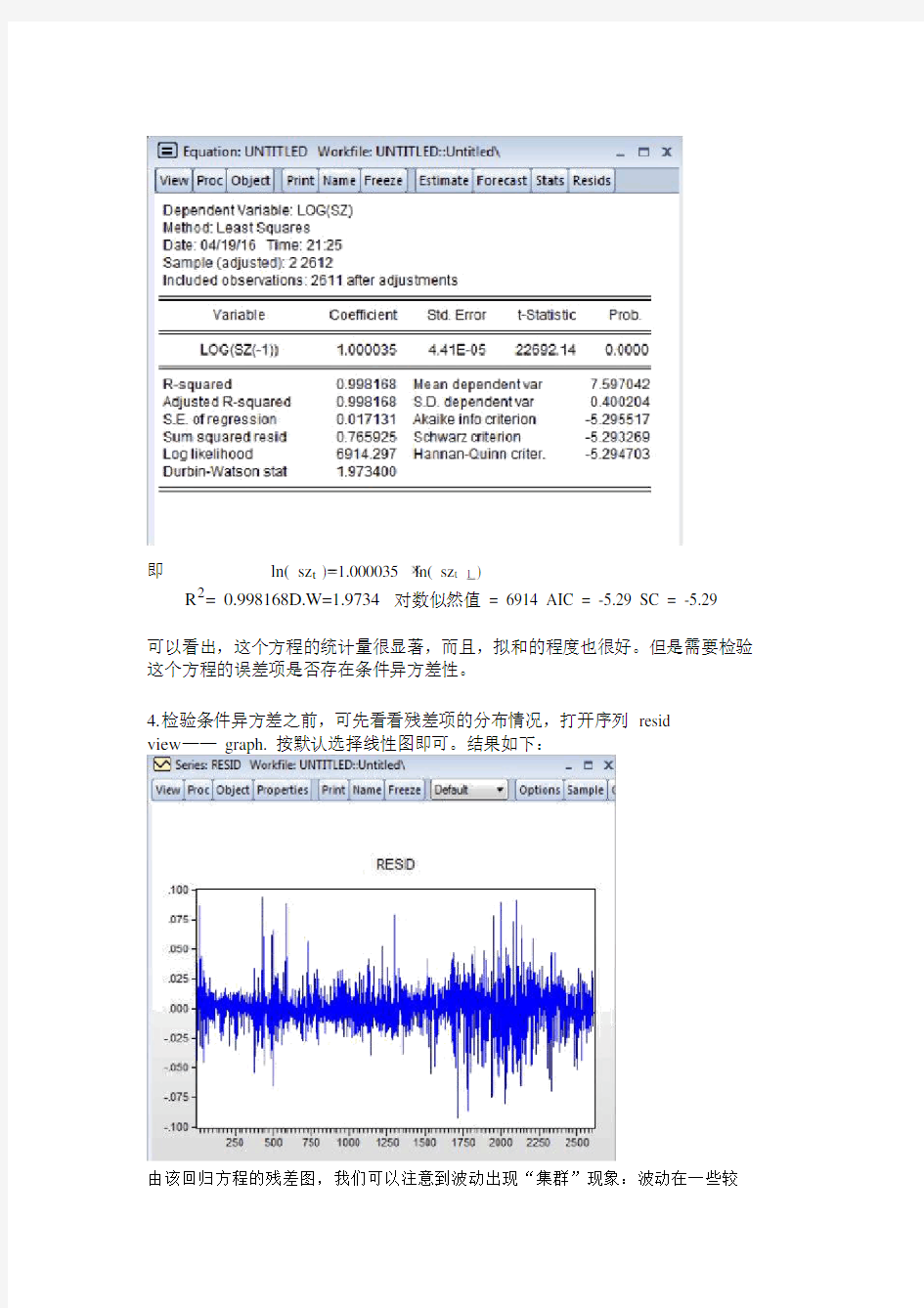
即ln( sz t ) 1.000035 ln( sz t 1 )
R2= 0.998168D.W=1.9734对数似然值 = 6914 AIC = -5.29 SC = -5.29
可以看出,这个方程的统计量很显著,而且,拟和的程度也很好。但是需要检验这个方程的误差项是否存在条件异方差性。
4.检验条件异方差之前,可先看看残差项的分布情况,打开序列 resid view—— graph. 按默认选择线性图即可。结果如下:
由该回归方程的残差图,我们可以注意到波动出现“集群”现象:波动在一些较
长的时间内非常小(例如 500~1500 期间),在其他一些较长的时间内非常大(例如 1750~2250),这说明残差序列存在 ARCH或者 GARCH效应的可能性较大。
5.条件异方差检验: view—— residual diagnostics—— heteroskedasticity test。选择ARCH test。滞后期选择 10 期,如图:
结果如下:
此处的 P 值为 0,拒绝原假设,说明式( 6.1.26)的残差序列存在ARCH效应。
6.估计GARCH和ARCH模型,首先选择Quick/Estimate Equation或Object/ New Object/ Equation,然后在 Method 的下拉菜单中选择 ARCH,得到如下的对话框。
注意:
在因变量编辑栏中输入均值方程形式,均值方程的形式可以用回归列表形式列出因变量及解释变量。如果方程包含常数,可在列表中加入 C。如果需要一个更复杂的均值方程,可以用公式的形式输入均值方程。
如果解释变量的表达式中含有 ARCH—M 项,就需要点击对话框右上方对应的按钮。 EViews中的 ARCH-M的下拉框中,有 4 个选项:
(1)选项 None 表示方程中不含有 ARCH-M 项;
(2)选项 Std.Dev表.示在方程中加入条件标准差;
(3)选项 Variance则表示在方程中含有条件方差2。
(4)选项 Log(Var),表示在均值方程中加入条件方差的对数 ln( 2)作为解释变量。另外,在该窗口内,还可进行如下操作
(1)在下拉列表中选择所要估计的 ARCH模型的类型。
(2)在 Variance 栏中,可以列出包含在方差方程中的外生变量。
(3)可以选择 ARCH项和 GARCH项的阶数。
(4)在 Threshold 编辑栏中输入非对称项的数目,缺省的设置是不估计
非对称的模型,即该选项的个数为 0。
(5)Error 组合框是设定误差的分布形式,默认的形式为 Normal (Gaussian)。
EViews为我们提供了可以进入许多估计方法的设置。只要点击 Options 按钮并按要求填写对话即可。
按照默认设置,得到如下结果:
利用 GARCH(1, 1)模型重新估计的方程如下:
均值方程:ln(sz t ) 1.000049 ln( sz t 1 )
方差方程:?2 3.651060.089?2?2
t u t 1 0.901t 1
R2=0.998168 D.W.=1.973353
对数似然值 = 7211AIC = -5.52SC = -5.51
方差方程中的 ARCH项和 GARCH项的系数都是统计显著的,并且对数似然值有
所增加,同时 AIC 和 SC值都变小了,这说明这个模型能够更好的拟合数据。
7.再对这个方程进行条件异方差的ARCH—LM 检验 :view—— residual diagnostics —— ARCH LM test
由结果可知:相伴概率为 P = 0.9662,说明利用 GARCH模型消除了原残差序列的异方差效应。
另外, ARCH和 GARCH的系数之和等于 0.990,小于 1,满足参数约束条件。由于系数之和非常接近于 1,表明一个条件方差所受的冲击是持久的,即它对所有的未来预测都有重要作用,这个结果在高频率的金融数据中经常可以看到。
计量经济学系列课件23一元线性回归模型检验
§2.3 一元线性回归模型的统计检验 回归分析是要通过样本所估计的参数来代替总体的真实参数,或者说是用样本回归线代替总体回归线。尽管从统计性质上已知,如果有足够多的重复抽样,参数的估计值的期望(均值)就等于其总体的参数真值,但在一次抽样中,估计值不一定就等于该真值。那么,在一次抽样中,参数的估计值与真值的差异有多大,是否显著,这就需要进一步进行统计检验。主要包括拟合优度检验、变量的显著性检验及参数的区间估计。 一、拟合优度检验 拟合优度检验,顾名思义,是检验模型对样本观测值的拟合程度。检验的方法,是构造一个可以表征拟合程度的指标,在这里称为统计量,统计量是样本的函数。从检验对象中计算出该统计量的数值,然后与某一标准进行比较,得出检验结论。有人也许会问,采用普通最小二乘估计方法,已经保证了模型最好地拟合了样本观测值,为什么还要检验拟合程度?问题在于,在一个特定的条件下做得最好的并不一定就是高质量的。