基于Kinect的三维重建
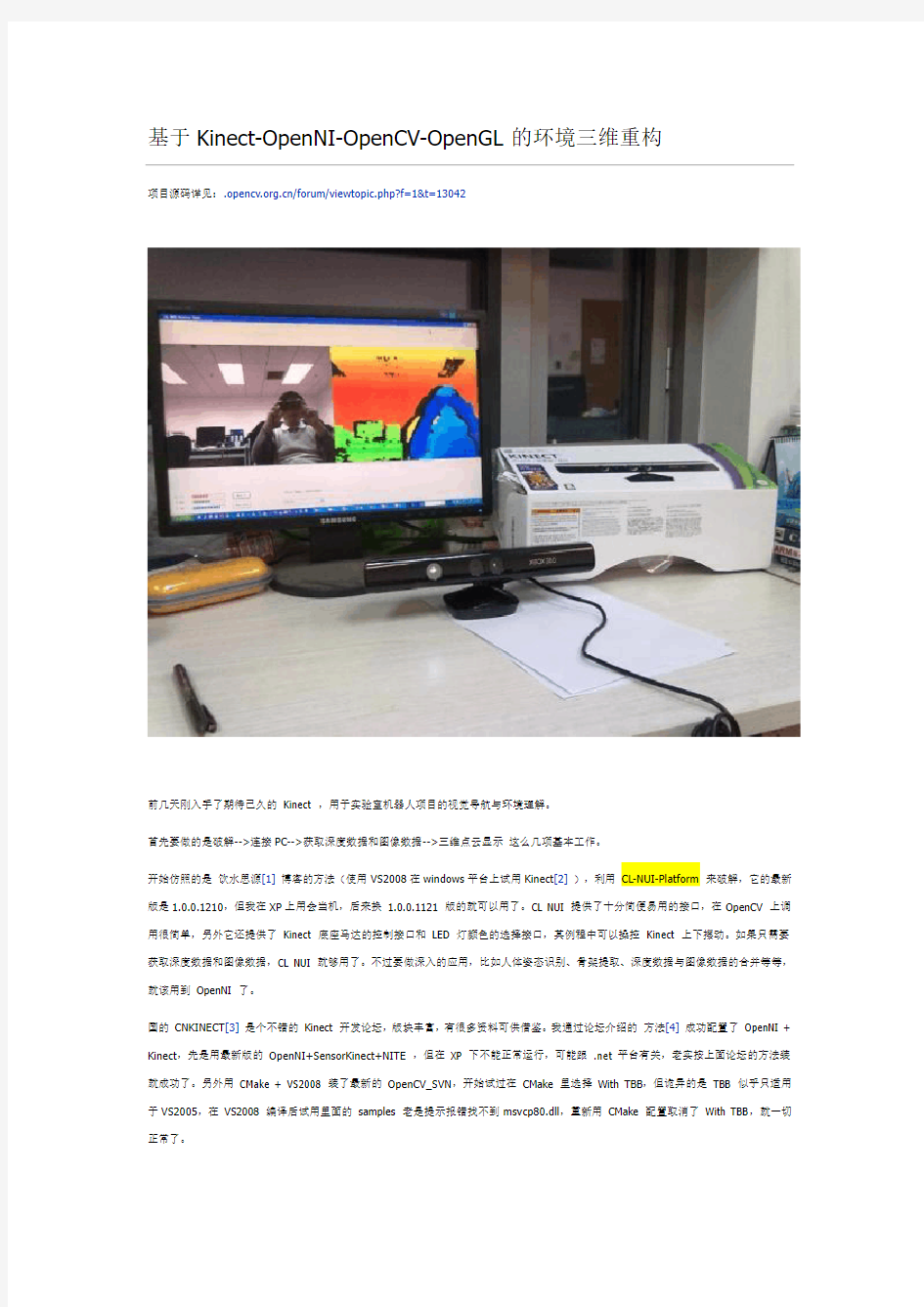
基于Kinect-OpenNI-OpenCV-OpenGL的环境三维重构
项目源码详见:https://www.360docs.net/doc/166843785.html,/forum/viewtopic.php?f=1&t=13042
前几天刚入手了期待已久的Kinect ,用于实验室机器人项目的视觉导航与环境理解。
首先要做的是破解-->连接PC-->获取深度数据和图像数据-->三维点云显示这么几项基本工作。
开始仿照的是饮水思源[1]博客的方法(使用VS2008在windows平台上试用Kinect[2]),利用CL-NUI-Platform 来破解,它的最新版是1.0.0.1210,但我在XP上用会当机,后来换 1.0.0.1121 版的就可以用了。CL NUI 提供了十分简便易用的接口,在OpenCV 上调用很简单,另外它还提供了Kinect 底座马达的控制接口和LED 灯颜色的选择接口,其例程中可以操控Kinect 上下摆动。如果只需要获取深度数据和图像数据,CL NUI 就够用了。不过要做深入的应用,比如人体姿态识别、骨架提取、深度数据与图像数据的合并等等,就该用到OpenNI 了。
国的CNKINECT[3]是个不错的Kinect 开发论坛,版块丰富,有很多资料可供借鉴。我通过论坛介绍的方法[4]成功配置了OpenNI + Kinect,先是用最新版的OpenNI+SensorKinect+NITE ,但在XP 下不能正常运行,可能跟 .net 平台有关,老实按上面论坛的方法装就成功了。另外用CMake + VS2008 装了最新的OpenCV_SVN,开始试过在CMake 里选择With TBB,但诡异的是TBB 似乎只适用于VS2005,在VS2008 编译后试用里面的samples 老是提示报错找不到msvcp80.dll,重新用CMake 配置取消了With TBB,就一切正常了。
[编辑]
一、深度摄像机的视角调整与深度/彩色图像的合并
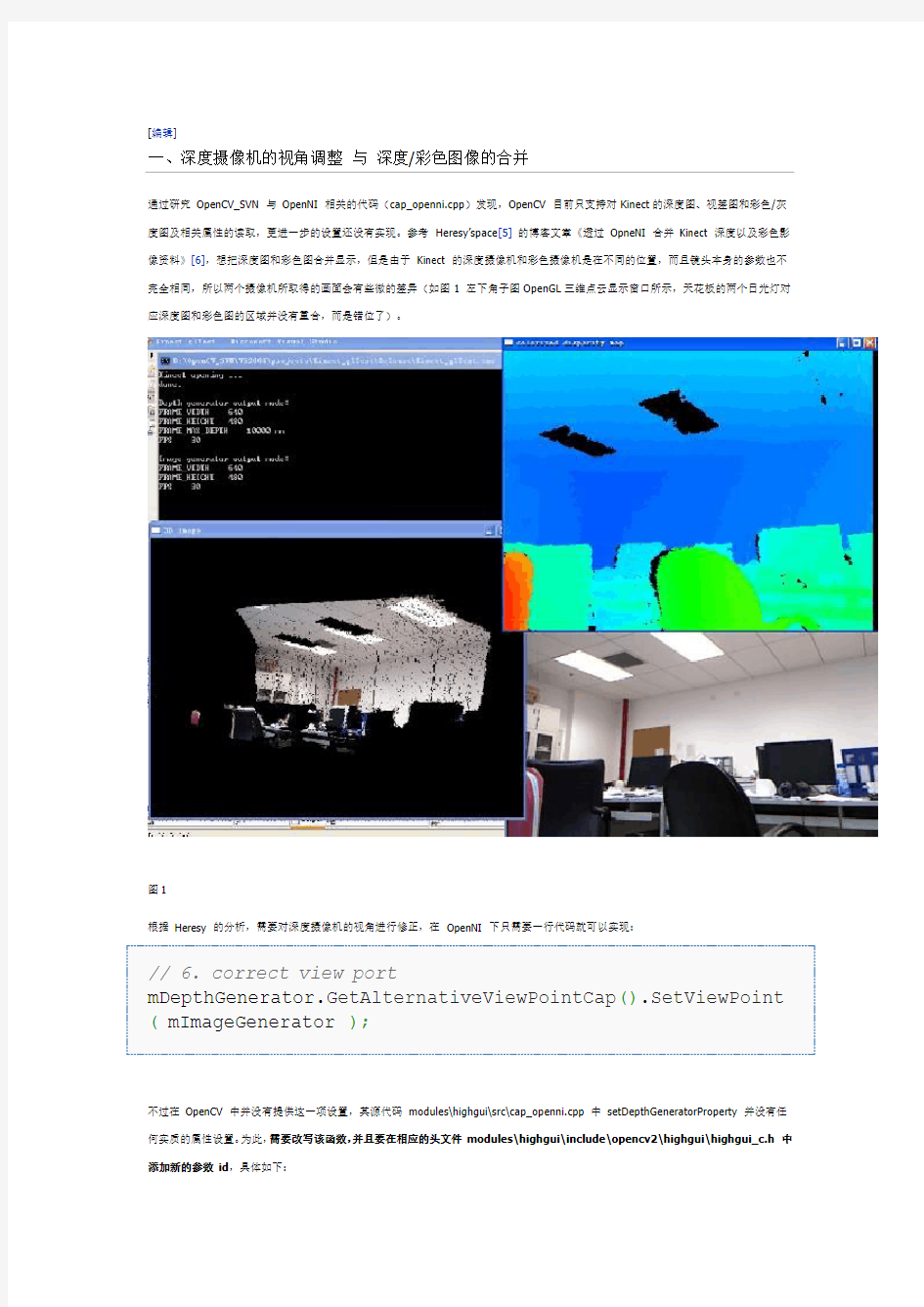
通过研究OpenCV_SVN 与OpenNI 相关的代码(cap_openni.cpp)发现,OpenCV 目前只支持对Kinect的深度图、视差图和彩色/灰度图及相关属性的读取,更进一步的设置还没有实现。参考Heresy’space[5]的博客文章《透过OpneNI 合并Kinect 深度以及彩色影像资料》[6],想把深度图和彩色图合并显示,但是由于Kinect 的深度摄像机和彩色摄像机是在不同的位置,而且镜头本身的参数也不完全相同,所以两个摄像机所取得的画面会有些微的差异(如图1 左下角子图OpenGL三维点云显示窗口所示,天花板的两个日光灯对应深度图和彩色图的区域并没有重合,而是错位了)。
图1
根据Heresy 的分析,需要对深度摄像机的视角进行修正,在OpenNI 下只需要一行代码就可以实现:
// 6. correct view port
mDepthGenerator.GetAlternativeViewPointCap().SetViewPoint ( mImageGenerator );
不过在OpenCV 中并没有提供这一项设置,其源代码modules\highgui\src\cap_openni.cpp 中setDepthGeneratorProperty 并没有任何实质的属性设置。为此,需要改写该函数,并且要在相应的头文件modules\highgui\include\opencv2\highgui\highgui_c.h 中添加新的参数id,具体如下:
然后在第352 行下添加:
从而使得OpenCV 的VideoCapture 属性关于OpenNI 的如下所示:
改写完上述源代码后保存,并且用CMake 和VS2008 重新编译一次OpenCV,我们就可以用OpenCV 的接口来控制Kinect 深度摄像头的视角,使其深度数据和图像数据能够很好的重合起来,如图2所示,注意与图1相比,右上角的伪彩色视差图四周出现了黑边,这就是视角调整后的效果:
图2
[编辑]
二、三维点云坐标的计算
在OpenCV 中实际上已经提供了三维点云坐标计算的接口,通过Kinect 的深度数据可以很快换算出三维点云坐标,cap_openni.cpp 中这部分代码具体如下:
IplImage* CvCapture_OpenNI::retrievePointCloudMap()
{
int cols = depthMetaData.XRes(), rows =
depthMetaData.YRes();
if( cols <=0|| rows <=0)
return0;
cv::Mat depth;
getDepthMapFromMetaData( depthMetaData, depth, noSampleValue, shadowValue );
const float badPoint =0;
不过可以看到上面核心的代码就一行:
具体是怎样实现的呢?我们可以进一步找OpenNI 的源代码来分析。不过这里我是从原来双目视觉的经验上自己编写代码来实现三维点云坐标的计算。实际上Kinect 的深度摄像头成像也类似于普通的双目立体视觉,只要获取了两个摄像头之间的基线(baseline)和焦距(focal length)、以及视差数据,通过构造矩阵Q,利用OpenCV 的reprojectimageTo3D 函数,也可以计算出三维坐标。下面我们通过以下代码看看矩阵Q 的构造过程:
三维重建综述
