HAProxy配置使用说明

配置管理工具简介
配置管理工具简介 要说配置管理工具,就要说到配置管理,因为配置管理工具是软件配置管理过程中所使用的一些工具,要了解配置管理工具,首先就必须了解配置管理。 一、配置管理工具的定义:软件配置管理的定义有很多,现在我只说一个我 觉得定义的必要好的定义。它是:“协调软件开发使得混乱减到最小的技术叫做软件配置管理,它是一种标识、组织和控制修改的技术,目的是使错误达到最小并有效地提高生产效率。”它贯穿整个软件生命周期并应用于整个软件工程过程,是软件工程中用来管理软件开发的规范,也是CMM(软件能力成熟度模型)二级中关键过程域。软件配置管理是软件质量改进的核心环节,它贯穿于整个软件生命周期,为软件改进提供了一套解决办法与活动原则。 二、软件配置管理的目标: 软件配置管理的目标是标识变更、控制变更、确保变更、和报告变更,它主要完成以下几种任务:标识、版本管理、变更控制、配置审计和配置报告。 三、配置管理工具的主要功能: 配置管理工具作为配置管理过程中使用的工具就理所当然的具有以下功能: 1).并行开发支持:因开发和维护的原因,要求能够实现开发人员同时在同 一个软件模块上工作,同时对一个代码部分做不同的修改,即使是跨地域 分布的开发团队也能互不干扰,协同工作,而又不失去控制。 2).修订版管理:跟踪一个变更的创造者、时间和原因,从而加快问题和缺 陷的确定。 3).版本控制:能够简单、明确地重现软件系统的任何一个历史版本。 4).产品发布管理:管理、计划软件的变更,与软件的发布计划、预先定制 好的生命周期或相关的质量过程保持一致;项目经理能够随时清晰地了解 项目的状态。 5).建立管理:基于软件存储库的版本控制功能,实现建立过程自动化。 6).过程控制:贯彻实施开发规范,包括访问权限控制、开发规则的实施等。 7).变更请求管理:跟踪、管理开发过程中出现的缺陷、功能增强请求或任 务,加强沟通和协作,能够随时了解变更的状态。 8).代码共享:提供良好的存储和访问机制,开发人员可以共享各自的开发 资源。 四、常见配置管理工具简介: 配置管理工具有很多,一下我对一些常见的配置管理工具做一简单的介绍。 1.元老:CCC、SCCS、RCS 上个世纪七十年代初期加利福利亚大学的Leon Presser教授撰写了一篇论文,提出控制变更和配置的概念,之后在1975年,他成立了一家名为Soft Tool的公司,开发了自己的配置管理工具:CCC,这也是最早的配置管理工具之一。 在软件配置管理工具发展史上,继CCC之后,最具有里程碑式的是两个自由软件:Marc Rochkind 的SCCS (Source Code Control System) 和Walter Tichy 的RCS (Revision Control System),它们对配置管理工具的发展做出了重大的贡献,直到现在绝大多数配置管理工具基本上都源于它们的设计思想和体系架构。 2.中坚:Rational Clear Case
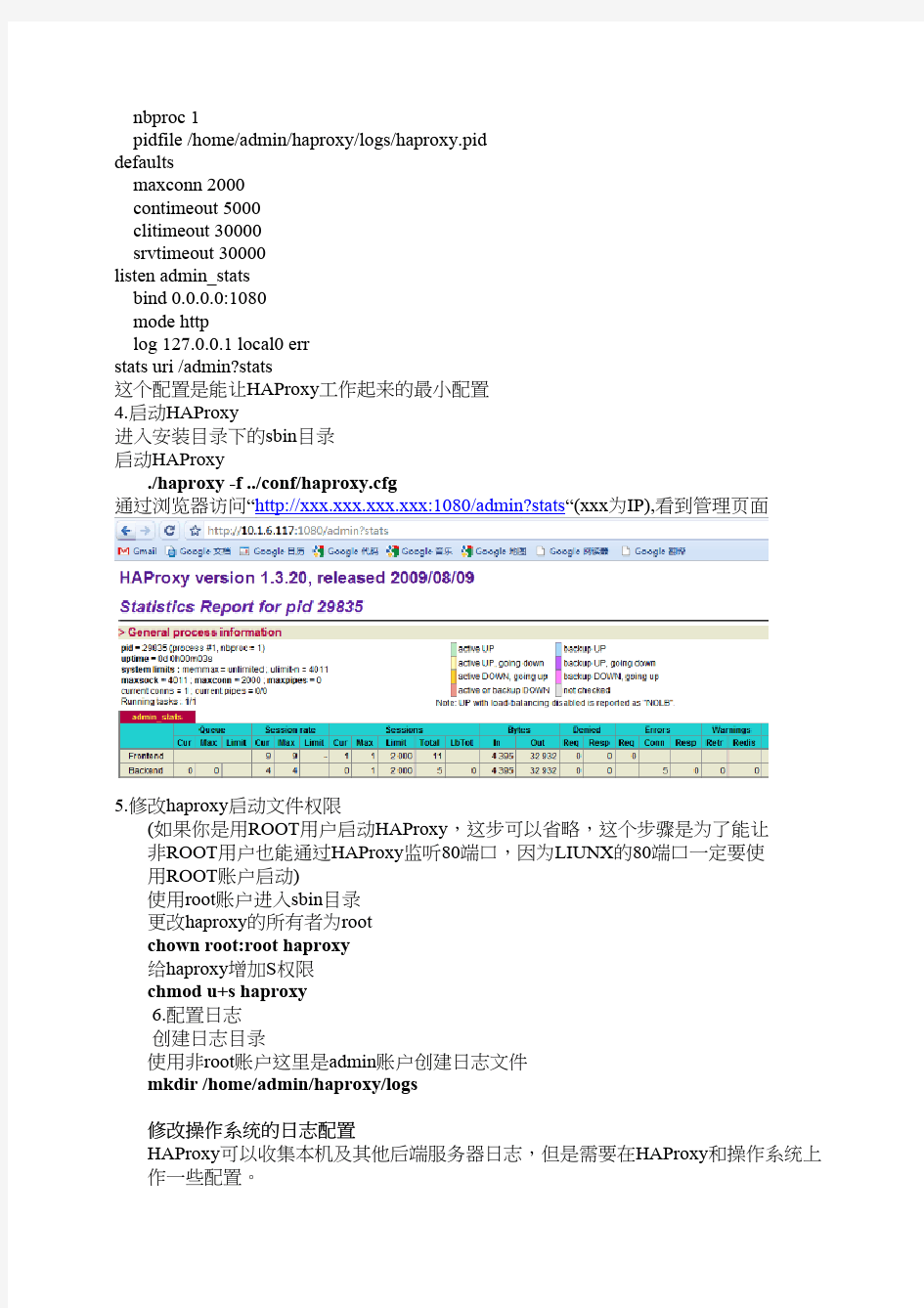
HAProxy的安装部署详细
HAProxy的安装和部署 考虑公司当前服务器的并发量,最终还是选定了HAProxy来实现负载均衡,相较于其他的负载均衡系统,HAProxy的配置和使用还是比较简单的。 下面是自己安装和部署haproxy的记录,比较重要的一点是解决了haproxy + syslog-ng的日志输出问题。 PS: 这个问题费了我好大神:-| PLATFORM: SUSE Linux Enterprise Server 11 (x86_64) 1. haproxy的编译安装 获取haproxy的源代码 官方地址:http://haproxy.1wt.eu/ 目前最新的版本:http://haproxy.1wt.eu/download/1.4/src/haproxy-1.4.8.tar.gz 命令:
wget http://haproxy.1wt.eu/download/1.4/src/haproxy-1.4.8.tar.gz 考虑到版本的更新,具体的安装属性可能会稍有改变,建议在安装前可以大致浏览下haproxy目录下的README和Makefile两个文件。 编译haproxy 进入解压后的haproxy的目录,用下列命令进行编译: make TARGET=os ARCH=arch CPU=cpu USE_xxx=1 ... 这里着重说明几个常用的选项。 TARGET 指定对目标操作系统在编译的时候进行优化,可选择如下值之一: Generic, linux22, linux24, linux24e, linux26, solaris, freebsd, openbsd, Cygwin, custom。 如果不确定目标系统,可以保留默认值generic。 CPU 指定对特定的CPU进行优化,可选择如下值之一:generic, i586, i686, ultrasparc, custom。默认值为generic。 ARCH 指定ARCH值可强制编译生成针对一个特定系统架构的程序。通常用于在一个系统架构的平台上生成针对另一个不同架构平台的程序,比如在一个64位架构的目标系统上编译生成一个32位的程序。 当前可选的值有:x86_64, i386, i486, i586, i686。 注:若选择上述其中的一个值,”-m32”或”-m64”会被添加到CFLAGS和LDFLAGS选 项中。