普通最小二乘法所保证的最好拟合,是同一个问题内部的比较,拟合优度检验结果所表示优劣是不同问题之间的比较。例如图2.3.1和图2.3.2中的直线方程都是由散点表示的样本观测值的最小二乘估计结果,对于每个问题它们都满足残差的平方和最小,但是二者对样本观测值的拟合程度显然是不同的。 .. ....... .. 图2.3.1 图2.3.2 1、总离差平方和的分解 已知由一组样本观测值),(i i Y X ,i =1,2…,n 得到如下样本回归直线 i i X Y 10???ββ+= 而Y 的第i 个观测值与样本均值的离差)(Y Y y i i -=可分解为两部分之和: i i i i i i i y e Y Y Y Y Y Y y ?)?()?(+=-+-=-= (2.3.1) 图2.3.3示出了这种分解,其中,)?(?Y Y y i i -=是样本回归直线理论值(回归拟合值)与观测值i Y 的平均值之差,可认为是由回归直线解释的部分;)?(i i i Y Y e -=是实际观测值与回归拟合值之差,是回归直线不能解释的部分。显然,如果i Y 落在样本回归线上,则Y 的第i 个观测值与样本均值的离差,全部来自样本回归拟合值与样本均值的离差,即完全可由
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
中级计量经济学讲义_第二章第一节数学基础 (Mathematics)第一节 矩阵(Matrix)及
上课材料之二: 第二章 数学基础 (Mathematics) 第一节 矩阵(Matrix)及其二次型(Quadratic Forms) 第二节 分布函数(Distribution Function),数学期望(Expectation)及方差(Variance) 第三节 数理统计(Mathematical Statistics ) 第一节 矩阵及其二次型(Matrix and its Quadratic Forms) 2.1 矩阵的基本概念与运算 一个m ×n 矩阵可表示为: 矩阵的加法较为简单,若C=A +B ,c ij =a ij +b ij 但矩阵的乘法的定义比较特殊,若A 是一个m ×n 1的矩阵,B 是一个n 1×n 的矩阵,则C =AB 是一个m ×n 的矩阵,而且∑== n k kj ik ij b a c 1,一般来讲,AB ≠BA ,但如下运算是成立 的: ● 结合律(Associative Law ) (AB )C =A (BC ) ● 分配律(Distributive Law ) A (B +C )=AB +AC 问题:(A+B)2=A 2+2AB+B 2是否成立? 向量(Vector )是一个有序的数组,既可以按行,也可以按列排列。 行向量(row ve ctor)是只有一行的向量,列向量(column vector)只有一列的向量。 如果α是一个标量,则αA =[αa ij ]。 矩阵A 的转置矩阵(transpose matrix)记为A ',是通过把A 的行向量变成相应的列向量而得到。 显然(A ')′=A ,而且(A +B )′=A '+B ', ● 乘积的转置(Transpose of a production ) A B AB ''=')(,A B C ABC '''=')(。 ● 可逆矩阵(inverse matrix ),如果n 级方阵(square matrix)A 和B ,满足AB=BA=I 。 则称A 、B 是可逆矩阵,显然1-=B A ,1-=A B 。如下结果是成立的: 1111111)()()()(-------='='=A B AB A A A A 。 2.2 特殊矩阵 1)恒等矩阵(identity matrix)
计量经济学模型分析论文
计量经济学模型分析论文 工商101
我国城镇居民储蓄存款影响因素的实证分析 摘要:近年来,随着中国经济的飞速发展,一直保持在高水平上的中国储蓄率受到了越来越多国内外经济学家的关注。高储蓄率给我国经济发展带来充裕资金来源,是支持经济快速增长的重要因素。更为重要的是,源源不断的资金流保证了金融机构的流动性,增强了银行的稳定性。与此同时,也给我国经济发展带来前所未有的挑战,因为,过高的储蓄,必然伴随着投资或消费的不足。所以对影响居民储蓄的主要因素进行分析,才能在制定宏观政策上采取适当的措施,使储蓄率保持在一个适当的水平,促进经济增长。本文利用我国1982年以来的统计数字建立了可以通过各种检验的城镇居民储蓄率的模型。通过对该模型的经济含义分析可以得出可支配收入率对储蓄率的影响不大,还有利率对储蓄率的影响很小,值得注意的是,模型中的基尼系数对城镇居民的储蓄影响是相当大的。
