常用限制性内切酶酶切位点保护残基

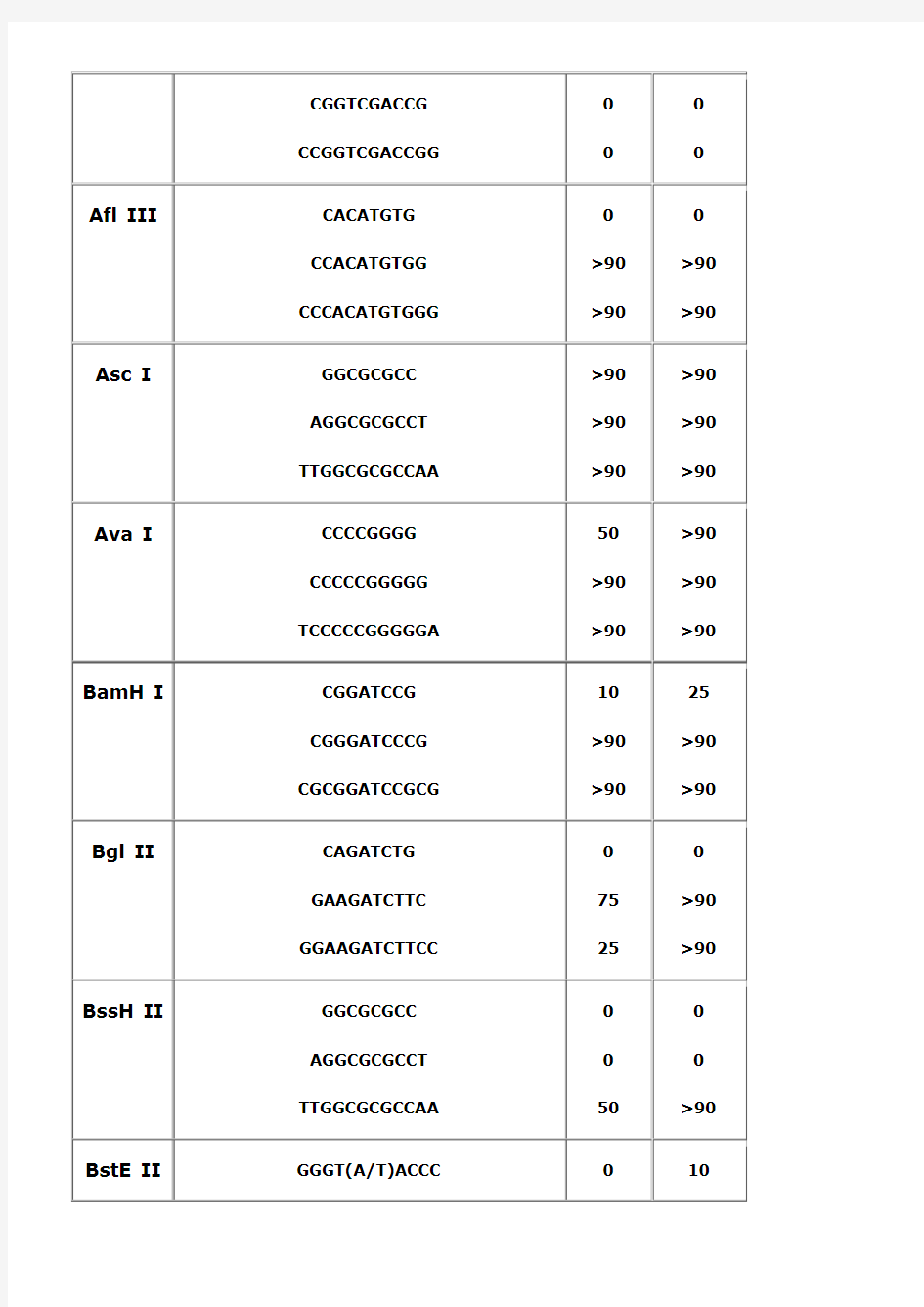
酶切位点保护碱基-PCR引物设计用于限制性内切酶
发布: 2010-05-24 20:19| 来源:生物吧| 编辑:刘浩| 查看: 161 次
本文给出了分子克隆中常用限制性内切酶的保护碱基序列,如AccI,AflIII,AscI,AvaI,BamHI,BglII,BssHII,BstEII,BstXI,ClaI,EcoRI,HaeIII,HindIII,KpnI,MluI,NcoI,NdeI,NheI,NotI,NsiI,PacI,PmeI,PstI,PvuI,SacI,SacII,SalI,ScaI,SmaI,SpeI,SphI,StuI,XbaI,XhoI,XmaI,
为什么要添加保护碱基?
在分子克隆实验中,有时我们会在待扩增的目的基因片段两端加上特定的酶切位点,用于后续的酶切和连接反应。由于直接暴露在末端的酶切位点不容易直接被限制性核酸内切酶切开,因此在设计PCR引物时,人为的在酶切位点序列的5‘端外侧添加额外的碱基序列,即保护碱基,用来提高将来酶切时的活性。
其次,在分子克隆实验中选择载体的酶切位点时,相临的两个酶切位点往往不能同时使用,因为一个位点切割后留下的碱基过少以至于影响旁边的酶切位点切割。
该如何添加保护碱基?