三维重建综述 三维重建方法大致分为两个部分1、基于结构光的(如杨宇师兄做的)2、基于图片的。这里主要对基于图片的三维重建的发展做一下总结。 基于图片的三维重建方法: 基于图片的三维重建方法又分为双目立体视觉;单目立体视觉。 A双目立体视觉: 这种方法使用两台摄像机从两个(通常是左右平行对齐的,也可以是上下竖直对齐的)视点观测同一物体,获取在物体不同视角下的感知图像,通过三角测量的方法将匹配点的视差信息转换为深度,一般的双目视觉方法都是利用对极几何将问题变换到欧式几何条件下,然后再使用三角测量的方法估计深度信息这种方法可以大致分为图像获取、摄像机标定、特征提取与匹配、摄像机校正、立体匹配和三维建模六个步骤。王涛的毕业论文就是做的这方面的工作。双目立体视觉法的优点是方法成熟,能够稳定地获得较好的重建效果,实际应用情况优于其他基于视觉的三维重建方法,也逐渐出现在一部分商业化产品上;不足的是运算量仍然偏大,而且在基线距离较大的情况下重建效果明显降低。 代表文章:AKIMOIO T Automatic creation of3D facial models1993 CHEN C L Visual binocular vison systems to solid model reconstruction 2007 B基于单目视觉的三维重建方法: 单目视觉方法是指使用一台摄像机进行三维重建的方法所使用的图像可以是单视点的单幅或多幅图像,也可以是多视点的多幅图像前者主要通过图像的二维特征推导出深度信息,这些二维特征包括明暗度、纹理、焦点、轮廓等,因此也被统称为恢复形状法(shape from X) 1、明暗度(shape from shading SFS) 通过分析图像中的明暗度信息,运用反射光照模型,恢复出物体表面法向量信息进行三维重建。SFS方法还要基于三个假设a、反射模型为朗伯特模型,即从各个角度观察,同一点的明暗度都相同的;b、光源为无限远处点光源;c、成像关系为正交投影。 提出:Horn shape from shading:a method for obtaining the shape of a smooth opaque object from one view1970(该篇文章被引用了376次) 发展:Vogel2008年提出了非朗伯特的SFS模型。 优势:可以从单幅图片中恢复出较精确的三维模型。 缺点:重建单纯依赖数学运算,由于对光照条件要求比较苛刻,需要精确知道光源的位置及方向等信息,使得明暗度法很难应用在室外场景等光线情况复杂的三维重建上。 2、光度立体视觉(photometric stereo) 该方法通过多个不共线的光源获得物体的多幅图像,再将不同图像的亮度方程联立,求解出物体表面法向量的方向,最终实现物体形状的恢复。 提出:Woodham对SFS进行改进(1980年):photometric method for determining surface orientation from multiple images(该文章被引用了891次) 发展:Noakes:非线性与噪声减除2003年; Horocitz:梯度场合控制点2004年; Tang:可信度传递与马尔科夫随机场2005年; Basri:光源条件未知情况下的三维重建2007年; Sun:非朗伯特2007年; Hernandez:彩色光线进行重建方法2007年;
基于Kinect深度信息的实时三维重建和滤波算法研究
第29卷第1期 计算机应用研究 V ol.29 No.1 2012年1期 Application Research of Computers Jan. 2011 ——————————————— 作者简介: 陈晓明(1987-),男(汉),浙江临海人,在读硕士,主要研究方向为嵌入式、图像处理 (xmchen2009@https://www.360docs.net/doc/166843785.html,);蒋乐天(1975-),男,博士,副教授,研究方向:嵌入式系统、软件可靠性和可用性研究;应忍东(1975-),男,博士,副教授,主要研究方向为导航信号处理、嵌入式系统、SoC 、数字信号处理。 基于Kinect 深度信息的实时三维重建和滤波算法研究 陈晓明,蒋乐天,应忍冬 (上海交通大学 电子工程系,上海市 200240) 摘 要: 三维重建技术是计算机视觉、人工智能、虚拟现实等前沿领域的热点和难点。本文分析了基于Kinect 输出的深度数据进行场景的实时三维重建的算法。针对实现过程中出现的深度图像噪声过大的问题,根据其信号结构的特点给出了改进的双边滤波算法。新算法利用已知的深度图像噪声范围,将权值函数修改为二值函数,并结合RGB 图像弥补了缺失的深度信息。实验表明,新算法无论在降噪性能还是计算效率上,都大大优于已有的双边滤波,其中计算速度是原始算法的6倍。 关键词: 实时三维重建;Kinect ;三维点云;噪声分析;深度图像;双边滤波;联合双边滤波 中图分类号: TP391 文献标志码: A Research of 3D reconstruction and filtering algorithm based on depth information of Kinect CHEN Xiaoming, JIANG Letian, Ying Rendong (Dept. of Electronic Engineering, Shanghai Jiao Tong University, Shanghai 200240, China ) Abstract: 3D reconstruction is one of the research hotspots. This paper analyzed and improved 3D reconstruction algorithm using the depth information from Kinect. To reduce noise, it proposed an improved bilateral filtering algorithm based on the signal structure. This new algorithm used a two-valued function to compute the weights of the filter, because the range of depth image data was already known. It also combined the RGB values and depth information of surrounding pixels to complement some missing depth information. The results show that the proposed algorithm has much better performance and efficiency, namely 6 times as fast as the original algorithm. Key words: real-time 3D reconstruction; Kinect; 3D point cloud; noise analysis; depth image; bilateral filter; joint bilateral filter 0 引言 三维重建技术是计算机视觉、人工智能、虚拟现实等前沿领域的热点和难点,也是人类在基础研究和应用研究中面 临的重大挑战之一,被广泛应用于文物数字化、生物医学成像、动漫制作、工业测量、沉浸式虚拟交互等领域。 