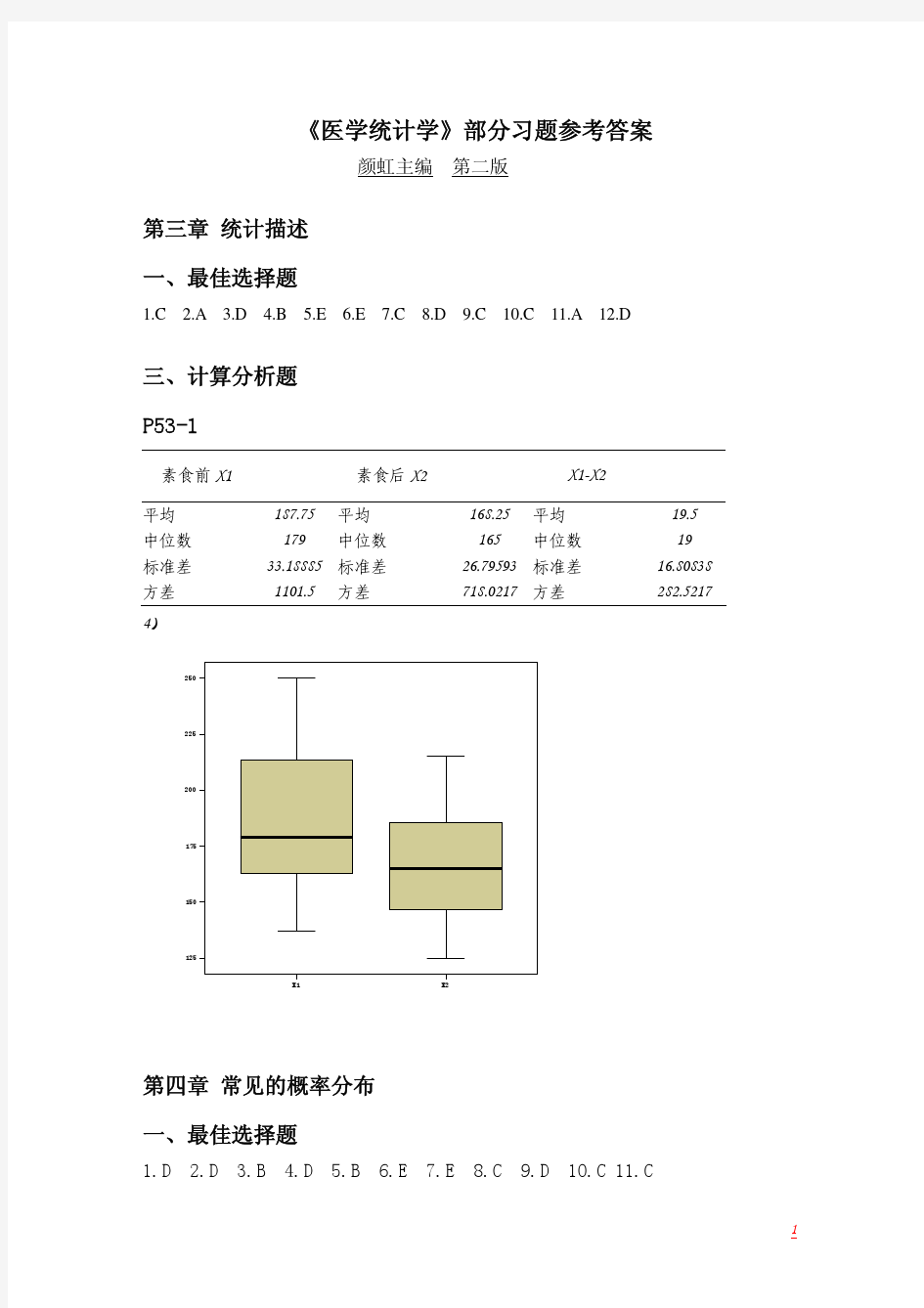
医学统计学参考答案(颜虹第二版)

医学统计学 第一课绪论及基本概念(已整理完毕)
《医学统计学》颜虹主编 Fundamentals of Biostatistics(Bernasrd Rosner)孙尚拱译(2004第五版) SPSS统计分析张文彬主编 一、绪论 【统计学】应用数学的原理和方法,研究数据的搜集、整理与分析的科学,对不确定性数据做出科学的推断。 产生过程:随机现象→随机事件→样本空间→随机变量 现象:确定现象 随机现象:与确定现象相对的不确定现象,在一定的条件下,其有多种可能的结果,而究竟出现哪一种结果事先不可预言的现象。≥2种结果。 特征:随机性、规律性 两种阶段认识随机现象:1.通过观察或实验取得观测资料; 2.通过分析所得资料来认识现象。 注:无论数据分析多么先进,都要以能够代表真实情况的数据为基础。 在偶然的背后发现必然 【随机事件】随机现象的一个结果叫随机事件。 【样本空间】为了便于研究随机试验,我们将随机试验E的所有基本事件所组成的集合叫做样本空间,记为Ω。每一个基本事件为样本点,基本事件也就是集合Ω的元素。 可以把样本空间中的基本事件映射成某个变量的取值,这样就引进了随机变量的概念。 【随机变量】在样本空间中,对不同事件指定有相应概率的数值函数,此函数成为一个随机变量。P (X=x k)=p k,X泛指随机变量 如抛掷硬币: 正反 10→随机事件的选项 X k P 0.50.5→对应概率,所有加起来=1 k 特征:与普通函数相比有两点不同: 1.随机变量随着实验结果不同取不同的值,因此在实验之前只能知道取值的范围,而不能预先知 道取什么值。由于随机试验的各个结果出现有一定的概率,所以随机变量的出现也有一定的概率。 2.普通函数定义在实数轴上,而随机变量是定义在样本空间上,样本空间的元素不一定是实数 二、统计学中的基本概念 1.总体(Population)、样本(Sample) 【总体】根据研究目的确定的、全体同质个体的某个(或某些)变量值。比如:糖尿病的血红蛋白水平、高血压患者的血压 分类:无限总体→新生儿体重 有限总体→一所学校今年新生的身高 【样本】:总体中的一部分,为了保证样本的代表性,在取样时我们要求X1、X2……Xn互相独立,并且与总体X有相同的概率分布。(同分布)如总体为正态分布,则样本应该也几近于正态分布。为母体分布的缩影。 为了保证样本的可靠性与代表性,需要采用随机的方法抽取样本(在总体中每个个体具有非0的
医学统计学试题及答案
医学统计学试题及答案 The latest revision on November 22, 2020
医学统计学 一、选择题 1、根据某医院对急性白血病患者构成调查所获得的资料应绘制( B ) A 条图 B 百分条图或圆图 C线图 D直方图 2、均数和标准差可全面描述 D 资料的特征 A 所有分布形式B负偏态分布C正偏态分布D正态分布和近似正态分布 3、要评价某市一名5岁男孩的身高是否偏高或偏矮,其统计方法是( A ) A 用该市五岁男孩的身高的95%或99%正常值范围来评价 B 用身高差别的假设检验来评价 C 用身高均数的95%或99%的可信区间来评价 D 不能作评价 4、比较身高与体重两组数据变异大小宜采用( A ) A 变异系数 B 方差 C 标准差 D 四分位间距 5、产生均数有抽样误差的根本原因是( A ) A.个体差异 B. 群体差异 C. 样本均数不同 D. 总体均数不同
6. 男性吸烟率是女性的10倍,该指标为( A ) (A)相对比(B)构成比(C)定基比(D)率 7、统计推断的内容为( D ) A.用样本指标估计相应的总体指标 B.检验统计上的“检验假设” C. A和B均不是 D. A和B均是 8、两样本均数比较用t检验,其目的是检验( C ) A两样本均数是否不同 B两总体均数是否不同 C两个总体均数是否相同 D两个样本均数是否相同 9、有两个独立随机的样本,样本含量分别为n1和n2,在进行成组设计资料的t 检验时,自由度是( D ) (A) n1+ n2 (B) n1+ n2 –1 (C) n1+ n2 +1 (D) n1+ n2 -2 10、标准误反映( A ) A 抽样误差的大小 B总体参数的波动大小
(完整版)医学统计学第六版课后答案
第一章绪论 一、单项选择题 答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D 二、简答题 1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。 3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。 4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。 5答系统误差、随机测量误差、抽样误差。系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。 第二章定量数据的统计描述 一、单项选择题 答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 二、计算与分析 2
医学统计学试题及答案
