多因素方差分析

多因素方差分析
多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因
[例子]
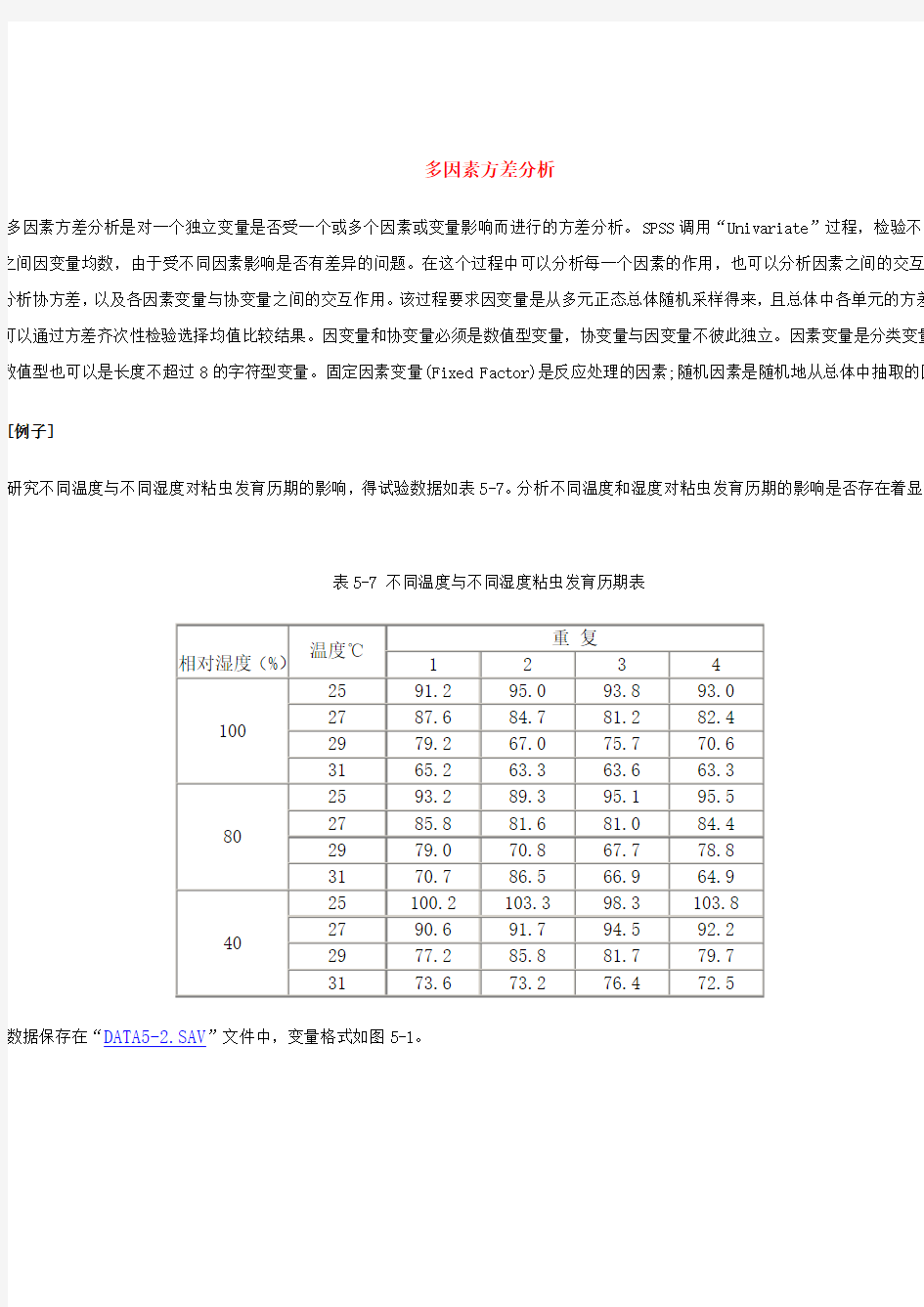
研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著
表5-7 不同温度与不同湿度粘虫发育历期表
数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。
1)准备分析数据
在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。
图5-6 数据输入格式
2)启动分析过程
点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因素方差分析设置窗口如图5-7。
图5-7 多因素方差分析窗口
3)设置分析变量
设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。
设置因素变量:在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量存容量的限制,选择的因素水平组合数(单元数)应该尽量少。
设置随机因素变量:在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量
设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到“Covariate(s)”框中。
设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。
4)选择分析模型
在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。
图5-8 “Univariate Model” 定义分析模型对话框
在Specify Model栏中,指定分析模型类型。
① Full Factorial选项
此项为系统默认的模型类型。该项选择建立全模型。全模型包括所有因素变量的主效应和所有的交互效应。例如有三个因素变量,括三个因素变量的主效应、两两的交互效应和三个因素的交互效应。选择该项后无需进行进一步的操作,即可单击“Continue”按钮话框。此项是系统缺省项。
② Custom选项
建立自定义的分析模型。选择了“Custom”后,原被屏蔽的“Factors & Covariates”、“Model”和“Build Term(s)”栏被激活ctors & Covariates”框中自动列出可以作为因素变量的变量名,其变量名后面的括号中标有字母“F”;和可以作为协变量的变量量名后面的括号中标有字母“C”。这些变量都是由用户在主对话框中定义过的。根据表中列出的变量名建立模型,其方法如下:Build Term(s)”栏右面的有一向下箭头按钮(下拉按钮),单击该按钮可以展开一小菜单,在下拉菜单中用鼠标单击某一项,下拉,选中的交互类型占据矩形框。有如下几项选择:
Interaction 选中此项可以指定任意的交互效应;
Main effects 选中此项可以指定主效应;
All 2-way 指定所有2维交互效应;
All 3-way 指定所有3维交互效应;
All 4-way 指定所有4维交互效应
All 5-way 指定所有5维交互效应。
③ 建立分析模型中的主效应:
在“Build Term(s)”栏用下拉按钮选中主效应“Main effects”。
在变量列表栏用鼠标键单击某一个单个的因素变量名,该变量名背景将改变颜色(一般变为蓝色),单击“Build Term(s)”栏中的右钮,该变量出现在“Model”框中。一个变量名占一行称为主效应项。欲在模型中包括几个主效应项,就进行几次如上的操作。也可“F”变量名中标记多个变量同时送到“Model”框中。
本例将“a”和“b”变量作为主效应,按上面的方法选送到“Model”框中。
④ 建立模型中的交互项
要求在分析模型中包括哪些变量的交互效应,可以通过如下的操作建立交互项。
例如,因素变量有“a(F)”和“b(F)”,建立它们之间的相互效应。
连续在“Factors &”框的变量表中单击“a(F)”和“b(F)”变量使其选中。
单击“Build Term(s)”栏内下拉按钮,选中交互效应“Interaction”项。
单击“Build Term(s)”栏内的右拉按钮,“a*b”交互效应就出现在“Model”框中,模型增加了一个交互效应项:a*b
⑤ Sum of squares 栏分解平方和的选择项
Type I项,分层处理平方和。仅对模型主效应之前的每项进行调整。一般适用于:平衡的AN0VA模型,在这个模型中一阶交互效应前指定主效应,二阶交互效应前指定一阶交互效应,依次类推;多项式回归模型。嵌套模型是指第一效应在第二
效应里,第二效应嵌套在第三效应里,嵌套的形式可使用语句指定。
Type II项,对其他所有效应进行调整。一般适用于:平衡的AN0VA模型、主因子效应模型、回归模型、嵌套设计。
Type III项,是系统默认的处理方法。对其他任何效应均进行调整。它的优势是把所估计剩余常量也考虑到单元频数中。对没有缺失单元格的不平衡模型也适用,一般适用于:Type I、Type II所列的模型:没有空单元格的平衡和不平型。