Kettle开发使用手册范本
Kettle开发使用手册 2017年4月
版本历史说明
1.Kettle介绍 1.1.什么是Kettle Kettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。1.2.Kettle的安装 Kettle工具是不需要安装的,直接网上下载解压就可以运行了。不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。 运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图1.1所示: 图1.1
2.Kettle脚本开发 2.1.建立资源库(repository仓库) Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle 开发环境也是要用到该资源库。建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle file repository选项,按确定,如图2.1所示: 图2.1 跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图2.2所示: 图2.2 建完后会kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。在连接到资源库的情况下打开文件就是
曙光SAS RAID卡配置工具与操作指南
前言 感谢您选用曙光服务器,配置曙光服务器SAS RAID卡前请详细阅读本手册。 本手册主要介绍了RAID的功能以及对各RAID级别进行了解释;同时对于曙光服务器中的SAS RAID卡的配置进行了说明。 本手册主要包括如下三个部分: 一、RAID简介及各RAID级别介绍; 二、对基于LSI ROC1078芯片的RAID卡的配置、操作系统下的管理工具的安装使用进行了介绍; 三、对基于Adaptec SAS RAID卡的配置、作系统下的管理工具的安装使用进行了介绍。 版权所有 ?2006 曙光信息产业有限公司。 本手册受版权法保护,本手册的任何部分未经曙光信息产业有限公司授权,不得擅自复制或转载。 本手册中提到的信息,如因产品升级或其他原因而导致变更,恕不另行通知。 “Lsilogic”及图标是LSI公司的注册商标。 “Adaptec”及图标是Adaptec公司的注册商标。 其他注册商标均由其各自的商标持有人所有。
目录 前言--------------------------------------------------------------------------------1第一章 Raid技术简介---------------------------------------------------------3 1 Raid技术简介------------------------------------------------------------------------------------------3 2 Raid级别简介------------------------------------------------------------------------------------------3 3 Raid各级别的对比------------------------------------------------------------------------------------8 4 Raid术语简介------------------------------------------------------------------------------------------8 第二章 LSI Raid配置及管理软件介绍-----------------------------------12 2.1 LSI Raid WebBIOS Configuration Utility配置向导------------------------------------------12 2.1.1 WebBIOS Configuration Utility简介---------------------------------------------------12 2.1.2 如何进入WebBIOS Configuration Utility--------------------------------------------12 2.1.3 WebBIOS Configuration Utility 存储配置--------------------------------------------14 2.1. 3.1 自动配置:-------------------------------------------------------------------------------15 2.1. 