医学统计学试题及答案集团文件发布号:(9816-UATWW-MWUB-WUNN-INNUL-DQQTY-
医学统计学试题及答案 习??题 《医学统计学》第二版??(五年制临床医学等本科生用)(一)??单项选择题 1.观察单位为研究中的( d??)。 A.样本? ?? ??B. 全部对象 C.影响因素? ?? ?????D. 个体2.总体是由( c )。 A.个体组成? ?? ?B. 研究对象组成 C.同质个体组成? ?? ? D. 研究指标组成 3.抽样的目的是(b??)。 A.研究样本统计量? ?? ?? ???B. 由样本统计量推断总体参数 C.研究典型案例研究误差? ???D. 研究总体统计量 4.参数是指(b? ?)。 A.参与个体数? ???B. 总体的统计指标 C.样本的统计指标? ? ??D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变? ?? ? B.均数改变,标准差不变 C.两者均不变? ?? ?? ?? ?? ??? D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a??)。 A.变异系数? ?? B.差 C.极差? ?? ?? ? D.标准差 8.以下指标中(? ?d)可用来描述计量资料的离散程度。 A.算术均数? ? B.几何均数 C.中位数? ?? ? D.标准差 9.偏态分布宜用(? ?c)描述其分布的集中趋势。 A.算术均数? ?? B.标准差 C.中位数? ?? D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(? ?b)不变。 A.算术均数? ??? B.标准差 C.几何均数? ?? ???D.中位数 11.( a??)分布的资料,均数等于中位数。 A.对称? ? B.左偏态 C.右偏态? ?? ?? D.偏态 12.对数正态分布是一种( c )分布。
《医学统计学》考试试题及答案(三)
《医学统计学》考试试题及答案 (一)单项选择题 3.抽样的目的是(b )。 A.研究样本统计量 B. 由样本统计量推断总体参数 C.研究典型案例研究误差 D. 研究总体统计量 4.参数是指(b )。 A.参与个体数 B. 总体的统计指标 C.样本的统计指标 D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变 B.均数改变,标准差不变 C.两者均不变 D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a )。 A.变异系数 B.差 C.极差 D.标准差 8.以下指标中(d)可用来描述计量资料的离散程度。 A.算术均数 B.几何均数 C.中位数 D.标准差 9.偏态分布宜用(c)描述其分布的集中趋势。 A.算术均数 B.标准差 C.中位数 D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(b)不变。 A.算术均数 B.标准差 C.几何均数 D.中位数 11.( a )分布的资料,均数等于中位数。 A.对称 B.左偏态 C.右偏态 D.偏态 12.对数正态分布是一种( c )分布。 A.正态 B.近似正态 C.左偏态 D.右偏态 13.最小组段无下限或最大组段无上限的频数分布资料,可用( c )描述其集中趋势。 A.均数 B.标准差 C.中位数 D.四分位数间距 14.( c )小,表示用该样本均数估计总体均数的可靠性大。 A. 变异系数 B.标准差 C. 标准误 D.极差 15.血清学滴度资料最常用来表示其平均水平的指标是( c )。 A. 算术平均数 B.中位数
医学统计学试题及答案
《医学统计学》课程考试试题(A卷) (评卷总分:100分,考试时间:120分钟,考核方式:□开卷 V 闭卷) 一、选择题(每题1分,共62分,只选一个正确答案) 1、医学科研设计包括( D ) A.物力和财力设计 B.数据与方法设计 C.理论和资料设计 D.专业与统计设计 2、医学统计资料的分析包括( D ) A.数据分析与结果分析 B.资料分析与统计分析 C.变量分析与变量值分析 D.统计描述与统计推断 3、医学资料的同质性指的是( D ) A.个体之间没有差异 B.对比组间没有差异 C.变量值之间没有差异 D.研究事物存在的共性 4、离散型定量变量的测量值指的是( D ) A.可取某区间内的任何值 B、可取某区间内的个别值 C.测量值只取小数的情况 D.测量值只取整数的情况5、变量的观察结果表现为相互对立的两种情况是( A ) A.无序二分类变量 B、定量变量. C.等级变量 D.无序多分类变量 6、计量资料编制频数表时,组距的选择( D ) A.越大越好 B.越小越好 C.与变量值的个数无关 D.与变量值的个数有关