Type IV顶,没有缺失单元的设计使用此方法对任何效应F计算平方和。如果F不包含在其他效应里,Type IV = Type IIIl = TypeII。如果F包含在其他效应里,Type IV只对F的较高水平效应参数作对比。一般适用于:Type I、Type 所列模型;
没有空单元的平衡和不平衡模型。
⑥ Include intercept in model栏选项
系统默认选项。通常截距包括在模型中。如果能假设数据通过原点,可以不包括截距,即不选择此项。
5)选择比较方法
在主对话框中单击“Contrasts”按钮,打开“Contrasts”比较设置对话框,如图5-9所示。
如图5-9 Contrasts对比设置框
在“Factors”框中显示出所有在主对话框中选中的因素变量。因素变量名后的括号中是当前的比较方法。
① 选择因子
在“Factors”框中选择想要改变比较方法的因子,即鼠标单击选中的因子。这一操作使“Change Contrast”栏中的各项被激活。
② 选择比较方法
单击“Contrast”参数框中的向下箭头,展开比较方法表。用鼠标单击选中的对照方法。可供选择的对照方法有:
None,不进行均数比较。
Deviation,除被忽略的水平外,比较预测变量或因素变量的每个水平的效应。可以选择“Last”(最后一个水平)或
“First”(第一个水平)作为忽略的水平。
Simple,除了作为参考的水平外,对预测变量或因素变量的每一水平都与参考水平进行比较。选择“Last”或“First”作为参考水平。
Difference,对预测变量或因素每一水平的效应,除第一水平以外,都与其前面各水平的平均效应进行比较。与Helmert对照方法相反。
Helmert,对预测变量或因素的效应,除最后一个以外,都与后续的各水平的平均效应相比较。
Repeated,对相邻的水平进行比较。对预测变量或因素的效应,除第一水平以外,对每一水平都与它前面的水平进行比较。
Polynomial,多项式比较。第一级自由度包括线性效应与预测变量或因素水平的交叉。第二级包括二次效应等。各水平彼此
的间隔被假设是均匀的。
③ 修改比较方法
先按步骤①选中因子变量,再选比较方法,然后单击“Change”按钮,选中的(或改变的)比较方法显示在步骤①选中的因子变量后中。
④设置比较的参考类
在“Reference Category”栏比较的参考类有两个,只有选择了“Deviation”或“Simple”方法时才需要选择参考水平。共有两种择,最后一个水平“Last”选项和第一水平“First”项。系统默认的参考水平是“Last”。
6) 选择均值图
在主对话框中单击“Plot”按钮,打开“Profile Plots”对话框,如图5-10所示。在该对话框中设置均值轮廓图。
如图5-10 “Profile Plots”对话框
均值轮廓图(Profile Plots)用于比较边际均值。轮廓图是线图,图中每个点表明因变量在因素变量每个水平上的边际均值的估计值定了协变量,该均值则是经过协变量调整的均值。因变量做轮廓图的纵轴;一个因素变量做横轴。
做单因素方差分析时,轮廓图表明该因素各水平的因变量均值。
双因素方差分析时,指定一个因素做横轴变量,另一个因素变量的每个水平产生不同的线。如果是三因素方差分析,可以指定第三量,该因素每个水平产生一个轮廓图。双因素或多因素轮廓图中的相互平行的线表明在因素间无交互效应;不平行的线表明有交互效
Factors框中为因素变量列表。
Horlzontal Axis横坐标框,选择选择“Factors”框中一个因素变量做横坐标变量。被选的变量名反向显示,单击向右拉箭头按钮,将变量名送入相应的横坐标轴框中。
如果只想看该因素变量各水平的,因变量均值分布,单击“Add”按钮,将所选因素变量移入下面的“Pl 框中。否
则,不点击“Add”按钮,接着做下步。
Separate Lines分线框。如果想看两个因素变量组合的各单元格中因变量均值分布,或想看两个因变量间是否存在交互效应,选择“Factors”框中另一个因素变量,单击右拉按钮将变量名送入“Separate Lines”框中。单击“Add”按钮,将生成
的图形表达式送入到“Plots”栏中。分线框中的变量的每个水平将在图中是一条线。图形表达式是用“*”连接的两素变
量名。
Separate Plots分图框。如果在“Factors”栏中还有因素变量,可以按上述方法,将其送入“Separate Plot”框中,单击“Add”按钮,将自动生成的图形表达式送入到“Plots”栏中。图形表达式是用“*’连接的三个因素变量名。分图变每个
水平生成一张线图。
将图形表达式送到“Plots”框后发现有错误,单击选错的变量,单击“Remove”按钮,将其取消,再重新输入正确内容。
在检查无误后,按“Continue”按钮确认,返回到主对话框。如果取消做的设置单击“Cancel”按钮
7) 选择多重比较
在主对话框中单击“Post Hoc”选项,打开“Post Hoc Multiple Comparisons for Observed Means”对话框,从“Factor(s)”框,单击向右拉按钮,使被选变量进入“Post Hoc test for”框。本例子选择了“a”和“b”。
然后选择多重比较方法。在对话框中选择多重比较方法。本例子选择了“Duncan”和“Tamhane's T2”。
8)选择保存运算值
图5-11 Save对话框