3.2 自定义配置:----------------------------------------------------------------------------15 2.1.4 设置热备盘(Hot Spare)---------------------------------------------------------------17 2.1.5查看及修改相关配置信息----------------------------------------------------------------19 2.2 MegaRaid Storage manager 管理软件安装与使用-------------------------------------------23 2.2.1 MegaRaid Storage manager在Windows下的安装----------------------------------24 2.2.2 MegaRaid Storage manager配置与使用-----------------------------------------------28 2.2.3 MegaRaid Storage manager 管理软件在Linux系统下的安装与使用--------35 第三章 Adaptec Raid配置及管理软件介绍------------------------------36 3.1 Adaptec Configuration Utility配置向导--------------------------------------------------------36 3.1.1 Array Configuration Utility---------------------------------------------------------------37 3.1.2 SerialSelect Utility--------------------------------------------------------------------------43 3.1.3 Disk Utilities---------------------------------------------------------------------------------44 3.1.4 View the Event Log------------------------------------------------------------------------44 3.2 Adaptec Storage Manager 管理软件安装与使用---------------------------------------------45 3.2.1 Adaptec Storage manager在Windows下的安装-------------------------------------45 3.2.2 Adaptec Storage Manager配置与使用-------------------------------------------------48 3.2.3 Adaptec Storage manager在Linux下的安装与使用--------------------------------55
配置nginx到后端服务器负载均衡
nginx和haproxy一样也可以做前端请求分发实现负载均衡效果,比如一个tomcat服务如果并发过高会导致处理很慢,新来的请求就会排队,到一定程度时请求就可能会返回错误或者拒绝服务,所以通过负载均衡使用多个后端服务器处理请求,是比较有效的提升性能的方法;另外当单机性能优化到一定瓶颈之后,一般也会用负载均衡做集群,配置也很简单,下面是配置过程: 首先需要安装nginx服务器,我这里已经安装好了,比如这里有三个tomcat 服务器,地址如下: 192.168.1.23 8080 192.168.1.24 8080 192.168.1.25 8080 其中nginx安装在192.168.1.23上面,如果只有一个服务器测试,也可以在一个服务器上运行多个tomcat开多个端口来实现,这样也能提升性能首先看nginx配置,在nginx.conf中http {}块内并且server {}块之外添加如下配置: upstream my_service { server 127.0.0.1:8080 weight=2; server 192.168.1.24:8080 weight=1; server 192.168.1.25:8080 weight=1; } 上面的my_service是集群的名字,可以自己命名,server指定后端服务列表,weight是设置权重,权重越大,请求被分发过来的可能性就越大,这里本机权重设置了2,也就是说对到达的请求分配到本地上的会多一些配置这个之后,需要在server {}中添加location配置拦截请求并转发给后端的集群,最简单的配置如下: location / {