现有的三维重建技术,按照获取深度信息的方式,可分为被动式技术和主动式技术。被动式技术利用自然光反射,一般通过摄像头拍摄图片,然后通过一系列的算法计算得到物体的三维坐标信息,如Structure from Motion[1]和Multi-View Stereo[2]。Structure from Motion 技术利用不同时间的图像建立对应关系,因此只适用于刚性物体;Multi-View Stereo 技术使用于刚体,但是计算量非常大,现阶段很难做到实时。主动式技术包含一个光源,直接测量物体的深度信息,因而很容易做到实时效果,如采用结构光技术的Kinect[3]和采用Time of Flight 技术的CamCube[4]。而相对于CamCube ,采用结构光技术的Kinect 价格更便宜,更容易推广。 本文着重解决动态场景建模,选用Kinect 技术作为三维重建的方法。Kinect 具有反应速度快、价格便宜的优点,但是得到的深度图像精度低,并包含大量噪声。因此在三维重建之前需要对得到的深度图像进行滤波,降低噪声。相对于RGB 图像滤波,深度图像滤波的研究工作还较少。文献[5]中采用双边滤波的方法降低噪声,采用多图像融合的方法修补未得到的深度信息,取得了很好的效果。但是该方法只适合静态场景,对于动态场景并不适合。对于缺失的深度信息,本文结合RGB 图像将其补全,并针对深度图像对双边滤波器进行改进,处理一般的噪声,提高了性能和计算速度。 本文首先阐述了三维重建的流程,然后针对重建过程 中噪声过大的问题分析并降低噪声,最后给出了实验结果和 结论。 1 三维重建算法 图1是三维重建的流程图。Kinect 设备的RGB 摄像头和红外摄像头分别得到RGB 图像和深度图像,为了消除因为两个摄像头位置不同而产生的图像中心不一致,首先将深度图像经过一定的坐标变换与RGB 图像对齐,之后计算出空间点的XY 坐标,最后将三维点云数据(X,Y,Z,R,G,B )通过PCL 开源库显示。 下面针对图中信号处理流程中各个环节具体分析。 红外摄像头 RGB 摄像头 坐标变换 XY 坐标计算 深度图像 RGB 图像 三维点云(X,Y,Z,R,G,B ) 显示 Kinect 图1 三维重建流程图 1.1 Kinect 摄像头信号标定 在使用Kinect 设备之前,需要对其进行标定,包括RGB 摄像头和红外摄像头 的标定,以及确定深度与RGB 图像间的坐标变换关系。 摄像头标定是一项比较成熟的技术,这里不加以详细叙述。文献[6]中,标定前的深度图像误差已经很小,标定后
数字化重建三维模型技术规范-
工厂数字化重建三维模型技术规范 南京恩吉尔工程发展研究中心 2014
目录 1 目标 (3) 2 范围 (3) 3 规范性引用文件 (3) 4 定义 (3) 4.1 建模对象 (3) 4.2 建模分类 (3) 4.3 建模区域 (3) 4.4 建模精度 (3) 5 建模范围 (4) 5.1 三维模型的建模范围 (4) 5.2 建模的功能分类与应用 (5) 6 建模精度要求 (6) 6.1 精度等级 (6) 6.2 专业建模描述 (7) 6.3 功能性建模 (8) 7 建模对象属性要求 (9) 7.1 一般对象属性 (9) 7.2 功能与属性的对照 (11) 8 装备拆解建模与建筑建模 (11) 8.1 装备建模 (11) 8.2 建筑建模 (12) 9 工厂信息采集及文档 (12) 9.1 建模文档及信息收集 (12) 9.2 三维扫描及场景照片 (13) 9.3 现场测绘及草图 (13) 9.4 工程变更信息收集 (13) 10 建模审查与交付 (14) 10.1 建模的中间审查 (14) 10.2 建模的终审与数字化交付 (14) 11 附件:资料收集一览表 (14)
1目标 工厂数模重建主要面向工厂的实际运营和维护需求的数字化,不同于三维工厂设计及建造建模,主要面向工厂建设和制造。而现代的数字化设计建造产生的数字化交付成果,可以通过迁移转换重用,还需要通过数字化的重建,补充大量的后续工厂数模信息,满足工程运维的数字化需求和大工厂物联网的大数据建设需求。 本规范适用于企业已建工厂的数字化重建工作。定义数字化三维模型重建工作中的建模类型、范围、编码规则、建模精度及模型属性等方面的要求和规则。 2范围 三维的数字化建模主要包括工厂的主装置区、辅助装置区、公用工程区、厂前区;以工厂的专属的站场、码头、管网、办公楼及辅助设施等。 3规范性引用文件 下列文件对于建模及信息收集应用是必不可少的。 ISO 15926(GB/T 18975)《工业自动化系统与集成及流程工厂(包括石油和天然气生产设施)生命周期数据集成》 GB/T 28170《计算机图形和图像处理可扩展三维组件》 HG/T 20519-2009《化工工艺施工图内容和深度统一规定》 4定义 4.1建模对象 指流程工厂模型的基本单元,如设备、管子、管件、结构、建筑、门、窗等。一个模型对象具有四类关键信息:唯一标识、几何属性、工程属性、拓扑关系(与其他模型对象间)。 4.2建模分类 三维工厂重建分为功能性建模和一般建模。 功能性建模:配合运维的管理功能要求,建立的符合一定功能需求的全息数模; 一般性建模:主要用于辅助管理功能要求的虚拟环境(如模型参考、信息索引、标识)的数模建模。 4.3建模区域 指按一定标准将工厂进行划分所得的空间分区(如装置区、功能区),区域间不可重叠。一般将以工程初始设计中的区域定义为准则。 4.4建模精度 建模精度按照一定的功能性需求分为:粗模、精模、全息模。分别在模型的尺寸及
基于Kinect的三维重建
