深入学习分区表及分区索引(详解oracle分区)

下载的,写的非常好,给大家分享下。
什么时候使用分区:
1、大数据量的表,比如大于2GB。一方面2GB文件对于32位os是一个上限,另外备份时间长。
2、包括历史数据的表,比如最新的数据放入到最新的分区中。典型的例子:历史表,只有当前月份的数据可以被修改,而其他月份只能read-only
ORACLE只支持以下分区:tables, indexes on tables, materialized views, and indexes on materialized views
分区对SQL和DML是透明的(应用程序不必知道已经作了分区),但是DDL
可以对不同的分区进行管理。
不同的分区之间必须有相同的逻辑属性,比如共同的表名,列名,数据类型,约束;
但是可以有不同的物理属性,比如pctfree, pctused, and tablespaces.
分区独立性:即使某些分区不可用,其他分区仍然可用。
最多可以分成64000个分区,但是具有LONG or LONG RAW列的表不可以,但是有CLOB or BLOB列的表可以。
可以不用to_date函数,比如:
alter session set nls_date_format='mm/dd/yyyy';
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
(
PARTITION sales_jan2000 VALUES LESS THAN('02/01/2000'),
PARTITION sales_feb2000 VALUES LESS THAN('03/01/2000'), PARTITION sales_mar2000 VALUES LESS THAN('04/01/2000'), PARTITION sales_apr2000 VALUES LESS THAN('05/01/2000') );
Partition Key:最多16个columns,可以是nullable的
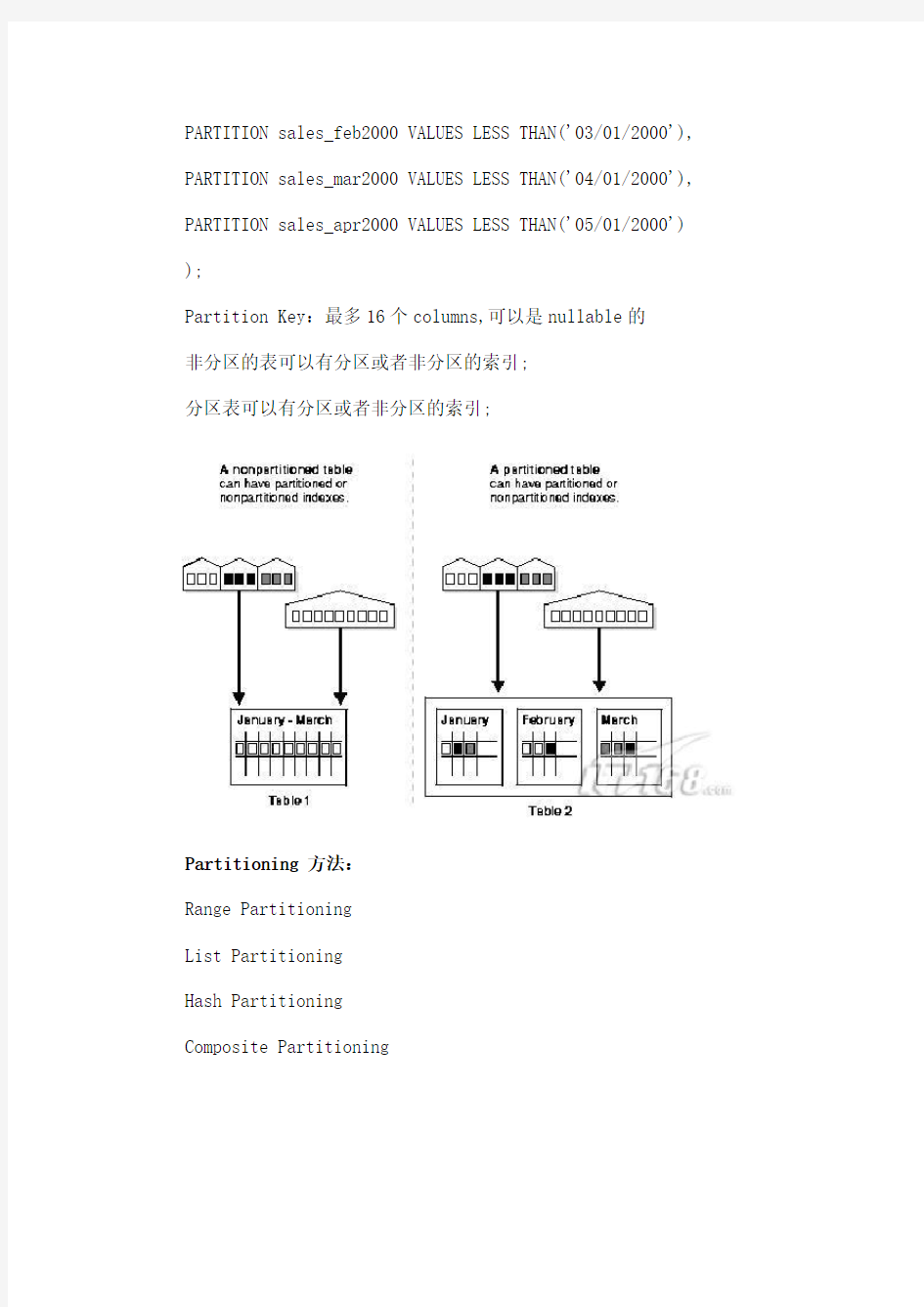
非分区的表可以有分区或者非分区的索引;
分区表可以有分区或者非分区的索引;
Partitioning 方法:
Range Partitioning
List Partitioning
Hash Partitioning
Composite Partitioning
Composite Partitioning:组合,以及 range-hash and range-list composite partitioning
Range Partitioning:
每个分区都有VALUES LESS THAN子句,表示这个分区小于(<)某个上限,而大于等于(>=)前一个分区的VALUES LESS THAN值。
MAXVALUE定义最高的分区,他表示一个虚拟的无限大的值。这个分区包括null值。
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
(
PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('01/02/2000','DD/MM/YYYY')),
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('01/03/2000','DD/MM/YYYY')),
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('01/04/2000','DD/MM/YYYY')),
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('01/05/2000','DD/MM/YYYY')),
PARTITION sales_2000 VALUES LESS THAN(MAXVALUE)
);
插入数据:
Insert into sales_range
values(1,2,3,to_date('21-04-2000','DD-MM-YYYY'));
Insert into sales_range values(1,2,3,sysdate);
选择数据:
select * from sales_range;
select * from sales_range partition(sales_apr2000);
select * from sales_range partition(sales_mar2000);
select * from sales_range partition(sales_2000);
按照多个列分区:
CREATE TABLE sales_range1
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_date DATE)
PARTITION BY RANGE(sales_date, sales_amount)
(
PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('01/02/2000','DD/MM/YYYY'),1000),
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('01/03/2000','DD/MM/YYYY'),2000),
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('01/04/2000','DD/MM/YYYY'),3000),
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('01/05/2000','DD/MM/YYYY'),4000),
PARTITION sales_2000 VALUES LESS THAN(MAXVALUE, MAXVALUE) );
Insert into sales_range1 values(1,2,500,
TO_DATE('21/01/2000','DD/MM/YYYY'));
Insert into sales_range1 values(2,3,1500, sysdate);
如果多个分区列的值冲突,则按照从左到右的优先级。
List Partitioning:
可以组织无序的,或者没有关系的数据在相同的分区。
不支持多列的(multicolumn) partition keys,只能是一个列。
DEFAULT表示不满足条件的都放在这个分区。
CREATE TABLE sales_list
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_date DATE)
PARTITION BY LIST(sales_state)
(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois'),
PARTITION sales_other VALUES(DEFAULT)
);
Hash Partitioning:
不可以作splitting, dropping or merging操作。但是可以added and coalesced.