7、比较一组男大学生白细胞数与血红蛋白含量的变异度应选( D )A.极差 B.方差 C.标准差 D.变异系数 8、若要用方差描述一组资料的离散趋势,对资料的要求是( D )A.未知分布类型的资料 B.等级资料 C.呈倍数关系的资料 D.正态分布资料 9、频数分布两端没有超限值时,描述其集中趋势的指标也可用( D ) A.标准差 B.几何均数 C.相关系数 D.中位数 10、医学统计工作的步骤是( A ) A、研究设计、收集资料、整理资料和分析资料 B、计量资料、计数资料、等级资料和统计推断 C、研究设计、统计分析,统计描述和统计推断 D、选择对象、计算均数、参数估计和假设检验 11、下列关于变异系数的说法,其正确的是( A ) A.没有度量衡单位的系数 B.描述多组资料的离散趋势 C.其度量衡单位与变量值的度量衡单位一致 D、其度量衡单位与方差的度量衡单位一致 12、10名食物中毒的病人潜伏时间(小时)分别为3, 4,5,3,2,5.5,2.5,6,6.5, 7,其中位数是( B ) A.4 B.4.5 C.3 D.2 13、调查一组正常成年女性的血红蛋白,如果资料属于正态分布,描
2016年北京协和医学院流行病与卫生统计学考研复试参考书
2016年北京协和医学院流行病与卫生统计学考研复试参考书 北京协和医学院流行病与卫生统计学专业2014年考研招生简章招生目录 招生年份:2014本院系招生人数:33流行病与卫生统计学专业招生人数:3专业代码:100401 研究方向考试科目复试科目、复试参考书参考书目、参考教材 01流行病与卫生统计学(学术型)只招收推免生,不接受统考生报名 北京协和医学院流行病与卫生统计学专业2013年考研招生简章招生目录 招生年份:2013本院系招生人数:未公布流行病与卫生统计学专业招生人数:6专业代码:100401 研究方向考试科目复试科目、复试参考书参考书目、参考教材 01流行病与卫生统计学①101政治 ②201英语 ③353卫生综合 ④--无 注: 《卫生综合》:含卫生统计学、流行病学、卫生事业管理学;任选两门。复试为笔试和面试相结合,面试含外语听说能力测试 备注:推免生为2353卫生综合 一.卫生综合(卫生统计学) 1.《卫生统计学》刘桂芬协和医大出版社 2.《医学统计学》颜虹人民卫生出版社第2版 二.卫生综合(流行病学) 《流行病学》(供预防医学类专业用)李立明人民卫生出版社2007年第6版 三.卫生综合(卫生事业管理学)
《卫生事业管理学》梁万年人民卫生出版社2003.7第1版 北京协和医学院流行病与卫生统计学专业2012年考研招生简章招生目录 招生年份:2012本院系招生人数:未公布流行病与卫生统计学专业招生人数:3专业代码:100401 研究方向考试科目复试科目、复试参考书参考书目、参考教材 一、流行病与卫生统计学 01心血管病流行病学研究方法 01高血压流行病学和防治研究 01心血管流行病学和血压监测研究 ①101政治 ②201英语 ③353卫生综合 ④--无复试为笔试和面试相结合,面试含外语听说能力测试 备注:推免生为2. 353卫生综合: 1.卫生统计学: 《卫生统计学》,刘桂芬主编,协和医大出版社 《医学统计学》,颜虹主编,人民卫生出版社 2.流行病学: 《流行病学》,第六版(供预防医学类专业用),李立明主编,人民卫生出版社,2007 3.卫生事业管理:
医学统计学课后答案.
第二章 1.答:在统计学中用来描述集中趋势的指标体系是平均数,包括算术均数,几何均数,中位数。 均数反映了一组观察值的平均水平,适用于单峰对称或近似单峰对称分布资料的平均水平的描述。 几何均数:有些医学资料,如抗体的滴度,细菌计数等,其频数分布呈明显偏态,各观察值之间呈倍数变化(等比关系),此时不宜用算术均数描述其集中位置,而应该使用几何均数(geometric mean )。几何均数一般用G 表示,适用于各变量值之间成倍数关系,分布呈偏态,但经过对数变换后成单峰对称分布的资料。 中位数和百分位数: 中位数(median )就是将一组观察值按升序或降序排列,位次居中的数,常用M 表示。理论上数据集中有一半数比中位数小,另一半比中位数大。中位数既适用于资料呈偏态分布或不规则分布时集中位置的描述,也适用于开口资料的描述。所谓“开口”资料,是指数据的一端或者两端有不确定值。 百分位数(percentile )是一种位置指标,以P X 表示,一个百分位数P X 将全部观察值分为两个部分,理论上有X %的观察值比P X 小,有(100-X )%观察值比P X 大。故百分位数是一个界值,也是分布数列的一百等份分割值。显然,中位数即是P 50分位数。即中位数是一特定的百分位数。常用于制定偏态分布资料的正常值范围。 2.答:常用来描述数据离散程度的指标有:极差、四分位数间距、标准差、方差、及变异系数,尤以方差和标准差最为常用。 极差(range ,记为R ),又称全距,是指一组数据中最大值与最小值之差。极差大,说明资料的离散程度大。用极差反映离散程度的大小,简单明了,故得到广泛采用,如用以说明传染病、食物中毒等的最短、最长潜伏期等。其缺点是:1.不灵敏; 2.不稳定。 四分位数间距(inter-quartile range )就是上四分位数与下四分位数之差,即:Q =Q U -Q L ,其间包含了全部观察值的一半。所以四分位数间距又可看成中间一半观察值的极差。其意义与极差相似,数值大,说明变异度大;反之,说明变异度小。常用于描述偏态分布资料的离散程度。 极差和四分位数间距均没有利用所研究资料的全部信息,因此仍然不足以完整地反映资料的离散程度。 方差(variance )和标准差(standard deviation )由于利用了所有的信息,而得到了广泛应用,常用于描述正态分布资料的离散程度。 