在主对话框中,单击“Save”按钮,打开“Save”设置对话框,如图5-11所示。通过在对话框中的选择,可以将所计算的预测值、测值作为新的变量保存在编辑数据文件中。以便于在其他统计分析中使用这些值。
① Predicted Values 预测值
.Unstsndardized,非标准化预测值。
.Weighted,如果在主对话框中选择了WLS变量,选中该复选项,将保存加权非标准化预测值。
.Standard error,预测值标准误。
② Diagnostics 诊断值
.Cook’s distance,Cook 距离。
.Leverage values,非中心化 Leverage 值。
③ Residuals 残差
.Unstsndardized,非标准化残差值,观测值与预测值之差。
.Weighted,如果在主对话框中选择了WLS变量,选中该复选项,将保存加权非标准化残差。
.Standardized,标准化残差,又称Pearson残差。
.Studentized,学生化残差。
.Deleted,剔除残差,自变量值与校正预测值之差。
④ Save to New File 保存协方差矩阵
选中”Coefficient statistics”项,将参数协方差矩阵保存到一个新文件中。单击“File”按钮,打开相应的对话框将文件保存
9)选择输出项
在主对话框中单击“Options”按钮,打开“Options”输出设置对话框,见图5-12。
图5-12 “Options”输出设置对话框
① Estimated Marginal Means 估测边际均值设置
在“Factor(s) and Factor Interactions”框中列出“Model”对话框中指定的效应项,在该框中选定因素变量的各种效应项,单击右拉按钮就将其复制到“Display Means for”框中。选择主效应,则产生估计的边际均值表;选择二维交互效应产估计
边际均值表实际上是典型的单元格均值表。选择三维交互效应也是单元格均值表。
在“Display Means for”框中有主效应时激活此框下面的“Compare main effects”复选项,对主效应的边际均值进行组间的配对比较。
Confidence interval adjustment参数框,进行多重组间比较。打开下拉菜单,共有三个选项:
LSD(none)、Bonferroni、Sidak.。
② 在“Display”栏中指定要求输出的统计量
Descriptive statistics项,输出描述统计量:观测量的均值、标准差和每个单元格中的观测量数。
Estimates of effect size项,效应量估计。选择此项,给出η2(eta-Square)值。它反应了每个效应与每个参数估计值可以归因素的总变异的大小。
Observed power复选项,选中此项给出在假设是基于观测值时各种检验假设的功效。计算功效的显著性水平,系统默认的临界值是0.05。
Parameter estimates项。选择此项给出了各因素变量的模型参数估计、标准误、t检验的t值、显著性概率和95%的置信区间。
Contrast coefficient matrix项,显示协方差矩阵。
Homogeneity test项,方差齐次性检验。本例子选中该项。
Spread vs.level plot项,绘制观测量均值对标准差和观测量均值对方差的图形。
Residual plot项,绘制残差图。给出观测值、预测值散点图和观测量数目,观测量数目对标准化残差的散点图,加上正态和标准残差的正态概率图。
Lack of fit项,检查独立变量和非独立变量间的关系是否被充分描述。
General estimable function项,可以根据一般估计函数自定义假设检验。对比系数矩阵的行与一般估计函数是线性组合的。
③ Significance level 框设置
改变“Confidence intervals”框内多重比较的显著性水平。
10) 提交执行
设置完成后,在多因素方差分析窗口框中点击“OK”按钮,SPSS就会根据设置进行运算,并将结算结果输出到SPSS结果输出窗口中
11) 结果与分析主要输出结果:
结果分析:
方差不齐次性检验显著
表5-8 方差齐次性检验表明:方差不齐次性显著,p<0.05。
方差分析:
表5-9 主效应方差分析表:在表的左上方标明研究的对象是粘虫历期。
偏差来源和偏差平方和:
Source列是偏差的来源。其次列是“Type III Sum of Squares”偏差平方和。
Corrected Model校正模型,其偏差平方和等于两个主效应a、b平方和加上交互a*b的平方和之和。
Intercept截距。
a温度主效应,其偏差平方和反应的是不同温度造成对粘虫历期的差异。与b偏差平方相同均属于组间偏差平方和。
b 湿度主效应,其偏差平方和反应的是不同湿度计量造成的粘虫历期之差异。
a*b温度和湿度交互效应,其偏差平方和反应的是不同温度和湿度共同造成的粘虫历期的差异。
Error误差。其偏差平方和反应的是组内差异。也称组内偏差平方和。
Total是偏差平方和在数值上等于截距、主效应、次效应和误差偏差平方和之总和。
Corrected Total校正总和。其偏差平方和等于校正模型与误差之偏差平方和之总和。
df自由度
Mean Square 均方,数值上等于偏差平方和除以相应的自由度。
F值,是各效应项与误差项的均方之比值
Sig进行F检验的p值。p≤0.05,由此得出“温度”和“湿度”对因变量“粘虫历期”在0.05水平上是有显著性差异的。