添加保护碱基时,最关心的应该是保护碱基的数目,而不是种类。什么样的酶切位点,添加几个保护碱基,是有数据可以参考的。
添加什么保护碱基,如果严格点,是根据两条引物的Tm值和各引物的碱基分布及GC含量。如果某条引物Tm值偏小,GC%较低,添加时多加G或C,反之亦反。
为了解不同内切酶对识别位点以外最少保护碱基数目的要求,NEB采用了一系列含识别序列的短双链寡核苷酸作为酶切底物进行实验。实验结果对于确定双酶切顺序将会有帮助(比如在多接头上切割位点很接近时),或者当切割位点靠近DNA末端时也很有用。在本表中没有列出的酶,则通常需在识别位点两端至少加上6个保护碱基,以确保酶切反应的进行。
实验方法:用γ-[32P]ATP在T4多聚核苷酸激酶的作用下标记0.1A260单位的寡核苷酸。取1μg已标记了的寡核苷酸与20单位的内切酶,在20°C条件下分别反应2小时和20小时。反应缓冲液含70mM Tris-HCl (pH 7.6), 10 mM MgCl2, 5 mMDTT及适量的NaCl或KCl(视酶的具体要求而定)。20%的PAGE(7M尿素)凝胶电泳分析,经放射自显影确定酶切百分率。
本实验采用自连接的寡核苷酸作为对照。若底物有较长的回文结构,切割效率则可能因为出现发夹结构而降低。
5‘端,就
(红的5’端加上
(黑,相同如果
3‘端加保
就在酶3’端加上相.切割率:正
。加保护碱基
常用限制性内切酶酶切位点汇总
Acc65I识别位点AccI识别位点AciI识别位点AclI识别位点AcuI识别位点 AfeI识别位点AflII识别位点AflIII识别位点AgeI识别位点AhdI识别位点AleI识别位点AluI识别位点AlwI识别位点AlwNI识别位点ApaI识别位点ApaLI识别位点ApeKI识别位点ApoI识别位点AscI识别位点AseI识别位点AsiSI识别位点AvaI识别位点AvaII识别位点AvrII识别位点BaeI识别位点BamHI识别位点BanI识别位点BanII识别位点
BbvCI识别位点BbvI识别位点 BccI识别位点BceAI识别位点BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点BmgBI识别位点BmrI识别位点BmtI识别位点BpmI识别位点Bpu10I识别位点BpuEI识别位点BsaAI识别位点BsaBI识别位点BsaHI识别位点BsaI识别位点BsaJI识别位点BsaWI识别位点BsaXI识别位点BseRI识别位点BseYI识别位点
BsiEI 识别位点BsiHKAI 识别位点BsiWI识别位点BslI 识别位点BsmAI识别位点 BsmBI识别位点BsmFI识别位点BsmI识别位点BsoBI识别位点Bsp1286I识别位点BspCNI识别位点BspDI识别位点BspEI识别位点BspHI识别位点BspMI识别位点BspQI识别位点BsrBI识别位点BsrDI识别位点BsrFI识别位点BsrGI识别位点BsrI识别位点BssHII识别位点BssKI识别位点BssSI识别位点BstAPI识别位点BstBI识别位点BstEII识别位点BstNI识别位点
蛋白酶酶切位点
蛋白酶酶切位点 木瓜蛋白酶巯基蛋白酶具有广泛特异性TPCK,TLCK,抑蛋白酶醛肽α-巨球蛋白,烷化剂胃蛋白酶酸蛋白酶广泛特异性胃蛋白酶抑制素 胰蛋白酶丝氨酸蛋白酶在K或R之后TLCK,PMSF,抑蛋白酶醛肽抑肽酶,α巨球蛋白人体20种氨基酸及其英文缩写
名称三字符号单字符号 丙氨酸Ala A 精氨酸Arg R 天冬氨酸Asp D 半胱氨酸Cys C 谷氨酰胺Gln Q 谷氨酸Glu/Gln E 组氨酸His H 异亮氨酸Ile I 甘氨酸Gly G 天冬酰胺Asn N 亮氨酸Leu L 赖氨酸Lys K 甲硫氨酸Met M 苯丙氨酸Phe F 脯氨酸Pro P 丝氨酸Ser S 苏氨酸Thr T 色氨酸Trp W 酪氨酸Tyr Y 缬氨酸Val V 【生化】特异性蛋白酶的酶切位点 胰蛋白酶arg、lys,得到以arg、lys为C末端残基的肽段。胰凝乳蛋白酶phe、trp、tyr 等疏水aa。胃蛋白酶phe、trp、tyr等疏水aa。木瓜蛋白酶arg、lys。葡萄球菌蛋白酶,磷酸缓冲液ph7.8时断裂glu、asp。碳酸氢铵缓冲液ph7.8或醋酸铵缓冲液ph4.0时断裂glu。梭菌蛋白酶arg,用于不溶性蛋白的长时间裂解。CNBr断裂Met。羟胺断裂asn—gly间的肽键。二硫键可以用巯基化合物还原法或者过甲酸氧化法断裂.。 木瓜蛋白酶(Papain),又称木瓜酶,是一种蛋白水解酶。木瓜蛋白酶是番木瓜(Carieapapaya)中含有的一种低特异性蛋白水解酶,广泛地存在于番木瓜的根、茎、叶和果实内,其中在未成熟的乳汁中含量最丰富。木瓜蛋白酶的活性中心含半胱氨酸,属于巯基蛋白酶,它具有酶活高、热稳定性好、天然卫生安全等特点,因此在食品、医药、饲料、日化、皮革及纺织等行业得到广泛应用。 木瓜蛋白酶是一种蛋白水解酶,分子量为23406,由一种单肽链组成,含有212个氨基酸残基。至少有三个氨基酸残基存在于酶的活性中心部位,他们分别是Cys25、His159和Asp158,另外六个半胱氨酸残基形成了三对二硫键,且都不在活性部位。纯木瓜蛋白酶制品可含有:(1)木瓜蛋白酶,分子量21000,约占可溶性蛋白质的10%;(2)木瓜凝乳蛋白酶,分子量26000,约占可溶性蛋白质的45%;(3)溶菌酶,分子量25000,约占可溶性蛋白质的20%;及纤维素酶等不同的酶。 番木瓜未成熟果实中含有木瓜蛋白酶(Papain)、木瓜凝乳蛋白酶A(Chymopapain A )、木瓜凝乳蛋白酶B(Chym opapain B )、木瓜肽酶B (PapayaPeptidase B ) 等多种蛋白水解酶。且已知四种半胱氨酸蛋白酶的一级结构具有高度的同源性。其中,木瓜蛋白酶属巯基蛋白酶,可水解蛋白质和多肽中精氨酸和赖氨酸的羧基端,并能优先水解那些在肽键的N-端具有二个羧基的氨基酸或芳香L-氨基酸的肽键。
限制性内切酶酶切位点汇总
Acc65I识别位点 AccI识别位点 AciI识别位点 AclI识别位点 AcuI识别位点 AfeI识别位点 AflII识别位点 AflIII识别位点 AgeI识别位点 AhdI识别位点 AleI识别位点 AluI识别位点 AlwI识别位点 AlwNI识别位点 ApaI识别位点 ApaLI识别位点 ApeKI识别位点 ApoI识别位点 AscI识别位点 AseI识别位点 AsiSI识别位点 AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI识别位点 BanI识别位点 BanII识别位点
BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点 BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点 BmgBI识别位点 BmrI识别位点 BmtI识别位点 BpmI识别位点 Bpu10I识别位点 BpuEI识别位点 BsaAI识别位点 BsaBI识别位点 BsaHI识别位点 BsaI识别位点 BsaJI识别位点 BsaWI识别位点 BsaXI识别位点 BseRI识别位点 BseYI识别位点
BsiEI识别位点 BsiHKAI识别位点 BsiWI识别位点 BslI识别位点 BsmAI识别位点 BsmBI识别位点 BsmFI识别位点 BsmI识别位点 BsoBI识别位点 Bsp1286I识别位点 BspCNI识别位点BspDI识别位点 BspEI识别位点 BspHI识别位点 BspMI识别位点 BspQI识别位点 BsrBI识别位点 BsrDI识别位点 BsrFI识别位点 BsrGI识别位点 BsrI识别位点 BssHII识别位点 BssKI识别位点 BssSI识别位点 BstAPI识别位点 BstBI识别位点 BstEII识别位点 BstNI识别位点
常用限制性内切酶酶切位点保护残基
酶切位点保护碱基-PCR引物设计用于限制性内切酶 发布: 2010-05-24 20:19| 来源:生物吧| 编辑:刘浩| 查看: 161 次 本文给出了分子克隆中常用限制性内切酶的保护碱基序列,如AccI,AflIII,AscI,AvaI,BamHI,BglII,BssHII,BstEII,BstXI,ClaI,EcoRI,HaeIII,HindIII,KpnI,MluI,NcoI,NdeI,NheI,NotI,NsiI,PacI,PmeI,PstI,PvuI,SacI,SacII,SalI,ScaI,SmaI,SpeI,SphI,StuI,XbaI,XhoI,XmaI, 为什么要添加保护碱基? 在分子克隆实验中,有时我们会在待扩增的目的基因片段两端加上特定的酶切位点,用于后续的酶切和连接反应。由于直接暴露在末端的酶切位点不容易直接被限制性核酸内切酶切开,因此在设计PCR引物时,人为的在酶切位点序列的5‘端外侧添加额外的碱基序列,即保护碱基,用来提高将来酶切时的活性。 其次,在分子克隆实验中选择载体的酶切位点时,相临的两个酶切位点往往不能同时使用,因为一个位点切割后留下的碱基过少以至于影响旁边的酶切位点切割。 该如何添加保护碱基? 添加保护碱基时,最关心的应该是保护碱基的数目,而不是种类。什么样的酶切位点,添加几个保护碱基,是有数据可以参考的。 添加什么保护碱基,如果严格点,是根据两条引物的Tm值和各引物的碱基分布及GC含量。如果某条引物Tm值偏小,GC%较低,添加时多加G或C,反之亦反。 为了解不同内切酶对识别位点以外最少保护碱基数目的要求,NEB采用了一系列含识别序列的短双链寡核苷酸作为酶切底物进行实验。实验结果对于确定双酶切顺序将会有帮助(比如在多接头上切割位点很接近时),或者当切割位点靠近DNA末端时也很有用。在本表中没有列出的酶,则通常需在识别位点两端至少加上6个保护碱基,以确保酶切反应的进行。 实验方法:用γ-[32P]ATP在T4多聚核苷酸激酶的作用下标记0.1A260单位的寡核苷酸。取1μg已标记了的寡核苷酸与20单位的内切酶,在20°C条件下分别反应2小时和20小时。反应缓冲液含70mM Tris-HCl (pH 7.6), 10 mM MgCl2, 5 mMDTT及适量的NaCl或KCl(视酶的具体要求而定)。20%的PAGE(7M尿素)凝胶电泳分析,经放射自显影确定酶切百分率。 本实验采用自连接的寡核苷酸作为对照。若底物有较长的回文结构,切割效率则可能因为出现发夹结构而降低。
限制性内切酶酶切位点_方便搜索
GACGTC CTGCAG Acc65I 识别位点 GTMKAC CAKMTG AccI 识别位点 GTMKAC CAKMTG AciI 识别位点 CCGC GGCG AclI 识别位点 AACGTT TTGCAA AcuI 识别位点 CTGAAG GACTTC AfeI 识别位点 AGCGCT TCGCGA CTTAAG GAATTC AflIII 识别位点 ACRYGT TGYRCA AgeI 识别位点 ACCGGT TGGCCA AhdI 识别位点 GACNNNNNGTC CTGNNNNNCAG AleI 识别位点 CACNNNNGTG GTGNNNNCAC AluI 识别位点 AGCT TCGA AlwI 识别位点 GGATC CCTAG
CAGNNNCTG GTCNNNGAC ApaI 识别位点 GGGCCC CCCGGG ApaLI 识别位点 GTGCAC CACGTG ApeKI 识别位点 GCWGC CGWCG ApoI 识别位点 RAATTY YTTAAR AscI 识别位点 GGCGCGCC CCGCGCGG AseI 识别位点 ATTAAT TAATTA GCGATCGC CGCTAGCG AvaI 识别位点 CYCGRG GRGCYC AvaII 识别位点 GGWCC CCWGG AvrII 识别位点 CCTAGG GGATCC BaeI 识别位点 NACNGTAYCN BamHI 识别位点 GGATCC CCTAGG BanI 识别位点 GGYRCC CCRYGG
常用限制性内切酶酶切位点
AatII 识别位点 Acc65I 识别位点 AccI 识别位点 AciI 识别位点 AclI 识别位点 AcuI 识别位点 AfeI 识别位点 AflII 识别位点 AflIII 识别位点 AgeI 识别位点 AhdI 识别位点 AleI 识别位点 AluI 识别位点 AlwI 识别位点 AlwNI 识别位点 ApaI 识别位点 ApaLI 识别位点 ApeKI 识别位点 ApoI 识别位点 AscI 识别位点 AseI 识别位点 AsiSI 识别位点
AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI 识别位点 BanI识别位点 BanII识别位点 BbsI识别位点 BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点BcgI识别位点BciVI识别位点BclI识别位点 BfaI识别位点BfuAI识别位点BglI识别位点BglII识别位点BlpI识别位点Bme1580I识别位点BmgBI识别位点BmrI识别位点
BmtI 识别位点 BpmI 识别位点 Bpu10I 识别位点 BpuEI 识别位点 BsaAI 识别位点 BsaBI 识别位点 BsaHI 识别位点 BsaI 识别位点 BsaJI 识别位点 BsaWI 识别位点 BsaXI 识别位点 BseRI 识别位点 BseYI 识别位点 BsgI 识别位点 BsiEI 识别位点 BsiHKAI 识别位点 BsiWI 识别位点 BslI 识别位点 BsmAI 识别位点 BsmBI 识别位点 BsmFI 识别位点 BsmI 识别位点
不同的酶切位点
ApaI (类型:Type II restriction enzyme )识别序列:5'GGGCC^C 3' BamHI(类型:Type II restriction enzyme )识别序列:5' G^GATCC 3' BglII (类型:Type II restriction enzyme )识别序列:5' A^GATCT 3' EcoRI (类型:Type II restriction enzyme )识别序列:5' G^AATTC 3' HindIII (类型:Type II restriction enzyme )识别序列:5' A^AGCTT 3' KpnI (类型:Type II restriction enzyme )识别序列:5' GGTAC^C 3' NcoI (类型:Type II restriction enzyme )识别序列:5' C^CATGG 3' NdeI (类型:Type II restriction enzyme )识别序列:5' CA^TATG 3' NheI (类型:Type II restriction enzyme )识别序列:5' G^CTAGC 3' NotI (类型:Type II restriction enzyme )识别序列:5' GC^GGCCGC 3' SacI (类型:Type II restriction enzyme )识别序列:5' GAGCT^C 3' SalI (类型:Type II restriction enzyme )识别序列:5' G^TCGAC 3' SphI (类型:Type II restriction enzyme )识别序列:5' GCATG^C 3' XbaI (类型:Type II restriction enzyme )识别序列:5' T^CTAGA 3' XhoI (类型:Type II restriction enzyme )识别序列:5' C^TCGAG 3'
蛋白酶专一性酶切位点地影响因素分析报告
蛋白酶专一性酶切位点的影响因素分析 摘要:生物活性肽(bioactive peptides)是具有特殊生理功能的肽。酶法水解蛋白质广泛用于制备生物活性肽,但酶解法存在目标肽得率低、副产物过多的缺点。蛋白酶和蛋白质的选择是关键步骤,局部构象、三维结构、实验条件以及其它偶然因素也会影响蛋白水解酶的酶切效果。本文综述了温度、pH值、温度和pH值共同作用、金属离子对酶切位点的影响,旨在为研究酶切规律、制备高得率活性肽提供理论基础。 关键词:生物活性肽;蛋白酶;水解条件;酶切位点 Influencing Factors Analysis of Protease Specific Cleavage Sites Abstract:Bioactive peptides are fragments with specific amino acid sequences that exert a positive physiological influence on the body. Many reported Bioactive peptides are produced by enzymatic hydrolysis,but there are disadvantages of by-product and low yield.The choice of protease and protein source is a key step,and many factors such as local conformation,tertiary structure, experimental conditions and causal interference can influence the protease hydyolysis.This article presents the influencing fators,temperature,pH values,temperature combined pH values and metal ions included,to provide theoretical basis for enzymatic law analysis and higher yield bioactive peptides production. Key words:bioactive peptides;protease;hydrolysis conditions;protease cleavage sites 1.前言 生物活性肽(bioactive peptides)是具有特殊生理功能的肽,是氨基酸以不同组成和排列方式构成的不同肽类的总称(氨基酸数目一般小于100)。生物活性肽有的是天然存在的,如谷胱甘肽、催产素、加压素、舒缓激肽、部分抗菌肽等,有的生物活性肽是以非活性的状态存在于某些蛋白质中,当用特定的蛋白酶水解后被释放出来,才成为有特定生理活性的肽。同种蛋白质经不同的蛋白酶酶解后,可以产生具有不同氨基酸序列、不同生理功能的生物活性肽,如大豆蛋白、
蛋白酶专一性酶切位点的影响因素分析
蛋白酶专一性酶切位点的影响因素分析 内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)