变异系数(coefficient of variance ,CV )亦称离散系数(coefficient of dispersion ),为标准差与均数之比,常用百分数表示。变异系数没有度量衡单位,常用于比较度量单位不同或均数相差悬殊的两组或多组资料的离散程度。 3.答:常用的相对数指标有:比,构成比和率。 比(ratio ),又称相对比,是A 、B 两个有关指标之比,说明A 为B 的若干倍或百 分之几,它是对比的最简单形式。其计算公式为 比=A /B 率(rate)又称频率指标,用以说明某现象发生的频率或强度。常以百分率(%)、千分率(‰)、万分率(1/万)、十万分率(1/10万)等表示。计算公式为: ) 比例基数(单位总数 可能发生某现象的观察单位数 实际发生某现象的观察率K ?= 构成比(proportion) 又称构成指标,它说明一种事物内部各组成部分所占的比重或
医学研究关于某样本例数选择
医学研究的样本例数 读者须知 在医学研究中样本例数的确定是一个难点,医学统计学家认为样本含量的确定有两种方法:公式法和查表法,公式法和查表法本质一样,查表法是统计学家由公式做出的,而公式法需要研究者自己做,因为医学研究中尚有不少问题还搜索不到相应的计算公式来确定样本例数,本书搜集到的公式也十分有限,那么通过搜索文献来估计样本例数也是读者需要学习的一种方法。 须知,不存在无限定条件的样本例数。现行统计教材中的样本例数没有特别强调这一点,以导致使用时,常提出如下问题:“了解吸烟是否是肺癌的危险因素,需要调查多少人?”,类似这样的问题是没人能回答出的。 医学研究中样本例数都是建立在一组限定条件之下的样本例数,若这一组限定条件改变,那么样本例数的值随之改变。简言之,样本例数是这一组限定条件的函数。这种函数关系具体由计算样本例数的公式表述。那么,确定公式等号右端的各参数就变成了计算样本例数的前提。根据此思路我们设计了一个确定样本例数的流程图(见下页),同时,这个流程图也是我们撰写本书具体内容和阅读本书的思路。这个小册子中的例题均来自各种卫生统
计学的教材和相关著作,其本质没有变化,但读起来却更加符合人们的认知习惯,你会感觉到更容易读懂了。 本书由一附院医学统计咨询室集体讨论,具体由孙奇执笔撰写和排版,几经修订,历时超过百天。尽管如此,鉴于我们知识的局限性,也只能做到抛砖引玉,而且书中错误肯定难免。欢迎读者不吝指正,我们将深表谢意!
样本例数估计流程图
目录 1.两样本率比较的样本例数 (4) 2.多个样本率比较的样本例数 (6) 3.两样本均数比较的样本例数 (8) 4.多个样本均数比较的样本例数 (10) 5.诊断试验的样本例数 (12) 6.现况研究的样本例数 (13) 7.病例对照研究的样本例数 (15) 8.队列研究的样本例数 (17) 9.多元统计的样本例数 (19) 20 10. 他····················································· 21 11. 表···························································
医学统计学课后习题答案
医学统计学 第一章 绪论 答案 名词解释: (1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基 础上各观察单位(或个体)之间的差异。 (2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。样本 是从总体中随机抽取的部分观察单位。 (3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称 为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为 样本统计量。 (4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误 差。 (5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示 (6) 计量资料:由一群个体的变量值构成的资料称为计量资料。 (7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称 为计数资料。。 (8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为 等级资料。 是非题: 1. × 2. × 3. × 4. × 5. √ 6. √ 7. × 单选题: 1. C 2. E 3. D 4. C 5. D 6. B 第二章 计量资料统计描述及正态分布 答案 名词解释: 1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标 2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标 3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布 称为标准状态分布。 4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指 标范围称为指标的正常值范围。 填空题: 1. 计量,计数,等级 2. 设计,收集资料,分析资料,整理资料。 3. σ μχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%