引言(提出问题) 自1949年以来,中国储蓄率随着经济增长和收入水平提高呈不断上升趋势,因而高储蓄率也被认为是解释中国经济高速增长的一个主要因素。虽然高储蓄率总是会导致更高的收入及较高的经济增长率,但并非储蓄率越高越好,必然会存在一个最优的储蓄率。 据统计,我国近年来的实际GDP平均每年增长9%左右,而资本的净边际产量即(MPK-δ),约为0.9%。我国的资本收益(MPK-δ)=每年0.9%,大大低于经济的平均增长率(n+g=9%)。可见,我国的资本存量已经远远超过了黄金律水平。也就是说,当前我国的储蓄率和投资水平已经偏高,而消费率则偏低。所以我们应该降低储蓄率,减少投资,把收入的更大份额用于消费,这样就会立即提高消费水平,并最终达到更高消费水平的稳定状态。 那应该如何降低我国的储蓄率呢?下面我们将以城镇居民的数据为例进行分析。
经典计量经济学应用模型
经典计量经济学应用模型 一、单选题 1. 生产函数的要素边际替代率表示的是( )。 A .维持产出不变,增加一单位的某一要素投入,需增加另一要素投入数量 ; B. 维持产出不变,减少一单位的某一要素投入,需增加另一要素投入数量; C .要素K 对要素L 的边际替代率等于ln()/ln()L K MP K d d L MK ; D .要素的边际替代率是要素的替代弹性。 2. 两种生产要素的比例的变化率与边际技术替代率的变化率之比叫做 ( )。 A .要素的替代弹性 B. 要素的产出弹性 C .边际技术替代率 D .技术进步率 3. 下列生产函数中,要素的替代弹性为变量的是( ) A .线性生产函数 B. VES 生产函数 C .C D -生产函数 D .CES 生产函数 4. 下列生产函数中,要素的替代弹性为∞的是( ) A .线性生产函数 B. 投入产出生产函数 C .C D -生产函数 D .CES 生产函数 5. 下列生产函数中,要素的替代弹性分别为0和1的是( ) A .线性生产函数和C D -生产函数 B. 投入产出生产函数和C D -生产函数 C .C D -生产函数和线性生产函数 D .CES 生产函数和投入产出生产函数 6. 狭义技术进步是指( )。 A .生产水平的提高 B. 产品价格的提高 C .要素质量的提高 D .管理水平的提高 7. 在C D -生产函数Y AL K αβ=中( )。 A .α和β是产出弹性 B. α和β是边际产出 C .α和β是替代弹性 D .A 是要素替代弹性
8. CES 生产函数/12()m Y A K L ρρρδδ---=+中,01ρ<<,1δ越接近于1,表示 ( )。 A .资本密集度越高 B. 资本密集度越低 C .技术进步程度越高 D .技术进步程度越高 9. 中性技术进步中,希克斯中性进步指的是( )。 A .要素之比/K L 不随时间变化 B. 劳动产出率/Y L 不随时间变化 C .自资本产出率/Y K 不随时间变化 D .资本密集度/L K E E ω=随技术 进步变大 10.当需求完全无弹性时,表示( ) A .价格与需求量之间存在完全线性关系 B.价格上升速度与需求量下降速度相等 C .无论价格如何变动,需求量都不变 D .价格上升,需求量也上升 11. 关于扩展的线性支出系统需求函数模型: (),1,2,,i i i j j j i b q r I p r i n p =+-=∑L 下列说法不正确的是( ) A .j γ是第j 种商品的基本需求量 B.i b 是第i 种商品的边际消费向 C .()j j j I p r -∑是剩余收入用于购买第j 种商品的支出 D .1i i b ≤∑ 12. 直接效用函数蒋孝勇表示为下列哪一项的函数( )。 A .商品供应量 B. 商品需求量 C .商品价格 D .收入 13. 消费函数模型的一般形式为( )。 A .t t t C Y αβμ=++ B. 011t t t C Y C ββμ-=++ C .1(,)t t t t C f Y C μ-=+ D .1(,)t t t t C f Y Y μ-=+ 14.下面四种单方程需求模型中,不能用于分析价格队需求量影响的模型时 ( )。 A .线性需求函数模型 B. 对数线性需求函数模型 C .耐用品消费调整模型 D .状态调整模型
计量经济学分析模型
计量经济学分析模型
摘要 改革开放以来,我国经济呈迅速而稳定的增长趋势,由于分配机制和收入水平的变化,城镇居民生活水平在达到稳定小康之后,消费结构和消费水平都出现了一些新的特点。本文旨在对近几年,我国城镇年人均收入变动对年人均各种消费变动的影响进行实证分析。首先,我们综合了几种关于收入和消费的主要理论观点;本文根据相关的数据统计数据,运用一定的计量经济学的研究方法,进而我们建立了理论模型。然后,收集了相关的数据,利用EVIEWS软件对计量模型进行了参数估计和检验,并加以修正。最后,我们对所得的分析结果和影响消费的一些因素作了经济意义的分析,并相应提出一些政策建议。并找到影响居民消费的主要因素。 关键词:居民消费;城镇居民;回归;Eviews