项目源码详见:https://www.360docs.net/doc/166843785.html,/forum/viewtopic.php?f=1&t=13042 前几天刚入手了期待已久的Kinect ,用于实验室机器人项目的视觉导航与环境理解。 首先要做的是破解-->连接PC-->获取深度数据和图像数据-->三维点云显示这么几项基本工作。 开始仿照的是饮水思源[1]博客的方法(使用VS2008在windows平台上试用Kinect[2]),利用CL-NUI-Platform 来破解,它的最新版是1.0.0.1210,但我在XP上用会当机,后来换 1.0.0.1121 版的就可以用了。CL NUI 提供了十分简便易用的接口,在OpenCV 上调用很简单,另外它还提供了Kinect 底座马达的控制接口和LED 灯颜色的选择接口,其例程中可以操控Kinect 上下摆动。如果只需要获取深度数据和图像数据,CL NUI 就够用了。不过要做深入的应用,比如人体姿态识别、骨架提取、深度数据与图像数据的合并等等,就该用到OpenNI 了。 国内的CNKINECT[3]是个不错的Kinect 开发论坛,版块丰富,有很多资料可供借鉴。我通过论坛介绍的方法[4]成功配置了OpenNI + Kinect,先是用最新版的OpenNI+SensorKinect+NITE ,但在XP 下不能正常运行,可能跟 .net 平台有关,老实按上面论坛的方法装就成功了。另外用CMake + VS2008 装了最新的OpenCV_SVN,开始试过在CMake 里选择With TBB,但诡异的是TBB 似乎只适用于VS2005,在VS2008 编译后试用里面的samples 老是提示报错找不到msvcp80.dll,重新用CMake 配置取消了With TBB,就一切正常了。
基于Kinect的三维重建
基于Kinect-OpenNI-OpenCV-OpenGL的环境三维重构 项目源码详见:https://www.360docs.net/doc/166843785.html,/forum/viewtopic.php?f=1&t=13042 前几天刚入手了期待已久的Kinect ,用于实验室机器人项目的视觉导航与环境理解。 首先要做的是破解-->连接PC-->获取深度数据和图像数据-->三维点云显示这么几项基本工作。 开始仿照的是饮水思源[1]博客的方法(使用VS2008在windows平台上试用Kinect[2]),利用CL-NUI-Platform 来破解,它的最新版是1.0.0.1210,但我在XP上用会当机,后来换 1.0.0.1121 版的就可以用了。CL NUI 提供了十分简便易用的接口,在OpenCV 上调用很简单,另外它还提供了Kinect 底座马达的控制接口和LED 灯颜色的选择接口,其例程中可以操控Kinect 上下摆动。如果只需要获取深度数据和图像数据,CL NUI 就够用了。不过要做深入的应用,比如人体姿态识别、骨架提取、深度数据与图像数据的合并等等,就该用到OpenNI 了。 国的CNKINECT[3]是个不错的Kinect 开发论坛,版块丰富,有很多资料可供借鉴。我通过论坛介绍的方法[4]成功配置了OpenNI + Kinect,先是用最新版的OpenNI+SensorKinect+NITE ,但在XP 下不能正常运行,可能跟 .net 平台有关,老实按上面论坛的方法装就成功了。另外用CMake + VS2008 装了最新的OpenCV_SVN,开始试过在CMake 里选择With TBB,但诡异的是TBB 似乎只适用于VS2005,在VS2008 编译后试用里面的samples 老是提示报错找不到msvcp80.dll,重新用CMake 配置取消了With TBB,就一切正常了。
学术讲座报告— 基于结构光照明的三维物体识别
学术讲座报告 —— 基于结构光照明的三维物体识别 结构光照明(Structured Light Illumination ),是指基于三角测量,立体重建。通过测量一系列的预测模式的失真反射目标,目标的3 - D 表面信息可以提取。为了帮助理解结构光照明,无论是理想和在此演示文稿介绍实用模式。然后,我们采用模型设计模式和分析三维重建的表现。 以下是我对此技术的了解和体会: 结构光照明三维成像系统(3D Imaging System with Structured Illumination)基于光学三角法测量原理,是一种主动三维传感技术。光学投影系统将一定模式的结构光图案投射到待测物体表面,在表面上形成受到被测物体表面形状调制的三维变形图像。该三维图像由位于另一角度的成像系统探测,从而获得二维的变形图像。结构光图案的变形程度取决于光学投影系统与成像系统之间的相对位置和物体表面轮廓。当光学投影系统与成像系统之间的相对位置一定时,由变形的二维图像可以恢复物体表面的三维轮廓。结构光照明三维成像系统由光学投影系统、成像系统、计算机系统等组成。 基于光学三角测量法的结构光照明三维测量技术,通过处理测量系统所获取的数据,建立投影光栅、待测物体表面与摄像机像面上对应点之间的三角关系。最终根据三角测量原理得到待测物体表面的三维形貌分布。 摄像机数学模型: 摄像机的径向畸变可以表示为:246123246123(,)(....)(,)(....)xr yr x y x k r k r k r x y y k r k r k r δδ??=+++????=+++???? 其中 222 12,,...r x y k k =+为径向畸变参量。
利用二维工程图重建三维实体模型
生产技术与经验交流 铸造技术 07/2011 皮带张紧装置设计在机尾,采用螺旋张紧装置即可满足输送带要求。此外,在机架上每个适当位置设置一对调偏立辊,机架下部设置下平行托辊,以防皮带过度下垂,机头处还设计有进料砂斗,机尾处有出料砂斗,出料斗直接连接斗式提升机,由提升机把造型工序所需要的砂子提升到储存砂斗上。改造后整个砂处理工艺流程如图1所示。 图1 旧砂处理工艺流程 5 结语 (1)此改造设计方案简便可行,资金投入少,冷却效率高,为旧砂再生、企业可持续发展创造了有利 条件。 (2)旧砂处理工序大大简化,可缩减操作人员,为企业实现减员提效、人员优化创造有利条件。 参考文献 [1] 秦文强.消失模铸造新工艺新技术与生产应用实例[M ]. 北京:北方工业出版社,2007. [2] 张尊敬,汪鲠.DT (A )型带式输送机设计手册[M ].北 京:冶金工业出版社,2003. [3] 成大先.机械设计手册[M ].北京:化学工业出版社, 1999. 