医学统计学部分试题及答案解析
第一章绪论 1.下列关于概率的说法,错误的是 A. 通常用P表示 B. 大小在0%与100%之间 C. 某事件发生的频率即概率 D. 在实际工作中,概率是难以获得的 E. 某事件发生的概率很小,在单次研究或观察中时,称为小概率事件 [参考答案] C. 某事件发生的频率即概率 2.下列有关个人基本信息的指标中,属于有序分类变量的是 A. 学历 B. 民族 C. 血型 D. 职业 E. 身高 [参考答案] A. 学历3.下列有关个人基本信息的指标,其中属于定量变量的是 A. 性别 B. 民族 C. 职业 D. 血型 E. 身高 [参考答案] E. 身高 4.下列关于总体和样本的说法,不正确的是 A. 个体间的同质性是构成总体的必备条件 B. 总体是根据研究目的所确定的观察单位的集合 C. 总体通常有无限总体和有限总体之分 D. 一般而言,参数难以测定,仅能根据样本估计 E. 从总体中抽取的样本一定能代表该总体
[参考答案] E. 从总体中抽取的样本一定能代表该总体 5.在有关2007年成都市居民糖尿病患病率的调查研究中,总体是 A. 所有糖尿病患者 B. 所有成都市居民 C. 2007年所有成都市居民 D. 2007年成都市居民中的糖尿病患者 E. 2007年成都市居民中的非糖尿病患者[参考答案] C. 2007年所有成都市居民 6.简述小概率事件原理。 答:当某事件发生的概率很小,习惯上认为小于或等于0.05时,统计学上称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓小概率事件原理,它是进行统计推断的重要基础。 7.举例说明参数和统计量的概念答:某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病率。统计量是研究人员能够知道的,而参数是他们想知道的。一般情况下,这些参数是难以测定的,仅能根据样本估计。显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的 8.举例说明总体和样本的概念 答:研究人员通常需要了解和研究某一类个体,这个类就是总体。总体是根据研究目的所确定的观察单位的集合,通常有无限总体和有限总体之分,前者指总体中的个体数是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体数是有限的,它是指特定时间、空间中有限个研究个体。但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。例如在一项关于2007
流行病学英文总结
流行病学英文版总结(精华版) 乌衣月Email:Frnbdx@https://www.360docs.net/doc/0e14725655.html, 1、Epidemiology Epidemiology is the study that is based on distribution and factors of diseases and health-related states in populations,and then makes politicies and takes measures to control heslth problems. 2、Exposure Exposure is a very common used term in epidemiology,it refers to the causal factors that may be associated with the disease,for example,contact with a harmful materials,or some characteristics ,such as the age which may put an individual at increased risk. 3、Outcome Outcome is the disease or other changes in health status.It is the possible result that may be associated with the causes,risk factors or preventive measures. 4、Descriptive epidemiology Descriptive epidemiology is concerned with the variations of morbidity and mortality in a community.It concentrates on the description of distribution of morbidity or mortality by person,place and time,and then we can pose the hyposthesis,such as case report,ecological study and cross-sectional study. 