目录 摘要.................................................................. II 前言. (1) 1 问题的提出 (2) 2 经济理论陈述 (3) 2.1西方经济学中有关理论假说 (3) 2.2有关消费结构对居民消费影响的理论 (4) 3 相关数据收集 (6) 4 计量经济模型的建立 (9) 5 模型的求解和检验 (10) 5.1计量经济的检验 (10) 5.1.1模型的回归分析 (10) 5.1.2拟合优度检验: (11) 5.1.3 F检验 (11) 5.1.4 T检验 (12) 5.2 计量修正模型检验: (12) 5.2.1 Y与的一元回归 (13) 5.2.2拟合优度的检验 (13) 5.2.3 F检验 (14) 5.2.4 T检验: (15) 5.3经济意义的分析: (15) 6 政策建议 (16) 结论 (17) 参考文献 (19)
计量经济学习题与解答
第五章经典单方程计量经济学模型:专门问题 一、内容提要 本章主要讨论了经典单方程回归模型的几个专门题。 第一个专题是虚拟解释变量问题。虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。 第二个专题是滞后变量问题。滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。 第三个专题是模型设定偏误问题。主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。本专题最后介绍了一个关于选取线性模型还是双对数线性模型的一个实用方法。 第四个专题是关于建模一般方法论的问题。重点讨论了传统建模理论的缺陷以及为避免这种缺陷而由Hendry提出的“从一般到简单”的建模理论。传统建模方法对变量选取的
第五章-单方程计量经济学应用模型试题及答案
第五章 单方程计量经济学应用模型 一、填空题: 1.当所有商品的价格不变时,收入变化1%所引起的第i 种商品需求量的变化百分比叫做需求的 。 2.对于生活必需品,需求的收入弹性i E 的取值区间为 ,需求的自价格弹性的取值区间为 。 3.当收入和其他商品的价格不变时,第j 种商品价格变化1%所引起的第i 种商品需求量的变化百分比,叫做需求的 。 4.替代品的需求互价格弹性ij E 0;互补品的需求互价格弹性 ij E 0;无关商品的需求 互价格弹性 ij E 0。 5.吉芬商品的需求自价格弹性 0。 6.西方国家发展的需求函数模型的理论模型,是由 函数在 最大化下导出的。而对数线性需求函数模型和线性需求函数模型则是由 拟合得到的。 7.在线性支出系统需求函数模型 )(∑-+ =j j j i i i i r p V p b r q 中,V 表示总 ,i r 表示第i 种商品的 需求量,i b 表示第i 种商品的边际 份额。 8.在扩展的线性支出系统需求函数模型 )(∑-+ =j j j i i i i r p I p b r q 中,I 表示 ,i r 表示第i 种商 品的 需求量,i b 表示第i 种商品的 消费倾向。 9.在绝对收入假设消费函数模型C Y Y t t t t =+++αββμ012 (t T =12,,,Λ)中,参数a 表示 , 且a 0; t t Y C 10ββ+=,参数b 1<0,表示递减的边际消费倾向。 10.在绝对收入假设消费函数模型 C Y Y t t t t =+++αββμ012 (t T =12,,,Λ)中,参数b 1 0,以反映边际消费倾向 规律。
计量经济学 Chow(邹氏)检验 检验模型是否存在结构性变化 Eviews6
数学与统计学院实验报告 院(系):数学与统计学学院学号:姓名: 实验课程:计量经济学指导教师: 实验类型(验证性、演示性、综合性、设计性):验证性 实验时间:2017年 3 月15 日 一、实验课题 Chow检验(邹氏检验) 二、实验目的和意义 1 建立财政支出模型 表1给出了1952-2004年中国财政支出(Fin)的年度数据(以1952年为基期,用消费价格指数进行平减后得数据)。试根据财政支出随时间变化的特征建立相应的模型。 表1 obs Fin obs Fin obs Fin 1952 173.94 1970 563.59 1988 1122.88 1953 206.23 1971 638.01 1989 1077.92 1954 231.7 1972 658.23 1990 1163.19 1955 233.21 1973 691 1991 1212.51 1956 262.14 1974 664.81 1992 1272.68 1957 279.45 1975 691.32 1993 1403.62 1958 349.03 1976 656.25 1994 1383.74 1959 443.85 1977 724.18 1995 1442.19 1960 419.06 1978 931.47 1996 1613.19 1961 270.8 1979 924.71 1997 1868.98 1962 229.72 1980 882.78 1998 2190.3 1963 266.46 1981 874.02 1999 2616.46 1964 322.98 1982 884.14 2000 3109.61 1965 393.14 1983 982.17 2001 3834.16 1966 465.45 1984 1147.95 2002 4481.4 1967 351.99 1985 1287.41 2003 5153.4 1968 302.98 1986 1285.16 2004 6092.99 1969 446.83 1987 1241.86 步骤提示: (1)做变量fin的散点图,观察规律,看在不同时期是否有结构性变化。