根据方差分析表明:
不同温度(a)对粘虫历期的偏差均方是1575.434,F值为90.882,显著性水平是0.000,即p<0.05存在显著性差异;
不同湿度(b)对粘虫历期的偏差均方是322.000,F值为18.575,显著性水平是0.000,即p<0.05存在显著性差异;
不同温度和不同湿度(a*b)共同对粘虫历期的偏差均方是19.809,F值为1.143,显著性水平是0.358,即p>0.05存在不显著性差异。
多重比较
由于方差不齐次性,应选择方差不具有齐次性时的“Tamhane's T2”t检验进行配对比较。表5-10 多重比较表就是“温度”各水平mhane's T2”方法比较的结果。表中的各项说明参见表5-6(5.2.2节)。
温度25℃与27℃、29℃和31℃之间都有显著性差异;
温度27℃与25℃、29℃和31℃之间都有显著性差异;
温度29℃与26℃和27℃之间都有显著性差异;与31℃无显著性差异;
温度31℃与25℃和27℃之间都有显著性差异;与29℃无显著性差异。
不同湿度水平之间无显著性差异存在,这里没有列出多重比较表。
双因素方差分析
双因素方差分析 一、双因素方差分析的含义和类型 (一)双因素方差分析的含义和内容 在实际问题的研究中,有时需要考虑两个因素对实验结果的影响。例如上一节中饮料销售量的例子,除了关心饮料颜色之外,我们还想了解销售地区是否影响销售量,如果在不同的地区,销售量存在显著的差异,就需要分析原因,采用不同的推销策略,使该饮料品牌在市场占有率高的地区继续深入人心,保持领先地位,在市场占有率低的地区,进一步扩大宣传,让更多的消费者了解,接受该产品。 在方差分析中,若把饮料的颜色看作影响销售量的因素A,饮料的销售地区看作影响因素B。同时对因素A和因素B进行分析,就称为双因素方差分析。 双因素方差分析的内容包括:对影响因素进行检验,究竟一个因素在起作用,还是两个因素都起作用,或是两个因素的影响都不显著。 双因素方差分析的前提假定:采样地随机性,样本的独立性,分布的正态性,残差方差的一致性。 (二)双因素方差分析的类型 双因素方差分析有两种类型:一个是无交互作用的双因素方差分析,它假定因素A 和因素B的效应之间是相互独立的,不存在相互关系;另一个是有交互作用的双因素方差分析,它假定因素A和因素B的结合会产生出一种新的效应。例如,若假定不同地区的消费者对某种品牌有与其他地区消费者不同的特殊偏爱,这就是两个因素结合后产生的新效应,属于有交互作用的背景;否则,就是无交互作用的背景。有交互作用的双因素方差分析已超出本书的范围,这里介绍无交互作用的双因素方差分析。 1.无交互作用的双因素方差分析。 无交互作用的双因素方差分析是假定因素A和因素B的效应之间是相互独立的,不存在相互关系; 2.有交互作用的双因素方差分析。 有交互作用的双因素方差分析是假定因素A和因素B的结合会产生出一种新的效应。例如,若假定不同地区的消费者对某种颜色有与其他地区消费者不同的特殊偏爱,
单因素方差分析和多因素方差分析简单实例
单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。 问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度”上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示 图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。
图6-67 方差分析对话框 (3)分析结果如下: 因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。 多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。
SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作 者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮
最新53双因素方差分析汇总
53双因素方差分析
§5.3 双因素方差分析 I 无交互作用的双因素方差分析 (1) 数学模型 现在考虑影响试验指标的因素有两个:A, B 。因素A 有水平r 个;有水平s 个;因素A, B 的各种组合水平均只作一次试验;两因素之间无交互作用。 数据结构表 假设:(1*) {:1;1}ij Y i r j s ≤≤≤≤独立; (2*) 2~(,)ij ij Y N μσ,即具有相同的方差; (3*) ij ij ij Y e μ=+,其中 2~(0,)ij e N σ,且{}ij e 独立; 数学模型: ij i j ij ij Y e μαβγ=++++ , 其中:111()r s ij i j rs μμ-===∑∑—总平均值; 11s i ij j s μμ-?==∑; 11r j ij i r μμ-?==∑; i i αμμ?=-—因素A 在水平Ai 下对试验指标的效应值; j j βμμ?=-—因素 B 在水平Bj 下对试验指标的效应值; 10r i i α==∑; 10s j j β==∑; ij ij i i γμμαβ=---—因素A, B 的交互效应值; 因素B s B r A 12r r rs Y Y Y r Y ? 12 ..s Y Y Y ???