当我们无法判断有多少数据映射或者怎样映射到各个分区时,可以使用这种方法。分区数据最好是2的幂,这样可以平均分配数据。
CREATE TABLE sales_hash1
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
PARTITIONS 4
STORE IN (users, TOOLS, TEST, TABLESPACE1); --表空间
CREATE TABLE sales_hash
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
(
PARTITION p1 tablespace users,
PARTITION p2 tablespace system
);
Composite Partitioning:
先按照range分区,每个子分区又按照list or hash分区。
CREATE TABLE sales_composite
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id) --子分区
SUBPARTITION TEMPLATE(
SUBPARTITION sp1 TABLESPACE data1,
SUBPARTITION sp2 TABLESPACE data2,
SUBPARTITION sp3 TABLESPACE data3,
SUBPARTITION sp4 TABLESPACE data4)
(PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('02/01/2000','DD/MM/YYYY'))
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('03/01/2000','DD/MM/YYYY'))
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('04/01/2000','DD/MM/YYYY'))
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('05/01/2000','DD/MM/YYYY'))
PARTITION sales_may2000 VALUES LESS
THAN(TO_DATE('06/01/2000','DD/MM/YYYY')));
使用TEMPLATE,oracle会这样命名子分区:分区_子分区,比如
sales_jan2000_sp1表示将数据放在data1表空间
Range-list:
CREATE TABLE bimonthly_regional_sales
(deptno NUMBER,
item_no VARCHAR2(20),
txn_date DATE,
txn_amount NUMBER,
state VARCHAR2(2))
PARTITION BY RANGE (txn_date)
SUBPARTITION BY LIST (state)
SUBPARTITION TEMPLATE(
SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE system,
SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE users,
SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE tools)
( PARTITION janfeb_2000 VALUES LESS THAN
(TO_DATE('1-03-2000','DD-Mm-YYYY')), PARTITION marapr_2000 VALUES LESS THAN (TO_DATE('1-05-2000','DD-Mm-YYYY')), PARTITION mayjun_2000 VALUES LESS THAN (TO_DATE('1-07-2000','DD-Mm-YYYY')) );
分区维护操作:
移动分区:
通常是移动到不同的表空间。Move
Alter table sales_hash move partition p2 tablespace users;
(单独移动表也可以,达到整理碎片的效果
Alter table t move tablespace users;)
添加分区:
Alter table t add partition p3 values less than……
只能在已经分区表的最后一个分区之后添加,并且最后一个分区使用特定健值定义,不能是maxvalue.
如果想在中间或开始部分,或者maxvalue后,添加分区,使用split 分裂已有分区。
拆分分区:
ALTER TABLE SALES_RANGE SPLIT PARTITION sales_2000
at (TO_DATE('01/05/2001','DD/MM/YYYY'))
INTO ( PARTITION sales_2000_1, PARTITION sales_2000_2);
相当于:PARTITION sales_2000_1 values less
than(TO_DATE('01/05/2001','DD/MM/YYYY'))
删除分区:
Alter table t drop partition p3;
Alter table t truncate partition p3;
结合分区:
只是对于hash partition, 用来合并并减少一个partition
set line 150
Select segment_name,partition_name from dba_segments
where segment_name=upper(’sales_hash’);
alter table sales_hash coalesce partition;
合并分区:
合并相邻的分区
ALTER TABLE four_seasons
MERGE PARTITIONS quarter_one, quarter_two INTO PARTITION
quarter_two;
交换表分区:
CREATE TABLE sales_range_temp
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE);
insert into sales_range_temp values(11,11,11,sysdate);
select * from sales_range partition(sales_2000_2);
alter table sales_range exchange partition sales_2000 with table sales_range_temp;
分区索引:
分为global, local index
local partitioned index:
每个local index对应一个分区。增加和删除分区自动的增加和删除了local index。
Local index可以是全表unique的,条件是partition key必须是index columns的一部分?