高级计量经济学之第5章分布滞后与动态模型
第5章 分布滞后与动态模型 §5.1 分布滞后模型 很多经济模型在回归方程中有滞后项,例如,因为修建桥和高速公路需要很多时间,所以公共投资对GDP 的影响有一个滞后期,而且这个影响可能会持续数年;研发新产品需要时间,而后把这个新产品投入生产也需要时间;在研究消费行为时,一个工资的变化可能影响好几期的消费。在消费的恒久收入理论中,消费者会用若干期去决定真实可支配收入的变化是暂时的还是永久的。例如,今年额外的咨询费收入明年是否还会继续?同样,真实可支配收入的滞后值会在回归方程中出现,是因为消费者在平滑其消费行为时十分重视他自身的终身收入。一个人的终身收入可以用他过去和现在的收入来推测。换句话说,回归关系可以写为: T t X X X Y t s t s t t t ,,2,1110 =+++++=--εβββα (5.1) 其中,t Y 代表被解释变量Y 在第t 期的观测值,t s X -代表解释变量X 第t s -期的观测值,α为截距项,0β,1β,…,s β是t X 当期和滞后期的系数。方程(5.1)式就是分布滞后模型因为它把收入增长对消费的影响分为s 期。X 的一个单位变化对Y 的短期影响由0β来表示,而X 的一个单位变化对Y 的长期影响由 (s βββ+++ 10)来表示。 假设我们观察从1955年到1995年的t X ,1t X -为相同的变量,但是提前一期的,也就是1954-1994。因为1954年的数据观察不到,我们就从1955年开始观察 1t X -,到1994年结束。这意味着当我们滞后一期时,t X 序列将从1956年开始到 1995年结束。对于实际的应用来说,也就是当我们滞后一期时,我们将从样本中
计量经济学经济模型分析
我国居民消费水平的变量因素分析 2010级工程管理赵莹 201000271120 改革开放以来,我国居民收入与消费水平不断提高,居民消费结构升级和消费需求扩张成为我国经济高速增长的主要动力,特别是进入20世纪90年代以来,居民消费需求对国民经济发展的影响不断增大,对国民经济产生了拉动作用。我国经济逐步由短缺经济走向过剩经济、由卖方市场转向买方市场,社会消费需求不足,居民消费问题显得更加突出。特别市对于如何启动内需,扩大居民消费变得越来越重要。因此,及时把握国民经济发展格局中居民消费需求变动趋势,制定符合我国现阶段情况的国民消费政策,对于提高我国经济增长速度和质量都有重要意义。 我选取了全国1990年-2009年居民消费水平及其影响因素的统计资料,详 一、建立回归模型并进行参数估计 导入数据后得到下表:
表2 由表2可知,模型估计的结果为: 550.78004.0023.0403.0?3 21-+-=X X X Y (0.046) (0.016) (0.006) (50.521) t= (8.743) (-1.442) (0.802) (-1.555) 999564.02=R 999483.02=R F=12239.64 n=20 D.W.=0.9217 二、异方差性的检验 用怀特检验进行异方差性的检验,得出下表:
表3 由表3可知,35292.11n 2 =R ,由怀特检验,在α=0.05的情况下,查可 知92.16905 .02 =)(χ >35292.11n 2=R ,表明模型不存在异方差性。 三、序列相关性的检验 由表2中结果可知D.W.=0.9217,D.W.检验结果表明,在5%的显著性水平下,n=20,k=2,查表得20.1d =L ,41.1d =U ,由于0 #学术探讨# 现代计量经济学模型体系解析* 李子奈刘亚清 内容提要:本文对现代计量经济学模型体系进行了系统的解析,指出了现代计量经济学的各个分支是以问题为导向,在经典计量经济学模型理论的基础上,发展成为相对独立的模型理论体系,包括基于研究对象和数据特征而发展的微观计量经济学、基于充分利用数据信息而发展的面板数据计量经济学、基于计量经济学模型的数学基础而发展的现代时间序列计量经济学、基于非设定的模型结构而发展的非参数计量经济学,并对每个分支进行了扼要的描述。最后在/交叉与综合0的方向上提出了现代计量经济学模型理论的研究前沿领域。 关键词:经典计量经济学时间序列计量经济学微观计量经济学 一、引言 计量经济学自20世纪20年代末30年代初诞生以来,已经形成了十分丰富的内容体系。