5、Ecological study Ecological study is a type of descriptive study.It is the study of the relationship between some factors and diseases in the group level, the unit of observation and analysis is group.We describe the exposure status of disease factors and the frequency of diseases in different populations and then analyse the relationship between exposure and disease,for example, ecological comparison study and ecological trend study. 6、Experimental epidemiology Experimental epidemiology is to identify a group of subjects with the same conditions,and randomizes the subjects into intervention and control groups,follows them up for a period of time,compares the outcome between the groups,so as to evaluate the efficacy of the intervention.It is also called the interventional study,includes clinical trial,field trial and community trial. 7、Observational study Observational study is a kind of epidemiology.We observe and measure the occurrence of the disease or other health-related status in different groups with various characteristics and attempt to identy the causal association between the exposure and outcome,but we do not intervene in any way,so it is called the observational study,such as cross-sectional study,cohort study and so on. 8、Three levels of prevention Primary prevention concentrates on the cause prevention or reduction of risk factors,so as to prevent the development of disease. Secondary prevention is to diagnose and treat diseases in their early stages so as to restore or improve health,such as the screening program. Tertiary prevention is to reduce complications of disease,improve the outcome,so as to improve the quality of life of the patients. 9、PYLL PYLL is measure of the socio-economic impact of the premature death of an individual.It is
医学统计学练习题与答案
一、单向选择题 1. 医学统计学研究的对象是 E.有变异的医学事件 2. 用样本推论总体,具有代表性的样本指的是E.依照随机原则抽取总体中的部分个体 3. 下列观测结果属于等级资料的是 D.病情程度 4. 随机误差指的是 E. 由偶然因素引起的误差 5. 收集资料不可避免的误差是 A.随机误差 1.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是 A. 中位数 2. 算术均数与中位数相比,其特点是 B.能充分利用数据的信息 3. 一组原始数据呈正偏态分布,其数据的特点是 D.数值分布偏向较小一侧 4. 将一组计量资料整理成频数表的主要目的是E.提供数据和描述数据的分布特征 1. 变异系数主要用于 A .比较不同计量指标的变异程度 2. 对于近似正态分布的资料,描述其变异程度应选用的指标是E. 标准差 3.某项指标95%医学参考值范围表示的是D.在“正常”总体中有95%的人在此范围 4.应用百分位数法估计参考值范围的条件是B .