CREATE INDEX employees_local_idx ON employees (employee_id) LOCAL;
分区上的位图索引只能建立为local partitioned index,不能是global
Global partitioned index:
索引也分区,但是分几个区,按照什么样的partition key分区跟表没有关系。不能增加分区,可以使用ALTER INDEX SPLIT PARTITION;删除:ALTER INDEX DROP PARTITION;这些操作会使的索引失效,所以建议:
ALTER TABLE DROP PARTITION P1 UPDATE GLOBAL INDEXES
这样保证索引仍然有效,online,不需重建。
CREATE INDEX employees_global_part_idx ON employees(employee_id)
GLOBAL PARTITION BY RANGE(employee_id)
(PARTITION p1 VALUES LESS THAN(5000),
PARTITION p2 VALUES LESS THAN(MAXVALUE));
Global Nonpartitioned Indexes:
怎样提高性能:
Partition Pruning
根据SQL自动选择应该访问哪些必要的分区,partition pruning可以跳过不必要的索引或者表分区或子分区。但是如果SQL对partition columns作了function( to_date除外),则不会删除分区。
深入学习分区表及分区索引(1)
2008-05-22 18:58
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类:
v Range(范围)分区
v Hash(哈希)分区
v List(列表)分区
v 以及组合分区:Range-Hash,Range-List。
对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。
对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。
注:本篇所有示例仅针对常规表,即堆组织表!
对于索引,需要区分创建的是全局索引,或本地索引:
l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。
l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你
add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。
Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。
WHEN
一、When使用Range分区
Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据放到a分区,08年2季度的数据放到b分区,因此在创建的时候呢,需要你指定基于的列,以及分区的范围值,如果某些记录暂无法预测范围,可以创建maxvalue分区,所有不在指定范围内的记录都会被存储到maxvalue所在分区中,并且支持指定多列做为依赖列,后面在讲how的时候会详细谈到。
二、When使用Hash分区
通常呢,对于那些无法有效划分范围的表,可以使用hash分区,这样对于提高性能还是会有一定的帮助。hash分区会将表中的数据平均分配到你指定的几个分区中,列所在分区是依据分区列的hash值自动分配,因此你并不能控制也不知道哪条记录会被放到哪个分区中,hash分区也可以支持多个依赖列。
三、When使用List分区
List分区与range分区和hash分区都有类似之处,该分区与range分区类似的是也需要你指定列的值,但这又不同与range分区的范围式列值---其分区值必须明确指定,也不同与hash分区---通过明确指定分区值,你能控制记录存储在哪个分区。它的分区列只能有一个,而不能像range或者hash分区那样同时指定多个列做为分区依赖列,不过呢,它的单个分区对应值可以是多个。
你在分区时必须确定分区列可能存在的值,一旦插入的列值不在分区范围内,则插入/更新就会失败,因此通常建议使用list分区时,要创建一个default分区存储那些不在指定范围内的记录,类似range分区中的maxvalue分区。
四、When使用组合分区
如果某表按照某列分区之后,仍然较大,或者是一些其它的需求,还可以通过分区内再建子分区的方式将分区再分区,即组合分区的方式。
组合分区呢在10g中有两种:range-hash,range-list。注意顺序哟,根分区只能是range分区,子分区可以是hash分区或list分区。
提示:11g在组合分区功能这块有所增强,又推出了range-range,list-range,list-list,list-hash,这就相当于除hash外三种分区方式的笛卡尔形式都有了。为什么会没有hash做为根分区的组合分区形式呢,再仔细回味一下第二点,你一定能够想明白~~。
深入学习分区表及分区索引(2)--创建range分区
2008-05-22 19:00
一、如何创建
如果想对某个表做分区,必须在创建表时就指定分区,我们可以对一个包含分区的表中的分区做修改,但不能直接将一个未分区的表修改成分区表(起码在10g 是不行的,当然你可能会说,可以通过在线重定义的方式,但是这不是直接哟,这也是借助临时表间接实现的)。
创建表或索引的语法就不说了,大家肯定比我还熟悉,而想在建表(索引)同时指定分区也非常容易,只需要把创建分区的子句放到";"前就行啦,同时需要注意表的row movement属性,它用来控制是否允许修改列值所造成的记录移动至其它分区存储,有enable|disable两种状态,默认是disable row movement,当disable时,如果记录要被更新至其它分区,则更新语句会报错。
下面分别演示不同分区方式的表和索引的创建:
1、创建range分区
语法如下,图:[range_partitioning.gif]
需要我们指定的有:
l column:分区依赖列(如果是多个,以逗号分隔);
l partition:分区名称;
l values less than:后跟分区范围值(如果依赖列有多个,范围对应值也应是多个,中间以逗号分隔);
l tablespace_clause:分区的存储属性,例如所在表空间等属性(可为空),默认继承基表所在表空间的属性。
①创建一个标准的range分区表:
JSSWEB> create table t_partition_range (id number,name varchar2(50))
2 partition by range(id)(
3 partition t_range_p1 values less than (10) tablespace tbspart01,
4 partition t_range_p2 values less than (20) tablespace tbspart02,
5 partition t_range_p3 values less than (30) tablespace tbspart03,
6 partition t_range_pmax values less than (maxvalue) tablespace tbspart04
7 );
表已创建。
要查询创建分区的信息,可以通过查询
user_part_tables,user_tab_partitions两个数据字典(索引分区、组织分区等信息也有对应的数据字典,后续示例会逐步提及)。
user_part_tables:记录分区的表的信息;
user_tab_partitions:记录表的分区的信息。
例如:
JSSWEB> select table_name,partitioning_type,partition_count
2 From user_part_tables where table_name='T_PARTITION_RANGE'; TABLE_NAME PARTITI PARTITION_COUNT
------------------------------ ------- ---------------
T_PARTITION_RANGE RANGE 4
JSSWEB> select partition_name,high_value,tablespace_name
2 from user_tab_partitions where table_name='T_PARTITION_RANGE'