KETTLE组件介绍与使用
KETTLE组件介绍与使用 4.1 Kettle使用 Kettle提供了资源库的方式来整合所有的工作,; 1)创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为Trans,kettle默认transformation文件保存后后缀名为ktr; 2)创建一个新的job,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为Job,kettle默认job文件保存后后缀名为kjb; 4.2 组件树介绍 4.2.1Transformation 的主对象树和核心对象分别如下图:
Transformation中的节点介绍如下: Main Tree:菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。 Steps:一个transformation中应用到的环节列表 Hops:一个transformation中应用到的节点连接列表 核心对象菜单列出的是transformation中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加: Input:输入环节 Output:输出环节 Lookup:查询环节 Transform:转化环节 Joins:连接环节 Scripting:脚本环节 4.2.2 Job 的主对象树和核心对象分别如下图: Main Tree菜单列出的是一个Job中基本的属性,可以通过各个节点来查看。 DB连接:显示当前Job中的数据库连接,每一个Job的数据库连接都需要单独配置。 Job entries/作业项目:一个Job中引用的环节列表 核心对象菜单列出的是Job中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。 每一个环节可以通过鼠标拖动来将环节添加到主窗口中。 并可通过shift+鼠标拖动,实现环节之间的连接。
批量配置工具用户手册(可视对讲)
批量配置工具 用户手册
版权所有?杭州海康威视数字技术股份有限公司2016。保留一切权利。 本手册的任何部分,包括文字、图片、图形等均归属于杭州海康威视数字技术股份有限公司或其子公司(以下简称“本公司”或“海康威视”)。未经书面许可,任何单位和个人不得以任何方式摘录、复制、翻译、修改本手册的全部或部分。除非另有约定,本公司不对本手册提供任何明示或默示的声明或保证。 关于本手册 本手册描述的产品仅供中国大陆地区销售和使用。 本手册作为指导使用。手册中所提供照片、图形、图表和插图等,仅用于解释和说明目的,与具体产品可能存在差异,请以实物为准。因产品版本升级或其他需要,本公司可能对本手册进行更新,如您需要最新版手册,请您登录公司官网查阅(https://www.360docs.net/doc/2010470716.html,)。 海康威视建议您在专业人员的指导下使用本手册。 商标声明 为海康威视的注册商标。本手册涉及的其他商标由其所有人各自拥有。 责任声明 ●在法律允许的最大范围内,本手册所描述的产品(含其硬件、软件、固件等)均“按照现状”提供,可能存在瑕疵、错误或故障,本公司不提供任何形式的明示或默示保证,包括但不限于适销性、质量满意度、适合特定目的、不侵犯第三方权利等保证;亦不对使用本手册或使用本公司产品导致的任何特殊、附带、偶然或间接的损害进行赔偿,包括但不限于商业利润损失、数据或文档丢失产生的损失。 ●若您将产品接入互联网需自担风险,包括但不限于产品可能遭受网络攻击、黑客攻击、病毒感染等,本公司不对因此造成的产品工作异常、信息泄露等问题承担责任,但本公司将及时为您提供产品相关技术支持。 ●使用本产品时,请您严格遵循适用的法律。若本产品被用于侵犯第三方权利或其他不当用途,本公司概不承担任何责任。 ●如本手册内容与适用的法律相冲突,则以法律规定为准。
PXC5.6实验集群的安装与设置
PXC5.6实验集群的安装与设置
目录 1.目的: (4) 2.集群构成: (5) 2.1.集群构成图: (5) 2.2.集群构成明细: (5) 3.安装设置操作步骤: (6) 3.1.安装Percona Yum Repository: (6) 3.2.安装EPEL源: (7) 3.3.安装PXC (7) 3.4.创建及设置数据目录 (8) 3.5.开通PXC相关IP端口 (9) 3.6.关闭SELinux (10) 3.7.设置https://www.360docs.net/doc/2010470716.html,f启动项文件 (10) 3.8.启动集群 (12) 4.通过HAProxy实现PXC集群负载均衡: (14) 4.1.安装HAProxy (14) 4.2.设置HAProxy (14) 4.3.启动HAProxy (16) 4.4.增加集群状态检查进程用Mysql用户权限 (16) 4.5.为集群每一个节点服务器安装xinetd (17) 4.6.配置xinetd (17) 4.7.通过HAProxy查看数据库集群状态: (18)