蛋白酶专一性酶切位点的影响因素分析 摘要:生物活性肽(bioactive peptides)是具有特殊生理功能的肽。酶法水解蛋白质广泛用于制备生物活性肽,但酶解法存在目标肽得率低、副产物过多的缺点。蛋白酶和蛋白质的选择是关键步骤,局部构象、三维结构、实验条件以及其它偶然因素也会影响蛋白水解酶的酶切效果。本文综述了温度、pH值、温度和pH值共同作用、金属离子对酶切位点的影响,旨在为研究酶切规律、制备高得率活性肽提供理论基础。 关键词:生物活性肽;蛋白酶;水解条件;酶切位点 Influencing Factors Analysis of Protease Specific Cleavage Sites Abstract: Bioactive peptides are fragments with specific amino acid sequences that exert a positive physiological influence on the body. Many reported Bioactive peptides are produced by enzymatic hydrolysis,but there are disadvantages of by-product and low yield.The choice of protease and protein source is a key step,and many factors such as local conformation,tertiary structure, experimental conditions and causal interference can influence the protease hydyolysis.This article presents the influencing fators,temperature,pH values,temperature combined pH values and metal ions included,to provide theoretical basis for enzymatic law analysis and higher yield bioactive peptides production. Key words:bioactive peptides;protease;hydrolysis conditions;protease cleavage sites
史上最全限制性内切酶酶切位点汇总
A系列 AatII识别位点 Acc65I识别位点 AccI识别位点 AciI识别位点 AclI识别位点 AcuI识别位点 AfeI识别位点 AflII识别位点 AflIII识别位点 AgeI识别位点 AhdI识别位点 AleI识别位点 AluI识别位点 AlwI识别位点 AlwNI识别位点 ApaI识别位点 ApaLI识别位点 ApeKI识别位点 ApoI识别位点 AscI识别位点 AseI识别位点 AsiSI识别位点 AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI识别位点 BanI识别位点 BanII识别位点
BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点 BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点 BlpI识别位点 Bme1580I识别位点 BmgBI识别位点 BmrI识别位点 BmtI识别位点 BpmI识别位点 Bpu10I识别位点 BpuEI识别位点 BsaAI识别位点 BsaBI识别位点 BsaHI识别位点 BsaI识别位点 BsaJI识别位点 BsaWI识别位点 BsaXI识别位点 BseRI识别位点 BseYI识别位点
BsiEI识别位点 BsiHKAI识别位点 BsiWI识别位点 BslI识别位点 BsmAI识别位点 BsmBI识别位点 BsmFI识别位点 BsmI识别位点 BsoBI识别位点 Bsp1286I识别位点 BspCNI识别位点BspDI识别位点 BspEI识别位点 BspHI识别位点 BspMI识别位点 BspQI识别位点 BsrBI识别位点 BsrDI识别位点 BsrFI识别位点 BsrGI识别位点 BsrI识别位点 BssHII识别位点 BssKI识别位点 BssSI识别位点 BstAPI识别位点 BstBI识别位点 BstEII识别位点 BstNI识别位点
酶切位点设计和选择
引物设计原则及酶切位点选择和设计 [整理]:最初的时候,由于害怕设计酶切位点最后且不开,所以经常采用最通用的方法,用T载体克隆解决问题,但后来发现她也有问题,就是浓度提不上去,你需要体大量的载体来酶切,所以感到还是直接扩增好一点。但这就需要你仔细设计引物。连入质粒中的重要目的就是进行酶切和连接,当然首先就是在想要合成或者是进行PCR扩增出靶基因的时候在核酸的两端接入酶切位点,酶切位点是与你的质粒的特点相关的,可以在质粒的图谱说明书上找取相应的位点,进行设计。 (一)设计引物前应做的准备工作: 准备载体图谱,大致准备把片断插在那个部分 对片断进行酶切分析,确定一下那些酶切位点不能用 准备一本所买公司的酶的商品目录,便于查酶的各种数据及两种酶是否可以配用 (二)设计引物所要考虑的问题 两个位点应是载体上的,,所连接片断上没有这两个位点,且距离不能太近,往往导致两个酶都切不好。因此,紧挨在一起,只能切一个,除非恰好是与上面两个酶在一起的酶切位点。我看promega的说明书上说,最好隔四个。还有一种情况是:不能有碱基的交叉,比如AGATCTTAAG,这样的位点比较难切。 两个酶切点最好不要是同尾酶(切下来的残基不要互补),否则效果相当于单酶切。 最好使用酶切效率高的。 最好使用双酶切有共同buffer的酶。 最好使用较常用的酶(如hind3,bamh1,ecor1等),最好使用自己实验室有的酶,这样可以省钱。 Tm的计算,关于Tm的问题,很多的战友都有疑惑。其实园子里有很多的解释了。 Tm叫溶解温度(melting temperature, Tm),即是DNA双链溶解所需的温度。大家可以理解,这个温度是由互补的DNA区域决定的,而不互补的区域对DNA的溶解是没有作用的。