3 order by partition_position;
PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------------------ ---------- --------------------
T_RANGE_P1 10 TBSPART01
T_RANGE_P2 20 TBSPART02
T_RANGE_P3 30 TBSPART03
T_RANGE_PMAX MAXVALUE TBSPART04
②创建global索引range分区:
JSSWEB> create index idx_parti_range_id on t_partition_range(id)
2 global partition by range(id)(
3 partition i_range_p1 values less than (10) tablespace tbspart01,
4 partition i_range_p2 values less than (40) tablespace tbspart02,
5 partition i_range_pmax values less than (maxvalue) tablespace tbspart03);
索引已创建。
由上例可以看出,创建global索引的分区与创建表的分区语句格式完全相同,而且其分区形式与索引所在表的分区形式没有关联关系。
注意:我们这里借助上面的表t_partition_range来演示创建range分区的global索引,并不表示range分区的表,只能创建range分区的global索引,只要你想,也可以为其创建hash分区的global索引。
查询索引的分区信息可以通过user_part_indexes、user_ind_partitions两个数据字典:
JSSWEB> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PARTI_RANGE_ID';
INDEX_NAME PARTITI PARTITION_COUNT
------------------------------ ------- ---------------
IDX_PARTI_RANGE_ID RANGE 3
JSSWEB> select partition_name, high_value, tablespace_name
2 from user_ind_partitions
3 where index_name = 'IDX_PARTI_RANGE_ID'
4 order by partition_position;
PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------------------ ---------- --------------------
I_RANGE_P1 10 TBSPART01
I_RANGE_P2 40 TBSPART02
I_RANGE_PMAX MAXVALUE TBSPART03
③Local分区索引的创建最简单,例如:
仍然借助t_partition_range表来创建索引
--首先删除之前创建的global索引
JSSWEB> drop index IDX_PARTI_RANGE_ID;
索引已删除。
JSSWEB> create index IDX_PARTI_RANGE_ID on T_PARTITION_RANGE(id) local; 索引已创建。
查询相关数据字典:
JSSWEB> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PARTI_RANGE_ID';
INDEX_NAME PARTITI PARTITION_COUNT
------------------------------ ------- ---------------
IDX_PARTI_RANGE_ID RANGE 4
JSSWEB> select partition_name, high_value, tablespace_name
2 from user_ind_partitions
3 where index_name = 'IDX_PARTI_RANGE_ID'
4 order by partition_position;
PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------------------ ---------- --------------------
T_RANGE_P1 10 TBSPART01
T_RANGE_P2 20 TBSPART02
T_RANGE_P3 30 TBSPART03
T_RANGE_PMAX MAXVALUE TBSPART04
可以看出,local索引的分区完全继承表的分区的属性,包括分区类型,分区的范围值即不需指定也不能更改,这就是前面说的:local索引的分区维护完全依赖于其索引所在表。
不过呢分区名称,以及分区所在表空间等信息是可以自定义的,例如:
SQL> create index IDX_PART_RANGE_ID ON T_PARTITION_RANGE(id) local (
2 partition i_range_p1 tablespace tbspart01,
3 partition i_range_p2 tablespace tbspart01,
4 partition i_range_p3 tablespace tbspart02,
5 partition i_range_pmax tablespace tbspart02
6 );
索引已创建。
SQL> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PART_RANGE_ID';
INDEX_NAME PARTITI PARTITION_COUNT ------------------------------ ------- --------------- IDX_PART_RANGE_ID RANGE 4 SQL> select partition_name, high_value, tablespace_name
2 from user_ind_partitions
3 where index_name = 'IDX_PART_RANGE_ID'
4 order by partition_position;
PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
--------------- --------------- --------------------
I_RANGE_P1 10 TBSPART01
I_RANGE_P2 20 TBSPART01
I_RANGE_P3 30 TBSPART02
I_RANGE_PMAX MAXVALUE TBSPART02
深入学习分区表及分区索引(3)--创建hash分区
2008-05-22 19:02
oracle 建立分区表
oracle 建立分区表 从上次在亚旭培训的时候,我和dba讨论一次我开发系统中为了一张表不是非常的大,采用了动态sql创建多个部门的表,然后存取相应的数据,从而解决了一张表过大的问题。当时dba和我说了分区表,我第一感觉,如果当时我知道数据库还有这种表,那我当时开发起来应该轻松的多,后来就一直有个想法,去了解分区表,因为最近自己一直都比较忙,被琐事所困,今天晚上终于抽出了点时间,了解了相关的知识,并做了400多w条数据的一个分区表的测试。 一.范围分区 范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。 1 2 3 4 5 6 7 8 9 10 11 12 --例一取值范围: CREATE TABLE CUSTOMER ( CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY, FIRST_NAME VARCHAR2(30) NOT NULL, LAST_NAME VARCHAR2(30) NOT NULL, PHONE VARCHAR2(15) NOT NULL, EMAIL VARCHAR2(80), STATUS CHAR(1) ) PARTITION BY RANGE (CUSTOMER_ID) (