数据服从偏态分布 5.已知动脉硬化患者载脂蛋白B 的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用 E .四分位数间距 1.样本均数的标准误越小说明 E.由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是D.个体差异 3.对于正偏态分布的的总体,当样本含量足够大时,样本均数的分布近似为C.正态分布 4. 假设检验的目的是 D.检验总体参数是否不同 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109 /L ~9.1×109 /L ,其含义是 E.该区间包含总体均数的可能性为95% 1. 两样本均数比较,检验结果05.0 P 说明 D.不支持两总体有差别的结论 2. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指 E. 有理由认为两总体均数有差别 3. 两样本均数比较,差别具有统计学意义时,P 值越小说明 D.越有理由认为两总体均数不同 4. 减少假设检验的Ⅱ类误差,应该使用的方法是 E.增加样本含量 5.两样本均数比较的t 检验和u 检验的主要差别是B.u 检验要求大样本资料
医学统计学第3版,02计量资料的统计描述试题
第二章 计量资料的统计描述 一、教学大纲要求 (一)掌握内容 1. 频数分布表与频数分布图 (1)频数表的编制。 (2)频数分布的类型。 (3)频数分布表的用途。 2. 描述数据分布集中趋势的指标 掌握其意义、用途及计算方法。算术均数、几何均数、中位数。 3. 描述数据分布离散程度的指标 掌握其意义、用途及计算方法。极差、四分位数间距、方差、标准差、变异系数。 (二)熟悉内容 连续型变量的频数分布图:等距分组、不等距分组。 二、 教学内容精要 计量资料又称为测量资料,它是测量每个观察单位某项指标值的大小所得的资料,一般均有计量单位。常用描述定量资料分布规律的统计方法有两种:一类是用统计图表,主要是频数分布表(图);另一类是选用适当的统计指标。 (一)频数分布表的编制 频数表(frequency table )用来表示一批数据各观察值或在不同取值区间的出现的频繁程度(频数)。对于离散数据,每一个观察值即对应一个频数,如某医院某年度一日内死亡0,1,2,…20个病人的天数。如描述某学校学生性别分布情况,男、女生的人数即为各自的频数。对于散布区间很大的离散数据和连续型数据,数据散布区间由若干组段组成,每个组段对应一个频数。制作连续型数据频数表一般步骤如下: 1.求数据的极差(range )。 min max X X R -= (2-1) 2.根据极差选定适当“组段”数(通常8—10个)。 确定组段和组距。每个组段都有下限L 和上限U ,数据χ归组统一定为L ≤χ医学统计学课后答案解析
第二章 1?答:在统计学中用来描述集中趋势的指标体系是平均数,包括算术均数,几何均数,中位数。 均数反映了一组观察值的平均水平,适用于单峰对称或近似单峰对称分布资料的平均水平的描述。 几何均数:有些医学资料,如抗体的滴度,细菌计数等,其频数分布呈明显偏态,各观察值之间呈倍数变化(等比关系),此时不宜用算术均数描述其集中位置,而应该使用几何均数(geometric mean)。几何均数一般用G表示,适用于各变量值之间成倍数关系,分布呈偏态,但经过对数变换后成单峰对称分布的资料。 中位数和百分位数: 中位数(median)就是将一组观察值按升序或降序排列,位次居中的数,常用M表 示。理论上数据集中有一半数比中位数小,另一半比中位数大。中位数既适用于资料呈偏态分布或不规则分布时集中位置的描述,也适用于开口资料的描述。所谓开口”资料, 是指数据的一端或者两端有不确定值。 百分位数(percentile)是一种位置指标,以P X表示,一个百分位数P X将全部观察值分为两个部分,理论上有X%的观察值比P X小,有(100-X)%观察值比P X大。故百分位数是一个界值,也是分布数列的一百等份分割值。显然,中位数即是P50分位数。 即中位数是一特定的百分位数。常用于制定偏态分布资料的正常值范围。 2?答:常用来描述数据离散程度的指标有:极差、四分位数间距、标准差、方差、及变异系数,尤以方差和标准差最为常用。 极差(range,记为R),又称全距,是指一组数据中最大值与最小值之差。极差大,说明资料的离散程度大。用极差反映离散程度的大小,简单明了,故得到广泛采用,如用以说明传染病、食物中毒等的最短、最长潜伏期等。其缺点是:1?不灵敏;2?不稳定。 四分位数间距(inter-quartile range)就是上四分位数与下四分位数之差,即:Q= Q u —Q L ,其间包含了全部观察值的一半。所以四分位数间距又可看成中间一半观察值的极差。其意义与极差相似,数值大,说明变异度大;反之,说明变异度小。常用于描述偏态分布资料的离散程度。 极差和四分位数间距均没有利用所研究资料的全部信息,因此仍然不足以完整地反 映资料的离散程度。 方差(variance)和标准差(standard deviation)由于利用了所有的信息,而得到了广泛应用,常用于描述正态分布资料的离散程度。 