因此,对于引物的Tm,只有和模板互补的区域对Tm才有贡献。计算Tm时,只计算互补的区域(除非你的酶切位点也与模板互补)。不少战友设计的引物都Tm过低,是因为他们误把保护碱基和酶切位点都计算到Tm里了,最后的结果是导致了PCR反应的诸多困难。所以,设计引物的时候,先不管5'端的修饰序列,把互补区的Tm控制在55度以上(我喜欢控制在58以上,具体根据PCR的具体情况,对于困难的PCR,需要适当提高Tm),再加上酶切位点和保护碱基,这样的引物通常都是可用的,即使有小的问题,也可以挽回。Tm温度高的引物就比较容易克服3‘发卡、二聚体及3'非特异结合等问题。简单的计算公式可以用2+4的公式。若你计算的Tm值达到了快90 ,不包括酶切位点。引物公司给你发的单子是包括酶切位点的。自己可以再估计一下。如你设计了带酶切位点的引物,总长分别为29、33个碱基,去掉酶切位点和保护碱基,分别为17、21个碱基。引物公司给的单子是70多度,实际用的只有50度,用55度扩的结果也差不多。 其它关于Tm值的计算,有用PP5.0进行评价的,需要考虑的参数包括:base number、GC%、Tm、hairpin、dimer、false priming、cross dimer。退一般退火温度为Tm-5度,退火温度的计算可以不把加入的酶切位点及保护碱基考虑进去,如上所言,PCR几个循环后,引物外侧的序列已经参入了扩增片断中,所以你可以在预变性后多加几步,温度比你Tm值低些(这样可能会增加非特异性),Tm值是你包括酶切位点及保护碱基的Primer计算出来的。1.一般在5'端加保护碱基,如果你扩增后把目的条带做胶回收转入T-VECTOR或者其它的载体的话,酶切时可以不需加保护碱基2.有人的经验加入酶切位点的引物可以和未加入时使用相同的退火温度,结果也还是令人满意。
限制性内切酶酶切位点汇总
限制性内切酶酶切位点汇AatII识别位点 Acc65I识别位点AccI识别位点AciI识别位点AclI识别位点AcuI识别位点AfeI识别位点AflII识别位点AflIII识别位点AgeI识别位点AhdI识别位点AleI识别位点AluI识别位点AlwI识别位点AlwNI识别位点 ApaI识别位点 ApaLI识别位点 ApeKI识别位点 ApoI识别位点 AscI识别位点 AseI识别位点 AsiSI识别位点 AvaI识别位点 AvaII识别位点 AvrII识别位点 BaeI识别位点 BamHI识别位点 BanI识别位点 BanII识别位点 BbsI识别位点 BbvCI识别位点 BbvI识别位点 BccI识别位点 BceAI识别位点 BcgI识别位点 BciVI识别位点 BclI识别位点 BfaI识别位点 BfuAI识别位点 BglI识别位点 BglII识别位点
BlpI识别位点 Bme1580I识别位点BmgBI识别位点BmrI识别位点 BmtI识别位点BpmI识别位点 Bpu10I识别位点BpuEI识别位点BsaAI识别位点BsaBI识别位点BsaHI识别位点BsaI识别位点BsaJI识别位点BsaWI识别位点BsaXI识别位点BseRI识别位点BseYI识别位点 BsgI识别位点 BsiEI识别位点 BsiHKAI识别位点 BsiWI识别位点 BslI识别位点 BsmAI识别位点 BsmBI识别位点 BsmFI识别位点 BsmI识别位点 BsoBI识别位点 Bsp1286I识别位点 BspCNI识别位点 BspDI识别位点 BspEI识别位点 BspHI识别位点 BspMI识别位点 BspQI识别位点 BsrBI识别位点 BsrDI识别位点 BsrFI识别位点 BsrGI识别位点 BsrI识别位点 BssHII识别位点 BssKI识别位点 BssSI识别位点 BstAPI识别位点 BstBI识别位点 BstEII识别位点 BstNI识别位点 BstUI识别位点 BstXI识别位点
常用限制性内切酶酶切位点汇总
ApaI识别位点Acc65I识别位点 ApaLI识别位点AccI识别位点 ApeKI识别位点AciI识别位点 ApoI识别位点AclI识别位点 AscI识别位点AcuI识别位点 AseI识别位点AfeI识别位点 AsiSI识别位点AflII识别位点 AvaI识别位点AflIII识别位点 AvaII识别位点AgeI识别位点 AvrII识别位点AhdI识别位点 BaeI识别位点AleI识别位点 BamHI识别位点AluI识别位点 BanI识别位点AlwI识别位点 BanII识别位点AlwNI识别位点
BmrI识别位点BbvCI识别位点 BmtI识别位点BbvI识别位点 BpmI识别位点BccI识别位点 Bpu10I识别位点BceAI识别位点 BpuEI识别位点BcgI识别位点 BsaAI识别位点BciVI识别位点 BsaBI识别位点BclI识别位点 BsaHI识别位点BfaI识别位点 BsaI识别位点BfuAI识别位点 BsaJI识别位点BglI识别位点 BsaWI识别位点BglII识别位点 BsaXI识别位点BlpI识别位点 BseRI识别位点Bme1580I识别位点 BseYI识别位点BmgBI识别位点
BspMI识别位点BsiEI识别位点 BspQI识别位点BsiHKAI识别位点 BsrBI识别位点BsiWI识别位点 BsrDI识别位点BslI识别位点 BsrFI识别位点BsmAI识别位点 BsrGI识别位点BsmBI识别位点 BsrI识别位点BsmFI识别位点 BssHII识别位点BsmI识别位点 BssKI识别位点BsoBI识别位点 BssSI识别位点Bsp1286I识别位点 BstAPI识别位点BspCNI识别位点 BstBI识别位点BspDI识别位点 BstEII识别位点BspEI识别位点 BstNI识别位点BspHI识别位点
常见限制性内切酶识别序列(酶切位点)