13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01, PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02, PARTITION CUS_PART3 VALUES LESS THEN(MAXVALUE) TABLESPACE CUS_TS02 ) --例二按时间划分(随着时间的增长,还需要添加分区表): CREATE TABLE ORDER_ACTIVITIES ( ORDER_ID NUMBER(7) NOT NULL, ORDER_DATE DATE, TOTAL_AMOUNT NUMBER, CUSTOTMER_ID NUMBER(7), PAID CHAR(1) ) PARTITION BY RANGE (ORDER_DATE) ( PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE('01- MAY -2003','DD-MON-YYYY')) TABLESPACE ORD_TS01, PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUN-2003','DD-MON-YYYY')) TABLESPACE ORD_TS02, PARTITION ORD_ACT_PART03 VALUES LESS THAN (TO_DATE('01-JUL-2003','DD-MON-YYYY')) TABLESPACE ORD_TS03
详解ORACLE簇表、堆表、IOT表、分区表
详解ORACLE簇表、堆表、IOT表、分区表 簇和簇表 簇其实就是一组表,是一组共享相同数据块的多个表组成。将经常一起使用的表组合在一起成簇可以提高处理效率。 在一个簇中的表就叫做簇表。建立顺序是:簇→簇表→数据→簇索引 1、创建簇的格式 CREATE CLUSTER cluster_name (column date_type [,column datatype]...) [PCTUSED 40 | integer] [PCTFREE 10 | integer] [SIZE integer] [INITRANS 1 | integer] [MAXTRANS 255 | integer] [TABLESPACE tablespace] [STORAGE storage] SIZE:指定估计平均簇键,以及与其相关的行所需的字节数。 2、创建簇 create cluster my_clu (deptno number) pctused60 pctfree10 size1024 tablespace users storage( initial128k next128k minextents2 maxextents20
);
3、创建簇表 create table t1_dept( deptno number, dname varchar2(20) ) cluster my_clu(deptno); create table t1_emp( empno number, ename varchar2(20), birth_date date, deptno number ) cluster my_clu(deptno); 4、为簇创建索引 create index clu_index on cluster my_clu; 注:若不创建索引,则在插入数据时报错:ORA-02032: clustered tables cannot be used before the cluster index is built 管理簇 使用ALTER修改簇属性(必须拥有ALTER ANY CLUSTER的权限) 1、修改簇属性 可以修改的簇属性包括: * PCTFREE、PCTUSED、INITRANS、MAXTRANS、STORAGE * 为了存储簇键值所有行所需空间的平均值SIZE * 默认并行度
postgresql和oracle表分区对比
PostgreSQL和oracle表分区对比 PostgreSQL是开源数据库,完全免费,oracle是有强大厂商支持和维护的数据库,把这两个的表分区特性放在一起对比,似乎有些勉强。但对于我们多了解一些特性,在实际开发中可以更好地进行理性选择和快速入手。
总结,数据库的表分区特性优点很多,比如: 1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。 5、将很少用的数据可以移动到便宜的、慢一些地存储介质上。 这两种数据库的分区表都具有这些优点。 对比来说,Oracle的分区创建和管理更加方便,很多工作是由oracle的内部机制来实现的。postgreSQL的分区表其实是一个个实际存在的数据表,分区的创建和管理都需要我们用语言来控制,增加了应用人员的工作量。 但,由于oracle自身的“侵占式”硬盘存储,对过期数据进行清除时,即便是drop分区表,也不能直接释放硬盘空间,属于“占了就占了”,这个管理起来就比较麻烦,除非对每个分区表都建立各个独立的tablespace,放在独立的物理文件上,删除过期分区表时,可以同时drop tablespace including contents。而postgreSQL在truncate 分区表时,可以直接释放硬盘,会看到硬盘使用率下降了,这一点对硬盘资源紧张时,就非常好了。 两种数据库的分区表使用,各有利弊,但总的来说,比较偏向postgreSQL,毕竟硬盘有限。而且,oracle收费。 Ps,在数据量很大时,任何关系型数据库都有性能上的瓶颈,不属于我们这两种数据库分区表对比的范围了。 以上,是一些使用中的总结,还请达人们指教:)。
Oracle 分区表的优点
ORACLE 表分区 表分区的好处和事处理 表分区描述 表分区(partition):表分区技术是在超大型数据库(VLDB)中将大表及其索引通过分区(patition)的形式分割为若干较小、可管理的小块,并且每一分区可进一步划分为更小的子分区(sub partition)。而这种分区对于应用来说是透明的。Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。每个分区都是一个独立的段(SEGMENT),可以存放到相同(不同)的表空间中。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用SQL DML 命令访问分区后的表时,无需任何修改。(对于高效率查询是有影响,主要差别是对某一分区数据时行查询时和对整体数据进行查询) 表分区的好处 通过对表进行分区,可以获得以下的好处: 1)增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 2)维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 3)均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能; 4)改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速
深入学习分区表及分区索引(详解oracle分区)
下载的,写的非常好,给大家分享下。 什么时候使用分区: 1、大数据量的表,比如大于2GB。一方面2GB文件对于32位os是一个上限,另外备份时间长。 2、包括历史数据的表,比如最新的数据放入到最新的分区中。典型的例子:历史表,只有当前月份的数据可以被修改,而其他月份只能read-only ORACLE只支持以下分区:tables, indexes on tables, materialized views, and indexes on materialized views 分区对SQL和DML是透明的(应用程序不必知道已经作了分区),但是DDL 可以对不同的分区进行管理。 不同的分区之间必须有相同的逻辑属性,比如共同的表名,列名,数据类型,约束; 但是可以有不同的物理属性,比如pctfree, pctused, and tablespaces. 分区独立性:即使某些分区不可用,其他分区仍然可用。 最多可以分成64000个分区,但是具有LONG or LONG RAW列的表不可以,但是有CLOB or BLOB列的表可以。 可以不用to_date函数,比如: alter session set nls_date_format='mm/dd/yyyy'; CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) ( PARTITION sales_jan2000 VALUES LESS THAN('02/01/2000'),