变异系数(coefficient of variance , CV)亦称离散系数(coefficient of dispersion ), 为标准差与均数之比,常用百分数表示。变异系数没有度量衡单位,常用于比较度量单位不同或均数相差悬殊的两组或多组资料的离散程度。 3?答:常用的相对数指标有:比,构成比和率。 比(ratio),又称相对比,是A、B两个有关指标之比,说明A为B的若干倍或百 分之几,它是对比的最简单形式。其计算公式为比二A/B 率(rate)又称频率指标,用以说明某现象发生的频率或强度。常以百分率(%)、千分 率(%。)、万分率(1/万)、十万分率(1/10万)等表示。计算公式为: 率.= 实际发生某现象的观察单位数迸比例基数(K) 可能发生某现象的观察单位总数 构成比(proportion)又称构成指标,它说明一种事物内部各组成部分所占的比重或
医学统计学试题及答案
医学统计学 一、选择题 1、根据某医院对急性白血病患者构成调查所获得的资料应绘制( B ) A 条图 B 百分条图或圆图C线图D直方图 2、均数和标准差可全面描述 D 资料的特征 A 所有分布形式B负偏态分布C正偏态分布D正态分布和近似正态分布 3、要评价某市一名5岁男孩的身高是否偏高或偏矮,其统计方法是(A ) A 用该市五岁男孩的身高的95%或99%正常值范围来评价 B 用身高差别的假设检验来评价 C 用身高均数的95%或99%的可信区间来评价 < D 不能作评价 4、比较身高与体重两组数据变异大小宜采用(A ) A 变异系数 B 方差 C 标准差 D 四分位间距 5、产生均数有抽样误差的根本原因是( A ) A.个体差异 B. 群体差异 C. 样本均数不同 D. 总体均数不同 6. 男性吸烟率是女性的10倍,该指标为(A ) (A)相对比(B)构成比(C)定基比(D)率 7、统计推断的内容为( D ) A.用样本指标估计相应的总体指标 B.检验统计上的“检验假设” C. A和B均不是 D. A和B均是 ' 8、两样本均数比较用t检验,其目的是检验( C ) A两样本均数是否不同B两总体均数是否不同 C两个总体均数是否相同D两个样本均数是否相同 9、有两个独立随机的样本,样本含量分别为n1和n2,在进行成组设计资料的t检验时,自由度是( D ) (A)n1+ n2 (B)n1+ n2 –1 (C)n1+ n2 +1 (D)n1+ n2 -2 10、标准误反映(A ) A 抽样误差的大小 B总体参数的波动大小 , C 重复实验准确度的高低 D 数据的离散程度 11、最小二乘法是指各实测点到回归直线的(C) A垂直距离的平方和最小B垂直距离最小 C纵向距离的平方和最小D纵向距离最小 12、对含有两个随机变量的同一批资料,既作直线回归分析,又作直线相关分析。令对相关系数检验的t值为tr,对回归系数检验的t值为tb,二者之间具有什么关系(C) A tr>tb B tr 2. ANOVA 实验结果 Sum of Squares df Mean Square F Sig. Between Groups 43.194 3 14.398 13.697 .000 Within Groups 37.842 36 1.051 Total 81.036 39 Multiple Comparisons Dependent Variable: 实验结果 Dunnett t (2-sided)a (I) 分组(J) 分组Mean Difference (I-J) Std. Error Sig. 95% Confidence Interval Lower Bound Upper Bound 0.5 对照组-2.15000*.45851 .000 -3.2743 -1.0257 1.0 对照组- 2.27000*.45851 .000 - 3.3943 -1.1457 1.5 对照组-2.66000*.45851 .000 -3.7843 -1.5357 F=13.697 P=0.000004 P A=0.000113 P B=0.000051 P C=0.000004均小于0.001 根据完全随机资料的方差分析,按α=0.05水准,拒绝H0,接受H1,认为四组治疗组小白鼠的肿瘤重量总体均数不全相等,即不同剂量药物注射液的抑癌作用有差别。 3. Tests of Between-Subjects Effects Dependent Variable: 重量 Source Type III Sum of Squares df Mean Square F Sig. Hypothesis 99736.333 1 99736.333 58.489 .005 Error 5115.667 3 1705.222a 治疗 Hypothesis 6503.167 2 3251.583 44.867 .000 Error 434.833 6 72.472b 分组 Hypothesis 5115.667 3 1705.222 23.529 .001 Error 434.833 6 72.472b F:44.867 23.529 P:0.000246 0.001020<0.01 根据随机区组资料的方差分析,按α=0.05水准,拒绝H0,接受H1,三组注射不同剂量雌激素的大白鼠子宫重量总体均数不全相等,即注射不同剂量的雌激素对大白鼠子宫重量有影响 5.医学统计学第三版第四章课后习题答案