收稿日期:2011 01 25; 修订日期:2011 02 20 作者简介:梁玉星(1971 ),广西武鸣县人,工程师.主要从事机械设计 工作. Email:lian gyu xing001@https://www.360docs.net/doc/166843785.html, 利用二维工程图重建三维实体模型 杨晓龙1,晁晓菲2 (1.西安航空技术高等专科学校机械工程系,陕西西安710077;2.西北农林科技大学信息工程学院,陕西杨凌 712100) 3D Solid Models Reconstruction with 2D Engineering Drawings Y ANG Xiao long 1 ,CHAO Xiao fei 2 (1.Faculty of Mechanical Engineering,Xi an Aerotechnical College ,Xi an 710077,China;2.C ollege of Infor mation Engineering,Northwest A&F University,Yangling 712100,C hina) 中图分类号:T P391.7 文献标识码:A 文章编号:1000 8365(2011)07 1034 03 为了适应大规模的机械化生成,以平面图来表达 三维实体为设计思想,二维工程图在指导生产、装配和技术交流等方面起到了举足轻重的作用。目前,随着计算机技术的飞速发展,现代设计越来越注重三维实体造型的应用,因为通过三维造型可以分析产品的动态特性、直观地表达设计效果和构造动画模型等[1]。 由此可知,三维实体模型要比二维工程图容易理 解,且效果直观。本文将介绍如何充分利用已有的二维图形信息来辅助建立三维模型,这既能提高三维建模的速度,又不会因采用三维造型技术而抛弃原有二维绘图的宝贵技术资源[2] 。1 三维模型重建的基本原理 图1 三视图的整体与局部都符合三等规律 根据画法几何学的基本理论,空间点在两个不同方向上的正投影可以完全确定点在空间中的位置,即点和线在不同视图中的坐标值应具有对应相等的关 系。对于三视图(亦称正投影工程图),若用F(front)、T(to p)、S(side)分别表示主视图、俯视图和左视图上点的集合,那么主视图中的点f(f F)具有x 、z 坐标, 1034
机器视觉—三维重建技术简介
三维重建技术简介 一、视觉理论框架 1982年,Marr立足于计算机科学,首次从信息处理的角度系统的概括了心理生理学、神经生理学等方面已经取得的重要成果,提出了一个迄今为止比较理想的视觉理论框架。尽管Marr提出的这个视觉理论框架仍然有可以进行改进和完善的瑕疵,但是在近些年,人们认为,计算机视觉这门学科的形成和发展和该框架密不可分。 第一方面,视觉系统研究的三个层次。 Marr认为,视觉是一个信息处理系统,对此系统研究应分为三个层次:计算理论层次,表示与算法层次,硬件实现层次,如下图所示: 计算机理论层次是在研究视觉系统时首先要进行研究的一层。在计算机理论层次,要求研究者回答系统每个部分的计算目的与计算策略,即视觉系统的输入和输出是什么,如何由系统的输入求出系统的输出。在这个层次上,将会建立输入信息和输出信息的一个映射关系,比如,系统输入是二维灰度图像,输出则是灰度图像场景中物体的三维信息。视觉系统的任务就是研究如何建立输入输出之间的关系和约束,如何由二维灰度图像恢复物体的三维信息。 在表示与算法层次,要给出第一层中提到的各部分的输入信息、输出信息和内部信息的表达,还要给出实现计算理论所对应的功能的算法。对于同样的输入,如果计算理论不同,可能会产生不同的输出结果。 最后一个层次是硬件实现层次。在该层次,要解决的主要问题就是将表示与算法层次所提出的算法用硬件进行实现。 第二方面,视觉信息处理的三个阶段。 Marr认为,视觉过程分为三个阶段,如表所示:
第一阶段,也称为早期阶段,该阶段是求取基元图的阶段,该阶段对原始图像进行处理,提取出那些能够描述图像大致三维形状二维特征,这些特征的集合构成所构成的就是基元图(primary sketch)"。 第二阶段也称中期阶段,是对环境的2.5维描述,这个阶段以观察者或者摄像机为中心,用基元图还原场景的深度信息,法线方向(或一说物体表面方向)等,但是在该阶段并没有对物体进行真正的三维恢复,因此称为2.5维。 第三阶段也称为后期阶段,在一个固定的坐标系下对2.5维图进行变换,最终构造出场景或物体的三维模型。 二、三维重建技术现状 目前三维重建的方法大致可分为三类,即:用建模软件构造的方式,多幅二维图像匹配重建的方式以及三维扫描重建的方式。 对于第一种方式,目前使用比较广泛的是3D Max, Maya, Auto Cad以及MultiGen-Creator等软件。这些三维建模软件,一般都是利用软件提供的一些基本几何模型进行布尔操作或者平移旋转缩放等操作,来创建比较复杂的三维模型。这样所构建出来的模型,比较美观,而且大小比例等非常精确。然而,这需要建模者精确知道三维场景的尺寸、物体位置等信息,如果没有这些信息,就无法建立精准的模型。 第二种方式是利用实时拍摄的图像或者视频恢复场景的三维信息。这种方式是基于双目立体视觉,对同一物体拍摄不同角度的图像,对这些图像进行立体匹
三维重建方法综述
三维重建方法综述 三维重建方法大致分为两个部分1、基于结构光的2、基于图片的。这里主要对基于图片的三维重建的发展做一下总结。基于图片的三维重建方法: 基于图片的三维重建方法又分为双目立体视觉;单目立体视觉。 A双目立体视觉: 这种方法使用两台摄像机从两个(通常是左右平行对齐的,也可以是上下竖直对齐的)视点观测同一物体,获取在物体不同视角下的感知图像,通过三角测量的方法将匹配点的视差信息转换为深度,一般的双目视觉方法都是利用对极几何将问题变换到欧式几何条件下,然后再使用三角测量的方法估计深度信息这种方法可以大致分为图像获取、摄像机标定、特征提取与匹配、摄像机校正、立体匹配和三维建模六个步骤。王涛的毕业论文就是做的这方面的工作。双目立体视觉法的优点是方法成熟,能够稳定地获得较好的重建效果,实际应用情况优于其他基于视觉的三维重建方法,也逐渐出现在一部分商业化产品上;不足的是运算量仍然偏大,而且在基线距离较大的情况下重建效果明显降低。 