The Type II restriction systems typically contain individual restriction enzymes and modification enzymes encoded by separate genes. The Type II restriction enzymes typically recognize specific DNA sequences and cleave at constant positions at or close to that sequence to produce 5-phosphates and 3-hydroxyls. Usually they require Mg 2+ ions as a cofactor, although some have more exotic requirements. The methyltransferases usually recognize the same sequence although some are more promiscuous. Three types of DNA methyltransferases have been found as part of Type II R-M systems forming either C5-methylcytosine, N4-methylcytosine or N6-methyladenine. ApaI (类型:Type II restriction enzyme )识别序列:5'GGGCC^C 3' BamHI(类型:Type II restriction enzyme )识别序列:5' G^GATCC 3' BglII (类型:Type II restriction enzyme )识别序列:5' A^GATCT 3' EcoRI (类型:Type II restriction enzyme )识别序列:5' G^AATTC 3' HindIII (类型:Type II restriction enzyme )识别序列:5' A^AGCTT 3' KpnI (类型:Type II restriction enzyme )识别序列:5' GGTAC^C 3' NcoI (类型:Type II restriction enzyme )识别序列:5' C^CATGG 3' NdeI (类型:Type II restriction enzyme )识别序列:5' CA^TATG 3' NheI (类型:Type II restriction enzyme )识别序列:5' G^CTAGC 3' NotI (类型:Type II restriction enzyme )识别序列:5' GC^GGCCGC 3' SacI (类型:Type II restriction enzyme )识别序列:5' GAGCT^C 3' SalI (类型:Type II restriction enzyme )识别序列:5' G^TCGAC 3' SphI (类型:Type II restriction enzyme )识别序列:5' GCATG^C 3' XbaI (类型:Type II restriction enzyme )识别序列:5' T^CTAGA 3' XhoI (类型:Type II restriction enzyme )识别序列:5' C^TCGAG 3' 当然,上面总结的这些肯定不全,要查找更多内切酶的识别序列,你还可以选择下面几种方法: 1. 查你所使用的内切酶的公司的目录或者网站;NEB网站上提供的识别序列图表下载 2. 用软件如:Primer Premier5.0或Bioedit等,这些软件均提供了内切酶识别序列的信息;
蛋白质序列分析
肽和蛋白质的直接测序法 目前,肽和蛋白质的测序有三种策略:①根据基因测序的结果,从cDNA演绎肽和蛋白质序列,这种策略简单、快捷,甚至可以得到未分离出的蛋白质或多肽的序列信息。但是,用这一策略得到的一级结构不含蛋白质翻译后修饰及二硫键位置等信息;②直接测序策略;③质谱测序与生物信息学搜索相结合的策略。第①种策略可参考分子生物学的有关专著,第③种策略将在本书蛋白质组与蛋白质组分析一章中介绍,本章介绍直接测序策略。 1953年,Frederick Sanger在对牛胰岛素的研究中首先提出氨基酸直接测序的概念,迄今为止,已通过直接测序阐明了几千种蛋白质的氨基酸序列。 在蛋白质序列测定中,因为可以得到的蛋白质样品十分有限,而且蛋白质包含的20种不同的氨基酸表现出不同的化学功能和化学活性,在测序过程中每一次变性或裂解所发生的一系列副反应,将使测定过程变得十分复杂,在蛋白质序列测定中由于没有类似于DNA序列测定中采用的PCR技术可应用,因此,与DNA 序列测定相比,蛋白质序列测定在许多方面要复杂得多。其基本的测序过程如下所述。 确定不同的多肽链数目 首先应该确定蛋白质中不同的多肽链数目,根据蛋白质N-端或C-端残基的摩尔数和蛋白质的相对分子质量可确定蛋白质分子中的多肽链数目。如果是单体蛋白质,蛋白质分子只含一条多肽链,则蛋白质的摩尔数应与末端残基的摩尔数相等;如果蛋白质分子是由多条多肽链组成,则末端残基的摩尔数是蛋白质的摩尔数的倍数。 肽链的裂解 当蛋白质分子是由二条或二条以上多肽链构成时,必须裂解这些多肽链。如果多肽链是通过非共价相互作用缔合的寡聚蛋白质,可采用8 mol L-1尿素,6 mo1 L-1盐酸胍或高浓度盐等变性剂处理,使寡聚蛋白质中的亚基裂解;如果多肽链之间是通过共价二硫键交联的,可采用氧化剂或还原剂断裂二硫键。然后再根据裂解后的单个多肽链的大小不同或电荷不同进行分离、纯化。 太长的多肽片段不能直接进行序列测定,一般肽片段长度不超过50个左右残基的肽段,当肽段超过这个长度时,由于反应的不完全以及副反应产生的杂质积累将影响测定结果,因此,必须通过特定的反应将它们裂解为更小的肽段。通过两种或几种不同的断裂方法(即断裂点不同)将每条多肽链样品降解成为两套或几套重叠的肽段或肽碎片,每套肽段分别进行分离、纯化,再对纯化后的每一肽段进行氨基酸组成和末端残基的分析。 使肽链中某些特殊位置上的肽键发生断裂,可采用化学反应或酶反应裂解产生若干能够进行测序的小片段。一般将蛋白质样品分为两等份,采用不同的试剂裂解产生两套不同的片段,两套片段在测序完成后,根据他们之间的重叠情况即可重新排序。 1 酶解法 蛋白质通过蛋白水解酶的裂解后将产生若干能够代表每个蛋白质特性的肽片段,用于特定的蛋白质裂解的蛋白水解酶包括外肽酶和内肽酶,裂解肽链的N-端或C-端的氨基酸可采用外肽酶,而内肽酶则用于切断肽链中某个特定部位。表10.5为常用的蛋白水解酶。 表10.5 用于蛋白质部分裂解的蛋白酶 蛋白酶酶切位点 内肽酶: 胰蛋白酶R n-1=Arg,Lys R n≠Pro 胃蛋白酶R n=Leu,Phe,Trp,Tyr,Val R n-1≠Pro 糜蛋白酶R n-1=Phe,Trp,Try R n≠Pro 内肽酶GluC R n-1=Glu