一般认为,可以以20世纪70年代为界将计量经济学分为经典计量经济学(Classical Econometrics)和现代计量经济学(Mo dern Eco no metr ics),而现代计量经济学又可以分为四个分支:时间序列计量经济学(Tim e Ser ies Econo metrics)、微观计量经济学(M-i cro-econometrics)、非参数计量经济学(Nonpara-m etric Econometrics)以及面板数据计量经济学(Panel Data Eco nom etrics)。这些分支作为独立的课程已经被列入经济学研究生的课程表,独立的教科书也已陆续出版,应用研究已十分广泛,标志着它们作为计量经济学的分支学科已经成熟。 据此提出三个问题:一是经典计量经济学的地位问题。既然现代计量经济学模型体系已经成熟,而且它们都是在经典模型理论的基础上发展的,那么经典模型还有应用价值吗?是不是凡是采用经典模型的研究都是低水平和落后的?二是现代计量经济学的各个分支的发展导向问题。即它们是如何发展起来的?三是现代计量经济学进一步创新和发展的基点在哪里?回答这些问题,对于正确理解计量经济学的学科体系,对于计量经济学的课程设计和教学内容安排,对于正确评价计量经济学理论和应用研究的水平,对于进一步推动中国的计量经济学理论研究,都是十分有益的。 现代计量经济学的各个分支是以问题为导向,以经典计量经济学模型理论为基础而发展起来的。所谓/问题0,包括研究对象和表征研究对象状态和变化的数据。研究对象不同,表征研究对象状态和变化的数据具有不同的特征,用以进行经验实证研究的计量经济学模型既然不同,已有的模型理论方法不适用了,就需要发展新的模型理论方法。按照这个思路,就可以用图1简单地描述经典计量经济学模型与现代计量经济学模型各个分支之间的关系。 本文试图从方法论的角度对现代计量经济学模型的发展,特别是现代计量经济学模型与经典计量经济学模型之间的关系进行较为系统的讨论,以期对未来我国计量经济学的发展研究提供借鉴和启示。本文的内容安排如下:首先分析经典计量经济学模型的基础地位,明确它在现代的应用价值,同时对发生于20世纪70年代的/卢卡斯批判0的实质进行讨论;然后依次讨论时间序列计量经济学、微观计量经济学、非参数计量经济学以及面板数据计量经济学的发展,回答它们是以什么问题为导向,以什么为目的而发展的;最后以/现代计量经济学模型体系的分解与综合0为题,讨论现代计量经济学的前沿研究领域以及从对我国计量经济学理论的创新和发展 ) 22 ) *本文受国家社会科学基金重点项目(08AJY001,计量经济学模型方法论基础研究)的资助。 计量经济学试题一 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显著是指模型中每个变量都是统计显著的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。()4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。() 5.线性回归是指解释变量和被解释变量之间呈现线性关系。() 6.判定系数的大小不受到回归模型中所包含的解释变量个数的影响。()7.多重共线性是一种随机误差现象。() 8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的变大。()10.任何两个计量经济模型的都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显著,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分) 五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给、投资、价格指数和产出。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob. LOG(DEBT) 0.65 0.02 32.8 0 Adjusted R-squared 0.983 S.D. dependent var 0.86 S.E. of regression 0.11 Akaike info criterion -1.46 Sum squared resid 0.21 Schwarz criterion -1.36 Log likelihood 15.8 F-statistic 1075.5 Durbin-Watson stat 0.81 Prob(F-statistic) 0 其中,GDP表示国内生产总值,DEBT表示国债发行量。 (1)写出回归方程。(2分) (2)解释系数的经济学含义?(4分) (3)模型可能存在什么问题?如何检验?