{}ij e —随机部分,假定:独立同正态分布; 注: “无交互作用”等价于:0ij γ=,即 ij i i μμαβ=++; (2) 方差分析 (i) 假设检验问题 两种因素分别进行检验: 0112:0r H ααα== == 即因素A 对试验指标影响不显著; 0212:0s H βββ== == 即因素B 对试验指标影响不显著; 注:当01H 和02H 成立时, ,(1;1)ij i r j s μμ=≤≤≤≤. (ii) 构造F-统计量及否定域 设 () 1 11r s ij i j Y rs Y -===∑∑ ; 11s i ij j Y s Y -?==∑; 11r j ij i Y r Y -?==∑; 2211()r s T ij i j S Y Y ===-∑∑; 221()r A i i S s Y Y ?==-∑; 221()s B j j S r Y Y ?==-∑; 2211()r s E ij i j i j S Y Y Y Y ??===--+∑∑; 注:注意, 2 211()r s E ij i j i j S Y Y Y Y ??===--+∑∑ 2 11()r s ij ij i i j j i j e e e e μμμμ????===+----++∑∑
多因素方差分析
多因素方差分析 1. 基本思想:用来研究两个及两个以上控制变量是否对观测变量产生显著影响。可以分析多个控制变量单独作用对观测变量的影响(这叫做主效应),也可以分析多个控制因素的交互作用对观测变量的影响(也称交互效应),还可以考虑其他随机变量是否对结果产生影响,进而最终找到利于观测变量的最优组合。 根据观测变量(即因变量)的数目,可以把多因素方差分析分为:单变量多因素方差分析(也叫一元多因素方差分析) 与多变量多因素方差分析(即多元多因素方差分析)。 一元多因素方差分析:只有一个因变量,考察多个自变量对该因变量的影响。例如,分析不同品种、不同施肥量对农作物产 量的影响时,可将农作物产量作为观测变量,品种和施肥量作为控制变量。利用多因素方差分析方法,研究不同品种、不同施肥量是如何影响农作物产量的,并进一步研究哪种品种与哪种水平的施肥量是提高农作物产量的最优组合。 多元多因素方差分析:是对一元多因素方差分析的扩展,不仅需要检验自变量的不同水平上,因变量的均值是否存在差异,而且要检验各因变量之间的均值是否存在差异。例如,用四个班级学生分别对两种教材、两种教学方法进行试验,除了要考虑着两种教材、两种教学方法的四种搭配以外,还要考虑四个班级学生的学习能力这些因素。 2. 原理:通过计算F统计量,进行F检验。F统计量是平均组间平方和与平均组内平方和的比。 尸$控制您童H 卜尸6小=的机竇量 这里,把总的影响平方和记为SST它分为两个部分,一部分是由控制变量引起的离差,记为SSA组间离差平方和),另一部分是由随机变量引起的SS(组内离差平方和)。即SST=SSA+SS组间离差平方和SSA是各水平均值和总体均值离差的平方和,反映了控制变量的影响。组内离差平方和是每个数据与本水平组平均值离差的平方和,反映了数据抽样误差的大小程度。 通过F值看出,如果控制变量的不同水平对观测变量有显著影响,那观测变量的组间离差平方和就大,F值也大;相反, 如果控制变量的不同水平没有对观测变量造成显著影响,那组内离差平方和就比较大,F值就比较小。 同时,SPSS还会依据F分布表给出相应的相伴概率值sig。如果sig小于显著性水平(一般显著性水平设为0.05、0.01、或者 0.001 ),则认为控制变量不同水平下各总体均值有显著差异,反之,则不然。一般地,F值越大,则sig值越小。 3. 具体实现步骤: 我们现在有一个公司员工的工资表,想看一下员工性别“gender”与接受教育年限“ edu”这两个控制变量对员工“当 前工资"的影响。采用多因素方差分析法,则要分别考虑“gender”、"edu"对"当前工资”的影响,称为主效应,还要考虑“gender*edu” 对“当前工资”的影响,称为交互效应。 ⑴将数据导入SPSS后,选择:分析->一般线性模型->单变量
多因素方差分析
多因素方差分析 多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著 表5-7 不同温度与不同湿度粘虫发育历期表 数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。
1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因素方差分析设置窗口如图5-7。
图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。 设置因素变量:在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量存容量的限制,选择的因素水平组合数(单元数)应该尽量少。 设置随机因素变量:在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量 设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到“Covariate(s)”框中。 设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。 4)选择分析模型 在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。 图5-8 “Univariate Model” 定义分析模型对话框
SPSS-单因素方差分析(ANOVA)-案例解析资料讲解
SPSS- 单因素方差分析( ANOVA) - 案例解 析
SPSS单因素方差分析(ANOVA)案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近习SPSS单因素方差分析(ANOVA分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠b代表雌性老鼠0代表死亡1代表着tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”一一比较均值-------- 单因素AVOVA,如下所示:
从上图可以看出,只有“两个变量”可选,对于“组别(性别)”变量不可选, 进行“转换”对数据重新进行编码, 点击“转换”一“重新编码为不同变量”将a,b"分别用8,9进行替换,得到如下结果”这里可能需
此时的8代表a(雄性老鼠)9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示:
“勾选“将定方差齐性”下面的项 点击继续 LSD选项,和“未假定方差齐性”下面的Tamhane's T2 选点击“选项”按钮,如下所示: I固疋和随枫效果(号 IN有建同備性檯验迥) 匚旦rown-Forsythe(B) El Welches} 姑朱値 ?按分析顺序排麒个案? 「I I S3 Affifi 勾选“描述性”和“方差同质检验”以及均值图等选项,得到如下结果:
多因素方差分析讲解