5.用Keepalived解决HAProxy单点故障: (20) 5.1.安装配置备份代理服务器 (20) 5.2.安装Keepalived (21) 5.3.在主HAProxy代理服务器中设置Keepalived (21) 5.4.在备份HAProxy代理服务器中设置Keepalived (23) 5.5.验证虚拟IP的漂移 (24) 6.问题排查及解决: (25) 6.1.ERROR 1047 (08S01): WSREP has not yet prepared node for application use (25)
Kettle开发使用手册
Kettle开发使用手册2017年4月
版本历史说明
1.Kettle介绍 1.1.什么是Kettle Kettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。1.2.Kettle的安装 Kettle工具是不需要安装的,直接网上下载解压就可以运行了。不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。 运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图1.1所示: 图1.1
2.Kettle脚本开发 2.1.建立资源库(repository仓库) Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle file repository选项,按确定,如图2.1所示: 图2.1 跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图2.2所示: 图2.2 建完后会kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。在连接到资源库的情况下打开文件就是资源库所在目录了,如图2.3所示。注意你在资源库建的目录结构要跟数据交换平台的目录结构一致,这样写好kettle脚本,保存后放的路径能跟交换平台的目录结构一致了。
快速配置指南
第1章产品安装 本说明书中的产品安装步骤以W316R为例,其他两款的安装方法与此类似。 1、请使用附带的电源适配器给路由器供电。(使用不匹配的电源适配器可能会对路由器造成损坏。) 2、请使用网线将路由器LAN口与您的计算机网卡连接。 3、将您的宽带线(电信ADSL、网通ADSL、长城宽带、天威视讯等)与路由器的WAN 口连接。 4、检查面板各指示灯状态。 面板指示灯图示: 各指示灯定义:
后面板接口图示:(以W316R为例) 面板接口意义: 5、请将附带的“一键设定”光盘放入计算机的光驱中,自动运行后或直接点击光盘中的“Setup”运行光盘,然后根据提示完成安装。或者进入路由器设置页面进行设置(详细请参考第三章)。
第2章设置上网 2.1 正确设置您的计算机网络配置 Windows XP系统配置 1、在您电脑桌面上,用鼠标右键单击“网上邻居”,在弹出的菜单中选择“属性”; 2、在随后打开的窗口里,用鼠标右键点击“本地连接”,选择“属性”; 3、在弹出的对话框里,先选择“Internet协议(TCP/IP)”,再用鼠标点击“属性”按钮;
4、在随后打开的窗口里,您可以选择“自动获得IP地址(O)”或者是“使用下面的IP地址(S)”; a、“自动获得IP地址(O)”如图: b、“使用下面的IP地址(S)” IP地址:192.168.0.XXX:(XXX为2~254) 子网掩码:255.255.255.0 网关:192.168.0.1 DNS服务器:您可以填写您当地的DNS服务器地址(可咨询您的ISP供应商),也可
以填写192.168.0.1。 设置完成后点击“确定”提交设置,再在本地连接“属性”中点击“确定”保存设置。 Windows7系统配置 1. 点击桌面右下角任务栏网络图标,并点击"打开网络和共享中心"按钮。 2. 在打开的窗口里点击左侧的"更改适配器设置"。
搜索配置工具使用说明剖析
搜索配置工具使用说明 1.网络设备搜索 网络设备搜索用于发现与软件运行PC同一个子网内的在线设备,工具软件还可以对搜索出的设备的基本信息进行修改。工具软件开始运行时如图1-1所示 图1-1 1.1修改端口 用户选择一个在线设备后,其各项信息会显示在图1-1中在线列表的下方,用户可以对端口进行修改。 1.2批量修改IP 当用户在在线列表中勾选多个设备后,输入起始IP、子网掩码、DNS、网关,点击批量修改IP,可以对多个设备自动修改IP地址。 1.3导出设备信息 该功能是将在线列表中的所有设备信息以CSV格式文件导出。 1.4恢复密码 (1).用户首先获得设备ID和运行时长 (2).拨打400电话获得加密字符串 (3).一小时内将加密字符串输入到密码追回框中,进行密码恢复 1.5重启设备 对当前选中的设备进行重启,不支持批量。 1.6写入文件 如果勾选了写入文件,该软件所产生的日志信息将会以文本形式记录到C盘下 2.参数配置 该配置页包含前端设备参数、通道参数、常用设置、保存配置文件、网络测试、格式化磁盘、清理插件功能。 在每项参数设置中都有“保存至模板”复选框,如果勾选“保存至模板”,当点击“保存模板”按钮时,可以将“常用参数配置”的数据保存到配置文件中,不勾选“保存至模板”