(7分) 思考题答案 第一章绪论 思考题 怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 理论计量经济学和应用计量经济学的区别和联系是什么 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 怎样理解计量经济学与理论经济学、经济统计学的关系 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 在计量经济模型中被解释变量和解释变量的作用有什么不同 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 一个完整的计量经济模型应包括哪些基本要素你能举一个例子吗 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u + = α βX Y+ 其中,Y为居民消费支出,X为居民家庭收入,二者是经济变量;α和β为参数;u是随机误差项。 假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提 我国人口数量的相关分析 一,寻找相关数据 二,进行模型的建立 打开Eviews,建立一个新的Workfile。数据类型为时间序列,1979~2012年。 输入被解释变量y与5个解释变量(如图所示) 将数据导入group中 分别观察y与x1,x2,x3,x4,x5的散点图,Y与x1的散点图: Y与x2的散点图: Y与x4的散点图: 观察上述散点图发现y与x1,x2,x3,x4,x5为非线性关系,因此对其进行非线性模型的线性化处理。 三,对模型进行参数估计 首先对模型进行线性化处理 对其进行模型回归,输入ls y c z1 z2 z3 z4 z5 得到如下图所示回归结果 回归结果为 i Y ^ =-123441.8-3988.052Z 1 +5043.003Z 2 +6105.032Z 3 -11.015X 4 +20443.4Z 5 i Y ^ =-123441.8-3988.05log(X 1 )+5043.0log(X 2 )+6105.03log(X 3 )-11.015X 4 +20443.4 log(X 5 ) t =(-5.5428) (-2.2016) (0.7198) (7.8404) (-5.3888) (6.2395) R 2 =0.997258 2— R =0.996769 F=2037.054 DW=0.981736 (1)经济意义检验 β1=-3988.052,说明出生率每增加单1%,我国总人口减少3988.052单位; β2=5043.003,说明死亡率每增加单1%,我国总人口增加5043.003单位; β3=6105.032,说明人均可支配收入每增加1个单位,我国总人口增加6105.032单位; β1=-11.015,说明受高等教育人数每增加1个单位,我国总人口减少11.015单位; β1=20443.4,说明医疗机构数每增加1个单位,我国总人口增加20443.4单位; (2)统计检验 ○ 1拟合优度检验 可决系数R 2 =0.997258,修正后的可决系数2 — R =0.996769,表明拟合结果相当好。 ○ 2T-检验 由表可知各参数的t 统计量为 β1为t 1=-2.2016 β2为t 2=0.7198 β3为t 3=7.8404 建立计量经济学模型的步骤和要点 | [<<][>>] 一、理论模型的设计 对所要研究的经济现象进行深入的分析,根据研究的目的,选择模型中将包含的因素,根据数据的可得性选择适当的变量来表征这些因素,并根据经济行为理论和样本数据显示出的变量间的关系,设定描述这些变量之间关系的数学表达式,即理论模型。例如上节中的生产函数 就是一个理论模型。理论模型的设计主要包含三部分工作,即选择变量、确定变量之间的数学关系、拟定模型中待估计参数的数值范围。 1. 确定模型所包含的变量 在单方程模型中,变量分为两类。作为研究对象的变量,也就是因果关系中的“果”,例如生产函数中的产出量,是模型中的被解释变量;而作为“原因”的变量,例如生产函数中的资本、劳动、技术,是模型中的解释变量。确定模型所包含的变量,主要是指确定解释变量。可以作为解释变量的有下列几类变量:外生经济变量、外生条件变量、外生政策变量和滞后被解释变量。其中有些变量,如政策变量、条件变量经常以虚变量的形式出现。 严格他说,上述生产函数中的产出量、资本、劳动、技术等,只能称为“因素”,这些因素间存在着因果关系。为了建立起计量经济学模型,必须选择适当的变量来表征这些因素,这些变量必须具有数据可得性。于是,我们可以用总产值来表征产出量,用固走资产原值来表征资本,用职工人数来表征劳动,用时间作为一个变量来表征技术。这样,最后建立的模型是关于总产值、固定资产原值、职工人数和时间变量之间关系的数学表达式。下面,为了叙述方便,我们将“因素”与“变量”间的区别暂时略去,都以“变量”来表示。 关键在于,在确定了被解释变量之后,怎样才能正确地选择解释变量。 广义计量经济学:利用经济理论、统计学和数学定量研究经济现象的经济计量方法的统称,包括回归分析方法、投入产出分析方法、时间序列分析方法等。 狭义计量经济学:以揭示经济现象中的因果关系为目的,在数学上主要应用回归分析方法。 计量经济学: 是经济学的一个分支学科,是以揭示经济活动中的客观存在的数量关系 为内容的分支学科。 