多因素方差分析 定义: 多因素方差分析中的控制变量在两个或两个以上,研究目的是要分析多个控制变量的作用、多个控制变量的交互作用以及其他随机变量是否对结果产生了显著影响。 前提: 1总体正态分布。当有证据表明总体分布不是正态分布时,可以将数据做正态转化。 2变异的相互独立性。 3各实验处理内的方差要一致。进行方差分析时,各实验组内部的方差批次无显著差异,这是最重要的一个假定,为满足这个假定,在做方差分析前要对各组内方差作齐性检验。 多因素方差分析的三种情况: 只考虑主效应,不考虑交互效应及协变量; 考虑主效应和交互效应,但不考虑协变量; 考虑主效应、交互效应和协变量。 一、多因素方差分析 1选择分析方法 本题要判断控制变量“组别”和“性别”是否对观察变量“数学”有显著性影响,而控制变量只有两个,即“组别”、“性别”,所以本题采用双因素分析法,但需要进行正态检验和方差齐性检验。 2建立数据文件 在SPSS17.0中建立数据文件,定义4个变量:“人名”、“数学”、“组别”、“性别”。控制变量为“组别”、“性别”,观察变量为“数学”。在数据视图输入数据,得到如下数据文件: 3正态检验(P>0.05,服从正态分布) 正态检验操作过程: “分析”→“描述统计”→“探索”,出现“探索”窗口,将因变量“成绩”放入“因变量列表”,将自变量“组别”、“性别”放入“因子列表”,将“人名”放入“标注个案”; 点击“绘制”,出现“探索:图”窗口,选中“直方图”和“带检验的正态图”,点击“继续”;点击“探索”窗口的“确定”,输出结果。 因变量是用户所研究的目标变量。因子变量是影响因变量的因素,例如分组变量。标注个案是区分每个观测量的变量。 带检验的正态图(Normality plots with test,复选框):选择此项,将进行正态性检验,并生成正态Q-Q概率图和无趋势正态Q-Q概率图。
第一节方差分析原理.doc
第一节方差分析原理 一、方差分析基本思想 方差分析( analysis of variance ,或缩写 ANOVA )又称变异数分析,是一种应用非常广 泛的统计方法。其主要功能是检验两个或多个样本平均数的差异是否有统计学意义,用以推断它们的总体均值是否相同。它是真正用来进行上述“多组比较”问题的正确方法,从这个意 义上说,它可看成是t 检验等“两组比较法”的推广。理解方差分析的原理,主要在于其基本思想,而不在于数学推导。 以单因素完全随机化实验设计为例(这是最简单的多组实验设计)介绍方差分析的原理。注意下面列出的该种设计的数学模式,假设有 k 个处理,每个处理下有n 个被试,一共有nk 个被试。 K 个处理下的数据构成比较中的k 个组或 k 个样本。 理T 1 T 2 ?T j ?T k X 11 X 12 ?X 1j ?X 1k X 21 X 22 ?X 2j ?X 2k 各?????? 数据X i1 X i2 ?X ij ?X ik ?????? X n1 X n2 ?X nj ?X nk 不失一般地,其对应的图示如下:
根据测量学中的真分数理论,观测值等于真值和误差之和;据此,对照上面的数据可得到下面的数学模型: 其中: X ij 指第 j 个处理下的第 i 个被试的实验数据; μ 指总体均值;在图中样本数据中,即红色线表示的总平均; μ 指第 j 个处理的均值; j τ 称为第 j 个处理的效应;通常,τj=μj–μ,也即各组均值偏离总平均的离差; j ε ij 为随机误差( idd 表示误差独立同分布);在该模型中,误差就是各组中数据偏离 其组均值的离差。因为根据单因素完全随机化设计的特点,同组中的被试,其各方面条件都相同,接受的处理也相同,其观测值间的差异只能归结为随机误差。 首先对检验的零假设进行变换: 下面我们就需要构造一个统计量使得它在Ho"下无未知量且有精确的分布,以进行假设2 检验。由于τj是每个处理的平均数与总平均之差,所以我们考虑从数据的离均差的平方 入手来构造统计量: 对每个观测数据: 即:任意一个数据与总平均数的离差= 该数与所在组平均数的离差+ 所在组的平均数与总平均数的离差。 我们针对第j 组中每个数据的上述分解式的平方求和得:
实验 10 双因素方差分析
实验10 双因素方差分析 双因素方差分析是对样本观察值的差异进行分解,将两种因素下各组样本观察值之间可能存在的系统误差加以比较,据此推断总体之间是否存在显著性差异,根据两因素是否相互影响,双因素分析分为不存在交互作用的双因素方差分析和存在交互作用的双因素方差分析。 10.1 实验目的 掌握使用SAS进行双因素方差分析的方法。 10.2 实验内容 一、用INSIGHT作双因素方差分析 二、用“分析家”作双因素方差分析 三、用glm过程作双因素方差分析 10.3 实验指导 一、用INSIGHT作双因素方差分析 【实验10-1】工厂订单的多少直接反映了工厂生产的产品的畅销程度,因此工厂订单数目的增减是经营者所关心的。经营者为了研究产品的外形设计及销售地区对月订单数目的影响,记录了一个月中不同外形设计的该类产品在不同地区的订单数据如表10-1(sy10_1.xls)所示。试用双因子方差分析检验该产品的外形设计与销售地区是否对订单的数量有所影响。 表10-1 不同外形设计的产品在不同地区的订单数据 销售地区设计1 设计2 设计3 地区1 700 450 560 地区2 597 357 420 地区3 697 552 720 地区4 543 302 515 该问题即检验如下假设: H0A:不同的设计对订单数量无影响,H1A:不同的设计对订单数量有显著影响 H0B:不同地区对订单数量无影响,H1B:不同地区对订单数量有显著影响 具体步骤如下:
1. 生成数据集 将表10-1在Excel 中整理后导入成如图10-1左所示结构的数据集,存放在Mylib.sy10_1中,其中变量a 、b 、y 分别表示销售地区、外形设计、销售量。 图10-1 数据集mylib.sy10_1与分析变量的选择 2. 方差分析 在INSIGHT 模块中打开数据集Mylib.sy10_1。 选择菜单“Analyze (分析)”→“Fit (拟合)”,在打开的“Fit(X Y)”对话框中选择数值型变量作因变量,分类型变量作自变量:选择变量y ,单击“Y ”按钮,选择变量a 和b ,单击“X ”按钮,分别将变量移到列表框中,如图10-1右所示。 单击“OK ”按钮,得到分析结果。 3. 结果分析 结果中表的含义与单因素方差分析相应的表的含义是类似的: (1) 第一张表提供了模型的一般信息;第二张表列举了作为分类变量的a 和b 的水平的信息;第三张参数信息表给出了标识变量P_i 的定义。 图10-2 多因素方差分析第1、2、3张表 其中,标识变量取值: ,其他类似。,其他,设计,,其他类似;,其他,地区,""? ??==???==01b 1P_601a 1P_2 (2) 第四张表给出了方差分析模型,利用参数信息表中标识变量P_i 的定义可以推算出在各个因素不同水平下变量y 均值的信息:
单因素方差分析和多因素方差分析简单实例 (1)
百度文库- 让每个人平等地提升自我 单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。 问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度”上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示 图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。 图6-67 方差分析对话框 (3)分析结果如下: 因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。 多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作 者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮 图6-69 单变量多因素方差分析主对话框 (3)分析结果如下: 因此,可以认为机器类型和操作者的影响均是显著的。 1
多因素方差分析资料讲解
多因素方差分析 是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同水平组合之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作用,以及分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差相同。但也可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量,可以是数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因素。 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。 表5-7 不同温度与不同湿度粘虫发育历期表