则不对其进行保存。 界面如图2-1所示 图2-1 2.1前端参数配置 (1).打开参数配置页,默认进入前端参数配置 (2).右击设备树,点击“登录”按钮登陆设备,登录后设备树会有相应颜色变化(成功:绿色,失败:红色,超时:蓝色) (3)在面板右侧选择设备类型IPC或者球机 (4).用户可以在“常用参数配置”中对设备进行控制 (5).点击“保存参数”,会将数据配置到设备 (6).勾选“显示码率帧率”,视频会叠加当前的码率和帧率 2.2 通道参数配置,界面如图2-2所示 (1).在字符叠加配置中,用户可以选择叠加通道名称和叠加通道时间,点击“保存参数”时,会进行相应的叠加。 (2).在音视频参数配置中,可以对设备的音视频参数进行设置,视频默认连接的是主码流,音视频参数模块的主副码流单纯的只是配置参数,与IE相对应,具体设置项见图2-2。(3).录像参数配置中,用户可以设置设备的录像时间模板,具体设置项见图2-2。
haproxy高级配置
使用rchs集群套件基于conga界面配置apache高可用集群 电源设备采用“virtual machine fencing” Conga是一个基于web界面的c/s架构的配置集群的工具 c 集群节点作为被服务管理集群配置的客户端节点 s 专门用于管理集群、配置集群的一个服务端节点 在S服务端上安装luci的服务端软件,打开该软件提供的一个web界面,进行集群的配置(配置的步骤跟使用rhel5上的system-config-cluster雷同),唯一的区别是,服务端(本机)本身并不参与集群,并不属于集群中的成员。 在c客户端上安装ricci服务,该服务会与服务端的luci建立连接,接受服务端的集群管理操作。客户端才是集群中的成员。 准备: FQDN、静态IP 、hosts文件 clients | |----------------| node1 node2 https://www.360docs.net/doc/2010470716.html, 192.168.29.11 https://www.360docs.net/doc/2010470716.html, 192.168.29.12 资源: vip 192.168.29.10 httpd OS :rhel6 准备: 静态IP、FQDN、hosts 暂时关闭iptables ,selinux
[Base] name=Base baseurl=file:///soft/el63 enabled=1 gpgcheck=0 [HighAvailability] name=LoadBalancer baseurl=file:///soft/el63/HighAvailability enabled=1 gpgcheck=0 [ResilientStorage] name=ResilientStorage baseurl=file:///soft/el63/ResilientStorage enabled=1 gpgcheck=0 [ScalableFileSystem] name=ScalableFileSystem baseurl=file:///soft/el63/ScalableFileSystem enabled=1 gpgcheck=0 一、在宿主机上模拟fence设备 # yum install fence-virt.x86_64 fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y fence-virt 实际用于fence设备工具:实际用于关机、重启、启动客户机的工具 fence-virtd 模拟fence设备的服务:负责接受集群中的节点(客户机)fence指令 fence-virtd-libvirt.x86_64 <----操作虚拟化的接口库 fence-virtd-multicast.x86_64 组播的方式在宿主机(fence-virtd服务)和客户机(集群节点)之间传达电源指令《---以模块的形式存在 软件安装完毕后,存在一个配置文件/etc/fence_virt.conf 向导配置 # fence_virtd -c
pentaho-Kettle安装及使用说明(例子)
Kettle安装及使用说明 1.什么Kettle? Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。Kettle包括三大块: Spoon——转换/工作(transform/job)设计工具(GUI方式) Kitchen——工作(job)执行器(命令行方式) Span——转换(trasform)执行器(命令行方式) Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高 效稳定。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。 2.Kettle简单例子 2.1下载及安装Kettle 下载地址:https://www.360docs.net/doc/2010470716.html,/projects/pentaho/files 现在最新的版本是 3.6,为了统一版本,建议下载 3.2,即下载这个文件pdi-ce-3.2.0-stable.zip。 解压下载下来的文件,把它放在D:\下面。在D:\data-integration文件夹里,我们就可以看到Kettle的启动文件Kettle.exe或Spoon.bat。 2.2 启动Kettle 点击D:\data-integration\下面的Kettle.exe或Spoon.bat,过一会儿,就会出现Kettle的欢迎界面:
稍等几秒,就会出现Kettle的主界面: 2.3 创建transformation过程 a.配置数据环境 在做这个例子之前,我们需要先配置一下数据源,这个例子中,我们用到了三个数据库,分别是:Oracle、MySql、SQLServer,以及一个文本文件。而且都放置在不同的主机上。 Oralce:ip地址为192.168.1.103,Oracle的实例名为scgtoa,创建语句为:create table userInfo( id int primary key,
通达OA管理员快速设置指南
通达OA管理员快速设置指南 一、常见问题 其他客户机如何使用OA软件,需要安装软件么? 客户机不需要安装软件,只要打开IE浏览器,输入OA服务器网址访问。 例如OA服务器计算机名为server,IP地址为192.168.0.10。 客户机访问可以输入 http://server 或者 http://192.168.0.10 如果OA软件设置的端口号不是80,请在网址后加冒号端口号 例如端口为8080,则网址为 http://server:8080 或者 http://192.168.0.10:8080 二、OA管理员初始化设置步骤 1、角色权限的设置 在初次进行OA的时候,首先需要定义不同的角色,设置角色权限的模块在菜单“系统管理/组织机构设置/角色与权限管理”。 每个用户都被赋予一个或多个“角色”,角色分为主角色和辅助角色,一个用户只能有一个主角色,但可以被授予多个辅助角色。角色反映了用户被授权看到的模块集合,一个用户能够在软件中看到多少模块,就是该用户的主角色和辅助角色中授权的模块的集合。 除了模块授权,角色还代表了什么? 首先,通达OA中很多模块是要区分管理级别的,而角色就决定了用户在OA软件中的管理级别。例如,用户在查看员工工作日志或者日程安排时,主角色的排序高低,决定了该用户有权查看哪些用户的日志和日程。 角色还代表了一个“用户类别”,即:拥有相同的主角色或者辅助角色的人员,可以被视作一个“用户类别”,一个用户可能被涵盖在一个或者多个“用户类别”中,这种类别,我们可以理解为在一个单位中拥有相同“职位”或者相同权限者的一种称呼。比如说,主角色为“部门经理”的用户可能有10个人,这10个人拥有作为“部门经理”这个角色的相同模块权限。在OA中设置公告、文件等的发布范围的时候,都可以将角色作为一个类别来进行选择,具备相同角色的人就可以得到相同的权限设置。 2、组织结构的管理 组织结构由单位、部门和用户三种元素组成,相关的设置菜单,在菜单“系统管理/组织机构设置”下。 虽然我们只能设置一个单位,但单位下可以设置任意多层次任意多数量的部门或分支公司,每个部门可以设定其下的用户,每个用户可以属于一个或多个部门。组织机构可以用这
自己总结的Kettle使用方法和成果
KETTLE使用自己总结的Kettle使用方法和成果说明 简介 Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。 Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。 Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。 Kettle可以在https://www.360docs.net/doc/2010470716.html,/网站下载到。 注:ETL,是英文Extract-Transform-Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。 下载和安装 首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20.0。 下载网址:https://www.360docs.net/doc/2010470716.html,/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi-ce-5.2.0.0-209.zip,解压后会在当前目录下上传一个目录,名为data-integration。 由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。 ?Kettle可以在https://www.360docs.net/doc/2010470716.html,/网站下载 ? 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。运行Kettle 进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat 或Kettle.exe文件。Linux用户需要运行spoon.sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令: # chmod +x spoon.sh # nohup ./spoon.sh &后台运行脚本 这样就可以打开配置Kettle脚本的UI界面。