oracle大表分区
摘要:本篇文章介绍了ORACLE数据库的新特性—分区管理,并用例子说明使用方法。 关键词:ORACLE,分区 一、分区概述: 为了简化数据库大表的管理,ORACLE8推出了分区选项。分区将表分离在若干不同的表空间上,用分而治之的方法来支撑无限膨胀的大表,给大表在物理一级的可管理性。将大表分割成较小的分区可以改善表的维护、备份、恢复、事务及查询性能。针对当前社保及电信行业的大量日常业务数据,可以推荐使用ORACLE8的该选项。 二、分区的优点: 1 、增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍然可以使用; 2 、减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,故能比整个大表修复花的时间更少; 3 、维护轻松:如果需要重建表,独立管理每个分区比管理单个大表要轻松得多; 4 、均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能;
5 、改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快; 6 、分区对用户透明,最终用户感觉不到分区的存在。 三、分区的管理: 1 、分区表的建立: 某公司的每年产生巨大的销售记录,DBA向公司建议每季度的数据放在一个分区内,以下示范的是该公司1999年的数据(假设每月产生30M的数据),操作如下: STEP1、建立表的各个分区的表空间: CREATE TABLESPACE ts_sale1999q1 DATAFILE ‘/u1/oradata/sales/sales1999_q1.dat’ SIZE 100M DEFAULT STORAGE (INITIAL 30m NEXT 30m MINEXTENTS 3 PCTINCREASE 0) CREATE TABLESPACE ts_sale1999q2 DATAFILE ‘/u1/oradata/sales/sales1999_q2.dat’ SIZE 100M DEFAULT STORAGE (INITIAL 30m NEXT 30m MINEXTENTS 3 PCTINCREASE 0)
oracle大表分区
oracle大表分区 回答人:软界网友我来回答回答(3) STEP2、利用操作系统的工具删除以上表空间占用的文件(表空间基于裸设备无须次步),UNIX系统为例: oracle$ rm /u1/oradata/sales/sales1999_q1.dat oracle$ rm /u1/oradata/sales/sales1999_q2.dat oracle$ rm /u1/oradata/sales/sales1999_q3.dat oracle$ rm /u1/oradata/sales/sales1999_q4.dat 4 、分区的其他操作: 分区的其他操作包括截短分区(truncate),将存在的分区划分为多个分区(split),交换分区(exchange),重命名(rename),为分区建立索引等。DBA能够依照适当的情形使用。 以下仅说明分裂分区(split),例如该公司1999年第四季度销售明细数据急剧增加(因为庆国庆、迎千禧、贺回来),DBA向公司建议将第四季度的分区划分为两个分区,每个分区放两个月份的数据,操作如下: STEP1、按(1)的方法建立两个分区的表空间ts_sales1999q4p1, ts_sales1999q4p2;
STEP2、给表添加两个分区sales1999_q4_p1,sales1999_q4_p2; STEP3、分裂分区: ALTER TABLE sales SPLIT PARTITON sales1999_q4 AT TO_DATE (‘1999-11-01’,’YYYY-MM-DD’) INTO (partition sales1999_q4_p1, partition sales1999_q4_p2) 5 、查看分区信息: DBA要查看表的分区信息,可查看数据字典USER_EXTENTS,操作如下:SVRMGRL>SELECT * FROM user_extents WHERE SEGMENT_NAME=’SALES’; SEGMENT_NA PARTITION_ SEGMENT_TYPE TABLESPACE ---------- ------------ --------------- -------------- SALES SALES1999_Q1 TABLE PARTITION TS_SALES1999Q1 SALES SALES1999_Q2 TABLE PARTITION TS_SALES1999Q2 SALES SALES1999_Q3 TABLE PARTITION TS_SALES1999Q3 SALES SALES1999_Q4 TABLE PARTITION TS_SALES1999Q4 SALES SALES2000_Q1 TABLE PARTITION TS_SALES1999Q1 SALES SALES2000_Q2 TABLE PARTITION TS_SALES1999Q2 SALES SALES2000_Q3 TABLE PARTITION TS_SALES1999Q3 SALES SALES2000_Q4 TABLE PARTITION TS_SALES1999Q4
ORACLE_分区表_分区索引_索引分区
分区表_分区索引_索引分区 在大量业务数据处理的项目中,可以考虑使用分区表来提高应用系统的性能并方便数据管理,本文详细介绍了分区表的使用。 在大型的企业应用或企业级的数据库应用中,要处理的数据量通常可以达到几十到几百GB,有的甚至可以到TB级。虽然存储介质和数据处理技术的发展也很快,但是仍然不能满足用户的需求,为了使用户的大量的数据在读写操作和查询中速度更快,Oracle提供了对表和索引进行分区的技术,以改善大型应用系统的性能。 使用分区的优点: ·增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; ·维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; ·均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能; ·改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 Oracle数据库提供对表或索引的分区方法有三种: ·范围分区 ·Hash分区(散列分区) ·复合分区 下面将以实例的方式分别对这三种分区方法来说明分区表的使用。为了测试方便,我们先建三个表空间。 create tablespace dinya_space01 datafile ’/test/demo/oracle/demodata/dinya01.dnf’ size 50M create tablespace dinya_space01 datafile ’/test/demo/oracle/demodata/dinya02.dnf’ size 50M create tablespace dinya_space01 datafile ’/test/demo/oracle/demodata/dinya03.dnf’ size 50M 1.1. 分区表的创建 1.1.1. 范围分区
ORACLE分区表、分区索引
深入学习Oracle分区表及分区索引 关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: ?Range(范围)分区 ?Hash(哈希)分区 ?List(列表)分区 ?以及组合分区:Range-Hash,Range-List。 对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。 对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。 注:本篇所有示例仅针对常规表,即堆组织表! 对于索引,需要区分创建的是全局索引,或本地索引: l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。 l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。 Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。 ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。 range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。 List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。 Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE 会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。 WHEN 一、When使用Range分区 Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据