1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输入对应的数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因变量多因素方差分析设置窗口如图5-7。 图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。
单因素方差分析完整实例知识讲解
单因素方差分析完整 实例
什么是单因素方差分析 单因素方差分析是指对单因素试验结果进行分析,检验因素对试验结果有无显著性影响的方法。 单因素方差分析是两个样本平均数比较的引伸,它是用来检验多个平均数之间的差异,从而确定因素对试验结果有无显著性影响的一种统计方法。 单因素方差分析相关概念 ●因素:影响研究对象的某一指标、变量。 ●水平:因素变化的各种状态或因素变化所分的等级或组别。 ●单因素试验:考虑的因素只有一个的试验叫单因素试验。 单因素方差分析示例[1] 例如,将抗生素注入人体会产生抗生素与血浆蛋白质结合的现象,以致减少了药效。下表列出了5种常用的抗生素注入到牛的体内时,抗生素与血浆蛋白质结合的百分比。现需要在显著性水平α = 0.05下检验这些百分比的均值有无显著的差异。设各总体服从正态分布,且方差相同。
在这里,试验的指标是抗生素与血浆蛋白质结合的百分比,抗生素为因素,不同的5种抗生素就是这个因素的五个不同的水平。假定除抗生素这一因素外,其余的一切条件都相同。这就是单因素试验。试验的目的是要考察这些抗生素与血浆蛋白质结合的百分比的均值有无显著的差异。即考察抗生素这一因素对这些百分比有无显著影响。这就是一个典型的单因素试验的方差分析问题。 单因素方差分析的基本理论[1] 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。
在上例中,因素A(即抗生素)有s(=5)个水平,在每一个水平 下进行了n j = 4次独立试验,得到如上表所示的结果。这些结果是一个随机变量。表中的数据可以看成来自s个不同总体(每个水平对应一个总体)的样本值,将各个总体的均值依次记为,则按题意需检验假设 不全相等 为了便于讨论,现在引入总平均μ 其中: 再引入水平A j的效应δj 显然有,δj表示水平A j下的总体平均值与总平均的差异。 利用这些记号,本例的假设就等价于假设 不全为零 因此,单因素方差分析的任务就是检验s个总体的均值μj是否相等,也就等价于检验各水平A j的效应δj是否都等于零。 2. 检验所需的统计量 假设各总体服从正态分布,且方差相同,即假定各个水平下的样本来自正态总体N(μj,σ2),μj与σ2未知,且设不同水平A j下的样本
SPSS多因素方差分析
体育统计与SPSS读书笔记(八)—多因素方差分析(1) 具有两个或两个以上因素的方差分析称为多因素方差分析。 多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。 下面用例子的形式来说说多因素方差分析的运用。还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级和不同教学法班级双因素。 分析: 1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据), 年级 不同教学方法的班级 定性班 定量班 定性定量班 五年级 (班级每个人) (班级每个人) (班级每个人) 初中二年级 (班级每个人) (班级每个人) (班级每个人) 高中二年级 (班级每个人) (班级每个人) (班级每个人) 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里假设他们之间有交互作用。
最新单因素方差分析和多因素方差分析简单实例
单因素方差分析和多因素方差分析简单实 例
单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第 三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度” 上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示
图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。 图6-67 方差分析对话框 (3)分析结果如下:
因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。 SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作
者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、 5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如 图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框, 再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮
spss多因素方差分析例子
1, data0806-height 是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及 八种草之间有无差异?具体怎么差异的? 打 开 spss 软 件 , 打 开 data0806-height 数 据 , 点 击 Analyze->General Linear Model->Univariate 打开: 把 plot 和 species 送入 Fixed Factor(s) ,把 height 送入 Dependent Variable ,点击 Model 打开: 选择 Full factorial , Type III Sum of squares , Include intercept in model (即 全部默认选项) ,点击 Continue 回到 Univariate 主对话框,对其他选项卡不做任何选 择, 结果输出: 因无法计算 ???? ??rror ,即无法分开 ???? intercept 的影响,无法进行方差分析, 重新 Analyze->General Linear Model->Univariate 打开: 选择好 Dependent Variable 和 Fixed Factor(s) 点击Custom,把主效应变量 species 和plot 送入 Model 框,点击 Continue 回到Univariate 主对话框,点击 Plots : 把 date 送入 Horizontal Axis ,把 depth 送入 Separate Lines ,点击 Add ,点击 Continue 回到 Univariate 对话框,点击 Options : 把 OVERALL,species, plot 送入 Display Means for 框,选择 Compare main effects , Bonferroni ,点击 Continue 回到 Univariate 对话框, 输出结果: 可以看到: SS species =, df species =7, MS species= ;SS plot =, df plot =7, MS plot= ;SS error =, df error =14, MS error= ; Fspecies= , p=<;Fplot=,p=<; 所以故认为在 5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。 该表说明: SSspecies= ,dfspecies=7 ,MSspecies= ;SSerror= ,dferror=14 ,MSerror= ; Fspecies= , p=<; 物种间存在差异: SSplot= , dfplot=7 , MSplot= ; SSerror= , dferror=14 , MSerror= ; Fplot=,p=<; 不同的物种间在差异: 由边际分布图可知:类似结论:草的高度在不同样地的条件之间有差异( Fplot=,p=< ),具 体是,样地一和样地三之间存在的差异最大;八种不同草的高度也存在差异( Fspecies= , p=<),具体是第四 和 ???? error ,无法检测 interaction ,点击 Model 打开:
单因素方差分析完整实例(精编文档).doc
【最新整理,下载后即可编辑】 什么是单因素方差分析 单因素方差分析是指对单因素试验结果进行分析,检验因素对试验结果有无显著性影响的方法。 单因素方差分析是两个样本平均数比较的引伸,它是用来检验多个平均数之间的差异,从而确定因素对试验结果有无显著性影响的一种统计方法。 单因素方差分析相关概念 ●因素:影响研究对象的某一指标、变量。 ●水平:因素变化的各种状态或因素变化所分的等级或组别。 ●单因素试验:考虑的因素只有一个的试验叫单因素试验。 单因素方差分析示例[1] 例如,将抗生素注入人体会产生抗生素与血浆蛋白质结合的现象,以致减少了药效。下表列出了5种常用的抗生素注入到牛的体内时,抗生素与血浆蛋白质结合的百分比。现需要在显著性水平α = 0.05下检验
这些百分比的均值有无显著的差异。设各总体服从正态分布,且方差相同。 在这里,试验的指标是抗生素与血浆蛋白质结合的百分比,抗生素为因素,不同的5种抗生素就是这个因素的五个不同的水平。假定除抗
生素这一因素外,其余的一切条件都相同。这就是单因素试验。试验的目的是要考察这些抗生素与血浆蛋白质结合的百分比的均值有无显著的差异。即考察抗生素这一因素对这些百分比有无显著影响。这就是一个典型的单因素试验的方差分析问题。 单因素方差分析的基本理论[1] 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。 在上例中,因素A(即抗生素)有s(=5)个水平,在每一个水平下进行了n j = 4次独立试验,得到如上表所示的结果。这些结果是一个随机变量。表中的数据可以看成来自s 个不同总体(每个水平对应一个总体)的样本值,将各个总体的均值依次记为,则按题意需检验假设 不全相等 为了便于讨论,现在引入总平均μ
多因素方差分析
多因素方差分析 实验目的:通过本次试验理解多因素方差分析的概念和思想,理解多个 因素存在交互效应的统计学含义和实际含义,了解方差分析分解的理论基础和计算原理,能够熟练应用单因素方差分析对具体的实际问题进行有效的分析。 实验内容:研究不同温度与不同湿度对粘虫发育历期的影响,分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。数据来源于网上搜索。 实验步骤: ①选择File/Open/Data命令,打开数据表。 ②选择Analyze/General Linear Model /Unievariate…命令,弹出(单变量方差分析)对话框,如图,在左侧变量框中选择“历期”变量为Dependent Vaiable (因变量)变量框,选择“温度”、“湿度”为Fixed Factors(固定因素)变量框,把重复选入Random Factors变量框。
③单击Model…按钮,弹出Univariate:Model(单变量方差分析:模型)对话框,如图所示:
弹出Univariate:Contrasts (单变量方差分析:对比)对话框: ⑤单击Continue按钮,回到方差分析对话框,单击Plots…,弹出Univariate:Plots(单变量方差分析:轮廓图)对话框:
Univariate:Post Hoc…(单变量方差分析:观察值的验后多重比较)对话框:这里不作选择
⑦单击Continue按钮,回到方差分析对话框,单击Save…,弹出Univariate:Save(单变量方差分析:保存)对话框:
⑧单击Continue按钮,回到方差分析对话框,单击Options…,弹出Univariate:Options(单变量方差分析:选项)对话框: 实验结论:
SPSS多因素方差分析
体育统计与SPSS读书笔记(八)—多因素方差分析(1) 具有两个或两个以上因素的方差分析称为多因素方差分析。 多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的 时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个 时间的因素。如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。 下面用例子的形式来说说多因素方差分析的运用。还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级和不同教学法班级双因素。 分析: 1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据), 年级 不同教学方法的班级 定性班 定量班 定性定量班 五年级 (班级每个人) (班级每个人) (班级每个人) 初中二年级 (班级每个人) (班级每个人) (班级每个人) 高中二年级 (班级每个人) (班级每个人) (班级每个人) 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里假设他们之间有交互作用。
单因素方差分析完整实例
什么是单因素方差分析 令狐采学 单因素方差分析是指对单因素试验结果进行分析,检验因素对试验结果有无显著性影响的方法。 单因素方差分析是两个样本平均数比较的引伸,它是用来检验多个平均数之间的差异,从而确定因素对试验结果有无显著性影响的一种统计方法。 单因素方差分析相关概念 ●因素:影响研究对象的某一指标、变量。 ●水平:因素变化的各种状态或因素变化所分的等级或组 别。 ●单因素试验:考虑的因素只有一个的试验叫单因素试验。单因素方差分析示例[1] 例如,将抗生素注入人体会产生抗生素与血浆蛋白质结合的现象,以致减少了药效。下表列出了5种常用的抗生素注入到牛的体内时,抗生素与血浆蛋白质结合的百分比。现需要在显著性
水平α = 0.05下检验这些百分比的均值有无显著的差异。设各总体服从正态分布,且方差相同。 在这里,试验的指标是抗生素与血浆蛋白质结合的百分比,抗生素为因素,不同的5种抗生素就是这个因素的五个不同的水平。假定除抗生素这一因素外,其余的一切条件都相同。这就是单因素试验。试验的目的是要考察这些抗生素与血浆蛋白质结合的百分比的均值有无显著的差异。即考察抗生素这一因素对这些百分比有无显著影响。这就是一个典型的单因素试验的方差分析问题。
单因素方差分析的基本理论[1] 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。 在上例中,因素A(即抗生素)有s(=5)个水平 ,在每一个水平下进行了nj = 4次独立试验,得到如上表所示的结果。这些结果是一个随机变量。表中的数据可以看成来自s个不同总体(每个水平对应一个总体)的样本值,将各个总体的均值依次记为,则按题意需检验假设 不全相等 为了便于讨论,现在引入总平均μ 其中: 再引入水平Aj的效应δj 显然有,δj表示水平Aj下的总体平均值与总平均的差异。 利用这些记号,本例的假设就等价于假设