计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。 截面数据:截面数据是许多不同的观察对象在同一时间点上的取值的统计数据集合,可理解为对一个随机变量重复抽样获得的数据。 时间序列数据:把反映某一总体特征的同一指标的数据,按照一定的时间顺序和时间间隔排列起来,这样的统计数据称为时间序列数据 面板数据:指时间序列数据和截面数据相结合的数据。 总体回归函数:指在给定Xi下Y分布的总体均值与Xi所形成的函数关系(或者说总体被解释变量的条件期望表示为解释变量的某种函数)。 样本回归函数:指从总体中抽出的关于Y,X的若干组值形成的样本所建立的回归函数。随机的总体回归函数:含有随机干扰项的总体回归函数(是相对于条件期望形式而言的)。线性回归模型:既指对变量是线性的,也指对参数β为线性的,即解释变量与参数β只以他们的1次方出现。 最小二乘法:又称最小平方法,指根据使估计的剩余平方和最小的原则确定样本回归函数的方法。 最大似然法:又称最大或然法,指用生产该样本概率最大的原则去确定样本回归函数的方法。 总离差平方和:用TSS表示,用以度量被解释变量的总变动。 回归平方和:用ESS表示:度量由解释变量变化引起的被解释变量的变化部分。 残差平方和:用RSS表示:度量实际值与拟合值之间的差异,是由除解释变量以外的其他因素引起的被解释变量变化的部分。 协方差:用Cov(X,Y)表示,度量X,Y两个变量关联程度的统计量。 R表示,该值越接近1,模型拟合优度检验:检验模型对样本观测值的拟合程度,用2 第一章绪论 一、单项选择题 1、变量之间的关系可以分为两大类,它们是【】 A 函数关系和相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指【】 A 变量间的依存关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间表现出来的随机数学关系 3、进行相关分析时,假定相关的两个变量【】 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机或非随机都可以 4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 5、下面属于截面数据的是【】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 6、同一统计指标按时间顺序记录的数据列称为【】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 7、经济计量分析的基本步骤是【】 A 设定理论模型→收集样本资料→估计模型参数→检验模型 B 设定模型→估计参数→检验模型→应用模型 C 个体设计→总体设计→估计模型→应用模型 D 确定模型导向→确定变量及方程式→估计模型→应用模型 8、计量经济模型的基本应用领域有【】 A 结构分析、经济预测、政策评价 B 弹性分析、乘数分析、政策模拟 C 消费需求分析、生产技术分析、市场均衡分析 D 季度分析、年度分析、中长期分析 9、计量经济模型是指【】 A 投入产出模型 B 数学规划模型 C 包含随机方程的经济数学模型 D 模糊数学模型 10、回归分析中定义【】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】 A. 计量经济学准则 B 经济理论准则 C 统计准则 D 统计准则和经济理论准则 模型的计量经济学检验 一、 概念 1、 异方差: 2 )(i i Var σε=,随机扰动项的方差随解释变量(被解释变量)的变化而变化 2、 自相关: s t E s t ≠≠ , 0)(εε时。一阶自相关:t t t v +=-1ρεε,0≠ρ,t v 中不存在自相关性;二阶自相关:t t t t v ++=--2211ερερε,02≠ρ,t v 中不存在自相关性。 3、 多重共线性: 完全多重共线性:1)(+ ●模型设置错误; ●蛛网现象。 3、多重共线性 ●经济变量变化趋势的共向性; ●经济变量之间的密切内在联系; ●模型中使用滞后变量; ●模型设置中变化选择不当。 三、产生的影响 1、异方差 ●最小二乘估计无偏,参数估计值的方差不再最小; ●t检验失效(可能出现虚假通过现象); ●估计与预测精度降低。 2、自相关: ●最小二乘估计无偏,参数估计值的方差不再最小; ●∧2σ低估2σ; ●t检验失效(可能出现虚假通过现象); ●估计与预测精度降低。 3、多重共线性(不完全多重共线性) ●难于区别单个解释变量的作用、回归模型缺乏稳定 性; ●参数估计的标准差扩大(膨胀); ●t检验失效(可能出现虚假通不过现象); ●估计与预测精度降低。 四、检验方法现代计量经济学模型体系解析
最新资料计量经济学期末考试试卷集(含答案)
计量经济学 庞皓 课后思考题答案
计量经济学我国人口总数模型分析
建立计量经济学模型的步骤和要点
计量经济学名词解释(全)
《计量经济学》作业题
模型的计量经济学检验