蛋白酶的分类及酶切位点
蛋白酶的分类及酶切位点
氨基酸0.ppt 氨基酸的名称与符号
alanine 丙氨酸Ala A arginine 精氨酸Arg R asparagine 天冬酰氨Asn Asx N aspartic acid 天冬氨酸Asp Asx D cysteine 半胱氨酸Cys C glutamine 谷氨酰胺Gln Glx Q glutamic acid 谷氨酸Glu Glx E glycine 甘氨酸Gly G histidine 组氨酸His H isoleucine 异亮氨酸Ile I leucine 亮氨酸Leu L lysine 赖氨酸Lys K methionine 甲硫氨酸Met M phenylalanine 苯丙氨酸Phe F proline 脯氨酸Pro P serine 丝氨酸Ser S threonine 苏氨酸Thr T tryptophan 色氨酸Trp W tyrosine 酪氨酸Tyr Y valine 缬氨酸Val V 血清终止胰酶消化的原理 血清终止的原理其实是竞争抑制。就是用过量的牛血清中含有的蛋白来和胰酶结合。不给胰
酶消化细胞蛋白的机会。 细胞传代时,血清为什么能终止胰酶消化? 胰蛋白酶的酶切位点是肽链的Lys和Arg两个残疾的羧基端肽键,血清的加入可使酶饱和,严格上说不是竞争性抑制,因为血清蛋白不是抑制剂,还是底物! 什么样的细胞不能用胰酶-EDTA消化 植物细胞不能用胰酶-EDTA消化,要用纤维素酶消化。 应该是肿瘤细胞吧。正常的细胞,貌似都需要用胰酶或者胶原酶消化。 EDTA-胰酶,只不过是在胰酶里加入了EDTA而已。 EDTA是乙二胺四乙酸,一种金属螯合剂。一般和胰蛋白酶配合使用。原因在于,钙,镁等金属离子会降低胰酶活力,故在使用胰酶消化液时要配合加入EDTA。它可以螯合这些离子,消除对胰酶的抑制。 干细胞饲养层制作中,胰酶—EDTA消化成纤维细胞(MEF)时,EDTA的作用是什么? 应该是胰酶分散细胞,EDTA鳌合金属离子使金属酶失活 《军医进修学院学报》1992年02期 加入收藏投稿 正常人血浆蛋白酶解产物对胃癌细胞肺转移抑制作用的研究 焦顺昌赵东海黄昌霞王洪海 【摘要】:本文采用胰凝乳蛋白酶和胃蛋白酶联合消化方法得到正常人血浆(NHP)有限蛋白酶解产物(NHP-EP)。体外研究发现,NHP的细胞粘附性可达90%;而NHP-EP的细胞粘附
常见限制性酶切位点
常见限制性内切酶识别序列(酶切位点)(BamHI、EcoRI、HindIII、NdeI、XhoI等)分子生物学实验室技术2009-11-17 17:46:32 阅读2235 评论2 字号:大中小订阅. 在分子克隆实验中,限制性内切酶是必不可少的工具酶。 无论是构建克隆载体还是表达载体,要根据载体选择合适的内切酶(当然,使用T载就不必考虑了)。先将引物设计好,然后添加酶切识别序列到引物5’端(英语怎么说?)。常用的内切酶比如BamHI、EcoRI、HindIII、NdeI、XhoI等可能你都已经记住了它们的识别序列,不过为了保险起见,还是得查证一下。 下面,我就总结了一些常用的内切酶的识别序列,仅供各位参考。下面这些内切酶都属于II型内切酶。 先介绍一下什么是II型内切酶吧。 The Type II restriction systems typically contain individual restriction enzymes and modification enzymes encoded by separate genes. The Type II restriction enzymes typically recognize specific DNA sequences and cleave at constant positions at or close to that sequence to produce 5-phosphates and 3-hydroxyls. Usually they require Mg 2+ ions as a cofactor, although some have more exotic requirements. The methyltransferases usually recognize the same sequence although some are more promiscuous. Three types of DNA methyltransferases have been found as part of Type II R-M systems forming either C5-methylcytosine, N4-methylcytosine or N6-methyladenine. ApaI (类型:Type II restriction enzyme )识别序列:5'GGGCC^C 3' BamHI(类型:Type II restriction enzyme )识别序列:5' G^GATCC 3' BglII (类型:Type II restriction enzyme )识别序列:5' A^GATCT 3' EcoRI (类型:Type II restriction enzyme )识别序列:5' G^AA TTC 3' HindIII (类型:Type II restriction enzyme )识别序列:5' A^AGCTT 3' KpnI (类型:Type II restriction enzyme )识别序列:5' GGTAC^C 3' NcoI (类型:Type II restriction enzyme )识别序列:5' C^CA TGG 3' NdeI (类型:Type II restriction enzyme )识别序列:5' CA^TATG 3' NheI (类型:Type II restriction enzyme )识别序列:5' G^CTAGC 3' NotI (类型:Type II restriction enzyme )识别序列:5' GC^GGCCGC 3' SacI (类型:Type II restriction enzyme )识别序列:5' GAGCT^C 3'