代表文章:AKIMOIOT Automatic creation of 3D facial models 1993 CHENCL Visual binocular vison systems to solid model reconstruction 2007 B基于单目视觉的三维重建方法: 单目视觉方法是指使用一台摄像机进行三维重建的方法所使用的图像可以是单视点的单幅或多幅图像,也可以是多视点的多幅图像前者主要通过图像的二维特征推导出深度信息,这些二维特征包括明暗度、纹理、焦点、轮廓等,因此也被统称为恢复形状法(shape from X) 1、明暗度(shape from shading SFS) 通过分析图像中的明暗度信息,运用反射光照模型,恢复出物体表面法向量信息进行三维重建。SFS方法还要基于三个假设a、反射模型为朗伯特模型,即从各个角度观察,同一点的明暗度都相同的;b、光源为无限远处点光源;c、成像关系为正交投影。 提出:Horn shape from shading:a method for obtaining the shape of a smooth opaque object from one view 1970(该篇文章被引用了376次) 发展:V ogel2008年提出了非朗伯特的SFS模型。优势:可以从单幅图片中恢复出较精确的三维模型。 缺点:重建单纯依赖数学运算,由于对光照条件要求比较苛刻,需要精确知道光源的位置及方向等信息,使得明暗度法很难应用在室外场景等光线情况复杂的三维重建上。 2、光度立体视觉(photometric stereo) 该方法通过多个不共线的光源获得物体的多幅图像,再将不同图像的亮度方程联立,求解出物体表面法向量的方向,最终实现物体形状的恢复。 提出:Woodham对SFS进行改进(1980年):photometric method for determining surface orientation from multiple images(该文章被引用了891次) 发展:Noakes:非线性与噪声减除2003年; Horocitz:梯度场合控制点2004年; Tang:可信度传递与马尔科夫随机场2005年;Basri:光源条件未知情况下的三维重建2007年;Sun:非朗伯特2007年; Hernandez:彩色光线进行重建方法2007年; Shi:自标定的光度立体视觉法2010年。 3、纹理法(shape from texture SFT) 通过分析图像中物体表面重复纹理单元的大小形状,恢复出物体法向深度等信息,得到物体的三维几何模型。
Kinect国内外研究现状
动作捕捉技术方面,目前主流的动作捕捉技术可分为光学式,机械式,以及视频捕捉式等[15]。光学式为目前应用较为广泛的方案,其实现主要原理为利用分布在空间中固定位置的多台摄像机通过对捕捉对象上特定光点(Marker)的监视和跟踪完成动作捕捉。光学式动作捕捉的优点在于表演者活动的动作幅度大,无线缆、机械装置对动作的束缚,此外此种方式采样速率较高,一般可达每秒60帧的速率,可满足大多数动作捕捉的需求。但光学式系统捕捉系统整体造价比较高,对环境的要求也比较严格。机械式动作捕捉主要借助机械装置完成运动信息的采集。典型的机械式动作捕捉系统由多个关节和刚性连杆组成,借助安装在各个关节处的角度传感器完成各时刻的关节形态的采集以此可重绘出该时刻被捕捉对象的形态。其优点在于捕捉精度较高,缺陷是对动作捕捉对象的限制较多。典型的基于视频序列的动作捕捉通常采取在不同角度固定摄像机拍摄,通过被拍摄者身上的显著标志点来区分人体的各部位,最后在计算机中完成合成的方法。此方法可以实现比较理想的动作捕捉效果,但是制作成本比较高。例如09年的好莱坞大片《阿凡达》就是让演员身着色素点矩阵服装在演示着各种动作,通过不同角度摄像机协同拍摄,最后在计算机中完成了三维合成,整个影片在技术方面花费了高昂的成本。 自微软Kinect红外深度感应器发布以来,国外对其技术和应用上的研究都取得了比较多且富有创造性的成果。Kinect感应器最初是作为微软XBOX游戏机的体感外设发布的,后经热心开发者将其驱动破解并建立起OpenNI的软件框架,Kinect在计算机方面的研究和应用才逐步获得了较大的影响力。现阶段微软已经为此款深度感应器发布了官方的驱动程序及SDK,更进一步推动了体感技术的开发应用。 与Kinect类似,华硕在2011年联合PrimeSense公司发布了另一款深度感应器-Xtion,此款感应器在体积上更小,功能上更精简,支持OpenNI的开源函数库,目前也获得了较多开发者的青睐。 人体骨架识别和建模方面,利用SDK,华中科技大学的Wei Shen和微软公司的Ke Deng等人提出了基于模型的人体骨架修正和标记方法[19],较好地解决了获取人体动作视频中的遮挡问题。此外,微软剑桥研究院的Shahram Izadi等人则利用深度摄像头开发了一套实时三维重建和交互系统,系统通过摄像头对所见物体进行三维重建,并实现了操作者在虚拟空间中的实时交互。 可以说,传感器方面的革新使人体骨架建模有了更优的解决方案,为基于人体骨架识别和运动跟踪方面的应用开拓了广阔的前景。
三维重建调研报告
调研报告 题目基于二维图形的三维构造 学生姓名张鹏宇 指导教师张昊 学院信息科学与工程学院 专业班级电子信息工程 完成时间2016年1月 本科生院制
摘要: 由于计算机和数字化技术的快速发展,传统的二维图像已经无法满足人们的需求。人们更希望计算机能表达更加真实的三维世界。因此计算机视觉技术迈入高速发展的时期。计算机视觉是指用计算机来实现人类的视觉功能,也就是用计算机对二维图像进行三维重构,流行一些的说法就是基于双眼视觉。 关键词:三维重建,算法,CT图像,立体建模,三维分布; 1.三维重建算法的主要分类: (1)自顶向下法: 将形体分解为由若干个基本形体或体素(正多面体、圆柱、圆锥、球、环等)组合而成。每种基本形体在三面视图上的投影具有固定的模式,例如圆柱的三视图是两个矩形与一个圆,而球则为三个圆。找出每个视图中的圆、矩形等元素,再通过检查其坐标值将这些元素相互对应,根据基本形体的投影特性确定出每个部分的形状,最后将它们组装起来,就完成了三维重建。(类似于映射的关系,word中的三维重建就是这个原理) (2)自底向上法: (1)二维点、线的对应与三维点、线的生成。参与对应的二维点包括曲、直线段的端点与曲线的极值点。最初的算法首先由二维点对应产生三维点,再由三维点得到三维线段;给出了基于边线分类,从而由视图一步获得三维线段的快速方法。 (2)平面与曲面的获得。共面但不共线的两条或多条直线段与曲线段都能够唯一确定一个平面。曲面一般只考虑圆柱面、圆锥面、球面等,其中的每一种都可以用特定的模式来产生。例如一个球面可以由半径相同、相交但不共面的两个三维圆或圆弧唯一确定。通常,产生的平面与曲面都被记录成方程的形式。 (3)面环“face一loop求取。前面获得的平面与曲面需要加上边界条件才能作为形体的表面。边界可以通过求取落在面上的闭合环,即面环来获得。面 环分为内环与外环,内环产生于形体上的孔洞。 (4)基元形体的生成与组装。前面步骤中获得的平面与曲面将空间分割成一些无公共内点的三维封闭子空间,称为基元形体或体环(bdoy一loop)。基元形体的组合构成重建的候选解集,通过检验是否完全符合视图,判断出正确的重建结果。 2.部分三维重建算法:
kinect三维重建
上海大学2014 ~2015学年秋季学期研究生课程考试 课程设计大作业 课程名称:建模与仿真课程编号: 09SAS9011 论文题目: 基于Kinect的三维重建 研究生姓名: 邵军强学号: 14721629 论文评语: 成绩: 任课教师: 评阅日期:
基于Kinect的三维重建 邵军强 (上海大学机电工程与自动化学院) 摘要:三维重建是计算机视觉的一个重要目标,可以帮助人们快速精确地将日常生活中的物体数字化,并有着广泛的应用前景。本文叙述了一种成本低廉、快速且操作简便的三维重建方法。借助于微软公司的Kinect 体感传感器作为采集深度图像和彩色图像的输入设备,通过对原始深度图像的去噪、平滑、表面重建等一系列方法,最终可以获得在三维空间中的点云模型。 关键词:三维重建,Kinect,点云模型 Based on Kinect 3D Reconstruction SHAO JUNQIANG ( Shanghai University EMSD and automation College) Abstract:3 D reconstruction is an important goal of computer vision, and can help people quickly and accurately to digital objects in everyday life, and has a broad application prospect. This paper describes a kind of low cost, quick and easy operation method of 3 d reconstruction. By using Microsoft's device body feeling sensor as a collection of depth image and color image input device, through the depth of the original image denoising and smoothing, surface reconstruction and a series of methods, finally can get the point cloud model in three-dimensional space. Keywords:3D Reconstruction,Kinect, point cloud model 1 引言 Kinect 传感器是一种RGB-D 传感器,即可以同时获得环境颜色值(RGB)和深度值(depth)的传感器.它的采集速度快,精度高,且价格低廉,使其迅速被运用到很多领域.机器人领域也开始了对Kinect 传感器广泛的研究[1].利用Kinect 传感器对室内环境进行3D 重构,获得环境的3D 点云模型是研究热点之一.华盛顿大学与微软实验室[2],开发了基于SIFT (尺度不变特征变换)特征匹配定位及TORO(Tree-basednetwORk Optimizer)优化算法的实时视觉SLAM系统来建立3D 点云地图.德国Freiburg 大学[3]提出了RGBD-SLAM 算法,采用了与华盛顿大学类似的方法,但是为了提高实时性,使用了Hogman(hierarchical optimization for pose graphs on manifolds)图优化算法,同时在相对位姿检测上采用了SURF (加速鲁棒特征)特征进行对应配.KinectFusion 算法与这些算法不同,它仅使用深度信息,通过设计高效及高度并行的算法在GPU(图形处理单元)上运行达到了非常高的实时性,在试验中,在配置4000 元左右的电脑上运行速度达到了18 帧/秒(在同样配置的计算机上前面两种算法仅达到2 帧/秒),在进行场景建立时有良好的用户体验,甚至可以用来做一些人机交互方面的应用[4-5].同时KinectFusion 采用了基于TSDF(truncated signed distance
三维重建模型 内窥镜图像综合分析软件产品技术要求renxing
三维重建模型/内窥镜图像综合分析软件 适用范围:适用于符合DICOM标准的CT图像以.rx3d格式存储的三维模型数据和内窥镜影像的导入、显示、叠加查看的操作。 1.1 软件型号规格:RXFQJMR-I 1.2 发布版本 软件发布版本:V1.0 1.3 版本命名规则 软件的完整版本命名由四部分组成,完整版本型号:VX.Y.Z.B ,分类描述如下: 字母V为版本Version的缩写; * X:主版本号,也是发布版本号,表示重大增强类软件更新,初始值为1,当软件进行了重大增强类软件更新,该号码加1; * Y:子版本号,表示轻微增强类软件更新,初始值为0,当软件进行了轻微增强类软件更新,该号码加1; * Z:修正版本号,表示纠正类软件更新,初始值为0,当软件进行了纠正类软件更新,该号码加1; * B:构建号,表示软件编译生成一个工作版本,符合软件更新的定义,初始值为0,当软件进行了构建更新,该号码加1。 2.1 通用要求 2.1.1 处理对象 软件针对腹腔镜影像、软件定义的.rx3d格式的三维数据进行处理。 2.1.2 最大并发数 软件运行的网络环境为单机环境,支持读取影像数据的最大用户数为1。2.1.3 数据接口 软件通过高清数字视频信号DVI、SDI、VGA接口,与医疗设备进行影像传输,支持模拟视频信号接口。 2.1.4特定软硬件 特定硬件:广播级视频采集卡,支持SDI、VGA、DVI接口,对于非DICOM 标准的视频输出的医疗设备,选用支持DirectShow的视频采集卡。