ONVIF Device Manager测试工具使用方法
ONVIF 测试工具使用方法 ONVIF Device Manage工具主要用来验证设备是否支持onvif,实时预览、PTZ控制及远程配置IPC参数等功能。 一、ONVIF Device Manage安装 1.PC安装环境要求:装有Microsoft .Net Framework 4.0版本 2.安装源文件请见:ONVIF Device Manage.rar 注:Microsoft .Net Framework 4.0安装不成功的解决方式,见备注。 二、ONVIF Device Manage的使用 1.运行工具 双击ONVIF Device Manage快捷方式,运行工具。当前局域网内,支持onvif协议的IPC可以自动显示出来,见下图。Device List列表即检索到的IPC列表 2.基本功能介绍
1>登录 此时输入的用户名和密码为设备自身的用户名和密码,有的厂家设备不需要。输入正确的用户名和密码,即可实时预览IPC及参数配置。 2>实时预览 在设备列表选择一个IPC(单击即可),点击Live video即可预览该IPC画面,main stream是主码流预览,sub stream是子码流预览 3>检索 在Device List区域的文本框输入IP地址,即可过滤其它IPC,留下符合条件的设备.
4>手动增加 点击Add按钮,输入url,例如http://192.168.1.123/onvif/device_service,点击Apply,即可手动增加IPC 5>rtsp路径
实时预览画面的下方,会显示rtsp路径。如下: rtsp://192.168.1.166:5504/channel=0;stream=0;user=system;pass=system 192.168.1.166为IPC的地址 5504为IPC的端口 channel为通道 stream为码流,0默认是主码流,1为子码流 user和pass:用户名和密码 6>视频编码配置 选择子码流预览,可以配置子码流的编码参数 7>码流选择 点击Profiles,进入码流切换界面
HAPROXY安装及配置详解与算法
HAProxy安装及配置详解与算法 HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。 HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy 运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整 合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。 其支持从4层至7层的网络交换,即覆盖所有的TCP协议。就是说,Haproxy甚至还支持Mysql的 均衡负载。如果说在功能上,能以proxy反向代理方式实现WEB均衡负载,这样的产品有很多。包括Nginx,ApacheProxy,lighttpd,Cheroke等。 但要明确一点的,Haproxy并不是Http服务器。以上提到所有带反向代理均衡负载的产品,都 清一色是WEB服务器。简单说,就是他们能自个儿提供静态(html,jpg,gif..)或动态(php,cgi..) 文件的传输以及处理。而Haproxy仅仅,而且专门是一款的用于均衡负载的应用代理。其自身并不能提 供http服务。
但其配置简单,拥有非常不错的服务器健康检查功能还有专门的系统状态监控页面,当其代理的后端服务器出现故障,HAProxy会自动将该服务器摘除,故障恢复后再自动将该服务器加入。自1.3版本开始还引入了frontend,backend,frontend根据任意HTTP请求头内容做规则匹配,然后把请求定向到相关的backend。 1.安装 官方版本获取地址:http://haproxy.1wt.eu/,不过官方页面已经打不开了,请自行搜索! 上面中的26是linux系统内核,通过命令#uname-a可查看,我使用的是CentOS #tar xzvf haproxy-1.4.24.tar.gz #cd haproxy-1.4.24 #make TARGET=linux26PREFIX=/usr/local/haproxy #make install PREFIX=/usr/local/haproxyb 2.配置 安装完毕后,进入安装目录配置文件,默认情况下目录里是没有.cfg配置文件的,可以回到安装文件目录下将examples下的haproxy.cfg拷贝到usr/local/haproxy下。 #cd/usr/local/haproxy #vi haproxy.cfg 默认文件内容如下:(注意!!标示开始的为默认的配置文件没有的)