oracle分区表彻底删除的办法
oracle分区表彻底删除的办法 当对一个不再使用的分区表进行drop后,查询user_tab_partitions视图发现出现如下不规则的分区表表名: SQL> select distinct table_name from user_tab_partitions; BIN$l+Pv5l1jCMXgQKjAyQFA0A==$0 这样很容易导致自己写的"自动增加表的分区"的存过发生错误,因此为了避免再修改存过,只能把这些不规则的表名删除才行.现提供如下方法彻底删除这些不规则的表名. 其实当我们执行drop table tablename的时候,不是直接把表删除掉,而是放在了回收站里,可以通过查询user_recyclebin查看被删除的表信息.这样,回收站里的表信息就可以被恢复或彻底清除。 通过查询回收站user_recyclebin获取被删除的表信息,如果想恢复被drop掉的表,可以使用如下语句进行恢复 flashback table
多做知识的积累 详解ORACLE数据库的分区表
多做知识的积累详解ORACLE数据库的分区表 此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念 2.表分区的具体作用 3.表分区的优缺点 4.表分区的几种类型及操作方法 5.对表分区的维护性操作. (1.) 表空间及分区表的概念 表空间: 是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。 分区表: 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 ( 2).表分区的具体作用 Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。 什么时候使用分区表: 1、表的大小超过2GB。 2、表中包含历史数据,新的数据被增加都新的分区中。 (3).表分区的优缺点 表分区有以下优点: 1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。 缺点:
Oracle建分区表
在ORACLE里如果遇到特别大的表,可以使用分区的表来改变其应用程序的性能。 以system身份登陆数据库,查看v$option视图,如果其中Partition为TRUE,则支持分区功能;否则不支持。Partition有基于范围、哈希、综和三种类型。我们用的比较多的是按范围分区的表。 在ORACLE里如果遇到特别大的表,可以使用分区的表来改变其应用程序的性能。 以system身份登陆数据库,查看v$option视图,如果其中Partition为TRUE,则支持分区功能;否则不支持。Partition有基于范围、哈希、综和三种类型。我们用的比较多的是按范围分区的表。 我们以一个2001年开始使用的留言版做例子讲述分区表的创建和使用: 1 、以system 身份创建独立的表空间(大小可以根据数据量的多少而定) create tablespace g_2000q4 datafile '/home/oradata/oradata/test/g_2000q4.dbf' size 50M default storage (initial 100k next 100k minextents 1 maxextents unlimited pctincrease 1); create tablespace g_2001q1 datafile '/home/oradata/oradata/test/g_2001q1.dbf' size 50M default storage (initial 100k next 100k minextents 1 maxextents unlimited pctincrease 1); create tablespace g_2001q2 datafile '/home/oradata/oradata/test/g_2001q2.dbf' size 50M default storage (initial 100k next 100k minextents 1 maxextents unlimited pctincrease 1); 2 、用EXPORT工具把旧数据备份在guestbook.dmp中 把原来的guestbook表改名 alter table guestbook rename to guestbookold; 以guestbook 身份创建分区的表 create table guestbook( id number(16) primary key, username varchar2(64), sex varchar2(2), email varchar2(256), expression varchar2(128), content varchar2(4000), time date, ip varchar2(64) ) partition by range (time) (partition g_2000q4 values less than (to_date('2001-01-01','yyyy-mm-dd')) tablespace g_2000q4
ORACLE分区表的使用
分区表的使用 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 一、Oracle中提供了以下几种表分区: 1、范围分区:这种类型的分区是使用列的一组值,通常将该列成为分区键。 示例1:假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID 进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。下面是创建表和分区的代码,如下: CREATE TABLE CUSTOMER ( CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY, FIRST_NAME V ARCHAR2(30) NOT NULL, LAST_NAME V ARCHAR2(30) NOT NULL, PHONE VARCHAR2(15) NOT NULL, EMAIL VARCHAR2(80), STATUS CHAR(1) ) PARTITION BY RANGE (CUSTOMER_ID) ( PARTITION CUS_PART1 V ALUES LESS THAN (100000) TABLESPACE CUS_TS01, PARTITION CUS_PART2 V ALUES LESS THAN (200000) TABLESPACE CUS_TS02 ) 注意:在创建表进行分区时,表空间必须先存在,而且建议将不同的分区放入不同的表空间中。 示例2:假设有ORDER_ACTIVITIES表,每6个月对订单进行清理,我们可以按月份对表进行分区,分区代码如下: CREATE TABLE ORDER_ACTIVITIES ( ORDER_ID NUMBER(7) NOT NULL, ORDER_DATE DA TE, TOTAL_AMOUNT NUMBER, CUSTOTMER_ID NUMBER(7), PAID CHAR(1) ) PARTITION BY RANGE (ORDER_DA TE) ( PARTITION ORD_ACT_PART01 V ALUES LESS THAN
oracle分区操作文档