2.1.5 临床功能 登录界面功能: 1)显示登录用户名,密码。 2)密码隐藏功能,点击输入框后面显示按钮可查看登陆密码。 3)点击登录或按键盘Enter键,均可登录。 操作界面功能: 1)文件导入模块:在软件菜单栏点击模型导入按钮,在软件右侧功能栏即显示患者三维模型信息的导入按钮列表。点击三维模型信息按钮可导入相应的三维模型。 2)患者信息录入模块:在软件菜单栏点击患者信息按钮,在软件右侧功能栏即显示三维模型中已存的患者信息(包括姓名、性别、入院编号、主治医师、病例诊断和手术类型),亦可在此对患者信息进行修改或重新录入。 3)三维模型器官分类模块:在软件菜单栏点击器官分类按钮,在软件右侧功能栏即显示器官分类。在此模块中,亦可通过点击代表各器官、组织的各色按钮来控制三维模型各器官、组织的显示或隐藏,以及拖动滑动条调整各器官、组织的透明度。 4)三维模型姿态调整模块:在软件菜单栏点击姿态调整按钮,在软件右侧功能栏即显示三维模型位置操作按钮,含上、下、左、右移动4个按键,远、近移动2个按键和三个可控制X/Y/Z轴的滑动按钮。在此模块可控制三维模型的姿态变换。 5)摄录模块:在软件的菜单栏点击摄录按钮,在软件右侧功能栏即显示录像和截屏按钮,点击录像按钮可录制手术的操作过程,点击截屏按钮可随时截屏,为后期的视频教学保存相关资料。 6)软件使用帮助模块:在软件的菜单栏点击软件使用帮助按钮,在右侧功能栏即显示鼠标和键盘操作的示意图,在主窗口显示操作视频,可观看学习软件快速上手视频。 7)软件安全退出:点击菜单栏退出按钮,软件数据即存储到指定的文件夹下,便于资料拷贝。
【CN110047144A】一种基于Kinectv2的完整物体实时三维重建方法【专利】
(19)中华人民共和国国家知识产权局 (12)发明专利申请 (10)申请公布号 (43)申请公布日 (21)申请号 201910257175.3 (22)申请日 2019.04.01 (71)申请人 西安电子科技大学 地址 710071 陕西省西安市太白南路2号 (72)发明人 卢朝阳 郑熙映 (74)专利代理机构 郑州芝麻知识产权代理事务 所(普通合伙) 41173 代理人 董晓勇 (51)Int.Cl. G06T 17/20(2006.01) (54)发明名称一种基于Kinectv2的完整物体实时三维重建方法(57)摘要本发明涉及一种基于Kinectv2的完整物体实时三维重建方法,包括数据采集→深度补全→点云处理→ICP点云配准→点云融合→曲面重建。本发明的有益效果是:该基于Kinect2.0的物体完整实时三维重建方法通过数据采集、深度补全、点云处理、ICP点云配准、点云融合及曲面重建等步骤的共同作用,使得该方法对物体完整实时三维重建的效果提升,替代传统的三维重建一般使用多张照片、单目或双目相机进行深度获取,这个过程计算量大,在实时性和精度方面很难同时保证,而专业的高精度三维扫描设备价格过高,使得三维重建技术的应用和普及度存在限 制的缺陷。权利要求书2页 说明书11页 附图4页CN 110047144 A 2019.07.23 C N 110047144 A
1.一种基于Kinect 2.0的物体完整实时三维重建方法,其特征在于,包括数据采集→深度补全→点云处理→ICP点云配准→点云融合→曲面重建。 2.根据权利要求1所述的一种基于Kinect2.0的物体完整实时三维重建方法,其特征在于:所述基于Kinect2.0的物体完整实时三维重建方法如下: (1)数据采集:通过Kinect2.0获取深度图像和彩色图像数据,对获取的深度图像进行噪声预处理,而后将彩色图与降噪后的深度图进行对齐,将结果输入进深度补全网络中。 (2)深度补全:在Torch框架中将彩色图与深度图放入设计好的深度补全网络中,利用彩色图的信息对深度图缺失部分进行预测,并将结合原始深度图进行全局优化,得到补全后深度图后通过相机内参矩阵将其转化为点云数据。 (3)点云处理:通过点云各点的坐标信息计算其法向量,为之后的点云配准中对应点匹配做准备。 (4)ICP点云配准:全局数据立方体得到的预测点云数据与当前帧的点云数据进行配准,得到当前点云的配准变换矩阵。 (5)点云融合:根据之前得到的配准变换矩阵,将当前帧的点云数据与全局数据立方体融合,然后通过光线投射算法,由全局数据立方体计算出新的预测数据,用于下一帧点云数据配准,同时对当前视角下的点云数据表面进行渲染,实时观察重建情况。 (6)曲面重建:当采集的所有帧点云数据都融合完后,将全局点云数据从全局数据立方体中提取出来,通过曲面重建算法重建出物体表面,形成完整的三维模型。 3.根据权利要求2所述的一种基于Kinect2.0的物体完整实时三维重建方法,其特征在于:所述点云处理中需要用到图像坐标系、相机坐标系以及世界坐标系。 4.根据权利要求2所述的一种基于Kinect2.0的物体完整实时三维重建方法,其特征在于:所述点云融合中的点云数据与全局数据立方体融合具体为:初始化时,全局立方体中所有体素值为D=1,W=0,相机的初始位置设为(1.5,1.5,-0.3),便于相机获得较好的视野,立方体中心坐标为(1.5,1.5,1.5)。在获取第i帧点云数据后,将其融入立方体中需要进行如下步骤: (1)首先在全局坐标系下获取体素的坐标V g (x ,y ,z),然后通过ICP配准得到变换矩阵并将其从全局坐标系转换到相机坐标系得到V(x ,y ,z); (2)将步骤(1)得到的相机坐标V(x ,y ,z)根据相机内参矩阵转换到图像坐标系,得到对应图像坐标(u ,v); (3)如果第一帧深度图像(u ,v)处的深度值D(u ,v)不为0,则比较D(u ,v)与体素相机坐标V(x ,y ,z)中z的大小,如果D(u ,v)>z,说明此体素距离相机更近,在重建表面的外部;如果D(u ,v)<z,说明此体素距离相机更远,在重建表面的内部; (4)最后根据(3)中的结果更新该体素中距离D和权重W。 更新所用的公式如下所示: W i (x ,y ,z)=min(max weight ,W i -1(x ,y , z)+1) sdf i =V.z -D i (u ,v) 权 利 要 求 书1/2页2CN 110047144 A