1. 分区建立 1.1. 建立分区表 create table bigtable ( sale_date date, product_id number, sale_count number, charge number, sales_id number ) tablespace ts_partition pctfree 5 pctused 80 initrans 1 maxtrans 255 parallel(degree 2) storage ( initial 2M next 2M minextents 1 maxextents unlimited pctincrease 0 ) partition by range(sale_date) ( partition sale_date_20020101 values less than (to_date('20020102','yyyymmdd')), partition sale_date_20020102 values less than (to_date('20020103','yyyymmdd')) ); 1.2. 建立分区索引 create index create index idx_bigtable_product_id on bigtable(product_id) parallel 2 local tablespace users on bigtable(product_id) parallel 2 local tablespace users;分区索引和全局索引:
分区索引就是在所有每个区上单独创建索引,它能自动维护,在drop或truncate某个分区时不影响该索引的其他分区索引的使用,也就是索引不会失效,维护起来比较方便,但是在查询性能稍微有点影响。create index idx_ta_c2 on ta(c2) local (partition p1,partition p2,partition p3,partition p4); 或者 create index idx_ta_c2 on ta(c2) local ; 另外在create unique index idx_ta_c2 on ta(c2) local ;系统会报ORA-14039错误,这是因为ta表的分区列是c1,不支持在分区表上创建PK主键或时主键列不包含分区列,创建唯一约束也不可以这样。 oracle 全局索引就是在全表上创建索引,它可以创建自己的分区,可以和分区表的分区不一样,也就是它是独立的索引。 在drop或truncate某个分区时需要创建索引alter index idx_xx rebuild,也可以通过alter table table_name drop partition partition_name update global indexes;实现,但是如果数据量很大则要花很长时间在重建索引上。 可以通过查询user_indexes、user_part_indexes和user_ind_partitions视图来查看索引是否有效。 create index idx_ta_c3 on ta(c3); 或者把全局索引分成多个区(注意和分区表的分区不一样): create index idx_ta_c4 on ta(c4) global partition by range(c4)(partition ip1 values less than(10000),partition ip2 values less than(20000),partition ip3 values less than(maxvalue)); 注意全局索引上的引导列要和range后列一致,否则会有ORA-14038错误。如不能这样写:create index idx_ta_c4 on ta(c1) global partition by range(c4)(partition ip1 values less than(10000),partition ip2 values less than(20000),partition ip3 values less than(maxvalue)); oracle会对主键自动创建全局索引 如果想使某个分区索引置为不可用则可以用如下脚本: alter index idx_tab1 modify partition "ind partition name" unusable 如果想在主键的列上创建分区索引,除非主键包括分区键,还有就是主键建在两个或以上列上,否则不能创建。
oracle分区表的建立方法
oracle分区表的建立方法 Oracle的分区表能够包括多个分区,每个分区差不多上一个独立的段(SEGMENT),能够存放到不同的表空间中。查询时能够通过查询表来访咨询各个分区中的数据,也能够通过在查询时直截了当指定分区的方法来进行查询。 分区提供以下优点: 由于将数据分散到各个分区中,减少了数据损坏的可能性; 能够对单独的分区进行备份和复原; 能够将分区映射到不同的物理磁盘上,来分散IO; 提高可治理性、可用性和性能。 Oracle提供了以下几种分区类型: 范畴分区(range); 哈希分区(hash); 列表分区(list); 范畴-哈希复合分区(range-hash); 范畴-列表复合分区(range-list)。 Oracle的一般表没有方法通过修改属性的方式直截了当转化为分区表,必须通过重建的方式进行转变,下面介绍三种效率比较高的方法,并讲明它们各自的特点。
方法一:利用原表重建分区表。 步骤: SQL> CREATE TABLE T (ID NUMBER PRIMARY KEY, TIME DATE); 表已创建。 SQL> INSERT INTO T SELECT ROWNUM, CREATED FROM DBA_OBJECTS; 已创建6264行。 SQL> COMMIT; 提交完成。 SQL> CREATE TABLE T_NEW (ID, TIME) PARTITION BY RANGE (TIME) 2 (PARTITION P1 V ALUES LESS THAN (TO_DATE('2004-7-1', 'YYYY-MM-DD')), 3 PARTITION P2 V ALUES LESS THAN (TO_DA TE('2005-1-1', 'YYYY-MM-DD')), 4 PARTITION P3 V ALUES LESS THAN (TO_DA TE('2005-7-1', 'YYYY-MM-DD')), 5 PARTITION P4 V ALUES LESS THAN (MAXV ALUE)) 6 AS SELECT ID, TIME FROM T; 表已创建。 SQL> RENAME T TO T_OLD;
Oracle Partition详解 优缺点
Oracle表分区详解 此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念 2.表分区的具体作用 3.表分区的优缺点 4.表分区的几种类型及操作方法 5.对表分区的维护性操作. (1.) 表空间及分区表的概念 表空间: 是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。 分区表: 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用 Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用SQL DML 命令访问分区后的表时,无需任何修改。 什么时候使用分区表: 1、表的大小超过2GB。 2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点 表分区有以下优点: 1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。 缺点: 分区表相关:已经存在的表没有方法可以直接转化为分区表。不过Oracle 提供了在线重定义表的功能。 (4).表分区的几种类型及操作方法
oracle数据表分区介绍
此文从以下几个方面来整理关于分区表的概念及操作:1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作。 (1.) 表空间及分区表的概念表空间: 是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。 分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 ( 2)。表分区的具体作用Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。 什么时候使用分区表:1、表的大小超过2GB. 2、表中包含历史数据,新的数据被增加都新的分区中。 (3)。表分区的优缺点表分区有以下优点:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数